
大数据背景的电子商务商品实体识别算法
2021-06-24 09:30:36王玉玲
微型电脑应用 2021年6期
王玉玲
(西安航空职业技术学院 航空管理工程学院, 陕西 西安 710089)
0 引言
近年来,随着网络和电子商务不断发展,电子商务逐渐步入大数据时代,电子商务大数据化为人们工作和生活提供便利,电子商务数据量增加为计算机研究学者带来极大挑战[1]。电子商务大数据是指针对不同需求者通过不同数据挖掘方法为客户提供需要信息,大数据背景的电子商务具有商品种类繁多,商品数据质量参差不齐以及异构性和多源性特点[2],不同电子商务平台对相同商品定义并不相同,导致电子商务大数据平台中商品应用和分析受到影响。
大数据背景的电子商务商品实体识别是电子商务数据不断发展而出现的重要研究课题[3],通过大数据背景的电子商务平台识别所需商品实体,为大数据分析与集成提供基础。研究大数据背景的电子商务商品实体识别算法,将电子商务商品实体识别算法应用于Hadoop云计算平台中,Hadoop云计算平台可有效应用于海量大数据处理中,该算法可有效识别大数据背景的电子商务商品实体。
1 大数据背景下的电子商务商品实体识别算法
1.1 Hadoop平台
Hadoop平台是可对电子商务商品实体大数据实施分布式处理的基础架构平台。Hadoop平台主要部分是Hadoop分布式文件系统,通过分布式文件系统存储Hadoop集群内全部节点文件[4]。Hadoop平台通过特定节点建立,主要包括可控制外部客户机访问与负责管理文件系统名称的姓名节点,可回应分布式文件系统客户机读写记录并存储将文件分成不同数量块的多个数据节点[5],Hadoop分布式文件系统位于Hadoop平台最底层。分布式文件系统最上层为Map-Reduce执行引擎,其中包括Task Tracker以及Job Tracker,Job Tracker数量为1,并且单独运行于主节点中;Task Tracker数量众多,运行于集群节点[6],Task Tracker中运行任务主要通过Job Tracker调度与协调。
Map-Reduce执行引擎是应用于大数据任务处理和分布式计算的软件架构,Map-Reduce执行引擎主要包括映射(MAP)与化简(REDUCE),通过键-值对
1.2 属性/值的规范化处理
电子商务平台存在大量等价的属性/值节点,但表达方法并不相同,大数据背景的电子商务商品实体识别前需要将等价的属性/值节点合并[8],便于电子商务商品实体识别。设大数据背景的电子商务商品中的倒排索引集合为R,依据R内的全部属性/值记录设置全局模式图用G=
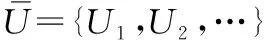
Simvalue(Ui,Uj)≥μ1
(1)
通过构建基于值文本语义相似度聚类获取等价值集合,利用Brown所提方法语义相似性分析Ui与Uj两值式,如式(2)。
(2)

等价值结合建立方法如下。

1.3 实体识别算法
通过上文属性/值的规范化处理获取可体现大数据背景的电子商务商品实体间相似关系的实体对集合[12]。将全部相似对用图表示,用不同实体以及实体间的相似关系表示图的顶点与边,利用图聚类思想的实体划分算法实现大数据背景的电子商务商品实体识别,该算法可依据电子商务商品实体节点收缩邻居信息关系[13],划分图获取具有统一实体的实体簇。图聚类思想的实体划分算法具体实现过程如下。
算法中,W(v)为图中顶点v的邻居节点集合,且满足v∈W(v)。
算法:
输入:依据相似实体对建立图H=(V,F)以及参数λ;
输出:识别电子商务商品实体D={H1,H2,…,HN},其中Hi={Fj|Fj表示相同类别实体}。
1. In order to independenceF=(a,b) do;
2. What If |W(a)∩W(b)|≥λ|W(a)∩W(b)| and then;
3. Commingle (a,b);
4. Renew=real;
5. Over if
6. What If renew=real then
7. Return 2;
8. Over if
9. Over for
10. Send out H;
以上算法中通过迭代的图聚类方式实现大数据背景的电子商务商品实体识别,由大数据背景的电子商务商品构成的图内的随机边用(a,b)表示,通过以上算法判断图的顶点a和b是否符合|W(a)∩W(b)|≥λ|W(a)∩W(b)|,参数λ依据实际情况设置,当符合以上条件时,收缩a以及b至相同顶点a′={a,b},重复迭代直至不存在边符合收缩条件为止。图中剩余顶点表示的顶点集即为采用该算法划分图结果[14],不同顶点集表示相同实体类实体。
大数据背景的电子商务商品实体识别过程中,获取结果|W(a)∩W(b)|与|W(a)∪W(b)|的代价为O(d),图中结点平均度用d表示,最大迭代次数为O(|F|),其中|F|表示图中存在边数,通过以上过程可知,该算法最差时间复杂度用O(d×[F])表示,以上聚类算法仅通过顶点所属联通分量集合获取[15],依据图的联通分量实现并行识别处理,利用各结点负载平衡获取最优识别速度。
2 实验结果与分析
为有效检测本文研究大数据背景的电子商务商品实体识别算法识别大数据背景的电子商务商品实体有效性,通过开源的虚拟化软件Oracle Virtualbox利用浪潮英信NF8560M2服务器设置50个主机节点布置分布式大数据硬件环境。选取CPU为锐龙 5 2600X 处理器、内存为8 GB的计算机作为实验主机,选取Ubuntu12操作系统的Hadoop 0.20.2平台作为实验节点平台。实验数据集来源于我国综合B2C电子商务平台天猫、京东、拼多多三个主流平台实时数据,通过Map-Reduce框架的开源平台实现实验。
统计2019年3月的10类30个二级分类共848 430件电子商务商品,来自各平台不同类别的电子商务商品数量如表1所示。

表1 不同类别实验数据集分类情况
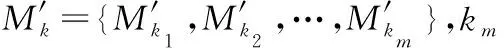
(3)
算法平均召回率如式(4)。
(4)
算法平均综合评价指标如式(5)。
(5)
三种算法识别大数据背景的电子商务商品实体结果如表2所示。

表2 不同算法电子商务商品实体识别结果
通过表2实验结果统计采用本文算法识别大数据背景的电子商务商品实体的平均识别精度,并将本文算法与HMM算法以及Winnow算法对比,对比结果如图1所示。
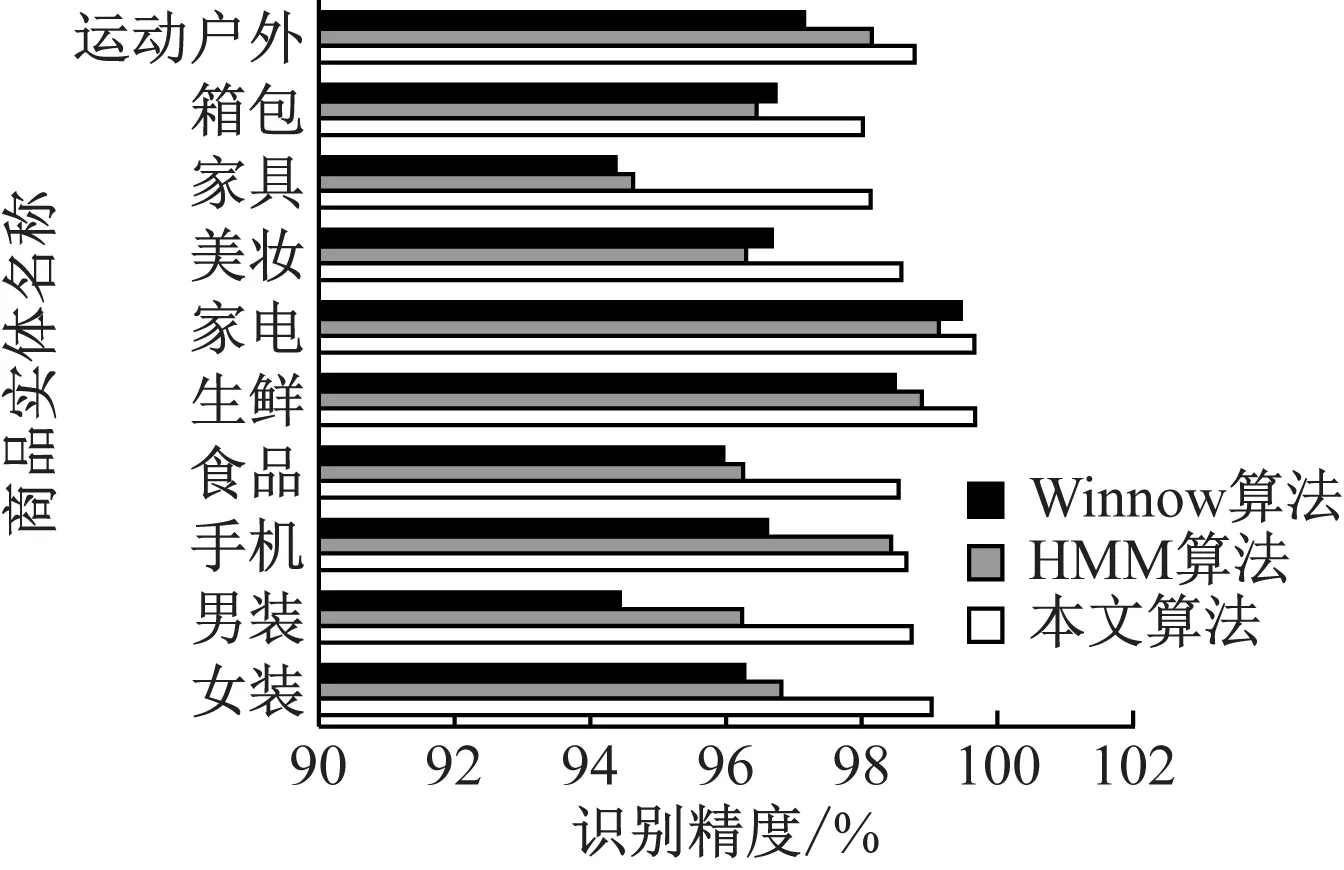
图1 不同算法平均识别精度对比
通过图1可以看出,采用本文方法识别大数据背景的电子商务商品实体平均识别精度均高于98%,对于不同类别电子商务商品实体均具有较高的平均识别精度,有效验证本文方法的识别准确性。
统计采用本文算法识别大数据背景的电子商务实体平均召回率,并将本文算法与HMM算法以及Winnow算法对比,结果如图2所示。
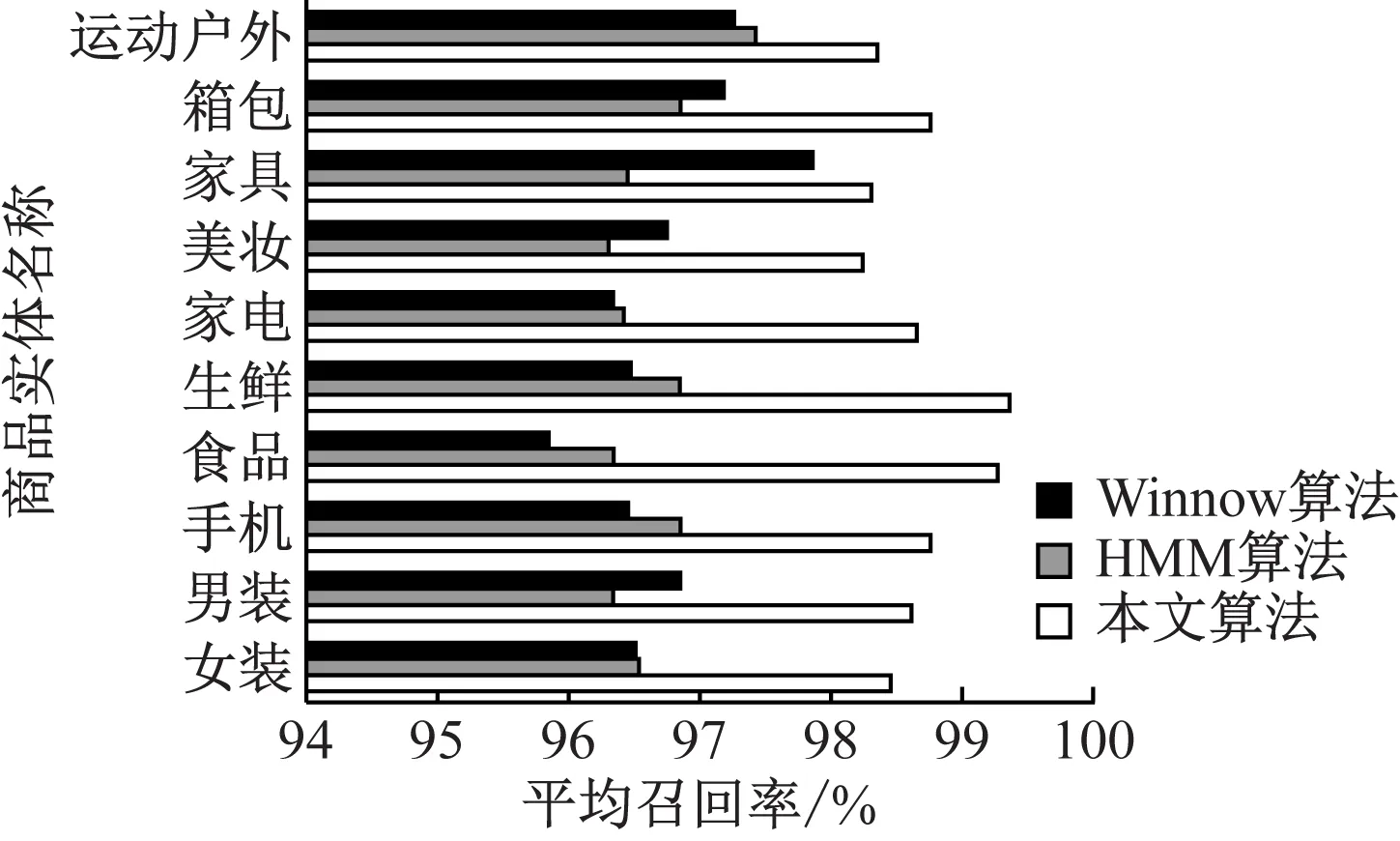
图2 不同算法平均召回率对比
通过图2可以看出,采用本文算法识别电子商务商品实体平均召回率明显高于另两种算法,本文算法的平均召回率均在98%以上;而HMM算法以及Winnow算法的平均召回率均低于98%,再次验证本文算法识别性能。
统计采用本文算法识别大数据背景的电子商务实体的平均综合评价指标,并将本文算法与HMM算法以及Winnow算法对比,结果如图3所示。

图3 不同算法平均综合评价指标对比
通过图3可以看出,采用本文算法识别大数据背景的电子商务商品实体平均综合评价指标明显高于另两种方法。
以上实验结果表明,采用本文算法识别大数据背景的电子商务实体准确率、召回率以及综合评价指标均优于另两种方法,具有较高的识别性能。
为进一步检测本文算法在大数据背景下识别性能,统计不同算法在不同数据量情况下识别效率,结果如表3所示。
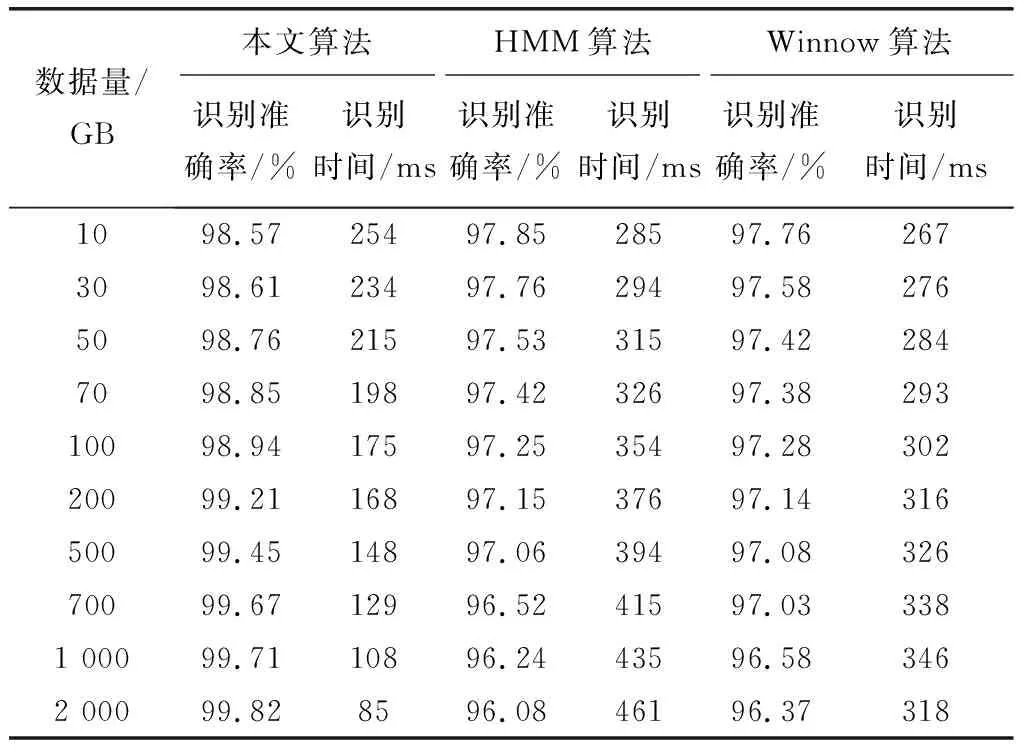
表3 不同算法识别效率对比
通过表3可以看出,数据量较小时,本文算法运行效率并不高;大数据量情况下,本文算法识别性能显著上升。主要原因是数据量较小时,本文算法无法发挥并行性能,运行效率较低;随着数据量提升,本文算法可充分发挥算法优良性能,利用不同进程执行并行任务,获取较好的识别效率。采用本文算法识别大数据背景的电子商务商品实体,不同数据量以及复杂的数据环境下均具有良好识别结果,验证本文算法具有较优的适用性。
3 总结
电子商务商品具有数据来源复杂、数据量庞大的异构多源特征,导致传统电子商务商品实体识别算法无法识别大数据下电子商务商品实体。研究大数据背景的电子商务商品实体识别算法,利用图聚类思想的实体划分算法实现大数据背景的电子商务商品实体识别。选取京东、天猫和拼多多3个电子商务平台数据作为实验对象,验证该算法具有较高的识别准确率以及识别性能,对大数据下的电子商务商品实体具有较优的识别性能。
猜你喜欢
中等数学(2021年9期)2021-11-22 08:06:58
北京大学学报(自然科学版)(2021年3期)2021-07-16 07:13:40
东北师大学报(自然科学版)(2021年1期)2021-03-27 01:22:14
电脑爱好者(2020年19期)2020-10-20 06:02:06
电子制作(2019年13期)2020-01-14 03:15:18
中国外汇(2019年18期)2019-11-25 01:41:54
山东科学(2018年6期)2018-12-20 11:08:58
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
