
小生境粒子群优化在多模态优化问题上的研究
2021-07-03 03:51:58尹杰
现代计算机 2021年12期
尹杰
(四川大学计算机学院,成都610065)
0 引言
基于种群或个体的解搜索算法通常是被设计为定位一个单一的全局解。代表性的例子包括进化算法(Evolutionary Algorithm)和 群 体 智 能(Swarm Intelli⁃gence)在内的多种算法。由于使用的是全局选择方案,这些搜索算法通常会收敛到一个单一解。然而,许多现实世界的问题本质上是“多模态”的,即存在多个令人满意的解。我们可能需要找到许多这样的解,甚至是所有可接受的解,这样决策者就可以选择一个特定问题域中最合适的解。过去已经开发了许多技术来定位多个最优解(optima)。这些技术一般被称为“小生境”方法。小生境方法可以以串行(sequential)或并行(parallel)的方式整合到标准的基于搜索的优化算法中,从而定位多个全局最优解。串行方式随着时间的推移逐步找到最优解,而并行方式聚焦于促进和维持一个群体中多个稳定子群体的形成。近期,将小生境技术应用于元启发式(meta-heuristic)算法,如粒子群优化(Particle Swarm Optimization)[1]、差分进化(Differen⁃tial Evolution)[2]和进化策略(Evolution Strategy)[3]等均取得了良好的效果。
然而,现有的大部分小生境方法在成功应用于现实世界的多模态问题之前,都有一些需要克服的困难,包括:难以预先指定一些小生境参数;难以在运行中保持发现的解;当维度和模态较高时,可扩展性差等。为了克服上述缺点,本文提出了一种新的小生境方法:基于粒子群优化,引入仿射传播(Affinity Propagation)[4]聚类形成多个小生境,再对小生境中粒子的pbest加权得到pbestw,然后使用牛顿插值(Newton Interpolation)预估比nbest的适应度更优的插值,接下来使用指数排序选择(Exponential Ranking Selection)选取pbestw更新的粒子,最后局部搜索(Local Search)寻找更接近最优解的点。
1 基础知识
粒子群优化是一种受到鸟群行为启发而发明的算法。在粒子群优化中,每个粒子拥有自己迄今为止访问过的最优位置记忆,并且能够与其他粒子共享信息。在每一次迭代中,粒子除了惯性地向原有方向移动外,同时被自身记忆中的最优位置pbest和整个粒子群的最优位置gbest所牵引。每个粒子的速度v和位置x根据以下公式进行更新:

标准粒子群优化的算法流程如下:
(1)设定群体规模N、惯性权重w、加速常数c1和c2,随机初始化每个粒子的速度v、位置x,并保证初始化位置在位置上界ub(upper bound)和位置下界lb(lower bound)之间。
(2)依照给定的函数评估每个粒子的适应度(fit⁃ness)。FEs是适应度函数评估(Function Evaluations,FEs),每当一个粒子的被评估了一次适应度,FEs=FEs+1。记每个粒子的当前位置为它的pbest,选择所有粒子中适应度最优的粒子位置为全局最优位置gbest。
(3)根据更新公式计算每个粒子新的速度和位置。
(4)对每个粒子,评估当前位置的适应度并与历史最优位置pbest的适应度相比较,如果当前位置更优,则更新pbest为当前位置。同时将所有粒子现在位置的适应度与全局最优位置gbest的适应度作比较,若有粒子的位置优于先前的gbest,则更新gbest为粒子现有位置中适应度最优的。
(5)如果达到实验设定的MaxFEs(Maximum FEs),算法结束,否则返回步骤(3)。
标准版本的粒子群优化算法只能找到单个解,为了定位多个解,还需要采取一些方法来提升算法的探索能力和分布式的收敛能力。
2 小生境粒子群优化
2.1 仿射传播聚类
与传统的聚类算法不同,仿射传播聚类不需要在运行算法之前确定或估计聚类数,它以数据点之间的相似度(例如欧氏距离作为测度)组成的相似度矩阵作为输入,在数据点之间交换实值消息,直到生成高质量的聚类中心(exemplar)和相应聚类。
假设x1到xn是一组数据点,s(i,j)>s(i,k)当且仅当xi和xj的相似度大于xi和xk的相似度,构建相似度矩阵(Similarity Matrix)s 描述任意两点之间的相似度。开始时,所有数据点都会被看作潜在的聚类中心。算法的执行可以看作两个消息传递(message-passing)步骤的交替,这两个步骤会更新两个初始化为零的矩阵:
吸引度(responsibility)矩阵r(i,k)衡量数据点k作为数据点i的聚类中心的适合程度。
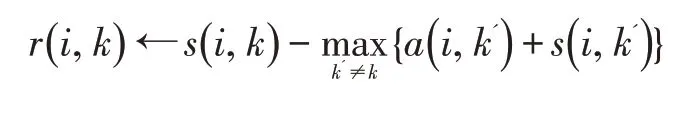
归属度(availability)矩阵a(i,k)量化数据点i选择数据点k作为其聚类中心的合适程度。
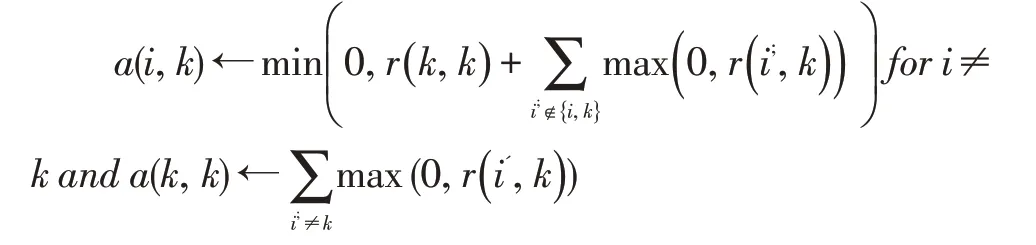
r(i,k)与a(i,k)越大,数据点k作为最终聚类中心的可能性就越大。
仿射传播通过消息传递迭代地更新吸引度矩阵和归属度矩阵,逐渐生成聚类中心,最后将数据点分配给最近的聚类中心形成对应的聚类。
2.2 均衡

2.3 pbestw
将每个粒子的pbest的适应度占小生境中总的pbest适应度的比例作为权值,加权得到pbestw。
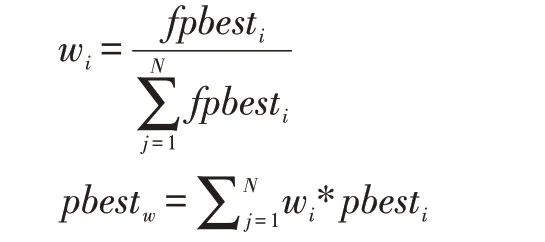
wi是小生境中第i个粒子的权值,fpbesti为第i个粒子pbest的适应度。
2.4 牛顿插值
在每个粒子数大于等于3 的小生境中选取适应度最优的Top 3 粒子,使用牛顿插值对其各维度分别构造插值多项式。如果插值多项式存在对应的最值,则将其作为这一维度的插值,否则用该小生境的nbest的相应维度值代替。
牛顿插值的计算过程如下:

2.5 更新
使用指数排序选择计算每个粒子被选中使用pbestw更新的概率,此时小生境中的粒子以适应度优劣降序排序。

Pi代表小生境中第i个粒子被选中的概率,n是小生境中的粒子数,参数c简单取0.5。
如果小生境中粒子数多,则其中选用pbestw更新的粒子也多,nmax为拥有最多粒子的小生境的粒子数。

2.6 局部搜索


3 实验结果
CEC2015 的20 个多模态基准函数[5]中高维度的F16-F20被用于测试小生境粒子群优化的性能表现。实验在64 位Win10 操作系统,16 Gb RAM 和4.80 GHz CPU 的PC 上的MATLAB 中运行。所有实验在给定MaxFEs 和精度ε=1.0-5均独立运行50 次,终止条件是找到所有全局最优解或达到MaxFEs。评价指标Peak Ratio(PR)反映多次运行后找到全局最优解的平均百分比。
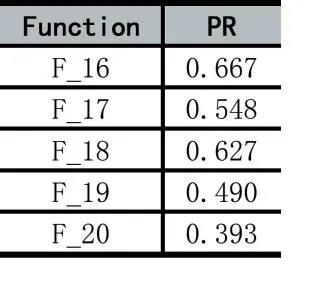
表1 在基准函数F16-F20 实验的Peak Ratio
4 结语
本文提出了一种新的小生境粒子群优化变体,首先通过仿射传播聚类自动地划分种群,降低了参数敏感度,同时迁移粒子使得每个小生境的规模均衡,再将pbestw和牛顿插值作为更好的学习对象,加速收敛,最后辅以局部搜索以提高解的精度。
即使小生境粒子群优化在平衡探索(exploration)和开发(exploitation)之间取得了不错的成绩,但在高维复杂的函数上,仍然难以定位所有的全局最优解。未来的研究中,希望能进一步提高性能。
猜你喜欢
计算机仿真(2022年8期)2022-09-28 09:53:02
——以贵阳花溪公园为例
山地农业生物学报(2022年3期)2022-05-13 09:58:54
西南石油大学学报(自然科学版)(2019年1期)2019-01-28 09:33:52
现代防御技术(2016年1期)2016-06-01 12:13:27
中国塑料(2016年11期)2016-04-16 05:26:02
电测与仪表(2016年10期)2016-04-12 00:26:24
电测与仪表(2016年14期)2016-04-11 12:32:48
计算机工程(2015年8期)2015-07-03 12:19:20
电测与仪表(2014年11期)2014-04-04 09:21:30
计算机工程(2014年6期)2014-02-28 01:26:31
