
基于U-net语义分割模型的田间玉米冠层图像分割
2021-06-16 06:56王晓东樊江川杜建军温维亮郭新宇
江苏科技大学学报(自然科学版) 2021年2期
王晓东,樊江川,杜建军,云 挺,温维亮,郭新宇 *
(1.中国农业大学 信息与电气工程学院,北京100083) (2.国家农业信息化工程技术研究中心,北京 100097) (3.数字植物北京市重点实验室, 北京 100097) (4.南京林业大学 信息科学技术学院, 南京210037)
基于可见光图像的玉米长势监测与表型解析在现代玉米育种、生产和管理中扮演了重要的角色[1-2].田间生长环境下采集的玉米冠层图像普遍受到复杂天气条件影响,这使得自动分割玉米多生育期图像数据面临巨大挑战,如何从玉米冠层图像序列中高质量提取出玉米结构信息,并准确确定其生育期成为当前作物表型研究热点之一[3].
近年来,传统的图像分割算法如阈值法[4]、聚类法[5]、区域生长法[6-7]、图论法[8]等在农业领域得到了广泛应用.传统的图像分割方法多基于人工提取图像的灰度、颜色、纹理和空间几何等特征,通过增强这些特征在前景与背景区域的差异性,使得前景与背景分离.这类方法虽然相对简单且易于实现,但人工定义的图像特征难以全面描述作物对复杂生长环境的响应,使得传统的算法只适用于特定类型的图像分割,而在处理不同光照条件、不同生育期作物图像时传统算往往法泛化能力不足,存在大量过分割和欠分割现象.
随着卷积神经网络的发展,深度学习已在自然语言处理[9]、图像识别[10-11]、视频跟踪[12]等领域超越了传统的机器学习算法.在农业领域,由于卷积神经网络较强的图像特征提取能力,越来越多的学者将深度学习应用于表型信息获取[13],农业遥感影像分类等[14]领域. 文献[15]提出的全卷积神经网络(fully convolutional networks,FCN),奠定了深度学习在语义分割领域的基础,而后大量的基于FCN的网络模型被提出,且被应用于农业的各个领域.如文献[16]利用全卷积网络结合条件随机场,实现了棉花冠层图像的语义分割;文献[17-18]利用SegNet模型提高了田间玉米冠层图像的分割精度.但这些方法中上下文特征语义信息联系不紧密,会造成部分细节信息丢失,从而导致分割精度不能满足精细化表型提取的要求;增加卷积层数虽然可以增强特征提取能力,但随着卷积深度的增加又可能造成梯度消失和网络难以训练的问题.针对这些问题,文献[19]提出的U-net模型通过跨层连接实现了上下文信息融合,能够实现端到端的训练输出.从而拥有较好的分割效果.文献[20]提出 ResNet的模型解决了随着卷积网络层数加深而造成的梯度消失、爆炸及深层网络难以训练的问题,可在更深层网络中提取特征信息.
针对传统分割算法对于不同光照条件下玉米原位冠层图像分割效果差,泛化性低的问题以及经典卷积网络模型缺乏上下文特征融合而造成分割精度难以满足精细化表型提取需求的问题.文中利用深度学习模型训练学习像素级图像特征.提出在U-net语义分割模型的基础上,通过残差学习进一步增强卷积深度,利用深层次特征进行像素级图像分割.
1 材料与方法
1.1 原位玉米冠层图像获取装置与方法
试验在北京市农林科学院试验田内开展,玉米种植小区大小为5 m×5 m(材料为ZD985,种植密度为45 000株/hm2,正常水肥管理).小区内部署一套冠层图像采集装置,如图1.
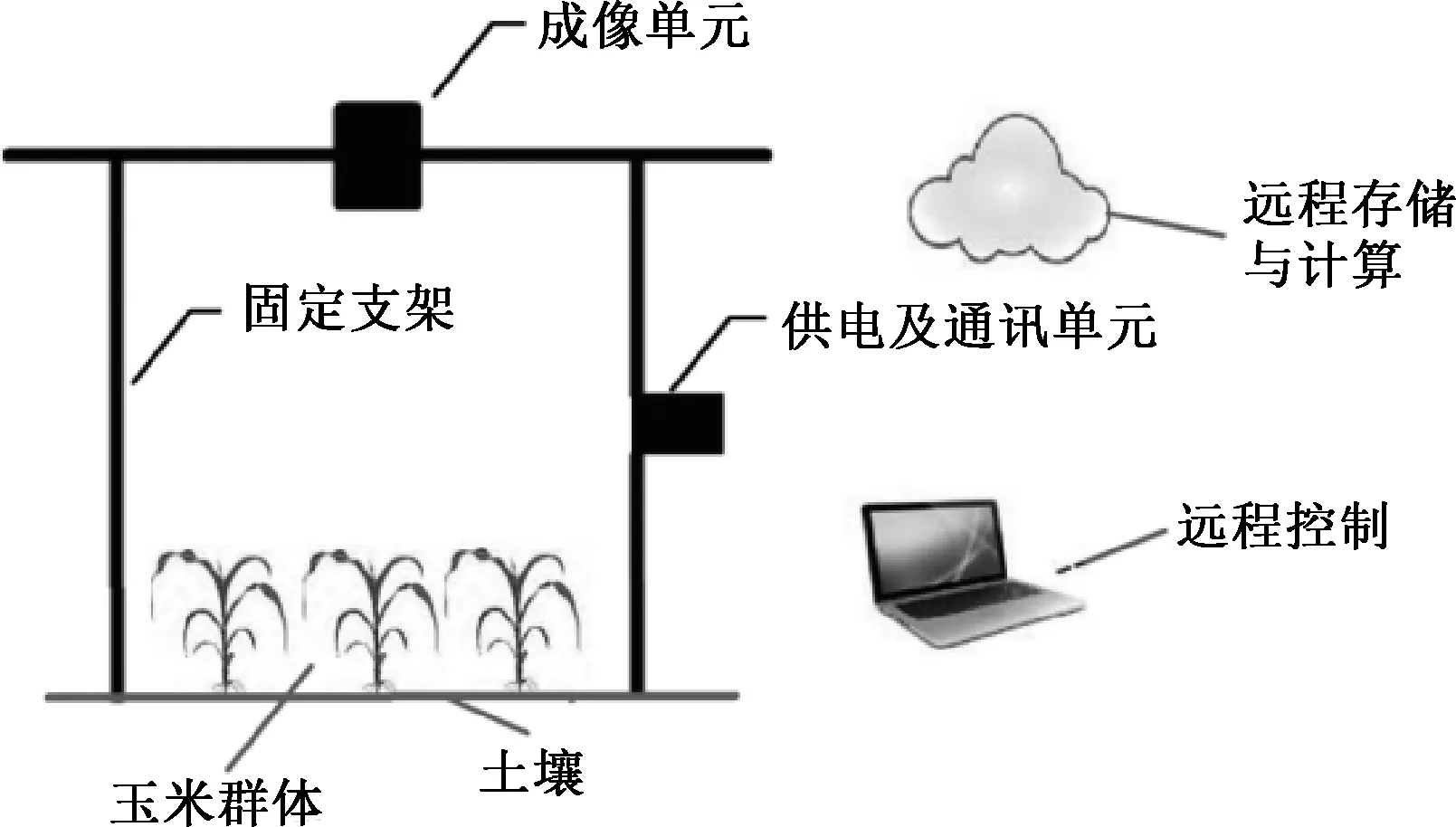
图1 图像采集装置示意
整个图像获取装置包括成像单元、供电及通讯单元和桁架结构.成像单元置于玉米冠层顶部,距离地面6 m,由桁架结构支撑固定,图像采集指令由远程上位机发出,无线176通讯网络负责指令和图像数据的传输.成像单元图像采集设备采用海康威视DS-2CD5052F的高清网络摄像头,像素为500万,图像的分辨率为1 920×1 080像素.本次实验采用自动曝光模式对田间作物进行图像数据采集.图像采集时间从2018年6月 15 日起到 2018年7月17日止,每隔 1 h 获取被监测玉米小区可见光图像,每天可获取24张图像,共计获取768张.
为了适配复杂的光照条件和不同生育期图像数据变化(如:晴天,阴天,强光,弱光,阴影,叶片高光反射等),选取从2018年6月16日到7月16日之间连续一个月早7时到晚19时的时序图像数据构成原始数据集(共390张图像).为了降低模型的输入大小、便于数据标注,从原始图像中选择中心无杂物区域进行裁剪,将图像尺寸从1 920×1 080像素减小为512×512像素.在此基础上将数据集按照7 ∶3划分为训练集和测试集.训练集,共273张图像,测试集共有117张图像.图2为裁剪后图像及其标注.

图2 不同光照条件下冠层图像及标注
U-net模型结构决定其输入图像尺寸需为32的倍数,为了增加数据数量防止过拟合,且在满足U-net模型的输入需求的条件下,将训练集彩色图像及其标注值由 512×512裁剪为256×256大小,即每张尺寸为512×512的图像裁剪为4张尺寸256×256的图像,并进一步进行镜像和旋转.最终训练集共2 184张图像.其中原始图像是JPEG格式,标注图像是PNG格式.
1.2 研究方法流程
文中基于U-net语义分割模型和Resnet残差学习模型进行田间玉米冠层图像分割方法流程如图3,主要包括数据获取及预处理、模型构建及优化和精度评价3个阶段.
数据获取及预处理阶段主要进行数据获取和数据集组织划分.模型构建及优化阶段主要是在U-net模型的基础上逐步进行结构优化和模型训练.精度评价主要比较不同模型在测试图像上的精度比较,确定最优参数并验证其泛化性.
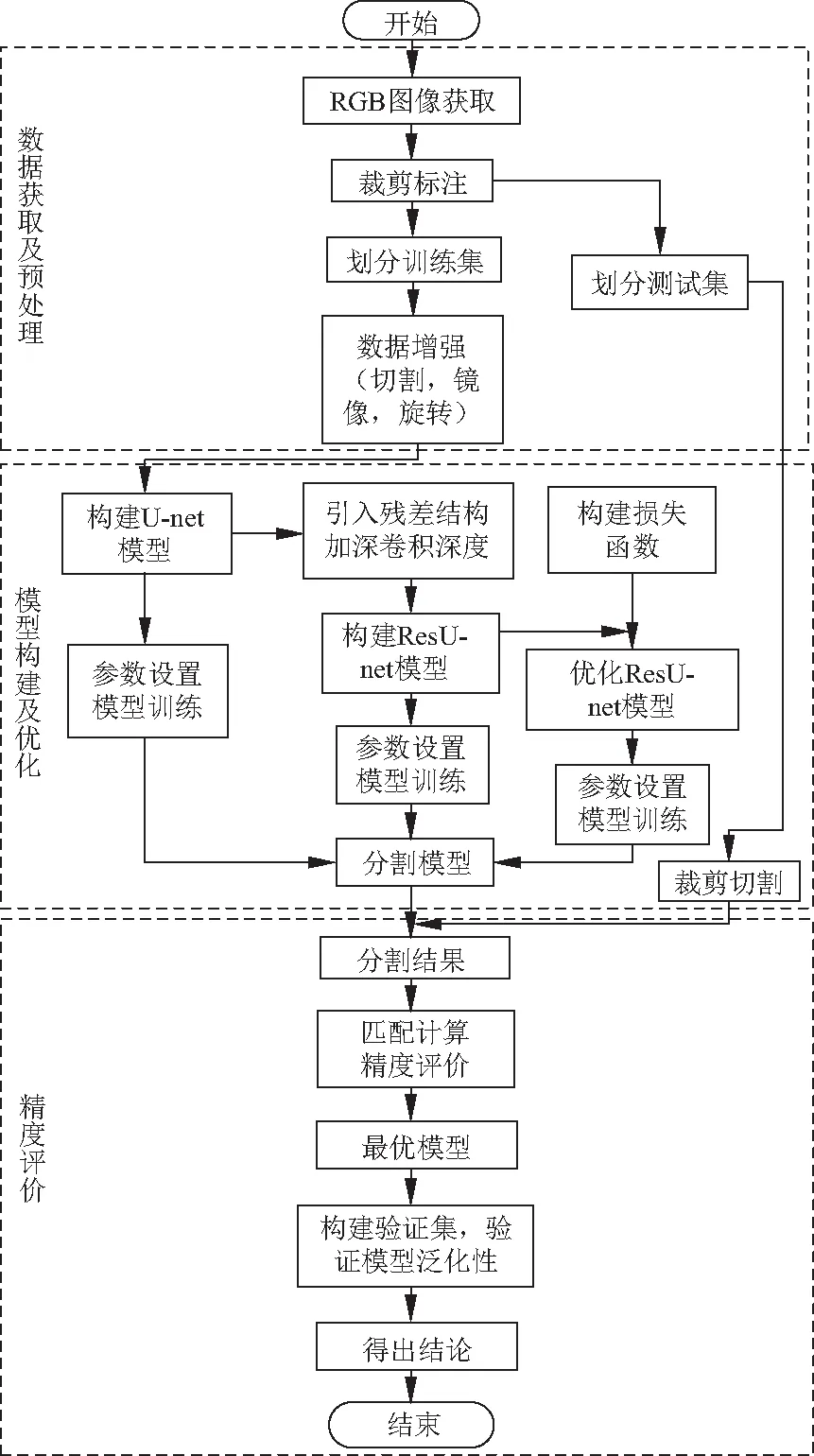
图3 基于U-net模型的玉米冠层图像分割流程
2 ResU-net图像分割模型
2.1 ResU-net模型结构
U-net模型包含一个收缩路径和一个扩张路径,收缩路径用于捕捉上下文,扩张路径用于实现精确定位,两个路径呈对称关系.收缩路径中包括5个卷积模块,每个模块中包括两次卷积操作,模块间进行一次池化操作;扩张路径是与收缩路径相反的上采样过程,扩张路径包括4个上采样模块.每个上采样模块包括一次反卷积操作、一次特征融合和两次卷积操作.输出前进行一次1×1卷积用于分类输出.
残差学习的主要思想是在网络中增加一个直接从输入到输出的旁路,并利用残差来学习神经网络层之间的差异,有效避免了随着网络深度的增加而造成的梯度消失或爆炸问题.残差学习单元的模型结构如图4.x为该层的输入数据,若经过隐藏层后x对应的输出为H(x),假设输入和输出维度一致,则可令F(x)=H(x)-x为残差函数.可以验证拟合F(x)与拟合H(x)的目标是等价的.由于增加了一个快捷映射分支,两个分支通过特征映射融合后,原始函数可表述为H(x)=F(x)+x,使得输入与输出之间由传统网络中的非线性连乘转变为残差累加的线性连接.整个网络只需要学习输入和输出之间的差异,简化了学习目标,降低了学习难度.
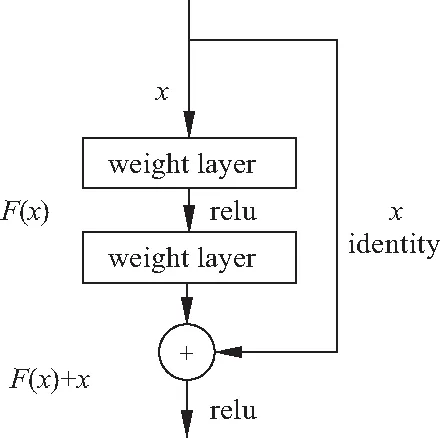
图4 残差结构
玉米冠层图像光照背景复杂,使用传统的U-net模型难以达到预期效果.而单纯的增加模型的网络深度又会造成训练难度增加,存在梯度消失及爆炸的问题.为了实现复杂光照条件下玉米冠层图像分割,文中基于残差学习的思想,在U-net网络的基础上设计应用了残差(Residual)学习单元,构成ResU-net网络结构.
ResU-net模型的收缩路径一共包括5个卷积模块,第一个卷积模块通过卷积和最大池化操作对输入图像进行尺寸调整,后四个卷积模块由不同数量的残差结构有机组合,对输入数据进行特征提取.收缩路径中结构及参数设置如表1.
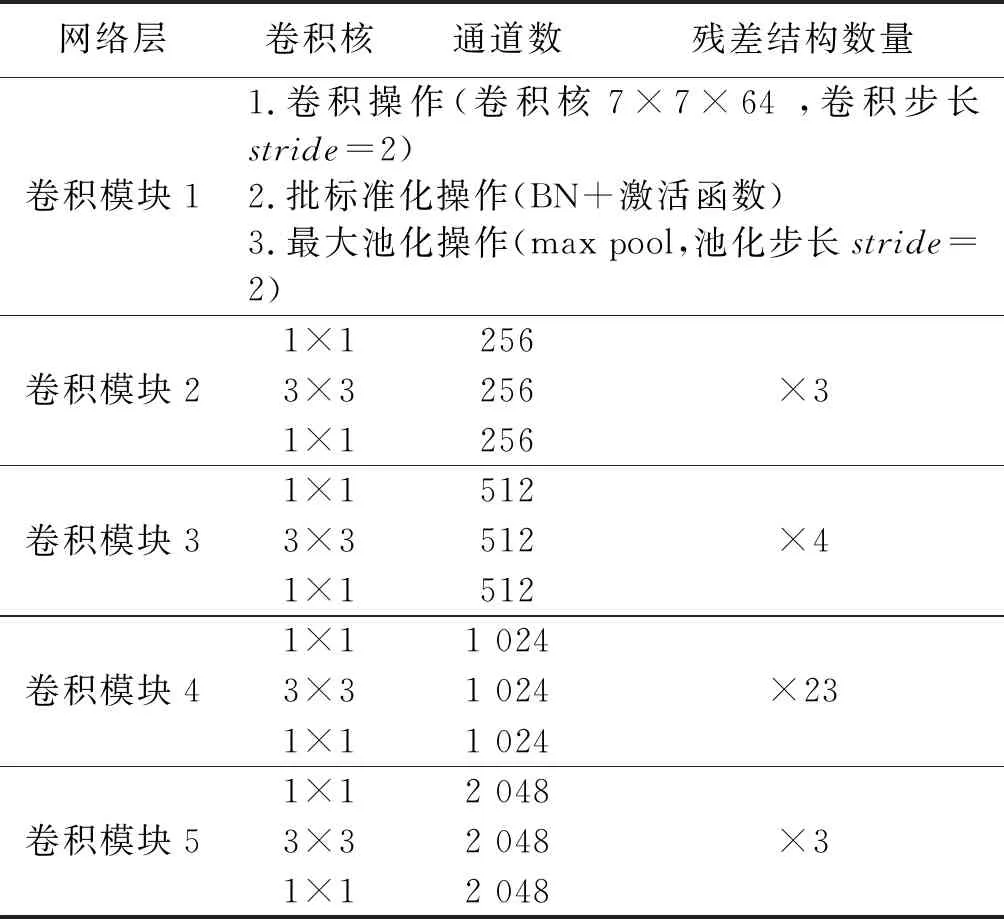
表1 收缩路径结构参数配置
对应于收缩路径的结构,ResU-net的扩张路径采用5层上采样结构.上采样层结构如图5.每次上采样后进行卷积、批标准化和激活操作,而后与收缩路径对应的低维特征进行融合.将融合后的特征图再进行两次卷积、批标准化及激活操作后传递到下一层上采样层.
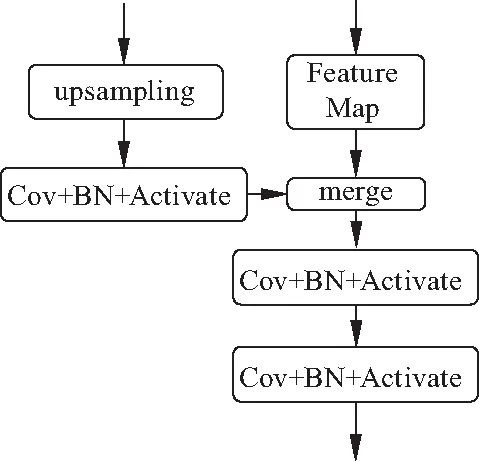
图5 上采样结构
2.2 ResU-net模型优化
传统的U-net模型隐藏层利用修正线性单元(rectified linear unit, ReLu)作为激活函数.如图6,ReLu函数当输入值为负时,输出值恒定为0,使得梯度变为0.这就可能造成的神经元失活情况.为此文中利用指数线性单元(exponential linear unit,ELU)作为激活函数.在ELU激活函数的基础上,将激活函数的曲线向上平移得到activation=elu+1,如式(2),式中x为经过当前隐藏层后的输出,a表示趋于0的非负数.这样就为负值输入添加了一个非零输出,从而防止失活神经元的出现,提高了学习效率.
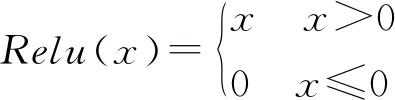
(1)
(2)
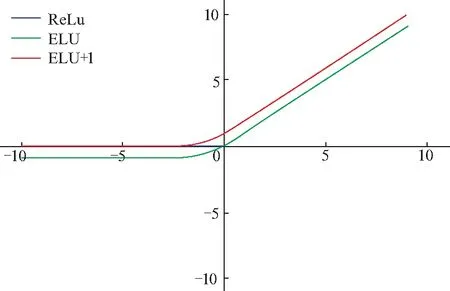
图6 激活函数图
玉米原位冠层图像随着玉米生育期的变化会造成冠层图像中的前景与背景像素点不均匀的问题.如图7,随着时间的推移前景像素点比例逐渐增大,而交叉熵损失是对每个像素点进行均匀的计算.仅仅使用交叉熵损失得到的效果并不理想.
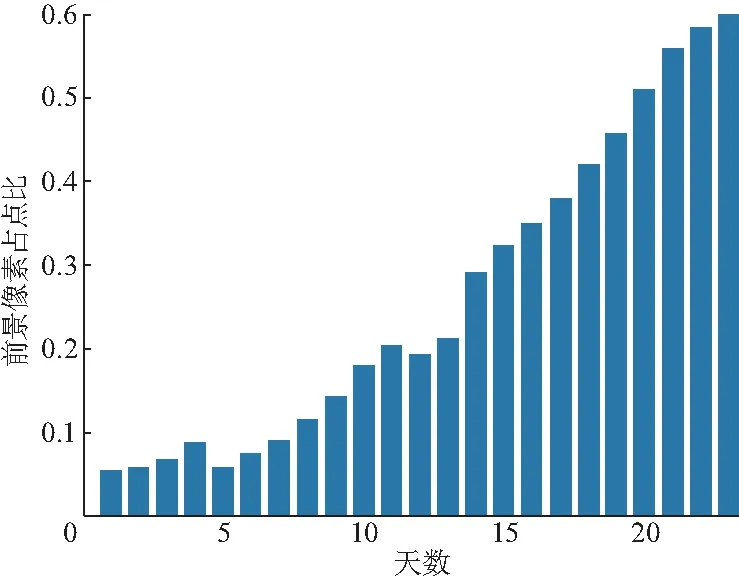
图7 前景像素比例变化图
为解决此问题,文中在交叉熵损失的基础上结合分割领域典型的损失函数和评价指标,构成CE-Dice、Focal-Tversky、CE-F1、Focal-Dice 4种损失函数,如表2.
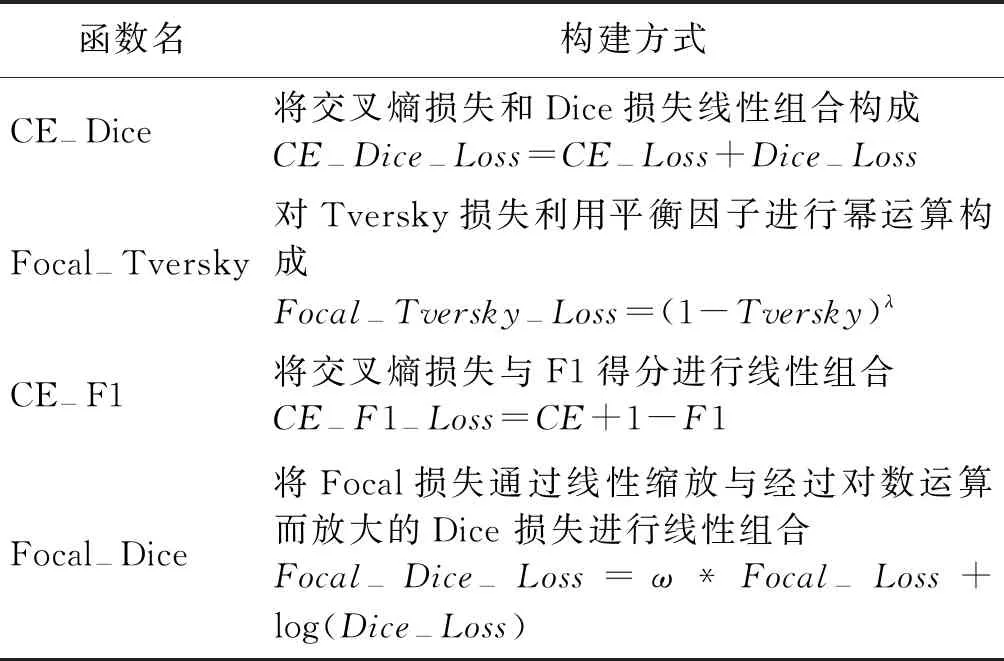
表2 不同损失函数的构建方式
其中Focal损失函数[20-21],是在交叉熵损失函数的基础上提出,旨在解决one-stage类型目标检测问题中由于类别失衡造成的分类精度低的问题.Dice 损失是文献[22]在V-net中提出的Loss function,其源于Sørensen-Dice coefficient,将Dice系数作为目标优化项.Tversky损失[23]对Dice Loss的正则化版本,其源于Tversky系数.各函数数学表达式如下:
(3)
式中:N为总样本个数;yn,l为第n个样本预测是否为第l个标签,若是记yn,l,否则为0;pn,l为第n个样本预测为第l个标签的概率.
(4)
式中:N为总样本个数;p和r为预测值和真实值.
(5)
式中:a为类平衡因子;λ为难易平衡因子;p为预测为1的输出概率;y为像素点的预测值,文中取值为0或1.
2.3 模型训练方式
模型训练过程就是对损失函数进行优化的过程.文中模型训练采用的是文献[24]提出的适应性矩估计优化算法(adaptive moment estimation optimization algorithm,Adam),其与传统的随机梯度下降不同.随机梯度下降保持单一的学习率更新所有的权重,学习率在训练过程中并不会改变;而Adam通过计算梯度的一阶矩估计和二阶矩估计从而为不同的参数设计独立的自适应性学习率,并且有很高的计算效率和较低的内存需求.算法的数学表达式如下:
(6)

文中模型训练将初始学习率设置为0.001,衰减率分别设置为为0.9、0.999.设置训练迭代次数为200次.批大小设置为2,模型训练是在Windows10操作系统下配载GTX1080Ti GPU利用tensorflow-Keras框架完成.
2.4 模型评价指标
分类模型训练结束之后需要判断其分类性能,尤其对于二分类而言,常用的评价指标有总体精度(Accuracy)、查全率(Recall)、查准率(Precision)、交并比(IOU)和F1值.为客观评价分类的精度,采用以上5种精度评价指标对玉米冠层图像分割结果进行精度评估.具体计算方式如下:
(7)
(8)
(9)
(10)
(11)
式中:TP为真阳性样本像素数;TN为真阴性样本像素数;FP为假阳性样本像素数;FN为假阴性样本像素数.
3 结果与分析
3.1 不同网络结构精度比较
设置隐藏层使用修正线性单元(rectified linear unit,ReLu)作为激活函数,输出层利用Sigmold进行激活.以交叉熵损失函数(cross entropy loss)作为模型训练的目标优化函数.分别对U-net模型的ResU-net模型进行迭代训练,训练曲线如图8.可知两个模型在迭代120次后,训练曲线趋于平缓.迭代200次后,ResU-net模型的训练准确率可以逼近94%,U-net模型的训练准确率约为92%.
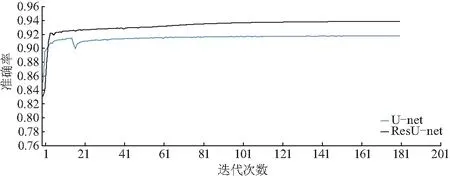
图8 模型训练曲线
不同模型对测试集的分割效果如图9.其中图(a)和(e)光照均匀,但亮度不同;图(b)、(c)和(e)光照不均匀且存在不同程度的阴影.对比可知,不同分割模型对于图(a)的分割并无明显差异,分割效果较好.但对于亮度比较低的图(e),通过对比框内区域可知,U-net模型存在欠分割现象,ResU-net模型分割较为完整;对比图(b)左下方的框内区域可知,U-net模型对于阴影遮挡部分欠分割严重,ResU-net模型虽然也存在欠分割,但其轮廓相对清晰完整.

图9 不同模型分割结果对比
对于图(e)和图(d)的分割,对比框内区域可知,U-net模型存在较大程度的过分割现象,错将杂草分为叶片,而ResU-net模型则对于杂草的分割则相对较好.
各模型在测试集的评价指标的平均值如表3,由表可知U-net模型的精确率为0.857 2,小于ResU-net模型的0.929 5,这也验证了ResU-net模型对于图9中样本的欠分割和错分割程度优于U-net模型,但ResU-net模型的IOU值小于0.87,说明ResU-net模型存在一定程度的欠分割和错分割现象.
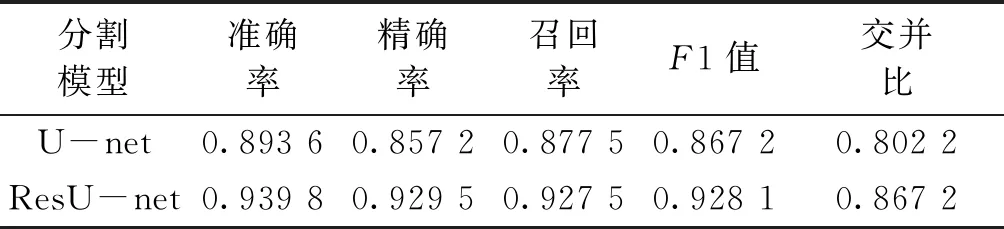
表3 不同分割方法测试集分类结果对比
3.2 不同损失函数ResU-net++模型的确定
为了进一步提升ResU-net模型的分割精度,将ResU-net模型隐藏层的激活用函数改为式(2)形式,并分别以CE-Dice、Focal-Tversky、CE-F1和Focal-Dice作为损失函数进行训练.不同模型对于测试集的5种评价指标的平均值如图10.
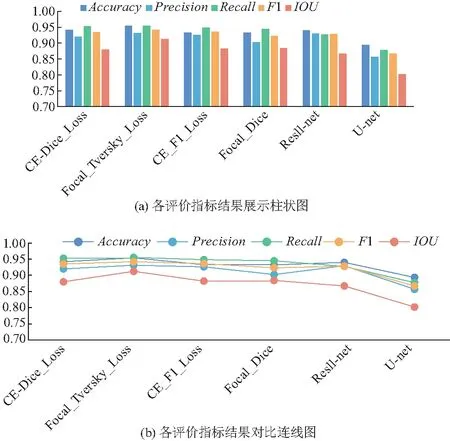
图10 不同损失函数ResU-net模型在测试集分割精度对比
由图10可知,修改损失函数后训练的4种ResU-net模型,在测试集中的总体分割准确率在0.93~0.984之间浮动;精确率在0.90~0.931之间浮动;召回率在0.95左右浮动,优于U-net模型的0.877 5和以交叉熵为损失函数的ResU-net模型的0.927 5;F1值在0.92~0.942之间浮动;IOU值在0.87~0.913之间浮动,优于U-net模型的0.802 2和以交叉熵为损失函数的ResU-net模型的的0.867 2.其中表现最为优异的是以Focal-Tversky为损失函数的ResU-net模型(简称为ResU-net++),其在测试集种的5种评价指标的平均值分别为:准确率为0.953 9、精确率为0.931、召回率为0.955 1、F1为0.941 9、IOU为0.912 3.
ResU-net++模型对于图9(b)的精确率是0.920 3,高于ResU-net模型的0.875 6;IOU值为0.894 0高于ResU-net的0.856 4,说明ResU-net++模型对于图9中(b)图的分割效果更好.
3.3 ResU-net++模型泛化性
为了验证ResU-net++模型对于不同玉米品种分割精度的鲁棒性,从种植材料为登海605的数据集(数据获取时间为2016年,数据获取方式与本文数据集一致)中随机选择选择40张图像作为测试集.在该测试集的平均准确度为0.912 5,平均精确度为0.931 5,说明ResU-net++具有一定的泛化性.图11为登海605测试集上的部分结果图.
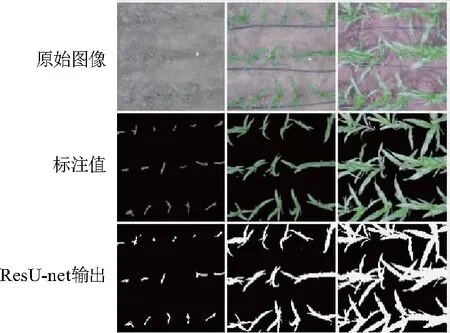
图11 ResU-net++模型在登海605测试集的分割
4 结论
(1) 以时序数据构建了不同光照调条件下的玉米原位冠层图像数据集.在U-net模型的基础上增加残差学习单元,构建了ResU-net模型.该模型在测试集的平均分割准确率0.939 8,优于传统的U-net模型的0.893 6.
(2) 通过修改ResU-net模型隐藏层的激活函数,并且构造、对比4种不同损失函数在测试集上的优劣,进一步提高了ResU-net模型的分割精度,其中以Focal-Tversky函数为损失函数的ResU-net++模型在测试集上的表现优于ResU-net模型,准确率达到0.953 9.
(3) 以登海605数据作为验证,得到的平均精确度为0.931 5,说明ResU-net++模型具有一定的泛化性.
(4) 基于U-net模型和残差学习模型的田间玉米冠层图像分割方法,对于田间玉米冠层分割具有较高的分割精度,未来可以在时间序列上继续扩充图像数据集,以进一步提高模型的性能,做到全生育期的图像分割,为全生育期冠层表型监测提供技术支撑.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
上海农业学报(2022年4期)2022-09-06
作物杂志(2022年3期)2022-07-06
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
作物学报(2022年5期)2022-03-16
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
北京航空航天大学学报(2020年10期)2020-11-14
