
基于聚类的推荐算法综述
2021-06-06 13:09:22漆翔宇
西南民族大学学报(自然科学版) 2021年3期
殷 锋 ,曹 旭,漆翔宇
(西南民族大学 计算机科学与工程学院,四川 成都 610041)
目前,随着人们物质和精神生活的不断丰富,信息技术得到了迅猛发展,但与此同时也导致人们处于一个信息异常稠密的环境之中.信息的爆炸式增长主要源自两个方面.一方面,先进的存储方式和存储介质中学术科研成果不断落地到实际应用中,人们可以存储的数据总量正在以惊人的速度直线上升;另一方面,随着移动技术、大数据、互联网的诞生和普及,工作中产生的数据也呈飞跃式增长.二者既促进了信息的高速、多样、密集化传播,同时也使人们困扰于“信息过载”这一问题.在这种大背景下,信息存在过度冗余且种类繁杂、数量庞大,导致人们对所需信息的高效获取和利用变得异常艰难.也正因此,推荐系统应运而生,为用户在广袤的海量数据中精准有效地获取高质量信息.
推荐算法作为推荐系统的核心聚焦了研究人员的目光,取得了长足进展.文章就近年来推荐算法领域内尤其是基于聚类的推荐算法方向的高质量论文,探讨了推荐算法的主要分类、最新研究进展、聚类推荐算法步骤及不同处理方式并做出总结与展望.
1 推荐算法发展脉络
1992年,Goldberg[1]等人提出世界上第一个推荐系统Tapestry,目的是解决邮件超载的问题,该系统属于协同过滤算法.此后,推荐系统成为了一类备受瞩目的、具有实用性的学科而被广大的研究人员所青睐.
1.1 国内外发展历程
自Goldberg[1]等人首次提出推荐算法以来,很多学者在致力于推荐领域的发展和拓宽.我国率先对推荐领域展开研究的学者为清华大学的路海明[9]教授等人,在他们的研究中提出了“基于Agent的个性化主动信息服务系统”.
协同过滤算法作为应用最广泛的算法模型,目前已得到了深入研究,也取得了较大的进展.其中,具有代表性的研究有,2016年Hernando[3]等人提出使用矩阵分解方法;该方法作为协同过滤技术的重要手段,大大的降低了计算时间,但其仍受到“数据稀疏性”和“冷启动”的影响.为解决“数据稀疏性”问题,Lee K[4]提出了基于图的推荐算法;该算法是一种启发式方法,可以在推荐新产品时缓解稀疏性的影响,保持它们与用户的相关性.除上述两种方法外,Huynh[5]、Bellogin[6]、Chen[7]等人提出了使用KNN、归一化切割、交替最小二乘法等方法应用于协同过滤推荐中;这些方法均被用来生成准确的推荐列表,具有较好的工作性能.
除使用协同过滤方法之外,亦有学者提出对项目或用户自身的属性、特征进行分析完成推荐.曾春[8]等提出相比传统的矢量空间模型,利用用户在不同领域模型的概率对用户建模可以更好的表达用户实际兴趣.吕学强[9]等人考虑到用户兴趣变化构建用户长短期兴趣模型用以拟合,提出基于兴趣漂移模型的推荐算法.
考虑到协同过滤模型和基于内容推荐模型各有其优势及劣势,将两者组合起来是一种较好的解决方案,可以产生更好的推荐.2013年,Lu[10]等人将协同过滤和基于内容方法结合起来,有效地解决了数据稀疏性、可伸缩性和冷启动问题,同时相比单一推荐模型具有更高的准确率.部分学者采用自然启发算法,如Katarya提出使用布谷鸟搜索[11]和群优化[12],与混合推荐方法相补充,提高了算法的精度,并展示出了更好的结果.此外,Katarya[11]等发现,加入上下文信息(如反馈时间、位置)可以进一步提高算法的效率.Nilashi[13]等提出了一种基于降维和本体的混合方法,在一定程度上解决了可扩展性和稀疏性问题.
近年来,深度学习在推荐系统中所表现出深度特征学习、内在特征提取、数据提取等方面的优势,借助深度学习可以捕捉非线性的、非琐碎的用户/项目关系或数据库中存在的任何内在关系,引起了人们的极大兴趣.2007年,Salakhutdinov[14]等人提出了基于受限波兹曼机的推荐模型,这也是我们所知的第一个使用神经网络的推荐模型.Guo[15]等人引入了深度因子分解,通过深度神经网络获取高阶特征,之后使用因子分解机集成低阶特征交互.循环神经网络(RNN)技术可以有效解决数据稀疏性的问题,它通过存储之前的计算结果以及进行合适的数据建模来解决这个问题[16].
1.2 目前推荐算法主要类别
文献[17]把推荐算法划分为以下三类,这里亦赞同该分类策略.
1)基于内容/记忆的推荐算法:Schafer[18]在充分考虑项目和用户自身的诸多特征,对用户/项目进行特征抽取,构建用户特征模型/项目特征模型,为用户推荐与其最喜欢的项目相似度高的其他项目.
2)基于协同过滤的推荐算法:通过用户和项目之间的交互记录进行相似度计算,获得与目标用户/项目最相似的用户/项目列表,进而通过最近邻的评分记录进行推荐.文献[17]还将协同过滤推荐分为基于记忆的推荐算法(memory based)[19]以及基于模型(model based)的推荐算法[20].
3)混合推荐算法:为解决协同过滤推荐模型和基于内容推荐模型所面对的困境,研究人员提出将多种推荐技术相结合,以解决单一算法模型的不足.如:2005年,Adomavicius G[21]等人提出协同过滤与基于内容的四种混合策略:只对推荐结果进行融合;将协同过滤算法融入基于内容的推荐算法中;基于内容推荐算法融合进协同过滤推荐算法中;把两者混合进一个新的算法模型内.
1.3 三类推荐算法优劣比较
上述三种类别各有优缺点,为更好的理清它们相互之间的关联及各自优势,特将三类算法予以比较.三者的优劣势详见表1.
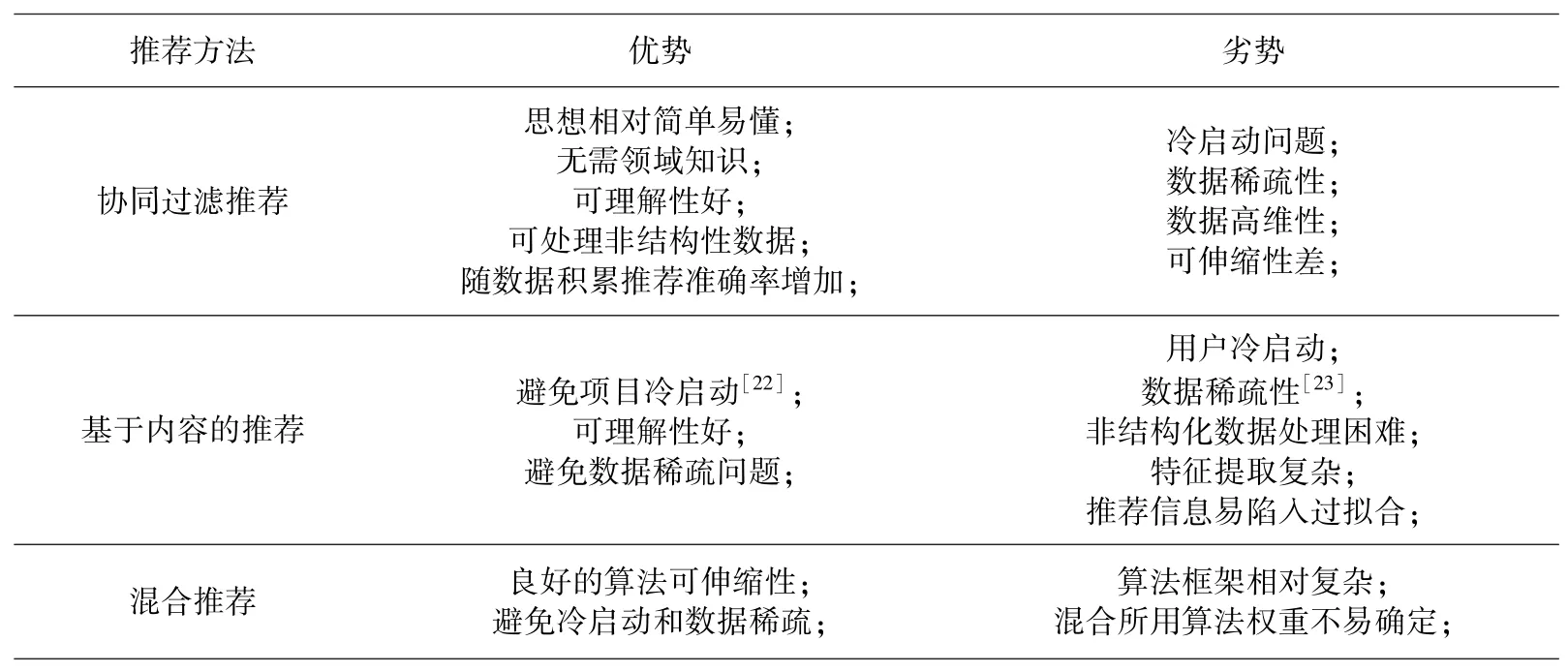
表1 经典推荐方法对比Table 1 Comparison of classic recommendation methods
1.4 协同过滤推荐的新发展-基于聚类的推荐算法
协同过滤推荐算法经过多年的发展,无论在相似度改进还是矩阵分解等层面都取得了较为丰硕的成果.但是随着推荐系统内数据量的增加,数据的“稀疏性”和“高维性”以及算法的“可伸缩性”和“实时性”等问题亟待解决.而聚类技术凭借其自身的特性,得到学者的关注和认可.聚类是将相似度高于一定程度的对象划分成有价值的、相似度高的簇(集合)的行为[24].通过将用户/项目进行聚类,可以实现在最小的范围内(簇集中)找到更多的邻居,可以有效地解决数据量过大所带来得算法伸缩性差、实时性差的问题.同时辅以矩阵分解技术可以有效地缓解数据“稀疏性”等不足.正因如此,基于聚类的推荐算法逐渐成为了协同过滤推荐算法下的一个重要分支.文章将在第2、3章重点对基于聚类的推荐算法进行描述和讨论,并对未来发展提出展望.
2 基于聚类的推荐算法
1994年,GroupLens[25]提出将不同的讨论组分区来解决数据量过大的方法,此时预测评分将只受同分区的Usenet讨论组影响,该方法即是最初将聚类思想融合进推荐领域的方法.1999年,O’Connor[26]等学者正式将聚类技术应用于推荐算法中,此后,将聚类引入推荐算法的相关技术不断得到发展.
2.1 聚类推荐算法的基本框架
从对1994~2021年期间发表的相关文献进行研究后,总结出一个典型的聚类推荐算法的基本框架如图1所示.
图1 中,基于聚类的推荐算法通常将用户-评分矩阵、项目内容或用户画像等原始数据作为算法的输入.若数据过于稀疏或维度过高则采用如矩阵分解[3]、潜因素模型[27]、主成分分析[28]等技术对数据进行预处理.预处理后再根据聚类目标的不同选择合适的算法完成聚类过程(详见2.2),生成用户/项目簇集.然后在生成的簇集内进行计算目标用户/项目的近邻集,通过近邻的历史交互记录生成推荐列表.

图1 基于聚类的推荐算法框架Fig.1 Framework of Clustering based recommendation algorithm
2.2 聚类推荐算法中不同的聚类目标
通过分析目前发表的论文来看,根据上述算法框架中聚类目标的不同,我们可将基于聚类的推荐算法分为“项目聚类”[29]、“用户聚类”[30]和“混合聚类”[31]等三种方式进行处理.
1)项目聚类
项目聚类是将项目划分为不同的簇集,利用簇集来缩小寻找近邻集时的计算量.2001年,O’Connor M[26]等首次将聚类技术融合进协同过滤推荐之中,将项目进行聚类之后在簇集中计算用户的近邻来完成推荐.袁仁进[32]等人提出基于兴趣和Bi-Kmeans聚类的新闻推荐算法,研究首先使用向量空间模型(VSM)对新闻文本向量化,采用带权关键词对新闻进行表达,并据此用Bi-Kmeans算法对新闻进行聚类,构建基于层次的用户兴趣模型,最后使用余弦相似度计算推荐结果.该方法获得了较为优秀的准确率和召回率,同时Bi-Kmeans算法相较传统K-means算法具有易收敛、聚类结果优秀等特点.苏庆[33]等人提出热门项目、冷门项目以及时间三种权重因子对相似度进行修正,同时使用模糊聚类算法避免聚类过程中出现“死节点”.Frémal[34]等人根据项目元属性进行聚类,由于项目具有不同的元属性所以被分到不同的类别中,使用加权策略将不同类别中的同一项目的预测评分进行综合完成推荐.
K-means算法作为聚类推荐常用的聚类算法,具有思想简单、可理解性好、易实现等优点,但是该算法存在中心敏感、易陷入局部最优等问题.针对上述困难,熊忠阳[35]提出利用粒子群算法优化K-means中心选择予以解决.Logesh[35]等人通过量子粒子群算法加以优化.除此之外,还包括兰艳[36]等人提出的综合时间权重改进聚类过程,Wang[37]等人提出的遗传算法优化K-means算法等方法.
2)用户聚类
用户聚类与项目聚类相似,区别在于聚类目标为用户.国内研究人员中,孟宪福[39]等首次将聚类技术应用到推荐中;郭弘毅[40]等通过重叠社区发现算法BIGCLAM[41]挖掘隐含的社区结构并与用户兴趣相结合继而实现两个层面的聚类.Chen[42]等考虑到群体智能的问题,从群组推荐角度出发,减少了为单独用户进行推荐时的计算量.文俊浩[43]等提出一种融合用户聚类和上下文信息过滤的矩阵分解推荐算法.文俊浩的算法选择活跃度较高的用户作为聚类中心,以用户评分相似度作为依据完成聚类,之后利用上下文信息计算每个簇中与目标用户相似的用户集合,由于添加上下文信息会进一步加剧数据的稀疏性和高维性,故采取矩阵分解来缓解该问题.文俊浩的方法相对传统的基于上下文的推荐算法具有准确率高、缓解数据稀疏的优点,但是没有考虑到对于不同的上下文可能对用户具有不同程度的影响的问题,所以有待进一步的研究.针对K-means算法的中心点敏感问题,文献[44]应用启发式思想确定簇集中心点.还有学者通过不同的优化算法从其他方面对聚类算法进行优化,如改进的蜂群优化算法[45]、花朵授粉优化[46].
3)混合聚类
由于数据集中用户与项目数据之间具有一定联系,无论是单独对用户还是项目进行聚类都会丢失另一维度的数据所蕴含的信息,进一步导致聚类效果不理想.因此,采用混合聚类有助于更全面的对数据进行分析以实现更准确的推荐.
针对数据的高维性和稀疏性,Shajarian[47]等利用潜在因素模型对数据分解压缩并聚类,实现了对缺省数据的合理预测;Gong[48]等利用用户聚类预测未评分项目的值解决数据稀疏,再利用项目聚类完成推荐.
同时,由于单次聚类的结果精确度仍然有限,采取多次聚类可以有效地实现对数据的高精度聚类.Nilashi[49]等首次实现结合两种不同聚类方法的推荐系统;吴湖[78]等提出针对评分模式聚类以及基于第一次聚类结果再次聚类的双重聚类算法,大幅提高了预测的效率以及推荐精确度;Xie[50]等人结合基于密度的聚类算法和K-means算法的优点完成双重聚类,并引入经济学理论中的效用剩余函数度量项目与用户之间的关系,该方法可以解决网页推荐中的新闻演化以及冷启动的问题.
另外,针对数据量日益增加的问题,李嵩等人[51-53]使用Hadoop或Spark等分布式技术加以解决成为了主流方法.
3 基于聚类的推荐算法研究趋势展望
当前,基于聚类的推荐算法已经有了很大的进展,在很多领域都得到很好的应用.但是仍然存在诸多问题和挑战.
趋势一:集成聚类
聚类算法是基于聚类的推荐算法中至关重要的一环,直接影响到近邻的选择是否精确和最终推荐结果的生成.但是单独某种聚类算法终究存在其不可避免的缺点和不足.借鉴混合推荐的思想将不同的聚类算法相结合或许是以后的解决思路之一[49].通过对多个聚类算法进行集成可以有效降低单一聚类算法生成的簇集结构与实际数据的结构不符的影响,同时进一步消除聚类时的不确定性.
趋势二:推荐攻击
推荐攻击是近几年来推荐系统领域新的研究内容,最初由Lam[54]等于2004年提出,攻击者通过向推荐系统中注入虚假的用户评分记录来干扰推荐结果的生成乃至迫使推荐系统停运.目前推荐系统研究方向主要聚焦在更高的推荐准确率上,对于推荐攻击的抵御相对少见.因此,如何将推荐攻击检测技术融合进现有推荐系统中或开发更加鲁棒的推荐算法将会是推荐领域下一步的研究热点.
趋势三:大数据环境下“并行”算法将大行其道
随着大数据时代的到来,计算压力明显增长,如何将现有的优秀的推荐算法并行化或开发新的并行推荐算法已经成为了必须要面对的问题[51].除此之外,大数据所带来的噪音也无可避免.如何精确的区分用户的主要特征以及辨别无意义噪音将会是推荐算法进一步研究的角度之一[38].
4 总结
推荐系统作为解决“信息过载”问题的有效工具,已经经过了近30年的发展,无论是在日常生活还是学术研究中都成为了不可或缺的重要组成部分.文章中讨论了各种重要的推荐算法,特别是基于聚类的推荐算法相关的研究内容、新趋势和未来方向,从而拓展该领域的研究视野,以期为即将从事或正在从事该领域研究的学者提供一些帮助.
猜你喜欢
科学大众(2020年23期)2021-01-18 03:09:08
成都信息工程大学学报(2019年4期)2019-11-04 00:56:02
阅读与作文(英语初中版)(2019年8期)2019-08-27 03:59:25
汽车观察(2019年2期)2019-03-15 06:00:50
小学生学习指导(低年级)(2018年11期)2018-12-03 05:05:00
电子测试(2017年15期)2017-12-18 07:19:27
中国卫生(2016年5期)2016-11-12 13:25:26
现代防御技术(2016年1期)2016-06-01 12:13:27
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
