
一种结合通道注意的图像描述方法
2021-05-20 01:03崔雨涵张世卓
北京信息科技大学学报(自然科学版) 2021年2期
崔雨涵,刘 琼,张世卓
(北京信息科技大学 自动化学院,北京 100192)
0 引言
图像描述生成的目标是将视觉信息转化为文字或某种语言的单词序列,属于多模态学习的典型问题,可应用于图像检索[1]、图文自动转换等领域,帮助视障人士还原视觉信息等,有效推动社会和谐与智能化的发展。
随着深度学习技术的发展和公开数据集的发布,图像描述算法发展迅速,研究者们在一定程度上解决了传统方法中的一些弊端,如生成句子结构单一、语义不足和理解偏差等等。目前主流的模型是端到端的训练方法。Wu等[2]借鉴机器翻译任务中的“编码器-解码器”思想将其引入图像描述生成任务中,首先采用多层深度卷积神经网络对图像进行建模,把图像的特征信息编码,然后将循环神经网络(recurrent neural networks,RNN)作为解码器,将文本信息与图像信息映射在一个循环神经网络中,输出描述句子。此外,Aneja等[3]用卷积神经网络作解码器,缓解RNN的梯度消失问题。
高质量的图像描述语句需要满足:语句通顺,符合人类表述习惯;描述准确,能真实地反映图像内容;描述细致,能完整地反映图像中的重要信息。要得到高质量的图像描述语句,关键之处在于让图像特征可以表示更多的图像信息,通过捕捉图像中所要描述的对象及其属性特征,并与自然语言相对应,减小图像信息和文本信息之间的异构鸿沟。最常见的方法是利用注意力机制模拟人类观察、理解图像的过程,提升图像特征的描述能力。
Xu等[4]受人类大脑的启发,首次将注意力机制引入,对“编码器-解码器”模型进行改进,大大提高了模型的效果。基于注意力机制的研究不断涌现,推动了图像描述生成模型的发展。Hu等[5]提出了一种基于通道关系的注意力模型,用平均池化对图像特征进行空间聚合,建模通道之间的相互依赖关系。通道维度的权重,可以表示图像中对象或属性之间的依赖关系,也可以表示图像的哪一部分更值得关注。但是,仅用平均池化对图像特征进行空间聚合会损失大量空间信息,导致最终的描述语句不精确,在图像复杂的情况下容易出现错误。
为了更精确细致地描述图像,本文提出一种新型的通道注意机制,用平均池化、最大池化、随机池化分别对图像特征进行空间聚合特征提取,可以得到具有丰富空间信息的通道特征。通过建模通道之间的相互依赖关系,挖掘不同通道对注意力机制的贡献差异,自适应地重新校准通道方向的特征响应。比如,当图像中有多个描述对象时,通过通道注意机制,可以把多个对象在图像特征图中所对应的通道进行关联,学习它们之间的关系;当一个对象有多个属性时,通道注意机制也可以表示多个属性之间的关系。通过学习图像特征图的通道维度的权值,进一步发挥注意力机制在图像特征提取网络中的作用,以减小图像信息和文本信息之间的异构鸿沟。实验结果显示,与传统方法相比,本文方法生成的图像描述细节精致、语句通顺。
1 本文方法
1.1 通道信息
众所周知,注意力在人类视觉感知中起着重要作用,而注意力机制就是通过模仿人类视觉感知的工作模式设计的[6-7]。在图像描述生成任务中,注意力机制可以模仿人眼在观察图像时对不同区域的关注度差异,重点学习感兴趣的区域特征,大大提高图像特征的表达能力,减小图像信息到文本信息转换的异构鸿沟。与传统注意力机制不同,本文单独从图像特征的通道维度进行研究,通过校准特征的通道维度,得到新的图像特征图。与传统的三维图像特征相比,从单一维度进行建模可以减小参数量和计算量。
通道信息的计算过程如图1所示,通过空间聚合和激励两个步骤得到通道特征描述符,然后再与原始图像特征融合,得到校准后的特征。
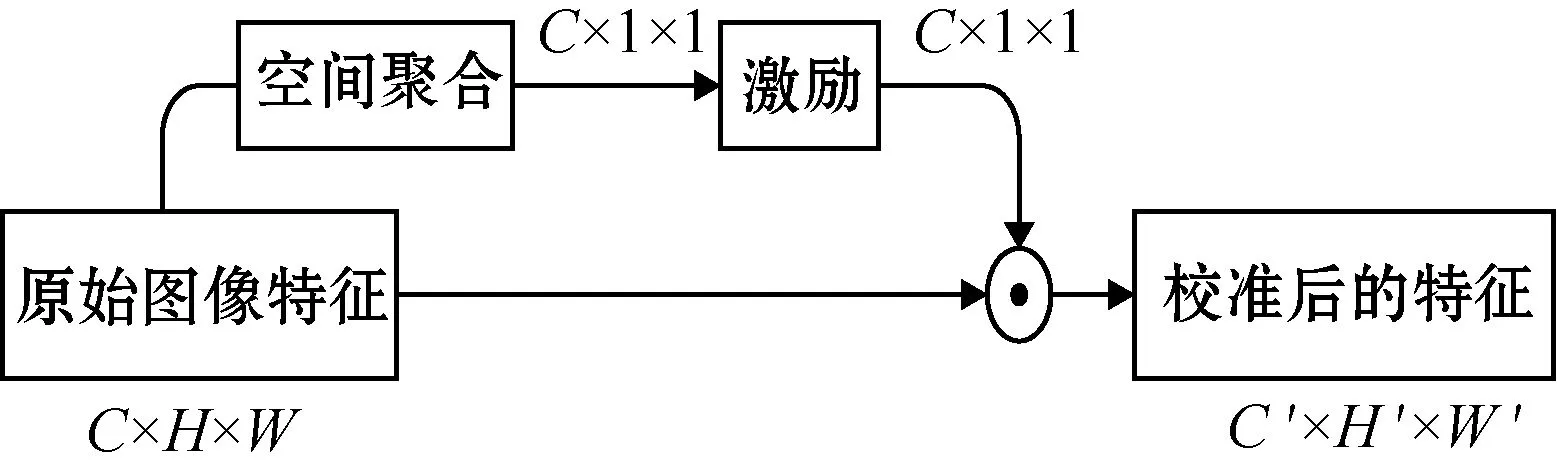
图1 通道信息的计算过程
输入的图像特征图为X∈RC×H×W,输出的图像特征图为X′∈RC′×H′×W′,⊙表示原始特征图X与通道特征描述符沿通道维度的乘法。通过空间聚合操作Fsq,把空间维度H×W缩小至1×1,将全局空间信息压缩到一个通道描述符中,得到一个z∈RC的统计向量,可以计算出z的权值大小:
z=Fsq(X,W1)=δ(W1X)
(1)
式中:δ为ReLU函数;W1为共享层,W1∈RC/r×C。
在空间聚合之后进行激励操作Fex,得到权重系数s,其目的是最大程度捕捉通道之间的相互依赖关系:
s=Fex(z,W2)=σ(W2δ(W1X))
(2)
式中:σ为一个Sigmoid函数;W2为共享层,W2∈RC×C/r。为了限制模型的复杂度并且提高模型的泛化能力,在非线性层采用两个全连接层,设置一个门控机制,其中,r为降维层的减速比。最终,用权重系数s对图像特征图X的通道维度进行重新加权,通过乘法操作Fscale,得到具有通道信息的图像特征图X′:
X′=Fscale(s,X)=sX
(3)
1.2 实现通道注意的网络结构设计
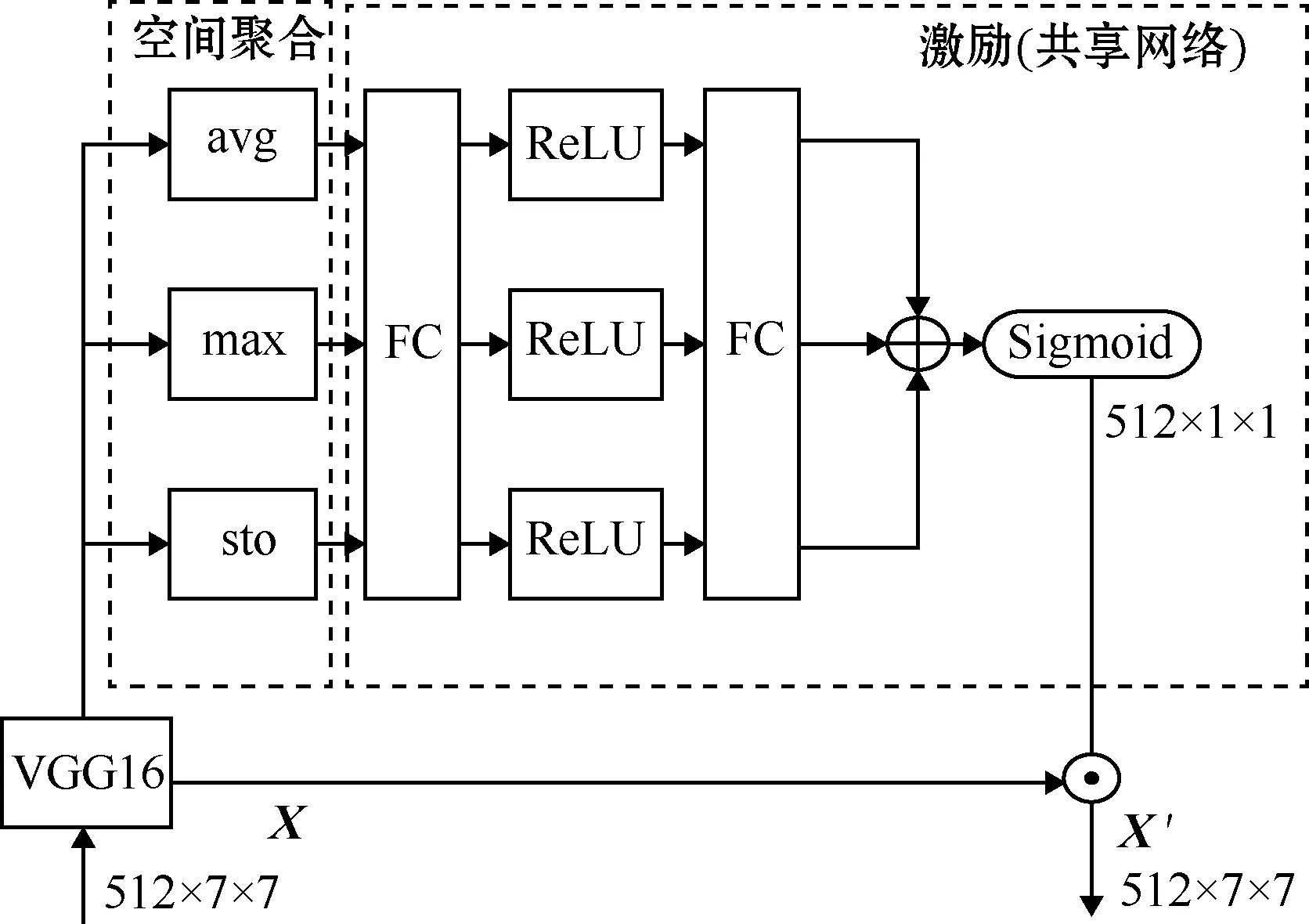
图2 C-Att模块结构

s=savg+smax+ssto=
(4)
1.3 算法流程
本文采用“编码器-解码器”模型作为基础结构,在Aneja等[3]的CNN+CNN架构的基础上进行改进,加入了C-Att模块。在编码阶段,本文采用VGG16提取图像特征信息,通过C-Att模块对图像特征信息的通道权值重新校正,再用CNN门控线性单元(gated linear unit,GLU)作为解码器,生成描述性句子。模型总体结构如图3所示。
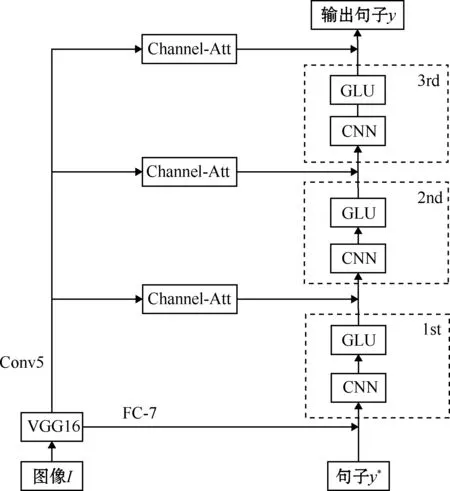
图3 模型总体结构
对于图像描述任务,当指定一个输入图像I,则生成一系列单词y=(y1,y2,…,yN)。可能出现在生成语句中的单词yi∈Y,而Y的容量很容易达到几千。给定一个训练集D={(I,y*)},其中,I是输入的图像,y*是与I相对应的原始描述句子。将y*进行编码生成向量用以训练。通过训练得到参数w,使pw(y1,y2,…,yN|I)最大化。
本文算法的整体训练过程和参数更新算法如下,其中步骤3、4是为了得到总的输入特征向量:
1) 输入:训练集D={(I,y*)}
2) 输出:网络参数w
3) 设置:批量大小N,预训练网络参数wp,迭代次数epochs,学习率α,dropout
4) 迭代步骤:①初始化;②循环开始itert = 1 to epochs;③通过编码层计算输入的单词特征向量;④得到输入图像的特征向量,并与步骤③得到的单词特征向量拼接,得到总的输入特征向量;⑤输入融合注意力模块的CNN解码器模型;⑥根据下文式(5) 计算单词分布;⑦计算pi,w(yi|y 主要步骤的详细操作如下: 1) 输入特征向量。本文基于VGG16提取图像特征图,VGG16是在ImageNet数据集上预训练得到的。将图像输入VGG16网络进行图像特征提取,将网络中的Fc-7层输出,得到1×1×4 096的特征向量,再通过一个线性层进行维度变换,得到一个1×1×512维度的图像特征向量。 在训练时,首先将原始的描述句子y*通过编码层进行独热编码(One-hot Encoding)以及将|Y|=9 221嵌入512维的向量中,得到输入句子向量。把得到的图像特征向量和输入语句向量拼接,得到1 024维度的向量,作为解码器模型中总输入特征向量;在测试时模型生成一个长度为15起始句子全零向量。通过编码层进行独热编码以及将|Y|=9 221通过嵌入层嵌入512维的向量中,得到起始句子输入向量。把得到的图像特征向量和起始句子输入向量拼接,得到1 024维度的向量作为解码器模型中总起始的输入特征向量。 2) CNN解码器。解码器模型是基于卷积机器翻译模型[9]。使用一个简单的前馈深度网络fw建模pi,w(yi|I),预测的单词yi依赖于过去的单词y pi,w(yi|y (5) 本文使用屏蔽的卷积层,只对过去的数据进行操作,防止使用未来单词标记信息。推理开始后,通过前馈网络生成p1,w(y1|Θ,I),以此从|Y|中得到句子的第一个单词y1。把y1反馈回前馈网络,生成p2,w(y2|Θ,I),再从|Y|得到句子的第二个单词y2。以此类推,一直到推理结束或者达到最大步数。 在解码过程中,执行3层掩膜卷积,将卷积后的句子表示向量特征维度保持在512维。并使用门控线性单元(GLU)来对每一个CNN层进行激活。 3) 分类层。使用一个线性层将解码器模型中得到的512维句子表示向量编码为256维的向量,再通过一个全连接层上采样到9 221维,通过Softmax函数输出最大概率的单词yi,最后生成句子y。 4) 注意力模块。把注意力模块添加到每层的单词嵌入中,为每个单词计算单独的注意参数和单独的注意向量。注意力模块的输入为VGG16网络Conv5层的输出特征X,其中,X=(x1,x2,…,xi,…,x512),i∈{1,2,…,512},xi∈R512×7×7为X的第i个维度的空间特征。第j个单词在图像特征X的第i个维度上的注意参数aij为 (6) 式中:W0为用于挖掘通道信息的通道注意机制;dj为CNN模块中第j个单词嵌入;W为应用于dj的线性层。 最后得到的第j个单词对应的注意特征向量为∑iaijxi。 本文实验中使用基于Linux- 4.15.0-29-generic内核的Ubuntu 16.04操作系统,CPU为Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10 GHz,GPU为NVIDIA GTX 1080 Ti,使用PyTorch-0.4.1深度学习框架,基于Python2.7语言实现。 本文在MS COCO(Microsoft Common Object in Context)2014数据集[10]上进行实验。MS COCO由微软发布,是当前最流行的图像描述数据集。该数据集包括82 783张训练图像和40 504张验证图像,每幅图像由5人注释说明。实验过程中,使用113 287张图像用于训练,5 000张图像用于验证,5 000张图像用于测试。 本文使用交叉熵损失来训练CNN模块和嵌入层,经过8轮训练,对VGG16网络进行微调。使用RMSProp 算法进行优化,初始学习率为5e-5,每15轮训练后学习率衰减0.1,总共经过30轮训练,然后评估验证集上的指标,选择最佳的模型。输入词嵌入向量为512维,输入图像特征向量为512维,总的输入特征向量为1 024维,每一层的CNN的输出维度是512。为了防止过拟合,采用dropout机制,参数设置为0.5。 基于CNN+GLU模型,不加注意力机制的模型(no-Att)、加入不含通道信息的注意力机制的模型(Att)和加入含通道信息的注意力机制的模型(C-Att)在MS COCO 2014测试集上的得分如表1所示,C-Att模型和Att模型在部分图片中生成的描述句子效果对比如图4所示。 可以看出,在评分指标上,本文方法生成的图像描述在Bleu_1、ROUGE_L、METEOR、CIDEr、SPICE[11]指标上的得分均比传统的Att模型有提高。 表1 不同模型在MS COCO 2014测试集上的得分对比 图4 C-Att模型和Att模型效果在部分图片中的描述结果对比 从句子描述的丰富度和准确性来看,C-Att模型生成的图像描述也优于传统的Att模型。如图4(a)所示,在C-Att模型生成的描述中,“dog”被细化为“brown and white dog”,增加了对象的颜色属性;在图4(b)中,C-Att模型生成的描述中,可以用“man”具体地描述是什么样的人,而不是用笼统的“person”表示;在图4(c)中,图像包含多个对象,传统的Att模型不能正确地生成相关描述,但C-Att模型生成的描述可以准确地涵盖图像中的对象,如:“cat”和“stuffed animal”;在图4(d)、(e)、(f)中,当一副图像中出现两个相同的对象时,用传统的Att模型生成的描述中,不能准确地表示图像中对象的数量,而用C-Att模型生成的描述中包含了“对象的数量”这个属性。通过以上例子可以说明,C-Att模型通过挖掘通道之间的相互依赖关系,可以捕捉到图像中关于描述对象的属性信息,可以学习到复杂图像中的对象,可以学习图像中相同对象的数量。 BLEU是一种基于精确度的相似性度量方法,用于分析生成语句和标准语句(“ground truth”)中n元组共同出现的程度。它的思想是计算生成的单词在“ground truth”中出现的频率。从表1可以看出,在Bleu_2、Bleu_3、Bleu_4这3个评价指标上,C-Att模型的得分没有较大提升,但在Bleu_1、ROUGE_L、METEOR、CIDEr、SPICE指标上,C-Att模型的得分均优于no-Att模型和Att模型。简单来讲,生成描述的句子中的单词在标注句子(ground truth)中出现过的个数越多,BLEU得分越高。以图4(a)为例,这张图像的一个标注句子是“a large dog retrieving the frisbee for his owner”。在C-Att模型生成的描述中,多了“brown”、“and”、“white”这3个单词,并且这3个单词在标注句子中也没有出现。根据BLEU的计算规则,由于C-Att生成的句子更加细致,出现了“ground truth”中未出现的单词,导致了BLEU的得分未能提高。虽然得分没有提高,但C-Att模型生成的描述更为细致准确,更符合人类的表述习惯。 本文对注意力机制进行深入研究,提出了应用于图像描述生成任务的Channel-Att模型。模型在原有注意力机制的基础上加入了通道信息,采用平均池化、最大池化、随机池化分别对图像特征进行空间聚合,得到通道特征,最大程度地减少在空间聚合过程中的信息损失。通过建模通道之间的依赖关系,重新校正图像特征的通道维度的权值大小。实验结果表明,与传统的不含通道信息的注意力机制的模型相比,加入通道信息的注意力机制模型在Bleu_1、ROUGE_L、METEOR、CIDEr、SPICE指标上的得分均有提高,生成的描述细致、准确,更符合人类的描述习惯。2 实验结果分析
2.1 实验数据集和设置
2.2 结果与分析


3 结束语
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09保定学院学报(2022年2期)2022-04-07中学生理科应试(2021年11期)2021-12-09现代信息科技(2019年18期)2019-09-10数学学习与研究(2018年15期)2018-11-12科技创新与应用(2017年26期)2017-09-12第二课堂(课外活动版)(2016年2期)2016-10-21中国信息技术教育(2016年13期)2016-09-10电脑爱好者(2015年24期)2015-09-10中学英语之友·高一版(2008年10期)2008-12-11
