
基于多层次划分的服装产品族构造方法
2021-05-25 21:27:59杨怡洁陈敏之
浙江纺织服装职业技术学院学报 2021年4期
关键词:BP神经网络
杨怡洁 陈敏之

摘 要:服装生产是典型的多品种小批量模式,为减少服装生产中产品内部多样性的影响,实现用工业化方式进行个性化生产,提出了基于多层次划分的产品成组分类方法。通过服装构成分解和成组技术,基于特征编码构建适用于服装生产的产品信息模型;采用改进的K-means聚类算法对同一品类下不同款式的服装进行产品族划分,并引入有效性评价指标CSI确定最佳聚类数,降低人为因素的干扰;最后采用BP神经网络实现新产品的族匹配。通过实例验证,提出的方法能有效构建相似件的产品族并进行新产品归类,有助于组织精益化生产,实现服装生产的快速反应与柔性化。
关键词:成组技术;分类编码;k-means聚类;BP神经网络;产品族
中图分类号:TS941 文献标识码:A 文章编号:1674-2346(2021)04-0018-07
多品种小批量短周期的市场环境下,降低产品内部多样性,实现服装生产的快速反应是中小型服装企业应对客户个性化需求的有效途径。成组技术(GT)通过分析相似特性,将产品或零件基于一定的标准进行归类形成零件族,并以此为基础采取类似方法进行生产组织管理,使得款多量少的生产模式转化为接近大批量的生产模式,从而提高生产效率。
服装成组技术目前多应用于产品的快速设计与开发,程碧莲等通过服装款式结构分析,进行模块化设计,构建旗袍纸样产品族,验证了个性化定制服装设计的可行性。[1]产品族设计的研究并不完全适用于生产,不同款式的产品可能拥有相似工艺,纯粹基于结构特征,会导致标准过于严格、形成过多产品族,使得通过聚类提高批量生产的效果不够明显。[2]机械生产中成组技术的研究较为成熟,殷胜昔等通过零件或机器成组划分产品族,基于结构和工艺特点,提出了适用于空空导弹零件的成组编码和分层次划分产品族的方法,为建立精益单元提供了基础。[3]郑华林等面向工艺规划提出了基于相似系数的零件族构造以及建立了基于累加矩阵的模式识别方法,实现了零件的分类与归类。[4]由于服装不同于机械零件,其产品和生产工序缺乏标准性和通用性,不能简单地从加工工艺进行分类;同时,服装制造过程复杂,设备简单但人工参与程度高,同一设备可以完成多种工艺,难以单纯进行设备成组。因此需要探寻适用于服装生产的成组技术应用方法。
服装整体工序流程长、工艺复杂,难以直接进行成组分类。本文通过将服装产品按部件、款式进行分层次解构,基于P-R分析法分析部件工艺路线的相似性,形成典型款式部件组,以此为基础进行服装特征的分类编码,引用改进的K-means算法对产品编码矩阵进行产品族划分,并引入有效性指标CSI对聚类结果进行评价,构造能有效识别产品特征的BP神经网络,最终实现已有产品的成组划分和新产品的匹配,为服装快速反应生产的组织提供参考。
1 基于部件成组的服装分类编码
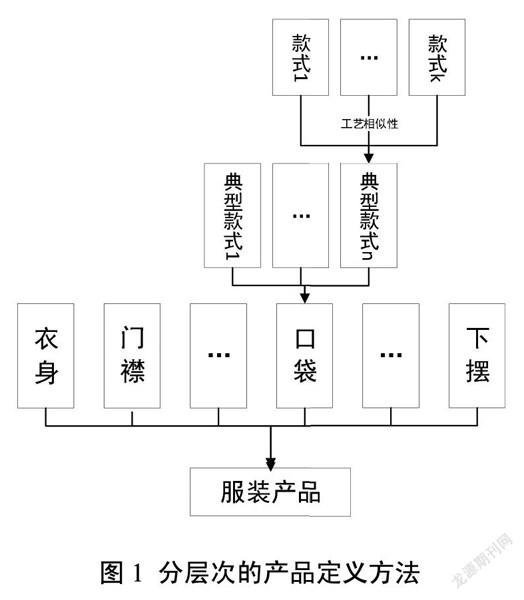
通过分类编码构建适用于生产的产品信息模型是实现计算机自动划分产品族的前提。不同款式的服装虽然在造型上千差万别,但作为组合式结构的产品,服装基本结构部件大同小异,整体工艺流程具有高度一致性,生产工艺的改变源于部件款式的改变,因此成组工艺的对象应为通用的服装部件。以女式衬衫为例,其构成可以分解为衣身、门襟、衣领、衣袖、下摆、口袋模块。对不同部件模块内的不同款式进行相似性分析,形成典型款式部件组,并将其定义为区分产品的特征属性,据此设计产品编码的码位表。(图1)
1.1 基于工艺特征的部件成组
应用P-R分析法根据现有零件的工艺路径,判断其在生产加工上存在的相似之处,由此进行零件成组。[3]
相较于机械加工,服装生产中的部件裁片可视作待加工的零件,缝制环节可以视作零件的组装配置。通过市场调研和相关资料收集,选择目前广泛生产和流行的款式,通过P-R法对模块内不同款式的部件进行分析,根据工艺特征进行部件成组。
1.1.1 定义工艺相似性
通过服装制作工艺表达产品的工艺路线,按照类型可分为车缝、熨烫、特种、装饰工艺这四大类,各大类下可细分多个小类,由于手工作业较为灵活、受限很小,不纳入工艺路线。编号见表1。
设部件的细分工序集合为{a0,b1,…,c3,…,d2,… },根据图论定义工艺路线的表达方式为若干节点相连的一条路径,每个节点即该道工序,以花边立领为例,其工艺路线见图2。
由此,两个部件的路径相似可视作工艺流程相似,同时考虑工艺类型和流程长度,将路径相似度定义[5]为下式:
式中:Gij代表部件i關于部件j的工艺相似度,Gij≠Gji;Sij代表部件i、j工艺路线图中相同的节点数;Ni代表部件i的总节点数。
1.1.2 基于相似度指标的部件成组
根据工艺路径,定义部件之间的工艺相似度指标,用以划分部件组。指标如下:
① 完全不同:Gij=0,说明两个部件的工序完全不同,无法成组;
② 完全相同:Gij=1,说明两个部件所有的工序和数量完全一致,可以成组;
③ 部分相同:Gij∈(0,1),说明两个部件的工序部分相同,生产上有一定参考价值,成组时需根据实际生产情况确定阈值k,Gij大于k即可成组;
④ 包含关系:Gij=1,Gji∈(0,1),说明部件j的工艺流程包含部件i的所有工序,且比部件i更复杂。以翻领和翻立领为例,翻立领的工艺即在翻领的基础上加上领座的制作及领座领面的组合,如图3所示,前4道工序完全一致,因此Sij=4,Gij=1,Gji=0.57,此时可将部件i划分入部件j的组内,同时也可用部件j代替部件i,以便与其他部件进行相似度比较,进一步成组。
1.2 基于款式特征的产品编码
良好的编码规则应具备实用性、完整性和可扩充性,以表述、存储零件信息。款式面料规格等因素影响实际生产,服装款式相同,仅从工艺角度出发,认为生产属于相同重复。[6]因此在形成服装部件组的基础上,基于款式特征进行码位设计,服装产品聚类的基础是同一品类,因此将产品编码包含属性码、部件码:属性码包含性别、着装位置及品类,不同品类的服装具有不同的部件构成;部件码又可细分为款式码,涵盖不同的典型款式。以女式衬衫为例,其编码体系如图4。
2 基于K-means算法的产品族划分
在产品编码的基础上,聚类分析能定义产品间的相似性,构成各部件款式属性相似的产品族,并尽可能用相同的制造方法加工制造,实现高效生产。[7]
2.1 聚类属性的权重确定
产品的编码中,列向量是不同属性的体现,产品集合则是多维的空间,产品的聚类需经过综合。[8]由上文可知,影响服装产品聚类的属性是部件的款式特征,首先确定聚类指标,以女式衬衫为例,产品聚类影响指标见图5。
不同部件模块对整体的影响程度不同,因此需要确定相应的权重值,但每次待聚类的产品情况不同,无法用单一加权计算,例如待聚类的产品集合中,衣领款式远远多于其他部件款式,此时衣领对产品的影响程度较高。
熵值法基于数据的不确定性判定权重,熵越小,权重越大。若某项指标的样本值差距较大,则该指标对于被评价对象的作用较大。[9]
假设产品集中有n个对象,每个对象有p个特征指标,利用熵值法确定的权重方法如下:
(1)构建原始数据矩阵:
(2)计算各项指标值的权重:
(3)计算第j项指标的熵值:
(4)计算各项指标的权重:
由此,可以得到指标的权重向量W=(w1,w2,…,wp)。式中0?i?n,0?j?p;xij是第j个指标在第i个产品中的指标值;aij是第j个指标在第i个产品中指标值的权重;ej是第j个指标的熵值,k=1/lnn;Wj是第j個指标的权重。
2.2 基于编码的K-means聚类
K-means算法是通过度量样本关系,将给定的样本集划分为k类。最小化类内样本点距离,最大化簇间距离。相似度的定义是聚类的关键[10],经典的K-means算法采用欧氏距离进行相似性度量,但由于欧氏距离将目标的不同属性(指标)等同看待,不符合服装产品的聚类要求,因此本文采用加权的欧氏距离度量相似性,误差平方和作为准则函数以评估聚类质量。
用产品集编码矩阵作为聚类的数据结构。设待聚类的产品集合U有n个对象,令U={X1,X2,…,Xn},每个对象具有p项属性,即编码的部件码位,Xi=(xi1,xi2,…,xip),产品集合编码矩阵可表示为:
式中xif 代表第i个产品的第f位属性。
采用加权的欧氏距离进行产品聚类的相似性度量,由2.1可知该产品集合的权重向量W,对于Xi=(xi1,xi2,…,xip)和Xj=(xj1,xj2,…,xjp),其欧氏距离计算如下式:
2.3 产品族聚类有效性评价
传统的K-means算法需要提前设置聚类数且难以获取最优结果,由此引入有效性指标判定聚类效果,确定最佳的聚类方案,以期降低人为因素的影响。本文采用基于紧凑度和分离度的CSI指标进行聚类结果评价,簇内紧凑,簇间分离即是有效的聚类结果。[11]改进的K-means聚类算法流程见图6。
假设产品集合U={X1,X2,…,Xn}被划分为k个彼此独立的类簇:{U1,U2,…,Uk},类簇Ui包含的产品数为|mi|,各簇类中心为{c1,c2,…,ck},产品集U的全局中心点位为c。类内紧凑度T、类间分离度S、有效性指标CSI的定义为下式:
当CSI指标取得极大值时,聚类结果为最优。
2.4 算例
根据上文给出的基于工艺特征和款式特征的产品编码方法,以某品牌25款女式衬衫为研究对象,经P-R法进行工艺分析后,进行产品编码,通过实例验证基于编码的K-means聚类算法对产品族划分性能。产品集编码见表2。
知聚类数k的较佳范围为,n为待聚类的对象数,在实际应用中,聚类数的范围可根据生产情况与企业需求制定。本例选择k∈[2,5]的范围,经过2.2提出的基于加权欧氏距离的K-means改进算法进行数据集的迭代,得到聚类结果,再由2.3提出的有效性指标CSI进行结果评价,输出最佳聚类结果。
可知当CSI指标值达到极大值时,即为最佳聚类结果,由图7可知,25个女式衬衫产品的最佳聚类数为3,聚类结果为{9,10,17,22}; {1,2,4,6,7,8,11,12,14,15,16,18,19,21,23,24,25}; {3,5,13,20}。经产品款式图和工艺再分析可知,各类簇内的产品在各个部件模块中有极大的相似性,特别是领子和袖子的造型,对于产品聚类的影响较大,结合实际生产可知,女式衬衫生产流程中,工艺变化最为复杂的正是这几个部位。因此,按划分的产品族对不同款式的服装集中生产,减少了产品内部多样性,实现了用工业化的生产方式进行个性化的生产。
3 基于BP网络的新产品匹配
完整的产品族构造方法不仅要对现有产品进行聚类形成产品族,也要具备识别新的产品,并将其划分至已有的产品族的功能。BP神经网络是有监督的学习模型,通过大量的学习和存储相关映射关系[12],实现期望。其优势在于能充分考虑数据自身特点且有较强推广能力,由此提出基于BP网络的新产品匹配方法,通过实例表述新产品的匹配过程。
3.1 BP网络创建与训练
给定输入样本和期望响应,运用MATLAB函数newff创建前向型BP网络并进行仿真,输入输出神经元由相应矩阵维数决定。
3.1.1 定义网络的输入矩阵P与期望响应T
根据2.4得到的产品族聚类结果,在每个产品族中随机选取4个对象,构成编码矩阵,经转置后作为输入矩阵P;期望响应即产品聚类结果的关系矩阵,采用0-1矩阵表达,矩阵的列代表各产品,行代表族类,1代表该产品属于该族。
3.1.2 BP网络的训练
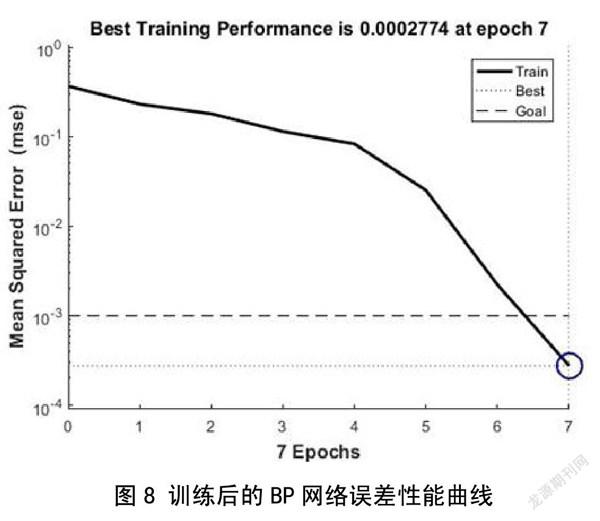
标准的梯度下降法在调整过程中会发生振荡,导致不稳定和收敛速度慢的问题,本文的网络训练采用带动量的梯度下降算法,避免陷入局部最小点。设定学习算法为trainlm,训练次数为3000,训练精度为0.001。
训练之后得到的网络误差性能曲线如图8,可知经7次迭代之后误差值以达到训练精度;通过比较神经网络输出的仿真结果与期望响应得到误差矩阵,可以看出二者之间的误差值极小,说明经过训练的BP神经网络完成了输入输出样本的映射。
3.2 BP网络的匹配
利用现有产品集中的某一产品与训练好的神经网络进行匹配,以24号产品为例,进行产品族的划分,输入向量X为该产品的编码数组:X=[4,6,3,3,2,1,1]。BP神经网络的输出结果为:Z=[0.0304; 0.9885; 0.0039],可知该产品与第二类产品族的匹配度达到0.9885,因此被划入该类簇。由上文可知,24号产品归属于第二产品族,由此证明基于BP网络的产品族匹配方法是合理有效的。
4 结论
(1)基于工艺路线相似性对服装部件成组,实现了部件的典型款式分类,将部件作为产品的特征属性,进行分类编码构建服装产品信息模型。针对传统的K-means算法相似性度量的不足以及无法确定最佳聚类数的问题,利用加权距离和有效性评价指标CSI进行改进,最终用于服装产品族的划分;
(2)产品族构造不仅要对现有产品进行划分,也要对新的产品进行族匹配,基于BP神经网络处理归类问题,尽可能降低在产品分类时人为因素的参与影响,实现新产品的快速匹配。经实例验证,由已完成划分的产品族信息训练的神经网络能对新产品进行高效准确的识别,说明结合聚类算法和BP网络的方法对实现产品匹配具备有效性和合理性。
参考文献[1]程碧蓮,刘正.以旗袍纸样为例的模块化设计方法[J].毛纺科技,2020,48(10):46-51.
[10]蘇迪,宋海草,陈永成.基于模糊聚类K-means播种机焊接零件的编码分类[J].石河子大学学报(自然科学版),2016,34(02):238-243.
猜你喜欢
商情(2016年43期)2016-12-23 14:23:13
软件导刊(2016年11期)2016-12-22 22:01:20
软件导刊(2016年11期)2016-12-22 21:53:59
电子技术与软件工程(2016年20期)2016-12-21 10:42:59
科技视界(2016年26期)2016-12-17 17:57:49
考试周刊(2016年21期)2016-12-16 11:02:03
现代经济信息(2016年27期)2016-12-16 01:26:55
价值工程(2016年30期)2016-11-24 13:17:31
商情(2016年39期)2016-11-21 09:30:36
数字技术与应用(2016年9期)2016-11-09 22:37:01
