
一种基于注意力导向CNN 的晶粒缺陷检测方法
2021-04-22 14:08陈晓艳陈俭永朱奎锋苏艳杰赵春东张东洋
天津科技大学学报 2021年2期
陈晓艳,陈俭永,朱奎锋,苏艳杰,赵春东,张东洋
(1. 天津科技大学电子信息与自动化学院,天津300222;2. 天津福莱迪科技发展有限公司,天津300385)
在半导体晶圆加工成芯片的过程中,繁琐的工艺流程会导致晶圆产生各种类型的缺陷.目前采用的主要手段是用扫描电镜(SEM)捕获晶粒图像,通过人工识别合格和因表面缺陷而不合格的晶粒.这种方法耗时较长,且会出现人为因素引起的误判,准确率和效率都不高[1].针对主流8 寸和12 寸晶圆的生产工艺需求,如何快速准确地识别不合格晶粒,并根据缺陷类型挖掘缺陷产生原因,成为国内外芯片生产企业亟待解决的技术难题.
此前,机器视觉的方法进行缺陷检测一度成为研究热点,并取得一定效果.He 等[2]基于K 近邻规则计算数据点平方距离的总和,与设定阈值进行比较,判断该数据是否为缺陷点.Palma 等[3]分别在模拟和真实晶圆图像上进行缺陷检测,采用自组织特征图(SOM)作为分类器取得了良好的检测结果.Liu 等[4]使用光谱减法提取标准模板,通过灰度匹配大大提高了缺陷检测的速度和准确性.上述方法的关键在于如何提取到有效表达类型差异的缺陷特征,算法适应性不高,通常需要对特定需求重新设计.
近年来,卷积神经网络(convolutional neural network,CNN)的发展为解决图像分类问题带来了新的思路,并迅速而广泛地被应用到工业[5]、农业[6]、医疗[7]、金融[8]等多个领域,在计算机视觉[9]、语音识别[10]、文本处理[11]任务中表现尤为出色.CNN 具有强大的特征学习能力和非常强的适应能力,不需要任何特定于任务的特征处理,所以有学者将CNN 技术应用于晶粒的缺陷检测领域.2018 年,Nakazawa等[12]设计了CNN 模型,使用2.86 万张合成晶粒图训练,在6 600 张测试数据上的分类准确率为98.2%.2019 年,Nakazawa 等[13]又提出了一种使用深度卷积编码器–解码器神经网络架构检测和分割异常晶粒图缺陷图案的方法,可以从实际晶粒图中检测到看不见的缺陷图案.Yu 等[15]集成CNN 和稀疏去噪自动编码器学习有效特征,在仿真数据集和实际晶圆图数据集(WM-811K)上的总体准确率为94.81%.
尽管缺陷检测精度不断提升,但是大多数CNN模型结构复杂,层数过深而导致模型规模过大,从发展需求和发展趋势上,轻量化CNN 模型更易于往智能芯片移植,在非GPU 硬件资源上更容易部署,而且更加能满足智能边缘计算的发展需求.因此,本文提出了一种以注意力机制(attention mechanism)为导向的轻量化CNN 网络模型(Attn-Net),从实际生产线上获取大量晶粒图像,构建数据库,通过训练、验证及测试,与基于 CNN 的主流模型 VGG-16、ResNet-50 和MobileNet-v2 进行对比,证明了本文提出的Attn-Net 模型具有更好的检测精度和检测速度.
1 注意力导向CNN
1.1 网络结构
注意力导向CNN 模型Attn-Net 的网络结构如图1 所示.Attn-Net 由4 个卷积提取块和1 个注意力机制模块组成.
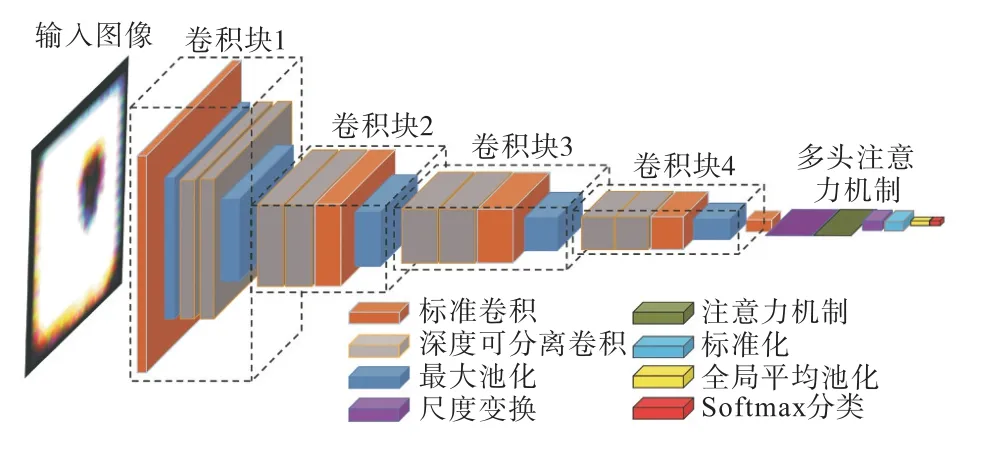
图1 注意力导向CNN网络结构Fig. 1 Structure of attention oriented CNN
输入图像大小为224×224.卷积采样过程中,为了保留图像特征,降低信息损失,卷积核的数目不断提高,图像通道数也逐渐增多.经过4 个卷积块后,图像的通道数由3 增加到64,再逐渐增加至512.最大池化层的步长为2,每经过一次最大池化,图像尺寸减半,图像的尺度逐渐降低,图像信息不断被压缩.首先,输入图像传入卷积块进行特征提取,得到卷积层输出的特征图;然后,对卷积层输出的特征图进行尺度变换,传入注意力计算层进行相应通道键值注意力计算,得到注意力机制筛选的特征图;最后,将此时的特征图标准化,输出至全局平均池化层,全局平均池化层将各通道特征图降维映射至Softmax层,输出分类结果.
1.2 优化策略
Attn-Net 的卷积块的基本组成是深度可分离卷积[16-17].深度可分离卷积对输入的每个通道先进行深度卷积(Depthwise Conv),然后通过1×1 的逐点卷积(Pointwise Conv)将输出通道混合.假定输入图像的宽、高和通道数为(W×H×C),卷积核的大小为(N1×N2),卷积核的数量为K.通过深度卷积和逐点卷积的拆分,可以将普通卷积的计算量压缩为
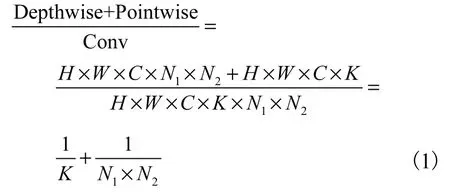
深度可分离卷积将空间特征学习和通道特征学习分开,计算量更低,卷积操作更为高效.
Attn-Net 在卷积层后加入了批标准化层(batch normalization,BN).对于输入的每一个最小批次(mini-batch)即δ ={ x1,x2,…, xm},BN 进行如下操作:
(1)求最小批次数据的均值

其中γ 和β 是需要被学习的参数.
批标准化层把每层的数据分布转换为均值为0、方差为1 的相同状态,能够加快网络的训练速度和收敛速度,避免梯度消失和梯度爆炸现象发生.同时,BN 层将每一个批次中所有样本关联在一起.因此,训练集中某个样本的输出取决于样本及这个样本同一批次的其他样本,网络的学习方向是随机的,这在一定程度上避免了过拟合.
继发于抗中性粒细胞胞浆抗体相关系统性血管炎的肥厚性硬脊膜炎1例报告 ……………………………………………………… 陈竹林,黄光,徐斌,等 124
在卷积层提取特征后,Attn-Net 使用全局平均池化层计算每个通道的特征图中所有像素的平均值,获得具有相同维数和类别数的特征向量,然后将其输入到Softmax 层中.与全连接相比,减少了卷积过程中大量的参数计算,也缓解了过拟合问题.
1.3 多头注意力机制
注意力机制[18]即为了充分利用有限的视觉信息处理资源,选择性地关注视觉区域中的特定部分,忽略其他可见信息.相较于卷积计算,注意力机制算法复杂度较低,额外引入的参数量和计算量较低,因其能够快速提取数据特征的内部相关性,被广泛用于图像处理[19]、语音识别[20]、自然语言处理[21]等任务中.本文也引入注意力以提升特征提取网络的性能.
注意力机制由 3 个要素即查询(Query)、键(Key)、值(Value)构成.注意力计算过程如图2 所示,给定目标的某一查询Q,计算该查询Q 和多个键K 的相似性或相关性,得出每个K 相应于V 值的权重系数.通过Softmax 归一化后,对权重系数和相应V 加权求和即可得到该查询Q 的注意力(Attention).
查询Q 的注意力可表示为

相似性计算方法包括点积、拼接、感知机等方式.放缩点积注意力的相似性计算为点积
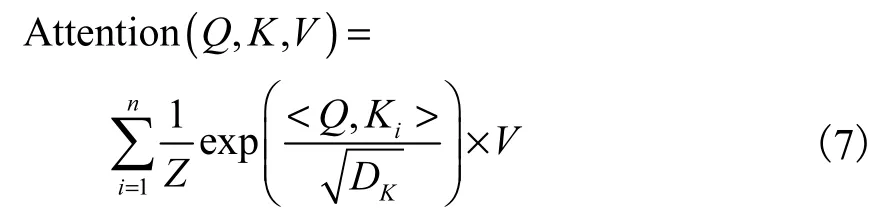
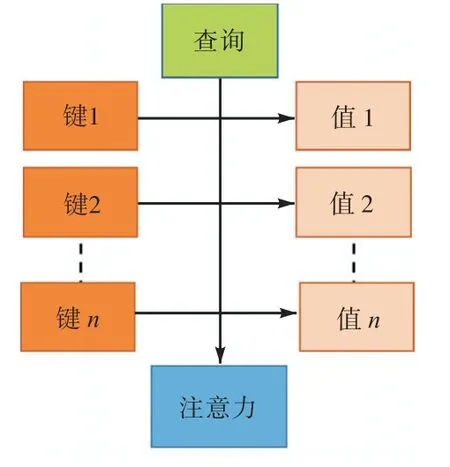
图2 注意力计算过程Fig. 2 Attention calculation process
多头注意力机制[22]是一种特殊的放缩点积注意力.如图3 所示,查询(Query)、键(Key)、值(Value)经过一次线性变换后输入到放缩点积注意力中.将h次Q、K、V 的放缩点积注意力结果拼接后,再进行一次线性变换得到多头注意力的输出.h 次Q、K、V 的参数是相互独立的.与放缩点积注意力相比,多头注意力机制算法复杂度较低,允许模型在不同的表示子空间里学习到相关的信息.
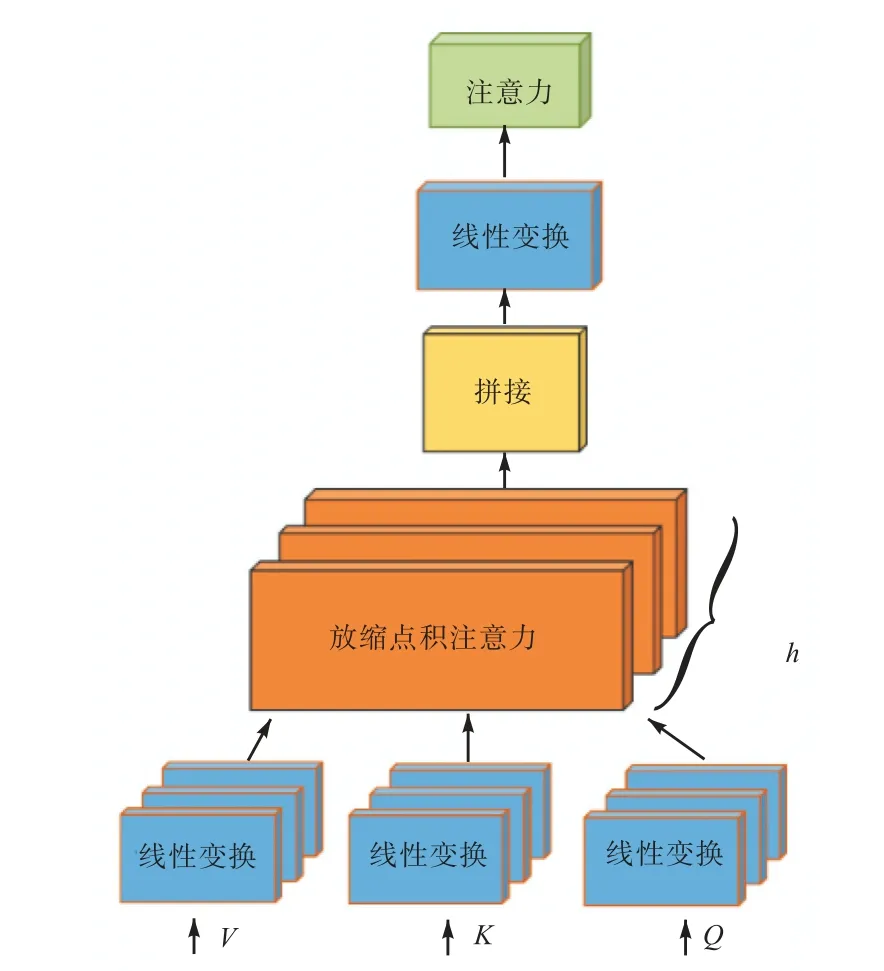
图3 多头注意力机制Fig. 3 Multi-head attention mechanism
2 实验及结果分析
实验软件环境:Python3.6 、TensorFlow-Gpu1.8.0、Cuda9.0、Keras2.1.4;硬件平台:Intel Core i7-9700K CPU、NVIDIA GeForce RTX 2060 GPU.
2.1 数据制备
实验室晶粒图像数据集[23]包含无缺陷晶粒图像和3 种常见的晶粒缺陷类型,如图4 所示.数据分布结构见表1.

图4 晶粒图像Fig. 4 Die images
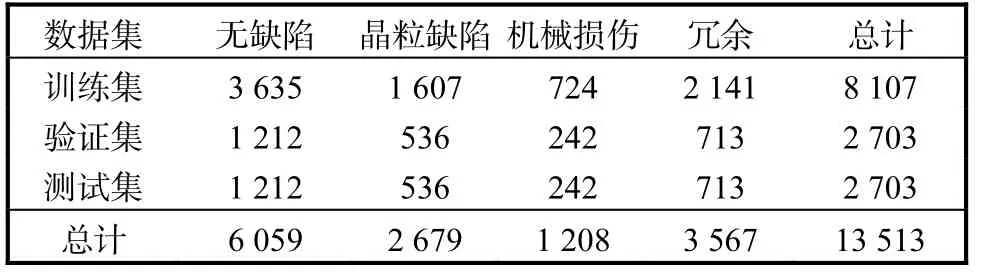
表1 晶粒图像数据分布Tab. 1 Distribution of die images
为了提升模型的泛化能力,在输入CNN 网络之前,对晶粒数据集进行了旋转变换、错切变换和随机缩放3 种数据增强处理.增强矩阵为

θ 为旋转变换角度,γ 为错切系数,μ 为缩放系数,A、B是旋转变换矩阵,C是错切变换矩阵,D是随机缩放矩阵.任意像素坐标x、y、z 增强处理后的结果为xu、yv、zw.
2.2 网络训练与检验
模型Attn-Net 的超参数设置见表2,训练过程中的损失值和准确率变化曲线如图5 所示.随着迭代次数的加深,模型的训练集损失和验证集损失逐渐降低,最终低于0.001;训练准确率和验证准确率逐渐提升,最终接近于1,这说明模型Attn-Net 正常收敛,训练过程未出现过拟合现象.

表2 Attn-Net超参数设置Tab. 2 Hyperparameter settings of Attn-Net
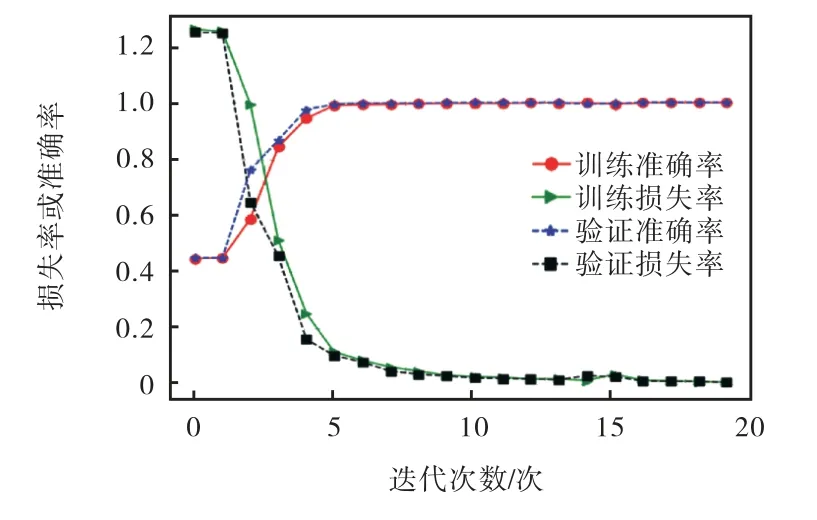
图5 训练集和验证集的损失率和准确率变化Fig. 5 Loss and accuracy of training set and validation set
图6 展示了Attn-Net 各个卷积块的特征图谱和注意力层的特征图谱可视化结果(为了比较,此处仅展示了32 个通道的图像).不同的通道提取到的特征是不同的,不同通道关注的位置和目标有差异.有的通道提取的只有噪声,而有的通道提取的是物理轮廓.从图6 可以看出:浅层卷积层提取到的特征图谱特征复杂度较低,可视化图像与输入图像相似.随着网络不断深入,模型逐渐提取从点、颜色到线段、边缘再到更高级的组合特征,特征属性越来越复杂,对应到可视化图像中,特征图谱越来越抽象,模型特征表达能力逐渐增强,特征拟合更加充分.
Attn-Net 卷积层和注意力层的类激活图(CAM)如图7 所示.CAM 获取到卷积层(注意力层)的输出和目标类别神经元相对于每一个通道的梯度,使用该梯度对每个通道进行加权,最后对通道求均值并归一化处理.CAM 可以指示图像每个位置相对于所考虑的类的重要程度.从图7 可以看出,在晶粒图像中,晶粒的矩形边缘贡献了最重要的特征,其次是矩形内部的区域信息.

图6 特征图可视化Fig. 6 Visualization of feature map

图7 类激活图可视化Fig. 7 Visualization of class activation diagram
2.3 性能测评
在晶粒图像数据集上,选取高精度模型VGG-16、ResNet-50 和轻量化模型MobileNet-v2 与Attn-Net 对分类精度、模型大小和检测时间进行测评,结果见表3.模型VGG-16、ResNet-50、MobileNet-v2 和Attn-Net 在2 703 张晶粒图像的测试集上的分类精度大致相同,均能达到99.9%以上.因为晶粒图像数据集中的缺陷类型的特征集中表现为角、线条和矩形轮廓,特征复杂度不高,4 个模型均能够有效提取并识别.图8 展示了Attn-Net 在测试集上的混淆矩阵,可以看出,Attn-Net 晶粒图像类内和类间的识别准确率仍能达到99%.这表明模型Attn-Net 能够满足晶粒缺陷检测精度的要求.
4 个模型中,模型VGG-16 的参数量最多.模型VGG-16 具有3 个全连接层,计算方式复杂,参数量超过了1 亿,模型大小为1.5 GB.模型ResNet-50 结构更为复杂,但省去了全连接层,参数量为23 792 612,模型大小为270 MB.模型MobileNet-v2使用扩张–卷积特征提取–压缩的轻量化网络结构,其参数量和模型大小都远低于模型VGG-16 和ResNet-50.模型Attn-Net 使用全局平均池化层代替全连接层,部分使用深度可分离卷积代替标准卷积,降低了参数量.相较于卷积结构,多头注意力机制模块的参数量和算法复杂度更低.因此,模型Attn-Net 的参数量最少,约217 万,模型也最小,约25 MB.

表3 模型性能测评Tab. 3 Model evaluation
与参数量和计算复杂度对应,模型VGG-16 和ResNet-50 的检测用时较长.轻量化模型MobileNetv2 网络计算方式更为简单,速度更快,用时1.35 s.模型Attn-Net 的优化策略降低了模型的参数量和计算量,检测用时最短,为1.26 s.
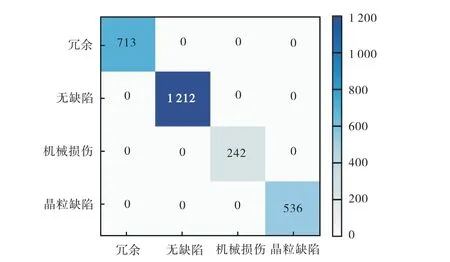
图8 混淆矩阵Fig. 8 Confusion matrix
模型VGG-16、ResNet-50、MobileNet-v2 和Attn-Net 的分类精度均超过99%.其中,模型Attn-Net 的参数量更低,模型更小,检测时间更短.因此,更适合部署至晶粒缺陷检测设备中.
3 结 语
本研究提出了一种注意力导向的新型CNN 模型Attn-Net,其最大优势是模型小,对硬件资源占用少,对缺陷识别快,而且集中不同的缺陷样本的识别准确率高.究其原因在于,其一是多个深度可分离卷积和标准卷积构成的混合卷积块能够更加快速地提取图像特征;其二是将图像特征的图谱采用多头注意力机制进行计算,相比卷积运算,具有降低算法复杂度和减少参数量的优势.在课题组前期研究[24]中,已对晶粒图像进行了轻量化模型识别与分类,取得了极快的检测速度.而本文提出的模型Attn-Net,融入了注意力机制,缓和了深度可分离卷积引起的精度损失,所以对机械损伤这一晶粒缺陷类别的识别精度显著提高,但是从测试速度上看,文献[24]的方法更具有优势.值得思考的问题是:在CNN 基础上的各种模型,精度和速度是两个相互制约的矛盾因素,精度的提高往往以损失速度为代价,反言之亦如此.今后将更加致力于如何将智能化的算法移植到应用层,在嵌入式芯片或其他终端上进行部署,真正发挥智能算法在各个应用领域中的优势.
猜你喜欢
金属热处理(2022年2期)2022-03-16
社会科学战线(2022年2期)2022-03-16
铀矿冶(2021年4期)2021-11-10
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
铝加工(2021年2期)2021-05-17
医学食疗与健康(2021年27期)2021-05-13
有色金属科学与工程(2021年1期)2021-03-04
成都信息工程大学学报(2021年6期)2021-02-12
健康体检与管理(2021年10期)2021-01-03
