
基于蒙古语新闻领域本体的分布式检索方法*
2021-04-06 10:48:28赵俊生王鑫宇尹玉洁
计算机工程与科学 2021年3期
赵俊生,王鑫宇,尹玉洁,张 林
(1.内蒙古工业大学信息工程学院,内蒙古 呼和浩特 010080;2.特警学院基础部,北京 100875)
1 引言
由于蒙古语的研究持续深入和对研究成果的普及推广,蒙古语记载的文字得到了快速网络化,促使传统Web向语义Web发展,导致语义Web的数据量迅速增长。语义Web作为当下研究的热点,在西文和中文领域发展迅速,但是在少数民族的语言文字领域却发展缓慢。由于蒙古族的文明与文化越来越受到国内外的关注,许多机构和学者开始对蒙古族文化进行探索和研究。而语言作为文化的载体,在文化的传承和研究中起着重要的作用。蒙古语是蒙古民族使用的语言,属于阿尔泰语系,且我国蒙古语的方言较多,主要有中部方言、东北部方言、西部方言,分别是内蒙古方言、卫拉特方言和巴尔虎布里亚特方言,方言中有不同的读音和词法,亟需统一,而畏吾体蒙古文就是各种方言通用的蒙古文。
随着蒙古文信息检索技术的不断发展以及Windows对蒙古文的支持,使用蒙古文检索的用户越来越多。内蒙古地区各个盟市,已经有各自的蒙古语官方新闻网站[1],但是网站数量多且繁杂,使得蒙古族人民在众多网站中查找自己需要的内容很困难,实现一个可以让蒙古语使用者使用的新闻领域语义Web检索系统已成为迫在眉睫的任务。
目前对于蒙古语语义Web的研究也在逐渐开展,文献[2]构建了“人工智能”蒙古语领域本体,实现了蒙古语“人工智能领域”的学习系统。文献[3]旨在提出一种构建蒙古语名词语义词典的方法,该词典收纳了使用频率较高的常用名词18 000条,翔实描述了每个词语的各种语义属性,为多义词的消歧、同形异义词的辨别和短语结构关系的判定提供了形式化的语义知识。文献[4]提出了一种融合主题模型LDA与语言模型的方法,更好地实现了蒙古文文档的主题语义检索,提高了检索的准确性。但是,目前的研究大多都是在单机环境下实现的,对于分布式环境下的蒙古语检索研究还比较少。
本文利用构建本体的原则和方法以及本体的相关理论[5 - 11]构建蒙古语新闻领域的本体,并将语义Web检索技术与分布式计算环境相结合,实现对蒙古语的新闻领域信息检索。分别将系统部署在单机环境和分布式环境下,对单机环境下的查询响应时间和分布式环境下的查询响应时间进行实验对比,验证分布式环境下的检索优势。该方法的实现可以推动蒙古语信息检索技术的发展,对于蒙古语信息资源共享具有重要意义。
2 蒙古语新闻领域本体的建立
2.1 本体构建需求分析与方法
(1)需求分析。
新闻是当下各用户获取信息最直接的载体,而近几年随着政府对蒙古语推广力度的加大,蒙古语新闻逐渐增多,蒙古语新闻网站也层出不穷,例如:中国蒙古语新闻网、新华社蒙古文网、人民网蒙古文网、蒙古语央视网和中国蒙古语广播网等。在内蒙古自治区各个旗县盟市也陆续有了新闻媒体、党政机关和教育机构的蒙古语网站。蒙古语网站建设取得了显著成绩,蒙古语资源也呈指数级增长。但是,从未来发展的角度来看,对这些网络资源进行集成处理将是蒙古语网络建设者亟需解决的新课题。
传统的基于关键字的信息检索技术会产生“词语孤岛”问题,这种方法往往存在检索出的结果不全、不完整和质量不高的问题,从而无法满足用户的需求,用户要在海量数据中找到自己需要的信息困难较大。而语义Web信息检索技术可有效提高获取信息的查准率和查全率,减少信息搜索的时间,是满足用户检索需求的好方法。语义Web的技术核心是领域本体,通过对本体网的语义相似性计算,将关键词进行语义扩展之后再进行检索,就可以在一定程度上提升检索的查全率和查准率。新闻领域本体与实例的数据量庞杂,容量可达TB级别,而 Hadoop的分布式计算环境可以方便地解决大数据量的存储与运算问题,所以将新闻领域本体与分布式系统结合,实现蒙古语语义Web信息检索是必然的解决方案。
(2)本体构建方法。
目前为止,本体构建仍没有统一的标准,在构建领域本体的过程中,还是需要有领域专家的参与和协同工作,即需要人工构建本体。对于研究人员或者用户来说,构建本体的方法有很多种,没有特定的方法去建立本体,且不同领域的本体语义不相同。对于任意一个学科领域,应针对学科领域的特点和需求来选择某一种适合的方法。本文选择七步法结合骨架法来构建蒙古语新闻领域本体,采用Protégé应用软件和支持蒙古语的OWL(Web Ontology Language)网络本体描述语言来具体实现本体的建立。
2.2 确定领域概念及本体层次结构
(1)蒙古语言的特点。
蒙古语在语音、词汇和语法上与汉语有较大的区别。蒙古语将音节分为元音和辅音2部分,是根据音素本身的性质分析的。蒙古语没有字的单位,主要以多音节词为主,词汇一般分为词根和词缀2部分,词根由1个或2个音节构成,词缀仅含有一种意义,属于实词的一般分为静词类和不变词类。蒙古语的语法是主语-宾语-谓语的句式,与汉语刚好相反。相同的是蒙古语也有同义词、多义词、同形异义词、同义异形词、近义词、上位词和下位词等。蒙古语的这些特点是分析蒙古语新闻领域本体概念间的语义关系和层次结构的依据和基础。
(2)领域本体概念之间的关系及层次结构。
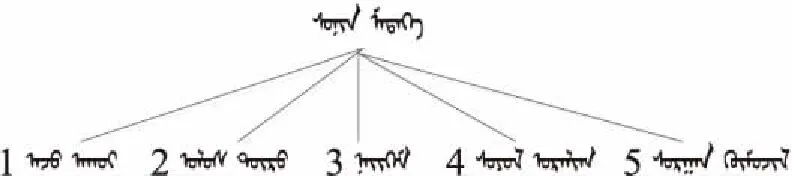
Figure 1 One level concept structure of news ontology
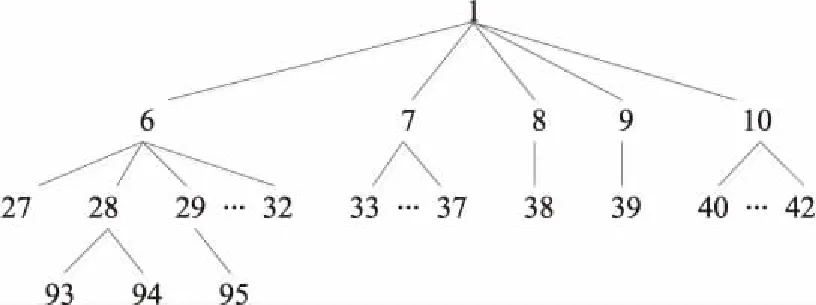
Figure 2 Structure chart of ontology concept under economics concept
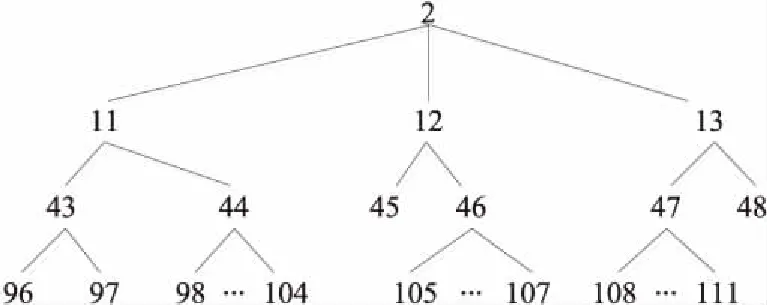
Figure 3 Structure chart of ontology concept under politics concept

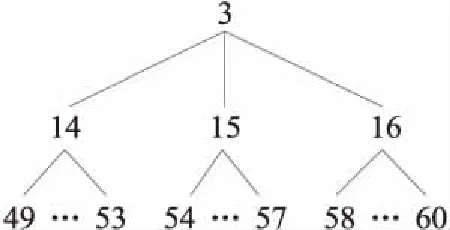
Figure 4 Structure chart of ontology concept under society concept
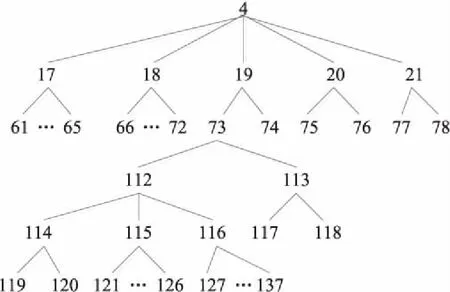
Figure 5 Structure chart of ontology concept under culture concept
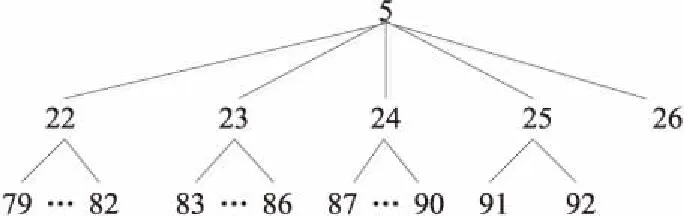
Figure 6 Structure chart of ontology concept under education concept
按照类之间的关系及关联性,依次自上而下、从左到右构建本体的2级、3级、4级、5级和6级概念,共计包含了137个领域概念类,形成了完整的蒙古语新闻领域本体结构。本体中各节点序号对应的概念信息如表1所示。
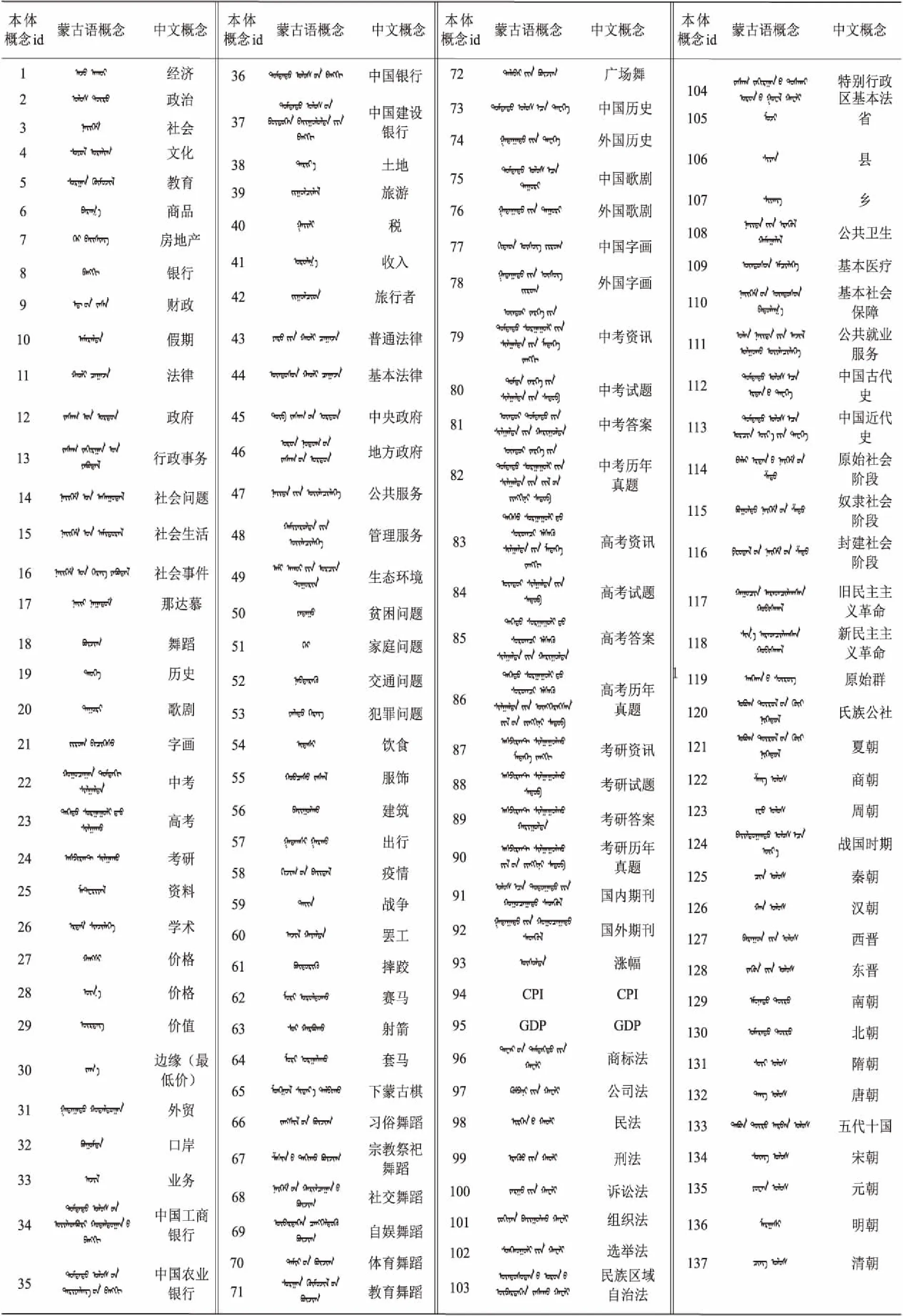
Table 1 Mongolian news domain ontology
2.3 定义类的属性

2.4 选择本体构建工具和本体语言
本文选择的本体构建工具是Protégé,它是基于Java语言开发的知识获取本体和本体编辑软件,也是基于知识的编辑器,属于开放源代码软件,主要用来构建语义Web中的本体。Protégé为开发人员提供了定义本体概念的功能,开发人员也可以定义本体之间的关系、属性和实例。因为该软件屏蔽了具体的本体描述语言,开发人员不会看到概念层次以下的结构,只需在概念层次上构建领域本体模型。
本文选择OWL语言实现本体数据的描述,OWL是RDFS(Resource Description Framework Schema)的一个扩展,OWL具有灵活快速的数据建模能力,并且可以进行高效的自动推理。OWL可以描述类、属性、个体和公理等类型的数据,本体模型中的概念在OWL中被描述成类,类中包含属性和实例对象。RDFS是基于RDF(Resource Description Framework)提出的,RDFS包括了类(rdfs:Class)、属性(rdfs:Property)、子类(rdfs:subClassOf)、子类属性(rdfs:PropertyOf)、定义域(rdfs:domain)和值域(rdfs:range)等。RDF本质是一个数据模型DM(Data Model),用三元组(s,p,o)来表示数据,其中,s、p和o分别代表主语(subject)、谓语(predicate)和宾语(object)。主语和谓语确定唯一的URI资源,宾语可以是资源或文字。RDF提供了处理元数据的基础设施和互操作标准,从而使计算机可以理解元数据的精确含义。RDF可使用自己的词汇表描述任何资源,并使计算机理解我们描述资源所使用的词汇表,自动便捷地处理Web上的各种资源,使得语义搜索更加准确和智能,解决了搜索引擎中返回无关数据的情况。下面是一个RDF/XML的展示。
〈rdf:RDF
xmlns:rdf="http://www.w3.org/2000/01/rdf-schema#"
xmlns:cd="http://www.semanticweb.org/chen/ontologies/2019/2/12/biye#"〉
〈rdf:Description
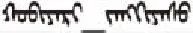
〈cd:from〉CCTV〈/cd:from〉
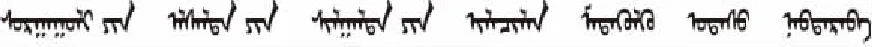
〈cd:time〉 2019/6/11 11:03 〈/cd:time〉
〈/rdf:Description〉
〈/rdf:RDF〉
其中,rdf:RDF定义了RDF文档根元素;xmlns:rdf定义了命名空间,规定了带有前缀rdf 的元素来自的命名空间;rdf:Description包含了被 rdf:about属性标识的资源描述;rdf:about定义了唯一标识的一个资源,剩下的就是资源的属性。
2.5 为本体类创建实例
定义好类和类属性以及类之间的关系后,要为每一个类创建实例。应用网络爬虫从蒙古语新闻网站爬取的大量新闻数据已存入MySQL数据库中,在数据表中的各个字段对应本体的各个数据属性,存储的每条记录对应本体类的一个实例。Jena是一个开源的基于Java的语义Web工具包,可以处理基于RDF的本体数据,为OWL和RDFS 提供不同的接口支持,并支持MySQL的数据存储及存取访问。本文使用Jena API将MySQL表的一条记录创建为本体的一个实例,并分配唯一的标识符,然后将MySQL表的字段值转换为本体类的相应数据属性值,用记录的外键索引来创建本体实例之间的关系,从而实现了由数据库为本体类创建实例的过程[7]。
2.6 本体评价
蒙古语新闻领域本体可依据概念定义的明确性、客观性、完整性、一致性、最大单向可扩展性和最少约束等规则来进行定性评价[10],评价合格则完成本体构建,评价不合格则重新获取概念,并修改类间关系及层次结构,依照本体的构建步骤进行修改和完善,直到本体进化合格为止。
3 蒙古语语义相似度计算
语义相似度是衡量词语之间关系的一个重要指标,也是语义Web中最重要的一部分。国内学者朱征宇等[12]给出的定义是几个词语或词语之间可能替代或相互交换的程度。通过语义相似度的计算结果实现隐藏概念的扩充和语义的扩展,利于检索关键词的语义解析和检索范围的扩大,从而提高检索的查全率和查准率[12-14]。
3.1 基于语义距离的语义相似度计算
首先依据本体的层次结构,从顶级概念开始,依自上而下、从左到右的次序赋予每个概念节点的id序号为1,2,3,…。在本体层次结构中用路径长度和概念之间的深度差来表示概念之间的语义距离。概念之间的语义距离和语义相似度成反比,当2个概念之间有较大的语义距离时,它们的相似度较低;相反,则它们的相似度较高。语义距离与路径长度和深度有关,用Distance(a,b)表示在本体中概念a到达概念b中所需要的最少的边数。Depth(a,b)表示概念a与概念b的深度差,计算深度值又与自身深度和共有祖先深度有关,2个概念深度差越大,说明2个概念距离越远,语义相似度越低;反之,语义相似度较高。用式(1)表示为:
(1)
其中,d(NCA(a,b))代表共同祖先深度,d(a)代表概念a的深度,d(b)代表概念b的深度。
令根节点新闻的深度为1,则4层本体结构的概念深度最大为5。任意2个概念a和b之间的语义距离Distance(a,b)应介于0~2*Depth(T),Depth(T)是树的最大深度。再考虑到距离和深度的关系应是同增同减,那么基于距离深度的概念语义相似度计算如式(2)所示为:
(2)
其中,Simdistance(a,b)∈[0,1]。
3.2 基于信息量的语义相似度计算
在本体层次结构中,对于父节点来说,它的每一个概念子节点都是对其概念的细化和具体化,所以可以通过比较概念之间所包含的信息量和公共祖先概念节点的信息量来衡量概念之间的相似度。信息量的计算方式如式(3)所示:
IC(c)=-lbP
(3)
其中P代表概念节点c出现的概率,用概率来表示概念的信息量。概率P的计算如式(4)所示:
(4)
其中,countleaves是叶子节点的个数。当p为叶子节点时,p出现的概率就是总叶子节点数的倒数;当p为非叶子节点时,p出现的概率就是p的子节点出现的概率之和。其中C(p)是p节点的子节点个数,ci是p节点的第i个子节点,而P(ci)是ci出现的概率。
根据分析可知,概念a和b信息量的相似度也取决于最近共同祖先节点的信息量,所以本文基于内容的语义相似度计算方式如式(5)所示:
(5)
其中,σ是平衡因子,以确保分子不为0。经过实验得知,平衡因子取0.5时,语义相似度计算的结果与主观判断的结果相符度高。
3.3 基于语义重合和语义密度的语义相似度计算
语义重合度是指概念拥有相同的祖先节点的个数,相同祖先节点越少,表明它们不在一个分支,则相似度越低;反之,语义相似度越高。而语义密度是指概念所拥有的子节点的个数。在本体层次中不同分支节点拥有的子节点的数量不同。如果在本体中,某一概念的节点密度越大,说明对该节点概念的具体化、细化程度越高,语义相似度越高。基于语义重合和语义密度的语义相似度计算如式(6)所示:
Simpro(a,b)=
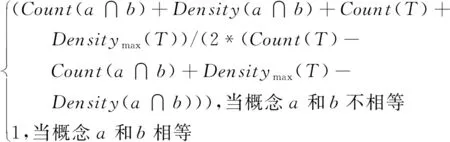
(6)
其中,Count(a∩b)代表概念a与b的共同父节点数;Density(a∩b)代表概念a与b的共同子节点数;Count(T)则是整棵树的父节点数;Densitymax(T)则是整棵树密度最大的节点数,也就是拥有子节点数最大的那个概念的子节点数。
3.4 混合式语义相似度计算
本文采用混合式语义相似度计算方式,根据实际情况进行混合,同时考虑了概念词的位置信息、概念词的信息量和概念词的密度等,如式(7)所示:
Sim(a,b)=α*Simdistance(a,b)+
β*Simic (a,b)+γ*Simpro(a,b)
(7)
因为每一个因素对语义相似度的影响不同,所以所占的比例也不同,故要对α、β、γ这3个参数的值进行实验确定。已知α+β+γ=1 ,用函数生成随机的60组满足条件的α、β、γ。通过实验得到,当α=0.35,β=0.2,γ=0.45时,既可以表达出父子节点的关系,也可以看出距离、信息量和语义密度以及重合度对语义相似度的影响。
表2中给出了4种语义相似度计算方法的实验结果。
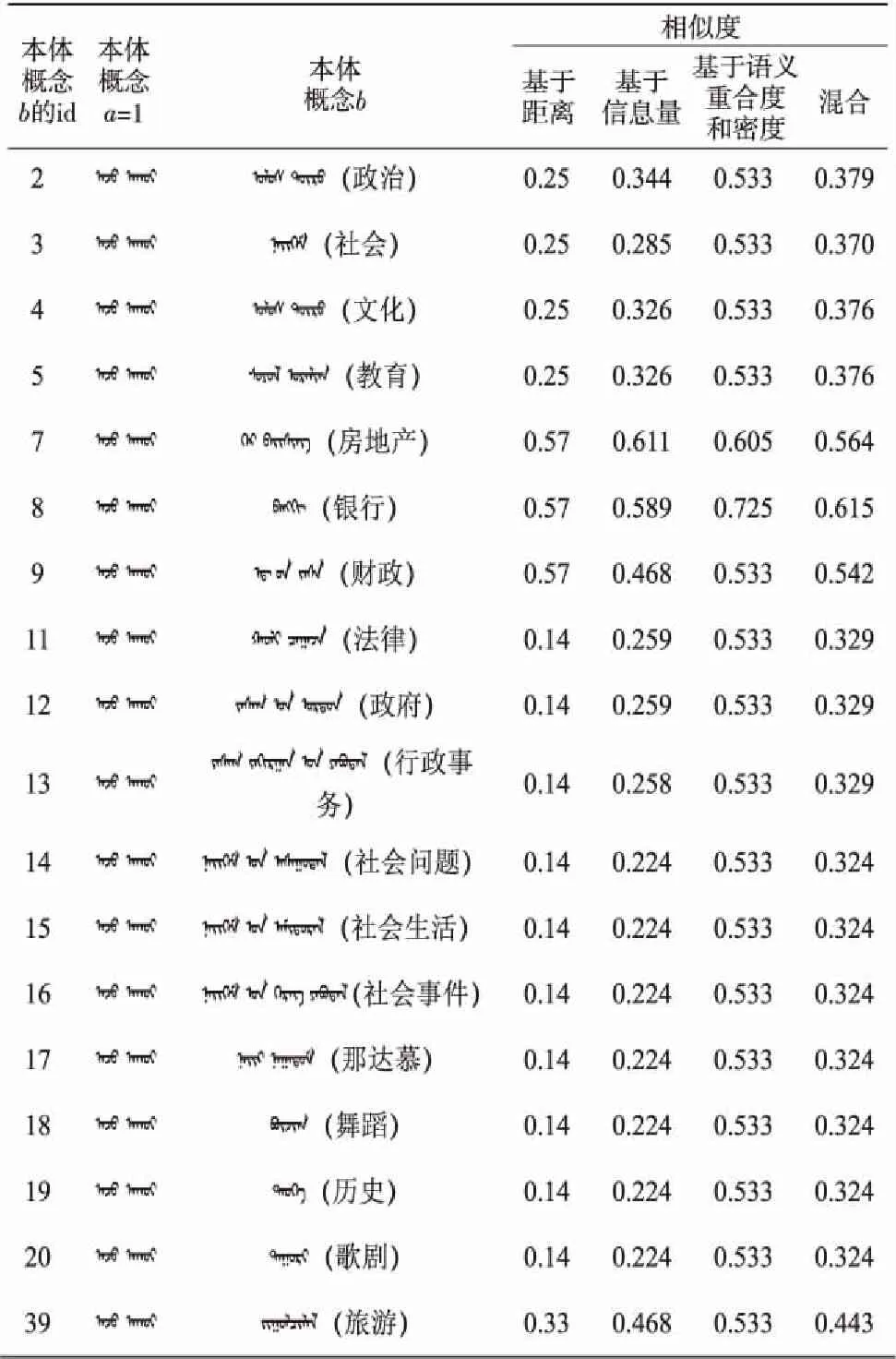
Table 2 Comparison of experimental results of four semantic similarity calculation methods
首先看基于距离的语义相似度,本体概念1与本体概念2、本体概念3、本体概念4、本体概念5是兄弟关系,根据距离与深度计算的结果都是0.25,因为本体概念2含有的子节点比较多,所以说本体概念1和本体概念2的相似度应该比其他兄弟本体概念的语义相似度高;再看基于信息量的计算结果,当2个本体概念所包含的子节点个数相同但处于不同的分支时,比如本体概念1和本体概念9,本体概念1和本体概念39,它们基于信息量的语义相似度一样,所以该方法没有办法考虑到位置信息;本体概念7和本体概念8均是本体概念1的子节点,本体概念11~13是本体概念1兄弟节点的子节点,而根据语义重合度的计算结果,无法判断哪个本体概念是兄弟节点,哪个本体概念是兄弟节点的子节点,所以也不适用于本文的本体。
经过对表2的分析,把数据结果大于0.5的本体概念取出,认为本体概念b和a相似。由实验结果得出,基于语义距离深度的语义相似度计算方法简单,易于实施,但是不能很好地体现节点密度和节点信息量之间的关系。基于信息量的语义相似度计算相对比较客观,能综合反映本体概念之间的相似性和差异,但是又不能完全分辨2个本体概念的位置信息。基于语义重合和语义密度的语义相似度计算必须依靠具有完备概念的概念集,本体概念语义重合和语义密度越大语义相似度越高,但不能反映概念节点距离和信息量之间的差异。
混合式的计算方法是将前3种计算方法混合起来,并且把每一个因素按照不同占比相加,最后所得出的语义相似度结果比单一因素的语义相似度结果更加准确。所以,本文采用混合式的语义相似度计算方法来对查询关键词进行语义扩展,然后在已经标记索引的本体实例库中进行搜索,从而得到所需的查询结果,最终充分提高检索的查全率和查准率。
4 蒙古语新闻领域分布式检索系统设计
4.1 分布式检索系统模型
将蒙古语新闻领域本体作为底层的知识组织基础,利用本体良好的概念层次结构和语义关系对用户查询请求进行规范化预处理和查询扩展,该模型主要由蒙古语新闻领域本体、用户界面模块、语义扩展模块、索引模块和Web信息管理库组成,如图7所示,只有Web信息管理库在本地。
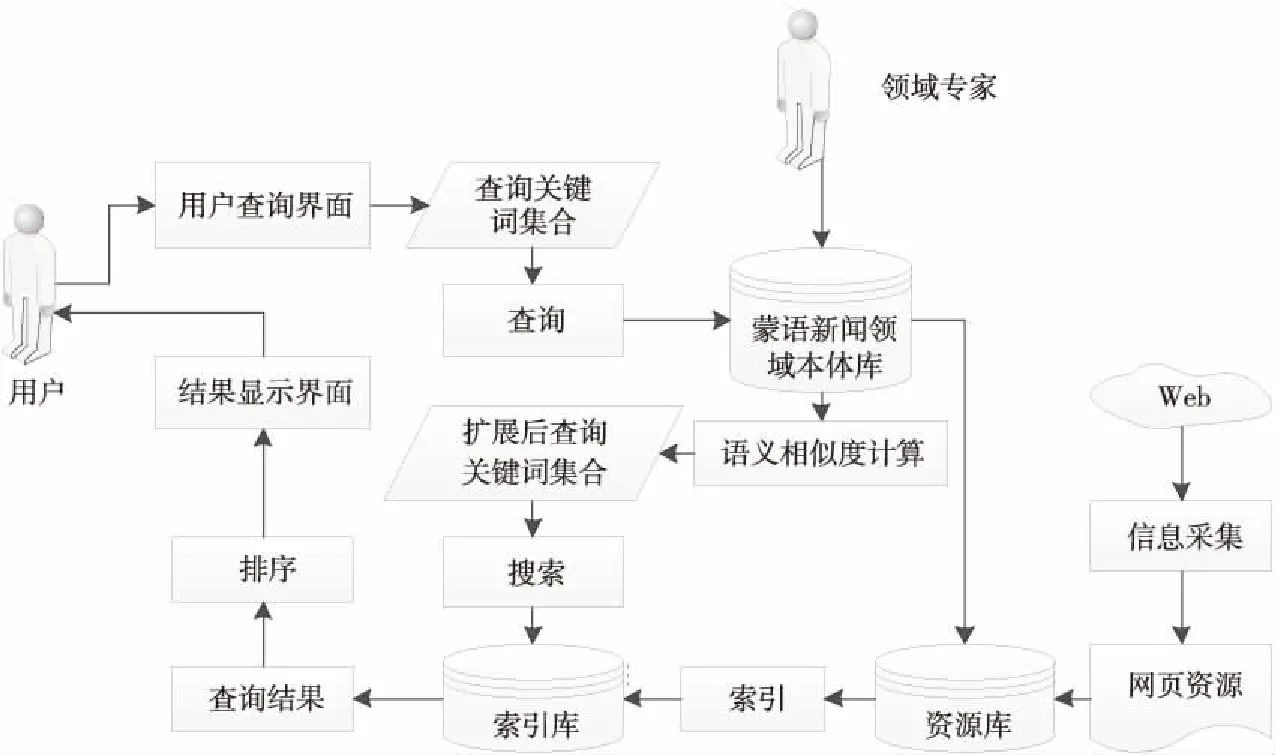
Figure 7 Model of Mongolian news domain retrieval system in distributed environment
4.2 分布式平台部署
本系统是基于Hadoop平台而设计的,Hadoop提供了基础的功能服务,因此要对Hadoop分布式平台进行规划和部署[15,16]。系统将使用3个节点,其中1个是master节点,其余2个为sla- ver节点。部署3台虚拟机系统为Ubuntu14.04版本,先部署Hadoop,再部署HBase(Hadoop Database),并使用HBase自带的ZooKeeper。因Hadoop和HBase版本要对应,所以本文使用的是Hadoop-2.7.3、HBase-1.2.4、Sqoop-1.4.7。机器名称和分配的地址如表3所示。

Table 3 Machine name and assigned address
4.3 数据在分布式环境下的存储
HBase是构建在HDFS(Hadoop Distributed File System)之上的分布式、面向列的数据库,HBase表由行和列组成,列分为若干个列族,行和列的坐标交叉决定了一个单元格,一个单元格需要根据行键、列族、列限定符和时间戳来确定,单元格中的数据都是字符串,没有类型。每个表的每一行都有一个可以排序的主键RowKey和任意多的列组成,列可以根据需要动态增加,同一个表中不同的行可以有截然不同的列。一个表可以有上亿行,上百万列,故能进行海量存储。HBase表是稀疏的,当表中某单元格没有数据时,该单元格将不会占用存储空间,因此减少了需要的存储量。由于HBase表由若干行组成,每行有一个行键RowKey作为这一行的唯一标识,则有如下3种方式访问表中的行:第1种是通过单个RowKey进行查询;第2种是通过RowKey的一个区间来访问;第3种是全表扫描。依上所述,RowKey是HBase表结构设计中重要的环节,其设计的好坏直接影响程序和HBase交互的效率和数据存储的性能[17,18]。在单机实验中,已将数据保存到了MySQL中,现在将借用Sqoop来将MySQL的数据存入HBase。根据上述考虑,将设计3个表,分别是:alldb表、idx表和sim表。alldb表存储的是所有本体的实例,idx表存储的是所有索引,sim表存储的是语义相似度的计算结果。
在alldb表中RowKey是本体的id,列名分别是f1、f2、f3。在f1列下存储实例的新闻链接(link)、新闻标题(top)和新闻内容(text);f2列下存储新闻的来源(from)和新闻的作者(author);f3列下存储新闻发布的时间(time)和新闻的id(num)。sim表中RowKey是本体概念的id,列名分别是f1、f2。在f1列下存储蒙古语本体概念(ont)和其中文含义(chn),f2列下存储每个蒙古语本体概念(1,2,3,…137)的语义相似度计算结果。idx表中RowKey是蒙古语本体概念(ont),列名分别是f1、f2。f1列下存储本体概念的id和索引(idx),f2列下存储中文含义(chn)。
4.4 分布式环境下检索方法的实现
本系统采用B/S结构,用Sqoop来进行批量数据传输。Sqoop可以分割数据集并创建MapReduce任务来处理每个区块的任务,可以将一个关系型数据库(例如:MySQL、Oracle、Postgres等)中的数据导入Hadoop的HDFS、HBase和Hive中,也可以将HDFS的数据导入关系型数据库中[19]。Sqoop底层用MapReduce程序实现抽取、转换和加载,本体数据的检索过程由MapReduce算法完成。与传统的ETL(Extract Transform Load)工具(如:Kettle等)相比,Sqoop中由于MapReduce的特性保证了并行化和高容错率。Sqoop的MapReduce任务在Hadoop集群上运行,减少了ETL服务器资源的使用。在特定情况下,抽取过程会有很大的性能提升。如果要使用Sqoop,因MapReduce任务的启动依赖于本地的Hadoop,所以必须在PC上正确地安装并配置Hadoop,MySQL数据库的JDBC(Java Data Base Connectivity)驱动也要放到Sqoop的lib目录下。
4.5 蒙古语新闻领域分布式检索结果

Figure 8 Query results
当用户把查询词提交到检索系统后,系统首先进行语义的扩展,在idx表中得到与查询词语义相似度大于0.5的本体id,然后在实例库表alldb中将本体id中的新闻实例取出,返回给查询结果显示模块。
5 检索系统性能分析
5.1 检索系统响应时间分析
本文通过对比单机环境和分布式环境下单用户和多用户的查询响应时间来反映查询效率。
(1)单机环境下的实验结果分析。
随机选择10个概念作为响应时间实验的对象。同时访问MySQL数据库进行检索操作,得到的结果如图9中单机环境下的单用户和多用户查询响应时间曲线所示。
由图9可以看出,单机环境下单用户查询不同关键词的响应时间普遍在30~35 s,对于用户来说这个检索时间就很长了,如果同时有10个用户访问服务器进行查询,那么查询响应时间普遍在148~236 s,这对于当下的使用环境,用户体验是极其不友好的。
(2)分布式环境下的实验结果分析。
将单机环境下所选择的10个关键词同样用到Hadoop上做实验[20,21],得到的结果如图9中分布式环境下的单用户和多用户查询响应时间曲线所示。
由图9可以看出,在分布式环境下查询不同关键词的响应时间普遍在5~15 s左右,相比较单机环境检索的响应时间有所下降,如果同时有10个用户访问服务器进行查询,那么查询响应时间普遍在60~70 s。
(3)单机和分布式环境下的响应时间对比分析。
由图9可知,单机环境下查询处理的时间是分布式环境下的处理时间的2~3倍,分布式环境下多用户的查询响应时间大幅度缩短,随着并发用户数的大幅增加,减少的幅度会更加明显,差距会越来越大。所以,本文将大量的数据放在分布式环境下来缩短检索的响应时间是可行的。
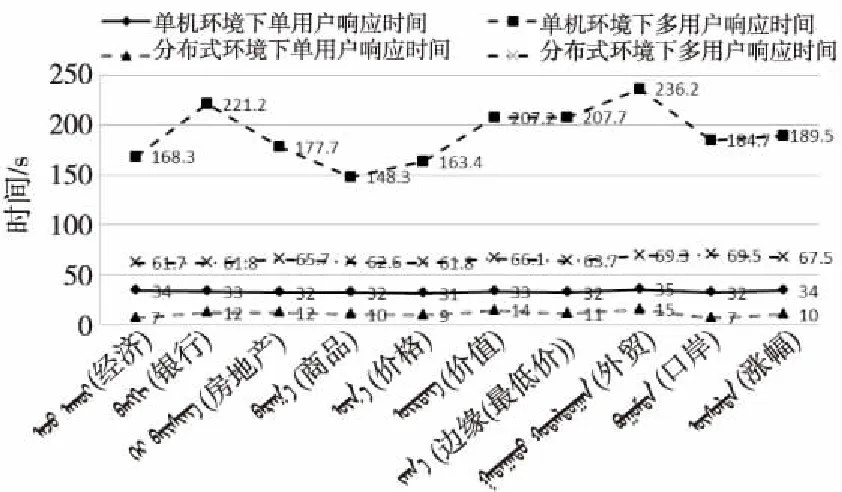
Figure 9 Comparison of query response time between single machine environment and distributed environment
5.2 检索系统综合评价指标分析
本文采用查全率和查准率相结合的综合评价指标F值来对蒙古语新闻检索系统的传统检索法和基于距离、信息量、语义重合和密度及混合语义相似度的检索方法作出评价,客观地反映混合语义相似度检索方法的优势和稳定性。
因为查全率和查准率有时会出现矛盾的情况,所以需要综合考虑查全率和查准率。本文中查准率P(Precision)是检索出的相关信息量与检索出的信息总量的百分比。而查全率R(Recall)是检索出的相关信息量与检索系统中相关信息总量的百分比。通常采用综合了查全率R和查准率P的评价指标F值,如式(8)所示。
(8)
F综合了P和R的结果,当F较高时,说明本文提出的方法比较有效。选择5.1节中的10个概念进行实验,分别计算不同语义相似度检索方法下检索的查全率R、查准率P和综合评价指标F,得到的F值比较结果如图10所示。
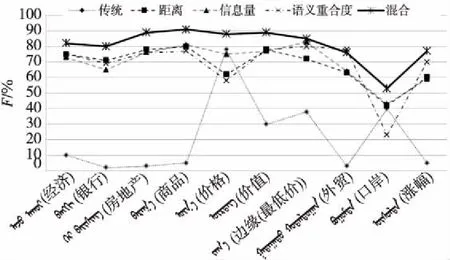
Figure 10 Comparison of retrieval evaluation index F of different semantic similarity calculation methods
由图10实验结果得出,传统检索方法的综合评价指标F值平均为21.5%,普遍低于语义Web的。而基于距离的语义相似度检索方法的F值平均为68.2%,基于信息量的语义相似度检索方法的F值平均为70.1%,基于语义重合和密度的语义相似度检索方法的F值平均为68.6%,以上3种检索方法的综合评价指标基本相当。本文改进的基于混合语义相似度检索方法的F值平均为81.3%,综合评价指标得到了较大的提升,从而表明混合语义相似度检索方法有效地提高了关键词查询的查全率和查准率。从图10可看出,混合语义相似度检索的综合评价指标的稳定性也明显好于其他方法的,没有出现太大的波动,并且普遍高于其他语义相似度的检索方法,所以本文改进的混合语义相似度检索方法提升了蒙古语新闻领域信息检索的查全率和查准率。
6 结束语
面对日益增长的蒙古语数据量和新闻网站,如果能快速、准确、全面地获取到需要的蒙古语新闻网络信息资源,就能很好地满足蒙古族人民在新闻领域中对信息检索的大量需求,满足对蒙古族文化传播和信息共享的需要。本文在建立蒙古语新闻领域本体的基础上,研究合适的混合式语义相似度计算方法进行语义扩展,分别研究和实现了单机环境下和分布式环境下的蒙古语新闻领域语义Web信息检索系统。系统性能分析结果表明,在支持大规模本体数据存储扩展的同时,分布式环境下的查询响应时间远少于单机环境下的查询响应时间,有效提高了蒙古语新闻的检索速度,同时也提高了蒙古语新闻关键词查询的查全率和查准率。
猜你喜欢
西部蒙古论坛(2022年2期)2022-07-12 04:47:38
蒙古学问题与争论(2020年0期)2020-03-29 06:26:58
西南交通大学学报(2018年5期)2018-11-08 10:59:16
现代电子技术(2018年16期)2018-08-21 02:57:42
赤峰学院学报(蒙文哲学社会科学版)(2018年1期)2018-04-25 07:57:25
现代电子技术(2017年23期)2017-12-20 13:23:31
计算机应用(2016年10期)2017-05-12 11:02:20
卫拉特研究(2016年0期)2016-12-06 09:12:06
新闻传播(2016年11期)2016-07-10 12:04:01
计算机工程(2015年4期)2015-07-05 08:29:20
