
KPCA-CS-SVM下的矿井突水水源判别模型
2021-03-26 06:32毛志勇崔鹏杰黄春娟韩榕月
辽宁工程技术大学学报(自然科学版) 2021年2期
毛志勇,崔鹏杰,黄春娟,韩榕月
(辽宁工程技术大学 工商管理学院,辽宁 葫芦岛 125105)
0 引言
煤矿突水是煤矿生产安全的主要威胁之一,该类灾害一旦发生,往往会造成重大的人员伤亡和巨大的经济损失.为有效预防此类灾害发生,最大限度地减少灾害带来的损失,研究如何快速判别突水水源以及时采取相应的防治水措施具有非常重要而现实的意义.
随着国内外学者相关研究的不断深入,矿井突水水源判别的研究方法理论已日趋成熟,目前,常见水源判别方法主要有3类,分别是水温水位法、水化学分析法、数学理论分析法.其中,运用数学方法的突水水源判别多以水质数据为基础,利用数学方法计算而得出判别结论,判别准确度较高,在实际工作中得到广泛的应用,具有很好的实用价值,相关的数学方法[1]随着机器学习理论及技术的发展也越来越丰富,如HUANG P[2-3]等提出了一种结合水化学和多元统计方法的判别模型,建立的Piper-PCA-Bayes-LOOCV判别模型可以有效提高识别精度;利用主成分分析(PCA)结合Piper三线性图和Fisher判别理论,建立了Piper-PCA-Fisher突水水源识别模型;YANG[4]、MA[5]等利用模糊聚类分析建立了模糊综合评价模型,用于矿井突水的快速识别;黄平华[6]、鲁金涛[7]等运用Fisher判别分析法分别对矿井突水水源进行准确识别做了基础性工作;宫凤强[8]等以淮南老矿区谢一煤矿的突水信息为研究对象,首次建立了基于距离判别分析法的突水水源识别模型;邓清海[9]等建立了鹤壁矿区突水水源的Bayes判别模型,为水害防治提供决策依据;张好[10]等运用主成分分析与Bayes判别法对突水水源判别应用作了补充性验证;温廷新[11]等运用Logistic回归分析和随机森林(Random Forest,RF)模型有效判别矿井突水水源;刘剑民[12]等将模糊综合评判和矩阵方程分析相结合应用于矿井突水水源识别,证明了该模型可有效预测突水水源类型;还有基于BP、Elman、SVM、ELM、ESN等神经网络模型[13-20]的突水水源判别方法的有效性均得到验证.上述研究都取得了一定的成果,促进了矿井突水水源判别研究领域的进展,为矿井安全生产做出了较大贡献.但目前很多突水水源识别方法仍存在一定的局限性,如SVM等方法效率及应用效果受有关参数选取影响较大,一些方法在判别指标选取时忽视了指标之间的信息冗余等,因此还有进一步改进和优化的空间.
针对以上问题,本文以淮南新庄孜矿为例,利用核主成分分析(Kernel Principal Component Analysis,KPCA)判别指标相关性的消减,利用布谷鸟搜索算法(Cuckoo Search,CS)对支持向量机(Support Vector Machines,SVM)的惩罚因子C和核参数g进行寻优,建立基于KPCA-CS-SVM的矿井突水水源判别模型,以期提高突水水源判别的有效性和准确性.
1 KPCA-CS-SVM理论模型
1.1 核主成分分析
核主成分分析是主成分分析(Principal Component Analysis,PCA)的非线性扩展算法,通过非线性的方法抽取主成分.其基本思想是:将PCA算法与核方法相结合,通过非线性映射将原问题的输入空间投影到高维特征空间,然后在此高维空间采用PCA算法来处理问题;采用核主成分分析可以用于降维,消除判别指标间的相关性和信息冗余,KPCA的基本原理见文献[21].
1.2 支持向量机
支持向量机(Support Vector Machine, SVM)是一种能够较好地解决高维数、小样本、非线性问题的神经网络模型.其基本思想是:利用核函数,将低维空间下的输入向量通过非线性变换映射到高维的特征向量空间,然后在该高维空间创造一个最优超平面,结合结构风险最小化原则和VC维理论,对样本进行线性分类,最终实现低维输入空间下的非线性分类.但其算法性能与惩罚因子C和核参数g取值有非常紧密联系,如果惩罚因子C和核参数g选择不当,算法性能会很差.SVM模型的具体理论和操作步骤见文献[22].
1.3 布谷鸟搜索算法
布谷鸟属于寄生繁殖性鸟类,在繁殖期间不筑巢、不孵卵、不育雏,而是采取巢寄生来繁衍后代.2009年,Xinshe Yang和Suash Deb依据布谷鸟行为学研究的相关理论,提出了模拟布谷鸟寄生繁殖行为的布谷鸟搜索算法(Cuckoo Search,CS).布谷鸟搜索算法设定了3个规则,如下所述:
(1)每只布谷鸟每次产蛋个数为1,代表问题的一个解,并随机分布到寄主鸟巢中;
(2)在所有鸟巢中,有一部分鸟巢中具有优质蛋,代表较好地问题解,这些鸟巢将被保留至下一代;
(3)寄主鸟巢的数量固定,且布谷鸟蛋被寄主发现的概率为Pa∈[0,1],此时寄主可能消除此蛋或另建新巢.
布谷鸟搜索算法执行的是随机性较强的莱维飞行方式,可用式(1)表示.
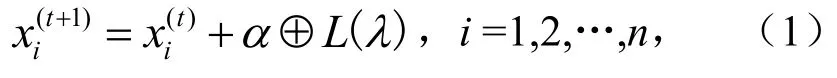
布谷鸟算法可用于参数寻优,寻优效果较好[23].
1.4 KPCA-CS-SVM模型流程的建立
传统的判别方法没有考虑指标间的相关性和信息冗余,直接使用指标数据容易对判别结果产生负面影响,且指标数过多也影响算法执行速度,需要降维,本文采用KPCA方法对判别指标数据进行降维处理;选取径向基函数(Radial Basis Function,RBF)作为SVM模型的核函数,如果不加以优化,惩罚因子C和核参数g选择不当将严重影响了SVM的泛化能力和学习能力,因而引入了CS算法优化SVM参数,使其预测效果达到最优.基于上述思路,本文建立基于KPCA-CS-SVM预测模型,具体处理流程见图1.

图1 KPCA-CS-SVM模型的具体处理流程Fig.1 specific process flow of KPCA-CS-SVM model
2 矿井突水水源判别模型建立及应用
2.1 特征指标的选取
(1)指标的初选
矿井突水受到多重因素的综合影响,各影响因素间存在着复杂的线性关系,本文以淮南新庄孜矿突水信息为研究背景,综合考虑各影响因素,最终选取了7个因素作为矿井突水的判别指标,分别为Ca2+(G1)、Mg2+(G2)、K++Na+(G3)、HCO3-(G4)、SO42-(G5)、Cl-(G6)和总硬度(G7)等的离子浓度(单位均为mg/L).文献[24]对每个影响因素进行了详细说明,此处不再赘述.此外,根据各含水层的水化学特征(地下水在形成过程中,由于受到含水层的沉积期、地层岩性、建造和地化环境等诸多因素的影响,使储存在不同含水层中的地下水主要化学成分有所不同),新庄孜矿井突水水源的类型可分为3类:煤系Ⅰ(HCO3--Na型)、太灰系Ⅱ(HCO3--Ca-Mg型)和奥灰系+C3Ⅲ(HCO3--Ca -Mg型、HCO3-Cl-- Na -Ca型、HCO3-Cl-- Na-Mg型).
文献[24]提供的淮南新庄孜矿突水典型样本数据(部分)见表1.
(2)数据的相关性分析及KPCA处理
先对表1的原始数据进行归一化处理,将物理数值变成相对值关系,减小数量级存在的较大差异,使得原始数据被规整到[0,1]范围内(部分见表1).通过相关性分析得出判别指标间具有明显的相关性(相关性矩阵见表2),存在着信息重叠,因此,有必要对样本数据进行KPCA处理.

表1 原始样本数据、归一化数据及KPCA降维数据Tab.1 original sample data, normalized data and KPCA dimension reduction data

表2 相关性Tab.2 relevance
根据主成分选取标准(累积贡献率大于85%),最终利用KPCA方法提取到4个主成分,分别记为F1、F2、F3和F4,对应的累积方差贡献率分别为44.382%、69.009%、83.853%、97.047%(见表3).由成分得分系数矩阵得到如下数学模型(表达式2-5),提取的4个主成分的协方差矩阵是一个单位阵,说明几个主成分不存在线性相关关系,本次主成分选取是理想的.经过KPCA降维后所得到的数据(部分)见表1.

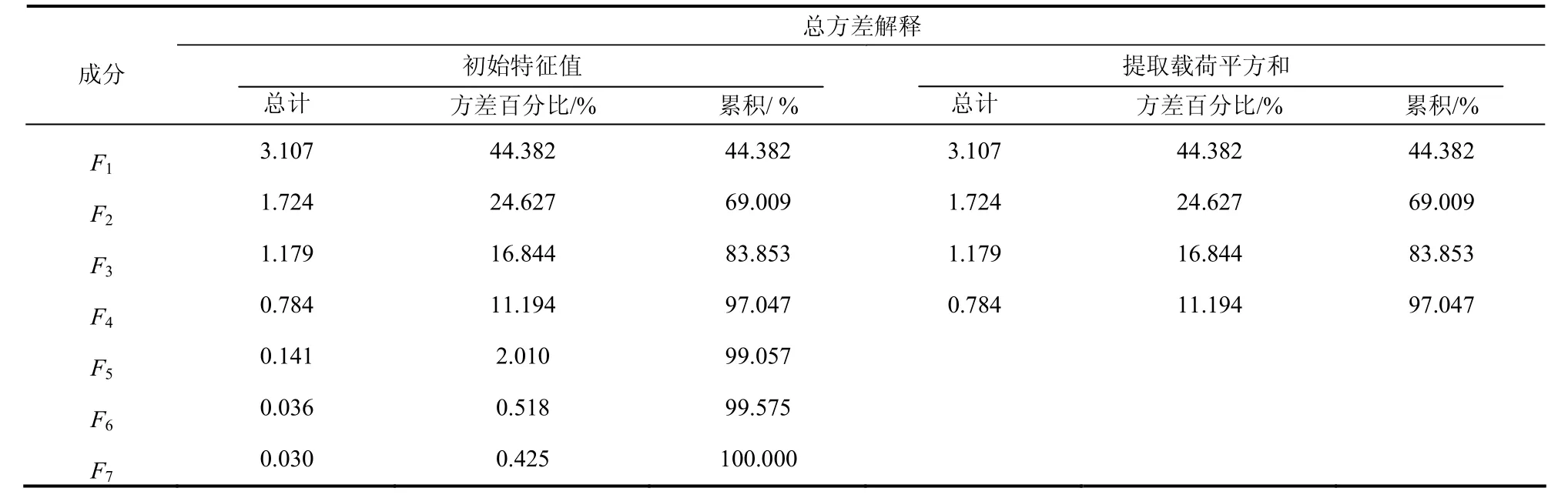
表3 累计方差贡献率Tab.3 accumulated variance contribution rate
2.2 矿井突水水源判别模型的建立与训练
将KPCA提取到的4个主成分作为CS-SVM预测模型的输入向量,突水水源类型作为输出,在Matlab软件平台上编写相应程序代码,利用LIBSVM 2.1工具箱,建立矿井突水水源判别的KPCA-CS-SVM模型.
利用建立的基于KPCA-CS-SVM预测模型,训练样本数据1~33(见表1),并将另外12组样本数据作为预测对象进行模型的判别.
2.3 矿井突水水源判别模型的检验与分析
将训练好的矿井突水水源判别模型对另外12组样本进行判别,结果与实际类型保持一致.从试验结果可知,该判别模型对矿井突水水源具有良好的判别能力.
为验证KPCA-CS-SVM预测模型的优越性,将其与KPCA-GA-SVM、KPCA-PSO-SVM模型作对比.为保证模型结果的公平可比性并使各模型效果发挥最优,模型相关参数是按照相关论文研究成果及实际测试合理设定,其中布谷鸟搜索算法Pa=0.25对于大多数优化问题具备很好的优势,遗传算法群体大小,一般取20~100;终止进化代数,一般取100~500;交叉概率,一般取0.4~0.99;变异概率,一般取0.000 1~0.1,粒子群算法c1和c2的取值通常在1.5到2之间[25-28],3个模型的寻优数量和终止代数已保持一致,参数具体设定见表4. 取终止代数=200,种群数量pop=25,CS算法、GA算法、PSO算法优化SVM参数的寻优过程分别见图2(a)、图2(b)、图2(c),模型适应度函数以判别突水水源错误率作为优化的目标函数值,CS、GA、PSO优化结果分别为:c=4.561 2,g=1.710 8,CAVccuracy=84.848 5%;c=56.081 7,g=0.859 7,CAVccuracy=81.395 3%;c=1.130 3,g=5.561 4,CAVccuracy=83.720 9%.图3(a)、图3(b)、图3(c)为3类算法判别结果,显然,CS具有更好的拟合度且收敛速度相当快,相对于GA、PSO有明显优势.由表5可知,KPCA-CS-SVM模型的判别准确率优于其他2个模型,不但收敛速度快,而且精度高,稳定性强,具有很强的泛化能力和学习能力.

表4 CS、GA、PSO算法的参数设定Tab.4 parameter settings of CS、GA、PSO algorithm
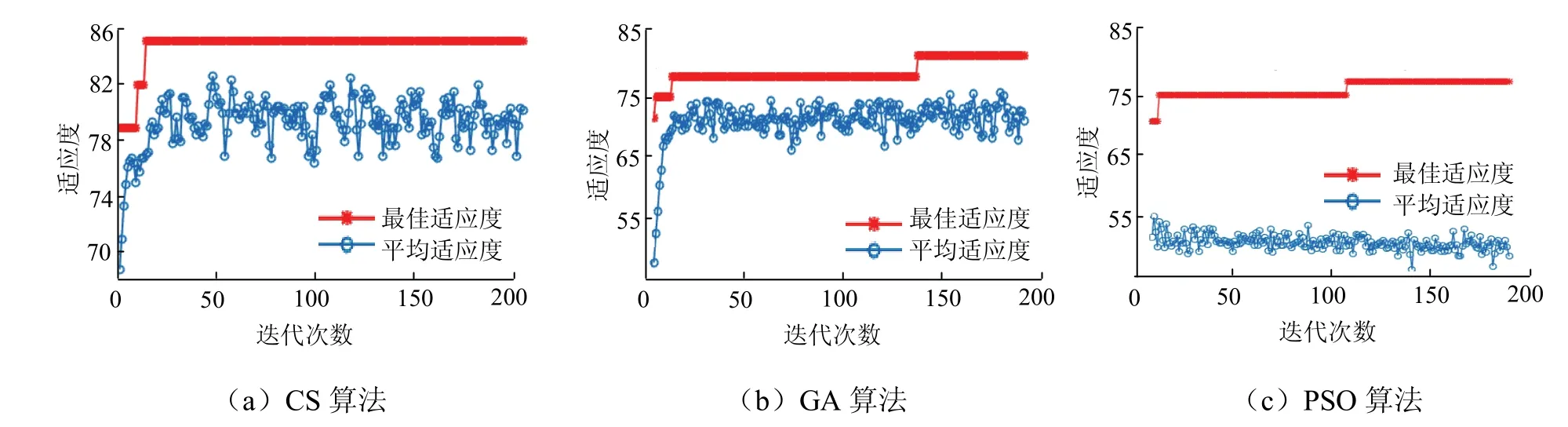
图2 支持向量机的参数寻优Fig.2 parameter optimization of support vector machine
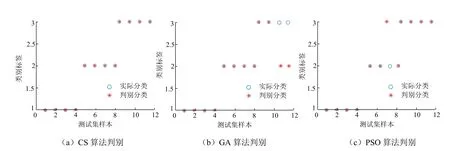
图3 判别分类Fig.3 discriminant classification
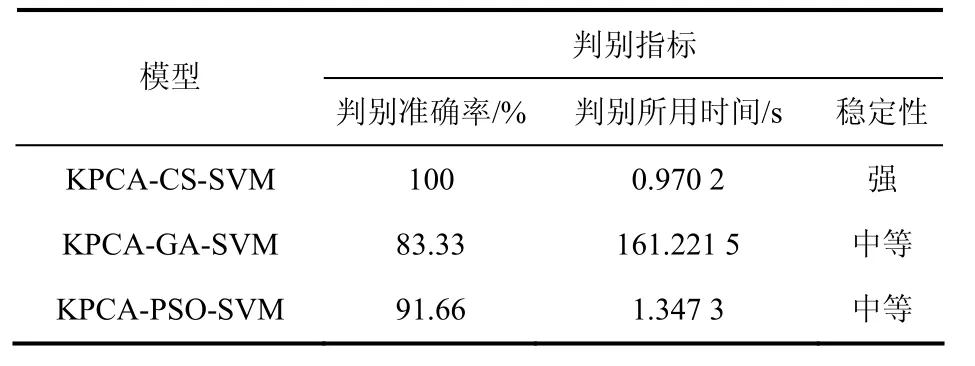
表5 判别结果对比Tab.5 comparison of discrimination results
3 结论
(1)建立了KPCA-CS-SVM矿井突水水源判别模型,利用KPCA方法对原始样本数据提取主成分,减少判别指标之间的信息重叠,降维的同时简化了模型结构,提高了算法的运行速率.并且引入CS搜索算法对SVM的惩罚因子C和核参数g进行寻优,由于莱维飞行的步长满足重尾的稳定分布,因此这种随机搜索更有效,与GA和PSO相比,CS搜索参数设定更少,提高了判别模型运行速度.相比于KPCA-GA-SVM、KPCA-PSO-SVM模型,KPCA-CS-SVM模型的判别准确率和运行速度更佳,具有更强的稳定性、泛化能力和学习能力.
(2)由于客观条件的限制,本文所使用的矿井突水水源判别数据有限,考虑的特征指标也较为有限,这在一定程度上影响了本模型的适用范围和判别的准确性.因此,在今后的突水研究工作中,有必要收集更加丰富的实测数据资料,同时引入更为全面的特征指标集合,以提供更佳可靠的判别信息,增强模型的适用性.
猜你喜欢
红蜻蜓·低年级(2021年12期)2022-01-19
内江科技(2021年6期)2021-12-28
红蜻蜓·低年级(2021年12期)2021-12-19
工程技术与管理(2021年19期)2021-04-03
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
山西焦煤科技(2016年4期)2016-12-01
剑南文学(2016年14期)2016-08-22
铁道科学与工程学报(2015年5期)2015-12-24
电测与仪表(2015年15期)2015-04-12
河北科技大学学报(2015年5期)2015-03-11
