
基于SSD-LeNet的矿井移动目标检测与识别方法
2021-03-24 00:53:10张帆栾佳星崔东林徐志超
矿业科学学报 2021年1期
张帆,栾佳星,崔东林,徐志超
1.中国矿业大学(北京)机电与信息工程学院,北京 100083;2.中国矿业大学(北京)智慧矿山与机器人研究院,北京 100083
智能化开采是矿井安全、高效集约化生产的发展趋势,为最终实现煤炭精准开采的少人(无人)、智能感知和灾害智能监控预警与防治提供技术支撑[1]。因此,研究井下作业人员、机车设备和机器人等移动目标的准确检测与实时跟踪识别,对保障矿井智能安全开采和提高煤矿灾害智能预警具有重要意义[2-7]。现有矿井人员和井下机车等移动目标检测识别方法主要采用静态的射频识别技术,该技术无法实现对移动目标的多维信息检测与跟踪识别,尤其是在井下雾尘、低照度环境中难以实现对矿井移动目标进行实时跟踪与准确识别[4-5]。
目前,传统的基于机器学习的目标检测方法是通过梯度直方图(HOG)和尺度不变特征转换(SIFT)等方法对检测目标进行特征提取,然后使用支持向量机(SVM)、AdaBoost等分类器对提取的特征进行分类[4-10],但这种方法通过人工获取特征,过度依赖目标提取特征和网络检测模型,增加了识别过程的复杂度,且泛化能力较差[11]。近年来,针对深度学习的理论研究已引起国内外众多学者关注,深度卷积神经网络(DCNN)被认为是一种适合目标检测和分类任务的重要深度学习方法,在视频图像识别、自然语言处理、运动目标检测与识别等各种应用中取得了巨大突破[12-15]。Girshick等[15]提出了基于区域卷积神经网络(R-CNN)的目标检测方法,避免了手工提取特征,但该方法采用选择性搜索[16],对目标图片进行区域候选框缩放和卷积网络特征提取,导致模型特征变形和检测速度很慢。He等[17]提出了改进的R-CNN目标检测方法,引入了空间金字塔池化,解决了候选区域的尺度映射问题,提高了模型的检测速度和准确率;Girshick[18]提出了Fast R-CNN模型,采用了MultiBox的多任务损失函数,通过目标定位和目标分类两个任务共有的损失函数来训练网络,提高了检测精度。但以上算法在提取区域候选框时都采用选择性搜索方法,运算耗时长,收敛速度缓慢,易陷入局部极小等问题,难以满足目标检测的实时性要求。文献[19]提出了Faster R-CNN模型,用区域建议RPN网络取代选择性搜索方法,解决了候选区域生成过程时间开销过大的问题,在一定程度上加快了网络的训练速度和测试速度,取得了较高的准确率和检测速度,但依然无法满足实时性要求。文献[20]提出了YOLO检测网络,极大地提高了模型的检测速度,但其每个网格只预测一个物体,对于尺度变化较大的物体泛化能力较差,且容易造成漏检,识别精度较低。上述网络模型和目标检测方法在提高目标检测的均值平均精度(mAP)方面取得了良好的效果,但在实时性检测效果方面还与实际需求存在一定差距。
近年来,众多人工智能科学研究者发现,单镜头多盒检测器(SSD)具有快速定位和聚焦兴趣目标的能力[21-22]。SSD多尺度特征图深度学习模型结合了YOLO检测网络的回归思想和Faster R-CNN检测网络的锚框机制,同时兼顾准确性和实时性,在多层特征图上生成不同尺度的区域候选框,从而实现对不同形状、不同尺寸物体的精准和快速检测。因此,将SSD深度学习能力引入DCNN 模型,无疑将提升目标识别的效率,为实现矿井移动目标实时性检测与识别提供借鉴。
本文针对现有矿井移动目标检测与识别存在的不足,提出一种基于深度卷积网络SSD-LeNet的移动目标检测与识别方法。其总体思路:① 利用视觉传感器捕获煤矿井下移动目标的一帧来构建原始图像模型输入,制作含有数字序列位置信息的移动目标数据集;② 采用扩大局部感受野和减小卷积滤波器尺寸的方法,获取更具显著区分力和表达力的多尺度特征,离线训练可以输出与自身位置对应的目标特征类的SSD网络模型;③ 利用训练好的SSD学习模型对测试集中移动目标图片上的数字序列位置进行检测,并根据数字序列位置对应的矩形区域进行字符分割操作;④ 将分割后的单个字符依次放入LeNet-5网络中进行识别,并将识别出的单个字符按顺序合成数字序列;⑤ 根据识别出的数字序列快速检索出移动目标的身份信息;⑥ 通过仿真实验验证了本文方法的有效性。
1 基于SSD-LeNet的目标检测与识别
1.1 网络模型
网络的结构直接影响目标特征的学习训练效率和逼近能力。为了提高对井下移动目标的多尺度特征深度学习能力,更好地实现对目标的智能检测与精准识别效果,本文选用单镜头多盒检测器(SSD)多尺度深度学习网络,SSD模型结构由主体网络层和扩展层构成,其模型结构如图1所示。主体网络层采用VGG16网络的前5层作为基础网络结构,主要用于卷积特征提取、抽取图片特征;扩展层是空间尺寸逐渐减小的卷积层,主要用于多层特征融合、提取不同尺度下的候选框。另外,还有多任务学习和非极大值抑制(NMS),用于对提取到的默认框特征融合进行深度学习,以及通过局部最大搜索去除冗余,旨在快速获取目标对象。

图1 SSD模型结构Fig.1 SSD model structure
为使 SSD 模型模仿人类视觉感知系统,能够在目标图像中快速搜索到目标位置对象,因此需要在目标定位阶段添加视觉识别特征。SSD模型通过选取Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2和Conv11_2六个不同尺度特征图,在其每一个特征面上生成一系列候选框,然后再将候选框与目标真实的标注框按照匹配策略进行匹配,最后通过NMS策略处理每个真实框附近的冗余框,过滤多余的非文本信息,从而根据定位的目标检测框位置偏移量得到最终的检测结果。
1.2 损失函数

(1)
目标函数由候选框的分类损失与定位损失构成,总的损失函数为
(2)
式中,x为输入样本;c为目标类别;l为候选框;g为真实框;N为匹配候选框的数目;λ为正则项权值,使用交叉熵验证的方式获得;Lloc和Lconf分别为检测目标的回归任务损失函数和类别任务损失函数。
目标候选框的位置偏移量损失函数Lloc为
(3)
(4)
式中,x为数字图片的三维矩阵;cx、cy为补偿后的候选框的中心坐标;w、h为候选框的宽和高。
检测目标的类别任务损失函数Lconf定义为
(5)

根据以上目标函数拟合本文所提方法的训练过程,网络模型得以收敛。此时,SSD模型具有了检测新图片中数字序列标识符准确位置的功能。
1.3 目标识别
本文通过SSD检测网络,获取移动目标和数字标签的位置信息。根据数字标签的坐标信息,利用openCV将数字标签从原始图像中截取出来,对截取的数字标签进行灰度化和二值化处理,并对数字序列位置对应的矩形区域进行字符分割操作,将分割后的单个字符作为输入,进一步利用LeNet-5字符识别网络对其进行字符识别,将识别出的单个字符按顺序合成数字序列,输出与移动目标位置对应的数字序列信息,从而实现对目标的精准识别。LeNet-5字符识别网络的预训练包括前向传播和反向传播两个阶段。其基本思想:首先从MNIST数据集中选取一个目标样本输入网络,通过前向传播对输入层传来的特征向量依次经过卷积计算、非线性变化、下采样及全连接计算,输出一个预测结果;然后对前向传播获得的预测值向量与输入的特征向量进行比较,计算二者的误差,再通过反向传播将该误差值反传回网络中;最后采用梯度下降方法优化网络训练,迭代调整网络的权值,达到最佳逼近性能,使预测值与真实值之间的累计误差最小。
(1) 前向传播阶段。传播过程中将当前卷积层的输入加权与当前层的偏置求和,对目标图像的每层输入特征的运算为
(6)
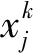
(2) 反向传播阶段。对m个样本的数据集,假设样本为(x,y),根据网络前向传播阶段输出的每个类别的预测值期望,定义网络的整体目标函数为
(7)

由式(7)可知,通过迭代训练最小化损失函数降低网络分类误差,使输出预测值期望无限接近于实际值。
定义损失函数L(zi)为
L(zi)=-logσ(zi)
(8)
式中,σ(zi)为预测输入zi属于每一个类别的概率。

2 算法流程
基于SSD-LeNet网络的矿井移动目标检测与识别总体流程如图2所示。SSD-LeNet算法由模型训练、目标位置检测和目标类别识别三部分组成。
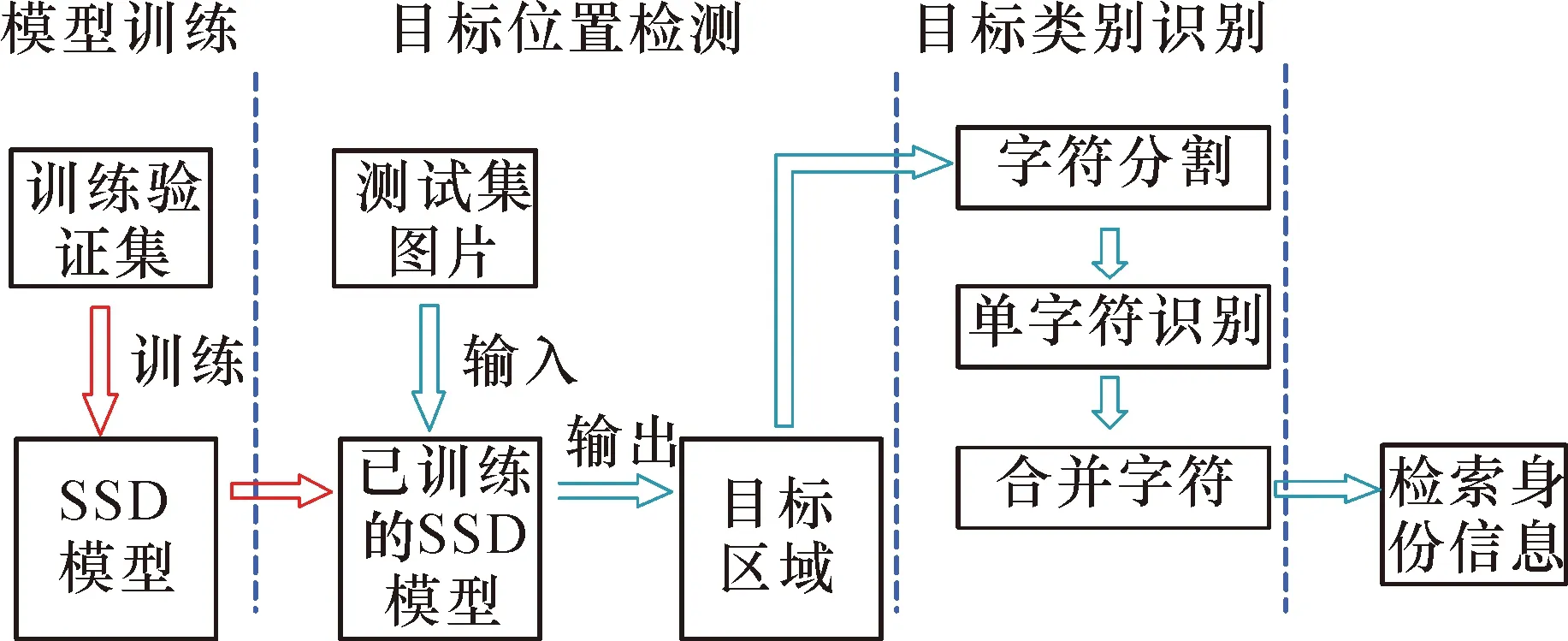
图2 矿井移动目标检测与识别总体流程Fig.2 Process of mine moving target detection and tracking identification
2.1 模型训练
步骤1:初始化。采用ImageNet预训练模型VGG16网络初始化SSD网络的主体网络层,采用均值为0、方差为0.01的高斯分布初始化SSD网络的扩展层。
步骤2:候选区域提取。在SSD网络模型中输入移动目标训练样本,SSD检测器分别从Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2和Conv11_2六个不同尺度的特征图上提取一系列候选框,并依据匹配策略选取其中部分候选框作为正负样本。
步骤3:误差计算。根据式(2)计算步骤2中的正负样本及数据集标注信息(包括数字序列的类别和位置坐标)的误差损失值。
步骤4:权值更新。利用基于梯度下降的深度学习反向传播算法更新SSD网络模型的权值。
步骤5:迭代收敛。遍历整个移动目标训练集,重复执行步骤2至步骤4,迭代并计算SSD模型在移动目标验证集上的误差值,直到该误差值达到最小。
2.2 目标位置检测
步骤1:将一张测试集图片输入到SSD模型中,SSD检测器自动提取目标图片特征。
步骤 2:根据步骤1中提取的目标图片特征,SSD检测器选取Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2和Conv11_2六个不同尺度的特征图,从其中提取出得分最高的一系列预测框。
步骤 3:SSD检测器采用非极大值抑制策略,从步骤2的一系列预测框中去除冗余的检测框,获得最后的目标预测框。
步骤 4:通过SSD检测器获取目标预测框的位置偏移量,确定目标预测框中的位置坐标。
2.3 目标类别识别
步骤1:从MNIST数据集中选取一个样本输入LeNet-5网络,利用式(6)对样本的特征向量进行卷积计算、非线性变化、下采样及全连接计算,输出一个预测结果。
步骤3:重复执行步骤1至步骤2,迭代更新网络的权值,最小化损失函数,当网络输出的误差收敛到预先设定的训练阈值时即停止训练。
步骤4:根据目标检测框中的位置坐标使用openCV对新图片进行截取,对截取的区域进行灰度化和二值化处理,并使用像素投影进行字符分割。
步骤5:将分割后的目标特征进行识别,并将识别出的特征字符合并成数字序列,对候选目标进行识别,输出测试图像的特征类别。
步骤6:从目标身份标识数据库中检索和确认目标身份信息。
上述算法的学习训练以及目标识别过程如图3所示。

图3 SSD-LeNet算法流程示意图Fig.3 Sketch map of SSD-LeNet Algorithm process
3 实验结果与分析
3.1 实验环境
为了验证本文所提出方法的有效性,对本文方法与其他几种流行的深度学习算法进行仿真实验对比。仿真实验采用阿里云GPU云服务器平台,GPU型号是NVIDIA P100,云服务器的处理器型号为Intel Xeon E5-2682v4,处理器主频2.5 GHz,本地盘存储大小440 GB,内存30 GB 、4vCPU,网络带宽为3 Gbps。网络模型的训练使用亚马逊深度学习框架mxnet,基于SSD_300 VGG网络和多GPU并行训练,编程语言采用python3.5以及计算机视觉库openCV实现完成。
3.2 实验数据集
本实验所用数据集包括目标检测数据集和数字识别数据集。使用具有反向传播的随机梯度下降网络优化算法训练数据,学习率为0.001,训练使用的批量为16,分类损失和回归损失的平衡参数为10。
实验中目标检测数据集采用手工制作。首先,采集像素为300×300的井下目标照片1 280张,经过图像去噪随机添加数字标签、标注其位置坐标,得到该数字标签的标注信息;然后使用深度学习框架mxnet,按9∶1的比例将1 280张图片分成训练验证集和测试集,作为训练和测试使用的原始数据;而数字识别则采用MINIST数据集,由0~9之间的灰度手写数字组成数据集,包含 70 000张图片,从完成去噪的数据集样本中随机选取60 000个样本构成训练集,10 000张用于测试集。在训练时将数字图片变成像素为28×28的标准图片作为输入进行测试,网络的输出设定为10个通道,即输出目标图像属于10个类别的概率。
3.3 实验分析
3.3.1 模型训练准确率测试
矿井移动目标边界框回归误差与训练样本批量的关系如图4所示,横轴是训练样本,纵轴是检测目标的边界框回归误差。由图4可知,随着训练样本批量的增加,边界框回归误差的总体趋势越来越小,使预测框能越来越准确地框选出输入图片中的数字标签。矿井移动目标类别预测的准确率和训练样本批量的关系如图5所示。由图5中可知,随着训练样本批量的增加,类别预测准确率的总体趋势是逐渐上升的,最终模型对数字标签区域的类别识别准确率可达99%以上。
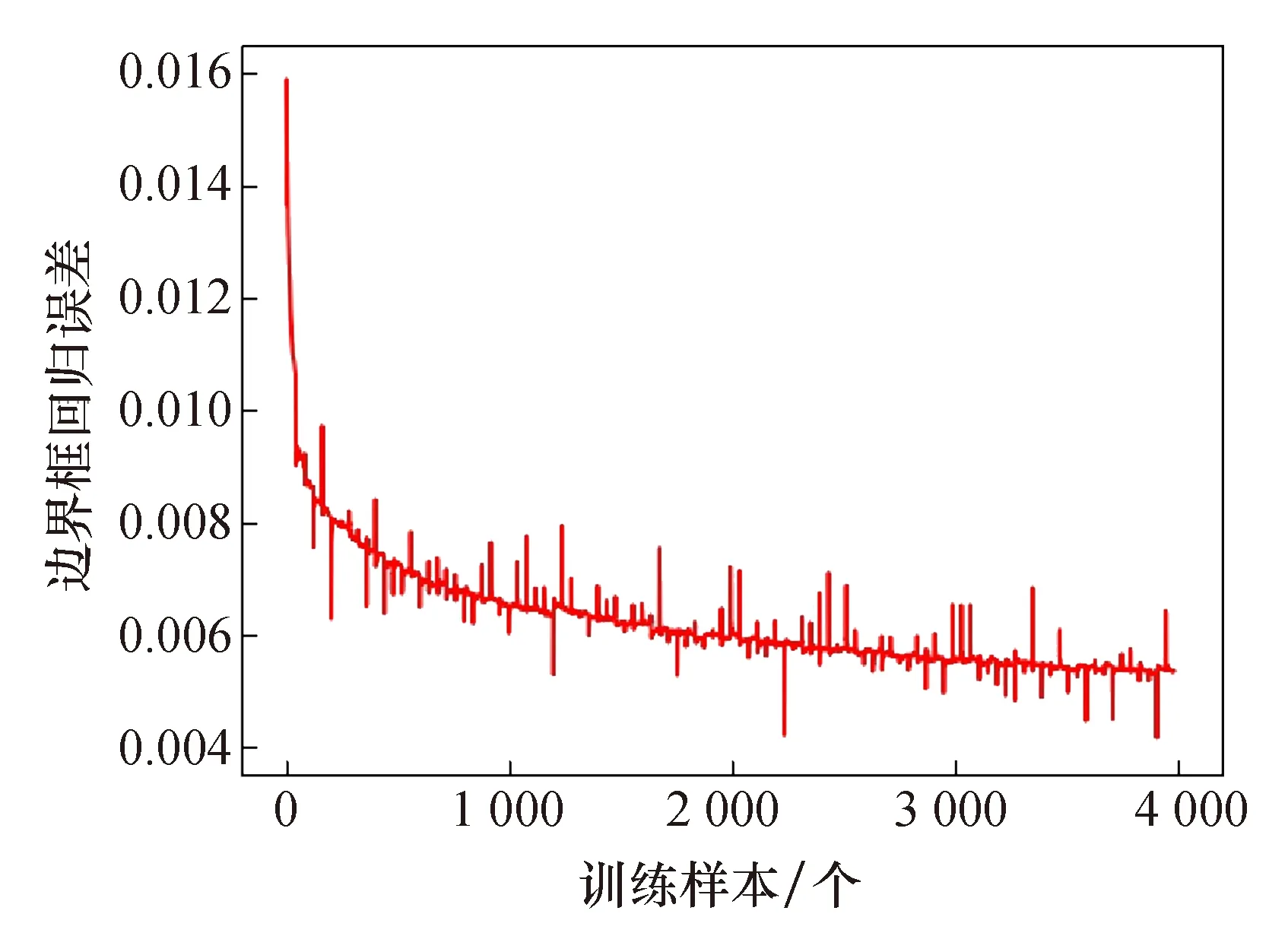
图4 边界框回归误差变化曲线Fig.4 Regression of regression error of bounding box

图5 类别预测准确率变化曲线Fig.5 Change of class prediction accuracy
3.3.2 检测准确率及识别实时性比较
为了进一步验证本文方法对井下不同大小、不同特征尺度目标的检测效果,与目前流行的Fast R-CNN、Faster R-CNN、YOLO等方法进行实验比较,选取井下作业人员和电机车等移动目标作为实验对象,分别添加不同大小的数字标签。同时,考虑井下实际环境中噪声的影响,模拟实验时在训练集的图片中分别添加高斯噪声和椒盐噪声,并经过300轮测试。上述几种方法的检测准确度和实时性对比结果见表1。

表1 几种方法在不同噪声条件下的检测准确率和实时性比较Tab.1 Comparison of real-time and precision of the algorithm in different image noise
由表1可见,本文所采用SSD模型的检测方法与Fast R-CNN、Faster R-CNN、YOLO等网络模型识别方法相比,对井下车辆和人员的检测准确度有较大差异,大目标的检测效果优于小目标,平均检测准确率最高可达94.0%以上。实验结果表明,SSD模型通过增加对主体网络层conv4_3的特征图的检测,使目标检测的准确率提高3%~5%。这是因为SSD模型利用基础网络特征图分辨率高、目标原图信息完整,通过增加输入图像尺寸提高了对小目标检测效果。在不同噪声条件下,采用的SSD模型对不同目标检测的实时性影响不大,在实验数据集上对图片的检测速度为32帧/s,可达到实时性效果,抗噪能力更好。因此,本文采用的方法在目标检测与识别的准确率和实时性,均优于其他几种深度学习模型。
3.3.3 测试实验
采用本文算法对某矿井泵房的巡检人员、出入井口人员等移动目标检测与识别进行实验。为体现视频帧测试样本随时空变化的视觉效果,对含有移动目标的视频序列进行快速逐帧检测,以25帧间隔提取一个视频帧,将所有提取出的视频帧组合成一个移动目标测试集,利用SSD检测网络对其进行测试,测试结果如图6至图8所示,图中测试样本下方的标注值为检测移动目标的置信度得分,该值越大,表明算法对目标检测的准确率越高。

图6 场景一的移动目标检测效果及置信度Fig.6 Example diagram of moving target detection effect and confidence

图7 场景二的移动目标检测效果及置信度Fig.7 Example diagram of moving target detection effect and confidence

图8 场景三的移动目标检测效果及置信度Fig.8 Example diagram of moving target detection effect and confidence
由图6至图8可知,当移动目标在不同时刻出现位姿变化、目标遮挡时,本文算法依然能准确、实时地检测识别到不同场景中的移动目标;当移动目标距视频图像采集设备较近时,本文算法不仅能检测到移动目标,还能对其携带的数字标签进行准确识别。实验表明,本文方法对不同测试场景下的人员目标及其携带数字标签的置信度得分较高,置信度最高达到0.999,能够对目标精准检测与精确识别。对视觉传感器远距离拍摄到的小目标,检测到人员目标与数字标签置信度分别达到0.751、0.574,说明对小目标检测具有较强适应性。因此,本文方法对矿井移动目标检测与识别,具有较强的学习训练能力,在目标检测准确性和实时性方面性能显著。
4 结 论
(1) 提出了一种基于深度卷积神经网络SSD-LeNet模型的矿井移动目标检测与识别方法,实现对矿井移动目标的检测与识别。
(2) 与其他方法相比,本文方法采用基于SSD模型的矿井移动目标检测与识别方法,克服了煤矿低照度环境下识别准确率下降的不足,对井下雾尘环境目标识别具有较强的鲁棒性。在目标检测的精准度和识别的实时性方面,性能优势比较明显,检测准确率在94%以上,检测速度达32帧/s以上。
(3) 与Fast R-CNN、Faster R-CNN、YOLO等相比,本文方法能够在较短的训练时间条件下达到98%以上的识别率,目标检测速度快,识别精度高,对提高矿井目标实时性检测与精准识别具有较好效果,对矿井小目标检测与识别具有较强适应性和鲁棒性,对矿井环境低分辨率目标图像具有较强的抗噪性。
猜你喜欢
光学精密工程(2022年13期)2022-08-02 08:53:30
计算机工程与应用(2022年1期)2022-01-22 07:46:48
高技术通讯(2021年3期)2021-06-09 06:57:24
计算机工程与科学(2021年4期)2021-05-11 01:59:36
创新作文(5-6年级)(2018年11期)2018-04-23 12:46:50
火力与指挥控制(2018年3期)2018-04-19 11:43:39
电测与仪表(2017年24期)2017-12-19 05:15:16
北京航空航天大学学报(2017年12期)2017-04-23 08:31:39
南风窗(2016年19期)2016-09-21 16:56:12
小天使·六年级语数英综合(2014年3期)2014-03-15 00:26:19
