
基于CNN和XGBoost的滚动轴承故障诊断方法
2021-07-08 11:04马怀祥冯旭威李东升齐澍椿
中国工程机械学报 2021年3期
马怀祥,冯旭威,李东升,齐澍椿
(1.石家庄铁道大学机械工程学院,河北石家庄050043;2.中铁十四局集团有限公司芜湖长江隧道建设指挥部,安徽芜湖241000)
随着大数据的发展,如何有效地处理数据,进行有效分析是当前重要的话题之一[1]。2012年,美国耗资2亿美元用于“大数据研究与发展计划”,将大数据纳入到国家战略标准。2015年,我国国务院颁布“促进大数据发展行动纲要”,明确提倡对大数据关键应用技术的研究和分析[2]。
滚动轴承是旋转机械中最基础、最常用的零部件之一,其工作状态事关整个机械设备的健康状况。统计表明:在使用滚动轴承的旋转机械中,大约有30%的机械故障是滚动轴承引起的,感应电机故障中的滚动轴承故障占电机故障的40%左右,齿轮箱各类故障中的轴承故障率仅次于齿轮,约占20%。因此,研究滚动轴承的故障诊断具有重要意义[3-4]。
随着世界迈入大数据时代,机械领域也不例外。而传统的方法不善于处理数据量较多的问题,因此,将善于处理大数据的深度学习,应用到机械的故障诊断中,为解决滚动轴承故障诊断问题开辟了一条新途径。
当前人工智能最热门的就是卷积神经网络(Convolutional Neural Networks,CNN)深度学习,受到人们关注的一个重要原因就是Alex等实现的深度卷积神经网络(Alex Net)在LSVRC-2010 ImageNet比赛中,取得了非常好的成绩。CNN利用了空间网络,擅长处理图像数据,在计算机视觉方面取得了重大的成就,并且在自然语言处理上也有应用。CNN有着强大的特征提取能力,并且滚动轴承的工作环境通常存在着大量的噪声,早期故障特征非常微弱[5],因此CNN适合于做滚动轴承的故障诊断。彭丹丹[6]利用CNN对滚动轴承的故障进行了诊断识别。王丽华等[7]、张安安等[8]利用CNN的图像特征提取能力对信号的时频图进行分类识别,基于CNN的故障诊断模型研究已见成效,但是存在着模型复杂、计算量庞大、分类能力有限等问题。
极端梯度提升(eXtreme Gradient Boosting,XGBoost)是一种提升树模型,属于Boosting算法的一种。XGBoost将许多树模型集成在一起,是一种提升树模型,它能够利用CPU的多线程进行并行运算,运算速度快且能够提升模型的准确度,常被用于各大机器学习竞赛中,能显著提升算法的准确率,被称为“机器学习大杀器”。
本文将CNN和XGBoost结合,使用德国帕德博恩大学滚动轴承数据进行实验,结果表明,故障分类准确率可达99.2%,优于仅使用CNN、SVM、XGBoost以及三层神经网络,具有一定的优越性。
1 CNN及XGboost原理
1.1 卷积神经网络
卷积神经网络(CNN)是一种前馈型神经网络,层与层之间采用局部连接方式,由一个或多个卷积层和顶端的全连接层组成,同时也包括关联权重和池化层等。
卷积层是卷积神经网络的核心,而卷积(Convolution)又为卷积层的核心。在卷积操作中,输入和卷积核均为张量(Tensor),张量是一个多维的数据存储形式,卷积运算即使用卷积核(Kernel)分别乘以输入张量中对应的元素,再输出代表每个输入信息的张量。卷积核又被称为权重过滤器,卷积层最显著的一个特点就是权重共享,也即一个卷积核以固定的步幅(Strides)遍历一次输入,由于权重共享使得CNN相较于其他深度学习结构使用更少的参数,避免了参数过多所导致的过拟合[15],从而使得CNN获得更好的性能。具体的卷积层运算为

式中:K l(j')i为第l层第i个卷积核的第j'个权值;x l(r j+j')为第l层第j+j'个局部域;W为卷积核的宽度。
池化(Pooling)又称下采样。理论上,数据输入到卷积层获得特征之后,可以直接利用这些特征训练分类器,但是这会产生非常大的计算量,同时又容易带来过拟合的问题,池化层进行的是降采样操作,目的是减少网络训练的参数和降低模型的过拟合程度,还相当于一个模糊滤波器,进行二次特征提取[9]。池化的方式通常有两种,最大值池化(Max Pooling)和均值池化(Mean Pooling)。最大值池化是输出感知域中的神经元的最大值,均值池化是输出感知域中神经元的均值,两者的计算式如下:

式中:al(i,t)为第l层第i帧第t个神经元的激活值;W为池化区域的宽度;p l(i,j)为池化区域的宽度。
卷积层、池化层的作用是将原始数据映射到样本空间中,全连接层用于将提取出的特征进行分类,映射到样本的标记空间中。将最后一个池化层的输出铺平(Flatten)为一维的特征向量,连接输入与输出。
1.2 极端梯度提升(XGBoost)
XGBoost由陈天奇和Carlos Guestrin于2011年提出,能够利用CPU多线程进行并行运算,提升模型的分类准确率。假设共有K颗树,F代表基本的树模型为
式中:右边第1项为损失函数,代表预测值和真实值的差距;第2项为正则化函数,用于防止过拟合,
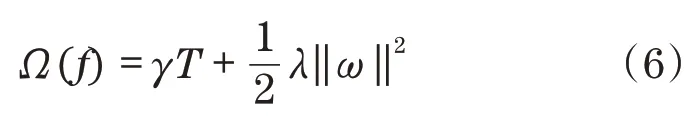
式中:T为每棵树的叶子数量;ω为叶子权重。
最终的目标函数为

式中:为了防止过拟合现象的产生,添加了一个γ,当且仅当信息增益大于γ时才允许叶子分裂[10]。
2 CNN特征提取模型的搭建
所建立的CNN滚动轴承故障诊断模型如图1所示。共搭建了两层网络,共包括两个卷积层和两个池化层,池化层为最大值池化;进行完最后一次池化操作后,为提高程序的运行速度,只设置了一个全连接层,并在最后连接SoftMax分类器进行分类;模型训练过程中需要根据预测值和实际值的损失进行优化,因此,损失函数的选择非常重要,使用交叉熵(Cross Entropy)作为损失函数,交叉熵用以计算目标与预测值之间的差值,同时,为了防止过拟合现象的产生在每层后都添加了Dropout。
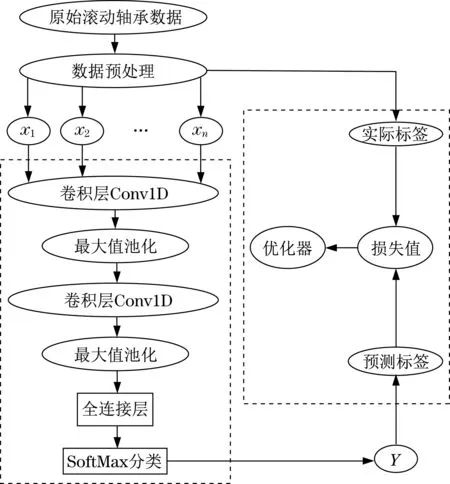
图1 CNN轴承故障诊断模型Fig.1 Convolution neural network bearing fault diagnosis model
所建立的表CNN故障诊断模型初始参数如表1所示。

表1 CNN模型初始参数Tab.1 Initial parameters of CNN
3 实验验证
CNN-XGBoost故障诊断流程如图2所示。使用原始数据对初始CNN模型进行循环调参,再保存调参完成的模型;将原始数据送入保存好的模型,提取最后一个全连接层的输出作为XGBoost分类模型的输入进行循环调参,完成调参之后进行交叉验证评估模型,最后进行数据集的故障分类。

图2 CNN-XGBoost模型流程图Fig.2 flow chart of CNN-XGBoost model
使用的数据为德国帕德博恩大学滚动轴承数据,使用轴承寿命加速试验台制造轴承损伤,实验装置如图3所示。数据集包括2 850个训练集、722个验证集和1 000个测试集,其中,测试集用于评估模型。

图3 轴承寿命加速试验台Fig.3 Bearing life acceleration test stand
在Anaconda3 5.1.0环境下的Spyder使用Python 3.6进行软件的编写,深度学习框架为Keras 2.2.4,以TensorFlow 1.12.0作为后端,程序运行的硬件以及软件环境如表2所示。

表2 程序运行环境Tab.2 Progr am envir onment
故障类型的划分如表3所示。

表3 故障类型划分Tab.3 Fault classification
3.1 CNN模型调参
批尺寸(Batch Size)是机器学习的一个重要参数,它首先决定的是下降方向。适当地增大批尺寸有助于提高数据的处理速度,并且下降的方向越准确,引起的训练震荡越小;但如果盲目增大,批尺寸增大到一定程度时,其确定下降的方向已基本不再变化,达到相同精度所需的时间更长,且会给计算机带来巨大的负担。为确定合适的批尺寸,控制其他变量不变,在100次迭代下,批尺寸设置为32、64、128、256、400、512、600、700、800、900、1 024运行结果,如图4所示。从图中可知,取64时获得最高的准确率.最终CNN模型在测试集上的准确率为87.8%。

图4 调整批尺寸运行结果Fig.4 Results of adjusting batch size
3.2 XGBoost模型调参及验证
为使XGBoost模型在未知数据集上有较好的泛化能力,以泛化误差作为指标,对模型的性能进行评估。泛化误差是用来衡量模型在未知数据上准确率的指标,一个集成模型f在未知数据集D上的泛化误差为

式中:E(f;D)为泛化误差;b为偏差(Bias);v为方差(Var);ε为噪声。
以往会取学习曲线最高的点,即偏差最小的点作为指标,但是往往模型极度不稳定,所以不仅要考虑偏差,还要考虑方差的影响,故使用泛化误差作为衡量指标对XGBoost模型的生成树的最大数目(nestimators)、学习率(learning rate)、树的最大深度(max depth)、一个子集的所有观察值的最小权重和(min child weight)进行调参。
首先对树的最大数目10~960,以50为步长进行调整,其他均使用模型的默认参数,运行结果如图5所示。由图5(a)可以看出,在100~200之间取得了较小的泛化误差,再继续增大并无明显变化,反而会增加程序的运行成本,将步长设置为10进一步分析,运行结果如图5(b)所示。在160时出现了大幅度的降低,在此之后无明显变化,故取160。

图5 调整n estimators运行结果Fig.5 Results of adjusting n estimators
将nestimators设置为160之后,同样的方法对学习率、树的最大深度、一个子集的所有观察值的最小权重和依次进行调整,运行结果如图6~图8所示。
从图6可知,学习率曲线在0.08~0.10之间出现了最小值,进一步缩小范围发现在0.09时,已经出现了较好的结果,学习率是指导如何通过损失函数的梯度调整网络权重的超参数,学习率越低,损失函数的变化也就越慢。较低的学习率可以避免错过局部极小值,所以选取0.09作为学习率。图7中在max depth为2时泛化误差较小。图8中可以看出,在min child weight在38处取得了最优解,继续增大,泛化误差呈现了增大的趋势,故取38。

图6 调整学习率运行结果Fig.6 Results of adjusting learning rate

图7 调整max depth运行结果Fig.7 Results of adjusting max depth
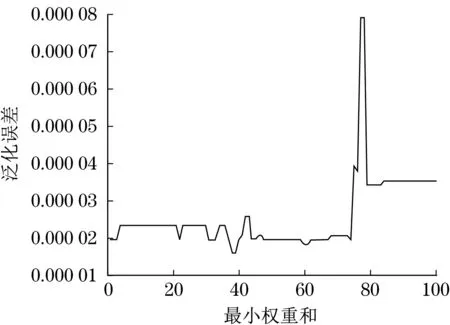
图8 调整min child weight运行结果Fig.8 Results of adjusting min child weight
通过上述步骤完成了XGBoost分类模型的参数调整,使用十折交叉验证得分对模型的性能进行评估,学习曲线如图9所示。交叉验证得分将接近满分,说明所建立的分类模型效果很好。
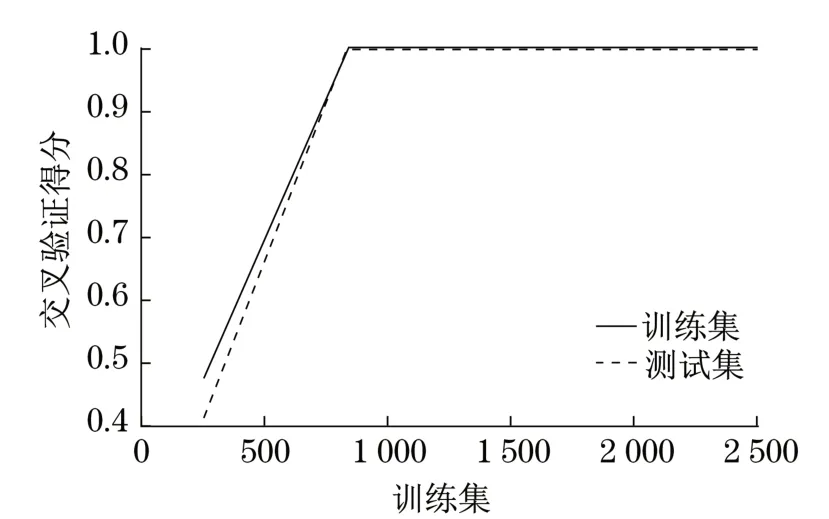
图9 学习曲线Fig.9 Learning curve
最后将测试集数据送入建立好的CNNXGBoost故障诊断模型中,在测试集上的准确率为99.2%,相较于CNN准确率有较为明显的提高,CNN-XGBoost、CNN、XGBoost、SVM、三层神经网络的准确率对比如表4所示。可以看出,通过模型结合,准确率有较为显著的提升,说明本文所建立模型具有一定的优越性。

表4 模型对比Tab.4 Comparison of models
4 结语
通过建立CNN-XGBoost模型实现了对滚动轴承的故障诊断,经过实验调参使模型达到理想状态。使用德国帕德博恩大学滚动轴承数据验证,在测试集上准确率达到99.2%,结果表明,经过模型结合明显提高了准确率,优于仅仅使用CNN、XGBoost、SVM以及三层神经网络,证明所建立的方法具有一定的优越性。
猜你喜欢
科学技术与工程(2023年3期)2023-03-15
软件导刊(2022年3期)2022-03-25
一重技术(2021年5期)2022-01-18
新一代信息技术(2021年22期)2021-12-29
科技创新与应用(2021年23期)2021-08-30
无线互联科技(2020年15期)2020-11-10
科技传播(2020年6期)2020-05-25
计算机技术与发展(2019年1期)2019-01-21
雷达科学与技术(2018年3期)2018-07-18
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28
