
基于外周视野刺激物的驾驶员视觉搜索机制研究
2021-07-10 02:20周理想
科技与创新 2021年12期
周理想,曾 娟
(武汉理工大学汽车工程学院,湖北 武汉 430070)
1 简介
在汽车行驶过程中,危险物通常以外显刺激的方式呈现。比较典型的场景有前方车辆突然刹车、临近车道上车辆突然变道、行人横穿马路等。而驾驶过程中80%的有用信息依靠眼睛获取,其余感官获取信息比例只占20%[1],因此,驾驶员视觉搜索模式的研究对于揭示交通事故的机理、主动安全技术开发具有非常重要的意义。
对于出现在中央视野和外周视野的刺激,驾驶员认知加工过程是不同的。神经生理学研究表明[2]:中心视野的信息由视觉皮层来处理,而外周视野的信息由大脑皮层下通道处理。由于光流效应,驾驶员在识别外周视野刺激物时,会对自己的车速产生错觉,眼睛产生感知的深度线索,纹理梯度与距离成反比[3]。而外周视野空间的部分信息发生改变,驾驶员会产生视觉的选择性注意[4],即视觉对信号产生有选择的处理和加工。方向、运动、空间频率和最小可感知的差异都对外源性眼睛跳跃有显著贡献,在中央视野,刺激物直接落在视网膜中央凹视觉区内,优先获得注意力;在外周视野,刺激物会引起眼球自动朝向反应[5],但目前的研究还无法确定眼动和注意机制发生的先后顺序[6]。
KRENDEL等[7]根据搜索时间t以及累积搜索概率F(t),提出了单目标随机搜索模型。NEISSER[8]提出单目标系统搜索策略,特征为扫视点严格不重复,即第i个扫视点只能随机分布在前i-1个扫视点没有覆盖的区域,并提出累积概率与搜索时间之间直线关系函数。ENGEL[9]给出了视觉搜索作业中发现一个目标所需的平均时间。随后,MORAWSKI等[10]进一步发展了单目标随机视觉搜索模型,得到了比较完整的发现目标累积概率与搜索时间的指数关系函数。ARANI等[11]提出了可变记忆效果模型,该模型非常复杂,包含了第i次扫视时回忆第i-1个扫视点的概率。CORBETTA等[12]研究了眼动与注意转移机制的关系。视觉搜索是通过一系列眼跳(saccades)和注视(fixation)获取外界刺激信息,二者在选择视觉信息、找到注视目标以及忽略无关信息的过程中都发挥作用,但二者相互独立,同时也相互影响。眼跳是对目标的外显朝向,而注意是对选择物体过程的内隐朝向。
近60年来,学术界基本都通过视觉搜索时间分布曲线来判断视觉搜索策略。采用拟合分布曲线最大的缺陷在于样本数量具有局限性。当训练样本无限多时,训练误差才收敛于实际风险,然而在实际中,样本数量通常都是有限的[13]。采用传统数值拟合的方式判断视觉搜索模式存在着规则制定困难、推广实用性差的局限性。另外在驾驶行为中,一个典型的场景是驾驶主任务和外周视野刺激物双重任务。随着搜索目标个数的增加及其相互间的交互,拟合视觉搜索绩效模型的有效性及可操作性都受影响[14]。因此,对多目标视觉搜索模式的影响因子交互关系及独立性问题的研究,更有效、可行的算法设计是该领域研究的难点所在。
21世纪以来,随着信息跟踪技术和通信技术的迅猛发展,人因工程领域内大量的视觉信息以计算机可读的形式存在,精准的眼动数据实时采集和存储为机器学习的数据处理方法提供了充分的资源。在这种情况下,以机器学习技术为主的视觉搜索分类技术逐步取代基于拟合曲线的统计方法,成为机器视觉领域里的重点研究方向。
在机器视觉领域的分类算法主要包括三类:①基于概率论和信息理论的分类算法,如朴素贝叶斯算法(Naïve Bayes,简称“NB”)[15]、最大熵算法[16];②基于TFIDF权值计算方法的算法,包括Rocchio算法、TFIDF算法、K近邻算法(简称“KN”)[17];③基于知识学习的分类算法,如决策树、人工神经网络(简称“ANN”)、支持向量机(简称“SVM”)[18]。
同决策树、人工神经网络算法相比,支持向量机基于结构风险最小化原理,而不是基于经验风险最小化原理,因此不存在局部极小点问题,避免了模型选择、过学习的问题,具有很强的泛化能力。SVM分类算法的最大优势是针对样本不足的问题,在选取合适的和函数、惩罚函数的基础上,仍然可以获得较高的分类正确率[19]。
针对驾驶过程中外周视野目标搜索问题,本研究将探讨视觉搜索模式中影响因子的交互关系,在此基础上,采用SVM分类方法构建视觉搜索绩效的判断模型。
2 方法
2.1 实验设计
本实验采用实车场地测试的方式。驾驶员头戴眼动仪,驾驶汽车通过道路宽10 m的双向道路。道路全长1 000 m。实验按速度分为3个水平:v=20 km/h、v=25 km/h、v=30 km/h。受试者按照性别、年龄平均分成3组,每组10人。实验场景包括2个干扰场景和1个实验场景:①干扰场景1,对向车道上有轿车变道;②干扰场景2,前方车辆减速;③实验场景,当车辆距离设定位置10 m时,行人从固定位置横穿马路,行人速度为10 km/h。行人起始点位于驾驶员外周视野内。观察驾驶员是否有反应,对应指标为驾驶员眼动指标、转向指标和踩刹车指标。
受试者为30名有经验的驾驶员(驾龄大于3年)。男性驾驶员25名,女性驾驶员5名,年龄分布20~60岁。受试者此前均未接受过类似实验。
本实验选用Tobii Pro Glasses 2眼镜式眼动仪,如图1所示。采用的实验车是广州本田思铂睿。

图1 Tobii Pro Glasses 2眼镜式眼动仪
2.2 实验操作流程
实验流程如下:①驾驶员戴好眼动仪,按照指定路线行驶400 m路程,副驾驶的工作人员讲解实验注意事项。②由场边工作人员指引到实验车道,加速到指定车速。依次经过上述三个场景。每位受试者仅参与一次实验。眼动仪场景摄像头记录整个实验过程,并将视频数据储存在SD储存卡中。③实验结束后,由工作人员将车开回指定的起点,重复上述过程,直到所有实验组结束。
3 实验结果
实验样本共30个,其中有效实验样本24个,无效实验样本6个。在有效实验样本中,踩下制动踏板的样本共20个,未踩下制动踏板的样本4个。
踩下制动踏板和未踩下制动踏板受试者累计注视时间对比如图2所示。A组为踩下制动踏板的样本组,B组为未踩下制动踏板的样本组。
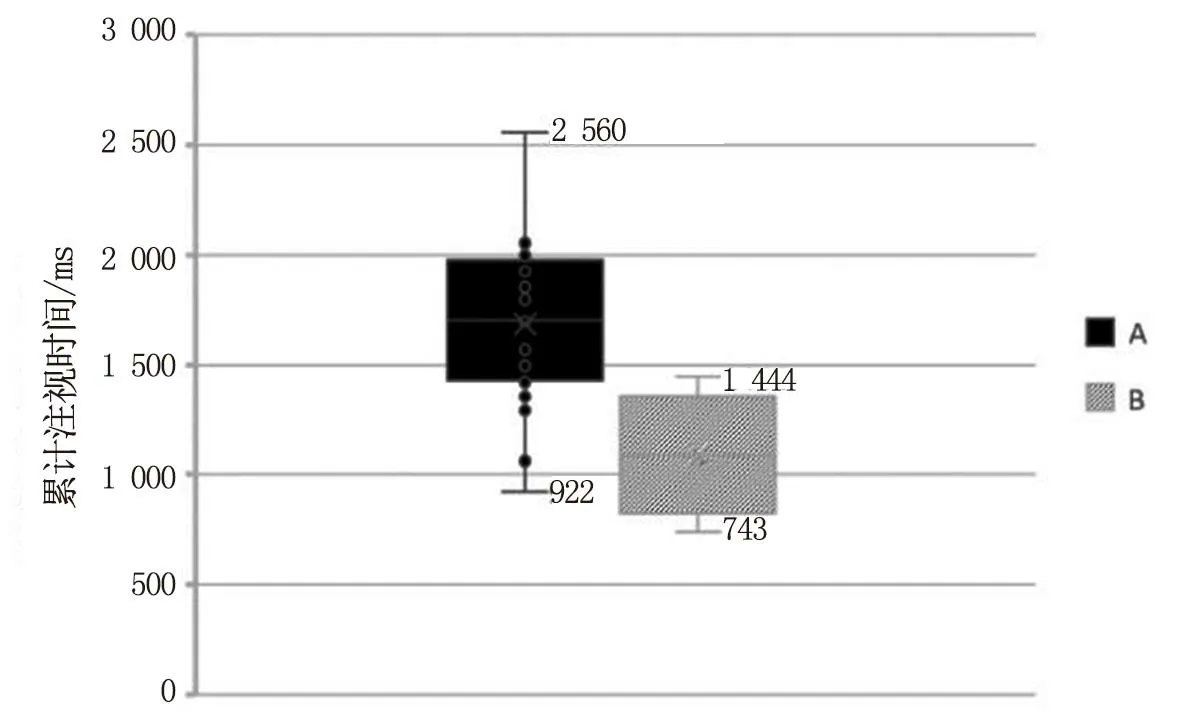
图2 累计注视时间对比
由图2可看出,A组样本的累计注视时间最低值为922 ms,B组最低值则为743 ms,最高值为1 444 ms,A组75%的样本累计注视时间在1 420~1 560 ms之间,A组在1 444 ms以上是高于B组样本的,但是,A组累计注视时间中在922~1 444 ms这一值域之间的样本和B组样本是重合的。这说明,累计注视时间不能单独用来衡量注意的加工行为是否发生(即是否踩下自动踏板)。
进一步分析眼跳频率,踩下制动踏板和未踩下制动踏板受试者眼跳频率分布如图3所示。A组为踩下制动踏板的样本组,B组为未踩下制动踏板的样本组。
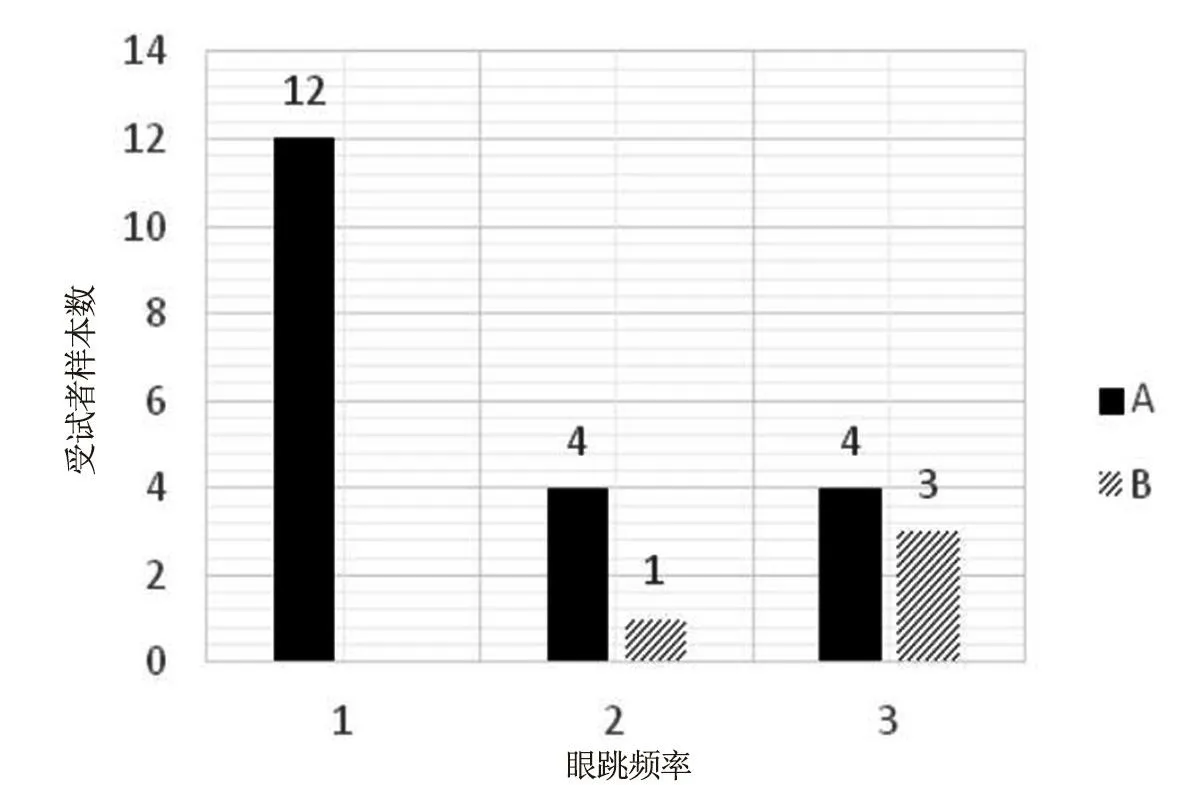
图3 受试者眼跳频率分布图
图3 中A组为踩下制动踏板的样本组,认定为注意到了外周视野的危险;B组为未踩下制动踏板的样本组,实验结束后访谈,4人均表示没有注意到外周视野的危险。A组受试者有2种视觉搜索模式,有12位受试者采用系统搜索模式,即仅眼跳1次便进行信息加工,有8位受试者采用随机搜索模式[14],多次眼跳,扫视点有重复,有信息加工。而B组受试者多次眼跳过程中信息加工并未发生。两者综合说明,在随机搜索的过程中,信息的加工可能发生,也可能不发生。所以,眼跳频率不能单独用来衡量注意的加工行为是否发生。
踩下制动踏板的受试者发生单次眼跳、两次眼跳和三次眼跳时注视时间最大值分布如图4所示。
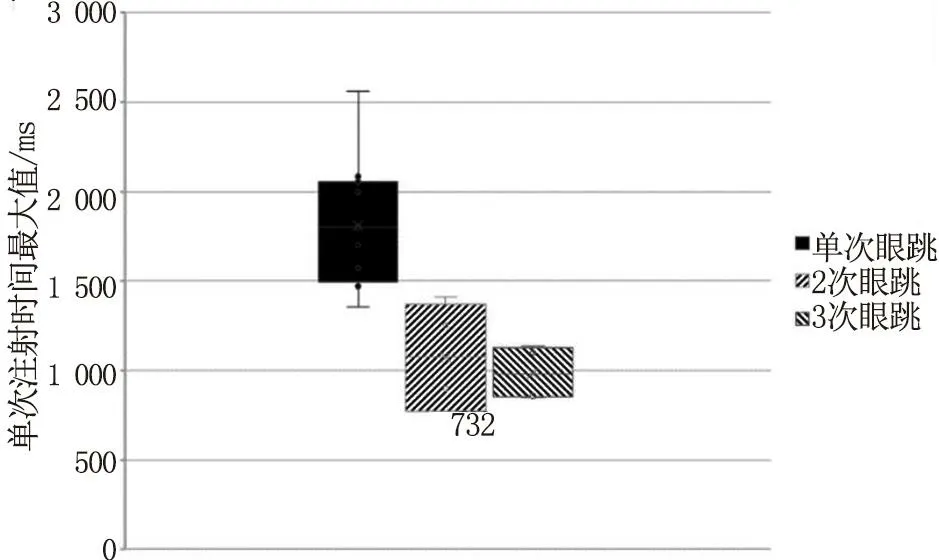
图4 踩下制动踏板受试者单次注视时间最大值分布图
从图4看出,踩下制动踏板的样本中,在单次眼跳的样本中75%的受试者单次注视时间最大值在1 469~2 560 ms之间,二次眼跳的样本中单次注视时间最大值在732~1410ms之间,三次眼跳的样本中单次注视时间最大值在849~1 134 ms之间,即单次眼跳要明显高于发生二次和三次眼跳的样本。无论是单次眼跳还是多次眼跳,踩下制动踏板受试者单次注视时间的最大值的取值不低于732 ms;而对于未踩下制动踏板的样本,其单次注视时间的最大值均低于500 ms,即踩下制动踏板的样本的值域明显高于未踩下制动踏板样本的值域。因此,单次注视时间可以作为信息加工是否发生的判断因子。
4 基于SVM的视觉搜索绩效判断模型
4.1 数据预处理
对数据进行SVM建模,首先需要提取特征变量。由于单次注视时间可以用来判断信息的加工是否发生,因此,解释变量选取为驾驶人单次注视时间。
当各个解释变量之间的相关系数过高时,可能会存在多重共线性问题。通过相关系数矩阵观察各个解释变量之间的相关性,发现各个解释变量之间的相关系数均低于0.4,基本上认为在本研究中不存在多重共线性问题。因此,适合建模需要。
4.2 SVM模型构建
SVM模型是一种基于统计学习理论用来解决分类问题的非参数方法,该模型最初被应用于二分类问题且已经被很多研究中所使用[20]。
根据模式识别理论,低维空间线性不可分的模式通过非线性映射到高维特征空间则可能实现线性可分,但是如果直接采用这种技术在高维空间进行分类或回归,则存在确定非线性映射函数的形式和参数、特征空间维数等问题,而最大的障碍则是在高维特征空间运算时存在的“维数灾难”。采用核函数技术可以有效地解决这样的问题。
将被解释变量设为驾驶人是否踩下自动踏板,即信息的加工是否发生,将踩下制动踏板归为正类,未踩下制动踏板归为负类。将样本分为训练集和测试集,其中各占50%。建立SVM模型,由于各个特征之间的相关系数较低,选择多项式核函数,拟合模型,预测并计算准确率。
ROC曲线是根据二分类方式(分界值或决定阈),以真阳率为纵坐标,误检率为横坐标绘制的曲线。在计算出准确率的基础上,定义函数画ROC图,如图5所示。
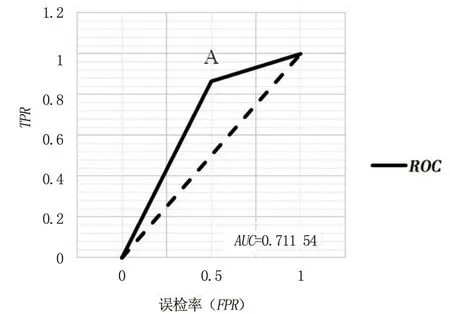
图5 AUC-ROC曲线
从AUC-ROC曲线可以看出,SVM模型的真阳率(TPR)为86.67%(图中A点),这说明,实际是正类(踩下制动踏板)中,有86.67%的正类被SVM模型发现。SVM模型的误检率(FPR)为50%,这说明,SVM模型误认为正类的负实例(未踩下制动踏板)占所有负实例的比例为50%。
AUC(Area Under Curve)被定义为ROC曲线下与坐标轴围成的面积,图中AUC=0.711 54,表明SVM模型的预测能力较好但不够完美,其中主要原因是未刹车的样本量占比仅有14.81%且样本量较少,使得模型对负类实例的错分类就十分敏感,模型预测的FPR大大提高。要解决这一问题,可以使正负样本的比例比较均匀或者提高样本量。
5 结论
因为在累计注视时间922~1 444 ms这一值域内注意的加工行为有可能发生,有可能未发生。因此,累计注视时间不能单独用来衡量注意的信息加工行为是否发生。在随机搜索的过程中,信息的加工可能发生,也可能不发生。因此,眼跳频率不能用来衡量信息的加工是否发生。
踩下制动踏板的样本单次注视时间最大值的值域明显大于未踩下制动踏板样本单次注视时间最大值的值域。因此,单次注视时间可以作为信息的加工是否发生的判断因子。
对驾驶人特征向量进行SVM的建模分析,得到SVM模型的真阳率为86.67%。画出的ROC图中,AUC=0.711 54,表明SVM模型的预测能力较好但不够完美,主要原因是未踩下制动踏板的样本量占比低且样本量较少,使得模型对负类实例的错分类十分敏感,模型预测的误检率大大提高。可以使正负样本的比例更加均匀或者提高样本量来解决这一问题。
猜你喜欢
中国心血管杂志(2022年2期)2022-11-25
中国心血管杂志(2022年4期)2022-11-25
世界最新医学信息文摘(2022年43期)2022-11-19
科学生活(2020年9期)2020-10-10
读写算·素质教育论坛(2017年16期)2017-08-04
教育界·下旬(2016年4期)2016-11-19
科学家(2015年2期)2015-04-09
读者(2014年18期)2014-05-14
飞天(2011年20期)2011-08-15
戏剧之家(2010年2期)2010-08-15
