
基于改进MTCNN 的动态人脸识别系统设计
2021-07-03 03:52:30胡渲
现代计算机 2021年12期
胡渲
(四川大学视觉合成图形图像技术国防重点学科实验室计算机技术系,成都610041)
0 引言
人脸识别,就是计算机根据人脸的特征判断人物身份。传统人脸识别技术的核心是根据人脸图像的各个像素分布情况计算得到描述个体身份的特征描述子,使用这些特征描述子来进行身份匹配。随着深度学习的兴起,人脸识别领域得到了长足的发展,深度学习使得人脸识别相比传统方法的速度和准确率都有很大的提升。深度学习的主要优势是它们可以利用大量的数据进行训练,在训练的过程中逐渐适应不同的情况,学习到表征这些数据的最佳特征。虽然深度学习方法比传统方法更能够应对复杂的外部环境,但是依然做不到完全忽视各种变化的场景。非限制条件下的人脸识别存在人物姿态不固定、表情变化多、光照条件复杂和面部容易有遮挡物等情况,对人脸识别存在巨大挑战。
基于以上背景,为了将人脸识别应用到非限制条件下,本文提出基于特征融合的MTCNN[1]人脸检测算法,结合VGG-16[2]添加Inception[3]结构的人脸识别网络设计了一套动态人脸识别系统,并利用KCF[4]跟踪算法减轻客户端GPU 压力。
1 MTCNN与特征融合
1.1 MTCNN介绍
MTCNN 中的MT 代表多任务学习,在同一个任务中同时进行“识别人脸”、“边框回归”与“人脸关键点识别”。在工程实践中,MTCNN 是一种检测速度和准确度都很优秀的算法。MTCNN 利用三层级联架构,同时实现图像中人脸检测和人脸关键点定位。
如图1 所示,MTCNN 由三个网络组成:P-Net、RNet 和O-Net。对MTCNN 的三个阶段的简单解释如下:
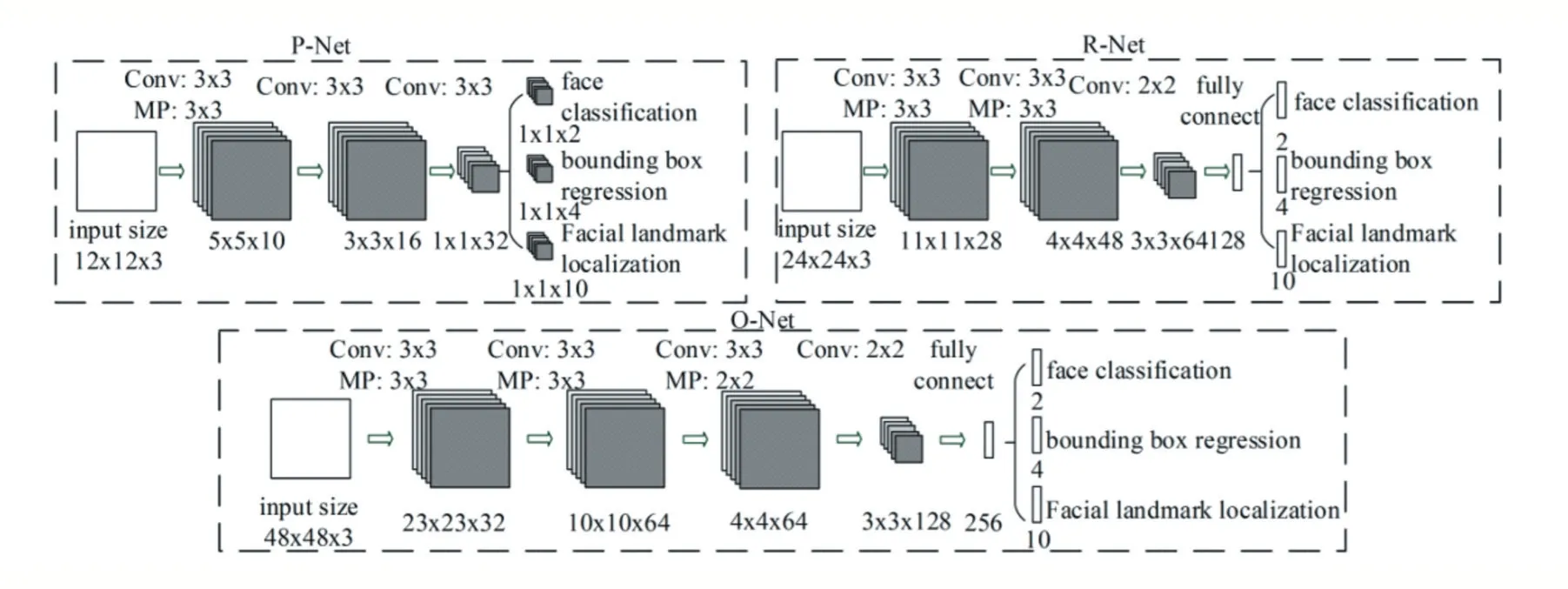
图1 MTCNN网络结构[1]
第一层网络P-Net:首先将图片进行多级缩放。使用12×12,步长为2 的滑动窗口,对每种缩放尺度的图片进行滑动检测。小图片能够检测到大人脸,大图片能够检测到小人脸。对所有检测到的人脸框进行非极大值抑制,得到人脸框,再将人脸框转换到原始尺寸,对短边进行填充,转化为24×24 的正方形。第二层网络R-Net:将上一级多个24×24 的人脸输入网络,进入卷积神经网络进行处理得到更多精确的人脸框,再进行非极大值抑制,最后进行尺寸变换到48×48 的正方形。第三层网络O-Net:将上一级多个48×48 的人脸输入网络,得到多个更精确的框、五个人脸位置标点和置信度。对人脸框进行非极大值抑制最后得到最终所需要的人脸框。
(1)人脸二分类任务使用交叉熵损失函数:
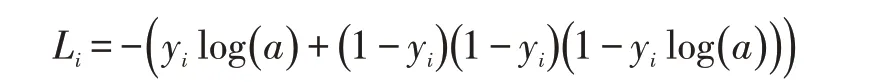
a 为神经网络实际输出值,yi为期望输出值,Li为分类损失。
(2)人脸坐标框回归任务使用均方误差函数:

1.2 特征融合
在传统MTCNN 中进行多尺度变换图像预处理使用的缩放因子为0.709。这样虽然可以将不同大小的人脸都缩放到接近12×12 大小,即模型尺度,但是依然不能够很完美地匹配,造成一定程度的漏检测,如图2所示,中间部分遮挡的人脸未检测成功。

图2 MTCNN只能够检测出部分人脸
MTCNN 检测速度已经很快,但模型使用的卷积神经网络对复杂情况下的处理会产生很多漏检和误检。而我们监控人脸识别环境中存在图像质量差、人脸大小不一的情况,MTCNN 人脸检测精度将会更差,所以我们需要在大体不影响检测速率的情况下提升人脸检测的精度,最大程度避免各种环境干扰。
(1)特征金字塔结构
既然MTCNN 可以在将图片输入神经网络之前将图片进行多尺度变换,以识别到不同尺度的人脸,同理也可以将不同层次的神经特征进行融合,即使用特征金字塔结构以此提高对不同大小的人脸的检测率。
从图3 的特征金字塔网络结构可以看出,它主要分为自顶向下结构和水平连接结构。自下而上的过程是卷积神经网络中正向传播的过程。底部图像是输入图像。在向顶层卷积的过程中,特征图的大小越来越小,卷积核的数量在增加,而卷积神经网络特征提取功能意义越来越抽象。MTCNN 使用的标准卷积神经网络将使用最后一个卷积层的高级特征进行面部检测。这样仅使用高级特征,而完全丢失了低级特征、边缘和其他信息的位置。在特征金字塔中,自顶向下是一个上采样过程,顶部最抽象的特征上采样之后和原神经网络上一级的特征进行融合,它们的尺寸必须一致,根据图3 的结构一层一层的向下融合,最后每一层都输出结果。
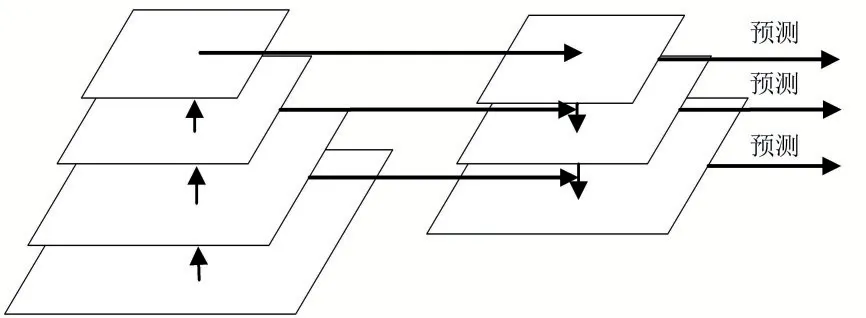
图3 特征金字塔结构
MTCNN 中的三个级联的卷积神经网络使用最后一层的输出作为特征,但是每一个卷积神经网络最后一层都是高分辨率特征,没有利用到当前神经网络前面几层的低分辨率特征,对信息的利用不足,就会导致MTCNN 对低分辨率的特征表现力不足,不容易检测到多尺度变换后中间尺度的人脸。在不同部分的神经网络内部进行特征融合,可以更好地利用图像信息,使得不同尺度大小的人脸都有更平等的机会被检测出来。而且特征融合是在卷积之后的特征之间进行融合,可以最大限度的减少因为融合带来的性能损耗。
(2)特征融合MTCNN 测试
特征融合MTCNN 采用WIDER FACE 人脸数据集进行训练,WIDER FACE 是香港中文大学收集的非限制条件下的人脸数据库,包含不同尺寸、光照、姿态等情况的人脸,在WIDER FACE 人脸数据上进行训练,对监控环境下的动态人脸识别系统具有重要意义。
使用FDDB 测试集进行人脸检测测试,使用检测准确率Acc进行评估,公式如下:

检测结果如图4。

图4 特征融合MTCNN与MTCNN性能测试结果
在特征融合之后MTCNN 检测准确率有了明显的提升,每一层网络特征融合MTCNN 都比原MTCNN 网络准确率高2%左右,可以更好地检测到不同大小的人脸,符合我们的应用需求。
2 动态人脸识别系统设计
动态人脸识别一般是使用监控摄像头进行识别,在监控的环境下,人脸识别技术面临非常多的不确定因素的挑战。在监控画面中虽然有时人物会不自觉的看向摄像头,但是大多数时候我们拍摄到的都是人物的侧脸。甚至有时候人物会佩戴面部遮挡饰品,例如帽子、眼睛、口罩等。在有的情况下为了拍摄到更大范围的人脸,人脸在画面中的比例容易变得很低,导致人脸分辨率很低。监控环境下阳光的变化也容易很剧烈,晴天、雨天、早上、傍晚都会影响人物的面部特征。基于以上对相关问题的研究(包括对人脸检测与识别的研究),以及基于本文系统需求分析与实际算法使用,我们设计了一套可以用于监控场景下的人脸识别系统。
2.1 功能架构
整个动态人脸识别系统基于C++语言开发,利用QT 形成一套完整的系统界面,包含登录、注册、检测、识别、删除、查询六大模块,如表1。

表1 功能架构
2.2 逻辑架构
本系统的逻辑架构主要分为客户端和服务端。
客户端完成人脸检测和KCF 人脸跟踪的功能,服务端提供人脸特征的提取与数据库对比特征的功能,最终向客户端返回识别到的人的信息。

图5 逻辑架构
2.3 模块详细设计
(1)登录
客户端使用HTTP(post)请求向服务端发送JSON包进行登录。服务端接收到用户名和密码之后进行验证,如果验证通过,服务端将随机生成32 位的ses⁃sion_id 发送给客户端。从此这个32 位的session_id 将成为客户端和服务端的通信标识,每次传输JSON 数据包都将验证session_id,如果不一致,将拒绝接收数据包。
(2)注册
在客户端上传人脸图片,填写姓名编号。客户端将进行人脸检测,如果没有识别到人脸,将提示重新上传含有人脸的图片。如果检测到有人脸,将人脸图片、人脸框、姓名、编号、指定库名称等信息一起通过HTTP(post)请求传输给服务端,服务端将注册人信息存入数据库,并返回相应状态信息。
(3)检测
对摄像头输出的帧序列进行人脸检测,将检测到的人脸位置交给KCF 进行跟踪,同时交给服务端进行人脸识别。客户端等待服务端返回的人脸识别信息,将识别到的人脸信息显示到界面上。为了防止KCF跟踪失效以及不能识别新出现的人脸,每10 帧图像客户端将再进行MTCNN 人脸检测,将所有检测到的人脸发送给服务端进行识别,同时更新现有的KCF 跟踪人脸框。
(4)识别
为了更快速、准确地进行人脸识别,我们设计了一种在VGG-16 基础上添加Inception 结构的人脸识别网络。适当的添加Inception 结构可以将网络设计的更宽更深,提高模型提取鲁棒特征的能力。服务端在接收到待识别人脸图片后,通过人脸识别网络提取768 个特征,将其与数据库中所有已注册的人脸特征进行对比,分数最高且超过设定阈值的人脸特征即识别到的人脸,将识别信息打包返还给客户端。
(5)删除
删除功能是删除注册的人脸,客户端中指定注册库名称,输入待删除注册人脸的姓名或者工号,将信息打包发送给服务端,服务端将在指定注册库中执行删除注册人脸操作,并返回是否删除成功。
(6)查询
查询功能不仅可以查询人脸是否注册,还可以查询识别记录。服务端在进行人脸识别的时候,会将识别到的信息存入本地,客户端填写查询时间段、个人信息、最低相似度等信息,发送到服务端,服务端将在数据库中筛选检索并返回结果。
3 程序运行界面效果
图6 为动态人脸识别系统运行界面,最上方为识别、注册、检测、查询四大功能。在识别界面可以选择M:N、1:N、1:1 三种工作模式。左边为识别记录,右边是实时识别效果,即使人物运动快速,也能够准确的跟踪。

图6 动态人脸识别系统运行界面
根据测试,在NVIDIA GTX 1050 Ti、注册库5 万人、同屏人数7 人的条件下,动态人脸识别能够达到30FPS。
4 结语
本文介绍了二维人脸识别技术的研究现状,针对MTCNN 人脸检测方法有部分人脸漏检的情况,提出了一种在不同网络结构内部进行特征融合的方法,有效提高了MTCNN 网络的检测准确率。在设计动态人脸识别系统的过程中,针对不同的用户需求设计了六大基本功能:登录、注册、检测、识别、删除、查询。在客户端的设计中本文利用了KCF 目标跟踪算法,有效地降低了客户端GPU 的运算压力,在实际运用过程中,可以有效地降低设备购置成本,降低能源消耗。最后展示了动态人脸识别系统的运行界面,达到了实时运算,且准确率高的目标。
猜你喜欢
作文中学版(2022年1期)2022-04-14 08:00:34
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
学生天地(2020年31期)2020-06-01 02:32:06
动漫星空(2018年9期)2018-10-26 01:17:14
东华大学学报(自然科学版)(2018年1期)2018-06-29 03:35:18
消费导刊(2018年8期)2018-05-25 13:19:48
网络安全和信息化(2017年9期)2017-11-07 06:30:48
计算机工程(2015年8期)2015-07-03 12:19:07
发明与创新(2015年33期)2015-02-27 10:40:09
奇闻怪事(2014年5期)2014-05-13 21:43:01
