
采用完整局部二进制模式的伪装语音检测
2021-06-20 03:55徐剑简志华于佳祺金易帆游林汪云路
电信科学 2021年5期
徐剑, 简志华,于佳祺,金易帆,游林,汪云路
(1. 杭州电子科技大学通信工程学院,浙江 杭州 310018;2. 杭州电子科技大学网络空间安全学院,浙江 杭州 310018)
1 引言
随着人工智能技术的深入发展,说话人证实得到广泛研究与应用[1]。但说话人证实系统容易受到伪装语音攻击,其安全性非常值得关注。伪装语音检测是通过对说话人的声音进行分析,进而识别它是真实说话人的语音还是人为恶意伪装的语音[2]。伪装语音通常由设备回放、语音转换及语音合成等技术生成[3-5],通过蓄意的操作能够伪装成特定的说话人声音,从而达到欺骗说话人证实系统的目的。伪装语音识别系统可针对恶意的伪装语音实现伪装检测,提高说话人证实系统安全性能,具有广阔的应用前景。
伪装语音识别通常需要对目标语音信号进行特征提取,再与其对应的真实语音特征对比分析进而判定真/伪。传统的伪装语音识别系统提取的特征参数主要分为两种:一种是语音信号的幅度谱特征,通常有高阶梅尔倒谱系数、梅尔主频率和对数幅度谱等[6-8];另一种是语音信号的相位谱特征,通常有修正的群时延和相对相移等[9-11]。但这些特征在应对未知类型伪装语音的攻击时,检测效果往往不是很理想。
近些年,纹理分析逐渐成为计算机视觉和模式识别领域的研究热点,并在图像的分类处理中得到较大的发展。局部二进制模式(local binary pattern,LBP)是一种流行的纹理分析方法,最初在面部图像识别中有广泛的应用[12-13]。最近,Alegre等[14]提出了一种基于LBP的反伪装说话人证实方法,利用了LBP对级联排列的声学特征向量进行纹理分析,从而区别真/伪语音。这种基于LBP的伪装语音检测策略相较于传统的伪装语音检测策略所需要的先验知识(如伪装语音类型、生成的算法等信息)较少,对于未知伪装语音的检测效果较好,有利于实际的应用。不过,这种方法在面对由语音转换生成的伪装欺骗时检测效果不如传统的伪装语音检测方法,而且它的步骤较为复杂,需预先提取语音信号的声学特征向量并级联处理后才可获取纹理特征向量。
本文提出了一种利用完整局部二进制模式(completed local binary pattern,CLBP)[15]提取语音信号的纹理特征向量的方法,它可以有效地实现伪装语音检测。该方法的好处在于不用提前获取、级联语音信号的声学特征向量,而是直接对语音信号的语谱图进行分析获得语音信号的纹理特征向量。CLBP通过计算语音信号语谱图的完整局部二进制模式的符号差值(CLBP-sign,CLBP_S)、完整局部二进制模式的幅度差值(CLBP-magnitude,CLBP_M)以及完整局部二进制模式的中心灰度(CLBP-center,CLBP_C)而得,所获取的图像纹理特征更加全面,有助于提高伪装语音检测的准确率。
2 基于LBP的伪装语音检测
2.1 LBP算法
LBP算法是一种对图像局部纹理和空间结构的测量方法,它的中心思想是比较图像像素点间的局部差异,即图像某一像素点跟其周围像素点进行灰度值大小的对比生成一串二进制数,计算式为:

其中,gp表示相邻像素点的灰度值,gc表示中心像素点灰度值,P表示相邻像素点的个数,R是相邻像素点与中心像素点的半径距离,而s(x)表示符号函数,有:

若相邻像素点的灰度值pg大于其中心像素点灰度值gc,二进制位设置为1,否则设置为0。
2.2 LBP伪装语音检测方法
基于LBP的伪装语音检测方法是应用LBP对语音信号的声学特征向量进行纹理分析,从而获取反映语音声学特性的纹理特征向量并用以真/伪语音的检测,具体过程如图1所示。包含的步骤有:首先,对一段语音信号进行声学特征提取并形成特征矢量序列,即矩阵。之后用LBP对整个矩阵进行纹理分析,同时映射至LBPP,R,由此得到一幅纹理特征模式图;最后将纹理特征模式图中每一行的LBPP,R值用统计直方图表示并垂直级联得到纹理特征向量,用该纹理特征向量训练分类器,从而达到伪装语音检测的目的。
这种伪装检测策略有以下方面的缺陷:第一,在检测语音转换的欺骗攻击时,伪装检测效果有欠缺;第二,步骤较为复杂,需预先提取传统的语音信号的声学特征向量,而且检测的效果依赖该声学特征,面对部分通过改变语音声学特征生成的伪装欺骗时,伪装语音检测效果较差。应用LBP提取语音信号的纹理特征如图1所示。
3 基于CLBP的伪装语音检测
3.1 CLBP算法
CLBP算法[15]是一种改进的LBP算法,由CLBP_S、CLBP_M和CLBP_C 3部分组成,CLBP的组成框架如图2所示。一段语音的声学特征参数矢量序列构成原始图像,其纹理特征分为两部分:局部差异和中心灰度。通过局部符号和幅度差异转换分析图像的局部符号差异和局部幅度差异分别得到CLBP_S和CLBP_M,再计算中心灰度与整幅图像的灰度平均值的差值得CLBP_C,最后将三者组合构成一幅CLBP图并统计生成CLBP直方图。
3.1.1 CLBP_S特征
CLBP_S特征表示图像局部的符号差异,计算方法与LBP相同,首先读取图像的每个像素点灰度值,设置3×3的评估窗口进行二进制编码,使其相邻像素点与中心像素点进行灰度值比较,若相邻像素点的灰度值gp大于中心像素点灰度值gc,二进制位设置为1,否则设置为0,即:


图1 应用LBP提取语音信号的纹理特征
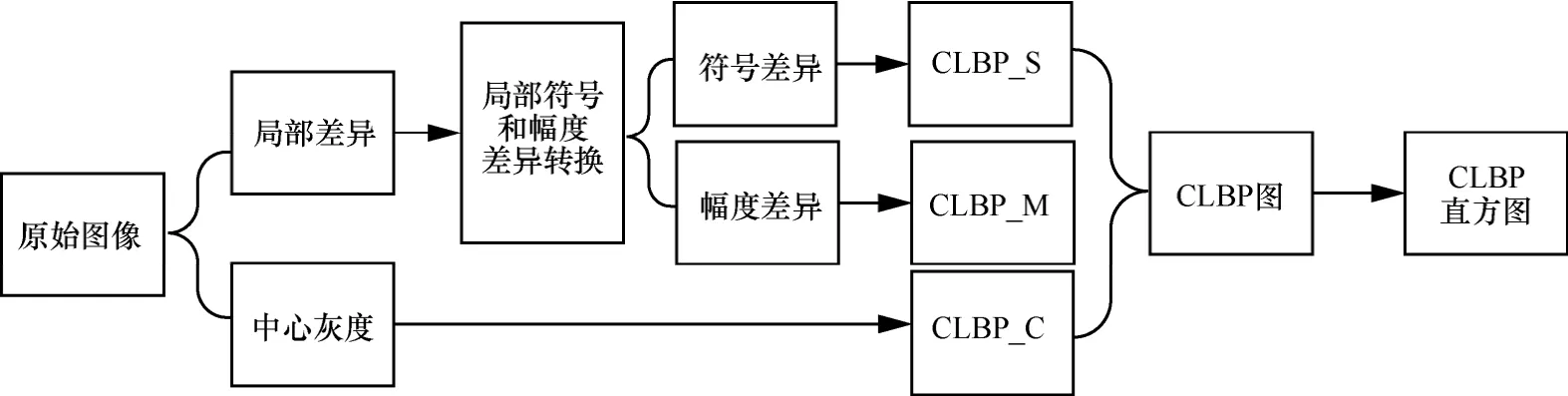
图2 CLBP的组成框架
该评估窗口可以生成8位二进制数,同时转换为十进制值,每一个十进制值代表一种纹理模式,从00000000(0)到11111111(255)一共有256种纹理模式。用该评估窗口分析整幅图像,可以得到一幅包含256种纹理模式的特征图像,通过直方图统计并生成统计直方图,将每一种纹理模式作为特征向量的一个维度,再将该纹理模式的数量作为特征向量在该维度下的值,所以一段语音可以得到1×256维的CLBP_S特征向量。
3.1.2 CLBP_M特征
CLBP_M特征表示的是图像局部的幅度差异。先对相邻像素点灰度值与中心像素点灰度值的差值取绝对值,记为相邻像素点与中心像素点的幅度差值mp;再取整幅图像所有幅度差值的平均,记为幅度差值的阈值c,即:
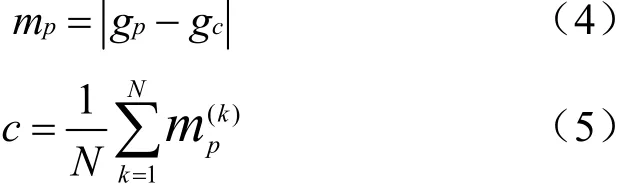
其中,gp为相邻像素点的灰度值,gc为中心像素点灰度值;k为幅度差值pm的序号,N为mp的总数。将每个相邻像素点与中心像素点的幅度差值的绝对值mp作为新的相邻像素点灰度值,幅度差值的阈值c作为新中心像素点灰度值。设置3×3的评估窗口进行二进制编码,使其新相邻像素点与新中心像素点进行灰度值比较,若新相邻像素点的灰度值大于其新中心像素点灰度值,二进制位设置为1,否则设置为0。该评估窗口同样可以生成8位二进制数并转换为十进制值,每一个十进制值代表一种纹理模式,共有256种纹理模式。这样一段语音的特征矢量序列构成的图就可以得到包含256种纹理模式的纹理特征,再将所有的纹理特征采用直方图统计就可以得到1×256维的完整局部二进制模式的幅度差值CLBP_M特征向量。CLBP_S特征和CLBP_M特征提取过程示意图如图3所示。
3.1.3 CLBP_C特征
CLBP_C特征表示整幅图像的中心灰度水平,通过计算整幅图像中所有中心像素点灰度值的平均cI,记为新的阈值,即:

其中,表示第k个中心像素点gc的灰度值,M为gc的总数。将每一局部区域的中心像素点的灰度值gc与cI比较,若中心像素点的灰度值大于cI记为1,否则记为0。这样通过二进制编码就可以得到CLBP_C特征的值。
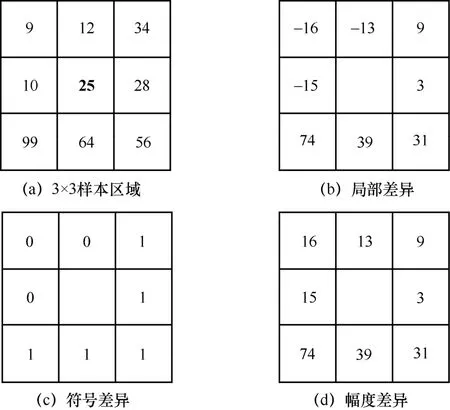
图3 CLBP_S特征和CLBP_M特征提取过程示意图
在分别计算CLBP_S特征、CLBP_M特征以及CLBP_C特征之后,将这些特征进行串联,得到用作伪装语音检测的CLBP特征向量。按照上述步骤,从所有真实语音和伪装语音的特征参数矢量构成的图中求得CLBP特征向量,用作支持向量机的训练。
3.2 训练支持向量机
本文采用支持向量机[16]作为真/伪语音的分类器。给训练集设置标签,记为其中,N是训练样本的总数,M是样本空间的维数,yi是样本的分类类别,yi=1表示伪装语音,yi=-1表示真实语音。选用径向基核函数(radial basic function,RBF),引入参数γ和错误惩罚因子C同时进行优化,训练最优支持向量确定一个最优超平面。使目标函数最大化,即:

受限条件为:

采用的RBF核函数为:

其中,iα为每个样本对应的拉格朗日乘子,错误惩罚因子C在确定RBF核函数后,控制错误分类样本的惩罚程度。解中只有一部分iα不为零,所对应的样本就是训练所得的支持向量。
分类器支持向量机示意图如图4所示,支持向量机共有3层,从下至上分别为SVM输入层、SVM隐藏层以及输出层。通过上述步骤,可得分类函数:

其中,b为分类阈值,可由支持向量求得。应用此分类决策函数可对待识别的语音信号的纹理特征分类,达到识别真/伪语音的目的。
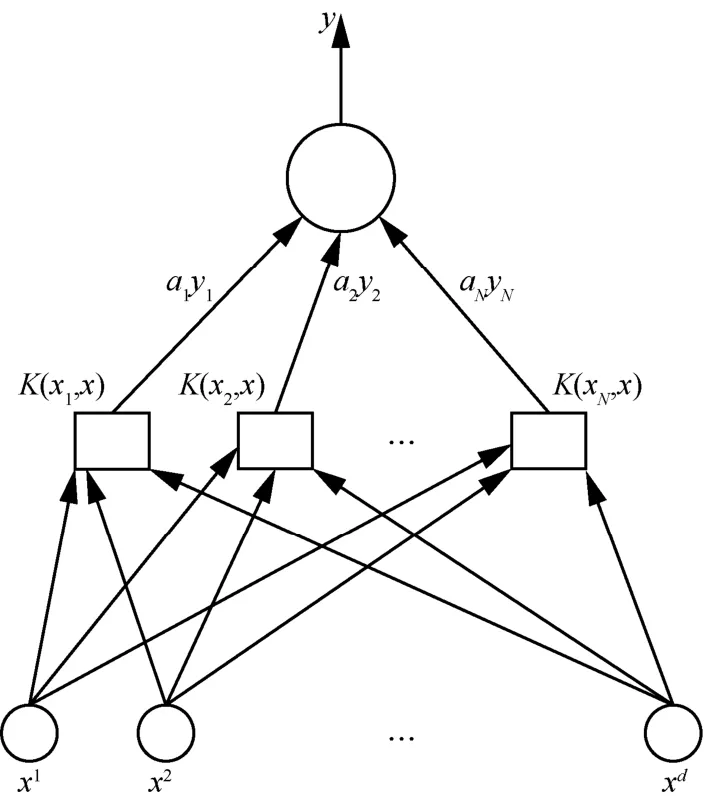
图4 分类器支持向量机示意图
3.3 CLBP伪装语音检测
本文提出的基于CLBP的伪装语音检测算法,通过CLBP分析语音信号的特征参数矢量序列图提取用以伪装检测的语音纹理特征向量。在提取语音信号的语谱图时,首先对说话人语音信号进行变量Q变换(VQT)得到清晰纹理的语谱图,表示为:

其中,wNk是长度为Nk的窗函数,Q是VQT中的变量因子,k表示VQT谱的频率序号,Nk值和k值有关。变量Q因子通过引入一个附加参数γ使Q因子向低频平滑减小,以提高低频处的分辨率,即:

将得到的语谱图转换为灰度图,并提取CLBP特征,将其用作SVM训练及分类的语音纹理特征向量。采用上述方法获取真实语音库及伪装语音库中所有语音信号的CLBP纹理特征向量用作训练集,将训练得到的SVM作为识别伪装语音的分类器。在识别时,同样需要提取待识别的说话人语音纹理特征向量,进而采用训练得到的SVM区分真/伪语音。
4 实验设计及结果分析
4.1 数据集
实验选用ASVspoof 2015语音库[17]评估本文所提算法的性能,该语音库包含了真实语音和伪装语音,真实语音是在无噪环境下由106位说话人录制,其中包含45名男性和61名女性,而伪装语音是采用多种不同算法修改真实语音而得。语音信号的采样频率为16 kHz,以16位比特量化,音频文件格式为RIFF/WAVE。将语音库中的数据集分为训练集、开发集和评估集3个子集,各个子集之间没有重复,具体情况见表1。

表1 训练集、开发集和评估集的说话人和语音数量
实验语音库中的伪装语音由语音转换和语音合成两种伪装方式生成见表2,共分为10个子集,分别表示为S1~S10,具体情况介绍可以参考文献[18]。

表2 语音库中各子集语音的数量及伪装方式
4.2 伪装语音检测系统性能评估方法
实验采用等错误率(equal error rate,EER)的指标来评价伪装语音检测系统的性能。在伪装语音检测系统中,为判别语音样本是否是真实的说话人声音,会为该语音样本计算打分。分数越高,是真实语音的概率越大;反之越小,更可能是伪装语音。检测系统预先设定阈值θ,若得分高于阈值θ判定为真实语音,反之判定为伪装语音。由此,可以得到两种常见的指标。
(1)错误拒绝率(false rejection rate,FRR)
真/伪语音分类问题中,若真实语音样本的得分小于阈值θ被系统误认为伪装语音,则为错误拒绝。错误拒绝数量在所有真实语音案例的比例即错误拒绝率PFR(θ),计算式为:

(2)错误接受率(false acceptance rate,FAR)
若伪装语音样本的得分大于阈值θ被系统误认为真实语音,则为错误接受。错误接受数量在所有伪装语音数量中的比例即错误接受率PFA(θ),计算式为:

其中,PFR(θ)会随着阈值θ的增大单调增大,而PFA(θ)会随着阈值θ的增大单调减小。当阈值θ=θEER时,这两种错误检测率相等,便是等错误概率EER,计算式为:

错误拒绝率和错误接受率相等时,EER大小可以用来评估伪装语音检测系统性能,EER越小,伪装语音检测效果越好,反之伪装语音检测效果越差。
4.3 伪装语音检测系统性能测试
实验采用LBP算法与本文所提CLBP算法进行性能对比,采用的特征参数如下。
(1)分别提取线性倒谱系数(linear frequency cepstral coefficient,LFCC)和梅尔倒谱系数(mel-frequency cepstral coefficient,MFCC)这两种声学特征参数。应用SPro5工具提取训练集中语音信号的38维LFCC特征(12LFCC、 12 ΔLFCC、12 ΔΔLFCC、ΔEnergy、 ΔΔEnergy)以及38 维MFCC特征(12 MFCC、 12 Δ MFCC、12 ΔΔMFCC、ΔEnergy、ΔΔEnergy),并用LBP和CLBP的纹理分析方法提取上述两种声学特征中各自的LBP特征向量和CLBP特征向量。
(2)利用VQT将训练集中每一个语音转换为语谱图,并用LBP和CLBP的纹理分析方法分别提取每一张语谱图的LBP特征向量和CLBP特征向量。
将上述各类参数在开发集和评估集中进行测试,比较各种情况下的伪装语音检测性能。在进行VQT时,为了选择合适的附加参数γ的值,实验在3个不同的分类器中进行了性能测试。这3个分类器包括GMM-UBM、具有因子分析(factor analysis,FA)信道补偿的GMM(GMM-FA)以及SVM-RBF系统,实验结果见表3。从表3的实验结果来看,在各类分类器,当γ=50时,检测系统的等错误率最小,性能最好。另外,不论附加参数γ取何值,本文采用的方案CLBP_S/M/C+SVM-RBF具有最佳的性能。
采用不同特征参数在开发集数据中进行性能对比,实验结果见表4。由表4可知,当提取特征的对象相同时,采用CLBP_S/M/C的系统检测效果普遍要好于采用LBP的系统;当提取特征的方法相同时,对语谱图提取纹理特征的检测性能优于LPCC和MFCC。因此,从实验结果来看,采用CLBP_S/M/C方法对语谱图提取纹理特征向量具有最好的检测效果。同时,实验也发现,不管采用哪个方法,在检测S2这种伪装语音类型时,EER都明显增大,因为S2是通过改变声学特征而生成的伪装语音,单纯依靠声学特征参数进行检测会比较困难。

表3 评估集中各个伪装语音检测系统的等错误率比较

表4 开发集不同特征参数情况下等错误率对比
从MFCC特征可以看出,通过它提取的纹理特征向量训练的系统检测S2欺骗的效果最差,这是由于S2为通过调整第一阶梅尔倒谱系数生成的语音转换欺骗。在检测S3、S4这两种语音合成伪装欺骗时,得到的等错误率普遍小于检测S1、S2和S5这3种由语音转换伪装欺骗求得的等错误概率,可见基于纹理特征的检测方法对语音合成的欺骗检测效果较好。在检测S1、S2和S5这3种语音转换伪装欺骗时,采用CLBP_S/M/C方法对语谱图提取纹理特征向量进行伪装检测相比于传统基于LBP的方法具有更小的EER值,可见本文所提出的基于CLBP对语谱图提取纹理特征向量的伪装语音检测方法比传统的基于LBP的方法有更好的性能,提升了对语音转换伪装欺骗的检测效果。
表5是系统在评估集的性能测试结果。从表5可知,由语谱图提取纹理特征向量在S1~S9这9种伪装欺骗中进行伪装检测的等错误率较小,检测效果较好。同时,不管哪种情况,在检测未知欺骗S10时,EER值均明显增大。这说明与其他攻击相比,使用MaryTTS的S10欺骗语音是最难检测的攻击类型,原因是S10欺骗语音不使用声码器,而是使用了单元选择合成算法选择语音段并级联生成欺骗语音,保留了较多的纹理特征。在检测S2和S6伪装欺骗时,由LPCC和MFCC这些声学参数提取纹理特征向量的性能表现较差,因为这依赖于语音信号提取的声学特征,导致在检测由语音信号的声学特征生成的语音转换欺骗时系统的伪装检测性能明显降低。在检测未知的语音转换欺骗攻击(S6~S9)时,传统基于LBP对声学特征提取纹理特征向量的伪装语音检测性能较差,而采用CLBP_S/M/C方法对语谱图提取纹理特征向量的检测性能较好。整体来看,基于CLBP_S/M/C纹理提取方法相比基于LBP的纹理提取方法在检测效果上有了较大的提升。
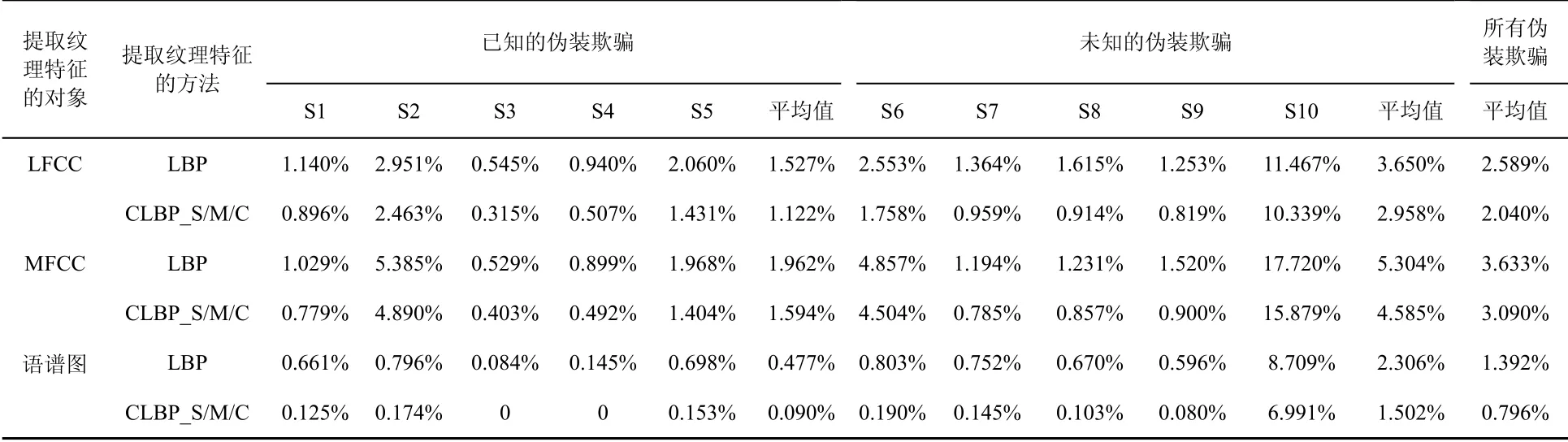
表5 评估集中几种伪装语音检测方法的EER对比
5 结束语
本文提出了一种基于CLBP的伪装语音检测算法,它有效地改善了传统的基于LBP的伪装语音检测方法的性能,特别是在面对由语音转换生成的伪装语音时效果更加明显。实验结果表明,当VQT的附加参数γ=50时,由CLBP特征参数和SVM-RBF分类器构建的伪装语音检测系统具有最佳的性能。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
现代电子技术(2021年1期)2021-01-17
家庭影院技术(2020年6期)2020-07-27
家庭影院技术(2019年1期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年10期)2018-11-02
上海大学学报(自然科学版)(2018年5期)2018-11-02
许昌学院学报(2018年4期)2018-05-02
电脑知识与技术(2018年35期)2018-02-27
