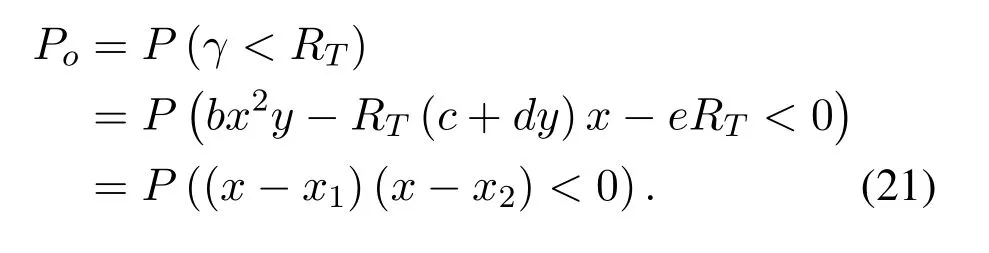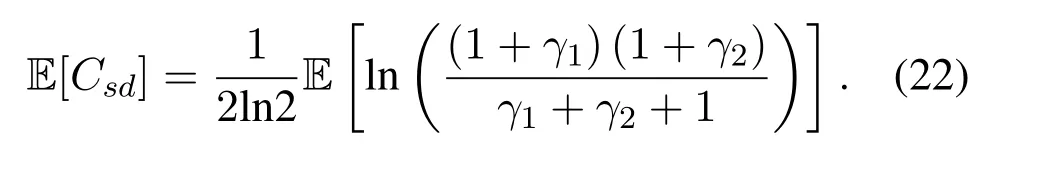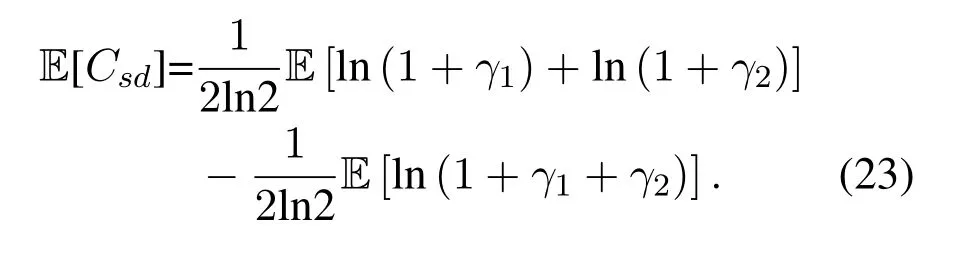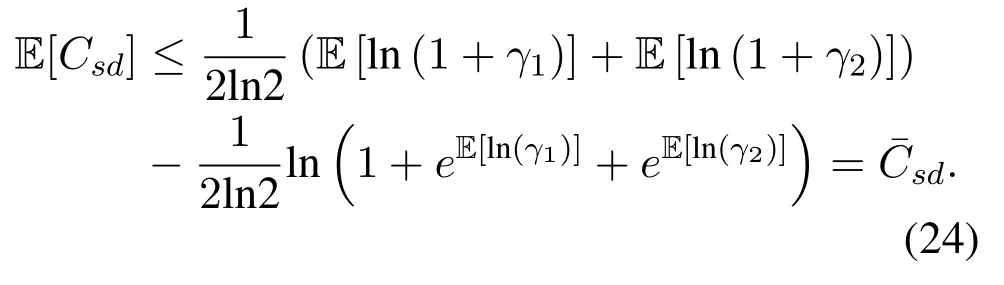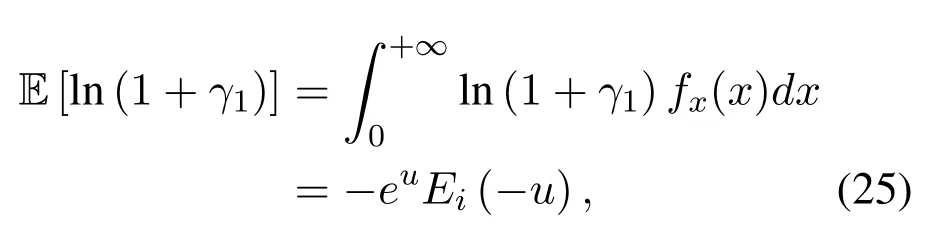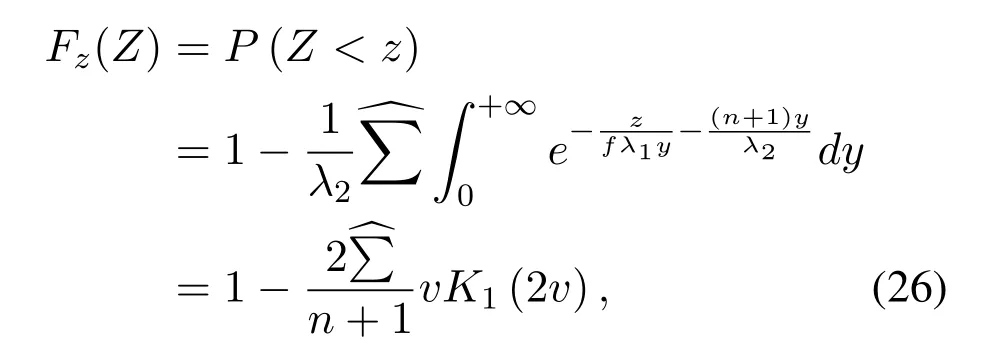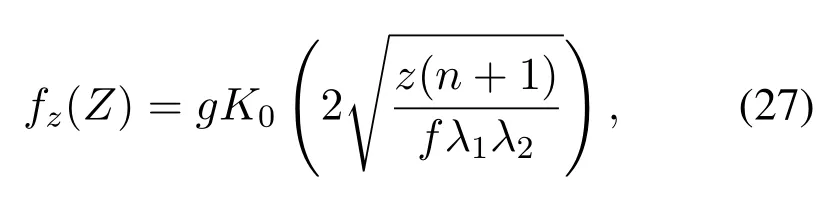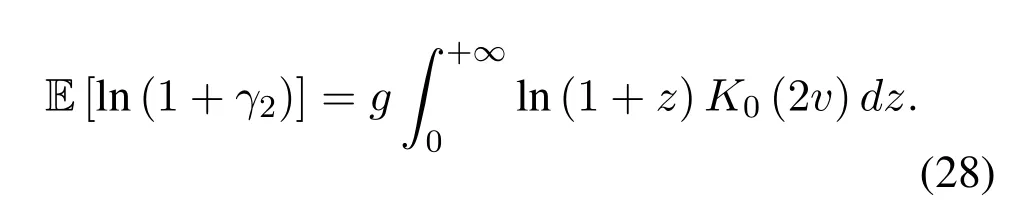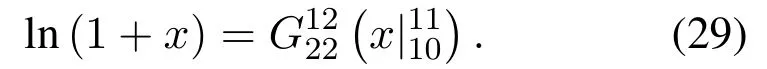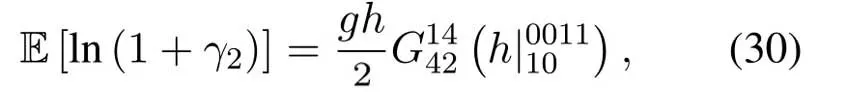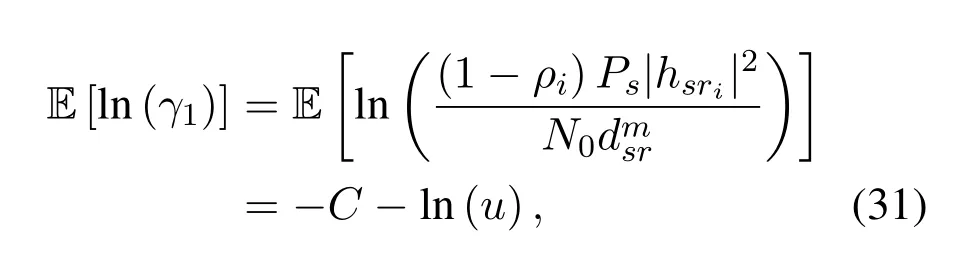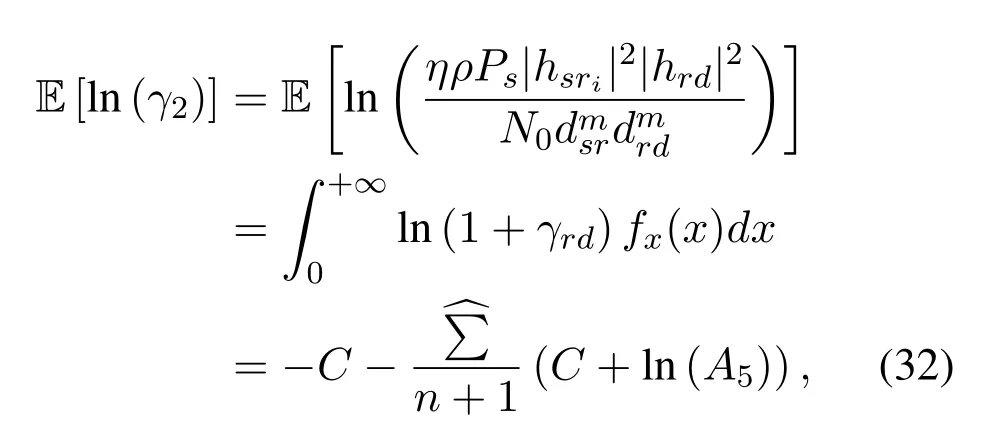Antenna Selection in Energy Harvesting Relaying Networks Using Q-Learning Algorithm
2021-04-14 10:11DaliangOuyangRuiZhaoYuanjianLiRongxinGuoYiWang
China Communications 2021年4期
Daliang Ouyang,Rui Zhao,*,Yuanjian Li,Rongxin Guo,Yi Wang
1 College of Information Science and Engineering,Huaqiao University,Xiamen 361021,China
2 Centre for Telecommunications Research,King’s College London,London WC2R 2LS,U.K.
3 School of Electronics and Communication Engineering,Zhengzhou University of Aeronautics,Zhengzhou 450046,China
4 China National Digital Switching System Engineering and Technological Research Center,Zhengzhou 450002,China
Abstract:In this paper,a novel opportunistic scheduling (OS) scheme with antenna selection (AS)for the energy harvesting(EH)cooperative communication system where the relay can harvest energy from the source transmission is proposed.In this considered scheme,we take into both traditional mathematical analysis and reinforcement learning(RL)scenarios with the power splitting(PS)factor constraint.For the case of traditional mathematical analysis of a fixed-PS factor,we derive an exact closed-form expressions for the ergodic capacity and outage probability in general signal-to-noise ratio (SNR) regime.Then,we combine the optimal PS factor with performance metrics to achieve the optimal transmission performance.Subsequently,based on the optimized PS factor,a RL technique called as Q-learning(QL)algorithm is proposed to derive the optimal antenna selection strategy.To highlight the performance advantage of the proposed QL with training the received SNR at the destination,we also examine the scenario of QL scheme with training channel between the relay and the destination.The results illustrate that,the optimized scheme is always superior to the fixed-PS factor scheme.In addition,a better system parameter setting with QL significantly outperforms the traditional mathematical analysis scheme.
Keywords:Q-learning;optimal PS factor;outage probability;ergodic capacity;antenna selection
I.INTRODUCTION
Wireless energy harvesting (EH) from ambient radio frequency (RF) signals can be a favorable option for prolonging the lifetime of energy-constrained devices.Comparing with the conventional batterypowered communication networks,the wireless EH technology improves the efficiency of communication and decrease the operation overhead in a large degree,which attracted enormous attention in the field of wireless communication networks.To enhance the information transmission rate of an energy-constrained source in a wireless-powered cooperative communication network,the source can harvest energy from a power station with the time-switching (TS) protocol[1].
Cooperative relay technology is beneficial to obtain both the diversity gain and the multiplexing gain.For the relaying networks,the intermediate relay is applied between a transmitter and a receiver for the intention of mitigating fading,enhancing link quality and improving transmission rate.Considering the cooperative single-antenna relay employed to assist the source transmission network,the authors have both investigated the effects of a power-splitting(PS)and TS protocols on ergodic capacity performance[2].In such a transmission scheme,the PS design apparently outperforms the TS in terms of the ergadic capacity.Based on the wireless EH amplify and forward (AF) relaying network,the optimal TS and PS factors were derived to achieve the maximum average success probability [3].Unlike the single-relay network,the authors extended the works in a multiple-relay network and the approximate closed-form expression for the average throughput of the harvest-then-cooperate protocol was provided in high signal-to-noise ratio(SNR)regime[4].In[5],the optimal relay selection scheme was proposed to gain the maximum secrecy performance of the half-duplex noncooperative EH relay network,where the secrecy outage probability is developed in high-SNR regime.Moreover,the optimal relay selection and the optimal PS factor were both provided in [6]for an EH cooperative multiple-relay network to minimize the outage performance.Only the closed-form expressions for the outage probability and throughput were derived in high-SNR regime for the full-duplex(FD)EH relaying network[7].
Apart from the single-antenna relaying network,the cooperative relaying network under multiple-antenna relay scenarios have also been of the prime interest as we can employ the beamforming and diversity gain techniques to improve the transmission performance[8–10].It was shown in[11],the optimal relay beamformer was designed to maximize the minimum of the data rates of the two information flows at the twohop multiple-antenna relay station.For the multipleinput multiple-output (MIMO) multiple-antenna AFrelay networks [12],the achievable sum-rate maximization problem was formulated.In[13],the authors analyzed the desired transmission rate and coverage region in the MIMO communication networks.For both the fixed-gain and variable-gain MIMO AF-relay network[14],where the source,relay and destination are all equipped with multiple-antenna,the closedform expressions of the outage probability was investigated.To take full advantage of the spatial degrees-offreedom of multiple-antenna relay network,antenna selection(AS)seems to be one of the promising techniques where the antenna at the relay is selected to realize the efficient allocation of the wireless channel resources.Combining the relay selection and AS techniques for the decode-and-forward (DF) relaying network [15],the approximate expression of the outage probability in the high-SNR regime was derived.In addition,joint the optimal relay selection and AS scheme was proposed to enrich the system capacity[16].To maximize the achievable rate for the proposed harvest-and-forward MIMO AF-relay network,the jointly optimized AS and PS scheme can achieve a flexible utilization of the received signals,which also achieve better transmission performances than the separated PS or AS does[17].The authors in[18]characterized the average bit error rate performance in the two-hop cooperative relaying network based on the AS technology at both the source and the relay.In[19],the close-form tight lower-bound for the outage probability was derived under the dual-hop MIMO relaying network.
Very recently,there have been many studies concerning about the wireless communication system based on the Q-learning algorithm,where the performance metric,such as the capacity or the utility function,is assumed as the reward based on the thought that it directly brings benefit to system performance.Unlike the traditional optimally selection scheme based on the mathematical analysis method,the QL algorithm can provide the dynamic transmission strategy to deal with the uncertainty of the change of the environment and has the relatively lowcomplexity computations.Without the estimation of primary traffic or the channel state information(CSI),each cognitive radio user can select its sensing task through times of interaction with the communication environment when the successful sensing rate is assumed as the reward [20].In [21],the transmission efficiency of the relaying network was defined as the reward and investigated with QL where the system did not have any knowledge of the CSI.Under less channel feedback information,the authors in [22]illustrated that the optimal relay selection strategy was obtained to maximize the outage performance when the received SNR at the destination is formulated as the reward.Moreover,a full-duplex jamming destination scheme was employed to boost the secure communication based on the observation state of the multipledestination communication environment with the secrecy capacity characterized as the reward [23].The optimal relay selection scheme of a wireless network based on QL was analyzed and the reward function is determined by the achievable rate[24].
Motivated by the above observations,an optimal PS factor and the AS scheme are proposed to maximize the transmission performance.We consider the opportunistic scheduling (OS) strategy with AS at the multiple-antenna relay to select the best antenna that maximizes the channel gain between the relay and the destination,which focuses on strengthening the utilization of the spatial degrees-of-freedom.To determine the performance metric,the analytical closedform expressions for the ergodic capacity and outage probability are both derived in general SNR regimes with traditional mathematical analysis of a fixed-PS factor method.Then,we combine the optimal PS factor with performance metrics to achieve the optimal transmission performance.Subsequently,to illustrate the advantage of QL compared to the traditional method,we combining the optimal PS factor and transmit power,propose two novel QL-based antenna selection optimization algorithms,where the design of the reward is both based on the single-channel between the relay and the destination,and the received SNR at the destination.
The main contributions of the paper are summarized as follows:
• For our proposed wireless EH AF-relay network,on the one hand,we combine the optimal PS factor with AS to achieve the maximum system performance.On the other hand,for the mathematical analysis of a fixed-PS factor scheme,the exact closed-form expressions for the outage probability and ergodic capacity are both derived to evaluate the transmission strategy in general SNR regime.
• By combining the QL theory and performance optimization,the optimal ergodic capacity and outage probability are investigated.The combining of the wireless EH,AS,optimal PS factor and QL algorithm herein are novel and hardly appear in prior literature.Furthermore,to attain more insightful results,we also reveal that our design where the transmission performance of the received SNR at the destination is characterized as the reward scheme better than that of the reward is based on the single-channel between the relay and the destination scheme.
The rest of the paper is organized as follows.In Section II,the system model and the EH protocol are described for the EH AF-relay network.In Section III,on the one hand,the optimal PS and AS schemes are derived and we combine the optimal PS factor with the exact analytical closed-form expressions to obtain the optimal outage probability and the ergodic capacity with traditional mathematical analysis method.On the other hand,the proposed QL scheme is described based on the optimal PS factor and the transmit power.Simulation results are presented to validate the correctness and effectiveness of our scheme in Section IV.Finally,conclusions are given in Section V.
II.SYSTEM MODEL
As shown in Figure1,we consider a dual-hop communication system where the energy-constrained intermediate relay can harvest energy from source transmission.A single-antenna sourceStransmits information to the single-antenna destinationDvia the multiple-antenna relayRi,i ∈{1,2,...,K}denotes the index of the antenna selected fromKantennas at the cooperative relay.Note that the selected antenna will be exploited to both receive source information and forward the processed signals to the destination.All nodes in the proposed network work in the halfduplex mode and the direct link between the source and the destination is not considered.In addition,we assume all channels are independent and follow the frequency non-selective Rayleigh block fading,so the channel fading coefficient is a constant in a time blockTwhich is normalized,i.e.,T=1.The entire transmission process is divided into two time slots,as illustrated in Figure2
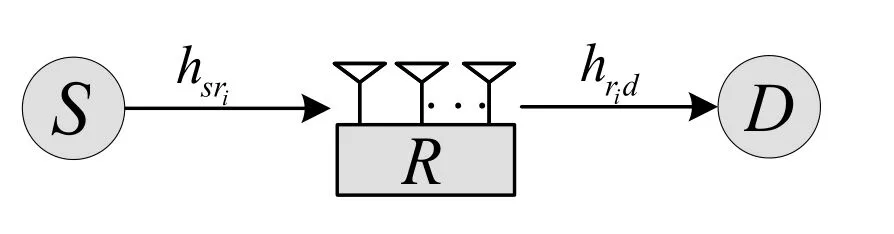
Figure1.Transmission model of the EH AF-relay network.
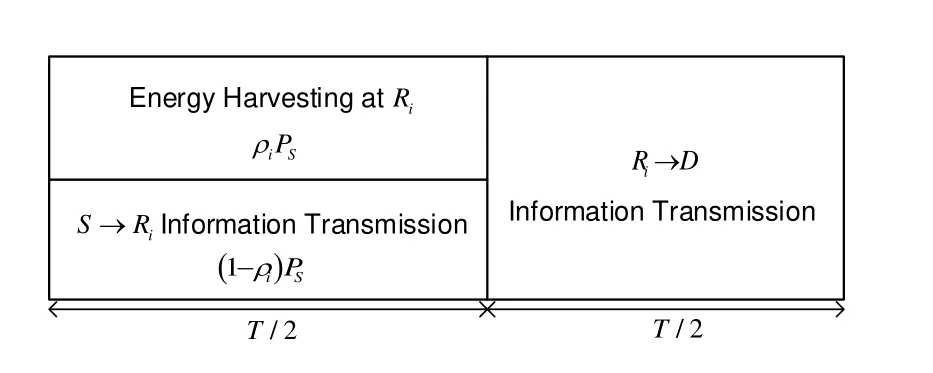
Figure2.Frame structure.
During the first time slotT/2,Stransmits information toRiwith powerPs.A fraction(ρ ∈[0,1])of the received signal power is utilized for EH at the energyconstrained relay,and the remaining fraction signal power (1−ρ)Psis employed for the source-to-relay information transmission.In the second time slot,Riamplifies the received information and forwards it to the destination utilizing the harvested energy.
The channels betweenSandRi,RiandDare denoted ashsriandhridrespectively,with the average channel power gains given respectively by E[|hsri|2]=λ1and E[|hrid|2]=λ2,where E[·]represents the expectation operation and|·|denotes the absolute value.
In the EH phase,the harvested energy at the intermediate relay can be expressed as
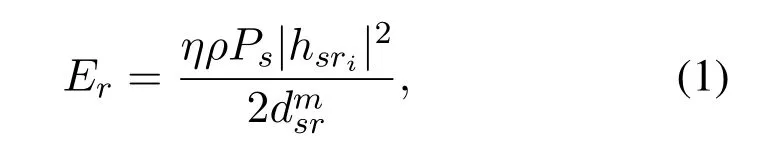
whereηis the energy conversion efficiency factor with 0<η≤1,dsrdenotes the distance from the source to the relay and m indicates the path loss exponent.Meanwhile,Rialso receives the synthesized signal from the source which can be expressed as
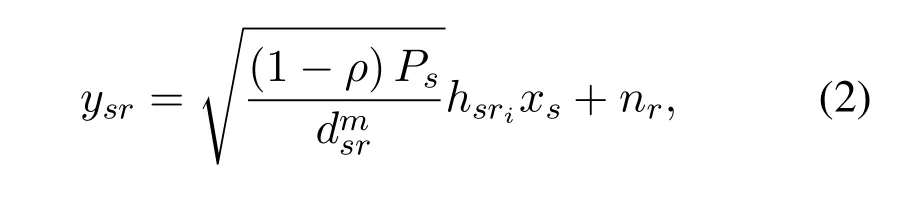
wherexsrepresents the information signal fromSwith unit power,nrdenotes the additive white Gaussian noise(AWGN)introduced by the selected receive antenna with mean 0 and varianceN0.Then,the SNR of the source-to-relay information transmission is given by
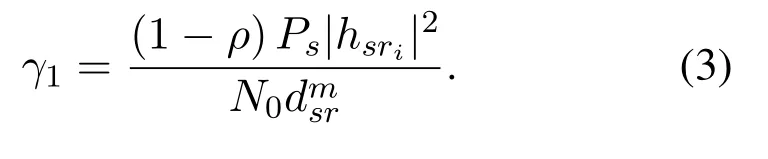
In the second time slot,since the intermediate relay works in the AF mode,it can amplify the received signalysrby a factorβand then retransmit it to the destination with powerPr.Hence,we have
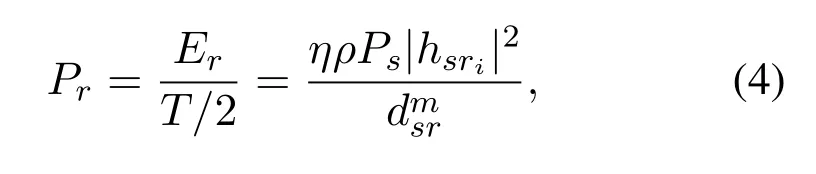
and
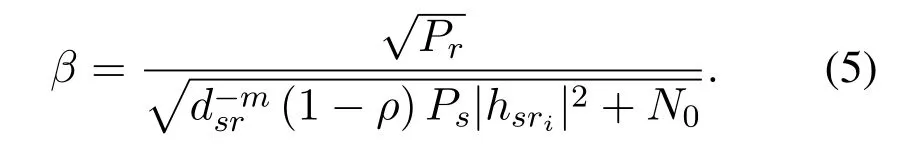
Then,the corresponding signal received atDcan be denoted by
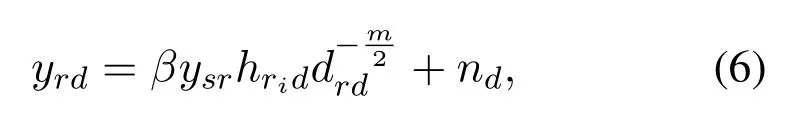
wheredrddenotes the distance of relay-to-destination information transfer andndmeans the AWGN introduced by the destination with mean 0 and varianceN0.According to (4),(5) and (6),the SNR from relayto-destination information transfer can be given by
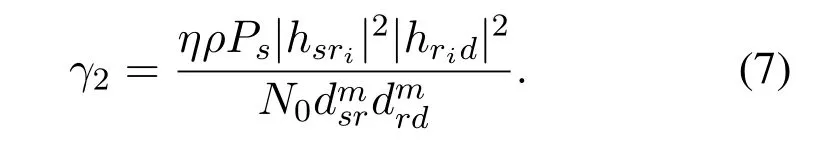
By combining the (3)and (7),the end-to-end SNR received atDcan be shown as[6]
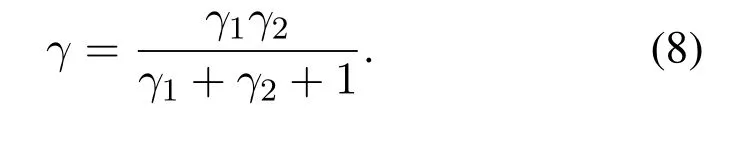
III.PERFORMANCE ANALYSIS WITH ANTENNA SELECTION STRATEGY
In this section,we take into consideration of the derivation of the closed-form expressions of ergodic capacity and outage probability in general SNR regime and then the optimal PS factor and transmit power will be derived to obtain the optimal transmission performance in the EH AF-relay system with traditional mathematical analysis method.Subsequently,we combing the optimal system parameters,employ the QL scheme to model the interaction between the source and destination to derive the optimal antenna selection strategy.
3.1 The Opportunistic Scheduling Strategy with Antenna Selection
To improve the information transmission and the wireless channel resource utilization ratio,we employ the AS scheme to select the best antenna at the relay according to the best channel quality between the relay and the destination.Consequently,we have
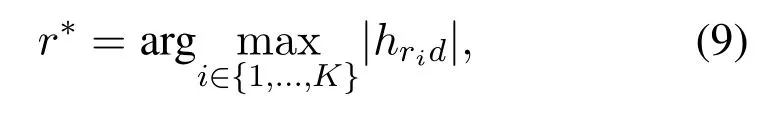
wherer∗denotes the best antenna at the relay which will be employed to both receive source information and forward the processed information to the destination.Next,we will derive the optimal PS factor and transmit power to achieve a better information transmission rate.By substituting (3) and (7) into (8),the maximization problem of the received end-to-end SNR at destination with the best antenna is formulated as
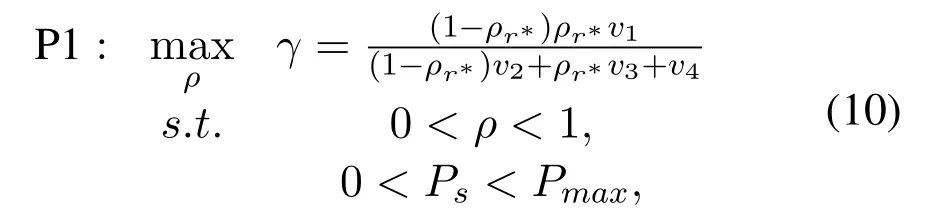
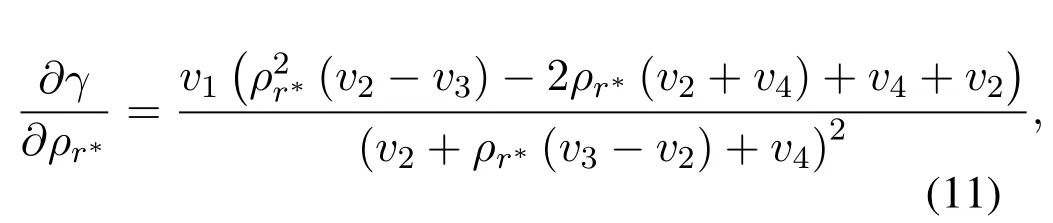
and
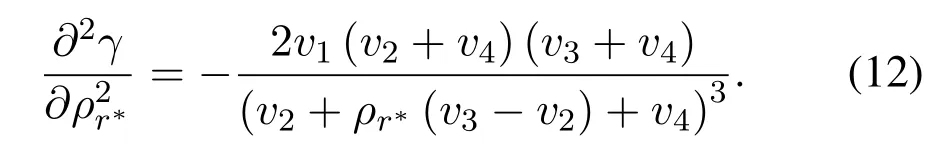
From (12),we can know thatγis a concave function w.r.t.ρr∗.Thus,there is a unique value ofρr∗maximizingγby makingAlso,it is noted that the sign ofcorresponds with the numerator termWe just need to derive the roots and then judge the sign off(ρr∗).For the caseis non-negative amongand is non-positive among the optimal value ofρr∗is achieved asIn the case ofv23and letf(ρr∗)=0,two roots can be derived as
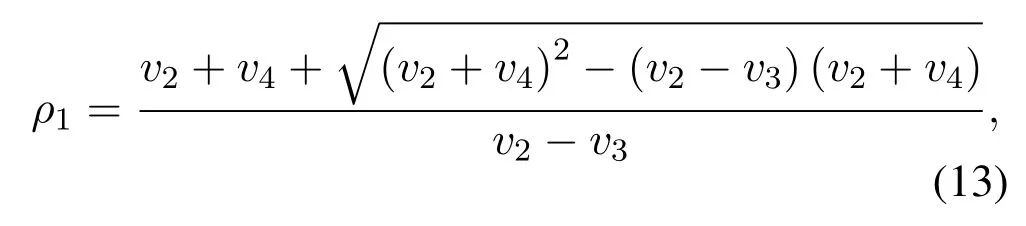
and
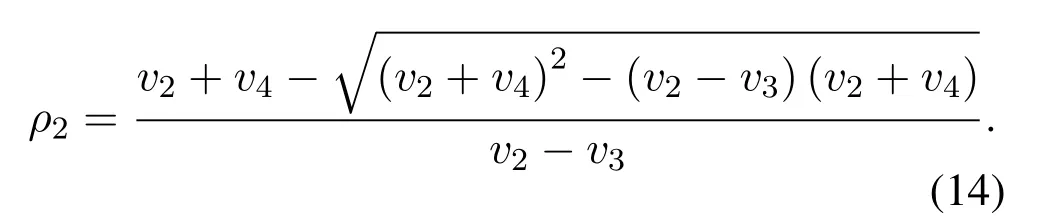
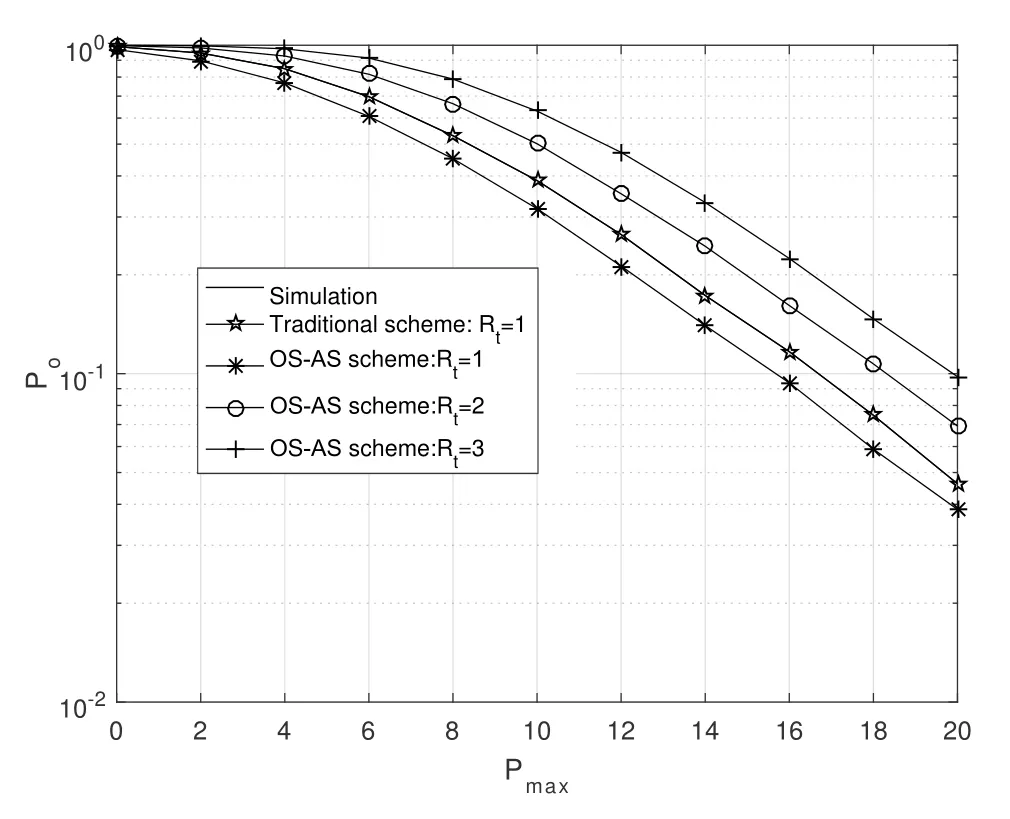
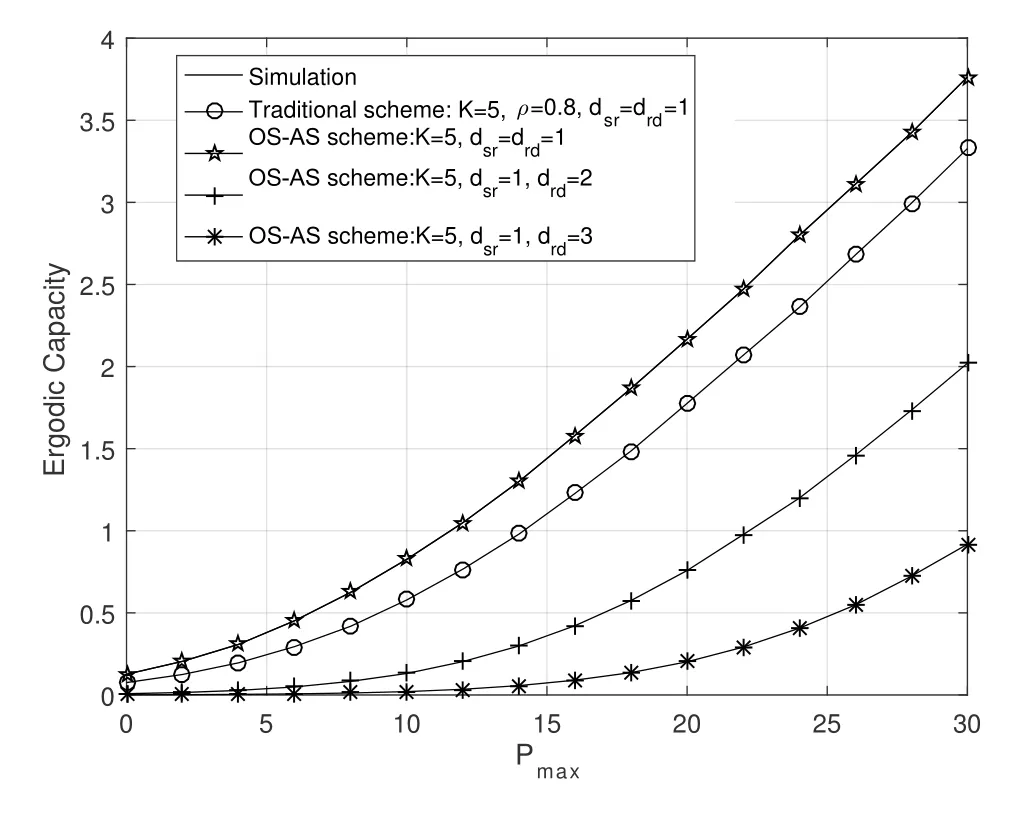
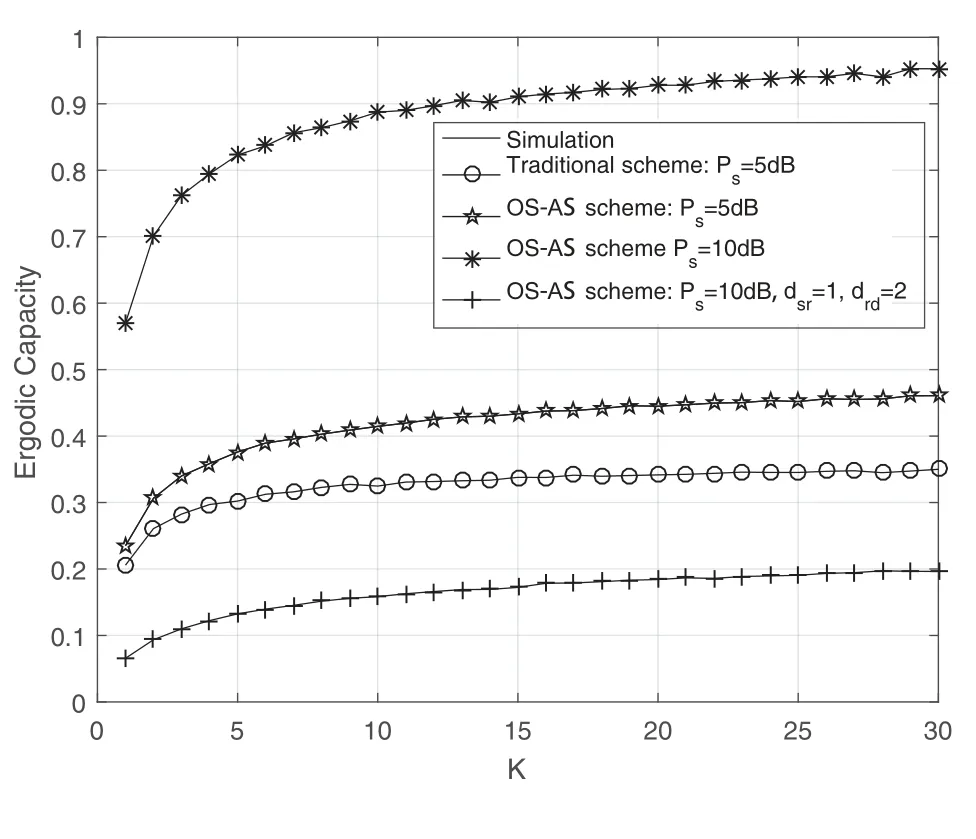
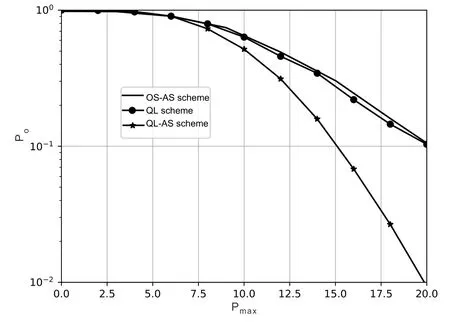
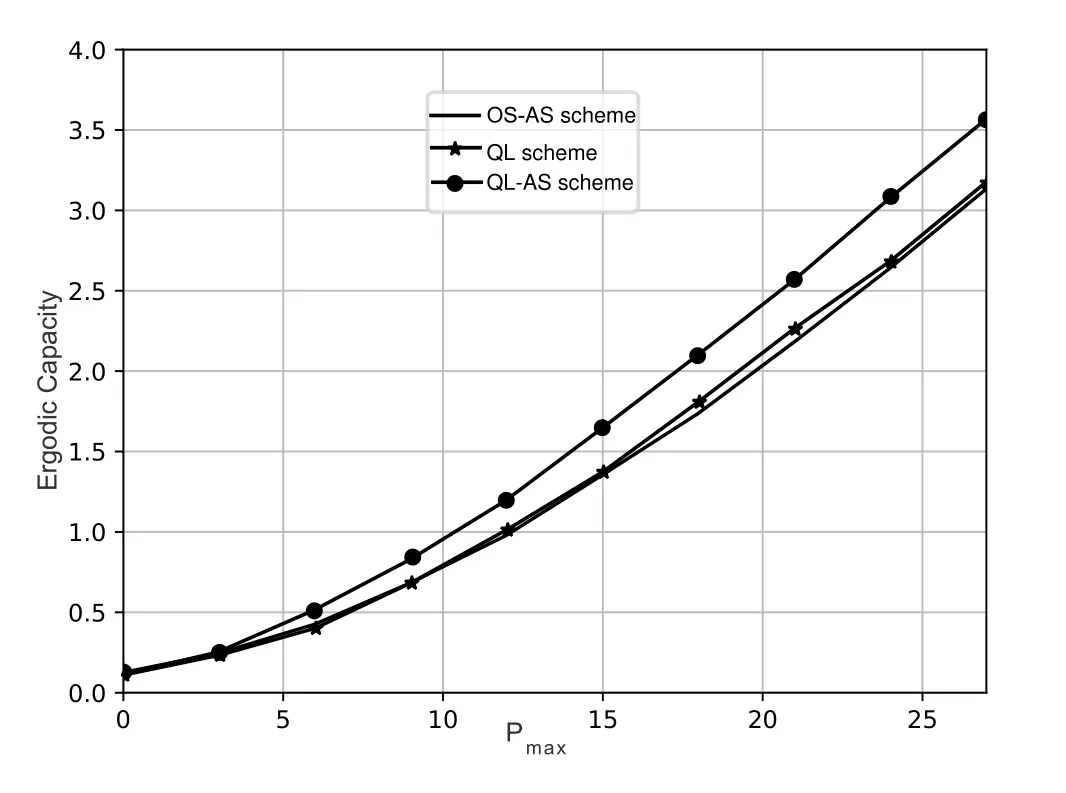
Obviously,ifv2>v3,we can observeρ1>1 and 0<ρ2<1.As such,f(ρr∗)monotonically increases with(0,ρ2]and then decreases withρr∗rises betweenρ2and 1.For the case thatv2 Based on the information-theoretical sense,if the end-to-end rate of the two-hop relaying channel is less than the target transmission rateRtbits/sec/Hz,the source transmission can be outage.Hence,the outage probability can be defined asPo=whereW=1 Hz means a unit bandwidth [25].According to (8),the outage probability can be computed as Next,by using the end-to-end SNR,the ergodic capacity E[Csd]of the EH AF-relay network can be defined as whereγis defined at (8). After some arithmetical operation,the ergodic capacity is given by Finally,by substitutingP∗sandρ∗r∗into (16) and(18),we can obtain the optimal outage probability and ergodic capacity. To minimize the outage probability and maximize the ergodic capacity,we can formulate the best AS scheme of the EH AF-relay network as a Q-learning process.The QL algorithm is employed at destination that is called as the agent,and then we can describe the optimal action-selection policy for any Markov decision process [23].For the proposed QL scheme,each antenna at the multiple-antenna relaying node is assumed as a state.Hence,s={s0,...,sK−1}can be defined as a set ofKstates.a={a0,a1,a2}can be defined as the predetermined three actions,i.e.,a0means that the agent moves left,a1indicates that the agent remains immobility state anda2denotes moving right.By combining the state and action,an immediate reward corresponding current actionaj ∈aand current statesi ∈sis formulated asr(si,aj)which is utilized to determine metric whether the system performance well or badly.For the possible selected actionajat any given state,the agent can observe ar(si,aj)and then employing the Q-valueQ(si,aj) to update the Q-table consisting of Q-values. The agent mainly depends on theε-greedy scheme to select an action from the currentsito the future statesi+1∈s.Utilizing theε-greedy scheme,a proportionεwill be used to select anajrandomly(with uniform probability).The remaining 1−εwill be employed to select an action that has the maximum Q-value in the Q-learning table,i.e.,aj=argmaxaj∈aQ(si,aj).With each a times of training,the agent randomly takes anajand calculates the Q-value function accordingly,where all possible actions are presented so that the agent can take all possible cases into account.According to Bellman optimality criterion,the basic formula of Q-value function is derived as[21],[22]whereσdenotes the discount factor determining the importance of the future rewards in current learning process.The future reward can be obtained from the cooperative communication environment utilizingQ(si+1,aj+1) that is evaluated when the agent choosesaj+1at the givensi+1.Then,we describe the environment for the QL algorithm by defining the followings: ? • At the wireless EH AF-relay system,since the relay hasKantennas,we can defined the state assi=i ∈{0,,...,K −1},whereidenotes index of current state. • Applyaj=j ∈{0,1,2}for an action selection at the multiple-antenna relay,i.e.,moves left 0 or moves right 2 or remains immobility 1.Whether the transmission performance would be improved or worsened while the agent selects a possible action in the decision process is not checked. • Defining a rewardr(si,aj) in the proposed QL algorithm is a critical issue.To maximize ergodic capacity and decrease the outage probability,we assume a reward based on (8)whenajis selected from the givensi,i.e., In the QL scheme,the agent will take an action,obtain a reward from current state and observe the future state,then calculate Q-value accordingly to update the Q-table.Through the QL scheme,we can derive the optimal antenna index in the Q-table which has the highest reward after a certain number of iterations.The pseudocode of the considered algorithm is described in Algorithm 1.Particularly,all the Qvalues in the Q-table are assumed as zeros initially. In this part,simulation results are presented to verify the theoretical analysis.For comparison,some strategies,namely,the OS scheme without the optimal PS factor (i.e.,traditional scheme),the OS with the AS and the optimal PS factor scheme (i.e.OSAS scheme),the QL scheme with the optimal PS factor and the reward function is assumed asr(si,aj)=|hrid|2,i ∈{0,...,K −1},and the other definition is same as aforementioned works (i.e.QL scheme) and the proposed QL scheme with the optimal PS factor where the received SNR at the destination is characterized as the reward scheme(QL-AS).Unless otherwise specified,we consider the following system parameters.The noise powerN0=1,K=5,η=0.9,ρ=0.8,Pmax=Ps,Rt=1 bits/sec/Hz andm=2.7.Additionally,the distance fromStoRiandRitoDare assumed asdsr=1 m anddrd=1 m respectively.The mean channel power gains areλ1=andλ2=[2]. Figure3.Po versus Pmax for different Rt. Figure4.Ergodic capacity versus Pmax for different drd. Figure3 shows the outage probability for both traditional scheme and the OS-AS scheme with differentRtwhenPmaxranges from 0 dB to 20 dB.From Figure3,the curve of outage probability for the traditional scheme matches the simulation results closely,which proves the correctness of our calculation and analysis results.It can also be observed that,forRt=1,the same decreasing trend is obtained by both the traditional scheme and the OS-AS scheme,which also implies that the OS-AS scheme with a optimal PS factor can achieve a better outage performance than the traditional scheme.In addition,increasingRtdoes not provide additional outage performance gain for the OS-AS scenario.In particularly,the outage probability of all schemes decrease with the growth ofPmax. Figure4 examines the ergodic capacity of the EH AF-relay network for both the traditional scheme and the OS-AS scheme.We can observe that the OS-AS scheme can achieve superior ergodic capacity performance than the traditional scheme.However,in the OS-AS scheme,such ergodic capacity performance diminishes gradually withdrdbecomes larger.This is because the mean channel power gainsλ2=decreases when increasingdrd,which leads to the destination receives poor signal due to the channel fading.Moreover,it can be seen that as the growth ofPmax,the OS-AS withdsr=drd=1 m scheme obtains better ergodic capacity than that of the other settings.By fixingdsr=drd=1 m andρ=0.8,we also can examine the effect between the fixed-PS factor and the optimal PS factor on ergodic capacity. Figure5.Ergodic capacity versus K for different drd and Ps. Figure5 provides an ergodic capacity performance comparison between the traditional scheme and OSAS scheme for the dual-hop AF EH multiple-antenna relaying networks.As illustrated in the Figure5,it can be observed that the ergodic capacity of all schemes increase asKrises.Moreover,the ergodic capacity of the OS-AS is significantly superior to the traditional scheme whenPs=5 dB anddsr=drd=1 m.By fixingdsr=1 m,varyingPsanddrd,we can observe that the ergodic capacity performance decreases asdrdincreases and increasingPsis beneficial to the ergodic capacity performance. Figure6 illustrates that the outage probability versusPmaxunder the OS-AS,QL and QL-AS strategies.In this setup,the outage performance of the proposed QL-AS always outperform more significantly than the OS-AS and the QL schemes.It can be readily observed that the QL design achieves almost the same outage performance as the OS-AS design,which indicates that the QL is a suitable alternative approach for practical implementation due to its acceptable performance gain and low-complexity.Moreover,the QLAS scheme decreases monotonically as the optimal transmit powerPmaxrises and the curves of outage probability gap between the QL-AS and other schemes get lager with the growth ofPmax.For instance,the outage probability of the OS-AS and QL strategies are almost 10−1atPs=20 dB,while the QL-AS achieves 10−2.Consequently,the proposed QL-AS can be considered as an efficient way to improve the transmission efficiency in the future wireless communication network. Figure6.Po comparison of the OS-AS,QL and QL-AS with σ=0.99 and the optimal PS factor. Figure7.Ergodic capacity versus Pmax under the OS-AS,QL and QL-AS strategies with σ=0.99 and the optimal PS factor. Figure7 plots a comparison of the ergodic capacity for the dual-hop AF EH multiple-antenna relaying networks with OS-AS,QL and QL-AS strategies.In this figure,we consider thatσ=0.99 andRt=1 bits/sec/Hz.As expected,it can be observed that compared with the QL and OS-AS schemes,the QL-AS scheme has a significant favorable effect on the ergodic capacity performance.This is because that the agent selects the received SNR at the destination as the reward function,which does not only consider the channel between the cooperative relay and the destination obtaining a larger ergodic capacity performance.Moreover,due to the uncertainty of the change of the wireless communication environment,the traditional mathematical analysis method,such as the OSAS scheme,is hard to design a dynamic transmission strategy,while the QL scheme has been shown to be effective to deal with this wireless communication problems [25].In the proposed QL-AS scheme,the agent adaptively choose an antenna to perform communication in the EH multiple-antenna relaying network with higher transmission data rate,which results in a larger ergodic capacity performance gap between the OS-AS,QL and QL-AS.It is also shown that the curve associated with the QL almost overlaps with the OS-AS design for all values ofPmax. In this paper,we have presented an algorithm using Q-learning method to improve the performance of the relay-aided communication systems.It has been demonstrated that a wireless-powered cooperative communication network is considered,in which the source transmits information to the destination via a wireless-powered multiple-antenna relay.To reduce unfavorable influence of the channel fading,the OS scheme is exploited at the multiple-antenna relay.For the traditional mathematical analysis method,the exact closed-form expressions are obtained for both the outage probability and ergodic capacity of a fixed-PS factor scheme,and then combing the optimal PS factor and AS scheme achieves an optimal transmission performance.Additionally,the QL is proposed to model the interaction between the source and the destination by the self-learning of the wireless network.Comparing with the OS-AS scheme,the QL has less complexity and the transmission efficiency is standout,which also reveals that the QL scheme could be very effective in the future fifth generation wireless communication networks. ACKNOWLEDGEMENT This work was supported in part by the National Natural Science Foundation of China under Grant 61720106003,Grant 61401165,Grant 61379006,Grant 61671144,and Grant 61701538,in part by the Natural Science Foundation of Fujian Province under Grants 2015J01262,in part by Promotion Program for Young and Middle-aged Teacher in Science and Technology Research of Huaqiao University under Grant ZQN-PY407,in part by Science and Technology Innovation Teams of Henan Province for Colleges and Universities (17IRTSTHN014),in part by the Scientific and Technological Key Project of Henan Province under Grant 172102210080 and Grant 182102210449,and in part by the Collaborative Innovation Center for Aviation Economy Development of Henan Province. APPENDIX A To ease the computation,we transformPoto From (21),we can know that two groups of real roots are existed,i.e.,x1=andx2=Sincex1is positive number andx2≤0,the expression in (21) can be further simplified asPo=P(0 B Based on (17),the ergodic capacity of the proposed AS scheme can be rewritten as According to the properties of the logarithmic functions,(22)can be transformed to Then,substitutingγ1andγ2into (23),we obviously will find that the integration of the second term in (23)can not be further simplified.Exploiting the Jensen’s inequality [10],we can present a closed-form upperbound on (23)which is upper bounded as Next,using the probability density function (PDF)ofxand with the help of [26,Eqs.(4.337.2)],E[ln(1+γ1)]can be calculated as Invokingγ2in (7)and definingit can be easily observed that E[ln(1+γ2)]is difficult to solve.Nevertheless,to calculate E[ln(1+γ2)],we can first compute the CDF ofZgiven by The above integral can be easily solved with the fact that Note that (29)is a shift of the Meijer’s G-function[26,Eqs.(7.821.3)].By substituting (29) into (28),we can derive Now,we can proceed to calculate E[ln(γ1)].Based on the PDF ofγ1and with the help of [26,Eqs.(4.331.1)],E[ln(γ1)]can be calculated as whereCdenotes the Euler constant[26]. Then,we further proceed to compute E[ln(γ2)].By combining the PDF of the exponential variableγ2and[26,Eqs.(4.331.1)],the exact expression of E[ln(γ2)]can be obtained as Substituting (25),(30),(31) and (32) into (24),the exact closed-form ergodic capacity expressionC¯sdis derived.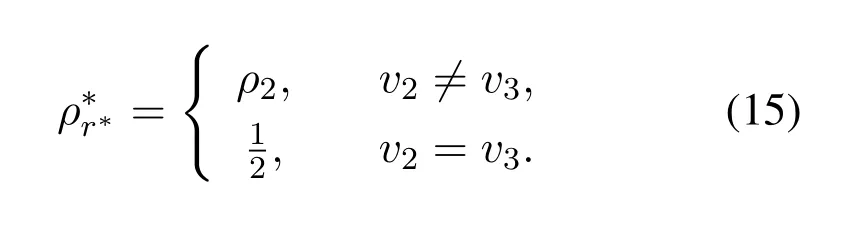
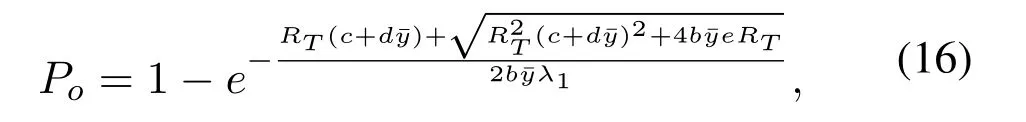
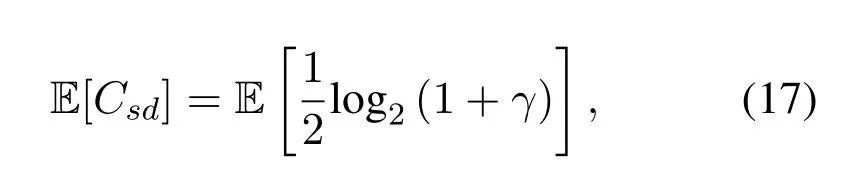
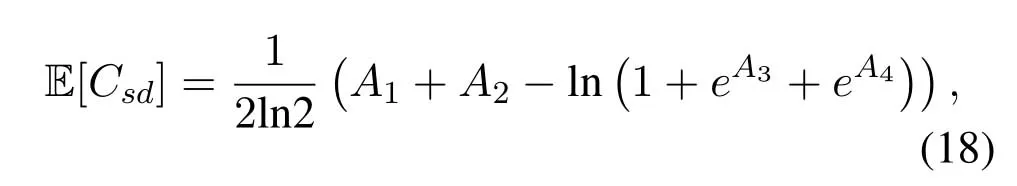
3.2 Q-Learning Algorithm with Antenna Selection
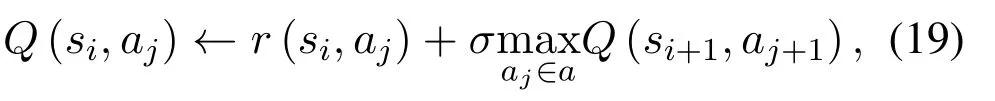

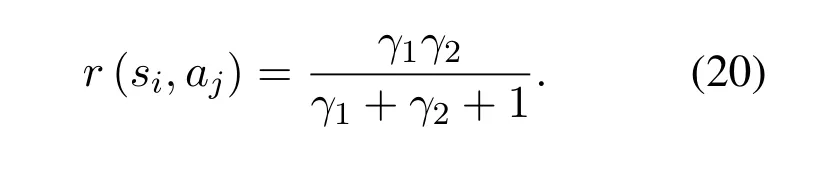
IV.SIMULATION RESULTS
V.CONCLUSION