
基于结构化分析和语义相似度的食品安全事件领域数据挖掘模型
2021-05-19 02:22张景祥胡恩华吴林海
食品科学 2021年7期
陈 默,张景祥,胡恩华,吴林海,张 义
(1.南京航空航天大学经济与管理学院,江苏 南京 211106;2.江南大学理学院,江苏 无锡 214122;3.江南大学生物工程学院,江苏 无锡 214122;4.江南大学商学院,食品安全风险治理研究院,江苏 无锡 214122)
近年来,我国食品安全事件不断涌现,并以互联网为主要载体快速传播。根据中国互联网络信息中心发布的报告,截至2020年3月,我国网民规模达9.04亿 人,网民使用手机上网的比例达99.3%,由于食品安全事件信息传播具有参与人数众多、传播速度快、范围广、表现形式多样等特点,加上传播者与受传者的意识形态、宗教文化、生活经历等存在种种差异,造成信息演化路径多样、不确定强、反复性高,都极大地推动了食品安全事件影响的深度和广度[1]。因此,对互联网上相关的食品安全数据进行挖掘与梳理,对食品安全的热点问题进行跟踪,不仅可以正确引导大众的舆论方向,也可以避免由于不实食品安全报道引起的社会恐慌。
目前,针对我国食品安全事件的大数据分析方法还较少,且互联网信息量巨大,关于食品安全的信息难以被有效提取和分析,只有通过对互联网数据的挖掘,科学分析食品安全事件发生的内外特征,为建立食品安全的预警机制奠定数据和理论基础,才能进一步健全食品安全的保障机制[2]。因此,构建针对食品安全事件的大数据挖掘模型,不仅可以实现信息的高效利用,强化政府监管、企业自律和公众参与的有机结合,还可以通过分析食品安全事件在空间分布的规律性特征,对防范未来系统性、区域性的食品安全风险发挥重要作用,有利于形成食品安全管控无缝隙、精细化的全社会共治新模式。
1 食品安全概述及食品安全事件挖掘技术
1.1 食品安全风险及危害因素的解析
食品安全风险达到并超过一定的临界点就可能诱发食品安全事件。Gratt[3]认为风险是风险事件发生的概率与事件发生后果的乘积。联合国化学品安全项目中将风险定义为暴露某种特定因子后在特定条件下对组织、系统或人群(或亚人群)产生有害作用的概率[4]。由于风险特性不同,没有一个完全适合所有风险问题的定义;针对特定问题,应依据研究对象和性质的不同而采用具有针对性的定义。关于食品安全风险,联合国粮农组织与世界卫生组织于1995—1999年先后召开了3 次国际专家咨询会,提出了食品风险管理的框架和基本原理[5]。国际法典委员会认为,食品安全风险是指将对人体健康或环境产生不良效果的可能性和严重性,这种不良效果是由食品中的一种危害所引起的。国际生命科学学会提出食品安全风险主要是指潜在损坏或危及食品安全和质量的因子或因素,这些食品安全风险的危害因素包括生物性、化学性和物理性的[6]。其中,生物性危害因素主要是指影响食品质量与安全的有关细菌、病毒、真菌及其毒素、寄生虫及其虫卵、昆虫等;化学性危害因素主要包括动植物固有天然毒素、农药、兽药、化肥、环境污染物、食品添加剂、食品包装浸出物;物理性危害因素主要指玻璃、铁丝、铁钉、石头、金属碎片、碎屑等各种各样的外来杂质[7-8]。除生物性、化学性和物理性危害因素外,吴林海等[9]进一步提出了人源性/人为性危害因素,即由于食品生产经营者故意违反食品安全法律法规所进行的不当行为以及其他制度性原因而产生的食品安全风险危害因素,主要包括生产经营者因素、信息不对称性因素、消费者因素、政府规制性因素、国际环境因素等。需要指出的是,人源性因素也是通过物理性、化学性、生物性因素等体现,并产生食品安全风险,但风险原因的本质完全不同。总之,由于技术、经济发展水平差距,不同国家存在的食品安全风险及其危害因素不尽相同。
1.2 食品安全事件概念界定与主要特征
现行的《食品安全法》中没有“食品安全事件”这个概念,但对“食品安全事故”作出了界定,即“食源性疾病、食品污染等源于食品,对人体健康有危害或者可能有危害的事故”。世界卫生组织将食品安全定义为,食品中有毒、有害物质对人体健康影响的公共卫生问题[10]。李清光等[11]认为基于食品安全的定义,食品中含有的某些有毒、有害物质(可以是内生的,也可以是外部入侵的,或者两者兼而有之)超过一定限度而影响到人体健康所产生的公共卫生事件就属于食品安全事件。厉曙光等[12]将食品安全事件与食品或食品接触材料关联,认为食品安全事件为所涉及食品或食品接触材料有毒或有害,或食品不符合应当有的营养要求,对人体健康已经或可能造成任何急性、亚急性或者慢性危害的事件。实际上,在可查阅到的国内外研究文献中,鲜见对食品安全事件的界定,而且近年来中国发生的影响人体健康的食品安全事件往往是由网络新闻媒体(而且主要由网络媒体)首先曝光,故在目前国内已有的研究文献中,学者们较多地选取媒体报道的与食品安全相关的事件进行研究[12-13]。
对于业已发生的食品安全事件,学者们主要对事件性质、产生的影响、危害类型等进行了相关的研究。较为典型的是,He Zhongyue[14]、Dai Yunhao[15]、Liu Huan’an[16]等分别研究了食品安全事件产生的影响,包括对消费者购买意愿和对国际贸易产生的影响、食品生产经营厂商对发生的食品安全事件的危机处理等。此外,学者们主要采用内容分析法进行食品安全事件特征的研究,重点分析食品安全事件中所涉及的供应链环节、食品类别、危害类型与本质原因等,且取得了一定的研究成果。如Li Qiang等[17]研究了2009年4月1日至2009年6月30日时段内中国发生的600 起食品安全事件;Liu Yang等[18]分析了在2004年1月1日至2013年8月1日时段内北京发生的295 起食品安全事件;张红霞等[19]研究了2010—2012年间中国发生的由于生产企业不当行为产生的628 起食品安全事件;莫鸣等[20]分析了2002—2013年间中国发生的由于经营与消费环节处理不当引发的359 个食品安全事件;而刘玉朋等[21]则研究了2001—2013年间中国发生的278 个类别畜产品食品安全事件。已有的食品安全事件研究多以人工为主,智能化不足,导致数据不全面、不精准,对防范食品安全事件意义不足,无法实现对食品安全事件的精准监管和预警,甚至可能产生误导。
1.3 网络媒体报道的食品安全事件挖掘技术
对食品安全事件研究而言,至关重要的是事件的数据来源。传统食品安全风险治理领域的数据,例如全国性的食品监管抽检数据,数量相对有限,难以起到食品安全风险治理中的预防、预警作用。而在大数据时代,获取食品安全风险治理大数据以防范食品安全事件的条件日趋成熟。由于目前国内在食品安全事件的分析方面尚没有成熟的大数据挖掘工具,因此近年来有关食品安全事件的研究,其涉及的数据主要来源于各个研究团队根据研究需要而基于网络媒体新闻所进行的专门收集[16-18]。数据从国内各相关网站收集,主要由人工进行重复性的检验和有效性的筛选,其中王东波等[22]通过条件随机场模型对食品安全事件当中食品名称与诱因的自动识别;沈思等[23]通过BilSTM-CRF模型构建基于深度学习的食品安全事件实体模型;郑丽敏等[24]提出FSE_ERE这种基于依存分析的食品安全事件新闻文本的实体关系抽取方法。也有学者利用“网络爬虫”技术取代人工搜索,抓取网站中与食品安全事件相关的新闻[25]。目前网页排序的典型算法是Page Rank算法,Page Rank是由Larry Page和Sergey Brin提出来的一种根据网页之间相互的链接关系计算网页排名的技术。通过对网页抓取技术获取相关数据,其主要技术方法都是将来源网站的网页解析成树,在树的基础上,再利用网页结构信息或视觉信息从中提取出网页正文内容。如Zhang Cheng等[26]构建了基于DOM树结构匹配和视觉一致性的新闻信息构造的算法;王俊峰[27]又改进提出了结合结构一致性和视觉一致性的新闻提取算法。基于关键词匹配的网页抓取技术也有较为广泛的研究,如Cai Xinbao等[28]提出基于网页关键词的主题相关性爬虫技术。Zhao Xu等[29]用语义本体代替传统关键词库,通过本体中词汇的层次关系计算网页的主题相关度。陆玉昌等[30]基于网页词汇共同分布进行了相关研究。Bollegala等[31]通过统计浅层关键词和语义分析技术,估计词汇间语义相似度和词汇共现频率,但此方法缺陷在于没有考虑外围语义成分及语义结构。随着研究的深入,学者们在选取文档特征码中也逐渐兼顾词语的语义信息,Chowdhury等[32]提出有选择性地挑选词语来生成文档特征码的策略;Theobald等[33]提出Spot Sigs算法,按特定规律提取网页特征值;Andoni等[34]根据内容相似度提出的局部敏感哈希(locality sensitive Hashing,LSH)算法;黄承慧等[35]提出按倒排序生成文档特征码的算法。
上述研究虽然在文本抓取和语义分析上取得了一定的成功,但目前针对食品安全事件的大数据研究方法尚不足以达到精准监管与预警的作用。长期以来,中国食品安全风险与由此诱发产生的食品安全事件历史数据非常匮乏,而网络媒体所报道并形成的食品安全事件大数据并没有为人们所综合利用。因此,对于网络媒体对中国食品安全事件的研究,迫切需要基于大数据技术,从食品安全事件的食品种类、事件在食品供应链环节上的分布、诱发事件发生的风险因子、事件的空间分布等各个方面来研究食品安全事件的演化规律,科学阐述食品安全事件的基本特征与发生机理。针对上述问题,本文全面分析了食品安全事件的基本特征,对食品安全事件关键词进行有序语义重构,构建了食品安全事件的多层多级语义模板,通过比较不同食品安全事件与语义模板的相似度,得到食品安全事件多层多级语义结构排序策略(strategy of multi-layer and multi-level semantic structure of rank,MMSS-Rank)算法。
2 基于结构的多层多级语义分析
2.1 语义模板
食品安全事件的报道应该包含的信息量很多,包括事件发生的区域、食品安全事件的类型以及危害程度等。为了更加准确描述一个食品安全事件的语义模板,做出如下定义:
定义1:设YRi是描述某一个食品安全事件Ri的一个词语,称YRi为语义关系词语。
定义2:YRi是语义关系词语;YR={YR1,YR2,...,YRn}为所有食品安全事件Ri的语义关系关键词集合。
定义3:满足食品安全事件条件下两个关键词YRi、YRj之间存在一动词DRij,且YRj后 为 名 词mRij, 则 称YRi、DRij、YRj、mRij4 个词组成一个语义结构体。
定义4:对语义结构体中的各个关键词YR={YR1,YR2,...,YRn}进行有序重构,次关键词为DRij,mRij可以描述关键词YRi、YRj间的语义关系,则称<YRi,DRij,YRj,mRij>为满足食品安全事件Ri的标准语义模板。
示例:2016年5月26日新华社报道:海口破获一起特大销售假冒白酒案。由定义4可知,<海口, 报道, 白酒,假冒>对应<YRi,DRij,YRj,mRij>是满足食品安全事件的语义模板。
2.2 食品安全事件的语义分层
食品安全数据经过去重、清洗等预处理后,转化为非结构化的文本数据,用分词技术和词频统计方法将文本转化为可处理的结构化形式。针对食品安全事件的语义特征,语义关键词出现在文本的位置不同,所起到的作用就不同,按文本结构可分为3 层:第一层是标题层,如标题、小标题等,已初步表达文本的主题概念,若食品安全事件的语义结构完整地出现在标题层,该文本数据被识别为食品安全事件作用明显;第二层是段落层,食品安全事件在不同段落中表达的语义结构体的内容较为完整,其作用与段落数、段落长度有关;第三层是关键词层,对于食品安全事件而言,包括食品种类、供应链环节、风险因子、空间分布等语义关系中的关键词,且与关键词的词频、关键词出现的位置、词长等属性有关。通过对食品安全数据的文本进行结构化分析,对文本数据进行抽象处理,进而建立描述食品安全事件的数学模型,通过对模型计算,实现计算机对大规模文本的挖掘和识别。
2.3 食品安全事件的多级语义模板
在主流媒体新闻报道中描述详尽的食品安全事件应该包含空间分布、食品种类、供应链环节、风险因子等信息,空间分布以省、直辖市、自治区为父类,下辖地级市为子类。食品安全事件中食品种类分类方法按照食品生产许可管理办法(征求意见稿)分类,共计32 类,见表1。食品安全事件的风险因子主要是指潜在损坏或危机食品安全和质量的因素,这些因素包括生物性、化学性和物理性,以及人的行为不当、制度性等因素,包括生产经营者因素、信息不对称性因素、消费者因素、政府规制性因素等,食品安全的风险因子词库见表2。根据定义4和文本数据中语义结构信息量,定义食品安全事件的一、二、三、四级语义模板,见表3。通过分词技术获得食品安全文本数据中的结构和语义信息,遍历结构化的文本数据,计算文本数据信息与食品安全事件语义模板的匹配度,可以有效提高语义分析处理粒度,从而降低语义分析处理的规模,同时也有助于将无规则的数据信息转化为标准化数据。

表1 食品安全事件的信息分类Table 1 Classification of information about food safety incidents

表2 食品安全事件风险因子Table 2 Risk factors for food safety incidents
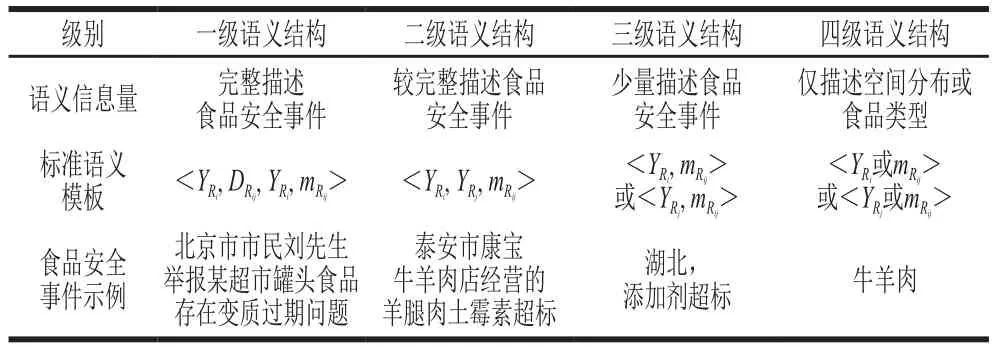
表3 食品安全事件的多级语义模板Table 3 Multi-level semantic template of food safety incidents
3 MMSS-Rank算法
3.1 MMSS-Rank算法流程
选择合适的网络媒体作为食品安全事件的来源网站,在确保所抓取数据来源真实可靠的基础上实现去重和清洗;利用分词技术提取数据中关键词的位置、词频、总字数等内容信息,并识别标题、首段、尾段等位置信息,根据数据的语义结构体在文本分层结构的位置,进一步与多层多级语义模板进行相似度计算,由相似度得分对文本数据进行排序,选择适当阈值判别并输出食品安全事件的精度,MMSS-Rank算法流程图如图1所示。

图1 基于多层多级语义模板相似度的网页排序框架Fig.1 Web page ranking framework based on multi-layer, multi-level semantic template similarity
3.2 文本数据与标准语义模板相似度算法
首先将抓取的文本数据集合进行预处理,转化为文本数据,利用分词技术确定文本数据中关键词的位置,然后计算与多层多级语义模板的相似程度,其相似度计算如式(1)所示。

式中:P1×m=(p1,p2,...,pm)表示语义结构体在文本中不同结构位置的权重;Wn×1=(w1,w2,...,wn)表示不同级别语义模板的权重;Simij表示食品安全事件语义结构体与第i个语义模板和第j个文本层次的关键词密度,i=1,...,m,j=1,...,n。
将抓取的文本数据按PValue(P,S,W)数值由大到小排列,并选择适当的阈值输出文本数据。关键词密度计算如式(2)所示。

式中:a为描述食品安全事件语义结构体的关键词集合;b为抓取的文本集合;vak为文本集合a中关键词k对食品安全的重要程度;vbk为文本集合b中关键词k对食品安全的重要程度。vak和vbk均采用式(3)计算,以vak为例。

式中:tf(ak,b)为文本集合a关键词k在文本集合b中出现的频率;为关键词i在文本集合b中出现的总数;N为文本集合中字数;nk为文本集合a关键词k出现的所有文档数。
根据上述描述,设计MMSS-Rank算法,步骤如下:
输入:数据D={title, content},文本层次权重P(简称层权重,共3 层权重),语义模板权重W(简称级权重,共4 级权重),文本层次级别数量m,语义模板级别数量n
输出:文本数据得分Score
1.根据系统设定的语义模版(地区行为学术标签风险标签)对文章进行分词和统计处理,得到文章字符数量、关键词列表和分段信息(区分是标题还是正文),关键词需要包含所在段落、所在段落中的排序和类型
2.keywordMap=[关键词: 密度值(关键词字数/全文关键词总字数)]
3.根据关键词和分段信息,采用最短路径和系统设定的语义模版组合各段落语义,划分标题语义列表、同段落语义列表、不同段落语义列表,每个语义需要含有(语义内容、语义关键词密度之和、语义级别(1级(4 类信息)、2级(3 类信息)、3级(2 类信息)、4级(1 类信息)、语义层次(1标题、2同段、3不同段))
取分段语义列表
标题中的语义计入标题语义列表中
正文段落区分同段语义列表和不同段语义列表,默认同段是第一段,判断各段落中语义级别最高且语义中各类关键词之和最大的段落作为本文同段
sameNum=1;
for all段落do
if段落语义级别最高且语义中各类关键词之和最大 then
sameNum=;
end if
end for
for all段落do
if段落Num == sameNum then
sameList=[段落语义]
else
differList=[段落语义]
end if
end for
4.文章语义关键词密度矩阵Cij=[0],同一层次将相同级别语义的关键词密度和相加后除以个数
for all m do
i按照标题、同段、不同段的顺序取出各层级语义列表
for all n do
if语义级别为jthen
cij=其中a为该文本层次语义集合,vk为语义k的关键词密度,n为a集合的个数;
end if
end for
end for
5.更加公式计算得分:Score=P×(Cmn×WT)
6.return Score
输出:Score
得分的高低进行排列,输出检索网页的重要程度,按得分数值高低进行排序。
3.3 示例
为说明MMSS-Rank算法,以单独一段的文本数据为例,计算过程如下:
标题:抽检嘉兴市嘉利、五福奶糖存在多批次不合格
正文:近日,嘉兴市工商行政管理局公布2019年4季度对海宁市流通环节销售的部分奶糖产品进行了质量监测抽检。本次监测主要对奶糖的卫生指标(如菌落总数、大肠菌群等)以及酸价、过氧化值、苯甲酸或山梨酸、苏丹红等项目进行了检测。监测结果显示,奶糖内在质量较好,个别产品存在甜蜜素、还原糖等指标不符合国家有关标准要求的问题。此次抽查49 批次产品,其中2 批次不合格。晋江市嘉利食品有限公司生产的五福多彩软饴,糖精钠、甜蜜素不合格,海宁市嘉利食品厂生产的五福酥糖(裹皮型),还原糖不合格。
计算过程:
1.从文章中提取关键词
keywordList:奶糖(4), 嘉兴(2), 公布(1),海宁(2)
2.计算提取的关键词分数
keywordMap:奶糖(2*4/254=0.0315), 嘉兴(2*2/254=0.01575), 公布(2*1/254=0.00787), 海宁(2*2/254=0.01575)
3.计算出标题、同段和异段中语义的分数
标题:{"2":[{"density":"0.04725","content":"海宁奶糖"}]};
同段:{"2":[{"density":"0.02362","content":"嘉兴公布"},{"density":"0.04725","content":"嘉兴奶糖"}],"1":[{"density":"0.0315","content":"奶糖"},{"density":"0.0315","content":"奶糖"},{"density":"0.01575","content":"海宁"}]};异段:{};
4.计算文章语义关键词密度矩阵
cmn=[ [0, 0, 0.04725, 0],[0, 0, 0.035435, 0],[0, 0, 0, 0]]
5.得出分数:score=[5, 3, 1]*(cmn*[[10][8][5][1]])=[5, 3, 1]* [ [0.23625][0.177157][0]]=1.7127
4 实验分析
4.1 实验设计与说明
4.1.1 数据准备
目前,针对国内外还没有关于食品安全事件的大规模数据作为公共测试集,因此,本文选择中国食品报网、中国食品监督网、食品安全快速检测网、39健康网、中国食品科技网、中国质量新闻网、浙江消费维权网、第一食品网、山东美食网、FT中文网、四川新闻网、东方网、光明网(食品频道)等58 家主流网站的食品版块,从2009—2019年间的720 000 条相关报道数据中通过科学地抓取、去重和清洗得到的数据作为实验文本数据。再借助分词技术对食品安全文本数据进行分词,通过对文本数据的语义分析、关键词识别、结构化分解、分层化标注等预处理,进一步得到不同文本数据的结构化信息。其中语义分析工具使用了哈尔滨工业大学社会计算与信息检索研究中心研发的“语言技术平台”,该平台提供包括中文分词、词性标注、命名实体识别、依存句法分析、语义角色标注等丰富、高效、精准的自然语言处理技术。少量食品安全事件特定的目标词识别和结构工作是通过人工进行标注及矫正。
4.1.2 评价指标
本文中MMSS-Rank算法的测试效果采用判别食品安全事件准确率来评价,具体做法为:从实验文本数据中随机抽取N条数据,通过人工判别是否为食品安全事件,标记为labeli,i=1, 2,...,N,当labeli=1时表示文本数据是食品安全事件,当labeli=0时表示文本数据不是食品安全事件;再从标注清楚的数据集中随机选取N1条文本数据作为训练集,剩余N-N1条作为测试集。设定不同层、级和阈值参数,按本文提出的语义模板相似度算法计算训练集中每一条文本数据的得分,将训练集中所有文本数据按分值由大到小排列,得到分值大于和等于阈值α的N2(N2≥N1)条文本数据,并定义此时的判别准确率P和召回率J。
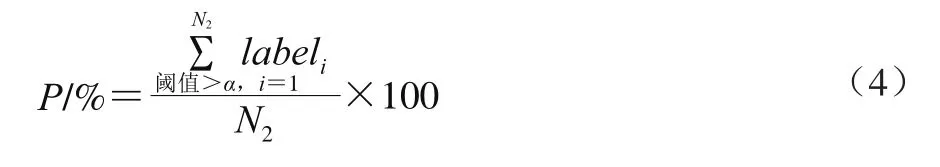
在食品安全事件准确率最优的条件下,得到层、级和阈值权重参数,在N2个文本数据中,得分大于和等于阈值α的文本中的确是食品安全事件的所占比例为P,P用于测试算法的判别准确率。

在N个文本数据中,得分大于和等于阈值α的文本占全部文本数据的比例为J,J用于测试算法的召回率。
4.1.3 对比算法及参数设置
为了验证文本所提MMSS-Rank算法的有效性,基于标准测试数据集,用不同方法进行性能评估,实验部分采用如下比较算法:1)传统的机器学习方法支持向量机(support vector machine,v-SVM),通过训练和测试已有的数据,得到较好的训练参数用于对新数据类别判别;2)基于主题的网页排序算法T-rank。v-SVM采用LibSVM参数,选择程序包的默认设置;基于主题Page-rank算法设置参数。MMSS-Rank算法有结构层、语义模板和阈值权重,因此,设置不同参数来研究结构层、语义模板和阈值权重系数的影响,见表4。

表4 MMSS-Rank权重算法参数设置Tale 4 MMSS-Rank parameters
4.2 同层级权重实验及结果分析
为了说明本算法中不同层级权重对多层多级语义模板语义影响的差异,首先从第一级开始,依次逐层级权重取值0.1,其他层级权重全部取值为[1, 1, 1, 1],来说明改变层级单一权重对算法影响的情况,计算结果如图2所示;然后将层级权重全部取值为[1, 1, 1, 1],来对比说明若仅考虑层级中一个因素取不同权重时对MMSS-Rank算法的影响,计算结果如图3所示。
从图2可以看出,在MMSS-Rank算法中仅改变层级中单一权重,或者层级权重相近时,准确率和召回率没有显著变化,说明对于MMSS-Rank算法若不考虑数据的文本位置信息和语义结构特征,由于对食品安全事件缺少比较完整的描述,因此,对于数据挖掘的准确率和召回率较低,说明对于MMSS-Rank语义分析算法而言,用不同权重系数反映层级间的重要程度是必要的。

图2 改变层级单一权重的准确率和召回率曲线Fig.2 Accuracy and recall rate curves determined by changing a single layer and level weight

图3 单层和单级权重准确率和召回率曲线Fig.3 Accuracy and recall rate curves of single layer and single level weights
从图3A可以看出,将MMSS-Rank算法中的级权重相同时,层权重越小准确率上升越快,召回率下降越快;从图3B可以看出,层权重相同时,级权重越小准确率上升越快,召回率下降越快。同时,准确率都随着阈值的增加而增加,召回率随阈值增加而减小。当阈值足够大时,准确率可以达到100%,召回率趋近于0。进一步说明通过适当层级权重可以反映数据结构关系和语义特征,进一步提升MMSS-Rank算法的精度。
4.3 不同层级权重实验及分析结果
为了更直观说明不同层级权重系数对准确率和召回率的影响,使用表4中已设定的参数对测试集进行评分测试,计算结果如表5所示。取准确率80%,当层权重参数为[1, 0.5, 0.1]和级权重参数为[10, 3, 1, 0.5]时,阈值经计算可得0.092 555,此时召回率达到68.24%;将层级参数设置为[1 000, 100, 10]和[1 000, 100, 10, 1]时,阈值取值较大且准确率有所下降。

表5 不同准确率下不同参数的召回率与阈值Table 5 Recall rates and threshold values of different parameters showing different accuracies


图4 层和级权重不同时准确率和召回率曲线Fig.4 Accuracy and recall rate curves for different layer and level weights
从图4A~D可以看出,在MMSS-Rank算法中当权重逐渐增大时,层数降低,层数越小,准确率和召回率均快速上升,这表明在MMSS-Rank算法中层权重的重要性高于级权系数,尤其是在标题结构和食品安全事件数据的一级语义结构基本可以描述食品安全事件数据的结构关系和语义特征时。因此,层权重重要性高于级权重。
在MMSS-Rank算法中,显著增加食品安全数据层权系数时,准确率和召回率变化情况如图4E所示,MMSS-Rank算法不仅兼顾文本位置信息,还融入了语义结构特征,因此能够完全描述一个食品安全事件,较好地克服了仅使用文本关键字来表达的句子语义信息的限制。
4.4 对比算法实验及分析结果
本部分实验选择v-SVM算法、T-rank算法对食品安全文本数据集进行判别,并与本文提出的MMSS-Rank算法进行性能比较,使用平均值作为算法对应的准确率,选择从2007—2018年主流媒体报道中食品安全事件发生较多的3 种食品类型进行对比实验,得出v-SVM、T-rank和MMSS-Rank 3 种算法对食品安全数据判别准确率,如表6所示。
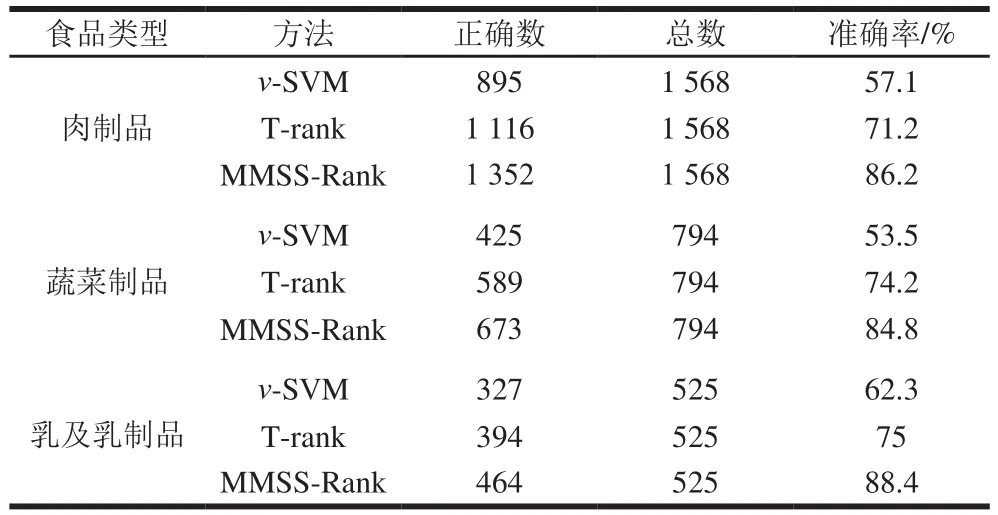
表6 三类食品安全事件判别准确率Table 6 Accuracy in discriminating FSI-related data
由表6可知,对于食品安全事件数据,相比之下,传统v-SVM方法的准确率均逊于其他方法,说明传统的分类学习方法处理文本数据时,仅通过提取文本词频、句长等信息,无法全面获取食品安全事件语义信息;基于主题的网页排序算法T-rank虽然对食品安全事件主题内容进行分割,能够在一定程度上避免v-SVM抽取方法的局限,但是由于食品安全事件具有时空特性,T-rank算法不考虑事件结构信息,特别是忽略食品安全事件语义特征,因而准确性不高。MMSS-Rank算法在充分考虑食品安全事件数据结构信息的基础上,又兼顾了食品安全事件发生地点、时间和环节等语义信息,通过与标准食品安全事件的语义模板进行相似度比对,从而较好地实现文本数据语义分析;因此,MMSS-Rank算法在肉制品、乳及乳制品上判别准确率明显优于其他两种方法。
5 结 语
本文提出的MMSS-Rank算法不仅能够高效提取不同食品安全事件的语义结构信息,还通过计算不同事件与语义模板间相似度,实现食品安全事件排序。实验结果表明,MMSS-Rank算法对食品安全事件的判别具有较好的准确性和高效性。较之于现有的相关方法,该算法的特色之处在于:1)从食品安全事件的食品种类、供应链环节、风险因子、空间分布等特征,全面梳理食品安全事件的关键词,构建食品安全事件多层多级标准语义模板。2)将主流来源网站数据清洗后,算法分别从横向和纵向提取食品安全数据的语义结构信息,粒度更小。3)创新地融合食品安全数据的分层结构信息和语义特征,实现在食品供应链环节上,应用大数据挖掘技术研究食品安全事件的演化规律。
利用MMSS-Rank算法开发的中国食品安全事件大数据分析平台,不仅可以分析食品安全风险产生的动因和传播方式,还可以基于信息收集、分析评估、预警预报、预案实施、效果评价等制定相应的措施,探索覆盖食品供应链全程动态安全预警系统,以及研究中国食品安全事件的空间分布特点和变化趋势。
在实验过程中,由于不同网站报道形式和内容表述的差异,特别是结构松散的食品安全事件文本数据、关键词抽取、分词、切词等问题不准确,直接影响了算法精度,这是本算法本身设计特点所决定的。对于未来的工作,可以从下面几个方面考虑:1)结合食品安全事件特点,需要寻找一种新的语义模板间相似度的计算方法。另外对于特殊食品安全数据和文本,如单句、单段或多关键词交叉,寻找一种高效率、高准确率的食品安全关键词和句抽取方法至关重要。2)食品安全事件关键词切词、分词方法也有待改进,本文事先将食品安全事件新闻报道中的关键事先设定好,但随着新闻报道和事件的变化,关键词会不断变化,因此需要开发一种动态的优化机制,提升食品安全事件语义分析的准确率。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
江苏安全生产(2022年5期)2022-06-16
心理学报(2022年5期)2022-05-16
中国计算机报(2021年9期)2021-04-26
当代陕西(2020年17期)2020-10-28
开放教育研究(2020年2期)2020-03-31
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
长江学术(2016年4期)2016-03-11
长江学术(2015年1期)2015-02-27
