
基于改进双流时空网络的人体行为识别
2021-03-25 12:23:24张红颖
光学精密工程 2021年2期
张红颖,安 征
(中国民航大学电子信息与自动化学院,天津300300)
1 引 言
人体行为识别作为视频理解的关键部分,一直以来都是计算机视觉领域的研究热点,在视频监控、虚拟现实、智能人机界面和社交视频推荐等领域有很高的应用价值[1-3],由于现实场景中存在着复杂背景、对象的外观差异和不同类别行为的相似性等问题,使行为识别仍然是一个具有挑战性的课题[4]。
视频行为识别主要可以分为基于手工设计特征的方法[5]和基于深度学习的方法[6],而后者展现出了更好的性能,其中双流卷积网络[7-9]的方法能够有效地在视频中提取表观信息和运动信息,在行为识别任务中取得了较好的识别效果,但是仍存在难以有效利用视频中的时空信息的问题。为此,研究学者们提出了多种改进方法,在网络输入方面,Bilen等[10]在保留次序信息的条件下将视频序列压缩为动态图,将其作为深度网络的输入,从而提取视频中的时序信息,但是动态图的生成带来了复杂的计算过程;在网络结构方面,Feichtenhofer等[11]等使用残差网络构建双流网络模型,并提出在两个卷积流之间加入短连接,以增强双流网络间的信息交互;在网络融合方面,文献[12]在隐藏层中间对两个网络融合,使网络学习时间域特征和空间域特征的像素间关系,并提出了多种融合方式。虽然以上三个方面的改进能够使双流网络更好的利用视频中的时空间信息,提高了行为识别准确率,但是仍存在着无法捕捉视频序列中时序关系的问题。此外,基于三维卷积神经网络的方法[13]在人体行为识别中也有不俗的表现,但参数和计算量会大大增加。因此,Lin等[14]提出了一种时间移位思想(Temporal Shift Module,TSM),使用二维卷积神经网络提取视频中的时序信息,但降低了网络的空间特征学习能力。
综合上述分析,本文提出了一种基于改进双流时空网络的人体行为识别算法。受时间移位思想的启发,构建了一个包含时空表观信息流和时空运动信息流的双流网络结构,提取包含时序关系信息的行为表观特征和运动特征,从而提高对时序依赖较大行为识别的辨识能力。然而由于时间移位模块的加入使网络的空间特征学习能力下降,为解决此问题,将卷积注意力机制[15]加入到卷积神经网络,通过在通道和空间上将学习到的注意力特征图与网络中生成的特征图进行加权,加大对局部细节信息的关注,从而提高网络的特征学习和表达能力,最后对两个流的输出类别得分进行加权平均融合,得到最终的识别结果。
2 本文算法
2.1 整体架构
本文提出的基于改进双流时空网络(Improved Two-stream Spatiotemporal Convolutional Neural Network,ITS-CNN)的人体行为识别算法的整体结构如图1所示,分为视频分段随机采样、改进双流时空网络和双流融合三部分。首先对输入视频进行分段随机采样,然后将采样得到的RGB视频帧和一组光流图像(x方向和y方向)送入改进双流时空网络,得到视频在时空表观信息 流(Spatiotemporal Apparent Information Flow,SAI-flow)和时空运动信息流(Spatiotemporal Motion Information Flow,SMI-flow)上的初始类别得分,最后采用加权平均的方式对初始类别得分进行融合,经过Softmax得到最终的识别结果。
2.2 视频分段随机采样与网络融合
现有双流网络的方法在短时行为的识别中取得了较好的效果,但是由于只能从单张RGB视频帧(空间流)和堆叠光流图像(时间流)中学习表观特征和运动特征,因此在对时间跨度较长的行为识别过程中会丢失部分重要信息,导致学习到的特征不能准确的代表整个行为,从而对长时行为难以准确识别。为此采用视频分段随机采样策略,实现对整段行为视频的有效学习,同时稀疏采样的方式减少了视频中的冗余信息。具体地,将输入视频分成时间长度相等的K段{S1,S2,···,SK},然后对片段序列按如下方式进行建模:
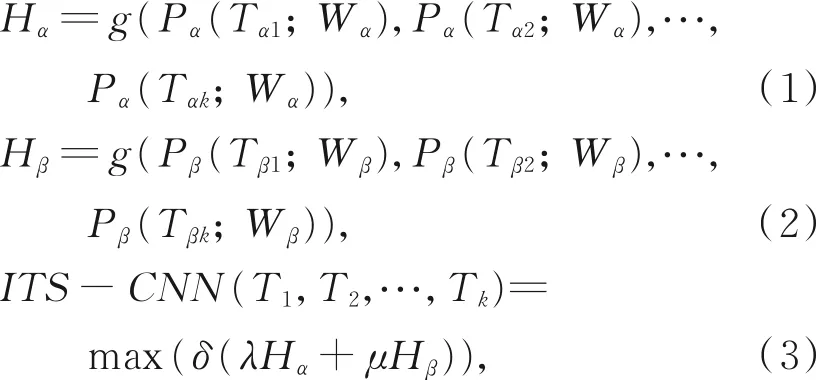
其中:使用下标α和β区分时空表观信息流和时空运动信息流。Ti表示从对应的视频片段Si(i=1,2,···,K)中随机采样得到的片段序列,Tαi为视频帧,Tβi为光流图像;Pα和Pβ为计算Tαi和Tβi属于每个类别得分的函数,Wα和Wβ为时空表观信息流和时空运动信息流的网络参数;g是一个融合函数,对所有Ti属于同一类别的得分取平均值;Hα和Hβ分别为时空表观信息流和时空运动信息流的类别得分;λ和μ为双流融合比例系数;δ为Softmax函数,用于预测整段视频属于每个行为类别的概率,将概率最高的类别判断为该视频的所属行为。
此外,K段(文中将K取为3)之间的网络参数共享,结合标准交叉熵损失,最终的损失函数为:
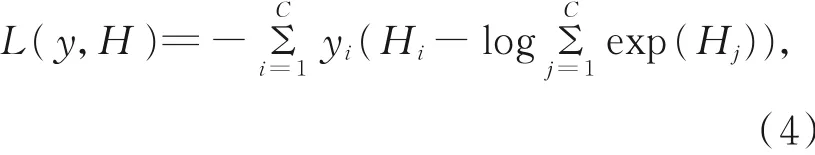
其中:C为行为类 别个数,H=g(P(T1;W),P(T2;W),···,P(Tk;W)),yi为第i类行为的真实标签,Hi为第i类行为的分类得分。文中改进双流网络的学习是一个非端到端的过程,即分别对两个网络进行训练及测试,再对两个网络进行融合。
结合标准反向传播算法,利用多个片段来联合优化网络参数W,在反向传播过程中,网络参数W相对于损失值L的梯度可以表示为:
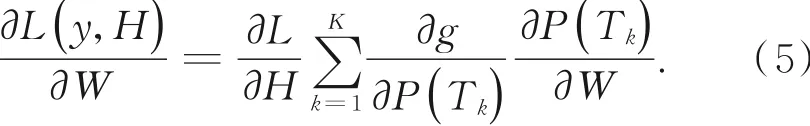
2.3 改进双流时空网络
2.3.1 时间移位模块
视频流的飞速增长给视频理解带来了巨大挑战,处理海量的视频就要求以较低计算成本实现较高的精度。目前三维卷积在提取时空特征时具有良好的性能,但是由于计算密集,使得其部署成本昂贵。为此,Lin提出了一种具有高效率和高性能的时间移位模块(Temporal Shift Module,TSM)[14],它能够以二维卷积的复杂性实现类似于三维卷积的性能。

图1 本文算法整体流程图Fig.1 Overall structure of algorithm in this paper
时间移位模块将卷积过程解耦为两个步骤:分别为数据移动(shift)和乘累加(multiply-accurate)。其中卷积运算操作Y=Conv(W,X)可以表示为:Y=ω1Xi-1+ω2Xi+ω3Xi+1,卷积权重W=(ω1,ω2,ω3),输入X是一个不定长度的一维向量。如图2所示,在时间维度上对部分通道进行-1,0,+1的数据移动,使来自相邻帧的信息在移动后与当前帧的信息混合,从而实现对视频的时序建模,在形式上可以表示为X-1i=Xi-1,X0i=Xi,X+1i=Xi+1;再分别乘以权重(ω1,ω2,ω3),得到Y=ω1X-1+ω2X0+ω3X+1。第一步shift可以在没有任何乘法的情况下进行,但是第二步乘累加的计算成本较高,为了不添加额外参数和计算成本,TSM将multiply-accurate合并到卷积神经网络中,因此不会添加额外的计算量。
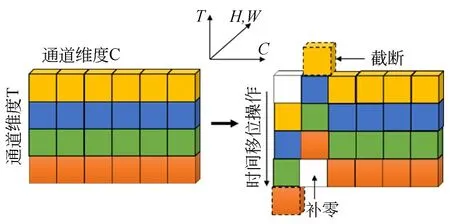
图2 时间移位操作Fig.2 Temporal shift module operation
一个视频模型中的特征映射可以表示为:A∈RN×C×T×H×W,其中N为批量大小,C为通道数,T是时间维度,H和W为空间分辨率。二维卷积在时间维度T上单独工作,各通道的信息独立存在,因此不具有时序建模能力。为此,本文引入TSM[14]模块,通过沿着时间维度T向前和向后移动部分通道,使来自相邻片段序列的图像(在时空表观信息流中为RGB视频帧,在时空运动信息流中为光流图像)的通道信息混合,实现对视频时序关系的建模,从而提取包含时序信息的行为表观特征和运动特征。
2.3.2 卷积注意力模块
为了解决时间移位带来的空间特征学习能力下降的问题,本文引入卷积注意力模块(Convolutional Block Attention Module,CBAM)[15],通过在通道和空间维度应用通道注意力和空间注意力使网络学习到视频图像中关键的局部细节信息,从而增强网络的特征学习与表达能力。
CBAM的结构如图3所示,给定一个中间特征映射F∈RC×H×W作为输入,依次输入一维通道注意力映射Mc∈RC×1×1和二维空间注意力映射Ms∈R1×H×W,总体注意力的计算过程可以概括为:
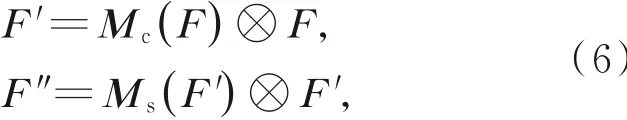
其中:⊗表示元素乘法,在乘法期间,注意力值相应地被广播,通道注意值沿着空间维度广播,空间注意值沿着通道维度广播,F″是最终的精确输出。
通道注意力模块使用全局最大和平均池化,聚合特征映射的空间信息,以生成两个不同的空间上下文描述然后使用由多层感知器(Multi-Layer Perceptron,MLP)组成的共享网络对这两个不同的空间上下文描述进行计算得到通道注意力特征映射Mc∈RC×1×1,具体计算过程如式(7)所示.
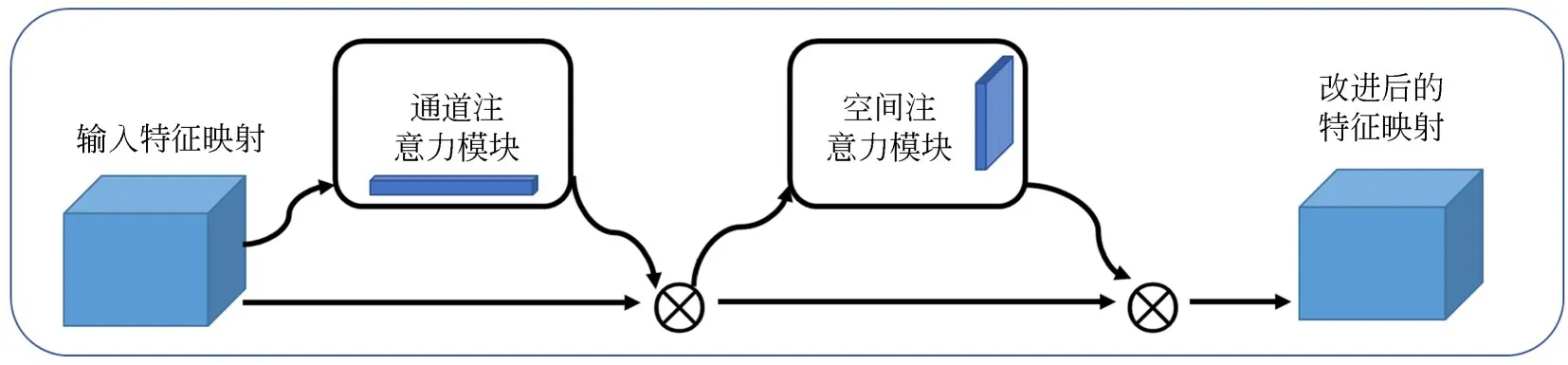
图3 CBAM模块Fig.3 Convolutional block attention module

其 中:σ表 示Sigmoid函 数,W0∈RC/r×C,W1∈RC/r×C,r为约简比;MLP的权值W0和W1对于两个输入都是共享的,并且在W0后面接Re-LU激活函数。
空间注意力模块将通道注意力模块输出的特征映射作为此模块的输入,在通道维度使用全局最大和平均池化,得到两个不同的特征描述:然后通过级联的方式将两个特征描述符合并,并使用卷积操作生成空间注意力特征映射MS(F)∈R1×H×W,空间注意力的计算过程为:
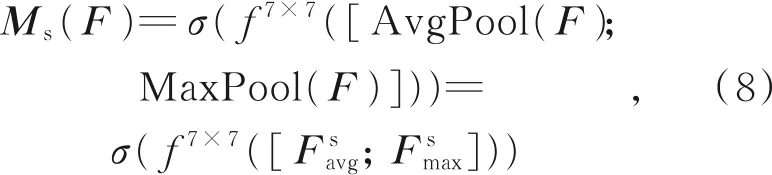
其中:σ表示Sigmoid函数,f7×7表示卷积核大小为7×7的卷积运算。
2.3.3 网络结构
时空表观信息流和时空运动信息流的具体的网络结构如图4所示,两个流均以ResNet50[16]为基础网络,采用残差移位(residual shift)的方式将TSM添加到残差块(residual block)中,将CBAM在时空表观信息流放置到残差块中,在时空运动信息流引入到最后一个卷积层后的位置,在实验中发现这种效果最好。分析原因可能是残差移位的方式能够使网络更好的捕捉时序信息,而且在一定程度上缓解了由于捕捉时序信息而带来的空间特征学习能力退化的问题。由于时空表观信息流输入的RGB视频帧包含复杂的场景信息,将CBAM加入到残差块中对特征校准能够使网络学习到更加精准的空间表观特征。在时空运动信息流中,由于输入的光流图像中只包含人体运动信息,采用原有网络便能完成特征提取,使用CBAM对高层次特征进行微调能够使网络获取更精准的特征表达。

图4 改进双流时空网络Fig.4 Improved two-stream convolution neural network
3 实验与结果分析
3.1 行为识别数据集
在UCF101[17]和HMDB51[18]数据集上对所提出算法进行评估,并将实验结果与当前主流的行为识别算法相比较以验证有效性。UCF101中的数据主要是来自YouTube的现实视频,包含相机运动、复杂场景、光照变化、遮挡、视频画质模糊等影响因素,包含101种行为类别,共有13 320段视频组成,根据视频中的行为类型可以划分为5种:人与人交互、人与物品对象交互、身体运动、乐器演奏和体育运动项目。HMDB51主要由电影片段构成,共包含6 766段视频,共51个行为类别,每类至少包含100段视频,包含的类别有单人行为、面部表情和操纵对象行为、人与人交互的行为、人与物交互等。根据两个数据集官方提供的方式划分3组训练集和测试集,将在3种划分方式的测试集上得到的识别准确率取平均值作为本文算法的最终识别结果。
3.2 实验设置
实验在Ubuntu18.04系统下基于PyTorch 1.4.0+CUDA10.0+cudnn7.6.5实现,计算机配置为Intel Xeon(R)Sliver 4112 CPU 2.6 GHz,NVIDA GeForce 2080Ti显卡。采用小批量随机梯度下降法,动量为0.9。根据计算机的内存大小和GPU利用率,将批量大小设置为8。初始学习率为0.001,训练25 epoch,每经过10个epoch衰减一次,衰减率为0.1。光流图像采用OpenCV库中的TVL1,结合denseflow工具库和GPU计算得到。
由于实验所用数据集容量较小,为避免在训练过程中出现过拟合,网络采用在ImageNet+Kinetics行为数据库上训练的权重初始化,利用角落裁剪和多尺度裁剪方法进行数据增广,对随机采样得到的340×256的图像进行裁剪。在角落裁剪中,对图像从中心和4个对角裁剪为224×224大小;在多尺度裁剪中,从中心和4个对角上分别从{168,192,224,256}中随机抽取两个值作为图像的宽度和高度进行裁剪,再将像素调整为224×224大小。此外冻结除第一层外其他卷积层的BN中的均值和方差参数。测试时对每个视频段进行两次采样,每次采样8组RGB帧或光流图像,将采样图像缩放后裁剪左右边角和中心,使用具有较短边为256像素的全分辨率图像进行测试评估。
3.3 TSM和CBAM的消融实验
为了验证时间移位模块和卷积注意力模块两者在改进双流时空网络中的相对重要性,进行了如下消融实验:
为了验证时间移位模块的有效性,对加入该模块前后本文算法在UCF101(split1)和HMDB51(split1)数据集上的识别准确率进行比较,将分段数K设置为3,按照时间移位模块的原始参数设置将移位比例倒数设置为8,实验结果如表1所示。
由表1结果可知,加入TSM模块后时空表观信息流和时空运动信息流在UCF101上的识别准确率分别提高了4.0%和3.6%,在HMDB51上分别提高了7.7%和2.4%。
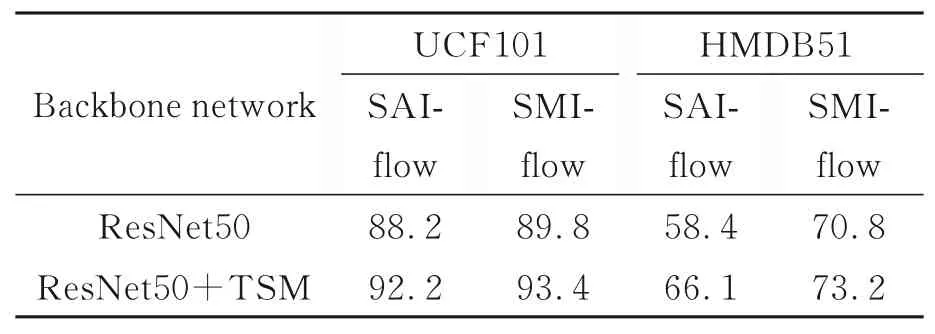
表1 加入TSM前后准确率对比Tab.1 Comparison of accuracy after adding TSM(%)
在实验结果中发现有些行为的识别准确率出现了上升,而有些则出现了下降,为了便于分析,选取了准确率上升和下降幅度最大的5个行为,其类别名称及准确率变化情况如表2所示。
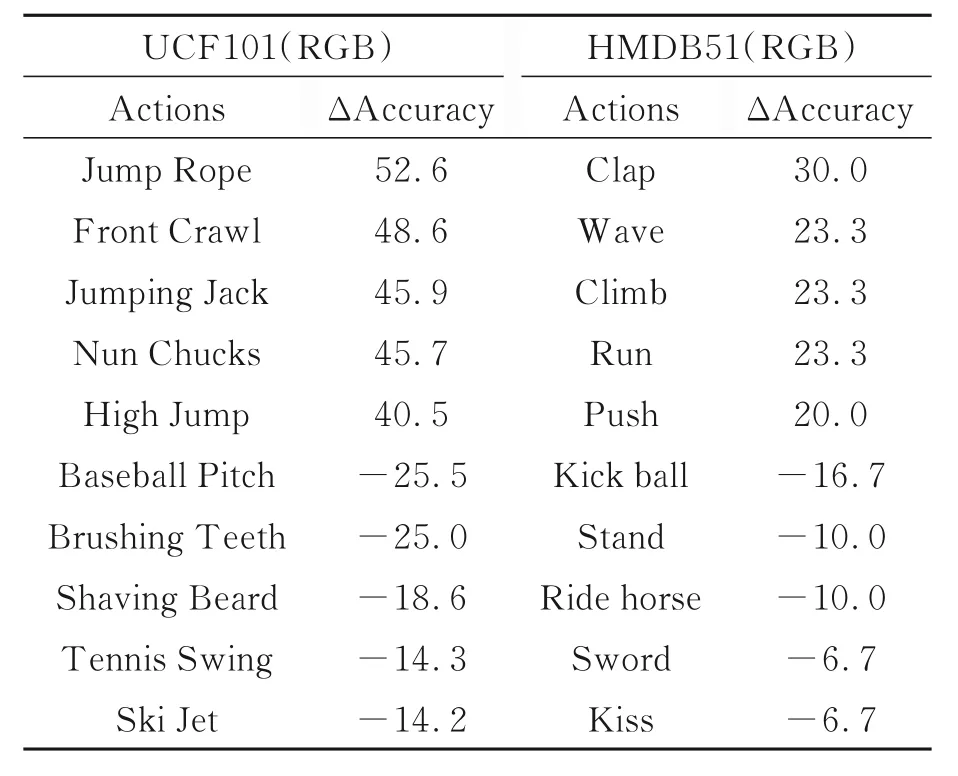
表2 加入TSM后准确率变化前5的行为Tab.2 Top 5 actions that change accuracy after adding TSM (%)
分析出现上述现象的原因可能是时间移位模块加入后,卷积神经网络能够提取到视频中的时空信息,但是在捕获时序信息的同时损失了一些空间特征学习能力,导致对空间场景信息依赖大的行为辨识效果下降,如在Baseball Pitch和Tennis Swing中,依靠场景中的棒球场和网球场就能够得到较好的识别结果,而加入TSM后识别准确率出现了下降。但是Jump Rope,Jumping Jack,High Jump等对时序信息的依赖性较强,其准确率的提升证明了通过引入时间移位模块来使卷积神经网络提取行为视频中的时空信息是可行的。
为了验证CBAM的有效性,在相同实验设置下与ResNet50和ResNet50+TSM进行了对比测试,实验结果如表3所示,当采用方式(c)和 (a)连接时得到了最好的识别结果。
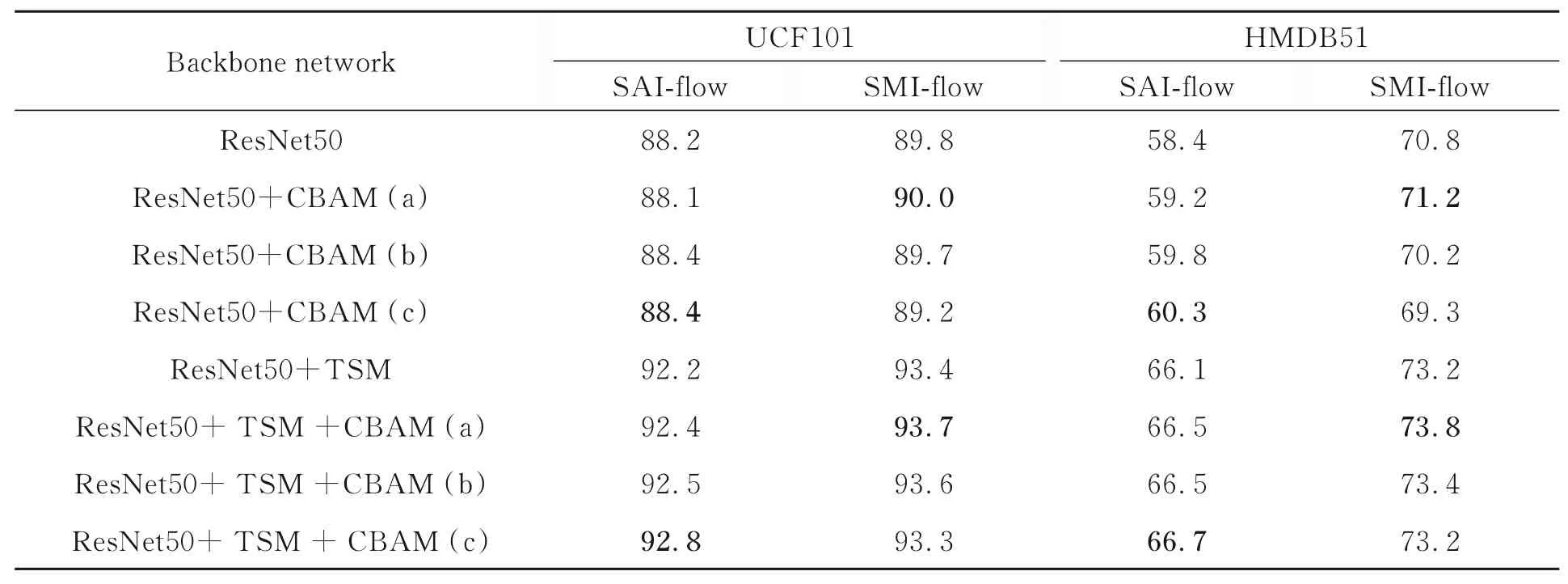
表3 不同主干网络下的识别准确率Tab.3 Recognition accuracy under different networks (%)
表4 所示为加入卷积注意力模块后准确率提升最大的十个行为及其提高量,由结果可知,对Baseball Pitch,Shaving Beard,Tennis Swing,Kick Ball和Ride Horse等行为的识别准确率都有了较大提升,在一定程度上解决了由于TSM的引入而带来的空间特征学习能力下降的问题。同时对Laugh,Drink,Throw,Catch等面部和手部局部运动的行为以及Climb Stairs和Climb、Throw和Catch等相似行为的识别更加准确,证明本文提出的结合注意力机制的方法能够增强网络的特征学习和表达能力,使网络学习到更加精细的行为特征,提高了对近似行为的识别能力。
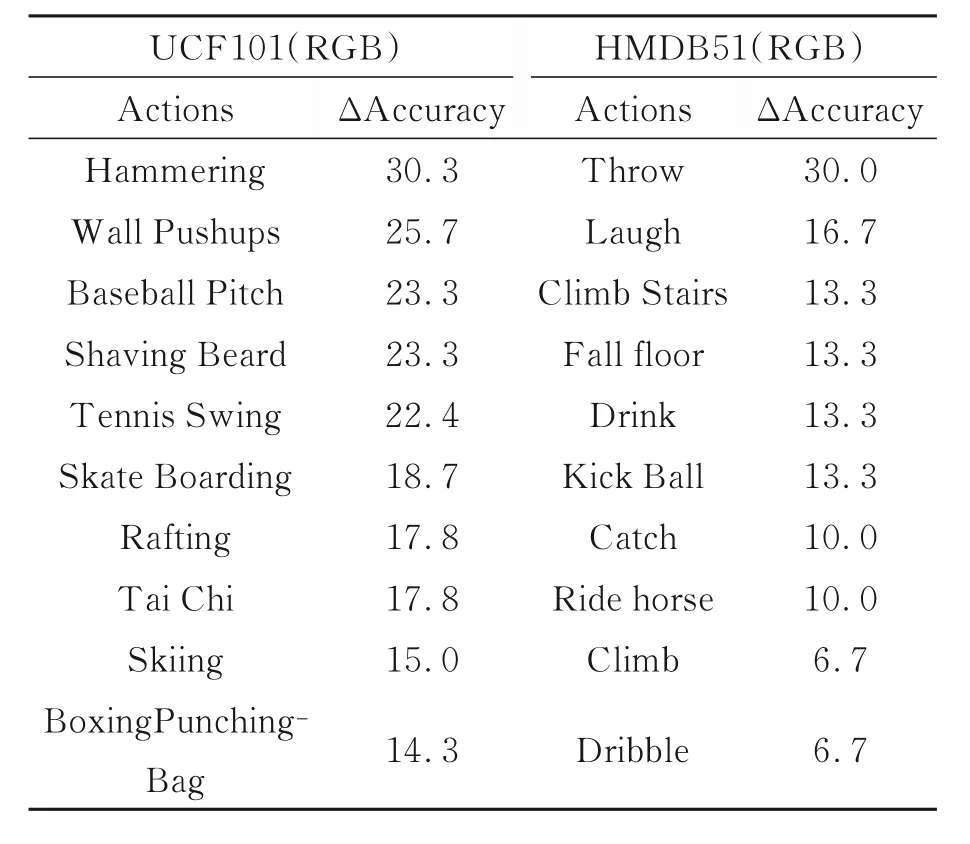
表4 加入注意力模块后准确率提升前10的行为Tab.4 Top 10 actions that increase accuracy after adding CBAM (%)
3.4 双流网络的融合
最后对时空表观信息流和时空运动信息流的分类得分进行加权平均融合,通过实验寻找最优的比例系数,由于在时空运动信息流上的准确率更高,因此尝试给其更大的权重系数,由表5可知,当融合比例为1:1.8时准确率不再上升,此时得到了最高的平均准确率。
为了体现本文算法在识别准确率方面的优势,选取UCF101和HMDB51数据集进行实验,将本文算法与现有主流人体行为识别算法进行比较,各算法在上述两个数据集上的识别准确率如表6所示。
由表6可知,本文算法的识别准确率较现有人体行为识别算法具有一定的优势。分析原因在于文中提出的改进双流时空网络能够有效利用视频中的时序关系信息和空间信息,提高了对时序依赖较大行为的识别能力,以及增强了网络学习空间局部细节特征的能力,对相似行为能够更好地辨识,从而提升了识别准确率。
4 结 论
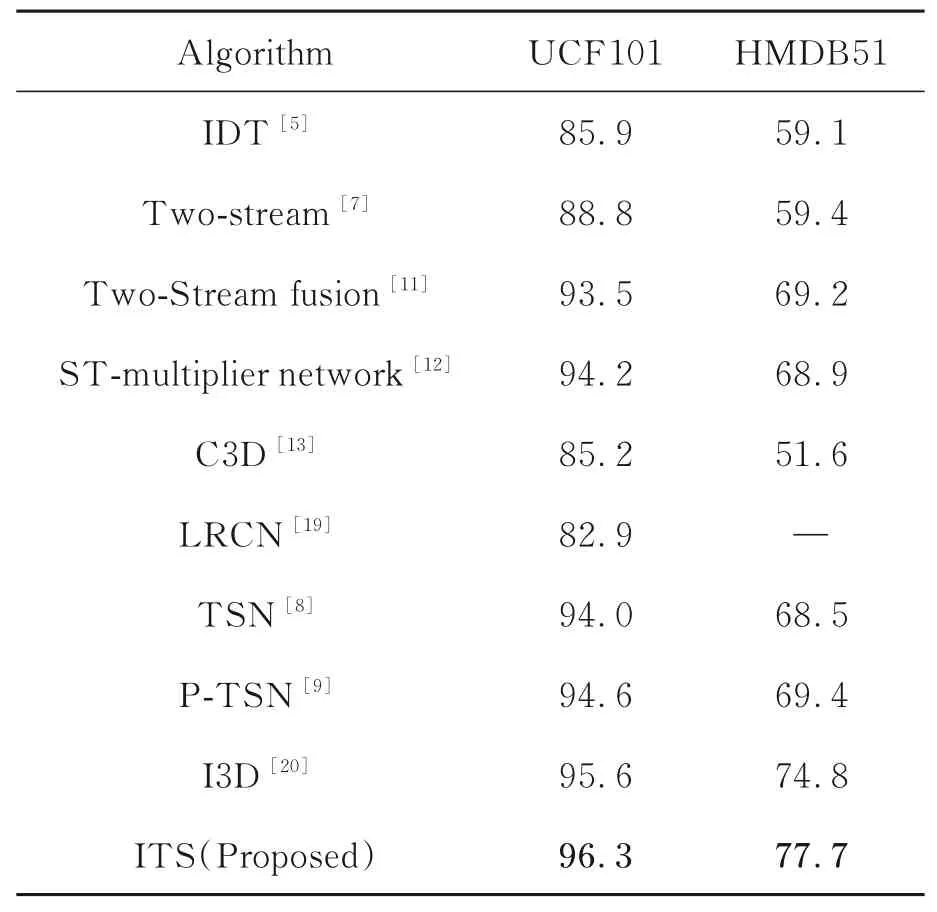
表6 不同算法的识别准确率对比Tab.6 Comparison accuracy of different algorithms(%)
本文提出了一种基于改进双流时空网络的人体行为识别算法,通过结合时间移位思想与注意力机制,构建了一个包含时空表观信息流和时空运动的信息流的双流网络结构,实现了对视频中时间特征和空间特征的有效提取,同时采用卷积注意力模块在通道和空间上强调关键细节特征,增强了网络的特征表达能力,从而提高了对时序关系依赖较大行为和相似行为的辨识能力,实验结果证明:本文算法在人体行为识别数据集UCF101和HMDB51上的识别准确率分别为96.3%和77.7%,相比已有算法取得了更高的识别准确率。为进一步提升算法的识别性能,今后还可以从构建端到端的双流网络的角度进行改进。
猜你喜欢
中小学校长(2022年7期)2022-08-19 01:36:36
四川党的建设(2022年8期)2022-04-28 21:29:35
冶金设备(2020年2期)2020-12-28 00:15:22
小学生学习指导(低年级)(2020年11期)2020-12-14 07:28:10
军事运筹与系统工程(2020年1期)2020-09-11 06:41:08
高原山地气象研究(2020年3期)2020-07-16 07:53:58
中小学校长(2019年10期)2019-11-07 04:56:38
铁道通信信号(2018年12期)2019-01-31 05:36:40
作文大王·低年级(2018年10期)2018-12-06 06:22:44
军事运筹与系统工程(2018年1期)2018-11-10 05:33:12
