
基于改进LSTM 模型的短期车流量预测*
2021-05-02 12:52赵红涛加鹤萍
科技创新与应用 2021年12期
魏 健,赵红涛,加鹤萍
(1.华北电力大学 数理学院,北京 102206;2.华北电力大学 经济管理学院,北京 102206)
近年来随着人们的生活质量不断提高,机动车购买量也变得越来越多。伴随而来的是严重的交通拥堵状况,给人们的出行造成极大不便。短时车流预测可以帮助交通部门及时了解某路段未来可能发生的拥堵情况,从而提前做出反应,同时对于人们的出行也具有一定的意义,可以让人们及时避过拥堵路段[1]。
文献[1]使用LSTM 模型对北京市朝阳区某道路交叉口的车流量进行预测,使用自动编码器进行无监督学习,将自动编码器的输出作为LSTM 的输出。文献[3]使用LSTM 模型预测地铁站温度,并且在数据预处理的过程中使用了小波降噪的方法,建立了有关时序数据的模型方法,并且与传统的ARIMA 模型比较,证明了LSTM 在处理较大幅度变化的数据时,其误差小于ARIMA 模型。文献[5]考虑到语言特征可能不仅仅受到以前语言的影响,也可能受到之后语句的影响,所以在自然语言处理中利用了双向GRU 模型和注意力机制。文献[6]针对数据的长期依赖性,使用基于注意力机制的CNN-LSTM 模型拟合数据,在LSTM 后端构建注意力机制,给隐含层赋予不同的权重来优化最终的输出结果。实验证明,在注意力机制的优化下,其误差结果小于CNN 等神经网络模型。文献[7]构建了短时车流量的预测模型,建立CNN-LSTM 模型预测车流量数据并且得到了良好的结果。
由于在后续的实验中发现车流量在工作日和节假日明显不同,所以将数据分成工作日和节假日两部分进行讨论[3],建立了基于注意力机制的长短时记忆神经网络模型对短时车流量进行预测,使用卷积神经网络(CNN)、长短时记忆神经网络(LSTM)、双向长短时记忆神经网络(BiLSTM)作为对比模型,且考虑到可能存在的过拟合问题,本文在对比模型中加入了基于注意力机制的双向长短时记忆神经网络(BiLSTM-attention)模型。LSTM 通过门结构的设置在很大程度上解决了循环神经网络(RNN)模型存在的问题,注意力机制对LSTM 隐含层赋予不同的权值,从而优化了输出值,得到了相对较小的误差值。
1 基于注意力机制的LSTM 模型原理结构
1.1 LSTM 模型
LSTM 模型是在上世纪90 年代提出的一种神经网络模型,它在处理时间序列数据方面具备独特的优势[4]。随着神经网络层数的增加,RNN 模型不可避免地会出现梯度消失或梯度爆炸现象,而LSTM 以其特有的结构可以大大缓解上述现象。
LSTM 模型在RNN 模型的基础之上增加了门结构的设置,使用三种门来控制信息。第一层门为遗忘门,遗忘门会遗忘一部分不重要的信息,选择记住一些重要的数据特征;第二层门为输入门,输入门会更新一些内容,以填补已经被遗忘门略去的信息;第三层门为输出门,输出门可以对先前的信息进行处理,然后对数据输出。
然而当步长过长时,LSTM 会发生明显的梯度消失现象,所以应使用下文的注意力机制算法对LSTM 中的权重进行处理,以更准确地进行预测。
1.2 注意力机制
注意力机制通过概率分配的方式,对关键信息赋予足够的关注,突出重要信息的影响,从而提高模型的准确率[5]。在序列数据过长时,LSTM 模型也可能会发生梯度消失现象,为了尽可能削弱梯度消失现象造成的影响,此处引入注意力机制,给不同的LSTM 单元赋予不同的权值,给较为接近真实值的LSTM 单元赋予较大的权值,反之亦然[6-7]。其计算公式如(1)、(2)所示。
设第x 个LSTM 神经元的输出值为hx,设每个神经元对应的权重为ux,最终的输出值为yt,设总共有a 个LSTM 神经元。

1.3 LSTM-attention 模型的算法步骤
Step1:数据预处理,其中包含根据工作日和节假日划分数据,对数据进行归一化处理,使用平均值填充缺失值等等。
Step2:将经过数据预处理的数据输入至模型中,通过LSTM 的遗忘门、输入门、输出门来学习数据的特征,其中主要学习的时间之间的关联。
Step3:对LSTM 中隐含层各单位赋予权值,给较为接近真实值的LSTM 单位较大的权值。
Step4:输出预测值。
2 实证分析
2.1 数据预处理
本文使用的数据是北京某公路路段的车流量,时间跨度为2018 年1 月18 日至2018 年5 月11 日,数据为五分钟记录一次,总共有数据26650 条,其中包含1320条缺失值。本文采用取平均值的方法来填补平均值,但是由于各个时刻的车流量差距很大,所以取缺失值所在时刻的平均值来代替缺失值,同时在使用LSTM 模型之前需要对原始数据进行归一化,否则不利于数据的训练。
在工作日时间,车流量存在明显的周期性变化,出现周期性变化的原因与早晚高峰有关,且其峰值也明显高于节假日的车流量;但是在节假日时间并没有十分明显的周期性波动。
2.2 模型参数设置
本文工作日数据总共有17686 条,节假日数据共有8964 条。参数的设置分两种情况,在工作日情况下,设定epoch=1200,batch_size=17000,shuffle=False;在节假日情况下,设定epoch=1000,batch_size=8000,shuffle=False。工作日测试集的时间跨度为2018 年5 月10 日18:00 至2018 年5 月11 日18:50,节假日测试集的时间跨度2018 年5 月5 日全天。测试集数据均为288 个,其余作为训练集。
2.3 使用误差说明
本文采取平均绝对百分误差(Mean Absolute Percentage Error,MAPE)和均方根误差(Root Mean Square Error,RMSE)来展示不同方法的负荷预测误差,如式(3)、(4)所示。
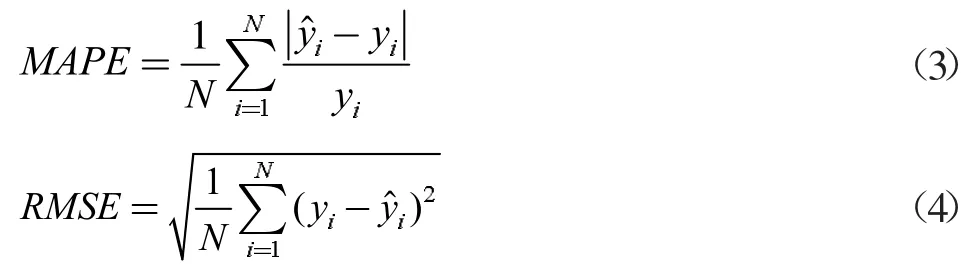
由于RMSE 使用的是平均误差,MAPE 是以相对误差为原理,所以二者误差兼顾了不同的因素,同时本文引入训练时间作为判断模型优劣的依据之一。
3 对比试验
在作对比实验的过程中,为了尽可能减少偶然因素,实验的数值均是用十次实验的结果取平均值,并且对每个对比实验的参数进行校正。本文使用CNN、LSTM、双向LSTM、BiLSTM-attention 模型作为对比实验。
3.1 实验结果
从图1、图2 可以得出结论,在节假日和工作日两种情况下,本文所使用的模型均能对短时车流量进行准确预测。下文将用量化的方式来具体对比。
3.2 模型结果解释
由表1、表2 知,LSTM-attention 的表现最好,BiLSTMattention 误差相对较大的原因与过拟合因素有直接的关联,且BiLSTM-attention 的训练时间也远高于LSTMattention。在工作日对车流量的预测中,LSTM-attention 模型在MAPE 标准下分别比LSTM、双向LSTM,CNN、BiLSTM-attention 低6.85%、6.34%、8.04%、0.72%;在RMSE 标准下,LSTM-attention 分别比LSTM、双向LSTM,CNN、BiLSTM-attention 低26.08、25.915、26.325、4.335,训练时间方面则节省了15s、111s、28s、96s。而在节假日中的差距更加明显,LSTM-attention 模型在MAPE 和RMSE两个标准下的数值甚至只有大部分对比模型的左右,训练时间也低于其它对比模型,从而证实了LSTMattention 模型可以胜任对于车流量的预测,有一定的应用潜力。
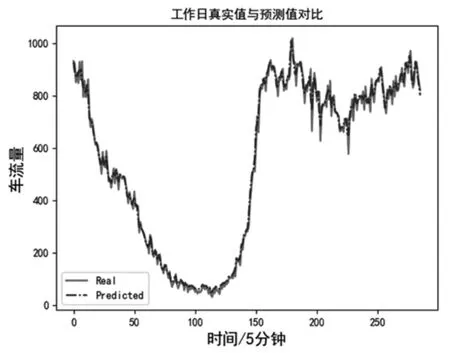
图1 本文模型预测值与实际值关系图(工作日)
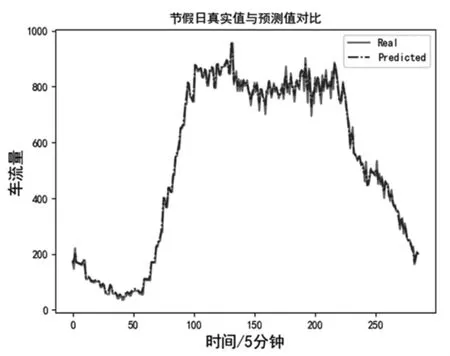
图2 本文模型预测值与实际值关系图(节假日)

表1 各实验误差对比(工作日)

表2 各实验误差对比(节假日)
4 结论
由前文的分析得知,节假日和工作日的车流量特点有很大的不同,主要体现在峰值和周期差距较大上,所以将二者分开分析有利于数据的预测。否则会干扰LSTMattention 模型学习数据特征,进而影响预测效果。LSTM可以通过门结构来学习时序数据特征,遗忘门、输入门、输出门的存在大大改善了RNN 模型存在的梯度消失与爆炸问题。但是当输入的序列长度过长时,LSTM 仍会出现此问题,注意力机制可以在很大程度上解决这一问题。
本文选用CNN、LSTM、BiLSTM、BiLSTM-attention 模型作为对比模型,由结果来看LSTM-attention 在MAPE、RMSE、乃至训练时间上都有很好的表现,还考虑到可能存在的过拟合现象,所以引入BiLSTM-attention 模型作为对比模型,事实证明LSTM-attention 确为最佳选择。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
甘肃教育(2020年22期)2020-04-13
湖北函授大学学报(2018年6期)2018-05-23
理论观察(2018年1期)2018-03-24
第二课堂(课外活动版)(2016年2期)2016-10-21
数学教学通讯·初中版(2015年5期)2015-06-17
商(2012年14期)2013-01-07
