
Closer:Scalable Load Balancing Mechanism for Cloud Datacenters
2021-04-14 10:12ZixiCuiPengshuaiCuiYuxiangHuJulongLanFangDongYunjieGuSaifengHou
China Communications 2021年4期
Zixi Cui,Pengshuai Cui,Yuxiang Hu,Julong Lan,Fang Dong,Yunjie Gu,Saifeng Hou
1 School of Electronic Engineering,Information Engineering University,Zhengzhou 450001,China
2 Science and Technology on Communication Networks Laboratory,Shijiazhuang 050081,China
3 61660 Unit of PLA,Beijing 100089,China
Abstract:Cloud providers (e.g.,Google,Alibaba,Amazon) own large-scale datacenter networks that comprise thousands of switches and links.A loadbalancing mechanism is supposed to effectively utilize the bisection bandwidth.Both Equal-Cost Multi-Path(ECMP),the canonical solution in practice,and alternatives come with performance limitations or significant deployment challenges.In this work,we propose Closer,a scalable load balancing mechanism for cloud datacenters.Closer complies with the evaluation of technology including the deployment of Clos-based topologies,overlays for network virtualization,and virtual machine (VM) clusters.We decouple the system into centralized route calculation and distributed route decision to guarantee its flexibility and stability in large-scale networks.Leveraging In-band Network Telemetry (INT) to obtain precise link state information,a simple but efficient algorithm implements a weighted ECMP at the edge of fabric,which enables Closer to proactively map the flows to the appropriate path and avoid the excessive congestion of a single link.Closer achieves 2 to 7 times better flow completion time(FCT)at 70%network load than existing schemes that work with same hardware environment.
Keywords:cloud datacenters;load balancing;programmable network;INT;overlay network
I.INTRODUCTION
With the prosperity of Internet and information technology,cloud computing platform becomes the national infrastructure construction as significant as water conservancy and electric power.Governments,enterprises,organizations and individuals have been hosting their business on cloud to improve efficiency and reduce costs [1].The cluster composed of VMs/containers provides a variety of services and contents for massive Internet users.The evolution of cloud computing virtualization also promotes the network virtualization in data center networks (DCNs)[2].Overlay virtual network(e.g.,VXLAN,NVGRE,STT)breaks through the limitations on the scale,identification and migration range of the VM clusters,covering the need of large-scale service cluster response,multi-tenant isolation and online migration of crossregional business.This trend also aggravates the conflict of performance requirements among distinctive applications [3].For example,cloud storage and disaster recovery desire network to provide burst high throughput,while online services,such as finance and games,have strict requirements in terms of long-tailed latency and bandwidth jitters[4].
To achieve high-throughput and low-latency communication,the switch-oriented topologies(e.g.,Leaf-Spine and Fat-Tree) are widely used for the physical carrier network of datacenters [5].These topologies follow the Clos architecture that provides large bisection bandwidth between any two endpoints.Typically,datacenters use ECMP algorithm for load balancing to adapt to the characteristic of multipath [1,5,6].ECMP randomly selects one from the available paths to traffic flow,making it highly susceptible to excessive congestion of local links caused by hash collisions of large flows[6,7].
Although a variety of works have been proposed from several different perspectives to address the shortcomings of ECMP,all of them come with significant deployment challenges and performance limitations that largely prevent their adoption [8].Purely centralized methods have been proved to be too slow for the volatile traffic patterns in datacenters[9].Hostbased schemes such as MPTCP [10]split each connection into multiple sub-flows by rebuilding the kernel network stack,but actually increase the burstiness of traffic and bring an additional burden to the endhost.Network-layer protocols(e.g.,CONGA[8]and HULA [11]) recursively implement link state awareness and route calculation in the data plane.Such radical revolutionary schemes require replacing every network switch (physical or virtual) that supports a new packet-processing logic with state-propagation[3].
Can we implement the dynamic traffic scheduling in apatchingmanner,so that it can be deployed quickly with the ECMP-based network but overcomes the defects of the congestion-oblivious method? We argue that the network virtualization edge (NVE) provides an ideal conduit to achieve this goal.As the innetwork switches are configured with standard ECMP feature,the NVE should recognize that 5-tuple header values used to identify different flows can be changed to influence the routes taken by the encapsulated packets.This has been implemented in Clove [3],where the virtual switch (vSwitch) in the source hypervisor would direct the traffic over other less congested paths if Explicit Congestion Notification(ECN)signal is received in reply message.However,Clove has to face up to two inadequacies.First,the ECN-based method is a stale and passive-defense model.It is too late to enhance system control when the link congestion has already happened.Second,Clove is not stable for large-scale networks as it offloads entire application into software switches,without any participation of the controller.It disobeys the vision of cloud providers for network visibility[12].
In this work,we propose Closer,a scalable loadbalancing mechanism for cloud datacenters.Closer tackles the problem by decoupling the system intocen-tralized route calculationanddistributed route decision.Enabled by INT technique,the switches insert the local congestion information into the packet header in turn.Then,the controller inputs the collected network state into the centralized routing algorithm for global optimal results.Subsequently,the updated entries are fed back to the data plane to make it adapt to traffic volatility in datacenters.The NVE proactively maps the traffic to appropriate path and avoids excessive congestion of a single link.More specifically,Closer implements the source routing when the packet is encapsulated by overlay gateway(ToR or vSwitch).The route the traffic takes through the network,used to be assigned randomly,now is selected in weighted ECMP fashion.Closer also introduces the concept offlowletto achieve fine-grained load balancing.It further weakens the impact effect of large flow,greatly improving the efficiency and stability of the load balancing system.
In summary,this paper makes the following contributions:
• We present a general load-balancing framework that is entirely compatible with the existing architectures and protocols in modern cloud datacenters.We take the advantage of Software-Defined Networking(SDN)to make the application comprehensibly configurable for network operator.
• We design Closer,a traffic scheduling algorithm that could be incrementally deployed at the edge of fabric without any modification on end-host.Closer realizes timely feedback loop to efficiently spread traffic across multiple paths,striking a balance between the control cost and responsiveness.
• We implement a Closer prototype by developing open source software projects,and provide an archetypal example for VXLAN network.It proves that Closer is very suitable for any hierarchy-based topology of cloud datacenters.
• We evaluate Closer against alternative schemes in our testbed.The experimental results show that it outperforms the state-of-the-art algorithm by 2x-7x in average FCT at high load,no matter the topology is symmetric or not.
II.BACKGROUND AND MOTIVATION
2.1 Challenges
Clos architecture is highly normalized and homogeneous.Figure1 shows a typically 2-tier Clos topology(henceforth calledLeaf-Spine).There are hundreds of high-bandwidth links across the spine-tier between every pair of leaf switches (ToR switch in Figure1),providing physical support for large amounts of traffic forwarding.The link speed in DCNs has grown from 1Gbps to 100Gbps in the past decade.However,with the rapid iteration of application architecture and service mode,such as resource disaggregate and heterogenous computing,the network architects can not improve the performance by simply increasing the link bandwidth[13].
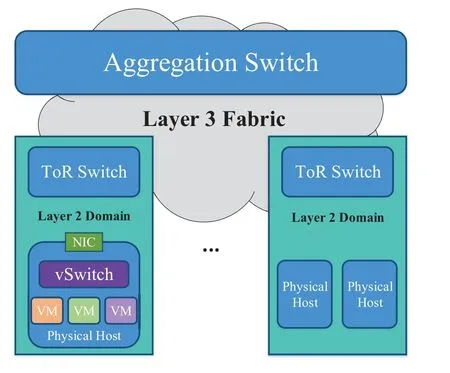
Figure1.Cloud DCN organized with Leaf-Spine topology.
Under the condition that both the network topology and the traffic distribution are symmetrical,ECMP should approach near-optimal load balancing within fabric [14].However,the symmetry of the model is likely to be destroyed because(i)the switches are heterogeneous as they are from several vendors;(ii) the shutdown of nodes/links occurs;(iii)the traffic distribution is uneven (more than 80% of VMs have never had communication,and 98% of VMs have throughput of less than 20Kbps)[15].Static routing policy is no longer fit with bursty and unpredictable datacenter traffic.How to detect link failures timely to reroute traffic? How to obtain network-wide congestion information for optimal load-balancing? How to minimize the table entries to be maintained in the data plane to optimize the forwarding delay? There are currently the most actively debated question in the networking community.
2.2 Motivation
There are many methods for determining which nexthop to use when routing with ECMP,while the hashthreshold is the simplest for making that decision.In this setting,each switch independently distinguishes different flows based on the packet’s header fields,and maintains a multipath table to identify available paths by next-hop.All flows that have the same destination address are aggregated as an ECMP group to improve the speed of lookup operations [16].Figure2 shows the pipeline of ECMP forwarding based on the hashthreshold.Suppose that there are totally 8 ports in the switch.Both Group-1 and Group-2 have their own destination prefix and multiple valid next hops.When the packet withdstAddr=10.0.2.1enters the ingress pipeline,the second rule in the IP forwarding table is matched.Thus,the packet will be mapped to the Group-2 that ranges from the 3th to the 6th entry in the multipath table.Next,the pipeline calls for the attaching processing action—performs a hash(e.g.,CRC16)over the 5-tuple fields that identify a flow,and then modulos the hashing results by the number of entries.Finally,the modulo result is added by the group’s offset,which obtains the index of the entry in the multipath table.In our example,it is10 mod 4 + 3=5.Thus,the egress port 7 is chosen as the outpost interface of the ingress packet.As such,the switch realizes the average of next hop within an ECMP group.This is the reason why ECMP has been criticized for a long time:all routing decisions made by single device only blindly pursue the equal cost in terms of the flows number,lacking the uniform evaluation metric for the following path.
However,if we consider the traffic scheduling of overlay network from the global perspective,some interesting features will be exposed to support the implementation of Closer.In the virtual fabric,both sides of communication must establish“tunnel”in advance between their own edge switch.In this context,a flow group consists of flows that are transmitted from the same source tunnel endpoint(TEP)to the same destination TEP.The source TEP appends to each packet an encapsulation header,which contains another“outer”5-tuple to be used to make multipath routing deci-sion.In particular,four elements of the 5-tuple —the source and destination TEP addresses,the transport protocol,and the destination port number—have been determined before communication.Therefore,there is a clear map between the source port and the route the packet takes through the network[3].In fact,the source TEP rotates the source port to realize the native ECMP load balancing in normal overlay protocol.Thus,leaf-to-leaf feedback for flow control is simple and natural for modern data centers [8].In designing Closer,we adds two new properties to the overlay gateway:(i) The source TEP is aware of a per-destination set of encapsulation-header transportprotocol source ports that map to distinct paths to the destinations.(ii)The encapsulation-header of normal traffic is extended to realize per-link congestion measurement.
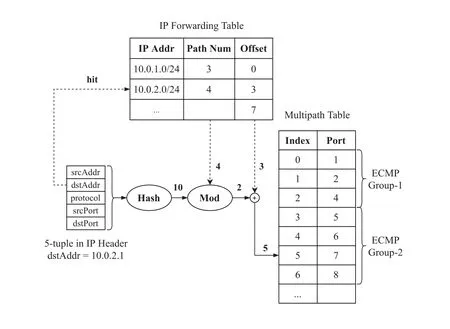
Figure2.ECMP forwarding based on the hash-threshold.
2.3 Our Goals for Closer
Closer is a scalable load balancing application with complete route feedback mechanism.Motivated by the shortcomings of existing work,we have several significant goals for our DCN load-balancer:
1.Global utilization awareness.It is essentially required for Closer to obtain exhaustive congestion knowledge about downstream to handling volatile traffic,especially within asymmetry topology.The path weight is not static result from the experience,but dynamically updated according to the universal congestion metric.
2.Stable and responsive.From the beginning of design,the stability of Closer in large-scale topology is fully considered.The overlay gateway would adaptively achieve rapid round-trip timescale(RTT)reaction to link congestion without any intervention.Definitely,the network manager have access to monitor the state of network traffic and modify the route policy when emergency occurs.
3.Flexible deployment with low cost.Closer builds the updated load-balancing logic at the NVEs (hypervisors or ToR switches).Without any modifications to end-host stack,the traffic from VM are obliviously transported through the ECMP-based network.The required resource for data plane is restrained enough to deploy Closer in software-based switches with general CPUs,while offloading functions into hardwareaccelerated appliances would achieve a better forwarding throughput.
4.Dynamical extension.Closer must support the scale-out of network topology as well as the incremental deployment of the NVE.Given a sweet spot,the feedback system allocates the initial optimal paths when a new virtual tunnel is established,while the capability to react to link congestion rapidly is reserved in the data plane.In a word,it will effectively deal with the imbalance of traffic in geographical and temporal dimensions.
2.4 Opportunities
Nowadays,we have seen two critical trends that have the potential to realize Closer which satisfies the preceding requirements.
Programmable data plane.Given that traditional software-based network stacks in hosts can no longer sustain complex cloud business logic,offloading network stacks into hardware is an inevitable direction in high-speed networks [17].The shipment of programmable hardware (i.e.,programmable switch and SmartNIC) in data center switch market is gradually increasing.It is because they provide powerful capability that allows network programmers to customize the algorithms directly in the data plane and operate packets at the line rate[18].At the same time,different layers of DCNs adopt different types of hardware for comprehensive factors.For example,the servers and ToR switches may use high-programmability Smart-NICs or ASICs for near-server computation offloading,while core switches employ less programmable but fixed-function ASIC with standard protocols to guarantee high-throughout[19].
In-band network telemetry.As the most concerned application that emerges along with programmable data plane,INT is bringing about much greater visibility into the network as new diagnostic techniques [20].Unlike passive measurement methods (e.g.,SNMP [21]),INT provides data plane services to actively collect,deliver,and report network state.At the runtime,an INT entity generates probe packets(special packet or modified normal packet)as the messenger of instruction and injects them into the network.Then,the INT-capable nodes along the forwarding path directly export device-internal states to the monitoring system based on the instructions,or push them into the header stack.This “packet-asinstruction”framework realizes a new workflow to automate network monitoring and troubleshooting.Also,it provides an exciting opportunity to achieve real-time control loops for load balancing.Alibaba has systematically supported INT features in their large-scale RDMA network and implemented high precision congestion control with commodity programmable NICs and switches[17].
III.CLOSER DESIGN
In this section,we elaborate the design of INT-based load balancing mechanism that achieves the above goals,including how to realize per-link congestion awareness in overlay network (§3.1),the logic behind the real-time feedback (§3.2) and finally how the feedback is used for fine-grained routing (§3.3).We choose VXLAN as the default tunnel protocol to clearly describe the details,while the application could be seamlessly transplanted to other overlay networks.
3.1 State Collection in VXLAN Network
In a multi-tenancy cloud datacenter,overlay gateways are responsible for encapsulating packets received from end-hosts so that Ethernet payload can be transmitted across Layer-3 network.The most popular network virtualization tunnel protocol is VXLAN,which is recognized as the cornerstone of cloud computing.As the architecture evolves,the IETF has been drafting the Generic Protocol Extension for VXLAN(VXLAN GPE)specification to allow for multi-protocol encapsulation[22].
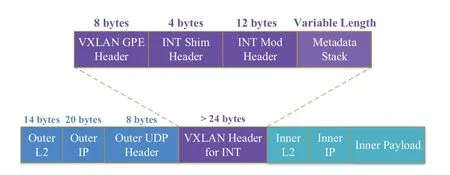
Figure3.Encapsulation of INT over VXLAN GPE.
In the INT data plane specification v2.1 [23],released by the P4 Language Consortium (P4.org) Applications Working Group in June 2020,the encapsulation for INT over VXLAN GPE is defined (see Figure3).The INT header,comprising of a shim header and a mode header,is positioned between the VXLAN GPE header and inner packet.The 8-bit next protocol field of VXLAN GPE header is set to 0x82 to indicate that there is an INT header as follows.The specification defines three distinctive work modes with different format and location of INT mode header.Based on our goals,Closer uses the classic“Hop-by-Hop”mode(a.k.a.“INT-MD”type)for path monitoring and state awareness.It leverages an additional variable-length metadata stack to carry any device-internal information.The source TEP embeds the INT-MD header,which contains the instruction bits corresponding to the network state to be reported at intermediate switches,into the normal packets that sampled from the out-port flows at the fixed frequency.It is understood that the probe packet generated by Closer will pull the local information ofnode idandlink utilization of the egress interfacein each switch along the forwarding path.When the probe traverses the network to the other edge,the destination TEP is supposed to extract the metadata stack and export the collected state to monitoring system.Such,the system achieves the end-to-end utilization-aware mechanism in a proactive service mode.Generally speaking,the sampling frequency is in the order of hundred milliseconds to limit the bandwidth overhead and processing delay.
The INT framework does not stipulate the mechanics to keep track of the current utilization of the egress interface.Both bin bucketing and moving average,as mentioned in the specification,are wildly accepted,while the latter is clearly superior to the former.There,we introduce the Discounting Rate Estimator(DRE),a simpler but more precise algorithm than exponentially weighted moving average(EWMA)mechanism.The DRE only occupies a register resourceXto measure the load of each link(whereas EWMA requires two).
The fluctuate ofXcomes from two aspects:(i)the increment for each packet sent over the link by the packet size in bytes;and(ii)the periodical decrement everyTdrewith a factor ofαbetween 0 and 1.Suppose that the link speed isC,then the utilization of egress interfaceUis estimated asU ≈X/Cτ,whereτ=Tdre/α.
The essence behind the DRE is a first-order low pass filter applied to packet arrivals,which can shape the traffic in the past period and calculate the average traffic rate.The parameterτreflects the sensitivity of the algorithm to the change of network traffic,which should be set larger than the network RTT to filter the sub-RTT traffic bursts of TCP [8].In our implementation,τis set to 200µs.When the probe packet is sent out via egress interface,the DRE will quantize the congestion metricUto 8 bits and push it into metadata stack.
3.2 Real-time Feedbak Loop
In the architecture of SDN,control plane provides a fundamental platform to manage the heterogenous network devices from remote console.By loading abundant applications and drivers(e.g.,LLDP,EVPN),the controller is able to obtain the basic topology information and then configurethe routing policy by populating tables with various entries [24].For Closer,the ToR switches can also easily maintain the mapping relationship between the available path and the corresponding source port number from the controller.Most of the distributed dataplane schemes expose excessive dependence on probes,which means that a fixed update frequency should be maintained even if there is no any data packet in the network.Instead,only the active traffic taking through the virtual tunnel,in Closer,needs to be scheduled with paths as best as possible.As a result,we adopt the strategy of “pre-allocation and dynamic-tuning”to give the load balancing algorithm a start state and keep the system running smoothly all the time.Owning the global perspective,the controller selects the paths as distinct as possible for every pair of overlay tunnel.Thanks to the inherited hierarchical attribute of topology,a simple heuristic algorithm that pinkskpath that shares the least number of links each other is accepted as there is no traffic load at the initial stage.In the largest datacenter networks,kis typically between 4 and 256[3].At runtime,the virtual TEP (VTEP) constructs probe packets actively to monitor the change of link congestion and network topology.It also indicates that our scheme is significantly different from other dataplanebased methods;unlike HULA,Closer is not reliant on probes to search all available paths and calculate the best route all the time.
In order to overcome the dilemma of local routing decisions,all congestion information stored in INT header should be analyzed centrally before being fed back to source switch.The entire application framework is shown in the Figure4.The INT sink strips the instructions and aggregated metadata out of the packet and sends the data to centralized database.Therefore,measure behavior is oblivious to the transport layer of VMs.We build the network state database at controller,so that the switch could deliver messages safely using RPC service.After simple data classification,the controller can realize the exhaustive link utilization between any two endpoints,which is necessary for the next optimal-path selection.Here,Closer chooses the bottleneck link with the maximum utilization as the only criterion for evaluating the quality of an end-toend path—the lower the link utilization of the bottleneck link,the better the whole path.Considering the limited capacity of switches for entries,the controller only selects several items from the hundreds of available paths to ensure that the table entries would not overwhelm the memory.

Table1.Conversion:from utilization to weight.
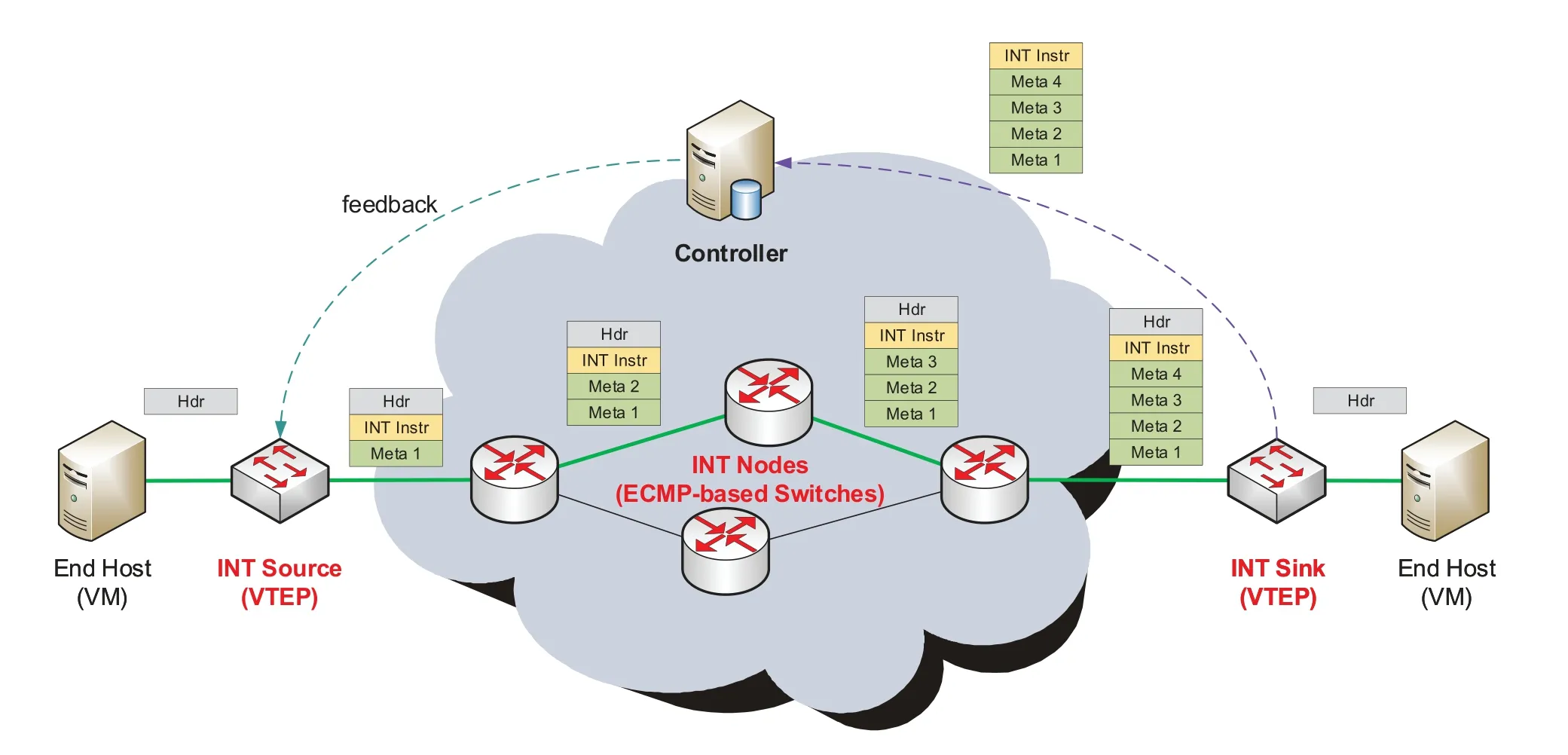
Figure4.INT-based network state feedback loop.
There is no doubt that path weight is inversely proportional to the maximum bandwidth utilization that the bottleneck link has.Table1 shows the conversion from utilization to weight in our implementation.The weight is evaluated with five levels,ranging from 0 to 4,so that 4-bit is large enough for maintaining congestion metrics in ToR switches.Definitely,a more fine-gained quantization levels would improve congestion awareness accuracy at the cost of physical resources,such as SRAM.When the link utilization exceeds 75%,the entire path is considered as extremely congested.This means that the switch temporarily stop dumping more new flows to this port,preventing the serious packet-loss caused by the influx of more traffic.Also,the controller may take the initiative to search other routes and then updates entries in the next round to ensure that the VTEP maintains the neark-optimal paths to every destination.Note that this may involve the competition that high-traffic nodes preempt the pre-allocated bandwidth of lowtraffic nodes,especially where there are large number of tenants with different service-level agreement(SLA)in the network.
3.3 WCMP for Flowlet
As described in §2.2,every overlay network has unique the transport protocol and the destination port number(UDP and port 4789 for VXLAN).As a result,the source port could be used to realize indirect source routing at the edge of the fabric.Given this feature,we build a linkage of packet encapsulation and path selection at the source TEP:the tables from the controller,actually,record the source port and the initial weight of the selected path.The VTEP simply rotates through the source port with the set of weights,which realizes a weighed ECMP algorithm throughout the network.Again,all the table entries are calculated from central algorithm with unified metric,so there is an extremely low probability of collision where the traffic between different tunnels preempt the same bottleneck link.
It should be pointed out that the path installation of the controller and the weight update of the switch are two side of the coin in our scheme.Considering the delay of upper feedback loop,the tolerance to table installation is beyond several seconds (5 seconds in our implementation).Intuitively,this time can be longer when the network traffic is at a low level consistently.In the interval of the global circulation,the ToRs continuously track the congestion ofk-paths and adaptively split the traffic to them.It means that the destination VTEP popes front the telemetry metadata stack one by one and then,besides reporting the copy to controller,piggybacks the maximum to the source VTEP together with the encapsulation header source port in the reverse direction.Hence,the system response time to traffic bursty is in the order of RTT(i.e.,milliseconds).
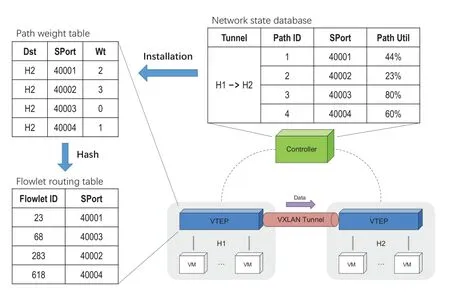
Figure5.WCMP routing in Closer.
Before WRR for route decision,we also consider further relieving the inefficiencies of uneven traffic distribution on equal-cost paths by dividing long-lived flows into small units and forwarding them independently.Based on previous work[3,8,11],Closer splits the flow into flowlet to make sure that packets are forwarded with the updated path but received in order as much as possible.The profound argumentation behind the flowlet is that the idle intervalTflbetween two bursts of packet is large enough to absorb the time lag,even if the second burst is sent along a more board path than the first.The source TEP caches the flowlet inactivity timeout,forcing packets to be encapsulated with the same source port.The whole routing mechanism is shown in Figure5.
In theory,the flowlet inter-packet gap more than the maximum RTT can eliminate the reorder delay of TCP messages caused by the different forwarding paths.Following the analysis in[8],we setTfl=500µs andTq=1ms in our implementation.
IV.IMPLEMNETATION IN P4
4.1 Introduction to P4
We use P4 (Programming Protocol-independent Packet Processors) [25]to describe the pipeline logic of overlay gateway for Closer.P4 is a packetprocessing language designed for programmable data plane architectures.Here,programmability refers to the capability of a switch to expose the packet processing logic to the control plane to be systematically,rapidly,and comprehensibly reconfigured [18].As a native technology of SDN,P4 inherits the match-action abstraction from OpenFlow[26].Moreover,it provides state machine to parse arbitrarily header fields,flexible lookup tables with customized actions,configurable control flow,and platformspecific extensions.The first three of above objects are programmable to realize protocol-independent.The language is based on an abstract forwarding model called protocol-independent switch architecture(PISA).PISA masks the underlying details and provides a standard programming paradigm for developers,enabling a concrete P4 program rapidly transplanting among different P4-enabled devices.
4.2 Closer in P4
We describe various components of Closer using version 1.2 of P4 [27].The P4 program has two main components:one,the P4 header format and parser specification,and two,packet control flow,which describes the main Closer logic.We assume that (i)the standard VXLAN tunnels have been established in overlay gateway,where VNI corresponds Bridge-Domain (BD) one by one;(ii) the layer-2 virtual access interface are set tountagtype (i.e.,there is no VLAN tag in the packet header from endpoint).
Header format and parsing.We define the INT header format for VXLAN GPE and the parsing state machine as shown in Figure6.The compiler has strict requirements of ordering and byte-alignment length for all member variables in header,which are arbitrary in structure.As shown in Figure6,the structure object header_t contains a header stack Switchh[MAX_HOPS]that carries status information collected from the data plane.The macro MAX_HOPS is set to 2 in our topology.However,it can be modified optionally by network operator to fit his deployment scenario (e.g.,4 in Fat-Tree topology).The packet from the VM jumps into the accept state after parsing the IPv4 header,while the UDP packet with port 4789 (which indicates the VXLAN header) has more complex parsing logic.Once the packet is identified as INT-MD probe(hdr.intShimHdr.teleType==1),the metadata would be extracted loop until the element of stack is null.In principle,given the defined headers and structures,the programmable parser merely enumerates several protocols that the pipeline should recognize from the beginning of ingress package.Other conditions are accepted or rejected by default.
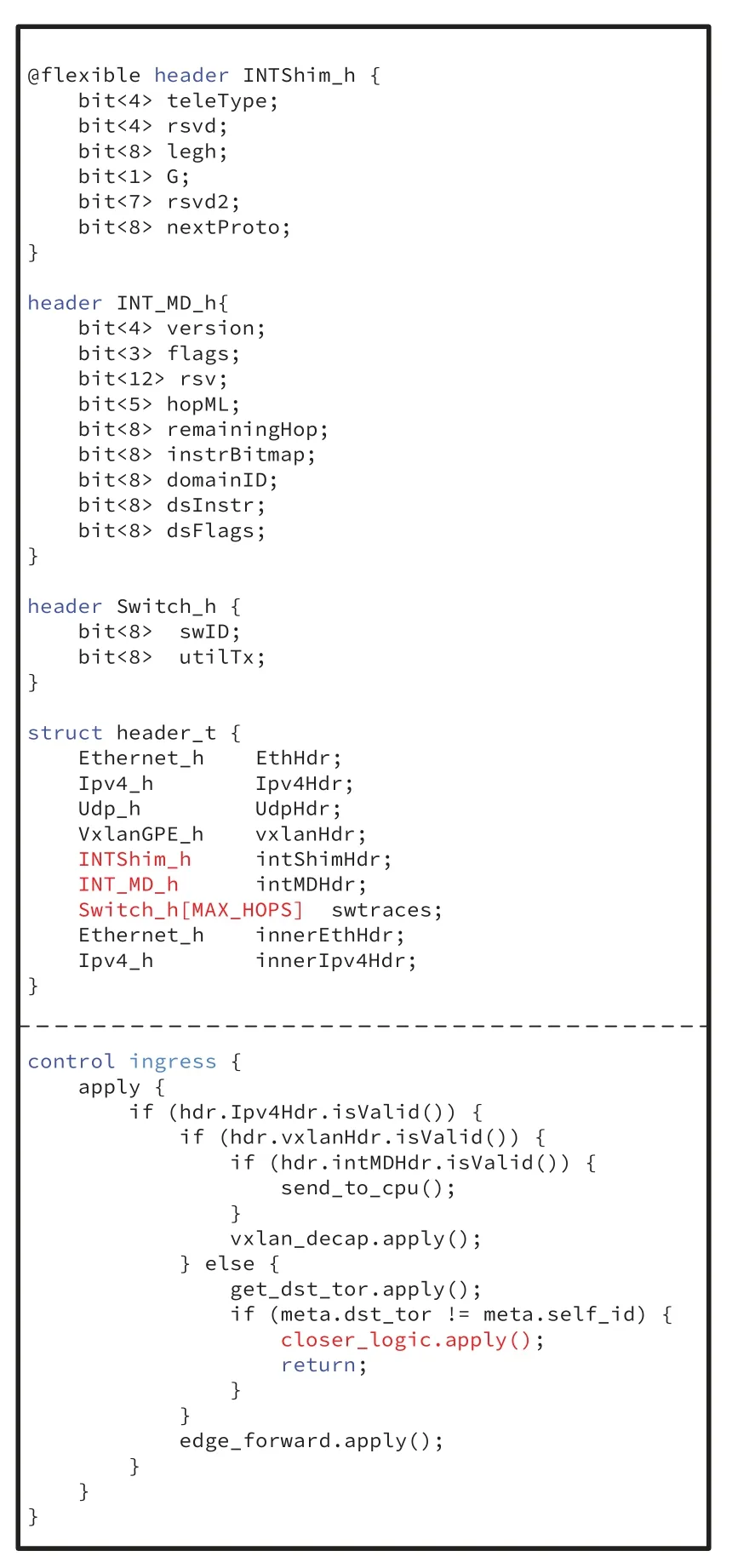
Figure6.Some components of the P4 program for Closer.
Closer pipeline logic.Before illustrating the P4 code of control flow,we firstly describe the complete packet processing logic in Algorithm 1.The pseudocode consists of two of blocks — (i) Processing VXLAN packet (line 2-14) and (ii) forwarding normal traffic(line 15-26).In a P4 pipeline,all protocol headers that have been recognized by parser would automatically be set tovalid.When the pipeline ends,the deparser emits the header to packet according to the bool value of “validity” field.Thus,we use the semantic of “set header valid/invalid” to describe the operation of encapsulation/decapsulation.For example,the line 13 tells the deparser to remove INT header from the header structure.
1.Processing VXLAN packet:When receiving a packet p from uplinks,the pipeline checks whether the header stack contains an INT header at first.If that,the switch would pop the state stack,which is used to update the path weight and construct a“Packet_in”messagep'to be report to controller (line 4-7).After that,the INT header has been removed so that the packet would be processed together with other normal traffic(line 9).Next,all VXLAN packet are mapped to their own BD based on the VNI number.No doubt,the VTEP is supposed to decapsulate the overlay header before transferring the packet(line 11-13).
2.Forwarding data packet:For data packet from end-host or VTEP,the pipeline lookups the destination MAC address(hdr.EthHdr.dstAddr)within the BD the packet belongs to.If the packet hits an entry of L2 forwarding table,the following downlink interface would be chosen as the output port(line 16).Otherwise,the VTEP takes over the packet and appends to it an appropriate VXLAN header(line 18-25).This process covers the soul of Closer algorithm:the UDP source port of outer header is selected by flowlet.WRR() method(line 20).Again,before forwarding to the upper node,the switch determines whether the packet should be transformed into an INT probe according to the update frequency(line 23).
Figure6 shows how we express the Algorithm 1 to control flow in P4.Although P4 provides unprecedented flexibility to describe various logic,the matchaction framework has many constraints on the underlying implementation [28].For example,the tables defined in the control flow can only be applied once,and each entry can invoke only one of actions associated to the table.As the result,we have to make some adjustments to implement the processing logic of data packets.We define the get_dst_tor table to determine whether the packet should be transmitted though the virtual tunnel.If the returned value of two metadata are not equal,the closer logic table is applied to implement the encapsulation work for L3 tunnel forwarding.Finally,the forwarding actions for L2 frame are gathered in the edge_forward table.
It should be noticed that the Closer pipeline logic requires the functionality of stateful forwarding for the data plane.The termstatein networking is defined as historical information that needs to be stored as input for processing of future packets in the same flow[29].P4 provides three extern data constructs — counter,register and meter—to retain the global device information across different packets.Specifically,we defined threeregistersto implement control flow:

?
• flowlet_time(48 bits):Last time the packet from a new flowlet was observed.
• flowlet_srcPort (16 bits):The next hop a flow should take.
• probe_time(48 bits):Last time the INT header is embedded to a packet.
At a high level,the closer logic table reads/writes to above registers to perform the stateful operations,which admits the P4 switch to processing flow traffic at line rate.
V.EVALUATION
We build a virtual network environment within Mininet emulator and develop a prototype to demonstrate the proposed Closer.The hardware is with Intel Xeon silver 4114 CPU and 64GB memory,running Ubuntu 18.04 OS.To evaluate the performance of Closer,we set up ECMP,MPTCP and Clove as control groups in the same environment.
5.1 Experimental Setting
Testbed.As shown in Figure7,the 2-tier Clos topology in our testbed consists of four spine switches(S1–S4) and four leaf switches (L1–L4).There are a total of four disjoint paths that traffic could take from one leaf to another.Each leaf is connected to eight servers that respectively contain an access virtual switch connected to a VM.The core of the network builds a VXLAN fabric using the modified Open vSwitch(OVS),while the access switch in the hypervisor is a P4-enabled software switch (bmv_2).All of the switches are managed by an ONOS controller(which loads both OpenFlow and the P4Runtime drivers).Due to the limited performance of the software switch,the link bandwidth between OVS is set to 1Gbps,and the servers gain access to the network with 500Mbps links so that the core-tier is not oversubscribed.
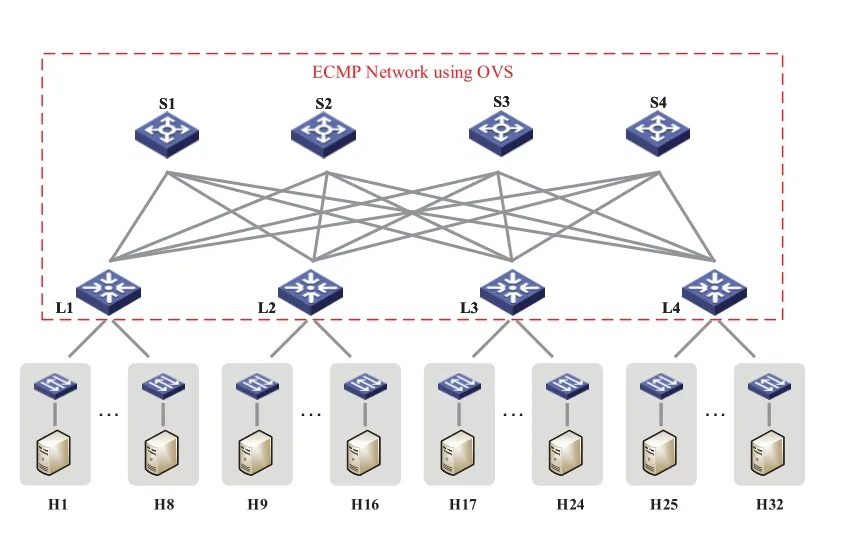
Figure7.2-tier Clos topology in our test-bed.
Traffic workload.We use two widely accepted datacenter traffic models [11],web-search and datamining,in testbed experiments.Both of these workloads are heavy-tail for the cumulative distribution of flow sizes.The difference is that 80% of Datamining traffic is less than 10KB in size,while the most Web-search traffic is concentrated between 10KB and 10MB.That is to say,data-mining is more uneven than web-search.We scale the dimensions of the traffic flow appropriately to accommodate the network bandwidth.
Powered by Iperf3 utility,we develop a client-server script,where half of the endpoints work as clients and randomly establish a persistent TCP connection to the servers under the different leaf.As a result,there are total of 10 VNI tunnels in the overlay network.The generation of flows is according to a Poisson process,and we change the mean of the inter-arrival rate to achieve the desired network load (10% – 90%).Ten random seeds are running for each experiment and we measure the average FCT of the ten runs as the main performance metric.All experimental results are normalized to the values of ECMP,unless specified otherwise.
5.2 Basline Symmetric Topology
Figure8 shows the result of four algorithms for the two workloads with the baseline topology.Other than MPTCP,the overall average FCT is similar to each other for all schemes,especially in the Websearch workload.When the network load continues to remain low-level,the simple policy of ECMP approaches near-optimal load balancing,while the complex control loop would slightly reduce the efficiency of the whole system(the processing and spread delay for congestion signal).However,the advanced nature of the congestion-aware scheme begins to manifest as the load increases up to 70%.Clove and Closer gradually narrow the gap with ECMP and realize the reverse overtaking.As for MPTCP,4 sub-flows per connection could accelerate the time the traffic spent in the network,but it also increases congestion at the edge links due to the burstiness of multiple sub-flows.
From the distinction between Figure8(a) and Figure8(b),we observe that ECMP prefers web-search and does quite well,which results from the relatively even distribution of flow size.On the contrary,the data-mining is more “heavy” — there are more hash collisions of large flows that seriously damage the performance of ECMP.Clove and Closer are resilient to flow distribution,achieving more than 50%better FCT at 90%load.
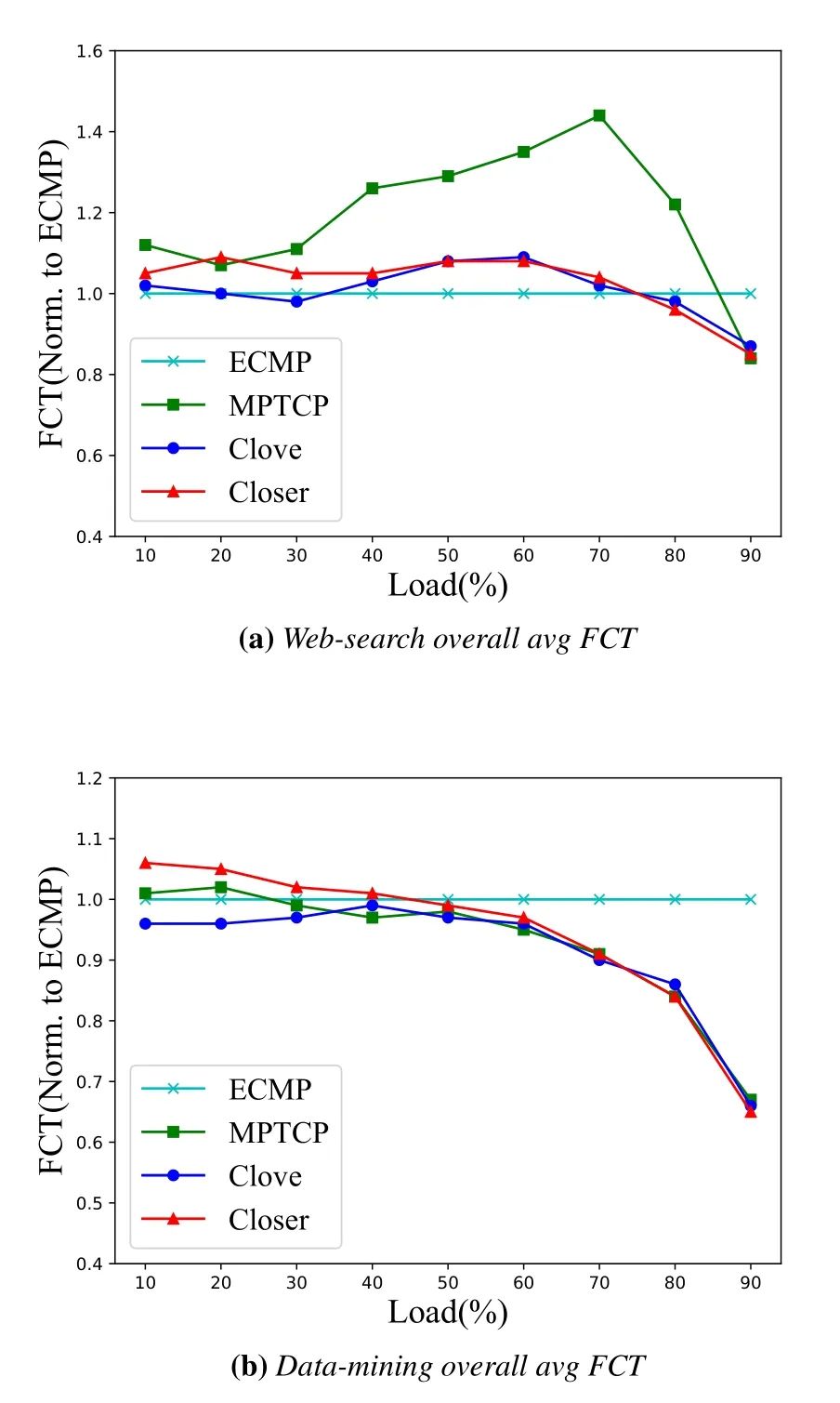
Figure8.Average FCT for two workloads on the symmetric topology.
5.3 Asymmetric Topology
To simulate asymmetry in the baseline symmetric topology,we set up the link between S4 and L4 with 500M.Correspondingly,the scope of the statistical object is adjusted to all data-mining traffic through the switch L4.The total available bandwidth is reduced by 12.5%,and thus the traffic loads should be balanced carefully to prevent the bottleneck link (S4-L4) from being congested.
Figure9 exposes the drawback of the congestionoblivious method.As the offered load increases beyond 50%,the whole system is in an embarrassing state that the bottleneck link is sharply congested while the remaining links still have a large amount of available bandwidth,which makes ECMP’s performance drastically deteriorate.Closer is superior to MPTCP and Clove in terms of sensitivity and performance.This is because Closer proactively adjusts traffic before congestion occurs and maintains a proportional increase of load across all links.This makes Closer achieve 6.7x better performance than ECMP and 1.4x better than Clove at 70%network load.
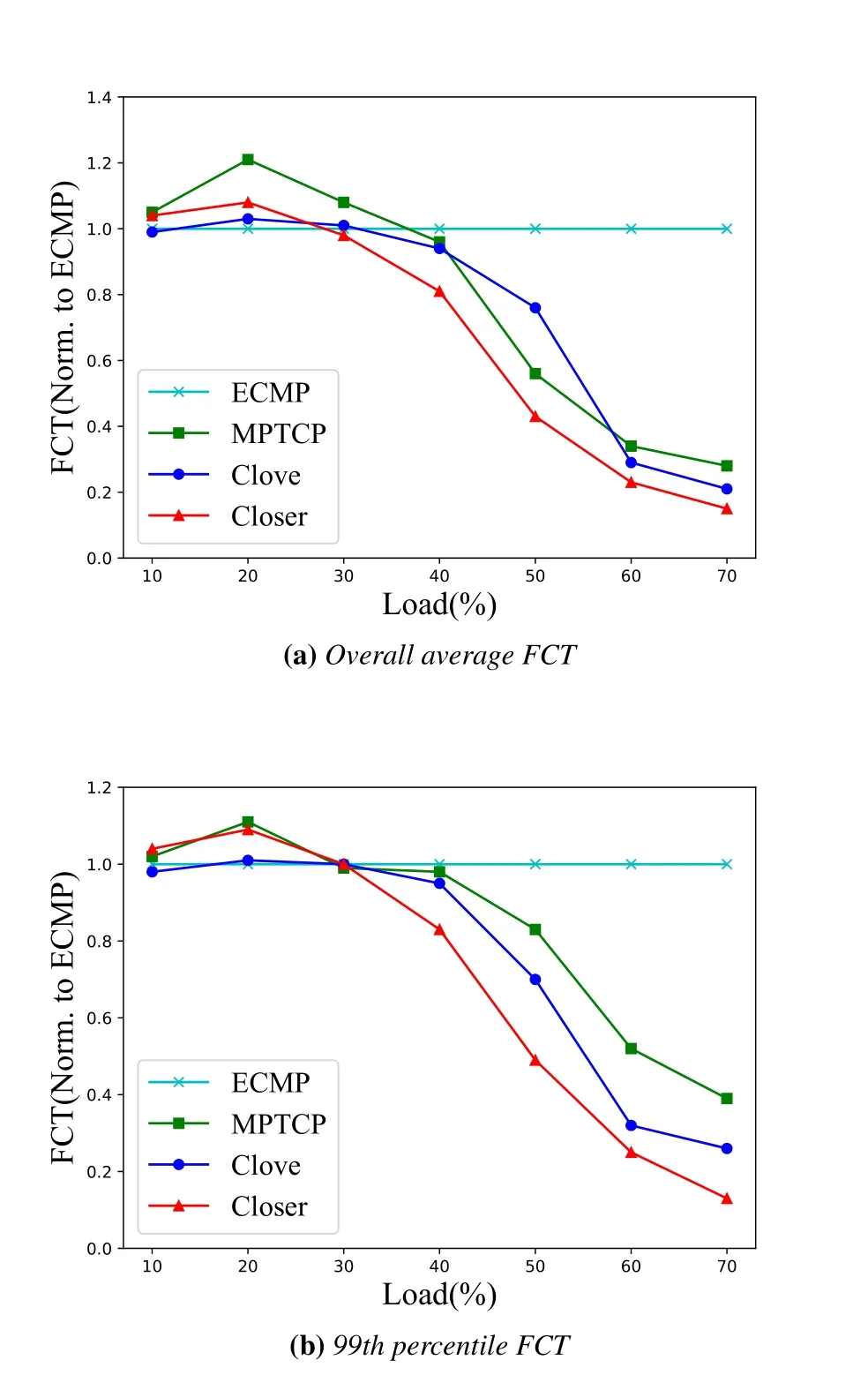
Figure9.Average FCT of data-mining on the asymmetric topology.
Figure9(b) shows the 99th percentile FCT of all schemes.One of the most notable is the change of MPTCP.Although MPTCP performs better in terms of average FCT in asymmetric topology,it is significantly worse than Clove or Closer on 99th FCT;i.e.,MPTCP suffers from long-tail latency.As described in Clove[3],the consistency of“flow”is destroyed in MPTCP,where there is at least a sub-flow of each connection get mapped to the congested path.Closer still maintains the best performance index,which achieves 3x better tail latency compared to MPTCP and 2x better to Clove at 60%network load.
5.4 Incast Workload
Incast widely exists in DCNs,especially in the distributed scale-out storage applications.In this pattern,resources are striped as small blocks and stored across several servers,which stresses the queue on the link connected to the client and may result in potential packet-drop and TCP retransmission.In this situation,the performance does not stress the network load-balancer but is determined by the Incast behavior for the transports layer protocols.However,we want to answer the question that how does Closr+TCP perform,comparing with MPTCP.
We design the following workload scenario to induce Incast in our testbed:the file the client request for has fixed size of 10MB,while the number of servers that response the connection simultaneously is n,where n is the x-axis variable of this experiment.The single client does not issue the next request to another set of servers chosen from the 19 servers until it receives all 10MB at the same time.The minimum retransmission timeout and packet size are the default value in Linux(200ms and 1500B respectively).
As can be seen from the Figure10(a) that the performance of MPTCP degrades sharply as the fanout increases.We believe that it results from the congestion windows of all the sub-flows and thereby the pressure on the access link queues,as confirmed similarly in Clove.Closer achieves more stable throughput without affecting the transmission quality of TCP because of its efficient traffic scheduling.For instance,Closer achieves 2.58x better throughout than MPTCP and 1.04x better than ECMP for a fanout size of 17.
5.5 Various Probe Frequency
As discussed earlier,Closer avoids the flaw that having over-reliance on probes even through there is no any traffic in the network.To quantify this advantage,we evaluated the performance of Closer in various sampling frequency with data-mining workload running on the asymmetric topology.
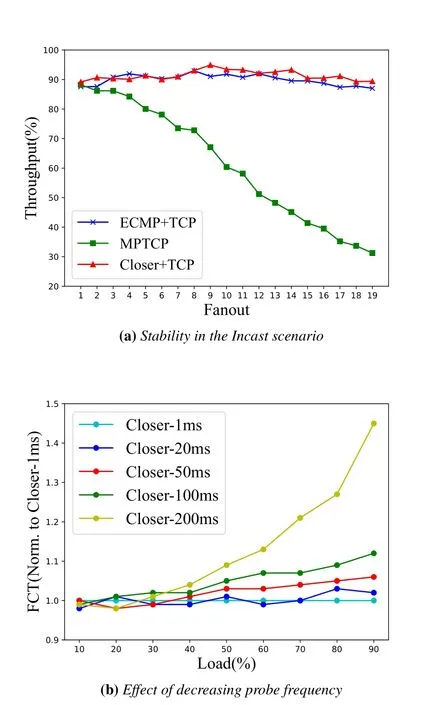
Figure10.Performance of Closer in various workload and probe frequency.
Figure10(b)shows the average FCT asTqis set to 20ms,50ms,100ms and 200ms respectively.Again,all experimental results are normalized to the values of Closer-1ms.When then network load is below 30%,the change of probe frequency has little effect on the transmission efficiency.As the network load increases to 50%,the hash collision of large flow were highlighted.At this time,properly increasing the probe frequency means that the VTEP can timely update the path weight and split the traffic with desired distribution.However,the average FCT of Closer-100ms is only 1.12x higher than that of Closer-1ms at 90%load.Anyway,there are absolute reasons to believe that Closer has high flexibility in the setting of probe frequency.
VI.CONCLUSION
This paper presents the design,implementation and evaluation of Closer,a scalable load-balancing algorithm for cloud datacenters.In control plane,Closer would collect global network status information in real-time.In data plane,the modified NVE can obtain the necessary information for routing decision from the controller and execute the traffic scheduling algorithm independently.This proactive approach achieves a good load balancing performance and scalability,which illustrates the advantages of SDN architecture.The experimental results show that Closer outperforms other load balancing algorithm both in average and 99th FCT.Although implementing the software solution only in virtual environment,we are actively verifying the performance of Closer in programmable ASIC with practical workload and large topology.
VII.ACKNOWLEDGMENT
We thank the anonymous reviewers for their comments that improved the paper.This work was supported by National Key Research and Development Project of China (2019YFB1802501),Research and Development Program in Key Areas of Guangdong Province(2018B010113001),and Open Foundation of Science and Technology on Communication Networks Laboratory(No.6142104180106).

- China Communications的其它文章
- Energy-Efficient Power Allocation for IoT Devices in CR-NOMA Networks
- Guarding Legal Communication with Smart Jammer:Stackelberg Game Based Power Control Analysis
- Shortest Link Scheduling in Wireless Networks with Oblivious Power Control
- A Proactive Selection Method for Dynamic Access Points Grouping in User-centric UDN
- A New Solution Based on Optimal Link-State Routing for Named Data MANET
- NOMA-Based UAV Communications for Maritime Coverage Enhancement