
用于面向目标的情感分析的分级预测策略
2021-03-29 03:08:04王卫红
浙江工业大学学报 2021年2期
王卫红,吴 成
(浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
面向目标的情感分析的主要任务是给定句子中的目标词,判断该目标词在当前句子中的情感极性。以句子“the food is good but the service is bad.”为例,在该句子中存在两个目标词“food”和“service”,这两个目标词在句子中的情感极性分别为正向与负向,在该任务上,神经网络的模型已经达到了较高的准确率。大部分神经网络模型都使用了注意力机制来捕捉目标与上下文的关系,但是注意力机制捕捉的词级别的特征可能会引入一些噪音。以“the dish tastes bad but its vegetable is delicious though it looks ugly.”为例,基于注意力机制的模型会在“bad”和“ugly”这些词上分配较大的权重。可以使用一种分层预测的策略来解决这个问题。将任务分为两个阶段:首先给所有的词分配一个软标签来标记该词作为意见词的概率,然后将所有标记的意见词的软标签作为特征来判断目标的情感极性。由于日常生活中人们语言使用非常自由,目标词的情感词在前后都可能出现,并且随着语境的变化相同的情感词有可能表达不同的情感,因此需要对词进行灵活的向量嵌入。笔者使用Bert对该过程建模,计算每个词的软标签概率[1]。卷积层在捕捉局部特征上有较好的表现[2],不仅在图像处理上有很好的效果[3-5],在文本分类上相对于其他神经网络效果也较好,因此使用卷积神经网络提取局部特征。此外,词语与目标词的距离也是一个重要特征,离目标词越近越可能是该目标的意见词,因此引入位置权重来捕捉该特征。
1 相关工作
在面向目标的情感分析任务中,以前的方法主要是监督学习并配合人工特征进行训练[6-8],通常忽略上下文信息以及目标与上下文的关系,一些使用该方法的神经网络模型在该任务上达到了较高的准确率。该方法具有一定的缺陷,比如AE-LSTM和ATAE-LSTM模型[9]仅仅将目标词的向量嵌入与上下文单词的向量嵌入拼接在一起来表示目标词与上下文的关系,都没有将目标词与上下文充分联系起来。Bert作为一种预训练的语言模型,极大地增强了词语之间的联系,使用实验语料对Bert进行微调,捕捉上下文关系,可以得到更灵活准确的向量嵌入。大部分SOTA的模型都使用了注意力机制来衡量句子中各单词的关系。IAN模型[10]采用了分开的两个LSTM层[11]和交互式的注意力机制;Hazarika等[12]使用注意力机制对句子内的目标词依赖进行建模,一次性对所有的目标词的情感极性进行分类;MemNet[13],RAM[14],TRMN[15],IARM[16]等使用句子级的深度记忆网络和多跳注意力机制将目标词信息整合到句子表示中,其中TRMN和IARM考虑了句子中各目标词之间的关系信息,着重对目标词和上下文以及目标词之间的关系进行建模。
考虑到卷积神经网络在文本分类和目标级情感分类问题上表现良好,笔者设计的模型采用了卷积神经网络。GCAE[17]和PG-CNN[18]都是基于卷积神经网络的模型,使用门机制对目标词和上下文进行建模。为进一步提升建模效果,引入位置权重对单词之间的距离信息进行编码。
2 模型介绍
目标级情感分析的任务是判别句子中目标词的情感极性,分为正向、中立和负向。笔者设计的模型架构如图1所示。
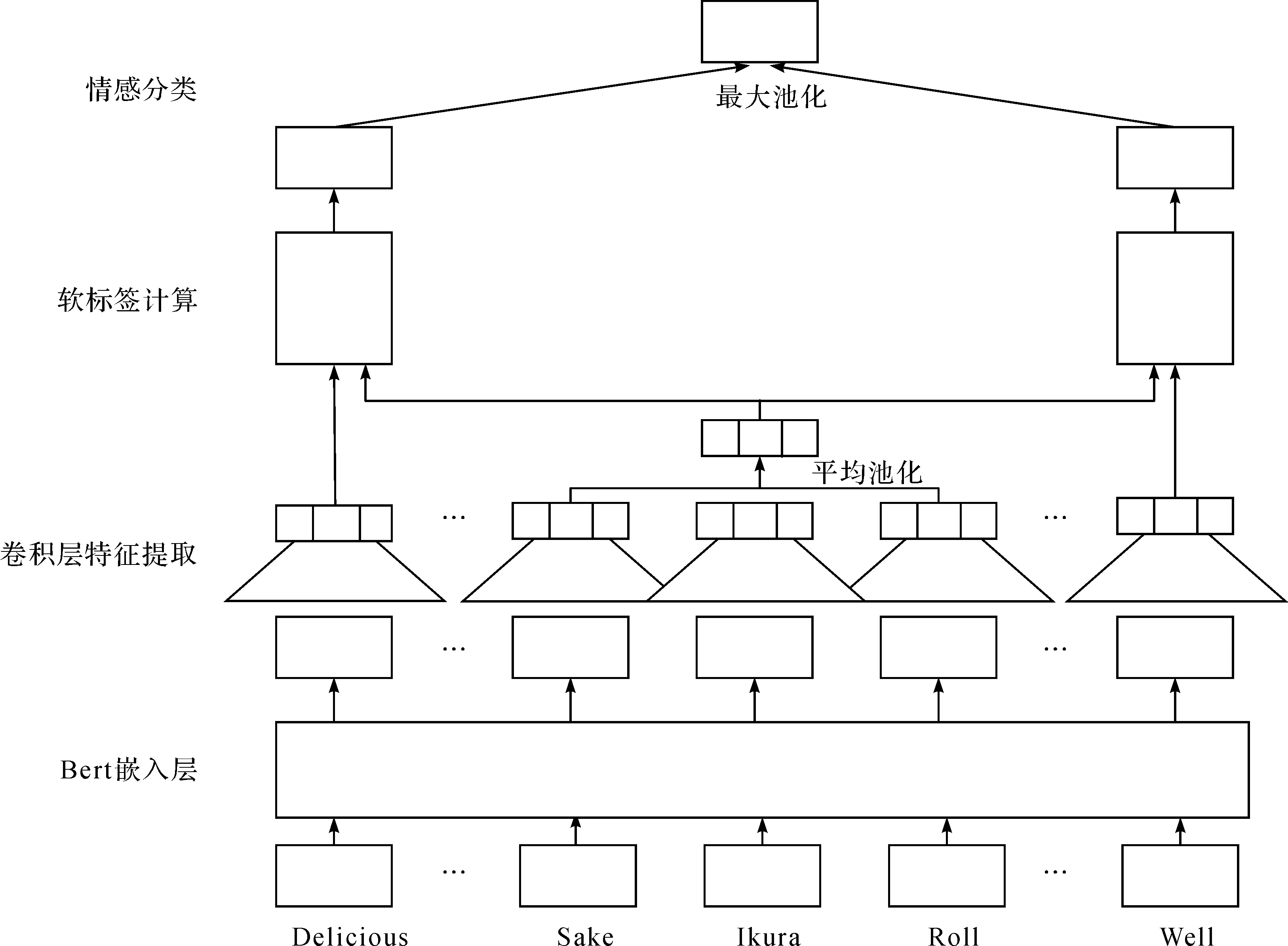
图1 模型组织架构
该模型由4 部分组成:1) 对上下文和目标词进行向量嵌入的Bert层;2) 基于卷积神经网络的特征提取器;3) 计算各单词软标签概率的软标签计算层;4) 结合位置权重和软标签概率输出情感极性的情感分类层。为方便起见,将一个句子表示为
s=[w1,w2,…,wn]
(1)
式中wi表示句子的第i个单词。
目标词位置表示为
t=[t,t+1,…,t+m-1]
(2)
式中:t≥1;t+m-1≤n,其中m为目标词长度。
2.1 Bert向量嵌入
自2018年诞生以来,Bert打破了很多自然语言处理任务的最好效果记录,因此采用Bert作为预训练语言模型。在使用Bert进行向量嵌入之前,使用SemEval语料的分类任务为Bert作微调工作。Bert模型由12 个Transformer block组成,在堆叠的12 个模块中,浅层模块通常学习的是比较基础的词语类信息,深层模块学习的是比较抽象的语义信息,分别取倒数第1~3 层的隐藏向量作为嵌入向量。实验结果显示倒数第2 层的隐藏向量效果最好,原因可能是倒数第1 层模块太靠近下游的训练任务,因此在语义的学习上反而不如倒数第2 层。最终采用倒数第2 层的隐藏向量作为嵌入的词向量和卷积层的输入。
2.2 卷积层特征提取
卷积神经网络在局部特征提取上相比于其他类型的网络(如RNN)通常具有更大优势,因此采用卷积神经网络进行语句局部信息的提取。在卷积核的选择上,受TextCNN模型启发,选择3 种不同大小的卷积核来提取不同维度的特征,然后将特征拼接后进行平均池化操作,最终得到固定大小的卷积层特征,卷积核大小分别为3,4,5。
假设每种卷积核有d1个模板,对于大小为sj的卷积核来说,可以用Wconvj∈Rd1×sj×2d′0表示其中的d1个卷积核模板的集合;用bconvj∈Rd1表示偏置;用xconvj表示卷积后的结果,计算式为
(3)
式中:RELU表示非线性的激活函数;∘表示点积操作。
将3 个卷积核的结果进行拼接即为最终的计算结果,计算式为
(4)
最后使用平均池化层计算htarget为
(5)
2.3 软标签计算
在目标级情感分析中,通常做法是通过上下文信息判断每个词是否为情感词,然后将判定为情感词的词语提取出来作为最终判断目标词情感极性的特征。但是,这种以“硬标签”的方式直接判定一个词是否为情感词,会造成在链式法则求导时出现不可微的点,从而不能使用后向传播方法;同时,由于对情感词的错误判定,在后续特征提取时会造成更大的误差。笔者通过引入软标签来避免这两个问题,使用门机制对细胞的历史信息进行过滤,加强软标签与目标词的相关性。
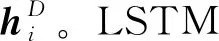
(6)

在上述计算过程中有一个问题,就是LSTM单元中存储的信息可能与目标词的关系不大。以预测“tasty food but the service was dreadful!”中的“service”一词的情感极性为例,将整句话输入LSTM层之后,有可能会由于“tasty”一词从而将整句的情感极性简单地预测为正面的,而没有考虑到“service”目标词的相关极性。笔者尝试通过引入门机制来解决这个问题,门机制可以根据历史信息和当前词与目标词的关系对当前细胞的历史信息进行过滤。其计算式为
(7)
式中Wg∈Rd′1×d′1为权重矩阵。
为加重目标词的影响力,将其信息加入到LSTM的输入中,计算式为
(8)
式中:WD∈Rd′1为权重参数;li-1为第i-1个单词的情感词概率。
为防止LSTM输入的向量维度过大,将目标词向量与词向量增加一个额外的运算操作。在得到LSTM层的输出之后,当前词的情感词概率的计算式为
(9)
式中ei=1,表示当前词相对于当前的目标词为情感词。
2.4 情感分类
最后的模块模型采用全连接层作为分类器。考虑到情感词与目标词之间的位置关系对情感判定的影响,给模型引入额外的特征,即相对位置权重。一般来说,离目标词越近,越能用于判断目标词的情感极性,基于这种考虑,笔者设计的位置权重为
(10)
式中β表示用来控制由与目标词的距离引起的位置权重的衰减速率。
将词概率与位置权重相结合,对上下文和相对位置特征进行整合,计算式为
ci=li×posi
(11)
进一步将词向量进行整合,预测目标词的情感极性,计算式为
(12)

训练过程中使用的损失函数为
(13)
式中:T为训练数据数量;yi为样本i的真实标签,是一个独热向量;pi,j表示样本i预测为极性j的概率;γ‖θ‖2为L2正则化损失。
3 实验结果
3.1 实验设置
实验使用的数据集是SemEval2014中的任务4,数据集为Laptop以及Restaurant,其统计数据如表1所示,评论分成3 个情感极性,即正向、中立和负向。
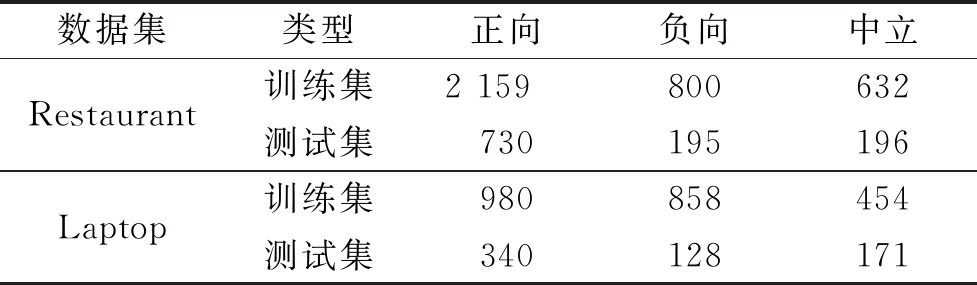
表1 数据集统计分布
实验中,首先用SemEval的分类任务对Bert进行微调,然后取Bert倒数第2 层的隐向量作为模型的嵌入向量,卷积核大小分别为3,4,5,每个卷积核有128 个过滤器。LSTM的输出是400 维,卷积层的输出是384 维。模型中使用了Adam进行梯度下降优化,学习速率设置为0.003,batchsize设置为128。为了防止过拟合,设置dropout的概率为0.5,L2正则的参数为0.000 01,用来调节位置权重的超参数β为40。
3.2 模型结果比较
将笔者设计的模型与之前的SOTA模型进行比较。其他模型信息为
1) GCAE模型,该模型基于卷积神经网络,使用门控Tanh-RELU单元控制信息流,对目标和上下文进行建模。
2) PG-CNN模型,该模型使用CNN作为基础架构,并使用门控机制来将目标信息编码进CNN结构中。
3) Hazarika模型,该模型使用双层LSTM结构对目标词之间的依赖进行检测,用注意力机制对句子中的所有目标词进行一次性分类输出。其中双层LSTM设计如下:首先,第1 层LSTM基于句子中的每个目标词对整句信息进行编码,其具体做法是将中间层中具有上下文信息的单词嵌入进行提取,将这些单词的向量进行简单拼接,输入LSTM,得到整句的编码向量;然后,将第1 层的输出作为第2 层的LSTM的输入来捕捉目标词之间的依赖信息。
4) Memnet模型,该模型使用了多跳注意力机制。具体做法是:将目标词的向量嵌入作为注意力模块第1 层的询问,并将注意力计算结果与目标词的线性变换相加作为中间记忆,然后进一步作为询问参与下一层的注意力计算。注意力机制最后一层的计算结果作为情感极性的向量表示,用来进行分类。
5) RAM模型,与Memnet类似,该模型也使用了多跳注意力机制,但是在计算中间记忆时加入了位置权重来对句子中的特征进行提取。
6) IARM模型,该模型混合使用了循环记忆网络与注意力机制。构建记忆网络的方法类似于Hazarika的模型的第1 层LSTM,使用基于目标词信息对整句进行编码,使用记忆网络对目标词之间的依赖来进行建模,而不是像Hazarika使用的LSTM。
在以上模型中,除了GCAE和PG-CNN,其他模型都采用了注意力机制对目标词和上下文进行建模。注意力机制虽然能较好地捕捉到情感词,但是没有充分考虑各个词位置之间的关系,从而混淆了目标词的真实情感极性。根据历史信息对每一步的单词单独估计其作为情感词的概率,并且额外引入相对位置权重衡量每个情感词对目标词的贡献。Memnet,RAM和IRAM模型是基于记忆网络进行设计的,仅仅提取了句子级别的特征,没有考虑单个词对目标情感极性的贡献,也就失去了情感词的信息。利用上下文历史信息对每个单词的情感词概率进行建模,充分利用了情感词的信息。基于卷积构建了GCAE和PG-CNN的模型,但是这两个模型的表现并不出色,其主要原因是原始的卷积层倾向于捕捉整个句子中最重要的特征,而不是寻找与目标词相关的特征。直观上离目标词越近的词与目标词的关系越密切,因此笔者设计了相对位置权重公式。通过以上策略对模型进行改进,效果对比如表2所示。
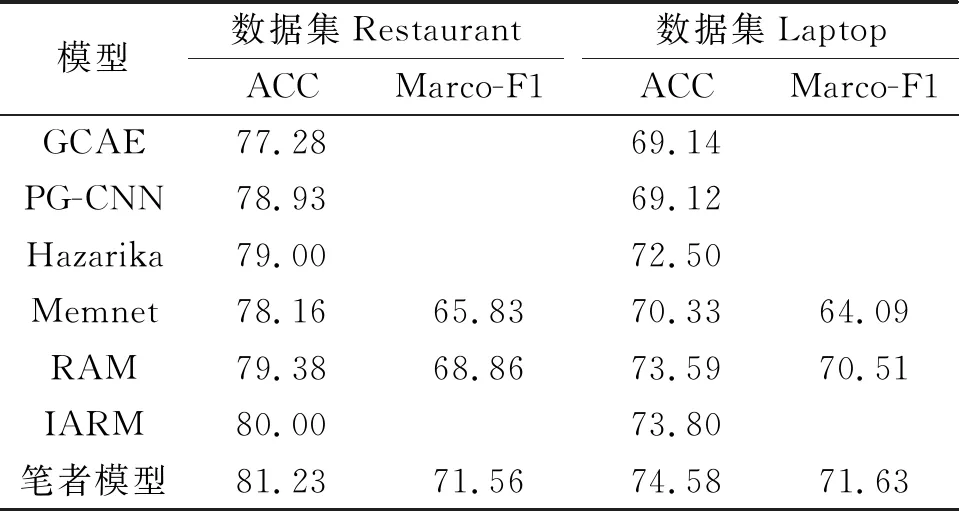
表2 各模型结果比较
3.3 模块分析
为估计各模块对模型的贡献,对模型中相应的模块进行移除操作或使用常用模型替代,观察其最终效果,效果对比如表3所示。
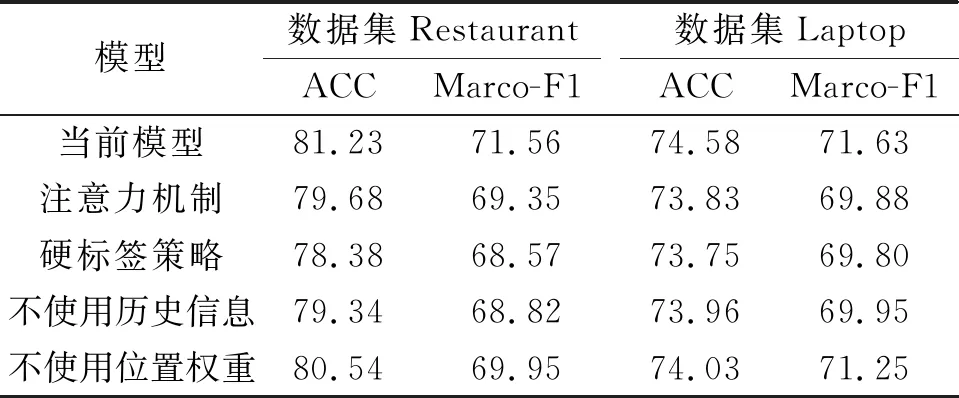
表3 模型模块分析对比
相比于之前的模型,笔者设计的模型使用了基于历史信息的软标签方法。注意力机制将目标词作为询问来计算其与上下文的关系,基于历史信息即之前的软标签概率和细胞状态计算当前软标签概率。为进一步评估软标签方法的效果,用注意力机制替代了该模块。结果显示:使用注意力机制的模型在Restaurant和Laptop这两个数据集上的准确率分别下降了1.55%和0.75%,Marco-F1则分别下降了2.21%和1.75%,说明采用软标签的方法是有效的。笔者也采用硬标签机制替换软标签机制进行效果评估。在硬标签机制中,一个词只能作为情感词或非情感词处理,标签值非0即1。软标签机制以0和1的概率来表示当前词作为情感词的概率,处理方式更为灵活。实验结果表明使用软标签相比于硬标签对实验效果有着巨大的提升。
笔者也测试了不使用历史信息和位置权重的模型的效果。不使用历史信息是指不将前一时间步的软标签信息和细胞状态作为当前时间步的输入,仅仅使用隐层的权值矩阵来计算当前时间步软标签的概率。结果表明:不使用历史信息,模型在两个数据集的准确率分别下降了1.89%和0.62%,说明历史信息在模型中起着重要作用;不使用位置权重,模型在两个数据集上的准确率分别下降了0.69%和0.55%,说明位置权重对于模型效果也有着明显的提升作用。
4 结 论
提出了一种基于计算情感词概率的分层策略来完成目标级情感分析任务,通过3 个途径提高了该任务的识别效果:1) 软标签的使用;2) 历史信息的有效利用;3) 相对位置权重的嵌入。在SemEval2014上的实验结果表明:笔者设计的模型相比Memnet、RAM和IARM等SOTA模型有一定提高。该模型存在的不足是:在实际工作中,同一个情感词在不同的上下文环境中有时有着不同的语义,会导致模型错判目标的情感极性,下一步的工作将解决这个问题。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
时代英语·高一(2019年5期)2019-09-03 02:09:34
电子制作(2019年11期)2019-07-04 00:34:38
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
公民与法治(2016年10期)2016-05-17 04:12:58
电测与仪表(2016年11期)2016-04-11 12:20:42
电源技术(2015年5期)2015-08-22 11:18:28
计算机工程(2015年8期)2015-07-03 12:20:27
