
基于最大信息系数的软件缺陷数目预测特征选择方法
2021-06-20 04:03刘国庆王兴起魏丹方景龙邵艳利
电信科学 2021年5期
刘国庆,王兴起,魏丹,方景龙,邵艳利
(杭州电子科技大学计算机学院,浙江 杭州 310018)
1 引言
随着信息时代的到来,计算机软件数量、种类快速增长,软件质量问题被越来越多的人关注。在软件开发的过程中,对软件需求的错误理解或人员的经验不足都可能引入缺陷。软件缺陷是软件质量的对立面,威胁着软件质量[1]。从软件开发的角度来看,处理软件缺陷是一项至关重要的任务。缺陷的存在不仅降低了软件的质量,而且还增加了软件的开发、测试和维护成本。因此,在软件开发的早期阶段预测出软件缺陷模块,可以指导软件测试人员关注缺陷模块,有助于提高软件质量。
目前在软件缺陷预测领域已经有大量研究工作,绝大多数致力于识别软件模块中有缺陷或无缺陷,含有不同缺陷数量的软件模块在软件测试中被同等对待。然而,对于有缺陷的模块,有些软件模块含有的缺陷较多,有些模块含有的缺陷数较少,与含有较少缺陷的模块相比,缺陷数量相对较多的软件模块则需要付出更多的资源去测试和修改。因此,仅根据有缺陷和无缺陷分配质量保证资源可能会导致资源利用效率低下,而预测软件模块的缺陷数目可以给软件测试提供更多的参考,更有利于分配测试资源。
目前,已有工作提出并且评估了基于回归模型的软件缺陷数目预测的方法,这类方法可以预测软件模块中有多少缺陷。但大部分都是基于模型的角度,利用从软件历史仓库挖掘的数据集,通过对比不同的回归模型,得到一个性能较好的回归模型。在构建缺陷数目预测模型时,数据集中的度量元含有冗余特征或无关特征,这些特征的存在会严重影响预测模型的性能。因此,设计有效的特征选择方法来移除这类特征具有重要意义。
特征相关性度量标准的选取对于冗余特征和无关特征的衡量非常重要。目前软件缺陷预测中常见的特征度量[2]大多仅能度量特征间的线性关系,难以刻画特征间的非线性关系。在软件缺陷数据中特征之间既存在线性相关关系,也存在非线性相关关系。对于软件度量特征来说,非线性的相关度度量方法比线性方法更为实际有效[3-4]。最大信息系数(maximum information coefficient,MIC)能够广泛地度量变量间的依赖关系,包括线性关系、非线性关系以及非函数依赖关系。
本文提出了一种基于MIC的两阶段特征选择方法(two-stage feature selection method based on maximum information coefficient,MIC-TSFS),该方法基于MIC度量特征与特征之间、特征与软件缺陷数目之间的关联性,衡量特征之间线性和非线性相关性,从而建立将特征冗余性分析和相关性性分析相分离的两阶段特征选择框架。为验证MIC-TSFS方法的有效性,在PROMISE真实软件项目上进行了实证性的研究,实验结果表明,MIC-TSFS能够移除冗余特征和无关特征,得到优化的特征子集,构建更有效的软件缺陷数目预测模型。
2 相关工作
软件缺陷数目预测从软件历史仓库中得到历史缺陷数据,然后构建缺陷数目预测模型,并用模型来预测出被测项目中软件模块的缺陷数目,从而为软件测试中如何分配测试资源提供指导意见。软件缺陷数目预测是智能化软件工程领域中的一个研究热点。
目前,国内外的研究者提出了多种有效的软件缺陷数目预测模型。Graves等[3]建立线性回归(linear regression,LR)模型并应用于大型的电信系统项目。Ostrand等[4]使用负二项回归(negative binomial regression,NBR)技术对故障数和故障密度预测进行了研究。Chen等[5]探究了一些典型的回归模型在软件缺陷个数预测上的可行性,实验结果表明,决策树回归取得了较好预测结果。Rathore等[6]提出了一种基于遗传编程的软件缺陷预测方法,实验结果表明,利用该方法对缺陷数目进行预测能够取得较好结果。Rathore等[7]探究了决策树回归模型在版本内缺陷数目预测和跨版本缺陷数目预测两种不同的研究场景下的预测能力,结果表明该方法在版本内进行预测时能够取得较好的结果。Rathore[8]比较了6种用于软件缺陷数目预测的方法(遗传编程(genetic programming)、多层感知(multi-layer perceptron)、线性回归(linear regression)、决策树回归(decision tree regression)、零膨胀泊松回归 (zero-inflated Poisson regression)和负二项回归 (negative binomial regression))对于软件缺陷数目的预测能力,实验结果表明决策树回归、遗传编程、多层感知和线性回归通常会有较好的预测性能,而零膨胀泊松回归和负二项回归表现通常不佳。Chen等[9]探究了有监督方法与无监督方法在缺陷数目预测方面的能力,将9种结合SMOTEND的有监督方法与基于LOC度量的无监督方法在版本内预测、跨版本预测、跨项目预测中分别进行了比较。
除上述基础模型外,也有些研究工作针对缺陷数目预测提出了一些集成方法。Rathore等[10]研究了集成学习方法在软件缺陷数预测方面的性能,先评价6种基础模型,然后从中选择3种性能较优的模型进行集成。他们[11]还提出了两种线性规则、两种非线性规则,用于集成基础模型的输出。并且做了实证研究,评估了在版本内预测以及版本间预测两种情景模式下,各个集成规则的预测性能。Yu等[12]探索了采样(SMOTEND和RUSND)和集成学习(AdaBoost.R2)方法对软件缺陷数目的预测能力,然后提出了SMOTENDBoost和RUSNDBoost这两种混合方法,实验结果表明融合过采样与集成学习可以有效提高对于缺陷数量的预测性能。
以上研究都是从模型的构建的角度出发,致力于找到一个性能较好的预测模型。然而,在构建软件缺陷数目预测模型时,在软件缺陷的大量度量元中不可避免地会产生冗余特征和无关特征。冗余特征大量或完全重复了其他单个或多个特征中含有的信息,而无关特征则不能对采用的数据挖掘算法提供任何帮助。若在构建模型之前去除冗余特征和无关特征,则能在一定程度上提升模型的性能。
特征选择通过挖掘特征间以及特征与缺陷数目间的内在联系,保留最有利于预测的有效特征,是除去冗余特征和无关特征的一种有效的方法。除去冗余特征和无关特征时需要衡量变量之间的相关性,信息增益[13]、ReliefF等是衡量相关性的常见方法。目前已有的特征选择算法可以分为两大类:基于子集搜索的特征选择算法和基于排序的特征选择算法。基于子集搜索的特征选择算法考虑特征之间的冗余性和特征与类别之间的相关性,但这类方法需要搜索的特征子集空间太大,计算开销过大;基于排序的特征选择算法根据特征与类别之间的相关性从高到低排序,排名越靠前,与类别属性的相关性越高,表明该特征区分不同类别的能力越强,然后从中选出排名靠前的特征来构建预测模型,其运行效率比较高,但选出的特征子集内通常含有冗余特征。
目前已有研究人员将特征选择方法应用到软件缺陷数目预测问题中。李叶飞等[14]提出了一种针对软件缺陷数目预测的特征选择方法——FSDNP,该方法采用欧氏距离度量特征间相关性,使用密度峰聚类对特征进行聚类,结合采用Pearson相关系数计算特征与缺陷数目之间的相关性时表现性能较好。Yu等[15]提出软件缺陷预测下的特征选择方法——FSCR,该方法首先基于特征间的Pearson相关系数进行谱聚类,然后根据ReliefF算法挑选与缺陷数目相关的特征。马子逸等[16]提出了一种面向软件缺陷个数预测的混合式特征选择方法——HFSNFP,该方法先使用ReliefF算法计算特征与缺陷个数之间的相关性,移除无关特征,随后根据特征与特征之间的Pearson相关系数对特征集进行谱聚类,将冗余度高的特征聚类到同一个簇中,最后基于包裹式特征选择的思想依次从每个簇中将最相关的特征加入特征子集中。这类针对缺陷数目预测而提出的特征选择方法在衡量特征与特征之间的相关性时通常采用Pearson相关系数或距离度量,仅表示了特征间的线性关系,忽略了特征之间的非线性相关性,不利于特征间的冗余性分析;此外,这类方法中采用的聚类方法需要事先设定参数,这些设定具有很大的主观性和经验性,设定不当会影响预测模型的性能。
基于以上分析,为了有效地识别并移除特征集中的冗余特征和无关特征,本文提出了一种基于最大信息系数的特征选择方法,该方法包括冗余性分析阶段和相关性分析阶段。在冗余性分析阶段,根据特征与特征间的关联度,采用自底向上的层次聚类的算法对特征进行聚类得到特征簇,降低所选特征子集的冗余率;在相关性分析阶段,根据特征与缺陷数目之间的关联度将每个特征簇中的特征进行排序,然后从每个特征簇中选择排名靠前的特征组成特征子集,过滤掉无关特征。
3 基于最大信息系数的特征选择方法
3.1 最大信息系数
最大信息系数可以用于衡量两变量的相关程度,其主要思想是:如果两个变量之间存在一定的关联,在这两个变量的散点图上进行某种网格划分之后,根据这两个变量在网格中的近似概率密度分布,计算这两个变量的互信息,该值经过正则化后可用于度量这两个变量之间的相关性。最大信息系数是互信息的推广,不仅可以度量变量间的线性关系,而且可以度量变量间的非线性关系和非函数依赖关系。
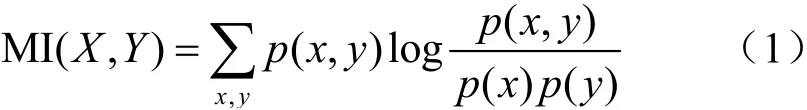
假设有限集合D由X和Y组成,定义划分G将变量X的值域分成x段,将Y的值域分成y段,得到一个x×y的网格,在得到的每一种网格划分内部计算互信息MI(X,Y),取不同划分的最大互信息作为划分G的互信息值,定义划分G下D的最大互信息公式为:
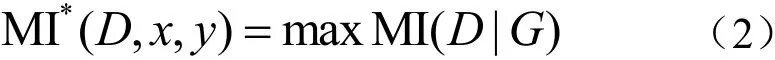
其中,D|G表示数据D使用G进行划分。
对于不同的划分都会得到一个MI值,将所有MI值组成特征矩阵,并对该特征矩阵进行规范化并定义为M(D)x,y,其计算式如下:

M(D)x,y为D在不同网格划分下的规范化后的特征矩阵。最大信息系数MIC的计算式如下:

其中,B(n)为网络划分x×y的上限值, 一般地,,参考文献[17]中给出B(n)=n0.6时效果较好。
MIC通过对连续型变量实施不等间隔的离散化寻优来挖掘非线性关联,并进一步通过标准化使得MIC(X,Y)∈[0,1]。如果X、Y相互独立,MIC(X,Y)=0,MIC值越大,两个特征越相关;MIC具有对称性,即MIC(X,Y)=MIC(Y,X);当Y=f(X)时,MIC(X,Y)=1,即当两个变量之间存在函数关系时,这两个变量之间的MIC值为1;若对变量X做任何单调函数g(X)变换,MIC不变,即MIC(X,Y)=MIC(g(X),Y)。
在软件缺陷预测领域中,为了充分描述软件特性,度量元特征集中存在冗余特征和无关特征。一些特征由同一组程序基本属性计算得到,这些特征之间有很大概率存在冗余。缺陷数据特征之间不仅存在线性关系(如变量个数与代码行数),也存在非线性关系(如类个数与类继承树深度)。一般的相关系数(如Pearson相关系数)因仅表示特征间的线性关系,不能充分表征特征间的相关性;而MIC具有较好的广泛性和均匀性,能够检测出变量间的线性和非线性关系,进而有效表达特征之间的相关性。本文把MIC作为特征与特征间相关性度量判据,从而通过移除冗余特征初步筛选特征集。
无关特征是与预测目标不相关的特征,特征子集的优劣可以通过特征与缺陷数目的相关性来度量。一般认为,好的特征子集中的特征与缺陷数目相关度较高。在传统的特征选择方法中,若特征与缺陷数目间存在非线性函数依赖关系,很有可能被排除在模型外;而MIC受噪声影响较小,可以敏感地检测出变量之间的各种函数以及非函数关系。另外,一般的相关系数对变量变换很敏感,然而在构建预测模型时变换并不明确,相关系数容易受到影响;而无论做何种单调变换,变量间的MIC值不变。因此,MIC稳健性更好,能够有效地度量特征与缺陷数目之间的相依关系。
基于上述分析,用MIC来选择特征适用于有复杂的软件缺陷的数据。因此,本文采用MIC衡量特征与特征间的相关性、特征与缺陷数目间的相关性,以此来移除冗余特征、初步筛选特征集,随后剔除一些无关特征,进而提高模型的预测性能。
3.2 特征关联性度量
给定一个n条样本的数据集F{f1,f2,f3,…,fN,d},其中fi(i=1,2,3,…,N)为特征集中第i个特征,N为特征总数,d为软件缺陷数目。对任意特征fi和fj,它们之间的相关度定义为FFfifj:

在软件预测数据集中,特征间的冗余性越大,则它们相关度值越大。FFfifj值越大,说明fi和fj之间的可替代性越强,即冗余性越强,聚类时趋向于聚在同一个类簇中。FFfifj值越小,说明fi和fj之间越相互独立,聚类时趋向与聚在不同的簇类中。
特征fi与软件缺陷数目d之间的相关度定义为FDi:

FDi值越大表明特征fi与软件缺陷数目d间的相关性越强,则fi为强相关特征,越倾向被保留;FDi值越小,表明特征fi与软件缺陷数目d的相关性越弱,则fi为弱相关特征,越倾向被删除。
3.3 MIC-TSFS方法
MIC-TSFS是一种将特征冗余性分析和相关性分析分离的两个阶段特征选择方法,其总体框架如图1所示。

图1 MIC-TSFS框架
第一阶段是冗余性分析阶段,根据特征与特征之间的相关度,采用层次聚类将原始数据集中的特征进行聚类,使得相关性较高的特征被划分到同一簇中,而相关性较低的特征被划分到不同簇中,这样同一个簇里的特征冗余性较高,不同簇中的特征冗余性较低。将这一阶段处理得到的特征簇作为第二阶段的输入。第二阶段是相关性分析阶段,在每个特征簇中计算特征与软件缺陷数目的相关度,根据该值对特征簇内的特征进行排序,在每个簇中选取排名靠前的特征组成新的特征子集。
3.3.1 冗余性分析阶段
为了降低特征间的冗余性,根据特征与特征之间的相关度,采用“自底向上”的凝聚层次聚类将数据集中的特征集合进行聚类,将特征分为若干个特征簇,同一簇中的特征相关度高,不同簇的特征相关度低。相对于最常用的密度峰聚类和谱聚类算法,层次聚类算法具有对聚类参数依赖小、适用于任意形状数据集聚类的优势。因此,MIC-TSFS在冗余性分析阶段选取了更适用于构建鲁棒特征选择算法的凝聚层次聚类算法。凝聚层次聚类算法过程是:初始时将每个样本看作一个类簇,然后依据某种准则合并这些初始的类簇,直到达到某种条件或者达到设定的分类数目,具体如算法1所示。
算法1凝聚层次聚类算法
将样本集中的所有的样本点都当作一个独立的类簇

达到聚类的数目或者达到设定的条件在算法1中,有多种方法可以计算簇间相似度,包括最小相似度、最大相似度和均值相似度,由于最小和最大相似度量代表了簇间相似度量的两个极端,它们趋向对噪声数据过分敏感,因此,MIC-TSFS采用均值来度量簇间相似度。给定两个特征簇Ci和Cj,簇Ci中包含p个特征,表示为簇Cj中包含q个特征,采用如下计算式计算它们之间的相关度:

若不提前中止簇合并,算法1会将所有的特征合并到同一个簇中。在算法1中,可设置达到聚类的数目或者达到设定的条件,使合并的过程提前停止。为了避免参数依赖问题,MIC-TSFS通过自适应调参方式设置合并中止条件:
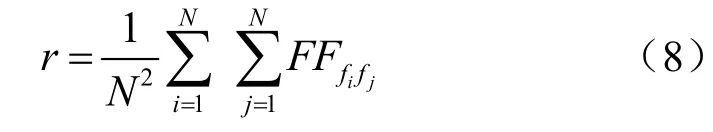
其中,N为特征的个数。当迭代过程中拟合并的两个簇之间的相似度小于r时,簇与簇之间的相似度较小,不再进行簇间的合并,从而结束迭代过程。
3.3.2 相关性分析阶段
在相关性分析阶段,为了过滤掉与软件缺陷数目无关的特征,选择对软件缺陷数目预测较为有用的特征。依据特征和软件缺陷数目之间的相关度,对每个特征簇中的特征进行排序,然后依据簇的大小从每个特征簇中挑选排名靠前的特征。具体步骤如下:
(1)对于每个特征簇,逐个计算簇内特征fi与软件缺陷数目d之间的相关度FiD;
(2)从每个特征簇中选取前M个特征。对于M的取值,参考文献[18]认为将软件缺陷数据集中特征数目减少为较为合适。考虑到簇中特征数目可能存在为1的情况,此时,会导致此特征将无法被有效处理,因此,MIC-TSFS设置M的取值为,其中p为每个簇的特征个数。
3.4 算法描述
MIC-TSFS特征选择方法的实现过程如算法2所示。
算法2MIC-TSFS算法
输入F{f1,f2,f3,…,fN,d}:原始数据集
输出Fsub{fi1,fi2,fi3,…,fim}:最终选择出来的特征子集
冗余性分析阶段
(1)初始化特征簇,对于含有N个特征的特征集{f1,f2,f3,…,fN},每个特征作为一个簇,共有N个簇。
(2)根据式(8)计算阈值r,作为聚类结束的判断条件。
(3)根据式(7)计算簇与簇之间的相似度,选取簇间相关度最大两个簇Ci和Cj。
合并这两个簇;
根据式(7)重新计算簇与簇之间的相似度,选择相关度最大两个簇。
相关性分析阶段
(7)foriin 1:N′ do。
(9)从中选取前M个特征并入Fsub
(10)end for
(11)returnFsub
步骤(1)~步骤(5)为使用特征间相关度与凝聚层次聚类算法对冗余特征的处理过程,经过聚类之后,将冗余特征分到同一个特征簇中,即每个特征簇中包含大量的冗余特征,将在第二阶段进行删除。步骤(6)~步骤(8),在每个特征簇中计算特征与软件缺陷数目间的相关度,然后按照此相关度的值对特征进行降序排序。步骤(9)选取每个特征簇中排名靠前的特征组成特征子集。经过MIC-TSFS处理之后,原始数据集中的冗余特征和不相关特征将被过滤,从而得到高质量特征子集,该特征子集可以作为回归模型的输入构建软件缺陷数目预测模型。
4 实证研究
4.1 评测对象
从软件缺陷常用数据PROMISE项目集[10]中选取4个项目共14个常用公开数据集进行实证研究,这4个项目均是Apache的实际项目。其中Ant是Apache中一个由Java语言进行编写的子项目;Camel是Apache的一个开源项目,提供基于规则的路由引擎;Xerces是一项用于XML文档解析的开源项目;ivy是Ant的子项目,主要用来解决Ant的jar包的版本管理。对各个版本的项目源程序按照参考文献[19]的度量方式进行度量,从而得到项目中每个模块的特征。每个项目都含有很多类级别的特征,例如特征dit表示一个类的继承数的深度;特征noc表示一个类的直接子类的个数;特征loc表示类的二进制码的行数等。这些特征都是基于代码复杂度和面向对象特性进行设计的。数据集特征见表1,Release表示软件项目不同的发行版本,#Instance表示实例的数量,#Defects表示实例中缺陷的总数,%Defects表示有缺陷的实例占所有实例的百分比,Max表示所有实例中最大的缺陷个数。这些项目在之前的研究工作中被广泛使用,并可从PROMISE中免费获取。

表1 数据集特征
4.2 评测指标
为了评估MIC-TSFS在软件缺陷数目预测中的性能,使用平均绝对误差(average absolute error,AAE)、平均相对误差(average relative error,ARE)、G-mean评价指标。
AAE是一组预测数据中所有误差的平均值,它表明了预测结果和真实结果之间的差距。其定义如下:

其中,ARE表示当整体目标项目被评估时相对误差的大小,其定义如下:

其中,表示测试集中的第i个样本的预测缺陷数目,iY表示测试集中的第i个样本真实含有的缺陷数目,n表示测试集中的样本数目。
为了进一步比较各种方法之间的性能,本文使用“Win/Draw/Loss”分析:“Win”表示“方法1”好于“方法2”的次数;“Draw”表示“方法 1”相似与“方法2”的次数;“Loss”表示“方法1”差于“方法2”的次数。
在软件缺陷数目预测中,平均绝对误差与平均相对误差反映了预测值偏离真实值的程度。为了衡量预测的准确性,引入G-mean作为评价指标,其定义如下:
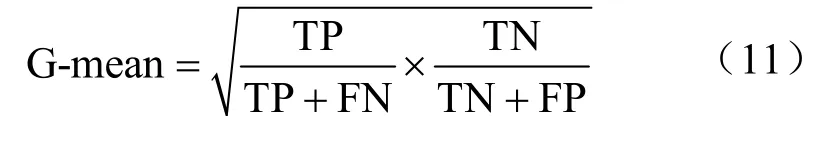
TP/(TP+FN)描述模型能正确搜索缺陷数目大于0的样本的能力;TN/(TN+FP)描述模型能正确搜索缺陷数目等于0的样本的能力;G-mean是这两种能力的综合评价指标,其值越大,表示模型预测性能越好。其中,TP是指被正确预测的有缺陷的样本数,FP是指被错误预测为有缺陷的无缺陷的样本数,FN是指被错误预测为无缺陷的有缺陷的样本数,TN是指被正确预测的无缺陷的样本数。本文预测软件缺陷数目,即缺陷数目大于0的实例被认为有缺陷,缺陷数目等于0即无缺陷。
4.3 回归模型
本文采用了3种回归模型来构建软件缺陷数目预测模型:贝叶斯岭回归(Bayesian ridge regression)、线性回归(linear regression)和决策树回归(decision tree regression)。这3种回归模型是在软件缺陷数目预测中常用而且性能较优的模型[17]。
· 贝叶斯岭回归:该方法类似于经典的岭回归方法。这种方法的超参数是通过先验概率引入的,然后基于概率模型的最大化边缘对数似然来评估。
· 线性回归:它通常被用于求解一个或多个自变量和一个因变量之间的线性关系的最小二乘函数。
· 决策树回归:该方法学习简单的决策规则来近似拟合给定的训练数据,然后预测目标变量。
在实验中,采用10折交叉验证,即将原始数据集等分为10份,使用其中的9份作为训练集,剩余的1份作为测试集,反复10次。在此过程中,每1份数据都保证恰好有一次作为测试集,最后结果采用10次交叉实验结果的平均值。
4.4 结果分析
在PROMISE数据集上对所提出的方法进行了实证性研究,对比了ReliefF算法、信息增益、卡方检验3种传统的特征选择方法,以及HFSNFP[18]、FSCR[17]、FSDNP[16]3种用于软件缺陷数目预测的特征选择方法。对于传统的特征选择方法,本文选取的特征数为其中N为特征的总数量。对于HFSNFP、FSCR和FSDNP方法,本文分别根据参考文献[16-18]中的设置来选择特征。在贝叶斯岭回归模型中,全特征(full)、ReliefF算法、信息增益(info)、卡方检验(chi2)、HFSNFP、FSCR、FSDNP等方法与MIC-TSFS方法的AAE见表2。
在贝叶斯岭回归模型中全特征(full)、ReliefF算法、信息增益(info)、卡方检验(chi2)、HFSNFP、FSCR、FSDNP等方法与MIC-TSFS方法的ARE的对比结果见表3。在表2中,第1列表示项目的名称,剩余列表示各种方法的AAE平均值。最后一行表示MIC-TSFS方法与其他方法之间的“Win/Draw/Loss”比较结果。例如MIC-TSFS与全特征的结果为“10/1/3”,即在10个数据集上MIC-TSFS比全特征的性能较好,在1个数据集上MIC-TSFS与全特征性能相似,在3个数据集上MIC-TSFS比全特征的性能弱。贝叶斯岭回归模型下,MIC-TSFS与传统的特征选择方法ReliefF、信息增益、卡方检验进行比较,“Win/Draw/Loss”的结果分别为“10/1/3”“10/1/3”“10/2/2”。MIC-TSFS与HFSNFP方法、FSCR以及FSNNP对比,“Win/Draw/Loss”的结果为“10/1/3”“9/2/3”“9/1/4”,AAE分别降低了5.9%、10.5%、3.8%。倒数第二行mean表示在所有数据集上AAE,贝叶斯岭回归模型下在MIC-TSFS上,AAE的均值最低,即在所有数据集上,MIC-TSFS方法的整体平均绝对误差最小。
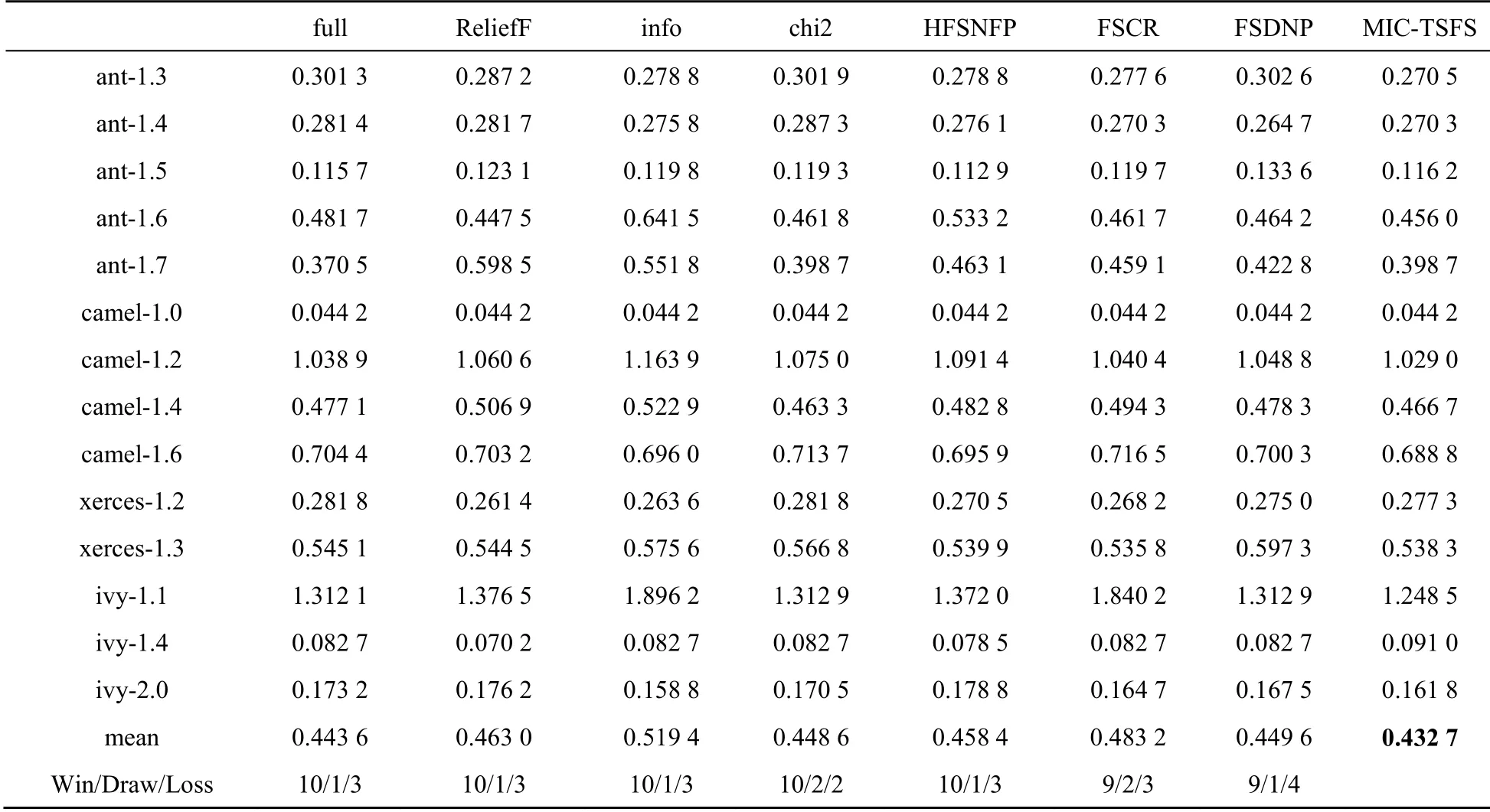
表2 贝叶斯岭回归模型的AAE
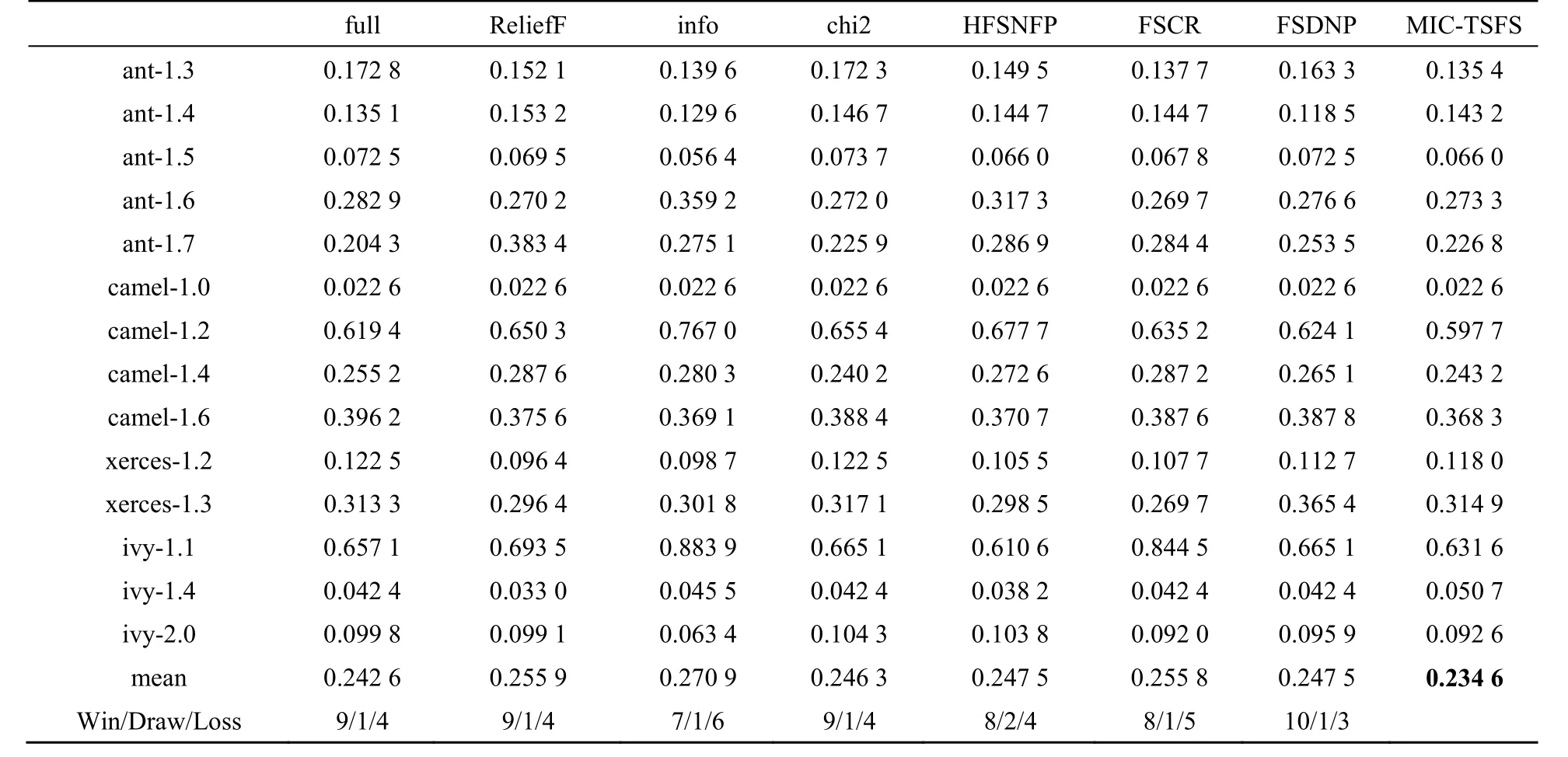
表3 贝叶斯岭归模型的ARE
表3列出了MIC-TSFS方法、全特征(full)、ReliefF算法、信息增益、卡方检验、FSCR、FSDNP以及HFSNFP方法等在贝叶斯岭归模型中的ARE值。MIC-TSFS与这几种方法对比的“Win/Draw/Loss”的结果分别为“9/1/4”“9/1/4”“7/1/6”“9/1/4”“8/2/4”“8/1/5”“10/1/3”。在大多数的数据集下,MIC-TSFS能获得较优的结果,而且在所有数据集上MIC-TSFS的ARE最低。由此可见在贝叶斯岭回归下MIC-TSFS的性能相对其他特征方法的性能较好,即选出的特征能构造更有效的贝叶斯岭回归缺陷数目预测模型。
在线性回归模型中,各种方法的AAE与ARE的对比结果见表4和表5。在表4中,MIC-TSFS方法与全特征(full)、ReliefF算法、信息增益、卡方检验、HFSNFP方法、FSCR以及FSDNP中AAE的“Win/Draw/Loss”对比结果分别为:“8/2/4”“8/2/4”“9/1/4”“9/1/4”“8/1/5”“8/1/5”“8/1/5”。对比FSCR以及FSDNP方法,AAE分别降低3.9%、1.5%。在大多数数据集中,MIC-TSFS方法对比其他特征选择方法,得到的AAE较小。
在表5中,在线性回归模型下,MIC-TSFS方法对比全特征、卡方检验的“Win/Draw/Loss”对比结果分别为“8/2/4”“9/1/4”,表明在大部分数据集中,MIC-TSFS方法得到的ARE较小;MIC-TSFS与ReliefF算法、信息增益、HFSNFP方法、FSCR方法以及FSDNP方法的ARE“Win/Draw/Loss”对比结果分别为 “7/2/5”“7/1/6”“7/1/6”“7/1/6”“7/1/6”,表明在过半的数据集上MIC-TSFS比ReliefF算法、信息增益、HFSNFP方法、FSCR方法以及FSDNP方法,MIC-TSFS所得到的ARE小,且MIC-TSFS方法选出的特征构建的线性回归模型在所有数据集上的AAE与ARE最低。因此MIC-TSFS方法选出的特征也能构造更为有效的线性回归预测模型。
表6和表7分别列出了在决策树回归模型下各种方法的AAE与ARE的对比结果。

表4 线性回归模型的AAE
在表6中,MIC-TSFS方法所有数据集的AAE均值最小,且MIC-TSFS方法与全特征、ReliefF算法、信息增益、卡方检验、HFSNFP方法的AAE“Win/Draw/Loss”比较结果分别为:“9/1/4”“9/1/4”“8/2/4”“8/2/4”“8/1/5”。在表 7中,所有数据集上MIC-TSFS的ARE均值最低,且MIC-TSFS方法与全特征、ReliefF算法、信息增益、卡方检验、HFSNFP方法的AAE“Win/Draw/Loss”的结果分别为“9/1/4 ”“8/1/5”“9/2/3”“8/2/4”“8/2/4”。说明在大多数数据集中,由MIC-TSFS方法所挑选的特征训练出的模型误差较小。MIC-TSFS相比于FSCR与FSDNP方法,AAE分别降低3.5%、3.2%,ARE分别降低3.8%、5.4%。由此可以看出MIC-TSFS方法选择的特征,也能构造更为有效的决策树回归模型。

表5 线性回归模型的ARE

表6 决策树回归模型的AAE

表7 决策树回归模型的ARE
为进一步说明MIC-TSFS方法的有效性,表8~表10分别给出经由各种特征选择方法选出的特征子集分别在贝叶斯岭回归、线性回归以及决策树回归模型中得到G-mean值。
在表8中,MIC-TSFS的G-mean均值最高。与ReliefF算法、信息增益、卡方检验、HFSNFP、FSCR以及FSDNP的特征选择方法相比,G-mean均值分别提升4.9%、7.2%、4.1%、5.9%、9.8%、10.5%。
在表9中,MIC-TSFS的G-mean同样具有最高的均值,与不使用特征选择方法的full相比,其G-mean均值提高5.3%,而对比ReliefF算法、信息增益、卡方检验,G-mean均值分别提升6.4%、29.1%、8.2%。MIC-TSFS相对于HFSNFP、FSCR以及FSDNP特征选择方法G-mean均值提升3.7%、5.4%、13.5%。
从表10可以看出MIC-TSFS同样具有较高的G-mean均值。与ReliefF算法、信息增益、卡方检验、HFSNFP、FSCR以及FSDNP的特征选择方法相比,G-mean均值分别提升3.2%、17.6%、2.8%、3.9%、3.2%、5.7%;而与不使用任何特征选择方法相比,G-mean均值提升3.8%。
在贝叶斯岭回归、线性回归以及决策树回归3种模型中,MIC-TSFS方法的G-mean的平均值都达到最优,说明就整体情况而言,MIC-TSFS方法要优于其他特征选择方法。然而,在数据集camel-1.0与ivy-1.4上,特征选择方法的大多数G-mean值为0,其可能原因是这两个数据集中数据不平衡率较高(其中缺陷数目大于0的样
本的占比分别是3.8%、6.7%),受数据不平衡的影响,这3种回归模型均没有正确找到的缺陷数不为0的样本,从而导致混淆矩阵中TP为0。因此,在后续工作中可以考虑对不平衡因素进行处理,如结合smote过采样或代价敏感,以进一步提高模型预测性能。
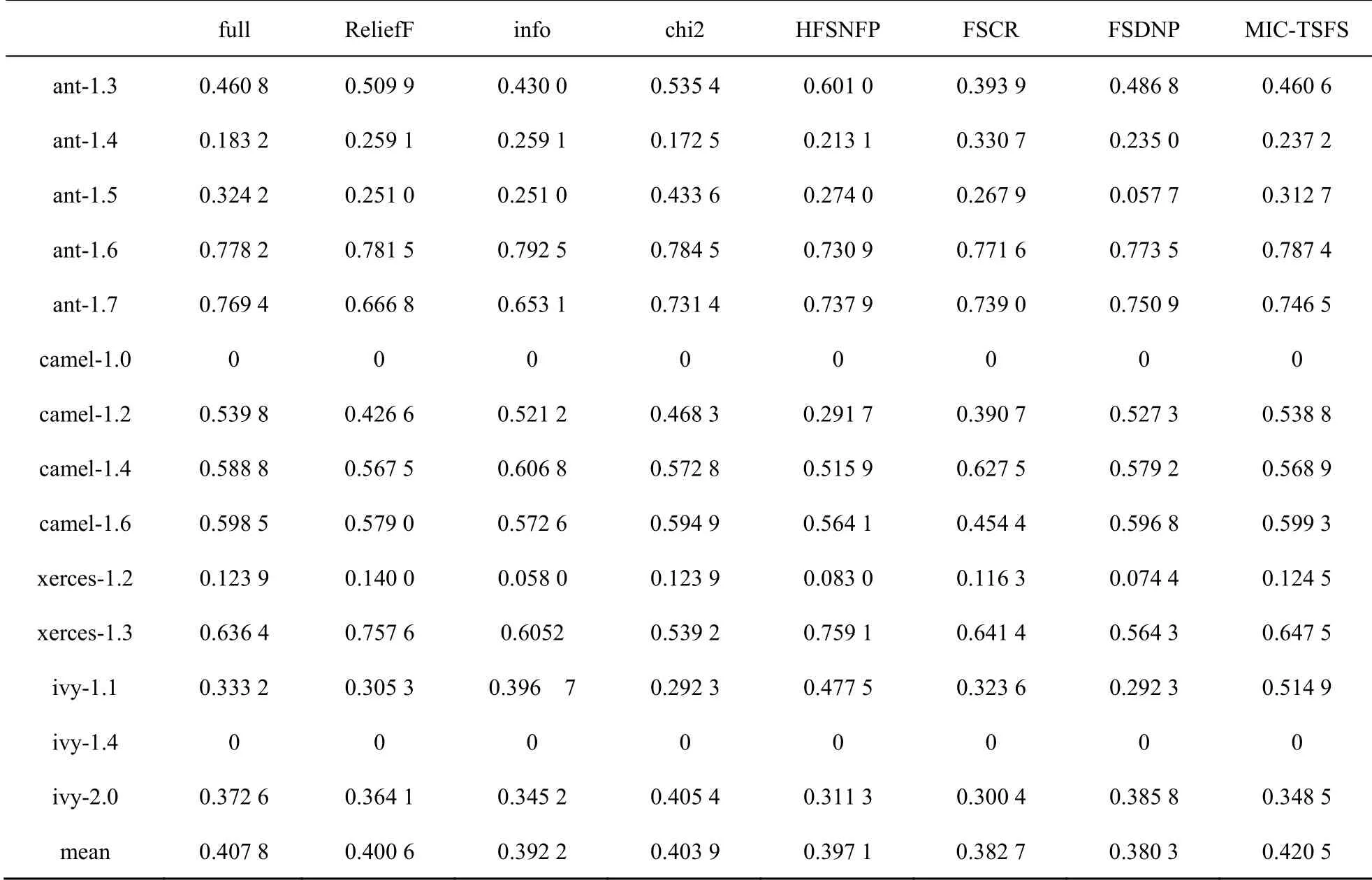
表8 贝叶斯岭回归模型的G-mean

表9 线性回归模型的G-mean

表10 决策树回归模型的G-mean
对比在贝叶斯岭回归、线性回归、决策树回归模型下,MIC-TSFS方法相对传统的特征选择方法的性能较好,这是因为MIC-TSFS除了考虑特征和标签之间相关性外,还考虑了特征与特征之间的冗余,通过特征聚类让较为相关的特征聚在同一个簇中,这样再从不同的簇中分别挑选特征,就能很好地改善特征冗余带来的负面影响,从而提高预测性能。与HFSNFP、FSCR、FSDNP方法相比,Pearson系数仅能衡量特征间的线性关系,MIC-TSFS方法采用最大信息系数,不仅可以描述线性关系,还可以很好地描述非线性、非函数关系等依赖关系,能够挖掘特征间以及特征与软件缺陷数目间更多的依赖关系。
从特征间的冗余性角度,MIC-TSFS方法能够更为公平地删除更多的冗余特征,使得特征间的冗余性进一步降低。从特征与软件缺陷数目间的相关性角度,MIC-TSFS方法能够最大限度地保留与软件缺陷数目相关的、更有区分能力的特征,也可以避免特征与软件缺陷数目的相关性评价的偏置。由此,MIC-TSFS 方法选择的特征对软件缺陷数目的识别能力更强,且冗余度低,因此预测准确率有所提升。
5 结束语
本文提出一种基于最大信息系数的软件数目预测特征选择方法MIC-TSFS,用于删除冗余特征和不相关特征。在PROMISE公开数据集上进行了大量的实验,实验结果表明MIC-TSFS能够有效地删除冗余特征和不相关特征,可以提高软件缺陷数目预测模型的预测精度。但该方法仍有一些后续工作值得扩展,包括:在冗余性分析阶段,探讨聚类中止条件的设置对MIC-TSFS方法是否存在影响;在相关性分析阶段,研究获取的特征数最优值的方法;讨论数据不平衡率对预测结果所产生的影响,并结合smote过采样方法、代价敏感等不平衡处理方法,进一步提高模型预测性能。此外,实验中MIC-TSFS方法仅应用于中小型项目(程序模块在1 000以内),讨论其在大型程序项目中的实际应用效果是下一步工作的重点。
猜你喜欢
小猕猴智力画刊(2021年6期)2021-08-05
黑龙江工业学院学报(综合版)(2020年6期)2020-08-11
成都信息工程大学学报(2018年3期)2018-08-29
电子元器件与信息技术(2017年4期)2017-03-08
电子制作(2017年23期)2017-02-02
中国民族医药杂志(2016年5期)2016-05-09
作文大王·低年级(2016年3期)2016-03-11
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
电脑与电信(2014年10期)2014-03-13
