
基于改进旋转策略的量子遗传-神经网络算法的软件缺陷预测模型
2021-06-06 13:08:24崔梦天吴克奇周绪川贺春林
西南民族大学学报(自然科学版) 2021年3期
崔梦天,吴克奇,谢 琪,周绪川,贺春林
(1.西南民族大学计算机系统国家民委重点实验室,四川 成都610041;2.西华师范大学计算机学院,四川 南充637009)
开源软件作为软件产业未来发展的主要趋势之一,如何保证其质量始终是业内关注且至关重要的问题.开源软件的开放性和基于社区的共享性使得源码中经常包含很多漏洞,导致缺陷处理的成本大幅增加,阻碍了开源软件的应用推广.因此,研究的热点之一是如何有效、准确地发现软件缺陷,并快速修复软件缺陷.为了评估动态系统中的构件可靠性,文献[1]提出了一种模型选择方法.为了克服神经网络易陷入局部最优,文献[2]提出了灰狼优化算法.
无论在模型表达还是在计算思想上,量子计算、神经网络和遗传算法之间都存在着许多类似的地方,大量学者对量子计算、遗传算法和神经网络相结合并开展了许多研究[3].人工神经网络算法是机器学习中的一种常用算法,BP神经网络被广泛用于缺陷预测.但传统BP网络容易陷入局部最优,影响预测准确率.为了提高缺陷预测准确率,利用量子遗传算法(QGA)优化网络的权值和阈值,构建预测模型进行实验.通过实验的对比,得出本文的软件缺陷模型预测的结果优于传统BP神经网络和标准的QGA-BP预测的结果.
1 相关工作
软件缺陷预测技术通过挖掘、分析软件项目中的历史开发数据来检测潜在有缺陷的软件模块,从而提高开发效率,节省开发成本.
1.1 BP神经网络架构
神经网络是一种非线性统计性数据建模工具[4].当神经网络进行正向传播时,上层神经元的状态会影响下层的神经元.如果输出的结果没有达到要求,就会出现反向传播,从而降低信号误差[5].
1.2 标准的量子遗传算法
量子遗传算法是一种新型进化算法[6],量子比特的状态表示为:
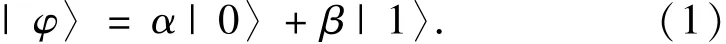
式(1)中,α和β分别表示状态|0〉和状态|1〉的幅常数,还满足以下条件:

量子遗传算法的染色体结构为:

调整操作中的量子旋转门为:

其更新过程为:
旋转角的调整策略如表1所示,如果f(x)≥f(b)判定为False,那么当前个体会向更利于b i的方向进行旋转;如果f(x)≥f(b)判定为True,那么当前个体会向更利于x i的方向进行旋转.
表中x i是当前个体的第i个基因位,b i是当前最优个体的第i个基因位,f(x)是当前个体的适应度数值,f(b)是当前最优个体的适应度数值,Δθi是旋转角度,是旋转方向,是旋转角[8].
2 软件缺陷预测模型的建立
基于BP神经网络的软件缺陷预测模型一般会导致学习时间长、预测精度差的问题,具有较高的概率陷入局部最优值.因此,需要调整以提高软件缺陷模型的预测性能.
2.1 改进的量子遗传算法
更新进化操作是量子遗传算法的重要组成部分,直接关系着收敛速度的快慢.当旋转角度变化太小时,可能导致收敛速度太慢;当旋转角度变化太大时,可能导致早熟的发生.因此,如何确定旋转角度的变化直接影响着量子遗传算法的性能.标准的量子遗传算法不够灵活,因为其根据更新策略表而变化.

表1 量子旋转门的旋转角与旋转方向调整策略Table 1 Adjustment strategy of rotation angle and direction of quantum revolving door
改进的量子遗传算法将适应度值和旋转角度联系在一起.当适应度的差值相差较大时,旋转角度的变化幅度也会比较大;当适应度的差值相差较小时,旋转角度的变化幅度也会比较小.
对于旋转角度Δθ的动态调整策略如下[8]:
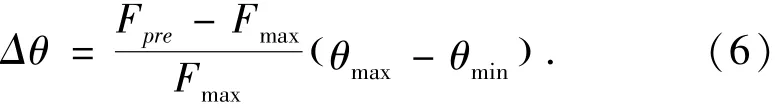

?
3)若Δθ<θmin,则Δθ取最小值θmin.
下面给出动态调整旋转角度的伪代码,具体如下:
2.2 改进的量子遗传算法优化BP神经网络
具体的实现过程如下:
1)创建神经网络并随机初始化,得到初始化种群Q(t0);
2)目标函数的输出[9]如下:

3)记录最优个体及其对应的适应度;
4)判断是否满足条件,如果满足,则停止计算并赋值,否则继续计算;
5)测量Q(t)中的个体,以得到相应的确定解[10],对各确定解进行适应度评估;
6)对个体实施调整,得到新的种群Q(t+1);
7)记录最优个体和适应度,然后t加1,返回步骤4).
2.3 软件缺陷预测模型
软件缺陷预测模型的流程图如图1所示.
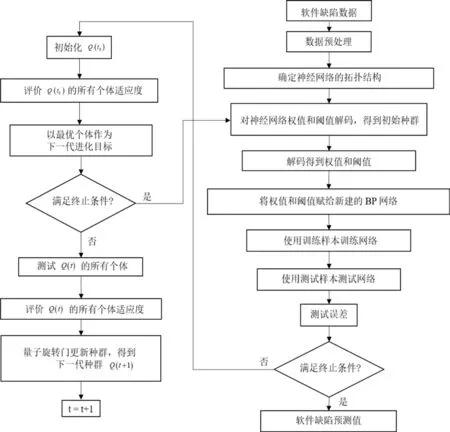
图1 软件缺陷预测模型流程图Fig.1 Flow chart of software defect prediction model
3 实例分析
3.1 实验数据
本文采用NASA提供的MDP软件信息数据集,对基于改进后的QGA-BP算法的软件缺陷预测模型进行验证分析和性能对比,实验数据集中的相关信息如表2所示.
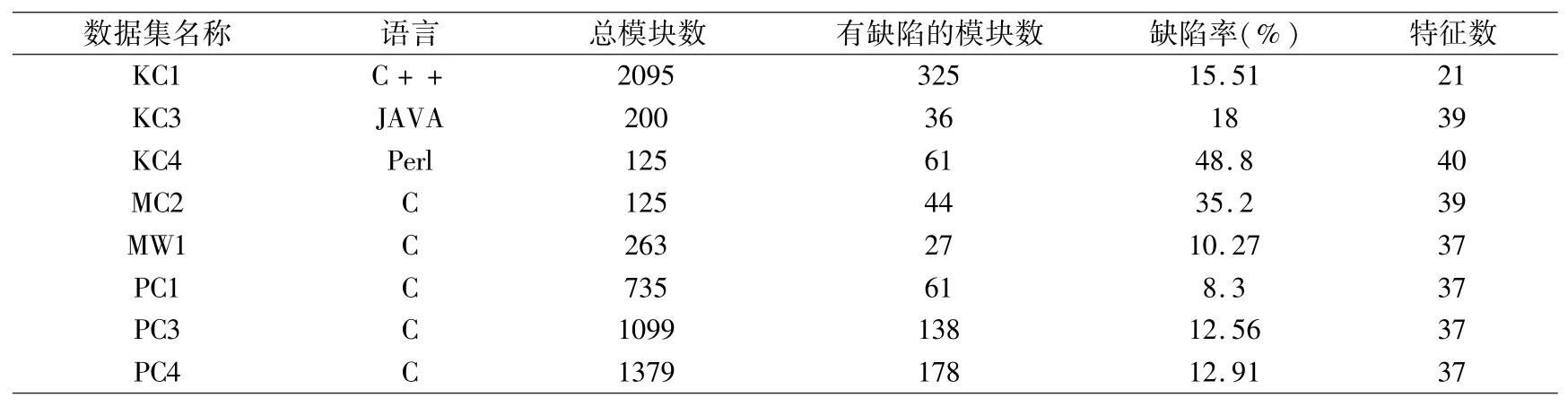
表2 NASA MDP数据集Table 2 NASA MDP data set
3.2 评估指标
为了证明本文方法的有效性,通过使用准确率、查准率及查全率这些通用指标进行比较.这些指标都是从混淆矩阵中推导出来的[11-12],混淆矩阵如表3所示.相关的定义如下:

表3 混淆矩阵Table 3 Confusion matrix
准确率表示模型所得分类结果中,预测与实际相同的测试实例与所有测试实例个数的比值,即

精确度也叫做查准率,表示模型所得分类结果中,被正确预测的正例与预测为正例的样本总数之比,即
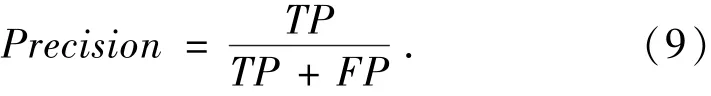
查全率表示预测正确的正例与实际容易出错的模块的比值,即

3.3 实验结果分析
表4 列出了基于改进后的QGA-BP和对比预测模型在8个数据集上的预测结果.
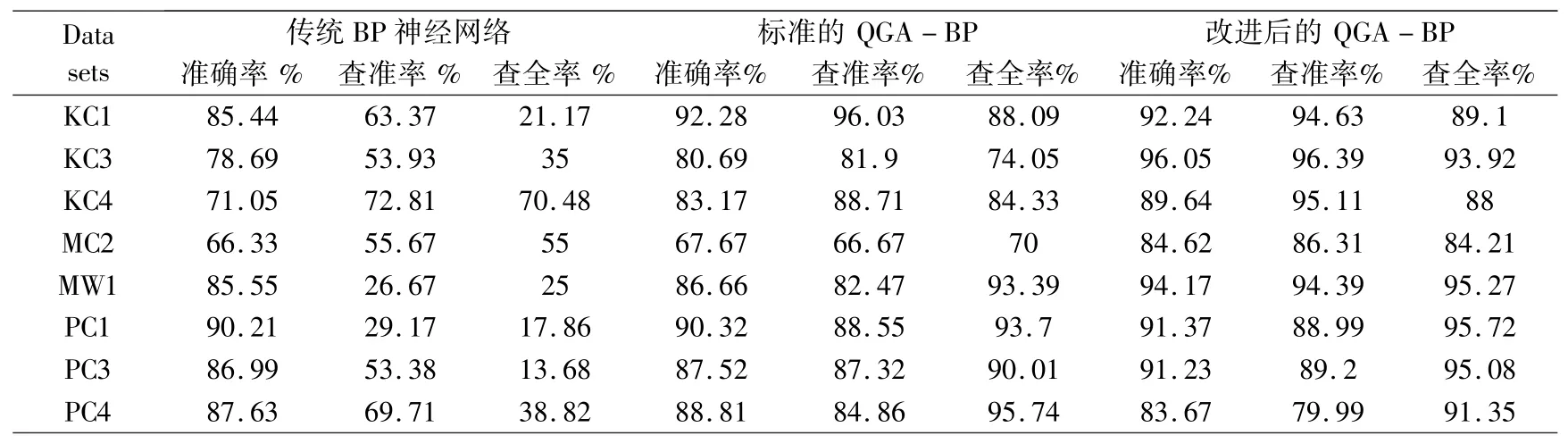
表4 不同模型的预测结果Table 4 Prediction results of different models

表5 改进后的QGA-BP预测性能增长百分比Table 5 Performance growth percentage predicted by improved QGA-BP
从表4的结果中可以看出,在6个数据集上准确率最高,平均值为90%.从表4可以看出,除KC1和PC4数据集外,该模型的查准率最高,分别为96.39、95.11、86.31、94.39、88.99和89.2(%).除PC4数据集外,查全率也最高,分别为89.1、93.92、88、84.21、95.27、95.72和95.08(%).如表5所示,改进后的量子遗传优化BP算法的预测模型,很大程度提高了准确率.与传统的BP神经网络相比,它在KC3、KC4和MC2数据集上提高了20%以上;与标准QGA-BP相比,准确率的值平均提高了7.5%.在查准率和查全率方面,本文提出的方法与传统的BP神经网络相比有了很大的改进;与标准QGA-BP相比,本文提出的方法在大多数的数据集上都有一定程度的改进.
在数据集KC1和PC4上,改进后的量子遗传BP模型和标准的量子遗传BP相比,出现了负优化,其原因是KC1和PC4都属于大规模数据集,标准的量子遗传BP已经达到比较理想的预测效果,优化后的量子遗传反而产生了负面影响.在改进后的量子BP模型与传统BP神经网络的对比中,出现了很多增长率的值超过100%的情况,其原因是这些数据集中的大部分都包含比较多的总模块数,传统BP神经网络在处理较大规模的数据集时表现不佳,而改进后的量子遗传的性能提高了很多.从实验结果可以看出,在大多数情况下,改进后的量子遗传算法优化的BP神经网络软件缺陷预测模型明显高于其他两种软件缺陷预测模型,提高了预测性能.
4 结论
本文提出的优化方法不仅能在一定程度上提高BP神经网络的收敛速度,还可以适当地防止陷入局部最优值.仿真实验结果表明,与传统BP神经网络和标准的QGA-BP相比,本文提出的缺陷预测模型在准确率、查准率和查全率方面均得到提高.但是,本文模型的预测精度仍有提升空间,后续会做进一步优化.
猜你喜欢
计算机仿真(2022年8期)2022-09-28 09:53:02
黑龙江工业学院学报(综合版)(2020年6期)2020-08-11 07:16:08
成都信息工程大学学报(2018年3期)2018-08-29 01:08:44
石油地球物理勘探(2017年2期)2017-11-23 06:02:04
中央民族大学学报(自然科学版)(2017年1期)2017-06-11 07:13:32
统计与决策(2017年2期)2017-03-20 15:25:24
电子元器件与信息技术(2017年4期)2017-03-08 02:15:59
中国塑料(2016年11期)2016-04-16 05:26:02
智能系统学报(2015年4期)2015-12-27 09:38:39
电脑与电信(2014年10期)2014-03-13 08:18:44
