
无监督机器翻译综述*
2021-06-22 01:57杨晓霞
通信技术 2021年6期
杨晓霞,李 亚
(昆明理工大学,云南 昆明 650500)
0 引言
机器翻译(Machine Translation,MT)是通过计算机自动地将源语言(Source Language,SL)转变为具有相同语义的目标语言(Target Language,TL)的过程。随着社会对机器翻译需求的增多和科技的发展,机器翻译的发展日新月异。机器翻译的发展主要经历了基于规则的机器翻译(Rule-based Machine Translation)、统计机器翻译(Statistical Machine Translation,SMT)以及神经机器翻译(Neural Machine Translation,NMT)3 个 阶段[1]。2013 年,Kalchbrenner 和Blunsom 等人提出使用深度神经网络(Deep Neural Networks,DNNs)来解决机器翻译的问题[2-3],自此神经机器翻译第一次被提出。2016 年,Junczys 等人在30 多个语言对上做了NMT和SMT 的对比实验。NMT 在其中28 种语言对上翻译性能超过了SMT,充分证明了NMT 的性能优势[4]。
虽然NMT 翻译效果卓越,但是NMT 的翻译效果严重依赖于高质量大规模的平行语料。然而,获取高质量的平行语料往往需要付出高昂代价。目前,除了英语、法语等小部分高资源语言具有很多高质量的平行语料,世界上还有很多种语言在平行语料上都十分匮乏,甚至完全缺失。在机器翻译领域的研究中,这些语言一般称为“低资源语言”(Low-Resource Languages)[5]。
无监督机器翻译(Unsupervised Machine Translation,UNMT)是不使用平行语料,仅利用单语语料来解决低资源机器翻译的一种翻译方法。无监督机器翻译不借助平行语料,特别适合低资源机器翻译场景,具有极大的研究价值。
1 无监督机器翻译发展历程
无监督机器翻译的发展历程可以分为4 个阶段——词级无监督机器翻译,基于初始化、去噪自编码、回译的无监督机器翻译,利用统计机器翻译的无监督机器翻译,引入预训练的无监督机器翻译。
1.1 词级无监督机器翻译
无监督机器翻译的思想可以追溯到基于单词的解密方法[6-7],将机器翻译问题视为统计解密问题。具体地讲,源语言被视为密文,并将生成密文的过程分为原始序列的生成和其中单词的概率替换两个阶段。Dou 等人发现,使用词嵌入技术可以显著提升机器翻译的翻译性能[8]。2017 年,Conneau 等人运用对抗训练技术将单语词嵌入空间对齐,从而实现词级无监督机器翻译。然而,这些研究都属于词级的机器翻译[9]。
1.2 基于初始化、去噪自编码、回译的无监督机器翻译
2018 年,Artetxe 和Lample 等人几乎同时在句子级无监督机器翻译任务中取得了很好的实验结果,使得越来越多的研究者开始重视无监督机器翻译。他们的研究思路都是先用单语语料训练两个词向量空间,然后用无监督方法对齐这两个空间。他们的研究工作都基于无监督的跨语言词嵌入映射。该映射独立地训练两种语言的词嵌入并学习线性变换,以通过自学习或对抗训练将它们映射到共享空间[9-10]。由此产生的跨语言嵌入被用于初始化两种语言的共享编码器,都使用了回译和去噪自编码这两种技术来对齐词向量空间[11-12]。不同之处在于,Artetxe 等人采用了之前的自学习方法来初始化词嵌入空间[10],而Lample 等人则采用了Conneau 等人的对抗训练方法来初始化词嵌入空间[9]。此外,Artetxe 等人采用了源语言和目标语言共享编码器,不共享解码器的系统架构[11]。Lample 等人的编解码器都是共享的[12],且Artetxe 等人的工作需要用单语语料里的阿拉伯数字做种子词典,不属于完全的无监督,严格来讲是弱监督[11]。Lample 等人的工作则是完全无监督的[12]。
Yang 等人使用两个独立的编码器(每种语言对应一个),但共享一部分权重参数,并提出了两种不同的生成对抗网络(Generative Adversarial Networks,GANs),即局部GAN 和全局GAN,以增强跨语言翻译。它提升了英法、英德语对上的翻译效果,且在非同源的中英语对上也取得了不错 结果。
1.3 利用统计机器翻译的无监督机器翻译
基于短语的SMT 的模块化体系结构更适合于无监督机器翻译问题。Lample 等人和Artetxe 等人通过跨语言嵌入映射生成了初始短语表,将其与n-gram 语言模型结合在一起,并通过迭代回译进一步改进了系统[13-14]。Lample 等人总结了无监督方法在机器翻译上成功的关键因素[11-12],将其归结为无监督翻译模型的3 条设计原则——初始化,语言建模,回译。基于这3 条设计原则做了更简单有效的无监督神经机器翻译模型和无监督的基于短语的统计机器翻译模型。在英法、英德语对上的实验结果证明,统计机器翻译模型的效果更好。Lample 等人还做了先后使用神经机器翻译模型和统计机器翻译模型来训练翻译的实验,结果表明,先使用统计机器翻译模型训练再使用神经机器翻译模型训练的效果较好[13]。Artetxe 等人也训练了无监督的统计机器翻译模型,相对于无监督神经机器翻译模型有很大提升,但不如Lample 等人的无监督统计机器翻译模型,尤其是在英德语对上性能差距明显[14]。除了Lample 等人将无监督统计机器翻译和无监督神经机器翻译联合起来使用外,Marie 等人使用无监督统计机器翻译得到的伪平行数据来训练神经机器翻译模型,然后将生成的神经机器翻译模型再通过回译合成新的伪平行语料,用新的伪平行语料继续训练神经机器翻译模型,并反复重复该过程[15]。Ren 等人采用了类似的方法,但在每次迭代中使用SMT 作为后验正则化[16]。可见,这些融合了统计机器翻译方法的无监督机器翻译性能正在逐步提升。
1.4 引入预训练的无监督机器翻译
很多研究证明,预训练语言模型对自然语言处理任务性能提升十分有效[17-19]。2018 年,Devlin等人提出了基于Transformers 的双向编码表征模型(Bidirectional Encoder Representations from Transformers,BERT),是一个用于训练Transformer 的编码器的语言模型。该预训练语言模型在11 种NLP 任务上超过之前的最好结果[20]。但是,BERT 运用在单一语言上,不适合机器翻译任务。于是,Lample 等人于2019 年在BERT 的基础上进行了跨语言语言模型预训练的研究[21],提出了两种跨语言预训练模型:一种是只依赖单语数据的无监督跨语言预训练模型;另一种是利用平行数据的监督跨语言预训练模型。Lample 等人提出无监督跨语言预训练模型包括因果语言模型(Causal Language Modeling,CLM)和遮蔽语言模型(Masked Language Modeling,MLM)。Lample 等人提出的监督跨语言预训练模型是翻译语言 模 型(Translation Language Modeling,TLM)。这3 种跨语言语言模型统称为跨语言语言模型(Cross-lingual Language Models,XLMs)。Lample等人在训练翻译模型前,先训练无监督跨语言语言模型(CLM 或MLM),然后用去噪自编码和回译任务微调翻译模型。
1.5 小 结
现有的无监督翻译方法通常先预训练语言模型,然后在微调阶段利用去噪自编码、回译等训练翻译模型[5]。预训练语言模型可以为翻译模型提供一个良好的初始化。微调可以帮助源语言目标语言在共享嵌入空间上实现对齐。
2 预训练阶段的相关技术
2.1 跨语言词嵌入
最初的跨语言词嵌入方法依赖于平行语料 库[22-23]。但是,平行语料获取成本高,甚至很多低资源语言对之间根本不存在平行语料。通过使用跨语言词嵌入映射,可以大大减少对平行语料的依赖。该操作通过分别学习每种语言的单语言单词嵌入,并通过线性变换将它们映射到共享空间中。早期的工作需要双语词典来学习这种转换关系。后来,Artetxe 等通过自学习大大降低了对双语词典的规模要求,只使用25 个单词的种子词典或甚至是自动生成的数字列表,即在英-法、英-德、英-芬兰语对上实现了较好的词嵌入,使得跨语言词嵌入映射不再依赖于大量平行语料库[10]。Conneau 等通过对抗训练、Proscrustes、CSLS 等技术,实现了完全无监督的跨语言词嵌入映射[9],且其在英-德语对上的结果超过了借助种子词典的Artetxe 等人的工作[10]。Artetxe 等人提出了一个线性变换的多步骤框架,包括归一化、白化、正交映射、加权、去白化以及降维等步骤。他们发现,大部分关于词嵌入的工作属于这一框架的一部分。借助双语词典,它在英语-意大利语、英语-德语、英语-芬兰语、英语-西班牙语语对上都取得了很好的成绩[24]。Artetxe 等人对之前提出的跨语言词嵌入线性变化的多步骤框架做了改进[24-25],采用随机字典归纳、基于频率的词汇cutoff、CSLS 检索、双向字典归纳等技术,实现了完全无监督初始化,并取得了良好的实验结果[25]。
2.2 预训练语言模型
2.2.1 BERT
由Vaswani 等人于2017 年提出的Transformer是流行至今的神经机器翻译模型架构[26]。BERT 是一个用于训练Transformer 的编码器的语言模型。BERT 提出的预训练任务有屏蔽语言模型(MLM)和 预 测 下 一 个 句 子(Next Sentence Prediction,NSP)两种。在机器翻译任务中,仅涉及MLM 任务。MLM 随机屏蔽句子中15&的单词,把屏蔽后的句子做为模型输入。训练模型通过上下文,正确预测这些屏蔽掉的单词。与Vincent 等人提出的去噪自编码不同,MLM 任务只对屏蔽词进行预测,而去噪自编码是重构整个句子[27]。
2.2.2 XLM
XLM 是Lample 等人提出的跨语言语言模型。其中,一个无监督跨语言语言模型MLM 与Devlin 等人的MLM 任务极其相似,其中MLM 如图1 所示。它们之间的差异在于,Lample 等人的MLM 使用任意数量句子的文本流(每256 tokens 进行截断),而不是采用句子对[20]。Lample 等人的无监督机器翻译任务中,编解码器都采用MLM 初始化的效果最好。
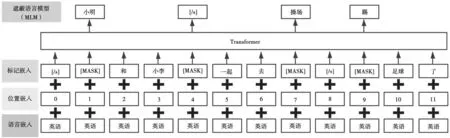
图1 MLM
2.2.3 RoBERTa
Liu等人对BERT进行了优化,提出了RoBERTa,全称为Robustly optimized BERT approach[28]。RoBERTa相较于BERT 最大的改进有3 点——动态遮蔽,取消下一句预测(NSP)任务,扩大一次训练所选取的样本数(Batch Size)。BERT 中的遮蔽是在预训练阶段完成的。同一个序列在每个训练轮数(epoch)中被遮蔽的词都是相同的。但在RoBERTa 中,遮蔽是在训练阶段完成的。每次向模型输入一个序列时,都会生成新的遮蔽方式。同一个序列在每个训练轮数中被遮蔽的词是不固定的。RoBERTa 在自然语言处理任务上的表现达到甚至超过了BERT。
3 微调阶段相关技术
3.1 去噪自编码
去噪自动编码器(Denoising Autoencoder,DAE)采用部分经过加噪的输入,旨在恢复出原始的输入。此技术通常用于序列到序列模型(如标准Transformer)重建原始文本。
具体过程如下:
(1)将句子x加噪,加噪后的句子用C(x)表示(x可以是源语言或者目标语言);
(2)编码器将C(x)映射到共享语义空间,用一系列的隐状态表示;
(3)解码器把共享语义空间中的一系列的隐状态重构回原句子,用表示,然后计算x和的交叉熵作为去噪自编码器的损失函数来训练模型,其中损失函数计算公式如下:
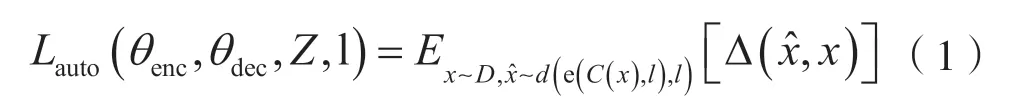
式中:θ为编码器或者解码器的参数;Z表示词嵌入;l表示某种语言,即源语言或者目标语言;Dl表示语言的数据集;C(x)为句子x加噪后的表示;∆表示计算交叉熵。
加噪的部分对于模型训练很关键,因为如果在编码时不加噪,模型可能会直接输出输入的句子,这样交叉熵损失值虽然很小,但是模型并没有学到语言的任何有用特征。常见的加噪方式有两种:一种是随机去掉句子中的某些单词(去掉的概率为p);另一种是打乱句子中单词的次序。
3.2 回 译
回译技术是利用单语语料的有效方式[29]。它在无监督机器翻译中的应用方法是通过从目标语言到源语言的反向模型pt→s生成伪平行句子来促进源语言到目标语言翻译模型ps→t的训练。尽管生成的源语言句子有噪声,但回译把无监督问题变成了一个半监督的学习任务。
在PBSMT 模型中,为了快速启动迭代过程,在目标端使用无监督短语表和语言模型来构造种子PBSMT 模型,然后利用该模型将源语言的单语语料库翻译成目标语言(回译步骤),再用这个伪平行语料库去训练pt→s翻译系统。
在NMT 模型中,用u*(y)表示由y∈T推断出的源语言句子,函数表达式为:

同样地,用v*(x)表示从x∈s推断出的目标语言句子,函数表达式为:

生成的[u*(y),y]和[x,v*(x)]可用于通过最小化以下损失函数来训练两个MT 模型:
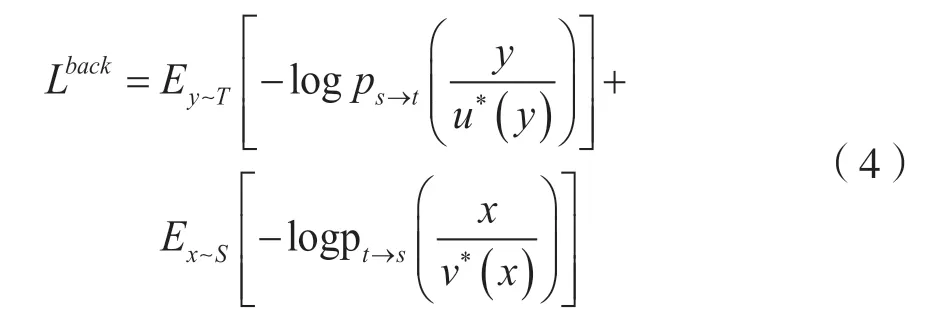
4 面临的挑战
尽管近几年来无监督机器翻译的发展迅速,但目前的无监督机器翻译还是面临很多关键性的挑战。
(1)目前的无监督机器翻译大多是在英法、英德语对上进行实验。其他同源语对上的无监督机器翻译研究较少,尤其是非同源语对上的无监督机器翻译研究更少。无监督机器翻译在相似的语言对(如英法、英德)上的表现较好,但在远距离语言对(如英-芬兰、英-阿塞拜疆)上表现较差[30-31]。
(2)目前的无监督机器翻译采用的源语言和目标语言的单语语料数据集都属于同一领域的数据集,存在一定的局限性。
5 结语
无监督机器翻译在远距离的非同源语言上的研究是一个难点,采用最新的跨语言词嵌入的技术、跨语言预训练语言模型技术以及通过统计机器翻译都可以对非同源语对进行较好的初始化。通过无监督方式融入双语词典、句法信息等弱监督机器翻译方法,也可以改进无监督机器翻译。
猜你喜欢
通信技术(2021年12期)2022-01-25
教育教学论坛(2019年18期)2019-06-17
河南教育·高教(2019年3期)2019-04-11
计算机应用与软件(2018年9期)2018-09-26
北方文学(2018年18期)2018-09-14
文理导航(2017年25期)2017-09-07
考试周刊(2015年36期)2015-09-10
科学中国人(2014年22期)2014-07-23
外语教学理论与实践(2014年2期)2014-06-21
疯狂英语·中学版(2013年7期)2013-08-01
