
基于迁移学习与特征融合的眼底图像分类
2021-03-25 12:23:20朱向冰吴昌凡张鹏飞
光学精密工程 2021年2期
陈 筱,朱向冰*,吴昌凡,余 燕,张鹏飞
(1.安徽师范大学物理与电子信息学院,安徽芜湖241000;2.皖南医学院第一附属医院眼科,安徽芜湖241000)
1 引 言
白内障、糖尿病视网膜病变(Diabetic Retinopathy,DR)、青光眼、年龄性黄斑变性是致盲的主要疾病。一些疾病的初始阶段往往是无症状的,临床表现仅仅出现在该疾病的晚期,对多种眼底疾病的早期诊断可以防止眼部病情的恶化。开展大规模的早期疾病筛查需要大量的医生,在现阶段有困难,采用计算机筛查眼底图像判断疾病可以有效地缓解医生的工作量[1-2],便于实现大规模的早期筛查[3]。
传统的图像特征提取方法可以对图像的形状、颜色、结构、纹理等低层信息进行表示,并已被证明可用于图像分类、检索、分割等任务中[4-5]。深度学习(Deep Learning,DL)[6-7]是一种新兴的技术,在众多领域中得到广泛的应用[8-10]。在眼科学中,深度学习方法可用于评估各种疾病,包括白内障、青光眼、年龄相关性黄斑变性(Age-related Macular Degeneration,AMD)和DR,它们可以采用彩色眼底图像和光学相干断层扫描图像[11],简化了眼底病变的诊断过程,并且使用这些深度学习算法对眼底疾病的诊断已证明了与眼科医生相媲美的识别能力。由于在眼底检查中可以发现各种各样的异常和疾病,因此用于筛查多种眼底疾病状况的深度学习算法可能更适合临床应用。许多研究人员不断对深度学习模型进行改进,自从AlexNet[12]的出现以后,深度学习方法取得了很多成果。其中,EfficientNet[13]模型在ImageNet上达到了最优的性能指标,比以往的模型具有更高的准确性和效率,并已被证明在其它数据集上得到了非常优秀的性能。
本文旨在寻找可用于区分健康眼底图像和病理眼底图像的最佳方法并建立完整的软件,同时对模型通过热力图突显出预测结果的依据,在临床中辅助医生诊断,并为患者自行筛查眼底疾病提供一种可能。为了开发该软件,我们进行了多次实验,并使用纹理、形状和预训练的卷积神经网络(Convolutional Neural Network,CNN)描述符作为随机森林(Random Forest,RF)[14]、支持向量机(Support Vector Machine,SVM)[15]、深度神经网络(Deep Neural Network,DNN)和XGBoost[16]的输入。在这些实验的基础上,我们通过结合特征融合[17]获得了更高的性能指标,该软件已提供了网页可以对眼底图像进行预测。
2 相关工作
Zhe Wang等[18]提出了一种“Zoom-in-Net”算法,用于诊断DR并突出显示可疑区域。该算法由用于DR分类的网络“Main-Net”、生成注意力图的子网络“Attention-Net”和子网络“Crop-Net”共同组成。在DR数据集EyePACS和Messidor上,准确度达到了86.5%。
VarunGulshan等[19]应用深度学习创建了一种自动检测眼底照片中的DR和糖尿病性黄斑水肿的算法,在EyePACS-1和Messidor-2数据集上分别进行研究,证明了基于深度机器学习的算法具有很高的灵敏度和特异性。
JoonYul Choi等[20]基于VGG-19架构的随机森林迁移学习对眼底图片进行多类别分类,包括正常的和9种不正常的视网膜眼底疾病,并证明了随着类别数量的增加,深度学习模型的性能逐渐下降。在10个类别上获得的准确度为30.5%。
Emran Saleh等[21]探讨了模糊随机森林和基于优势关系粗糙集平衡规则集成两种分类器在眼底图片上的应用。在2323张眼底图片中进行有无DR风险二分类,两种分类器在测试集上分别获得了80.29%和77.32%的准确度。
熊荔[22]提出一种用于白内障自动诊断分级算法,首先提取眼底图片的多阈值分割的可见眼底结构、可见眼底结构增强平均值以及局部标准方差等局部特征,应用决策树方法实现了最终的白内障模糊度分级,准确率为94.85%。
李建强等[23]采用预训练的AlexNet进行微调和训练,对白内障眼底进行分级。该方法在白内障四个严重程度等级分类任务中达到81.86%的平均准确率。
TurimerlaPratap等[24]使用800张公开的白内障眼底图片,将预训练的CNN模型用于图片特征提取,然后将提取的特征应用于SVM分类器,在200张测试集上获得的四级分类准确度为92.91%。
柯士园等[25]提出集成学习算法,对杯盘比和视神经纤维层厚度分别提取出二维特征,并将这两种特征融合起来作为线性分类器和非线性分类器的输入,用于诊断青光眼。实验证明了对两个视图上的预测进行融合后,预测准确率有较大的提高。
Maila Claro等[26]使用特征融合的方法,将灰度共生矩阵(Gray-Level Co-occurrence Matrix,GLCM)算法和4种迁移学习模型提取的图片特征进行拼接并通过增益比的特征选择方法,使用RF分类器,在青光眼检测中获得了93.61%的准确度。
通过对国内外眼底图片分类的调研,有关视网膜图像分类的研究大多数都选择了二元分类解决“有无某种眼底疾病”的问题,或者根据某一种疾病的严重程度进行分级,他们的模型对各种各样的异常眼底不具备识别能力,不能保证在检测各种眼底病变上表现出良好的性能,且一些方法没有进行模型可视化解释,无法保证模型的可信度。本文旨在构建检测眼底几种常见致盲疾病和其它眼底疾病的自动筛查系统,并对模型预测的结果做可视化解释,在临床中更具备应用价值,并将该系统制作为软件以及网络程序,减少医生检查眼底疾病的工作量,方便病人自己进行眼底病的筛查,解决偏远地区缺少有经验的医生的问题。
本文所提出的方法遵循图1所示的流程图。首先修改并微调训练EfficientNet-B0(E-B0)和EfficientNet-B7(E-B7)模型,微调后保存模型用于提取眼底图片的特征,然后将两个模型提取的特征以串联的方式进行融合,最后使用DNN分类器检测异常眼底。
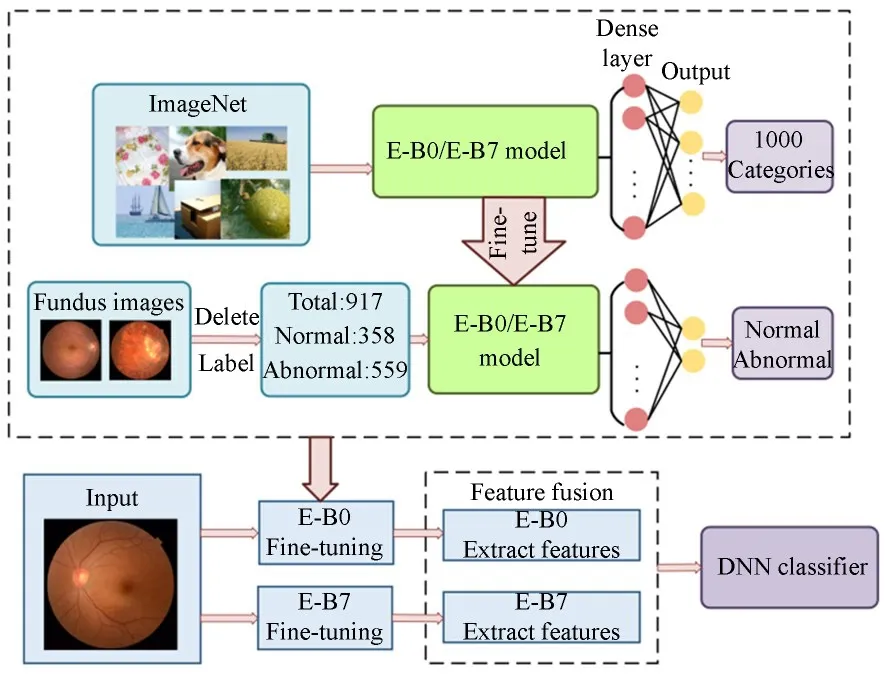
图1 本文提出的检测异常眼底的流程图Fig.1 Flowchart of proposed method to detect abnormal fundus.
3 本文方法
3.1 数据集
3.1.1 内部数据集
内部数据集是由皖南医学院第一附属医院收集的929张眼底图像。将存在以下情况的图片删除:(1)模糊区域占50%或更多;(2)黄斑或视盘缺失;(3)黄斑区域的血管无法区分。最后用于本研究的图片共917张。图片尺寸为3 352×3 264,受试者年龄在10~85岁之间。
首先由三位资深眼科医生为图片分类,共分为正常的眼底和异常的眼底图片两类。其中,异常的眼底图片包括青光眼、高度近视视网膜病变、视网膜静脉阻塞、AMD、白内障、DR、视网膜下出血、玻璃体病变、视乳头炎症等12种眼底疾病。正常眼底的图片数量为358张,异常的有559张,三位医生对所有图片的分类都是一致的。图2展示了内部数据集中的部分眼底图片。
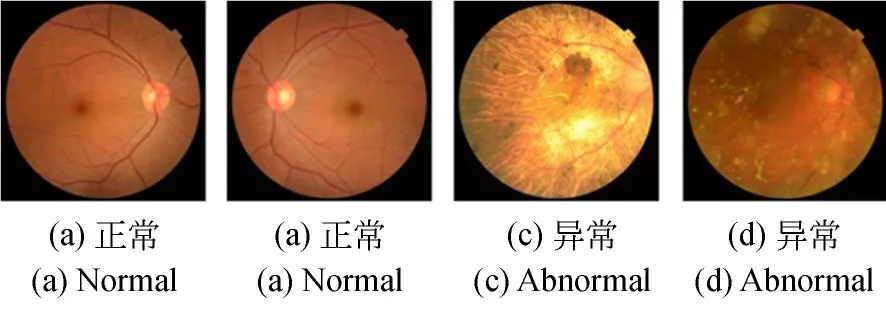
图2 内部数据中的正常和异常眼底图片Fig.2 Abnormal and normal fundus images in internal dataset
3.1.2外部数据集
外部数据集是汕头国际眼科中心收集的眼底图片(Joint Shantou International Eye Centre,JSIEC),该公开的JSIEC数据集共有1 000张,分为正常、大杯盘比、豹纹状眼底、动脉阻塞等39个类别。本文的目标是快速筛查异常的眼底图片,由于其中的大杯盘比的眼底图片需要结合患者的病史判断是否异常,因此在测试集中没有使用该类的眼底图片,仅使用了正常的和其他37种异常眼底图片作为外部测试集,用于测试模型的性能。
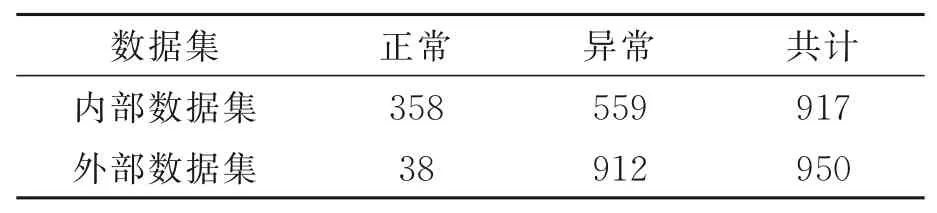
表1 内部数据集和外部数据集的数量Tab.1 Number of fundus images in internal and external datasets
3.2 特征提取
在本研究中使用多种特征提取方法,这几种方法已被证明在图像特征提取方面取得较好的性能,本文对比了这几种特征提取方法在眼底图像分类上的性能,并探究特征融合与特征选择的影响。
3.2.1 深度学习与模型选择
随着深度学习的不断发展,采用深度学习模型用于图像任务如目标检测、图像识别、图像检索等性能得到大幅度提高。
用于图像任务的深度学习模型往往采用CNN,在训练过程中不需要复杂的预处理,可以自动从图像中提取和学习丰富的相关特性,通过不断地优化来获得网络所需参数,避免了人工特征提取。另外,CNN通过结合局部感知区域、共享权重、空间上的降采样来充分利用数据本身的局部特征,并且能一定程度上保证位移和旋转的不变性,通过前人的研究[18-20],表明CNN特征能够很好地表征眼底图像中的有用信息。
然而由于深度学习网络较深,涉及的参数很多,在数据集较少的情况下训练模型很容易出现过拟合现象,采用迁移学习方法[27]可以将在大型数据集中学习好的特征重新用到新的任务中,解决新任务中数据比较少、数据对模型的初始化很敏感的问题,适用于本文数据较少的情况。
本文使用在ImageNet上训练好的Efficient-Net-B0和EfficientNet-B7作为微调的模型。VGG16[28]是从神经网络的深度对CNN模型进行扩展,Inception-ResNet-V2(I-R-V2)[29]是将Inception模块以ResNet方式连接,从增大网络的宽度和深度优化CNN的特征提取能力。本文的模型是采用神经架构搜索设计基线网络,从模型宽度、深度和图片分辨率三个方面进行扩展得到一系列模型,称为EfficientNets。分别为EfficientNet-B0,EfficientNet-B1,…,EfficientNet-B7。其中,EfficientNet-B0为基线模型,Efficient-Net-B7在ImageNet上获得了当时最优的84.4%的top-1准确度和97.1%的top-5准确度,同时比当时最好的卷积网络大小缩小了8.4倍、速度提高了6.1倍。该模型所提出的思想如图所示。
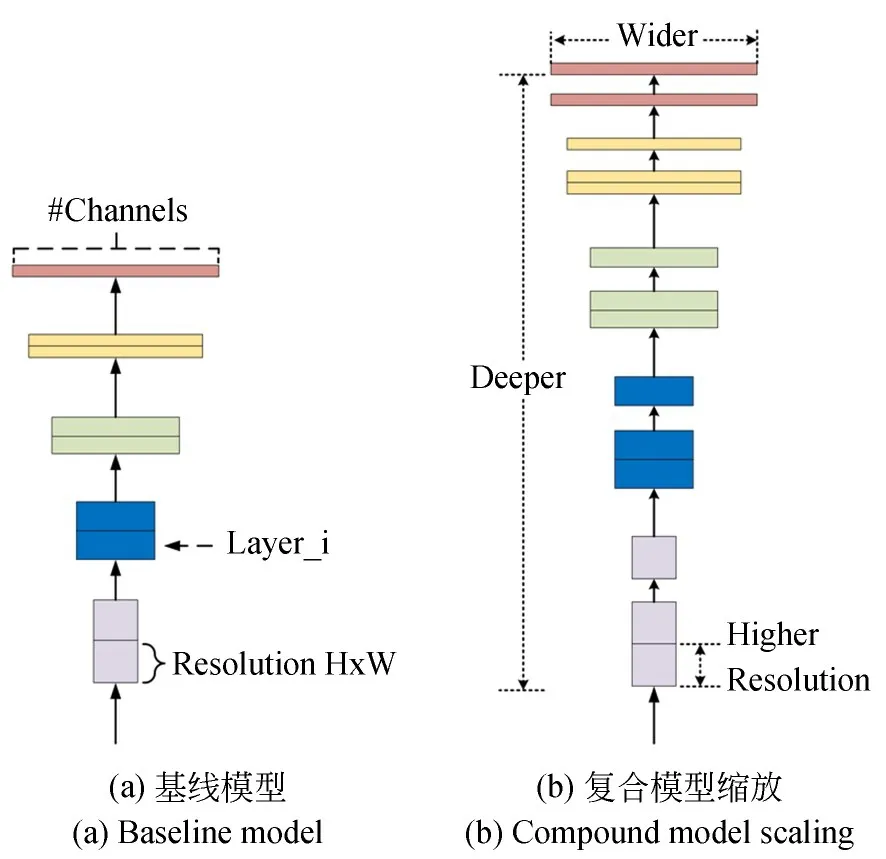
图3 EfficientNets模型采用的复合缩放方法Fig.3 Scaling method used by the EfficientNet model
由于该模型的源任务用于ImageNet图像的分类,与本文分类数不同,因此需要先对模型进行修改,且ImageNet中图像与眼底图像差别较大因此采用微调的方式进行迁移学习。将EfficientNet-B0和EfficientNet-B7模型的全连接层的输出维度改为本研究中的眼底图像二分类类别数。然后对数据集进行划分,随机选取所有数据集的60%用做训练集,20%用作验证集,剩下的作为测试集,为防止模型出现过拟合,将训练集和验证集的数据分别进行旋转、镜像、翻转和放大操作,扩充后的数据分别是3 000和1 000张。训练中,本文采用随机梯度下降更新网络的权值和偏置并微调整个模型的参数,超参数批处理大小、迭代数、学习率、和动量分别设置为8,50,0.001和0.9。保存在验证集上性能最好的模型,用于测试集的测试和提取眼底图片中的特征,并探究CNN特征结合其它分类器以及多种特征融合的影响。使用微调后的EfficientNet-B0(Fine-tuned EfficientNet-B0,FT-E-B0)和EfficientNet-B7(Fine-tuned EfficientNet-B7,FT-EB7)提取每张图片特征分别产生1 280和2 560个描述符。
3.2.2 局部二进制模式
局部二进制模式(Local Binary Pattern,LBP)是一种纹理特征描述符,可以用于计算纹理的局部表示。本文使用Ojala等人提出的旋转不变均匀LBP描述子[30],该算法引入了两个参数:圆形对称邻域中的点数p和圆的半径r。
旋转不变均匀LBP描述子是对原始的LBP描述子进行的改进,其具有旋转不变性,用于提取眼底图像的特征时,通过LBP算法提取的特征不会因为拍摄对象(人眼)的倾斜而发生改变,均匀LBP描述子则起到了降维的作用,均匀模式占了全部模式中的绝大多数信息,因此该旋转不变均匀LBP描述子能够很好地提取图像的本质特征,文献[26]采用该方法提取彩色眼底图像特征用于识别青光眼,并证明了能够获得一定的准确度。
旋转不变均匀LBP模式提取的特征数完全取决于p的数量,均匀模式仅p+1类,所有非均匀模式归为1类,最后用于表示整幅纹理图像的旋转不变LBP描述子的直方图矢量特征仅p+2维。在本实验中,将图片转化为灰度图并调整图片尺寸为1 024×1 024,点数p设为24,半径r设为8,因此LBP算法在每一张图片上产生了26个描述符。
3.2.3 GLCM
GLCM是一种计算纹理的统计方法,该方法考虑了像素的空间关系[31]。GLCM通过计算图像中具有特定值和指定空间关系的像素对出现的频率创建GLCM。然后从该矩阵中提取统计信息来表征图像的纹理。相关的统计信息包括对比度、逆差矩、能量、同质性、熵、自相关性等。其中,对比度反应了图像的清晰度和纹理的沟纹深浅;逆差矩反映了图像纹理的清晰程度和纹理程度,度量图像纹理局部变化的多少;熵表示图像中纹理的非均匀程度或复杂程度;自相关值大小反映了图像中局部灰度相关性。眼底图像中具有非常复杂的纹理信息,灰度共生矩阵不仅提供了图像中灰度方向、间隔和变化幅度的信息,在GLCM的基础上通过计算纹理特征统计属性来定量描述纹理特征进而实现更好地描述眼底图像。
本文在眼底图像灰度图上使用能量、同质性、自相关性、对比度和差异性描述图像的特征,空间位置关系设置为0°,90°,135°和180°,相邻元素之间的距离设置为1,2,3,4,因此每张图片上产生80个描述符。
3.2.4 方向梯度直方图
方向梯度直方图(Histogram of Oriented Gradient,HOG)描述符[32]主要用于描述图像中对象的结构形状和外观,常用于图像分类。
HOG是在网格密集、大小统一的细胞单元上进行计算,通过将细胞单元组成更大的块并归一化块内的所有细胞单元来实现对直方图进行对比度归一化,因此HOG对光照和阴影有更好的不变性,可以减少光线对眼底照片拍摄过程造成的影响;由于HOG捕获了局部强度梯度和边缘方向,因此它提供了良好的纹理描述符,考虑到眼底图像中具有丰富的纹理信息,因此本文也使用了HOG方法提取特征。
在本文中,将单元大小设置为16×16,块的大小设置为2×2,并在9个方向上计算眼底图像的HOG描述符,产生了8 100个描述符。
3.3 特征融合与特征选择
特征融合可以实现各种方法提取的特征之间的信息互补,能够从融合中涉及的多个原始特征集中获得最具差异性的信息。LBP,GLCM和HOG是三种传统的特征提取方式,能有效提取图片中的低阶纹理信息。FT-E-B0和FT-EB7是深度学习模型,可以自动学习到图像中的高阶信息。本文将提取的特征使用串联方式进行特征融合,主要有两组实验:
(1)LBP,GLCM,HOG提取的低层特征与FT-E-B0和FT-E-B7提取的高层特征以串联的方式融合;
(2)FT-E-B0和FT-E-B7特征描述符以串联的方式融合。
实验的具体实现方法是:首先对每一张眼底图片采用3.2节中介绍的LBP,GLCM,HOG方法以及FT-E-B0,FT-E-B7模型提取特征向量,各种方法在一张眼底图上产生的特征向量大小为26,80,8 100,1 280和2 560。上述实验(1)中采用串联方式融合所有特征后,每一张图的特征向量大小为12 046;实验(2)采用串联方式进行融合两种模型提取的特征后,每一张图的特征向量大小为3 840。通过两组实验对比,探究传统特征提取方法提取的特征与CNN特征进行融合对分类的影响。
包装法是一种特征选择与算法训练同时进行的方法[33]。经过包装法筛选后的特征可以在特征数量很少时就能达到非常优秀的效果。递归特征消除法(Recursive Feature Elimination,RFE)使用的是一种典型的包装法的目标函数[34],带有交叉验证的RFE(RFECV)是在RFE的基础上对不同的特征组合进行交叉验证,得到不同特征组合性能指标的重要程度,然后保留最佳的特征组合。
对两组融合特征进行特征选择的具体做法是:采用scikit-learn中RFECV函数实现,分类器使用参数为500棵树的随机森林分类器,采用10折分层采样方式对数据进行采样,在筛选特征过程中以准确度作为评估模型的标准观察不同特征数量时得到的结果,每训练一步特征数量减少50,如果减少特征会造成性能损失,那么将不会去除任何特征。
3.4 分类
本文中用于实验的分类器是SVM,DNN,XGBoost和RF,其中RF和XGBoost参数设置500棵树,DNN中使用500个隐藏层,其余参数均为默认参数。
3.5 评估标准
本文采用医学图像分类中常用的评估指标:准确度、特异度、灵敏度、F1度量和曲线下面积(Area Under Curve,AUC)评估分类器性能。标签异常且预测异常的为真阳性(True Positive,TP),标签异常且预测正常的为假阴性(False Negative,FN),标签正常且预测异常的为假阳性(False Positive,FP),标签正常且预测正常的为真阴性(True Negative,TN),准确度、特异度、灵敏度、F1度量的计算公式如下,其中F1度量能够综合评估精确度和灵敏度,受试者工作特性曲线(Receiver Operating Characteristic curve,ROC)曲线能够显示灵敏度和特异度的变化。

内部数据上使用的验证方法是10折交叉验证。将数据分割成10个子集,1个单独的子集作为测试模型的数据,计算得到上述的相关指标,其他9个子集用来训练。交叉验证重复10次,每个子集验证一次,平均10次的结果,最终得到一个单一估测。10折交叉验证是在数据较少时评估模型性能的常用方法,能够更好地反映模型的泛化性。
4 实验结果与环境
本实验中,所有程序在Ubuntu18.04 LTS 64-bit系统上运行以及使用Python3.6进行编程,CPU为Intel®CoreTM i3-8100。HOG,LBP,GLCM算法采用scikit-image库实现。微调使用Py-Torch深度学习框架实现,并使用一个NVIDIA GTX 1080Ti的GPU微调预训练的E-B0和EB7。采用scikit-learn机器学习库实现四种分类器和RFECV。
4.1 实验结果与分析
4.1.1 内部数据上的分类结果与分析
表2 展示了使用内部数据集提取图片的11种特征描述符和两种融合后的特征描述符在四种分类器上的分类准确度和F1度量。其中,融合(1)描述符表示GLCM,LBP,HOG,FT-E-B0和FT-E-B7提取的特征串联融合。融合(2)描述符表示FT-E-B0和FT-E-B7提取的特征串联融合。
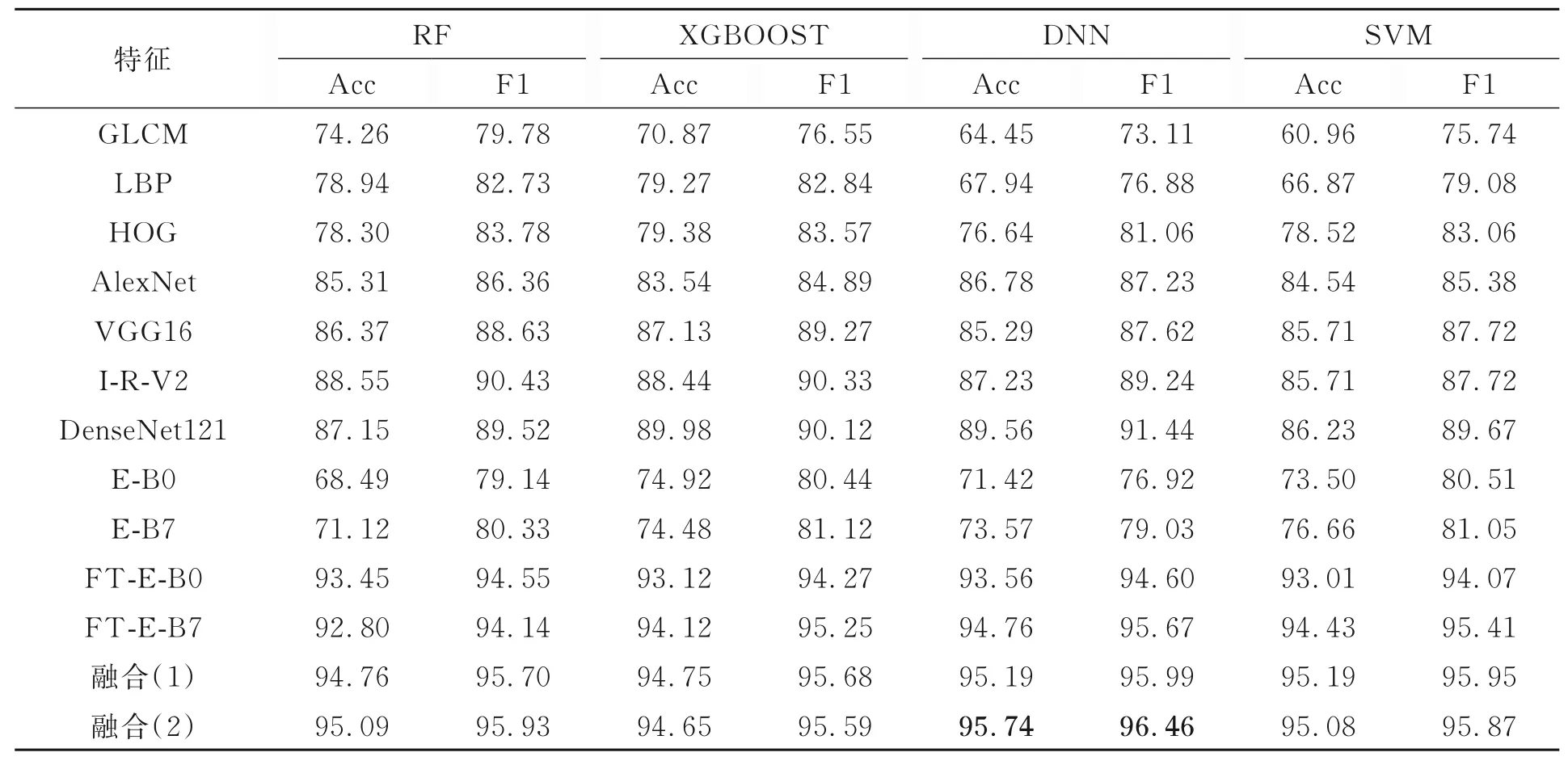
表2 13种不同的特征在4种分类器上的准确度和F1度量Tab.2 Accuracy and F1-score of 13 different features on 4 classifiers
从表中的每一行对比可以发现:
(1)微 调 的AlexNet,VGG16,I-R-V2,DenseNet121,FT-E-B0和FT-E-B7模型与3种传统特征提取方法相比,在4个分类器都得到了更高的准确度和F1度量,因此微调模型具有比传统特征描述符更强的特征提取能力;
(2)AlexNet,VGG16,I-R-V2,DenseNet121,FT-E-B0和FT-E-B7微调模型中,FT-E-B0和FT-E-B7在四种分类器获得的准确度高于其他任何一种模型,表明FT-E-B0和FT-E-B7模型提取方法能更好地提取眼底的复杂信息;
(3)未进行微调的E-B0和E-B7模型获得的最高准确度为76.66%,微调后的E-B0和E-B7模型即FT-E-B0和FT-E-B7模型获得的最高准确度94.76%,因此采用微调方式获得了极大的改善;
(4)两种融合后的描述符与单一的描述符相比,在4个分类器上的准确度和F1度量均有所改善,表明多特征融合可以提高分类的性能;
(5)融合(1)得到的特征与融合(2)得到的特征相比,五种描述符融合后的特征数量是FT-E-B0和FT-E-B7融合后的3倍,准确度和F1度量仅在XGBOOST和SVM分类器上高于FT-E-B0和FT-E-B7融合后特征0.1%左右,且最好的结果是FT-E-B0和FT-E-B7融合后特征采用DNN分类获得,因此仅仅采用两种CNN特征进行融合的分类性能比传统方法提取的特征与CNN特征融合的效果更好,表明传统方法提取的特征中包含了一定的冗余信息,对分类的结果产生了负面的效果,且仅仅采用两种CNN特征描述符不仅不会丢失眼底图片中的有用信息,且实现了融合后的特征改进了分类性能。
FT-E-B0和FT-E-B7融合后的特征采用DNN分类的十折交叉验证得到的ROC曲线和AUC值如图4,其中黑色线表示十折交叉验证平均后的ROC曲线。
本文也探究了特征选择对本实验的影响,图5展示了使用基于随机森林分类器的RFECV筛选后的特征数量与对应的准确度。由图可以看到,用250左右的描述符就能将模型的准确度达到95%,最高的准确度仍在所有的特征均保留时获得,因此可以推断FT-E-B0和FT-E-B7提取的特征几乎不包含冗余信息,本文使用该融合特征结合DNN分类器用于内部数据集和外部数据集的测试。
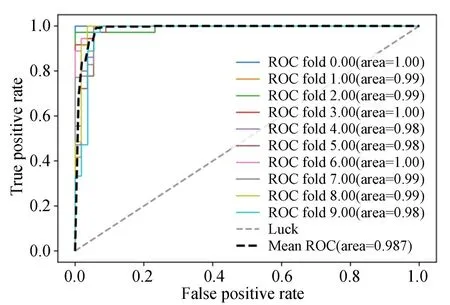
图4 FT-E-B0和FT-E-B7融合后的特征在DNN上交叉验证的ROC曲线以及AUC值Fig.4 10-fold cross-validated ROC curve and AUC value of FT-E-B0 and FT-E-B7 fusion features on DNN
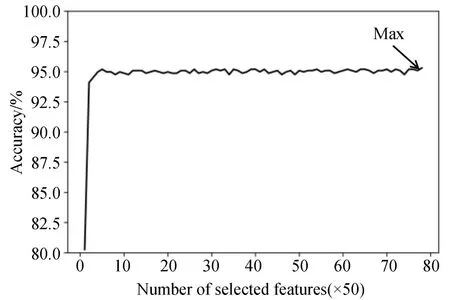
图5 基于随机森林分类器筛选的重要特征数与相应的准确度Fig.5 Number of important features and the corresponding accuracy based on the random forest classifier
4.1.2 内部数据的测试结果并与其它方法进行比较
将本文提出的FT-E-B0+FT-E-B7+DNN方法与其他文献中提到的方法进行比较,由于其他文献的数据和实验目的与本文的不同,因此本文复现了其他文献中的方法,并与本文提出的FT-E-B0+FT-E-B7+DNN方法进行对比,在内部数据集上的测试结果如表3。

表3 本文方法与其他方法在内部数据集测试结果Tab.3 Test results of this method and other methods on internal dataset
由表3得到,本文提出的FT-E-B0+FT-EB7+DNN方法在内部数据集的测试中得到了最佳的性能指标,该方法与文献[21],[23],[36]都采用了深度学习模型,与文献[35],[37]的传统机器学习方法相比,性能都得到很大改善;与文献[21]、文献[23]、文献[36]相比,本文采用微调的E-B0和E-B7模型结合DNN分类器更适用于异常眼底筛查任务。
4.1.3 外部数据测试结果并与其他方法行比较
在外部数据的测试中,本文的FT-E-B0+FT-E-B7+DNN方法得到了最高的准确的、特异度和AUC,尽管在文献[21]获得了最高的灵敏度,但是特异度较低,仅有50%,特异度较低表明模型将正常的眼底样本预测为异常的数量较多,这将耗费过多的医疗资源,与开发该模型的目的相违背,本文的方法能综合考虑特异度和灵敏度,有较高的实用价值。
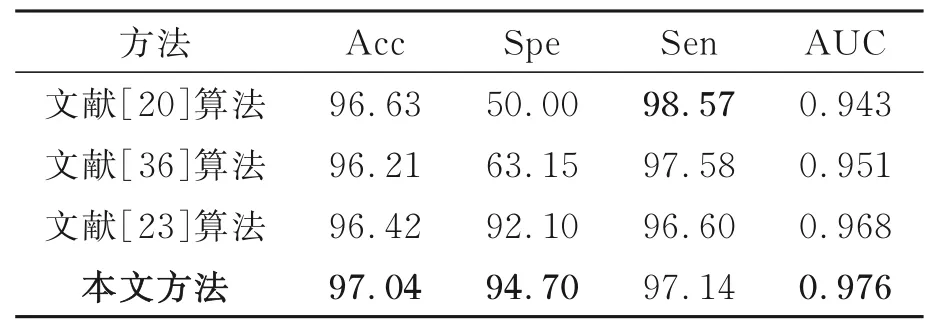
表4 本文方法与其他方法在外部数据集测试结果Tab.4 Test results of this method and other methods on external dataset
采用本文提出的FT-E-B0+FT-E-B7+DNN方法诊断一张眼底图片仅需要约0.4 s的时间,实现了高效的自动诊断,有利于大规模筛查异常眼底。
4.2 模型可视化解释
深度学习模型在图像识别任务中取得了非常出色的效果,但是人们往往不知道模型为什么会做出这样的预测,即模型的可解释性较差。尤其在医学图像的应用中,对模型进行特征重要性分析和可视化研究非常重要,可以辅助医生找到病变的位置,做出可靠的诊断。本文采用加权梯度类激活热力图(Gradient-weighted Class Activation Mapping,Grad-CAM)[38]方法对FT-E-B0和FT-E-B7模型进行可视化解释,该方法通过构建热力图以显示输入的图像中具体区域对图像最终的分类判断起到了作用。图6展示了在JSIEC数据集中眼底图片可视化解释的例子。图中,4张眼底图片的原图均为异常眼底,图(a)为视盘异常;图(b)为黄斑区存在可见微血管瘤和小出血点;图(c)为视盘周围有可见棉绒斑;图(d)为黄斑区异常,有渗出和色素沉着。每张原图的右侧为原图对应的热力图,其中红色区域是模型认为图片异常的位置,与医生读片结果一致(彩图见期刊电子版)。
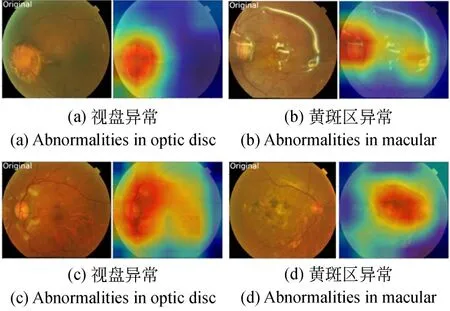
图6 JSIEC数据集中异常眼底图片的热力图Fig.6 Heatmaps of abnormal fundus images in JSIEC dataset
4.3 软件和网页程序
将本文提出的FT-E-B0+FT-E-B7+DNN方法制作成软件,软件界面如图7,该软件已上传到网址:https://www.wzyrr520.xyz/blog/post/admin/pyqt-fundus,且已在医院眼科进行安装测试。该模型的网页版的程序位于:http://fundusimages-recognition.top,将需要测试的眼底图像上传到网页,在服务器端进行自动诊断,诊断结果显示在用户的浏览器中,实现患者的自行筛查。
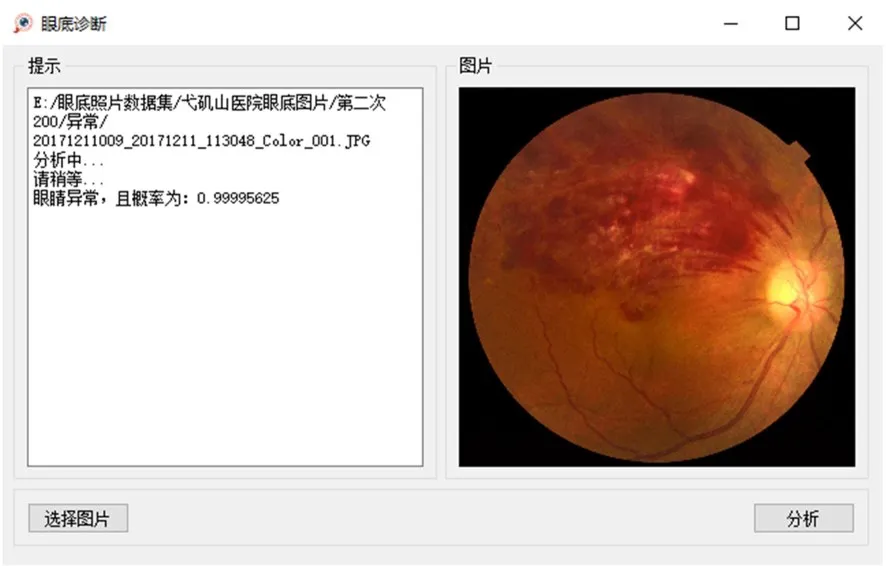
图7 眼底疾病自动筛查软件界面Fig.7 Surface of fundus diseases automatic screening software
5 结 论
本文探索了多种传统特征提取方法和多个深度学习模型提取眼底图像特征取得的效果,并探究了特征融合对检测异常眼底的影响。本文的最佳结果通过将微调后的EfficientNet-B0和EfiicientNet-B7模型提取的眼底图像特征融合后在DNN分类器上获得,最高的准确度和灵敏度分别为95.74%,96.46%。因此微调后的EfficientNet-B0和EfficientNet-B7模型提取特征并融合能够更加高效地反映眼底图像中复杂的纹理特征,方法在公开数据集中也取得了较好的性能。本文所提出的FT-E-B0+FT-E-B7+DNN方法能够实现自动化识别异常眼底,并采用Grad-CAM方法对模型进行可视化解释,为模型预测提供可靠的预测依据。尽管本文探究的仅是二分类,但在眼底图像分类中是基础且重要的。该方法已制作成软件与网页程序提供给医院测试。
本文的外部测试结果仅展示了在国内的JSIEC数据集的性能,由于国外的公开数据集与国内数据集之间在颜色、照度、分辨率、质量以及分类标准等方面有很大的差异,因此没有得到较好的性能,限制了软件的使用范围。在未来工作中,将提高软件的通用性,提高对国外异常眼底数据的筛查性能,并将异常眼底疾病进一步分类,完善能实现多种常见致盲疾病的筛查软件。
猜你喜欢
测绘学报(2022年12期)2022-02-13 09:13:01
建筑科技(2018年6期)2018-08-30 03:40:54
电子测试(2018年1期)2018-04-18 11:52:35
数字通信世界(2018年1期)2018-04-18 11:05:22
测绘科学与工程(2017年5期)2017-05-07 06:30:44
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
中国交通信息化(2016年5期)2016-06-06 03:51:43
电测与仪表(2014年15期)2014-04-04 12:05:20
天津冶金(2014年4期)2014-02-28 16:52:58
