
基于角度距离损失与小尺度核网络的表情识别*
2021-04-24 06:19苏志明
电讯技术 2021年4期
苏志明,王 烈
(广西大学 计算机与电子信息学院,南宁 530004)
0 引 言
人脸表情识别具有极大应用价值,是当前研究的热点之一。目前基于卷积神经网络(Convolution Neural Network,CNN)的静态图像人脸表情识别算法主要是对神经网络的关键三要素即数据、特征和损失函数进行改进,从而提升网络的分类性能。
(1)数据。主要包括对人脸表情静态图像的预处理和数据增强。数据增强主要通过剪切、仿射变换和增加对比度等方式增加训练样本数量,提升模型鲁棒性。
(2)特征提取。主要是通过改进CNN的网络结构来提升模型性能。杨等[1]改进了AlexNet,引入多尺度卷积提取多尺度特征和利用全局平均池化将低层特征降维跨连到全连接层分类,在CK+人脸表情数据集的准确率达到了94.25%。冯杨[2]提出了3×3小尺度核卷积神经网络,该网络结构简单有效。Liu等[3]将课程学习策略应用到卷积神经网络训练阶段,在FER2013数据集上达到了72.11%的识别准确率。
(3)损失函数。损失函数用来监督CNN的自我更新学习,决定了网络学习的方向。传统的卷积神经网络使用Softmax损失函数来优化类间特征的差异,但忽略了类内特征存在的差异性。为解决这个问题,许多新的损失函数被提出。Wen等[4]提出了Center损失函数,缩小了类内差距,有效聚集了类内簇。然而,Center损失函数没有关注类间差异。Cai等[5]对其改进,提出了Island损失函数,通过增加约束特征与相应类的距离范围,从而增大类间距离、缩小类内差异,提高了表情识别精度。
本文着重改善CNN特征提取和损失函数并使用数据增强来提高人脸表情识别准确率。
1 卷积神经网络
1.1 神经网络结构
本文的CNN结构由多层3×3小尺度核卷积层构成,如图1所示。图中R×R×C表示每层输出的C个分辨率大小为R×R的特征图。每个3×3卷积层均有BN(Batchsize Normalization)和Mish损失函数。第一个全连接层使用损失函数LIsland辅助监督类内特征聚集、类外特征隔离,加强了网络的特征提取能力。最后一层使用LArc-softmax和Llog_softmax分类损失函数对网络提取的高维特征预测出当前输入所属的真实类别。
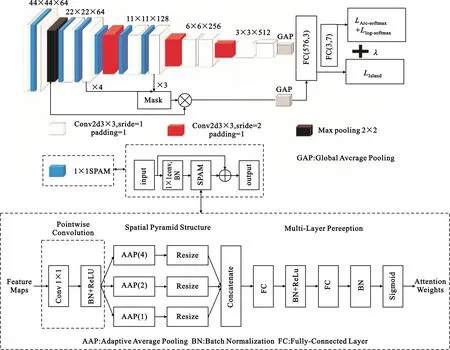
图1 卷积神经网络结构
在网络中分辨率为11×11及以上的特征图(除第一个卷积层外)的每个卷积层前添加1×1空间金字塔注意力模块[6](Spatial Pyramid Attention Module,SPAM)(具体结构见图1中间虚线框,由1×1卷积和SPAM构成的残差块),目的是加深网络和突出表情图像的显著区域,达到提升分类性能的目的。
在分类网络中,通常SE-Net(Squeeze-and-Excitation Networks)中的SE模块注重分配通道不同的权重来凸显图像的显著区域,但全局池化通常应用在7×7分辨率及以下的特征图,在较高分辨率应用全局池化会丢失过多细节信息。因此,在模型中引入空间金字塔注意力模块来凸显人脸表情图像的关键区域。SPAM由1×1卷积、空间金字塔结构和多层感知组成,见图1最下方的虚线框;1×1卷积是为了匹配通道数和集成通道信息。空间金字塔结构包括3个尺寸分别为1、2、4的自适应平均池化,将结构正则化和结构信息整合到一条注意路径中。多层感知从空间金字塔结构的输出中学习出一幅注意力图。
1.2 低层特征掩膜化
传统高低层特征融合直接将池化层的特征通过全局池化后输入到全连接层分类。低层特征有着丰富的细节信息,但噪声多且缺乏高级语义信息,而高层特征缺失细节信息,因此本文提出一种低层特征掩膜化方法,结构见图2。

图2 低层特征掩膜化结构
该方法先将高层特征图x1双线性插值上采样,然后通过1×1卷积逐层融合多层不同分辨率的次高维特征x2、x3、x4,再通过Softmax对通道取最大值得到掩码,最后将掩码和低层池化层的特征元素相乘得到输出,具体的计算表达式为
xfuse=Wfuse×concat(x3,Ups(x4))。
(1)
式中:Wfuse表示使用1×1卷积加性融合特征图的权重,Ups表示双线性插值上采样。xfuse表示最终融合的多层特征,然后将其通过Softmax得到通道权重,再与低层特征(Maxpool的输出)元素相乘得到掩膜结果xmask,如式(2)所示:
xmask=Mp⊗Softmax(xfuse)。
(2)
最后将低层特征掩膜化后的输出通过全局池化连接到全连接层分类。由于掩膜化的过程只有1×1卷积降维,并没有引入太多参数。每个1×1卷积后加入BN层平衡特征,1×1卷积还有一个作用就是将高层级的特征维度降维为次高级的特征维度。
1.3 网络参数配置
模型参数量越大,复杂度越高,模型参数计算公式为
K2×Ci×Co。
(3)
式中:K为卷积核大小,Ci为输入通道数,Co输出通道数。本文模型参数配置如表1所示,提出的模型参数量比VGG16少,复杂度更低。

表1 模型网络参数配置
1.4 Dropblock
为了避免模型过拟合,引入一种适用于卷积层的正则化方法即Dropblock[7]。该方法通过丢失掉相邻的连续整片区域(类似于3×3等卷积核所占区域大小)来提高网络模型的泛化能力。γ是一个表示丢失过程中的概率的超参数,服从伯努利分布,表达式为
(4)
式中:keep_prob为保持不丢失的概率,f_size为特征图大小,block_size为控制丢失区域大小的超参数,(f_size-block_size+1)确保丢失范围在边缘以内。伯努利函数表达式为
(5)
1.5 损失函数
1.5.1 Softmax损失函数
目前许多研究者致力于设计更精细的网络骨干结构换取性能提升,但是如果属于有监督范畴,损失函数是一个提升识别精度的值得深入研究的关键工作。传统的Softmax分类损失函数定义如下:
(6)
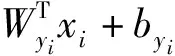
1.5.2 Island损失函数
为了缩小类内特征差异,Wen等[4]改进了Softmax并提出Center Loss,计算公式为
(7)
式中:cyi为第yi个类别的特征中心,xi表示全连接层之前的特征,m表示mini-batch的大小。公式(7)表示一个批次中的每个样本的特征离每个类别的聚类中心的距离的平方和越小,类内距离越小,也就是每个类的特征聚集度越高。Cai等[5]对Center Loss优化改进,提出了Island Loss,表示式为
(8)
式中:N为人脸表情总类别数量,本文N=7;ck和cj分别表示具有L2范数的‖ck‖2和‖cj‖2的第k个和第j个表情类别中心;+1使得约束范围为0~2,越接近0表示类别差异越大,从而优化损失函数使得类间距离变大;而Lc缩小类内距离,式(8)通过系数λ1来平衡类内和类间差异,本文λ1取10。神经网络最终的损失函数为
L=L1+βLIL。
(9)
式中:β为平衡两项损失函数的超参数。
1.5.3 基于角度距离的损失函数
Island Loss加大了人脸表情特征的约束,但仍将最后一个全连接层输入到Softmax损失函数对人脸表情的类别做出预测。通过对传统损失函数的分析可知,Island Loss的分类性能上限在一定程度上受Softmax影响。因此,可在Island Loss的基础上,通过基于角度距离损失函数改进Softmax损失函数,其核心思想就是用人脸识别中的Arc-softmax[8]辅助其他损失函数提高表情识别精度。Arc-softmax的计算公式为
LArc-softmax=
(10)
式中:s是缩放因子,cos(θyi+m)是角度距离,m决定了距离的大小。二分类情况下,Island和Arc-softmax的决策边界如图3所示,蓝色虚线表示分类决策边界。Softmax通过角度分类,Arc-softmax直接在角度空间通过决策余量m控制着分类决策边界的距离,从而加大类间距离,利于分类决策。

图3 二分类下 Island和Arc-softmax的分类决策边界
本文最终的基于角度距离的损失函数为
LA=LArc-softmax+λLIL+Llog_softmax。
(11)
式中:λ取0.01;Llog_softmax为对Softmax取对数,作为辅助分类损失函数,搭配NLLLoss(reduction=“sum”)使用。LA收敛速度快,分类效果好。
2 实验
CK+实验在 Pytorch框架上实现,处理器为英特尔酷睿i7-9750H CPU@2.60 GHz,显卡为NVIDIA GTX1650。采用AdaBound优化器,批处理大小为128,初始学习率为0.001,200个epoch后每个epoch学习率乘以衰减因子0.8。IslandLoss的学习率固定为0.5。Dropblock的keep_prob为0.9,block_size为3。为了不过多遮挡面部表情,Dropblock只在特征图分辨率为11及以上的卷积层使用,决策余量m=0.2,缩放因子s=20。FER2013实验在GTX2080Ti上进行,batch_size=128,初始学习效率为0.01,150个epoch后每8个epoch衰减0.9倍。先将原图片按照人脸区域预处理为48×48大小,训练时再随机剪切为44×44大小,测试时采用TenCrop(将图像沿左上角、右上角、左下角、右下角、中心剪切并水平翻转),取识别率均值作为最终的表情分类准确率。
2.1 数据集
CK+数据集[9]共 有593 个图像序列,其中带标签的表情序列有 327 个,从每个序列中提取最后3个帧,共 981 张。CK+数据集采用十折交叉训练,将数据集分为10份,每次9份训练,留1份测试。
FER2013[10]数据集共有35 888张人脸表情图像,其中训练样本28 709张,公开测试样本和私有测试样本各3 589张。采用私有测试样本测试,两个数据集人脸表情示意图如图4所示。

图4 不同数据集人脸表情示意图
2.2 实验结果
为了验证提出方法的有效性,将提出的不同方法加入网络,实验结果如表2所示。
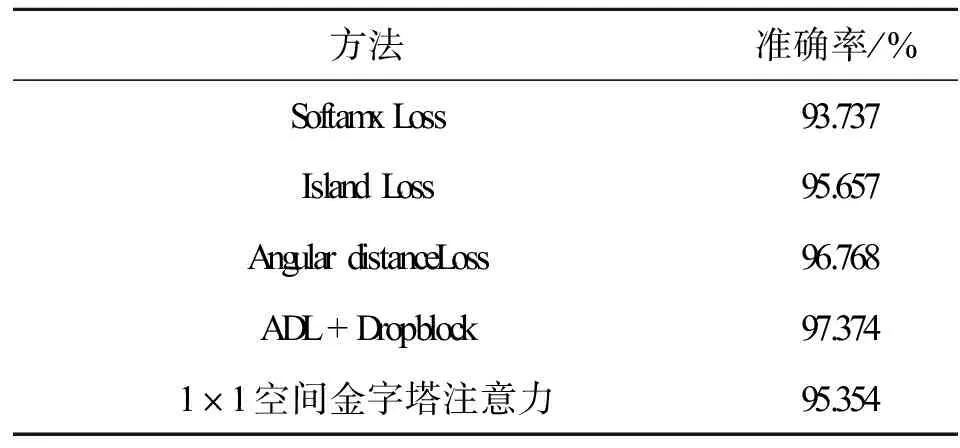
表2 不同方法在CK+的实验对比
使用Softmax分类,准确率为93.737%,而Island损失函数比Softmax损失函数高1.92%;使用Angular Distance Loss(ADL)分类,比Softmx高3.03%,比Island损失函数高1.11%。这说明提出的基于角度距离的损失函数对人脸表情特征有着更好的缩小类内相似性、增大类间距离的作用,具有更强的特征区分能力。Dropblock正则化的使用提高了网络的鲁棒性,表情识别准确率达到97.374%,较没加入之前整整提高了0.61%。表2中的前4种方法均在网络中加入了1×1空间金字塔注意力机制,最后1种方法是在Angular distance Loss的基础上去掉1×1空间金字塔注意力机制来进一步验证其有效性。实验表明,通过加入1×1空间金字塔注意力机制,网络模型分类精度提升了1.41%。
为了研究倒数第二层全连接层的不同特征输出维度对表情识别的影响,对其不同取值进行了多次实验(没有加入Dropblock),结果如表3所示。

表3 倒数第二层全连接层不同输出维度的表情识别准确率
当特征维度取3时,准确率最高。特征维度过高,角度距离损失函数不能有效聚类人脸表情特征,并且输出维度越高,类间距离区分度越小,从而影响网络的分类性能。
为了验证低层特征掩膜化的有效性,将特征图大小为3×3、6×6、11×11、22×22的最后一个卷积层的输出分别记为x1、x2、x3、x4,实验默认每个层级(除了全局平均池化GAP)都融合有x4的特征,GAP表示直接将池化层特征跨连到全连接层分类。最后在CK+数据集上将几个不同层级高层特征掩膜到低层的对比实验,实验结果如表4所示。当把x3的高层特征掩膜到低层特征时,冗余特征最少,准确率最高。

表4 融合不同层级特征的对比实验
为了进一步验证本文方法的有效性,在同样的 FER2013数据集和 CK+数据集上,将本文方法与当前其他表情识别方法相比较,结果如表 5 所示。

表5 不同算法的表情识别率对比
由表5中结果可知,本文方法无论是在CK+数据集上还是FER2013数据集上均取得了更高的人脸表情识别精度。文献[1-2]使用传统的Softmax损失函数分类,没有提取到具有强区分度的特征,分类效果不明显。文献[3]将课程学习策略应用到卷积神经网络训练阶段,取得了较高识别率。文献[11]通过控制余弦值和输入特征图的大小来来改善 Softmax 函数,增强了特征区分度,提高了人脸表情识别率,但仍存在特征提取不充分的问题。文献[12]对输入图像分割出包含人脸表情的人脸关键区域以提高CNN识别率。本文算法识别率在CK+数据集上低于文献[3],但在FER2013数据集上高于文献[3],这表明本文方法更适合于数据规模大的复杂环境(光照条件、不同角度、头部姿态各异等)下人脸表情识别。通过与上述文献的对比分析,本文方法提取到了更完全且具有强分辨力的特征,从而获得了更高的识别率,证明了本文方法的有效性。
图5分别为 CK+和FER2013测试集表情分类的混淆矩阵。CK+数据集由于厌恶、悲伤表情数据量少,识别率较低。FER2013数据集存在遮挡、漫画脸和错误标注等,识别难度大,故整体识别准确率不高,仍有改进空间。
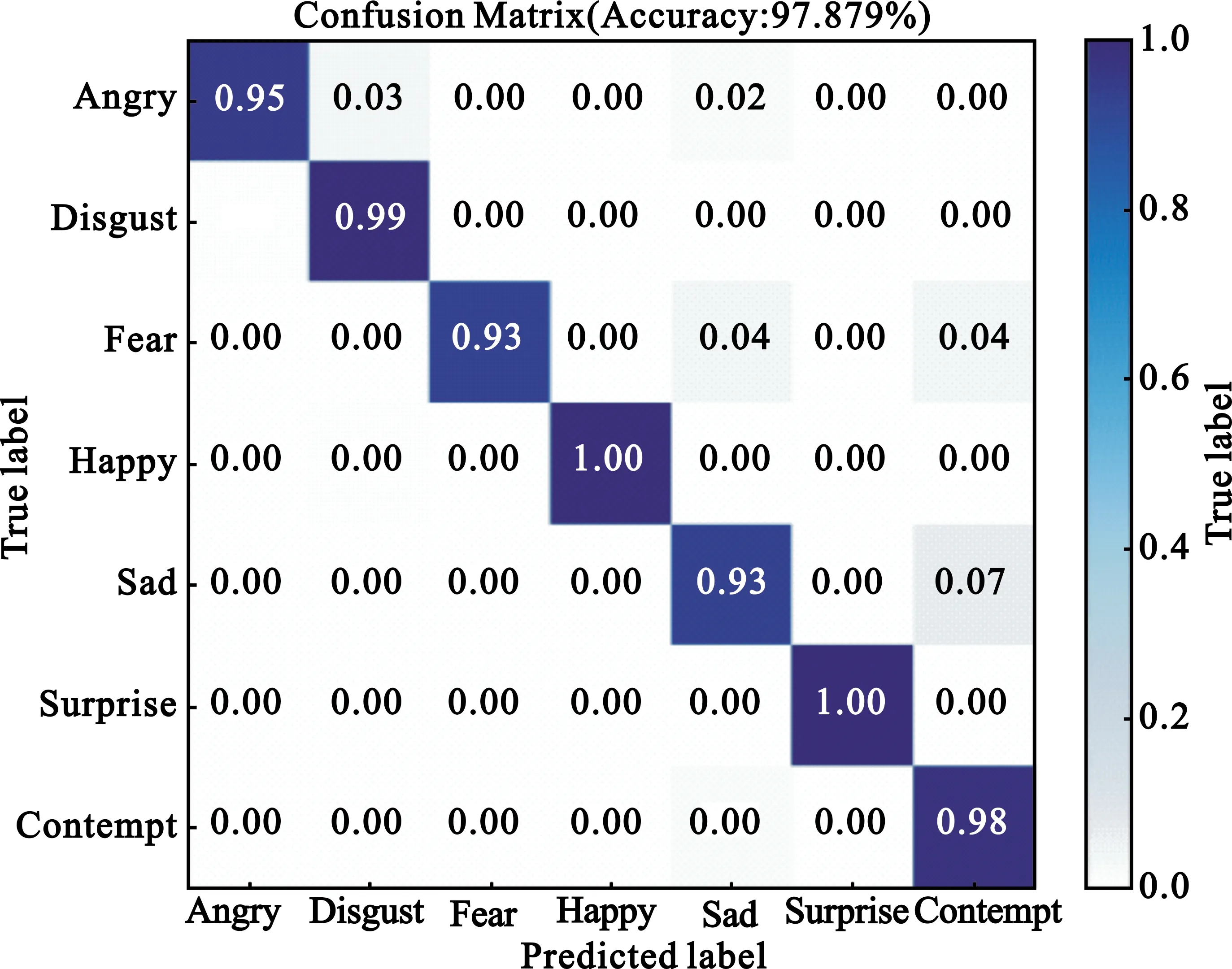
(a)CK+
3 结束语
本文基于小尺度核CNN模型,加入1×1卷积融合空间金字塔注意力,并提出了低层特征掩膜化,最后将掩膜后的特征通过全局池化输入到全连接层分类,结构简单有效。提出基于角度距离的损失函数对模型进行监督优化训练,可以学习到区分度明显的表情特征,即最小化类内距离,最大化类间距离。本文进一步探讨了倒数第二层全连接层的特征输出维度对表情识别准确率的影响。实验结果证明,相比于其他先进算法,本文方法在人脸表情识别任务中识别准确率较高,具有较强竞争力。特别地,在CK+数据集上,本文提出的角度距离损失函数,相对Softmax和Island损失函数分别提高了3.03%、1.11%。下一步工作将融合LBP特征以及改进LBP特征来提升表情识别率。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
北京航空航天大学学报(2021年9期)2021-11-02
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
人工晶体学报(2021年3期)2021-04-17
电子制作(2019年11期)2019-07-04
动漫星空(2018年9期)2018-10-26
北京航空航天大学学报(2018年1期)2018-04-20
制造技术与机床(2017年10期)2017-11-28
奇闻怪事(2014年5期)2014-05-13
