
基于户型图实例分割的室内场景建模研究
2021-03-29 03:08王辰鑫李澎林
浙江工业大学学报 2021年2期
李 伟,王辰鑫,李澎林
(浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
传统的数字城市是城市地理信息与其他城市信息相结合的一个虚拟空间,其关注的重点是城市的全貌[1]。随着“互联网+房地产”模式的出现,客户对房产信息获取体验提出了更高要求,房产室内场景的在线三维快速建模与展示成为亟待解决的技术难题,其技术难点在于建模效率和模型的灵活性。
当前,室内场景的三维建模方法主要分为人工和自动化建模两种。人工建模虽然具有较好的模型质量,但建模周期长、成本高;自动化建模主要有基于激光扫描和基于RGB-D图像两种方法。在基于激光扫描建模的研究方面,Enrique等[2]提出基于激光雷达点云数据建立室内边界模型的方法,对比较规则的室内平面,如墙、地板和天花板等进行了简单的重建;莫悠等[3]提出一种室内移动与地面定点激光扫描技术相结合的室内精细点云数据获取方式,解决了部分区域密度不足及缺失的问题。虽然基于激光扫描的建模方法相比人工建模提高了效率,但其数据采集设备非常昂贵,需要较大人力对模型进行后期处理。在基于RGB-D图像建模的研究方面,著名的KinectFusion系统[4-5]使用一台移动的Kinect摄像机完成精细的扫描和模型创建工作;Xiao等[6]采用人工标注的方法建立不同RGB-D视图之间的对应关系,从而建立完整的室内场景的三维模型;Choi等[7]提出了一种基于RGB-D视频的室内场景建模方法。虽然Kinect等消费级RGB-D摄像机降低了图像采集的成本,但要建立完整的室内场景三维模型,需要采集大量关联的RGB-D图像来获取对空间的整体理解,建模成本高、效率低。上述两类方法所建三维模型需实地采集数据,模型的灵活性较差,且模型数据量较大,在线浏览往往需要专业Web插件,在应用上有较大的局限性。随着卷积神经网络的提出,深度学习得到了迅速的发展,它能通过大量的样本学习得到目标的深层特征,而不需要人为指定的特征[8]。姚晓峰等[9]从RGB-D图像出发,通过改进的卷积神经网络模型,把室内场景的建模转化为一个图像分类问题;Mask R-CNN在图像识别中的三个重要任务中都取得了目前最好的结果[10],但目前还没有在室内场景建模方面的应用。综上所述,现有的室内场景三维建模方法建模成本高、效率低,所得模型数据量较大,且无法二次修改,灵活性差,无法满足房产室内场景的在线三维建模与展示要求。笔者设计一种基于户型图实例分割与ThreeJS的室内场景建模方法,该方法以住宅户型图栅格数据和户型结构矢量数据为输入,将Mask R-CNN应用于户型图栅格数据的实例分割,通过自动坐标配准与模型匹配等技术,快速而灵活地建立室内场景三维模型。
1 室内场景建模框架
室内场景三维模型主要包括墙体和空间家具,其中墙体空间信息可通过户型结构矢量数据获得,室内空间的家具适配及摆放是自动建模的难点,因此,笔者提出的基于户型图实例分割与ThreeJS的室内场景建模框架处理过程分为两个阶段:
1) 户型图实例分割阶段:通过Mask R-CNN算法对户型图栅格数据样本集进行训练,得到检测模型;在实际建模过程中,直接使用该模型检测户型图栅格数据,得到实例分割结果——家具掩膜图像。
2) 室内场景三维建模阶段:首先将家具掩膜图像与户型结构矢量数据进行配准,然后计算家具坐标,结合家具模型库适配模型,最后基于ThreeJS完成三维场景可视化。室内场景建模框架如图1所示。
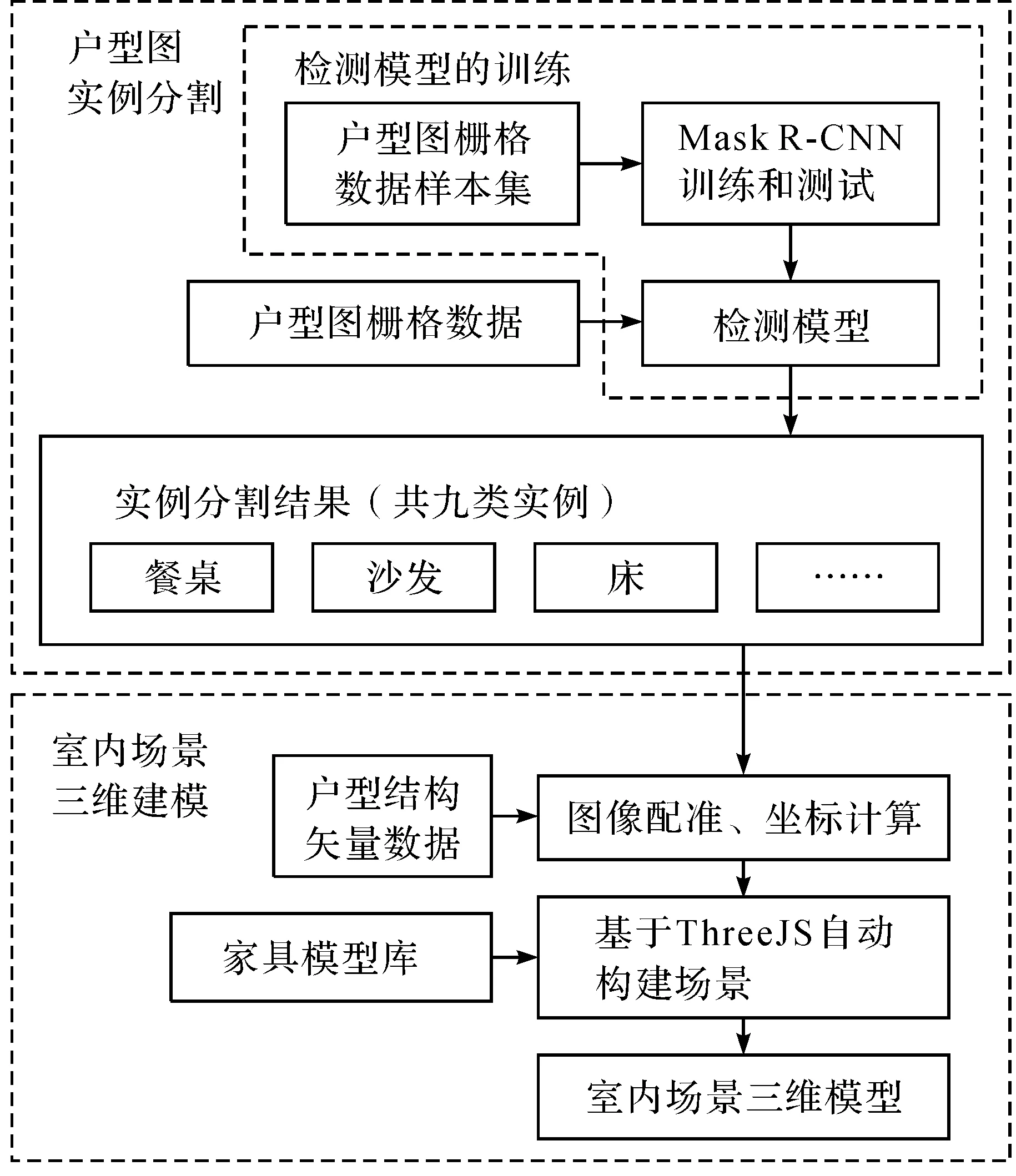
图1 室内场景建模框架图
2 户型图实例分割
该阶段创建了户型图栅格数据样本集,通过Mask R-CNN算法对该数据集进行训练和测试,得到效果最好的检测模型。在实际建模过程中,直接使用该检测模型对输入的户型图栅格数据进行实例分割,输出实例分割结果。
2.1 户型图栅格数据样本集
为了验证Mask R-CNN检测和识别户型图栅格数据的有效性,创建了户型图栅格数据样本集(以下简称数据集),如图2所示。该数据集搜集了各类户型图,其中房产市场主流的三居室和四居室分别占56.8%和30.4%,其他户型占12.8%。通过旋转、翻转等数据增强方法解决因没有足够的训练数据所导致的性能问题[11],得到户型图栅格数据原始样本共1 250 幅,其中1 050 幅作为训练集,200 幅作为测试集。
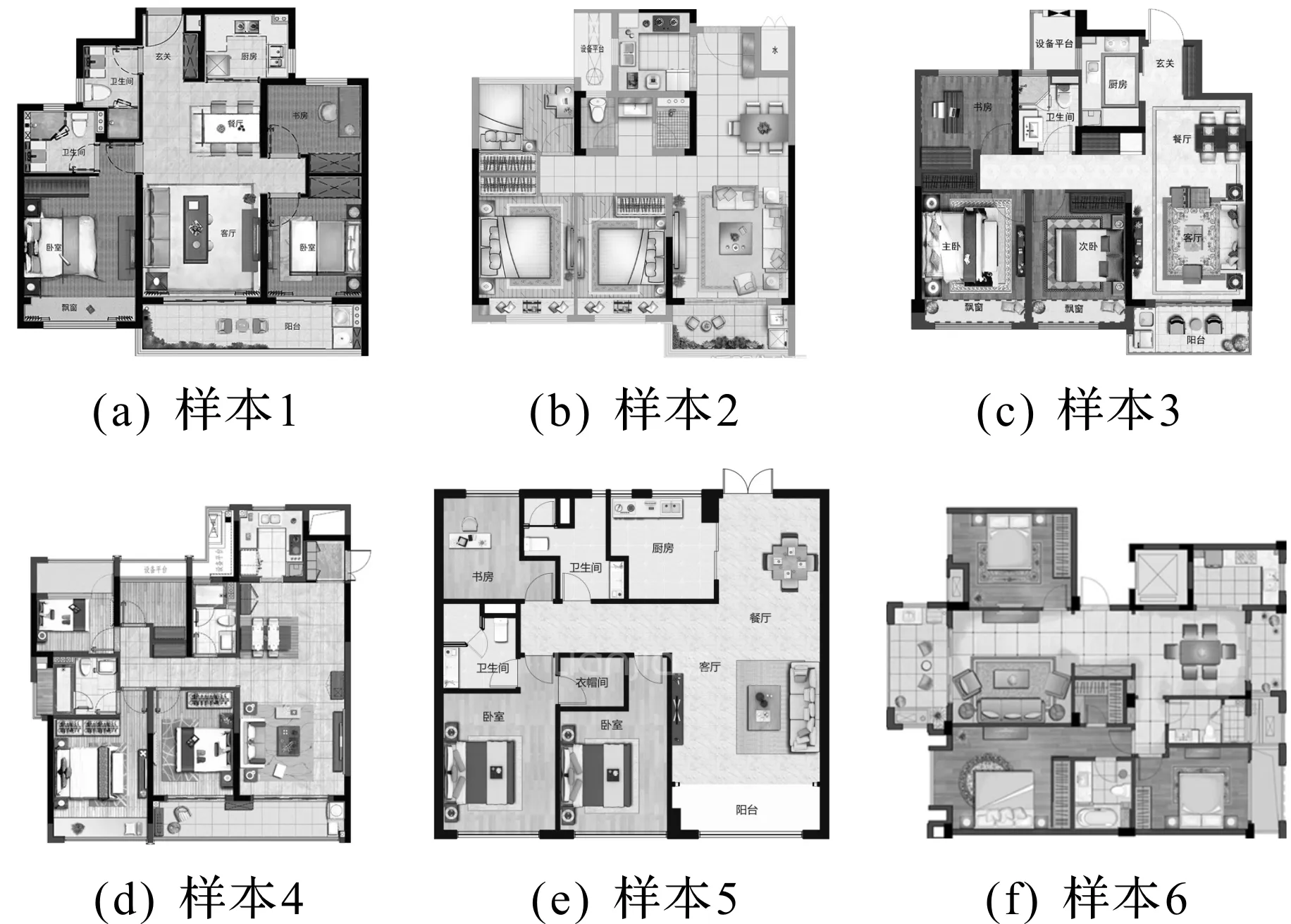
图2 部分数据原始样本
笔者定义了8 类需要进行图像语义分割标注的家具,按其出现的场景可分为4 类,如表1所示,这4 类场景占据了住宅的大部分面积,可以构成一个比较完整的室内场景。

表1 家具分类表
通过在原始样本上对这8 类家具进行人工标注,得到数据集格式,如图3所示。图3(a)是原图,图3(b)是用labelme制作的灰度标签形成的伪彩色图,图3(c)是伪彩色图在原图所占的面积显示,右下角是其图例。

图3 数据集构成
笔者自定义了一张RGB颜色表,如表2所示,附加在灰度标签上,Mask R-CNN神经网络的标签共有9 类灰度值,颜色表可以直观地表明灰度值与家具的对应关系。

表2 RGB颜色表
2.2 Mask R-CNN训练和测试
采用的深度学习算法是FaceBook AI研究院提出的端到端卷积神经网络Mask R-CNN。Mask R-CNN的网络结构如图4所示,它的框架简单、灵活和具有通用性。该网络能有效地检测在图像中同时出现的每个实例,预测出每个实例的类别,并对每个实例生成一个高质量的掩膜(mask)。Mask R-CNN使用的是Faster R-CNN的框架[12],并且在这个基础上增加了一个并行的掩膜(mask)分支,可同时实现分类和像素级掩膜的分割。训练采用多任务损失函数,在Faster R-CNN损失函数的基础上增加了3 个损失函数,损失函数表达式为
L=Lrpn_class+Lrpn_bbox+Lcls+Lbox+Lmask
(1)
式中:Lrpn_class和Lrpn_bbox均为Faster R-CNN 中的损失函数;Lcls为分类损失函数;Lbox为边界框损失函数;Lmask为掩膜损失函数。

图4 Mask R-CNN网络结构图
模型训练阶段,通过户型图栅格样本对具有初始参数的卷积神经网络进行迭代训练,根据训练结果和Tensorboard查看训练过程,从而不断优化相关训练参数,最终得到目标检测模型。笔者模型的训练流程包含4 个步骤:
步骤1将经过标注和Mask掩膜制作的户型图样本输入到一个预训练模型的神经网络(ResNet-101-FPN)中获得对应户型图训练样本的特征图,对这个特征图中的每个位置生成9 种预先设置好面积和长宽比的目标框,从而得到多个候选RoI(region of interest)。
步骤2将这些候选的RoI送入区域建议网络(RPN)进行二值分类(前景和背景)和BB(bounding box)回归,通过非极大值抑制算法筛选得到RoI,对RoI进行RoI Align操作。
步骤3对RoI进行分类(家具分类)、BB回归和Mask生成。
步骤4重复步骤2,3,训练完所有样本得到最终优化调整的检测模型。
模型测试阶段,将测试样本输入目标检测模型得到检测结果。笔者模型的测试流程包含2 个步骤:
步骤1利用测试样本对户型图目标检测模型进行测试,得到测试样本的检测结果。
步骤2人工判断测试结果是否符合要求,如不符合要求则调整训练参数重新进行模型训练。
3 室内场景三维建模
该阶段首先使用薄板样条插值算法将家具掩膜图像与户型结构矢量数据进行配准,其次根据配准后的图像计算掩膜外切矩形的顶点坐标,最后根据适配规则适配家具库中的模型,基于ThreeJS完成三维场景可视化。
3.1 图像配准、坐标计算
采用薄板样条插值算法对户型结构矢量数据和家具掩膜图像进行图像配准[13-14]。薄板样条插值算法是在非刚性配准中应用最广泛的非线性变换算法[15],它包含一个全局仿射变换和一个结合权重的局部非线性项[16]。对于在图像上的N个控制点(xi,yi)∈R及对应的函数值vi∈R,薄板样条插值函数f(x,y)定义了映射f:R2→R,它有最小弯曲能量Ef为
(2)
并且闭合形式的解为
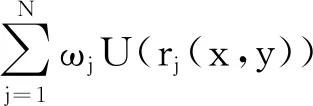
(3)
式中:rj(x,y)为插值点(x,y)到第j个控制点(xj,yj)的距离;α1,α2,α3,ωj为加权系数;U(rj(x,y))为薄板样条插值基函数。
将N个控制点坐标及对应的函数值代入式(3),联立得到薄板样条插值的系数α和ω有以下线性方程的解:
(4)
式中:Kij=U(rij);P的第i行为(1,xi,yi);ω,v为由ωi和vi分别构成的列向量;α=(α1,α2,α3)T。
图像配准流程如下:
1) 在户型图墙体结构上选择4 个分散的控制点。
2) 将控制点坐标及其对应的值代入薄板样条插值函数求解。
3) 由求解结果变换图像,完成家具掩膜图像和户型结构矢量数据的配准工作。
根据配准后的图像可以计算得到家具掩膜外切矩形的顶点坐标,为下一步构建场景提供了基础。
3.2 家具模型库
根据表1的分类方法将模型分为4 类,家具及其配套家具以模型组合的形式添加到模型库中,并根据相关信息定义模型的类型、长宽、构成元素及数量、装饰风格等属性。由于家具模型的文件大小会极大地影响整体模型在WebGL中的运行效率[17],而glTF是“3D JPEG”,所以将搜集到的三维模型通过格式转换工具预处理成glTF格式。
3.3 基于ThreeJS自动构建场景
室内场景的三维模型由目标空间的墙体结构和家具模型组成,其中墙体结构由房屋结构矢量数据确定。家具模型的确定分为模型适配和模型放置两个过程。
笔者模型的适配规则如下:
1) 装饰风格默认为简约现代风格。
2) 卧室家具根据识别到的床的长宽比和床头柜的数量适配模型,床头柜缺失的情况将床头柜数量默认设置为2;根据识别到的电视柜的长宽比适配电视柜模型。
3) 客厅家具根据识别到的最大的沙发的长宽比和沙发的数量适配沙发及配套茶几模型;根据识别到的电视柜的长宽比适配电视柜模型。
4) 餐厅家具根据识别到的餐桌的长宽比和椅子的数量适配模型。
5) 书房家具根据识别到的桌子的长宽比适配模型。
由笔者模型的适配规则,从模型库中适配模型加载到ThreeJS中,则调整模型的步骤如下:
步骤1根据模型包围盒质心坐标相对坐标原点的偏移量校正模型坐标到坐标原点。
步骤2根据掩膜外切矩形的顶点坐标定义标准包围盒。
步骤3根据包围盒顶点坐标分别计算标准包围盒和模型实际包围盒的边长。
步骤4若标准包围盒垂直于模型实际包围盒,则将模型旋转90°后重复步骤3。
步骤5根据标准包围盒和模型实际包围盒边长的比例关系,取最小值作为缩放比例缩放模型。
步骤6根据标准包围盒质心坐标相对坐标原点的偏移量移动模型。
步骤7手动调整模型的朝向、装饰风格得到室内场景三维建模结果。
4 实验及分析
实验计算平台采用NVIDIA GeForce 2080Ti的GPU,搭载Intel Core i7-9700K CPU,32 GB内存,ubuntu18.04系统的PC机。PSPNet是目前最好的语义分割网络[18],为验证Mask R-CNN的检测和识别效果更优,选择PSPNet作为Mask R-CNN的对照实验组, 在数据集上对两种算法进行训练和测试,部分实验结果如图5所示,Mask R-CNN的识别结果相比PSPNet边缘更平滑、噪声点更少,识别效果更好。
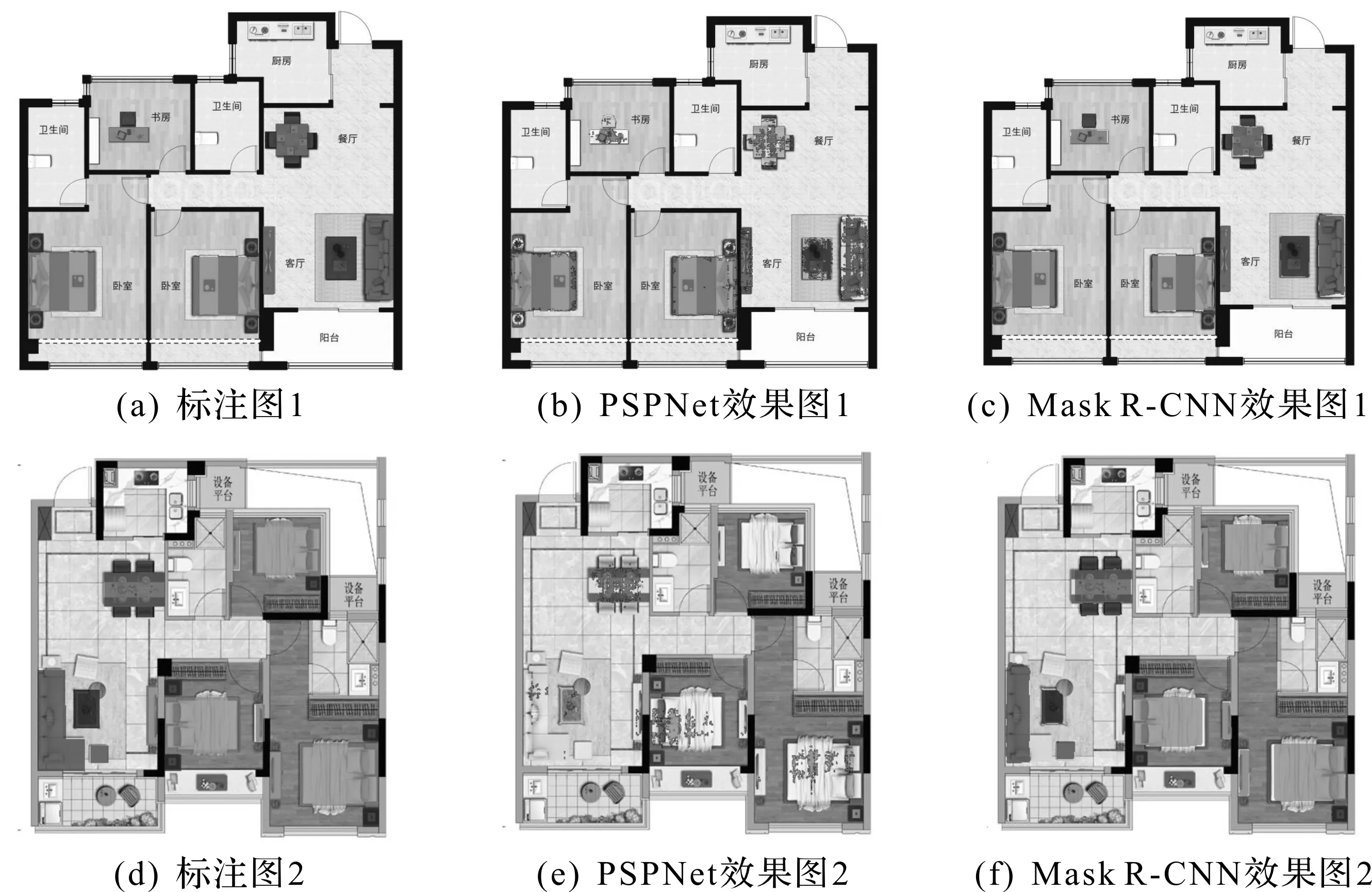
图5 部分实验结果
传统的目标检测是从待检测数据中准确完整地识别和检测出所有目标,因此采用检出率(true positive rate,TPR)、误检率(false positive rate,FPR)、漏检率(loss positive rate,LPR)作为实例分割结果的评价指标,具体如下:
1) 检出率表示一个样本集中,被分类器检测的正样本数目占目标实际总数的比值,其表达式为
(5)
式中:nP为正样本数目;n为目标实际总数。
2) 误检率表示一个样本集中,被分类器错误判定为目标的数目占所有被分类器检测的正样本数目的比值,其表达式为
(6)
式中:nFP为被分类器错误判定为目标的数目;nP为正样本数目。
3) 漏检率表示一个样本集中,未被分类器检测到的目标数量占目标实际总数的比值,其表达式为
(7)
式中:nL为未被分类器检测到的目标数量;n为目标实际总数。
通过对测试结果的统计,得到表3实验对比结果。由表3可见:就实验对象而言,Mask R-CNN算法的检出率达到了97.05%,漏检率仅为4.72%,都远远优于PSPNet。由此得出:使用Mask R-CNN算法能够有效地检测和识别户型图中的家具,为后续三维建模提供了基础。

表3 不同算法实验结果对比
图6给出了部分户型图栅格数据的实例分割和自动三维建模效果图。从图6中可以看出:即使户型图中不存在床头柜实例,也可通过笔者的三维建模方法建立完整的室内场景模型。实验表明:通过输入户型图栅格数据和户型结构矢量数据,系统可以快速地生成模型,用户可以根据效果对模型进行调整,使模型更符合要求。
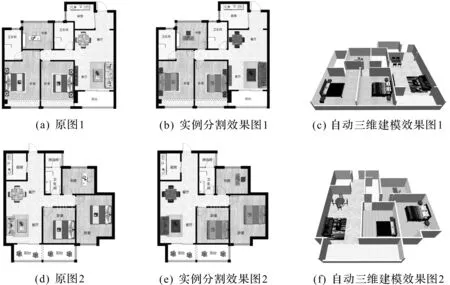
图6 部分三维建模效果
表4给出了笔者方法与不同建模方法的对比。其中建模成本由人工成本、时间成本和设备成本等3 方面综合评估;建模效率由模型制作周期确定;模型质量由三维场景与真实场景的差异性确定;Web可视化难易由是否易于实现在线访问模型、是否需要插件支持等因素确定;模型灵活性由场景内各家具元素是否独立、易替换确定。从表4中可以看出:笔者方法以较低的建模成本、较高的建模效率满足了房产室内场景的在线三维建模与展示需求,且模型灵活性较好、模型质量符合预期。

表4 不同建模方法对比
5 结 论
现有的室内场景三维建模方法建模成本高、效率低和灵活性差,已无法满足房产室内场景的在线三维建模与展示的需求,为此,提出了一种基于户型图实例分割与ThreeJS的室内场景建模方法。该方法有两点创新:1) 将Mask R-CNN应用到了户型图栅格数据实例分割上,解决了三维建模的数据采集问题;2) 基于ThreeJS完成三维场景可视化,实现了在线浏览房产室内场景三维模型。实验结果表明:该方法基本满足房产室内场景的在线三维建模与展示的需求。由于户型结构检测难度较大,直接使用户型结构矢量数据构建室内场景的墙体,后续工作可以加强基于户型图的墙体识别,简化建模流程,实现在缺少户型结构矢量数据的情况下建立室内场景三维模型的愿望。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
电子技术与软件工程(2021年5期)2021-06-16
阅读与作文(小学高年级版)(2020年12期)2020-12-23
河北画报(2020年8期)2020-10-27
证券市场红周刊(2019年44期)2019-11-23
电子技术与软件工程(2018年5期)2018-04-09
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
缤纷家居(2010年6期)2010-06-09
