
基于生成对抗网络的图像着色技术的研究
2021-05-30 10:35兰胜杰江柏霖
河北建筑工程学院学报 2021年4期
岳 杰 兰胜杰 江柏霖
(河北建筑工程学院,河北 张家口 075300)
1 引 言
近年深度学习在图像识别和图像分类管理以及图像处理技术方面风靡一时,神经网络的使用远远大于传统算法,而使用深度学习神经网络对黑白和灰度图像以及老照片的色彩恢复也成为热点研究之一.目前手工上色黑白图像需要花费很大的时间和人力成本,并且上色的效率和上色的效果不是很高,然而借用神经网络上色可以对黑白和灰度图像以及老照片进行批量处理着色,在节约时间人力成本的同时也提高了黑白图像的可塑性以及上色后的视觉冲击力.本文的实验技术基于14年提出的GAN模型[1]对黑白和灰度图像进行着色处理,该模型主要包括发生器G(Generator)和鉴别器D(Discriminator)两个主要部分,其中G的常见结构也看作一种特殊的卷积操作,即转置卷积,生成器的目的是用来拿到图像的特征分布内容,生成图像,通过可学习方式使特征图增大.D的结构是卷积神经网络,变相可以当作一个二分类器,区分输出图像的真假,损失数值.在输出端给出判别概率.该模型的核心就是这两部分主体互相对抗、互相优化然后互相再对抗[2],G产生图像欺骗判别器D,而判别器去对该图像进行判断真假,如果判断成功则G优化,以此迭代互相优化,达到动态平衡,直到整个模型可以输出与原始数据相差不多的图像.
本文根据GAN的网络特点优化超参数、网络结构以及激活函数等,将彩色图片数据集进行像素归一化调整,并产生对应灰度数据图像,将模型预训练操作,在训练学习的同时对测试图像进行着色处理.
2 生成对抗网络的原理
生成对抗网络由两个神经网络互相博弈互相优化的过程[3],将随机噪声和图像输入生成器模型生成对应图像,然后将生成的图像和原始图像一起输入判别器模型进行判断,输出一个真实概率,标准GAN结构图1如下所示:
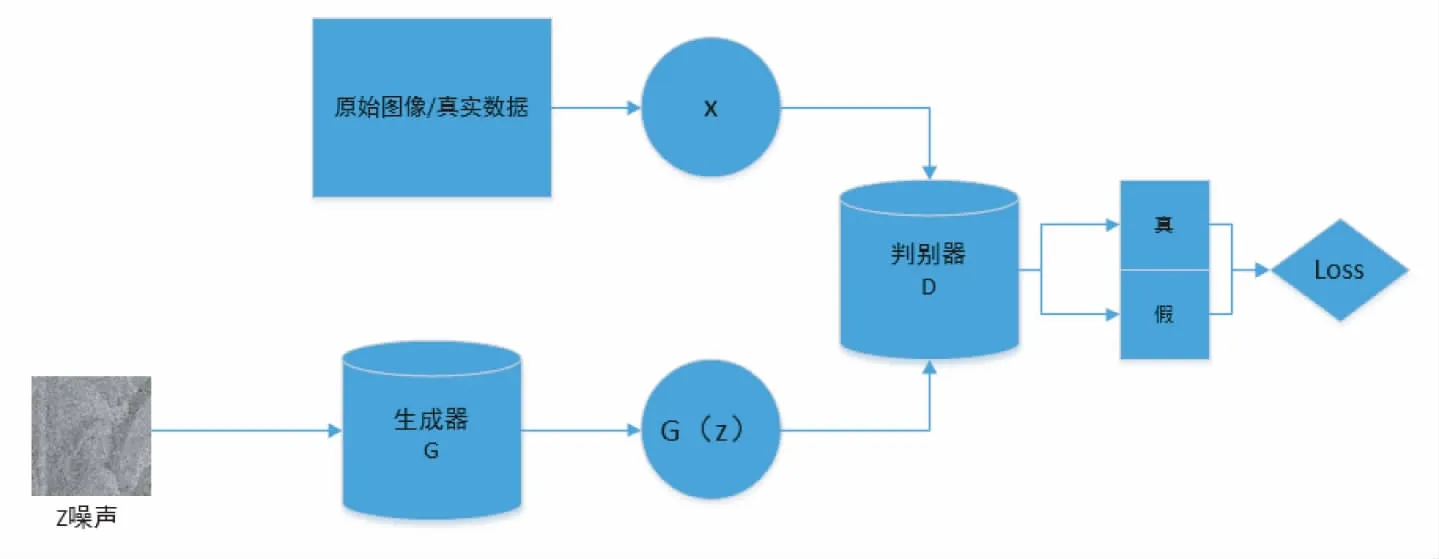
图1 标准GAN结构图
两个主要板块在互相博弈互相欺骗并互相优化的过程中整个模型会趋于平衡和稳定[4],函数表达式如下(1):
min maxV(D,G)=Ex-Pdata(x)[log D(x)]+Ex-Pz(z)[log(1-D(G(z)))]
(1)
我们在训练的过程中发现生成对抗网络GAN的训练稳定性很低,原始GAN模型的这两个G和D只要能满足可以拟合产生和辨别的函数便能用来当作整个模型的两大板块,但是本文选择擅长用来拟合判别函数的神经网络分别作为G和D,但是常常D太强,G太弱,我们需要分别对D和G训练,必要的时候可以把D学到的特征直接传给G,变成一种新的目标函数.
3 网络结构
该网络主要包含两大部分,生成器G的模型和判别器D的模型共同组成了这个网络架构,大多数图像上色技术依旧还是会融入一种编码器/解码器的网络结构[5],这个网络结构的好处在于原始数据和结果数据可以一起分配图像的像素数据和位置数据,并可以完全经过整个网络,该网络结构将原图像的信息压缩提取精髓再通过解码器来解压图像信息,然后进行对比测出误差反向传递,编码器网络结构示例如图2所示,通过压缩原有信息提取最小特征集合并放入提前训练好的神经网络,编码器起到了给特征属性降维的作用.
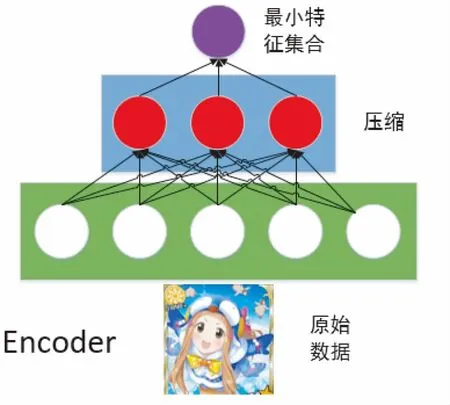
图2 编码器网络
解码器Decoder在训练时将最小特征集合解压成重构的原始信息,相当于一个解压器,与GAN中的生成器类似,结构示例如图3所示:
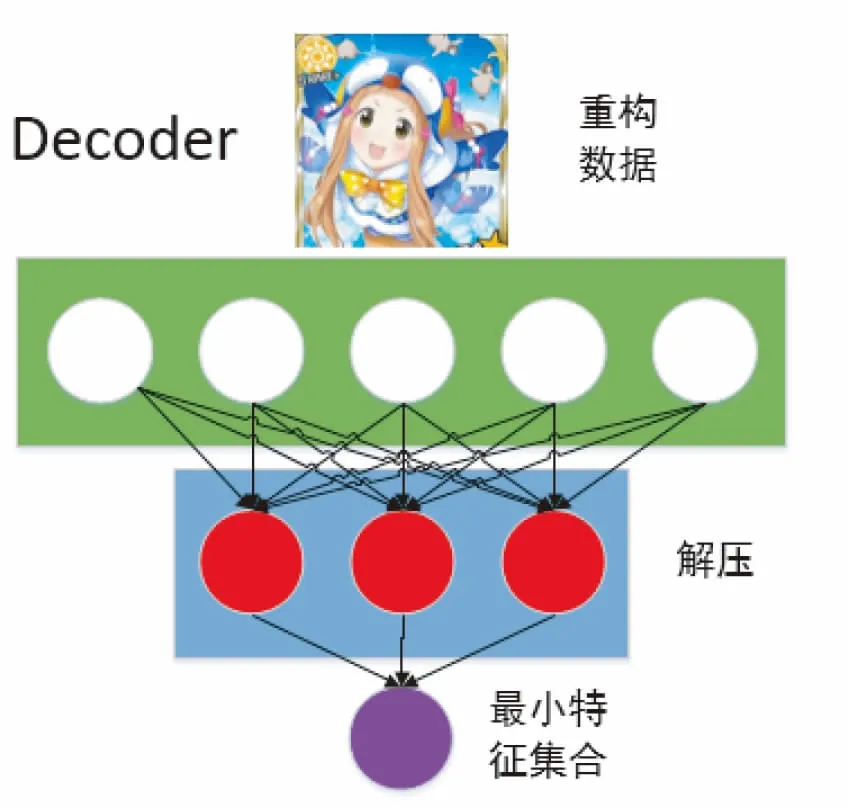
图3 解码器网络
3.1 生成器模型
本文生成器G的模型采用了基于FCN(Fully Convolutional Networks)的语义分割网络结构U-net[6],如图4所示,该网络结构包含上采样和下采样,上采样通过下采样的信息汇合输入信息还原图像精度,在我们对整个网络的编码过程中会对每一个块分别进行编码,而每一个块编码使用的方法结构是卷积层到Batch Normalization层再到带泄露修正线性单元激活函数层,用来解决在训练过程中梯度爆炸和训练速度过慢情况的发生.而在解码部分我们也分别对每一块进行解码,采用的方法结构是反卷积层到Batch Normalization层最后激活函数层可以采用Dropout激活函数或者是修正线性单元激活函数.但是有区别的是最开始三个块采用的是Dropout激活函数层,在这后面的块区都采用了修正线性单元激活函数.与此同时,每个编码区域的块输出都指向了和它本身的解码区域的块连接,这个网络结构在图像的细节处理方面能有一定的提升.

图4 U-net网络结构
3.2 判别器模型
针对D,我们将判别器换成了全卷积网络,也被称为patchGAN.把判别器D的图像区域分割成一小批一小批来处理,把整个图片分割成n2个批次,然后再反复操作,再对每个区域操作以上步骤.将判别器换成了全卷积网络,其中每一块包括了Conv层、Batch Normalization层、修正线性单元激活函数层.本文输入图像数据集都是256*256像素图像,我们将它们分为每70*70作为一个块进行的.这个方法可以使实验结果效果更加明显,判别器D的模型如图5所示:
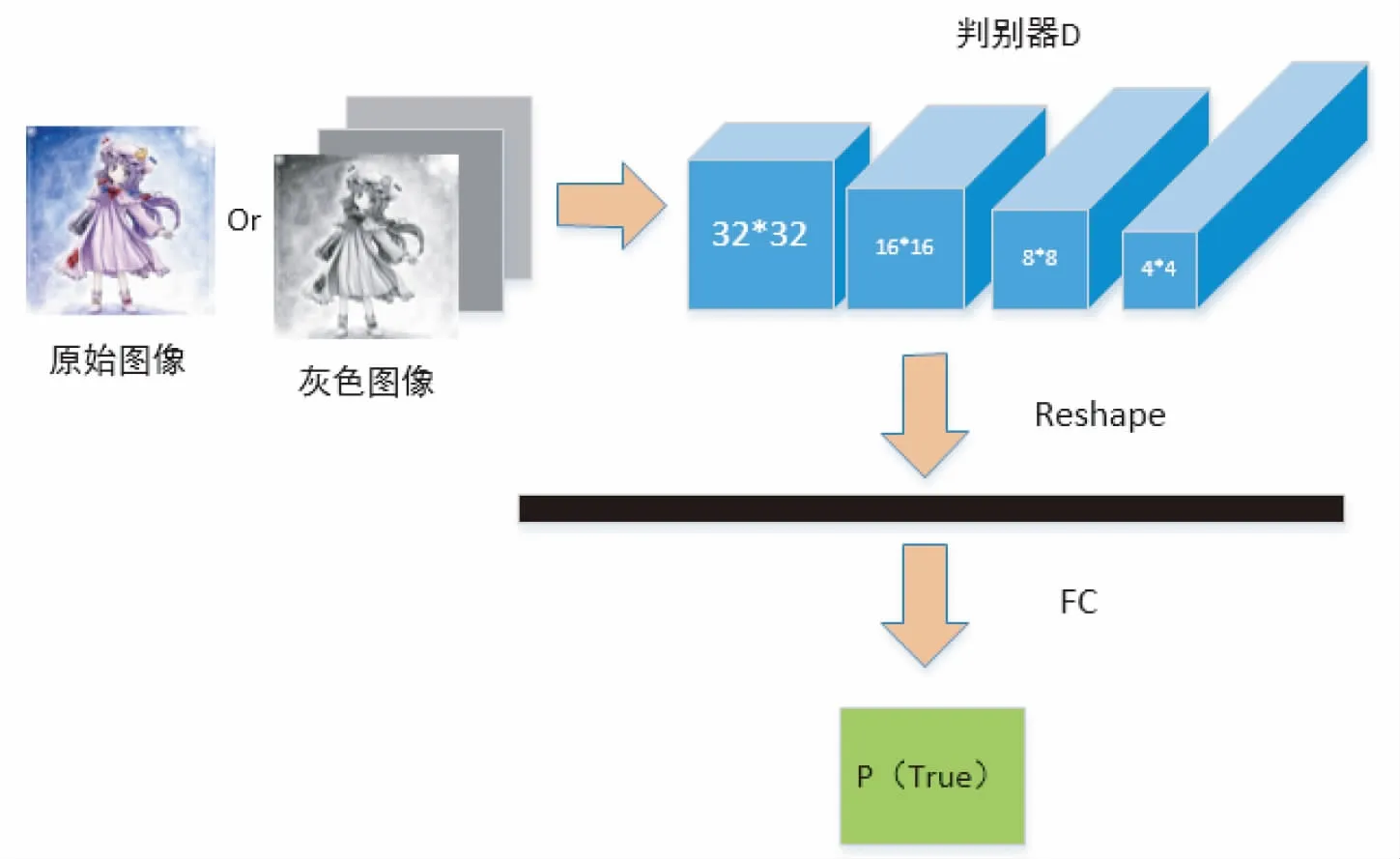
图5 判别器D模型
4 实 验
4.1 实验平台与数据集
本文的模型训练过程中计算的需求量比传统的模型同比增加,使用CPU来实验训练时间为33小时,相对于CPU而言,使用图形处理单元GPU训练会很大程度的缩短时间提高效率.实验平台为Windows10 64位操作系统,GPU使用NVIDIA GTX2060,16G内存进行训练,所使用的框架为Pytorch 2.6,所需要的Python库有numpy、scipy、Pytorch、scikit-image、Pillow、opencv-python.
本文训练所使用的数据集主要是漫画图像,该数据集使用网络爬虫从漫画素材网站seeprettyface上抓取了28059张图像,使用resize_all_imgs.py对所有图片批量修改到256*256像素尺寸,部分原始图像如图6:

图6 部分原始图像
再使用grey_imgs.py对该数据集生成对应黑白和灰度图像数据,效果如图7所示:

图7 生成黑白效果图
4.2 实验超参数选择
本文实验所使用损失函数为GAN原始损失函数,学习率为0.0001且保持固定,衰减权重为0.0001,更新权重0.1,每次迭代次数10000次,epoch设置为400次,并采用SGD法,针对GAN容易崩溃的情况,本文实验应用修正线性单元作为激活函数,求解器类型为ADAM,动量参数设置为0.5,λ为100.
4.3 模型训练效果
我们采用提前训练完成的网络模型对测试数据集的28059张黑白和灰度图像进行着色处理,CPU训练耗费时长30多小时,GPU耗费10多个小时,本次训练效果虽没有达到预期图像结果值,但是较传统方法有了很大改变,相较于传统图像上色算法,本文算法优势在于训练参数增加导致图像细节上色方面处理更优,在图像边缘区域上色均匀,边界连接处色彩区分明显.同时,上色效果相较于传统GAN模型上色产生的噪点要少,尤其对于大背景的图片上色效果不错.如图8为训练好的模型对测试数据集上色效果图,左图为灰度图片,右边为上色效果图.

图8 训练效果图
但是由于本实验模型是基于传统GAN模型优化而来,生成对抗网络极易崩溃,由此在训练测试过程中可能呈现出部分过拟合状况,导致着色效果不佳,生成部分失败图片,如图9所示:

图9 失败案例
5 结 语
本文的实验优化并改进了一种基于生成对抗网络的黑白和灰度图像着色技术,在常规GAN模型基础上修改优化参数提高图像上色速率和视觉效果.在训练好的模型上,黑白和灰度图像可以批量着色,模型简单,没有太复杂的预处理过程,在超参选择上略优于传统GAN上色方法,效果略优,但是这个方法大体基于传统GAN结构设计,训练不稳定,极易崩溃,所以可以修改生成对抗网络中的生成器G与判别器D,需要针对D和G分别加入LSR用来防止过拟合现象的出现,增强泛化能力.本文采用U型结构生成器G来保留边缘信息,构建两者映射关系来进行交互训练.可以发现,在整个训练的进程中,由于GAN的生成器太过脆弱,图像边缘信息不易保存,网络架构不稳定,优化超参改变生成器和判别器模型,防止过拟合现象的出现尤其重要,但是本实验方法上色效果优于传统GAN模型架构,给受众群里的视觉冲击力不错,处理细节良好,因为本次实验技术的训练数据集无一不是低分辨率,在这个技术之后还要使用高分辨彩色图像对应的黑白图像数据集来完成更加高效的优化.
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
今日农业(2021年9期)2021-11-26
天津医科大学学报(2021年1期)2021-01-26
西安邮电大学学报(2020年1期)2020-12-17
今日农业(2020年16期)2020-12-14
中国信息技术教育(2020年2期)2020-02-02
计算机系统应用(2019年9期)2019-09-24
电影(2018年10期)2018-10-26
军事运筹与系统工程(2016年4期)2016-07-10
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
