
Physics-informed deep learning for one-dimensional consolidation
2021-04-26 02:07YaredBekele
Yared W.Bekele
Rock and Soil Mechanics Group, SINTEF AS, Trondheim, Norway
Keywords:Physics-informed deep learning Consolidation Forward problems Inverse problems
ABSTRACT Neural networks with physical governing equations as constraints have recently created a new trend in machine learning research.In this context, a review of related research is first presented and discussed.The potential offered by such physics-informed deep learning models for computations in geomechanics is demonstrated by application to one-dimensional (1D) consolidation.The governing equation for 1D problems is applied as a constraint in the deep learning model.The deep learning model relies on automatic differentiation for applying the governing equation as a constraint,based on the mathematical approximations established by the neural network.The total loss is measured as a combination of the training loss (based on analytical and model predicted solutions) and the constraint loss (a requirement to satisfy the governing equation).Two classes of problems are considered: forward and inverse problems.The forward problems demonstrate the performance of a physically constrained neural network model in predicting solutions for 1D consolidation problems.Inverse problems show prediction of the coefficient of consolidation.Terzaghi’s problem,with varying boundary conditions,is used as a numerical example and the deep learning model shows a remarkable performance in both the forward and inverse problems.While the application demonstrated here is a simple 1D consolidation problem, such a deep learning model integrated with a physical law has significant implications for use in,such as,faster realtime numerical prediction for digital twins, numerical model reproducibility and constitutive model parameter optimization.
1.Introduction
Machine learning has been a fast-growing field of research over the last years with ever growing areas of application outside pure computer science.Deep learning, a particular subset of machine learning which uses artificial neural networks (ANNs), is being applied in various disciplines of science and engineering with usually surprising levels of success.Recently, the application of deep learning related to partial differential equations (PDEs) has been picking up pace.Several researchers are contributing to this effort where different names are given to the use of deep learning associated with physical systems governed by PDEs.Some of the commonly encountered labels include physics-informed neural networks, physics-based deep learning, theory-guided data science, and deep hidden physics models, to name a few.In general,the aims of these applications include improving the efficiency,accuracy and generalization capability of numerical methods for the solution of PDEs.
Data-driven solution of PDEs was recently presented by Raissi et al.(2019a).The authors investigated various differential equations and demonstrated how deep learning models can be applied in forward and inverse problem settings.Some of the PDEs studied include Burgers’ and Navier-Stokes equations.The forward problems demonstrated how deep learning models can be trained based on sample data from exact solutions while optimizing an embedded governing PDE.In the inverse problems, deep learning models were trained to identify the coefficients of the PDEs.For practical problems in science and engineering,this is equivalent to identifying material parameters based on given exact or numerical solutions.The neural network models for both the forward and inverse problems showed astonishing levels of accuracy.Bar-Sinai et al.(2019) presented a similar study where the emphasis was on learning data-driven discretizations that are best suited to a PDE with certain boundary conditions.A related study combining deep learning and PDEs was presented by Sirignano and Spiliopoulos(2018) where the authors introduced a so-called deep Galerkin method (DGM).The proposed method was applied to differentPDEs.This method was also applied to application problems such as in quantitative finance and statistical mechanics, governed by the Black-Scholes and Focker-Planck PDEs,respectively(Al-Aradi et al.,2018).The application areas are increasing rapidly with dizfferent variations in the general methodology.A deep learning-based solution of the Euler equations for modeling high-speed flows was presented by Mao et al.(2020) where physics-informed neural networks were used for forward and inverse problems.Deep learning for computational fluid dynamics,in particular for vortexinduced vibrations,was presented by Raissi et al.(2019b).A related work for predictive large-eddy-simulation wall modeling was presented by Yang et al.(2019).The solution of time-dependent stochastic PDEs using physics-informed neural networks by learning in the modal space was demonstrated by Zhang et al.(2019a).A conceptual framework for theory-guided deep learning was presented by Karpatne et al.(2017).Application of deep learning,with physics-informed recurrent neural networks,to fleet prognosis was presented by Nascimento and Viana(2019).Bending analysis of Kirchhoff plates using a deep learning approach was shown by Guo et al.(2019).Deep learning-based study of linear and nonlinear diffusion equations to learn parameters and unknown constitutive relationships was presented by Tartakovsky et al.(2018).Other recent and related studies are those by Huang et al.(2019), Tipireddy et al.(2019), Yang and Perdikaris (2019), Zhang et al.(2019b), Zheng et al.(2019), Jia et al.(2020), Meng and Karniadakis (2020), Sun et al.(2020), and Xu and Darve (2020).While the neural network architecture used in many studies is a feed-forward network with the desired number of layers and hidden units,a recent study applied convolutional neural networks for the solution of the Poisson equation with varying meshes and Dirichlet boundary conditions (Özbay et al., 2019).
Soil consolidation coupled with equilibrium equations constitutes the foundation of numerical modeling in geomechanics.One of the greatest challenges in numerical modeling in geotechnical engineering is the optimization of material and model parameters and faster inverse analyses for parameter determination.This is especially significant when performing large-scale simulations with complex constitutive models.Physics-informed deep learning models can be used to enhance such simulations where they can be applied in both forward and inverse problem settings.Another important application of physics-informed deep learning models is faster numerical prediction for digital twins where examples in geotechnical engineering include monitored foundations of critical infrastructure, geotechnical large-scale experiments and monitored slopes.To this end,the potential offered by physics-informed deep learning models can be demonstrated through application to one-dimensional (1D) consolidation, one of the most ubiquitous problems in geomechanics.Even though 1D consolidation involves only a single governing equation and only one material parameter(the coefficient of consolidation), the concept can be upscaled for problems in geomechanics involving coupled governing differential equations with several material and model parameters.Analysis of soil consolidation and settlement is an important problem in geotechnical engineering.The theory of consolidation describes fluid flow and excess pore water pressure dissipation in porous media,or particularly soils in geotechnics.The pioneering works of Terzaghi and Biot have contributed the most to the theory (Biot,1941; Terzaghi et al.,1996), from first formulation for a 1D case to later generalization for three-dimensional cases.Analytical solutions exist for the solution of the governing equation for 1D cases(Verruijt, 2013).For complex materials or higher-dimensional problems, numerical methods such as the finite difference method and the finite element method are applied (Schrefler,1987).For a soil layer or layers sustaining loads in initially undrained conditions, the process of consolidation determines how long it takes for excess pore pressures to dissipate and how much settlement will occur.Good estimates on the degree of consolidation and settlement highly depend on the accuracy of the material parameters determined from laboratory tests and the solution method used, whether analytically or numerically.
This paper presents a study on the application of physicsinformed deep learning model for 1D consolidation.The governing equation for the problem is first discussed briefly.The deep learning model for the governing PDE is then described.The problem is studied both for forward and inverse problems and the results from these are presented subsequently.Resources related to this work can be found on the author’s GitHub page here.
2.Governing equation
The theory of consolidation describes the dissipation of fluid from a porous medium under compressive loading,thereby causing delay of the eventual deformation of the porous medium.The governing equation for 1D consolidation is given by
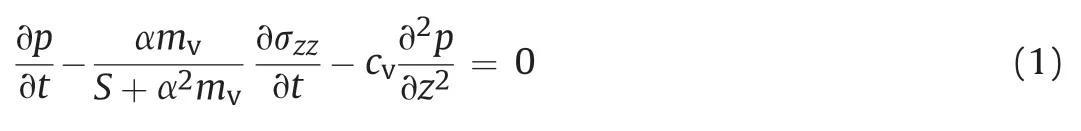
where p is the pore fluid pressure,α is the Biot coefficient,S is the storativity of the pore space, mvis the confined compressibility of the porous medium,σzzis the vertical effective stress,and cvis the coefficient of consolidation.The classical 1D consolidation problem is that at time t =0,a compressive load in the direction of fluid flow is applied and the load is maintained for t >0(Verruijt,2013).This implies that, for t > 0, the stress σzzis constant, i.e.with a magnitude q.Thus,we can reduce the general governing equation in Eq.(1) as

The first equation in Eq.(2) establishes the initial condition for the 1D consolidation problem where at t =0,the total vertical load is carried by the pore fluid and any fluid dissipation does not yet occur from the porous medium.The second equation governs the dissipation rate of the pore fluid as a function of both time and spatial dimension.This equation may be solved for various drainage boundary conditions (Fig.1) at the top and bottom of the porous medium through either analytical or numerical methods.Weconsider an analytical solution here for two different drainage boundary conditions, which are described in a later section.

Fig.1.One-dimensional consolidation.
3.Deep learning model
In this section,the neural network architecture is first discussed and the approach for applying a physical constraint, based on the governing 1D consolidation equation,is then presented.Automatic differentiation is briefly discussed.The model training procedure and the hyper-parameters that are controlled during training are also presented.
3.1.Neural network architecture
A fully-connected deep neural network with the desired number of hidden layers and hidden units is used as a model to be trained with the 1D consolidation problem.An illustration of the neural network architecture is shown in Fig.2.For the 1D consolidation problem herein, the input layer provides inputs of (z, t)values from the training data, which usually include initial and boundary condition data.The details are discussed in forward and inverse numerical example sections later.The neural network with the desired number of hidden layers and hidden units predicts the excess pore pressure,which is then used to compute the loss based on the excess pore pressure training data.The neural network also includes a physical constraint based on the governing 1D consolidation equation,where the constraint is evaluated using automatic differentiation,briefly discussed in a sub-section below.The neural network is designed to optimize both the training loss and the physical constraint.
3.2.Automatic differentiation
A key part of the deep learning model for the problem here is automatic differentiation.It is important to not confuse automatic differentiation with other methods of computing derivatives in computer programs.There are four ways of computing derivatives using computers (Baydin et al., 2017): (i) manually obtaining the derivatives and coding them; (ii) numerical differentiation using finite difference approximations; (iii) computer-based symbolic differentiation and subsequent evaluation based on the algebraic expressions; and (iv) automatic differentiation, which is used herein.Like the other methods, automatic differentiation provides numerical values of derivatives obtained using the rules of symbolic differentiation but keeping track of derivative values instead of obtaining the final expressions.This approach of tracking derivative values makes automatic differentiation superior to the two most commonly used methods of computing derivatives, namely numerical differentiation and symbolic differentiation.Automatic differentiation exploits the fact that any derivative computation,no matter how complex, is composed of a sequence of elementary arithmetic operations and elementary function evaluations.It applies the chain rule repeatedly to these operations until the desired derivative is computed.Such an approach for computation makes automatic differentiation to be accurate at machine precision and computationally less demanding than other methods.Once a deep neural network is constructed for 1D consolidation with the pore pressure as the output variable and the spatial and temporal coordinates as inputs, automatic differentiation is used to estimate the derivatives involved in the governing equation based on the universal mathematical expression established by the neural network.For this purpose, the automatic differentiation capability in TensorFlow is utilized.TensorFlow is an open-source software developed by the Google Brain team at Google and it is a symbolic math library that can be use d for different tasks such as data flow,differentiable programming and machine learning (Abadi et al.,2016a,b).It provides an application programming interface (API)for automatic differentiation by recording all operations and computing the gradients of the recorded computations using reverse mode differentiation.The Python-based open-source library for neural networks called Keras, which has been integrated in TensorFlow in the latest versions, is used for implementation of the deep learning model here.The advantage of Keras with TensorFlow as the back-end is that it is user-friendly, modular, extensible, and allows for a faster experimentation for deep learning(Gulli and Pal,2017).
3.3.Model training and hyper-parameters
The deep learning model training is performed in slightly different ways for forward and inverse problems.However, the model hyper-parameters in both cases are adjusted in a similarway.For forward problems, the training data involve initial and boundary condition data, i.e.a pair of initial and boundary (z, t)values and the corresponding excess pore pressure values p(z, t).The model predicts the excess pore pressure value^p for a given data point.The training loss is calculated as a mean squared error from:

Fig.2.Illustration of the neural network architecture with input, hidden and output layers.The activation function used at the hidden units is tanh(x), where x denotes the total weighted and bias-added input to the hidden unit.Automatic differentiation is used to determine the partial derivatives in the governing equation and is used as a physical constraint to optimize together with the prediction error based on training data.The number of hidden layers and hidden units in this figure is for illustration only,and the actual number of hidden layers and hidden units used for different cases are discussed in a later section.

where N is the number of training data, and (zk, tk) represents the training data point.The physical constraint based on the governing PDE is applied at randomly generated collocation points(zc,tc).The collocation points are generated using a Latin hypercube sampling strategy where the bounds of the original training data are taken into consideration.The physical constraint is evaluated at the collocation points based on the predicted excess pore pressure using automatic differentiation:

The constraint loss is calculated as a mean squared error from the following equation:

where Ncis the number of collocation points, and (zc,k, tc,k) represents a data point from the collocation points.The total loss from training and the physical constraint is defined as

which is minimized by the model optimizer.For inverse problems,the training procedure and loss evaluation are mostly similar with some differences.A larger size of (z, t) training data is used and collocation points are not generated in this case.This implies that automatic differentiation for the physical constraint is evaluated at the original training data points and the coefficient of consolidation is defined as a trainable parameter:

where cvtis the trained value of the coefficient of consolidation updated during each step.An additional trainable model variable or weight wcv, associated with the coefficient of consolidation, is introduced in the neural network and is used to evaluate cvtbased on an exponential function to always guarantee positive values during training:

The hyper-parameters tuned during training, both for forward and inverse problems, include the number of hidden layers, number of hidden units, batch size and learning rate.The batch size is adjusted to control the number of samples from the training data that are passed into the model before updating the trainable model parameters.The total loss here is minimized using the Adam optimizer where its associated learning rate is tuned during the training process.After training, the model is used to predict the pore pressures (and the coefficient of consolidation for inverse problems) for given input data.The model is improved by making the necessary adjustments for bias-variance tradeoff.If the model is observed to have high bias, the neural network architecture(numbers of hidden layers and hidden units)is adjusted and/or the model is trained longer.In case of high variance, the amount of training data is increased and/or the neural network architecture is adjusted.Regularization techniques can also be used for decreasing variance,but for the models trained in this paper,no regularization is used.
4.Forward problems
The problem considered here is a classical 1D consolidation problem,usually referred to as Terzaghi’s problem,as illustrated in Fig.3.The problem examines the dissipation of excess pore pressure with time from the soil column due to the application of a surcharge load of magnitude poat the top boundary.This numerical example is studied for two drainage boundary conditions: with only the top boundary drained and with both the top and bottom boundaries drained.The training data for forward problems are selected to include initial and boundary condition data,as shown in Fig.4.The nodes shown in the figure are for illustration only and the actual numbers of nodes and time steps depend on the spatial and temporal discretization used to obtain the analytical solution to the problem.The total number of training points is divided into batches during training by using a specified batch size.The results from this numerical example for the two different boundary conditions are presented in the following sub-sections.
4.1.Consolidation with a drained top boundary
The first case considered is a variation of Terzaghi’s problem where excess pore pressure dissipation is allowed at the top boundary only, i.e.the bottom boundary is considered impermeable.These boundary conditions are expressed mathematically as

The initial condition is p = pofor t = 0.The analytical solution for the excess pore pressure as a ratio of the initial value is given by(Verruijt, 2013):where h is the so-called drainage path which in his case is equal to the total height of the domain, i.e.h =H.The spatial coordinate z can be chosen to have its origin either at the top or at the bottom with positive coordinates in the domain.For the boundary conditions in this case, we have 0 ≤ z ≤ H.
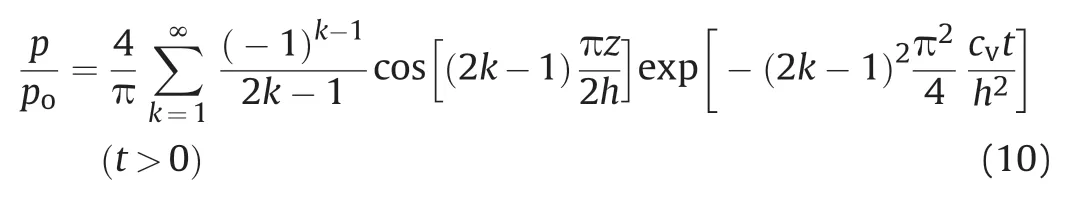

Fig.4.Initial and boundary condition training data for forward problems.The total number N of training data points (z, t) depends on the spatial and temporal discretization used to obtain the exact solution.The training data are shuffled and divided into batches according to a specified batch size during training.
For a numerical example, let us consider the height of the 1D domain to be H =1 m and the coefficient of consolidation of the soil as cv=0.6 m2/a.The exact solution based on the analytical solution is obtained for t = 1 a using a spatial discretization with Nz= 100 and a temporal discretization with Nt=100.As illustrated in Fig.4,the initial and boundary data, z, t, and p, are extracted from the exact solution as training data.The inputs to the neural network are the values of(z,t)where the model predicts a pore pressure value^p as an output, which is then used to calculate the training loss.
A neural network with 10 hidden layers and 20 hidden units at each layer is used as the model to be trained.The spatial and temporal derivatives of the predicted pore pressure,as they appear in the constraint equation, are determined at selected collocation points using automatic differentiation in TensorFlow.The collocation points are generated using the Latin hypercube sampling strategy and for example here Nc=10,000 collocation points are generated.After the derivatives of ^p with respect to the collocation points are determined, the constraint loss is calculated.A combination of training and constraint losses, as defined in Eq.(6), is minimized using the Adam optimizer for the desired number of epochs.The learning rate for the optimizer and the batch size used for training are 0.001 and 100,respectively.The model training was performed on an NVIDIA Tesla K80 GPU and for the hyperparameter combinations used here, the model training time for 10,000 epochs was about 12 min.Models with lower numbers of hidden layers,hidden units and epochs take lesser time for training.
The final model trained using the initial and boundary data,and constrained at the collocation points according to the governing equation, is used to predict the excess pore pressure for spatial and temporal points of the model domain.Prediction based on a trained model takes only a fraction of a second.The results obtained from the analytical solution and model prediction are shown in Fig.5 in terms of color plots on a two-dimensional grid from the(z,t)data.The color plot is obtained by interpolation of the nearest excess pore pressure values from the actual grid points and is chosen here only for visualization convenience.As can be seen from the color plots of the analytical solution and model prediction, the deep learning modelpredicts the excess pore pressure values at the interior grid points reasonably well just based on initial and boundary training data.This demonstrates the remarkable accuracy of the physical constraint enforced through automatic differentiation in the deep learning model.A closer comparison of the analytical solution and model prediction is shown for selected time steps in the plot in Fig.6a.The time steps used for comparison are shown in the top plot in Fig.5.The results show a remarkably good agreement.The L2norm of the relative error is expressed as follows:

Fig.5.Results from analytical solution and model prediction in terms of color plots on(z,t)grid for a drained top boundary.The color plots are obtained using interpolation with the nearest available values.The batch size used for training the model is 100.

In this case,e was found to be 4.462×10-3.A plot of the mean squared errors versus number of epochs is shown in Fig.6b.The plot shows the total mean squared error as well as the mean squared errors of the training and constraint losses.Mean squared error values in the order of 10-5are obtained near the end of the training.
To show how the performance of the model varies and for comparison purposes,different combinations of number of hidden layers and number of hidden units are analyzed.The results are presented in Table 1.The results show that a shallower network with smaller number of hidden units per layer performs poorly compared to deeper networks in terms of model performance as measured by the relative L2error in the predicted pore pressure.The results obtained for a network with 10 hidden layers and 20 hidden units at each layer are considered satisfactory.
4.2.Consolidation with drained top and bottom boundaries
When both the top and bottom boundaries are permeable,excess pore pressure can dissipate through both boundaries.Mathematically, this boundary condition is expressed as

The analytical solution to Eq.(10) still holds in this case where the drainage path is half of the height of the sample,i.e.h =H/2,as the pore fluid is allowed to dissipate through both the top and bottom boundaries.This case is equivalent to stating that there is no pore fluid flow at the center of the sample.Thus,the origin of the spatial coordinate is defined at the mid-height of the domain and we have -H/2 ≤ z ≤ H/2.

Table 1Relative L2 error in the model predicted pore pressure for different combinations of number of layers and number of hidden units.
The numerical example in the previous section is considered here again with the same model geometry but with different boundary conditions,i.e.with drained top and bottom boundaries.In addition,the coefficient of consolidation in this case is assumed to be cv=0.1 m2/a for the same model height,considering the faster consolidation as a result of both boundaries being drained.The analytical solution is again obtained using Nz= 100 and Nt= 100.The initial and boundary data are extracted in a similar way as in the previous case for training the model.The hyper-parameters of the neural network model are set to be similar as well.A deep network with 10 layers and 20 hidden units at each layer is used.The number of collocation points and the learning rate for the optimizer(Adam)are 10,000 and 0.001,respectively.A batch size of 100 is used here as well.
Grid color plots comparing the analytical and model predicted solutions are showninFig.7.We againobservea goodperformanceby the deep learning model in predicting the excess pore pressure at the interior grid points.A closer comparison of the excess pore pressure for selected time steps is shown in Fig.8a.The time steps selected for comparison are shown in the top color plot in Fig.7.We see a very good agreement between the analytical solution and the deep learning model prediction.The L2norm of the relative error between the analytical and predicted solutions in this case is found to be 2.62×10-3.Fig.8b shows the evolution of the mean squared error with the number of epochs for the total mean squared error as well as the mean squared errors for the training and constraint losses.
5.Inverse problems
The second class of problems considered are inverse problems where we aim to find material/model parameters used in analysisbased on a given solution to the problems.For our problem described herein, the aim is to determine the coefficient of consolidation used in an analytical solution given the excess pore pressure as a function of space and time, i.e.p(z, t).The deep learning model is trained based on training data randomly selected from the whole analytical solution, as shown in Fig.9.The size of the training data may be adjusted as desired but a limited sample size is usually sufficient for training to obtain good model prediction capabilities.Before training,the training data are shuffled and divided into batches based on a specified batch size.The main feature that differentiates inverse models from forward models,in the context of our problem here,is the fact that a trainable variable in addition to the default model variables is required to keep track of the coefficient of consolidation.Thus,a trainable weight is added to the deep learning model to update the coefficient of consolidation after initialization using a random weight.The constraint function based on the governing equation, with the trainable coefficient of consolidation, is continuously optimized together withthe training loss.The following examples demonstrate this procedure numerically.It is worthwhile to mention that even though we are dealing with a simple demonstration using a 1D problem here, the approach has important implications in numerical modeling in science and engineering.Some of the potential applications of the methodology that could be mentioned are improved model reproducibility (given a certain numerical solution for a physical problem) and optimization of constitutive model parameters for complicated numerical simulations.Such important problems and applications may be addressed in a later study.
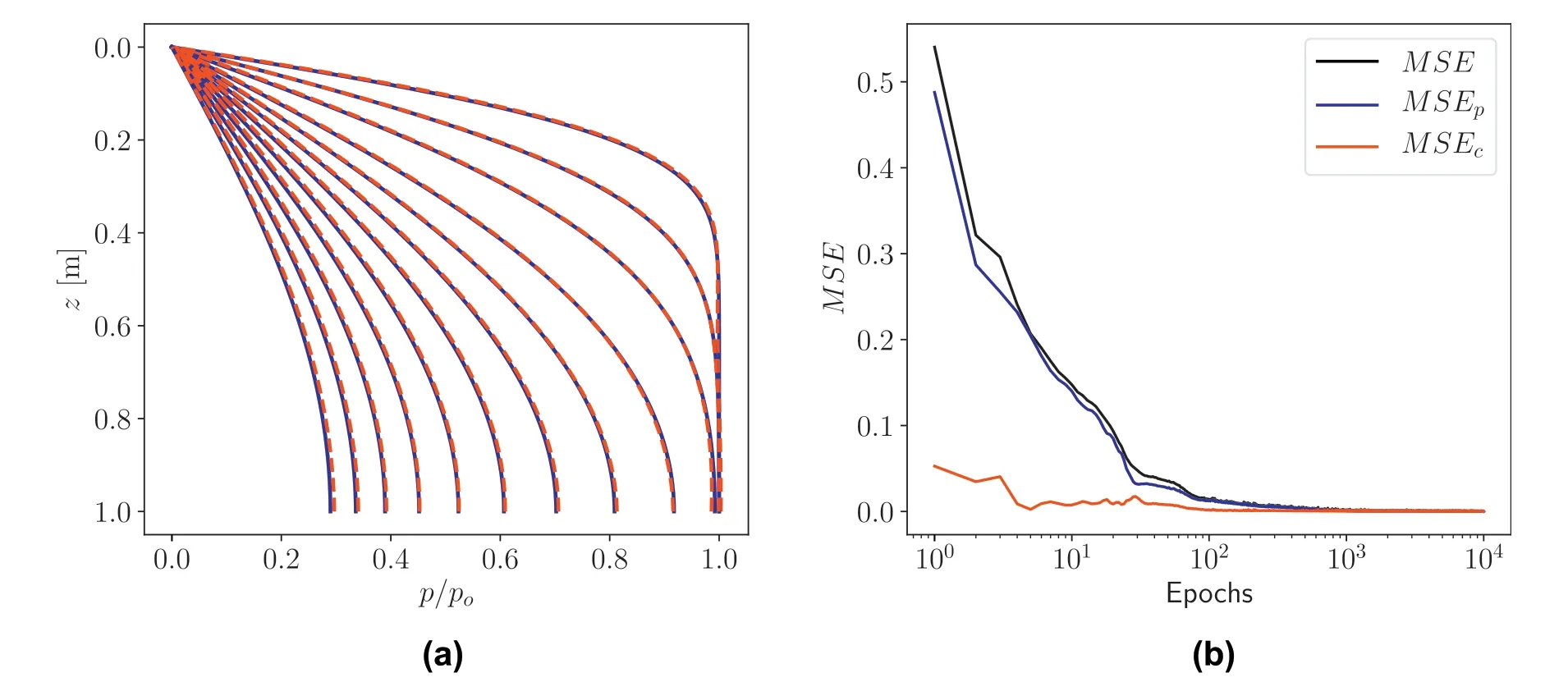
Fig.6.(a)Comparison of the excess pore pressure ratio between analytical solution(solid blue lines)and model prediction(red dashed lines)for selected time steps,for a drained top boundary.The time steps for comparison are those shown using vertical lines in the top plot in Fig.5.(b) Mean squared error versus number of epochs used for training.

Fig.7.Results from analytical solution and model prediction in terms of color plots on (z, t) grid for drained top and bottom boundaries.The color plots are obtained using interpolation with the nearest available values.The batch size used for training the model is 100.
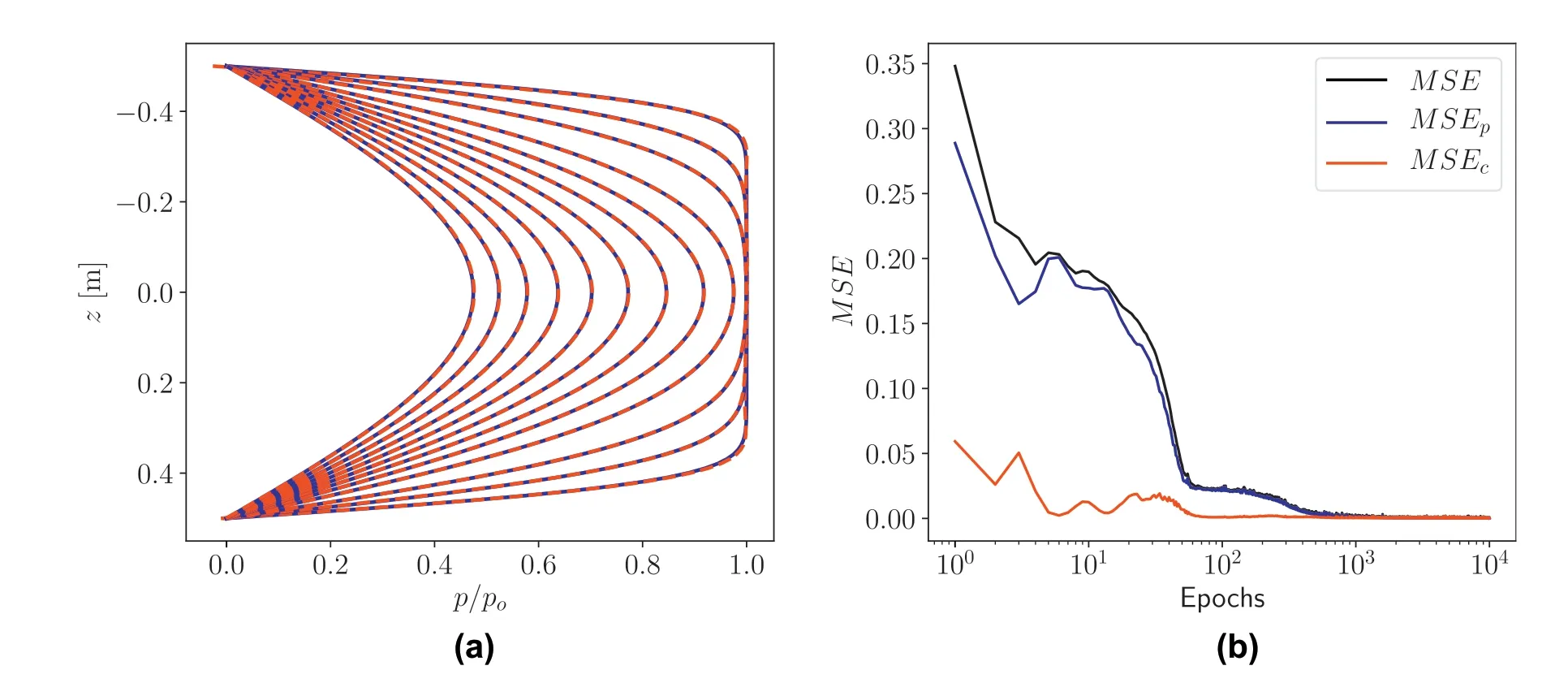
Fig.8.(a)Comparison of the excess pore pressure ratio between analytical solution(solid blue lines)and model prediction(red dashed lines)for selected time steps,for drained top and bottom boundaries.The time steps for comparison are those shown using vertical lines in the top plot in Fig.7.(b) Mean squared error versus number of epochs used for training.
5.1.Consolidation with a drained top boundary
The first example in the forward problems in Section 4 is considered here in an inverse setting with the same geometry and material/model parameters, i.e.a 1D model with a drained top boundary, a model height of H =1 m and a coefficient of consolidation of cv=0.6 m2/a is analyzed.The analytical solution is again obtained using Nz= 100 and Nt= 100.This implies that the number of(z,t,p)points in the exact solution is equal to 10,000.The neural network architecture is set up to have 10 hidden layers with 20 hidden units at each layer.A random sample of 2000 points is selected from the analytical solution data (with 10,000 available points) for training the neural network.
The training data are shuffled and divided into batches using a batch size of 200.The trainable weight corresponding to the coefficient of consolidation is initialized as wcv=0, implying an initial coefficient of consolidation of 1 m2/a.Adam optimizer is used to minimize the training and constraint losses with a learning rate of 0.0001.The model training for 10,000 epochs and for the combination of hyper-parameters described here takes approximately 8 min.The training was performed on an NVIDIA Tesla K80 GPU.
The results for inverse analysis of the problem with a drained top boundary are shown in Fig.10.The randomly selected training data points are shown in the top color plot as white dots.As in the case of the forward problem,the deep learning model predicts the excess pore pressure well from a limited training sample data and prediction takes only a fraction of a second.This again shows the remarkable performance of the physical constraint obtained using automatic differentiation.Fig.11a presents the evolution of the predicted coefficient of consolidation as the training progresses,as a function of the number of epochs.The final predicted value of the coefficient of consolidation is cv=0.597 m2/a,which is close to the expected value of cv= 0.6 m2/a with an absolute error of 3 × 10-3.Fig.11b shows the evolution of the mean squared errors as a function of the training epochs.

Fig.9.Randomly selected training data for inverse problems.The total number of training data points (z, t) is chosen depending on the specific problem under consideration.The training data are shuffled and divided into batches according to the specified batch size during training.
In a similar way as shown for forward problems, the model performance of different combinations of number of hidden layers and number of hidden units is investigated for inverse problems.The results are presented in Table 2.The results show that a shallower network with smaller number of hidden units per layer performs poorly compared to deeper networks in terms of model performance as measured by the absolute error in the predicted coefficient of consolidation.The result obtained for a network with 10 hidden layers with 20 hidden units at each layer is considered satisfactory.
5.2.Consolidation with drained top and bottom boundaries
We consider again the numerical example in the previous section where both the top and bottom boundaries are drained.The model geometry remains similar but the analytical solution here is obtained using a coefficient of consolidation of cv=0.1 m2/a,which we aim to predict using the inverse deep learning model.We have 10,000 data points from the analytical solution based on Nz=100 and Nt=100, from where a training sample size of 2000 is randomly selected.The neural network has a similar architecture with 10 hidden layers and 20 hidden units at each layer.The other model hyper-parameters remain similar:the batch size is 200 and Adam optimizer is used with a learning rate of 0.0001.
The results for inverse analysis for drained top and bottom boundaries are shown in Fig.12.With a limited training sample,the model predicts the excess pore pressures throughout the grid with a good accuracy.The coefficient of consolidation predicted by the deep learning model is cv=0.0994 m2/a, which compared to the expected value of cv=0.1 m2/a implies an absolute error of 6 × 10-4.These results are shown in Fig.13a, which presents the evolution of the predicted coefficient of consolidation as a function of the number of training epochs.Fig.13b shows the mean squared errors(total,training and constraint)as a function of the number of training epochs.
6.Summary and conclusions
A deep learning model for 1D consolidation is presented where the governing PDE is used as a constraint in the model.Research on physics constrained neural networks has been gaining traction recently in the machine learning research community and the work presented here adds to that effort.Various application areas where the idea has been applied were briefly reviewed, indicating the potential in diverse science and engineering disciplines.
The deep learning model used here is a fully-connected sequential neural network.The neural network is designed to take the spatial and temporal coordinates as inputs and predict the excess pore pressure,which is a function of these parameters.A key feature of the neural network architecture here is automatic differentiation which makes physical constraint of the system possible, using the governing equation of 1D consolidation.The spatial and temporal derivatives of the predicted excess pore pressure are evaluated using the automatic differentiation capability in TensorFlow.Two classes of problems are considered:forward and inverse problems.For forward problems, the derivatives are evaluated at a certain number of collocation points which are generated using the Latin hypercube sampling strategy, with the spatial and temporal bounds of the actual model taken into consideration.This approach made training of the neural network using just the initial and boundary condition data possible with a remarkable degree of accuracy.For inverse problems,a larger size of randomly selected data is used for training the neural network and the derivatives according to the governing equation are evaluated at the training data points.The coefficient of consolidation is used directly for forward problems while it is left asa trainable parameter for inverse problems.For both forward and inverse problems,the total training loss is defined as a combination of the training and constraint losses.The mean squared error for the training loss is evaluated based on the model predicted excess pore pressure and the corresponding exact analytical solution.The mean squared error for the constraint loss is evaluated according to the governing PDE based on the derivatives evaluated using automatic differentiation.A model optimizer (Adam) is used to minimize the total mean squared error during training.For both classes of problems, the model hyper-parameters that are tuned include the number of hidden layers, number of hidden units at each layer, the batch size for training and the learning rate for the optimizer.The potential of the model is demonstrated using Terzaghi’s 1D consolidation problem with two variations: with only a drained top boundary and with drained top and bottom boundaries.The model resulted in remarkable prediction accuracy for both classes ofproblems; the pore pressure throughout the model’s spatial and temporal bounds was predicted well for forward problems and the coefficient of consolidation was predicted with a very good accuracy for inverse problems.

Fig.10.Inverse analysis results from analytical solution and model prediction in terms of color plots on (z, t) grid for a drained top boundary.The color plots are obtained using interpolation with the nearest available values.The white dots represent the randomly selected training data points and the sample size used is 2000.The batch size used for training is 200.
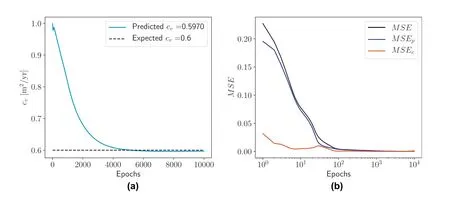
Fig.11.(a) Evolution of the predicted coefficient of consolidation as a function of the number of training epochs, for a drained top boundary; and (b) Mean squared error versus number of epochs used for training.

Table 2Absolute error in the predicted coefficient of consolidation for different combinations of number of hidden layers and number of hidden units per layer.
While the application presented here is a simple 1D consolidation problem,the implications of such a deep learning model are far greater.Even though 1D consolidation involves only a single governing equation and only one material parameter (the coefficient of consolidation),the concept can be upscaled for problems in geomechanics involving coupled governing differential equationswith several material and model parameters.The efficiency demonstrated for forward problems indicates the potential for predicting numerical solutions faster using deep learning models trained using a very limited amount of data but with a very good accuracy because of the physical constraint.This could have a huge potential for digital twins where faster real-time numerical prediction is desirable.The potential for predicting material parameters,as demonstrated using inverse problems,could be very useful in numerical model reproducibility and optimization of constitutive material and model parameters for complex numerical models.A faster and efficient design optimization can be achieved in computational geomechanics by exploiting this advantage of physics-informed deep learning models.
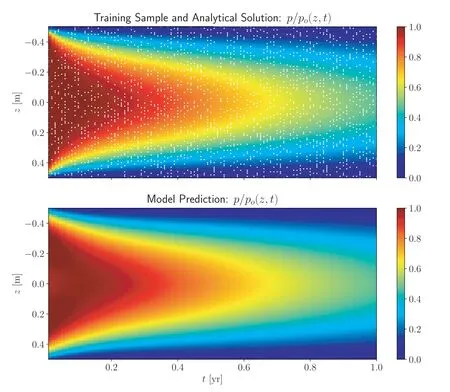
Fig.12.Inverse analysis results from analytical solution and model prediction in terms of color plots on (z, t) grid for drained top and bottom boundaries.The color plots are obtained using interpolation with the nearest available values.The white dots represent the randomly selected training data points and the sample size used is 2000.The batch size used for training is 200.

Fig.13.(a)Evolution of the predicted coefficient of consolidation as a function of the number of training epochs,for drained top and bottom boundaries;and(b)Mean squared error versus number of epochs used for training.
Declaration of competing interest
The author declares that he has no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgments
The research is supported by internal funding from SINTEF through a strategic project focusing on Machine Learning and Digitalization in the infrastructure sector.The author gratefully acknowledges the support provided.
 Journal of Rock Mechanics and Geotechnical Engineering2021年2期
Journal of Rock Mechanics and Geotechnical Engineering2021年2期
- Journal of Rock Mechanics and Geotechnical Engineering的其它文章
- Case study of a driven pile foundation in diatomaceous soil.I: Site characterization and engineering properties
- On the measurements of individual particle properties via compression and crushing
- Particle breakage of sand subjected to friction and collision in drum tests
- Permeability and setting time of bio-mediated soil under various medium concentrations
- Novel experimental techniques to assess the time-dependent deformations of geosynthetics under soil confinement
- Numerical modeling for rockbursts: A state-of-the-art review