
基于深度学习的煤中异物机器视觉检测
2021-03-24 00:53王卫东张康辉吕子奇谷诏闯钱瀚文张情意
矿业科学学报 2021年1期
王卫东,张康辉,吕子奇,谷诏闯,钱瀚文,张情意
中国矿业大学(北京)化学与环境工程学院,北京 100083
原煤开采过程中会混入各类铁器、锚杆、锚索、网片、破损胶带、电缆头、木材等生产废旧物资,井下作业产生的生活垃圾(如塑料瓶、塑料袋等)也会混入到原煤中[1-3]。煤中异物容易堵塞管道、溜槽、阀门、筛孔等部件,成为困扰选煤厂连续生产的主要因素之一。一旦发生事故,轻则运输系统堵塞、降低脱泥脱介系统效率、发生跑冒滴漏现象,重则会划伤带式输送机,造成设备故障和产品质量等事故[4]。拦杂网、除杂钩等机械装置是近年来常用的除杂方法,但除杂效率较低,且需要频繁检查和维护除杂装置,应用局限性较大[4],无法满足当前生产的需求,因此作者提出一种基于机器视觉的异物分拣方法[5],该方法的关键在于异物的智能检测。
近年来,基于机器视觉的异物检测研究逐渐深入。文献[6]通过传统的图像处理进行特征提取,并引入支持向量机(Support Vector Machine,SVM)进行分类;文献[7]基于概率图模型提取纹理特征和基于紧凑颜色编码结构化的目标跟踪方法,对异物进行定位和识别;基于传统图像处理技术的异物检测方法在特定应用场景中可以有效识别异物,然而其稳定性与可扩展性有待提高。常规的异物检测方法受用户设置的手工参数的影响很大,但是基于深度学习的方法可以通过学习训练数据的特征来提供更加准确的结果,并且在食品、农业、医学领域已有应用[8-10]。
深度学习在目标检测和语义分割等视觉任务中的成功应用[11-20],展示了神经网络强大的特征提取能力。利用深度学习目标检测框架Faster-RCNN对运煤输送带上的异物进行识别,虽然能精准定位到异物位置信息但不能完整勾勒轮廓,不利于异物中心点的描述,从而影响后续分拣[21]。
针对煤中异物检测,本文提出一种基于深度卷积神经网络的方法,用于复杂环境下煤中异物的像素级预测,完成边界的精确标记。该方法利用神经网络卷积层自动分层提取特征,提出一种损失函数用于解决样本分布不平衡带来的漏检和误检问题,并使用条件随机场作为后端优化模块,细化网络输出结果,实现煤中异物的准确检测与分割。
1 网络结构
基于深度卷积神经网络的煤中异物检测模型的网络结构如图1所示,前端主要包括编码器模块、解码器模块和跳层连接模块,后端使用条件随机场优化编码器模块。模型层级嵌套具有残差连接的卷积层,可以有效捕捉异物图像的局部特征;池化层将特征图尺寸缩小,使其成为更低维的表征;转置卷积执行上采样恢复空间维度,跳层连接融合多尺度的特征,建立端到端的异物检测,对每一个像素点进行分类,从而完成前景(煤中异物)和背景的分割。
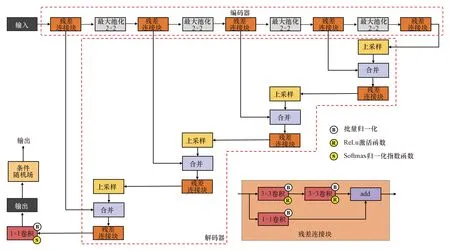
图1 网络结构Fig.1 Network structure diagram
1.1 前端网络结构设计
为保证网络结构能够提取有效信息,又可提高模型的训练速度,卷积层使用残差卷积块,由2个33卷积和一个11卷积组成,并采用残差连接,能够增加网络深度,使得特征映射对输出的变化更加敏感,模型拥有更强的表达能力,提高网络分割精度,还可以使模型更容易训练,既能防止模型退化,又能缓解梯度消失[22]。卷积层步长为1,全0填充,池化层采用最大值池化,池化窗口为22,步长为2,图像经过编码器端4次池化下采样后,大小为原图大小的1/16。为得到与原图同样大小的输出结果,解码器的上采样层采用转置卷积,滑动窗口大小为22,步长为2,每次转置卷积后都要进行批量归一化(Batch Normalization,BN),允许模型使用较大的学习率,减弱对初始化的强依赖性,保持隐藏层中数值的均值、方差不变,让数值更稳定,为后面网络提供坚实的基础,同时还有正则化作用。将不同尺度的特征图谱进行上采样恢复图像信息,在解码器端进行多尺度特征融合,最终经过Softmax激励函数输出概率值,进行逐像素的预测,从而完成边界的精确标记。Softmax激励函数概率值计算公式如下:
(1)
式中,xi表示特征图谱中的第i个输出向量。
1.2 后端优化模块设计
前端网络不断的卷积和池化操作,使后续像素点的感受野不断增大,导致输出结果对边缘约束力不足,最后的分割结果较粗,因此使用条件随机场考虑全局信息(颜色和空间位置),对模型分割结果进行细化。
条件随机场(Conditional Random Field, CRF)是给定一组随机变量的条件下另一组输出随机变量的条件概率分布模型[23-25]。对于每个像素i具有类别标签xi对应的观测值yi,每个像素点作为节点,像素与像素间的关系作为边,即构成了一个条件随机场。通过观测变量yi来推测像素i对应的类别标签xi,条件随机场如图2所示。

图2 条件随机场示意图Fig.2 Schematic diagram of conditional random field
CRF基于底层图像像素强度对前端网络输出结果进行“平滑”,将像素强度相似的点标记为同一类别。后端优化模块的能量函数如下:
E(x)=∑θi(xi)+∑θij(xi,xj)
(2)
式中,xi,xj分别表示像素点i,j对应的标签;θi(xi)为一元势函数来自异物检测模型的输出;θij(xi,xj)为二元势函数描述像素点间的关系。
鼓励相似像素分配相同的标签,而相差较大的像素分配不同标签。像素点之间综合考虑颜色空间和欧式距离进行相似性度量,因此基于CRF后端优化模块能够细化异物图像在边界处的分割。
θi(xi)=-logp(xi)
(3)
式中,p(xi) 为深度卷积神经网络计算的像素点i处的标记分布概率。
θij(xi,xj)=μ(xi,xj)∑ωmkm(fi,fj)
(4)
式中,μ(xi,xj)为约束力方向,只有相同的标签能量才可以互相传导;ωm为权重参数;km为高斯卷积核,取决于像素i、j提取的特征(表示为f),并由参数ωm进行加权。

(5)
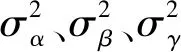
式(5)的km(fi,fj)求和项中,第一项表示两像素点空间位置距离越近,颜色越接近,特征就越强;第二项是平滑处理,考虑两像素点空间上的接近程度。
1.3 模型评估指标
煤中异物检测模型的评价标准采用交并比(Intersection Over Union,IOU),即标签与预测结果的重叠区域大小与它们占总区域大小的比值,表示为
(6)
式中,TP(True Positive)为分类正确的正样本;TN(True Negtive)为分类错误的正样本;FN(False Negtive)为分类错误的负样本。
图像中每个需要分割类别的 IOU 均值MIOU表示为
(7)
式中,N为类别总数。
2 实验设置
2.1 异物图像数据采集
在安徽省淮北矿业股份有限公司涡北选煤厂手选输送带上采集的异物图片共9 653张,其中异物主要为木棍、竹竿、绳子、塑料袋、铁器等。图像数据采集装置如图3所示。图像数据采集主要设备分为两部分:一部分为高清相机和高压风喷吹的镜头除尘装置;另一部分为数据处理单元,主要为高性能的中央处理器CPU和图像处理器GPU。具体型号和参数见表1。

图3 图像数据采集装置Fig.3 Image data acquisition device

表1 主要设备清单Tab.1 List of major equipment
2.2 异物图像预处理
为了提高数据特征的多样性,将采集到的异物图像从RGB色彩空间转换到HSV色彩空间进行统一预处理,随机0.9~1.1倍调整曝光和饱和度,然后再将其从HSV色彩空间转换到RGB色彩空间。为了增强模型的鲁棒性和泛化能力,对数据集剪切、缩放、旋转、平移变换,进行数据增强,由原始的9 351张异物图像增至18 715张,最后将所有图像统一处理为256×512像素的RGB彩色图像,作为网络的输入。对训练样本集按照8∶2的比例随机划分训练集和测试集,得到训练异物图像样本14 972张,测试样本集3 743张。
2.3 模型的损失函数
为了缓解前景(异物)、背景(输送带、煤、矸石)比例严重失衡对模型训练的影响,提出一种损失函数能够降低易分类样本的权重,使其更加关注难分类的样本,避免在训练过程中大量的简单负样本淹没检测器,从而解决类别不均衡问题。损失函数计算公式如下:
(8)

不同γ对于损失函数的调整如图4所示。当γ>0时可减少易分类样本的损失,更加关注于难分、错分的样本。
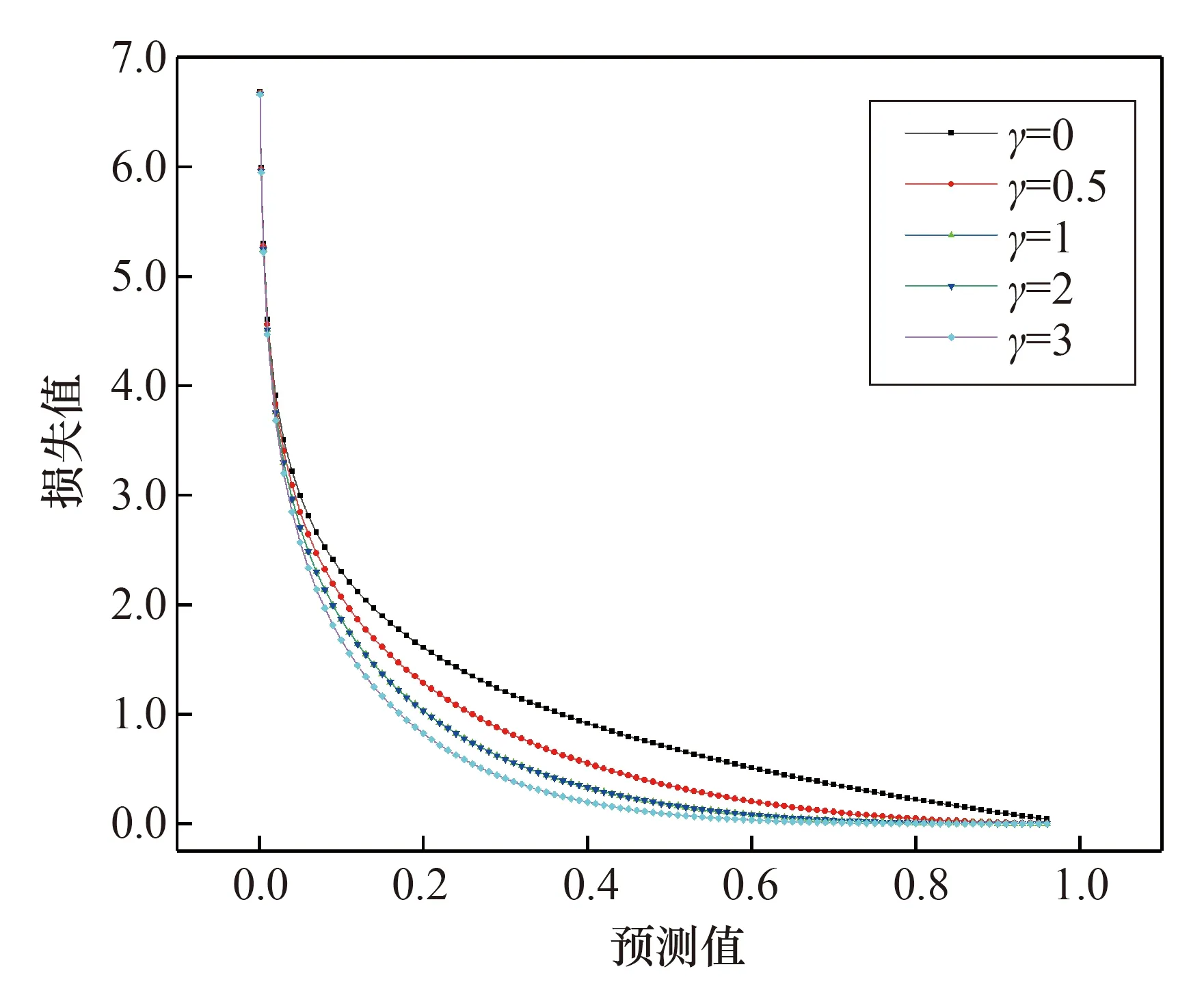
图4 不同情况下损失函数曲线Fig.4 Loss function graph under different γ cases
此外,加入平衡因子α,用来平衡正负样本本身的比例不均。最终损失函数计算公式如下:
(9)
2.4 网络训练与参数寻优
为了减少模型训练时间,在ImageNet预先训练权重的基础上进行微调,采用Adam优化器,学习率为10-5,学习衰减率为5×10-4,迭代30次。对于损失函数中的2个超参数进行网格寻优,通过前期探索实验初步确认参数搜索范围。首先,选取α=0.25,对比γ分别为0、1、2、3这4组参数,确定最优γ值;然后,取α分别为0.15、0.25、0.35这3组参数进行对比,确定损失函数中参数的最优组合;训练过程中采用相似度系数作为精度评价指标,当验证集的相似度系数不继续上升时即终止模型训练,以防止模型发生过拟合。
3 结果与分析
为验证本文提出模型对煤中异物的检测效果,选取经典语义分割网络FCN-32、Unet、Segnet作为对比,使用3 743张异物图像数据集测试模型性能,测试结果见表2。由表2可知,文中提出的模型在测试集上的表现最优,正样本MIOU达到55.82%,总样本MIOU为77.83%。使用最优模型对测试集中4类异物(硬质棍状异物、硬质板状异物、软质绳状异物和软质布状异物)在两种不同生产状况下(正常生产和物料堆叠)进行测试,异物检测准确率达到98.58%,测试结果如图5所示。
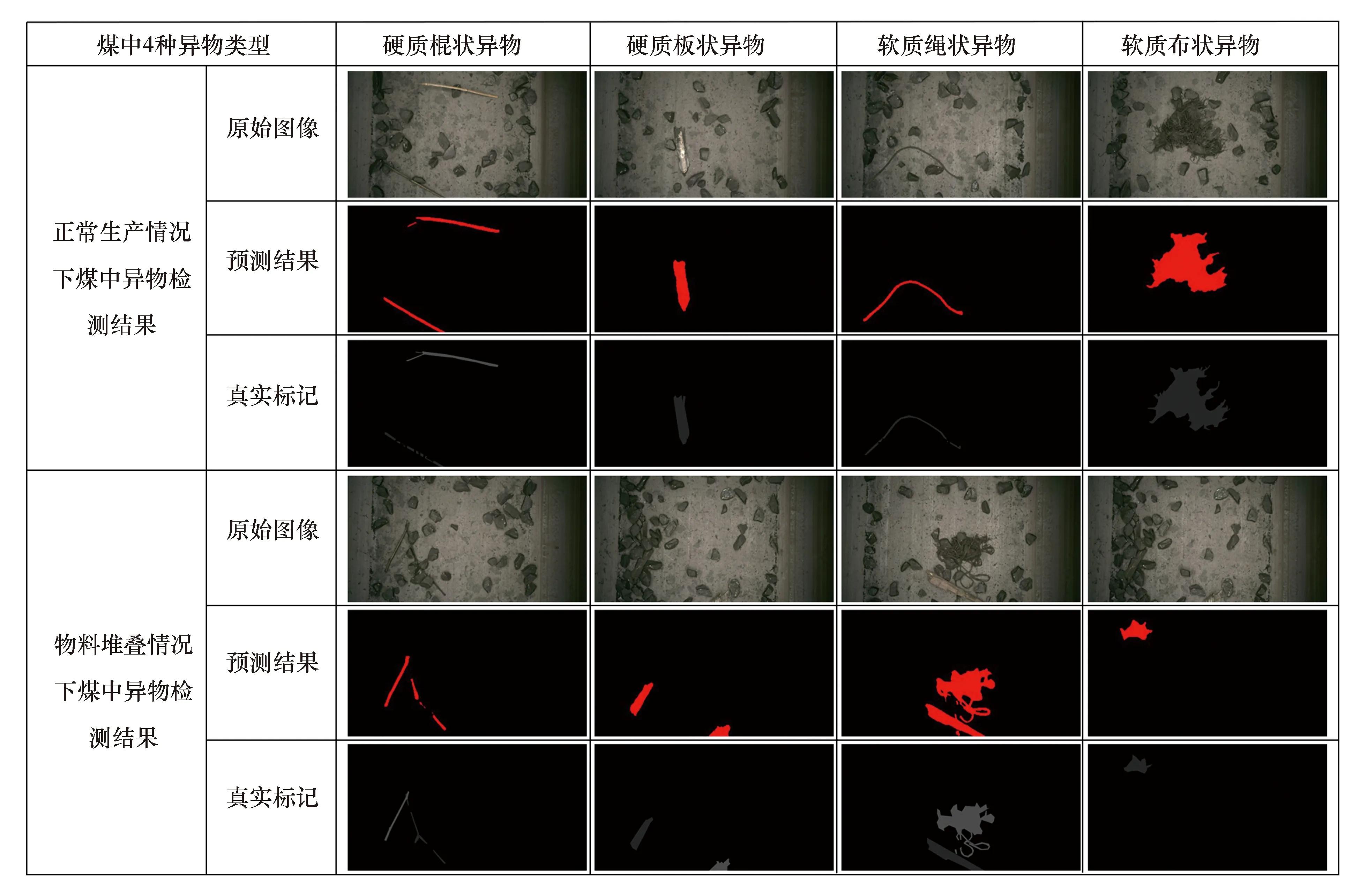
图5 煤中异物测试示例Fig.5 Example of foreign objects detection in coal images
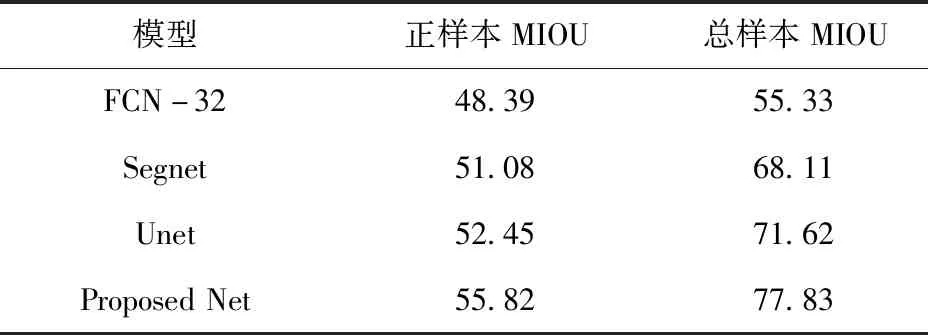
表2 模型表现对比Tab.2 Comparison with other models %
3.1 损失函数对模型效果的影响
损失函数是决定网络学习质量的关键,用来表现预测与实际数据的差距程度。文中提出的损失函数包含2个超参数:γ因子用来调节样本权重降低的速率,使得模型减少易分类样本的损失,以便更加关注于难分、错分的样本;平衡因子α用来平衡正负样本的比例。通过超参数的调节可使模型减少误检情况,不同超参数组合训练结果对比如图6所示。以交叉熵损失函数作为模型基准,确定损失函数最佳参数组合为γ=1,α=0.25,使得模型正样本MIOU提高了7.85%,总样本MIOU提高了3.74%。使用不同损失函数训练模型,预测结果对比如图7所示。其中,图7(b)为真实标注,图7(c)预测结果1对应的模型由交叉熵损失函数训练得到,图7(d)预测结果2对应的模型由最佳参数组合的损失函数训练得到。对比图7(c)(d)可以看出,损失函数的调节能够有效缓解前景、背景比例严重失衡引起的模型误检问题,同时还能抑制部分图像噪声,使得模型在复杂情况下对煤中异物的检测具有更强的鲁棒性和泛化能力。
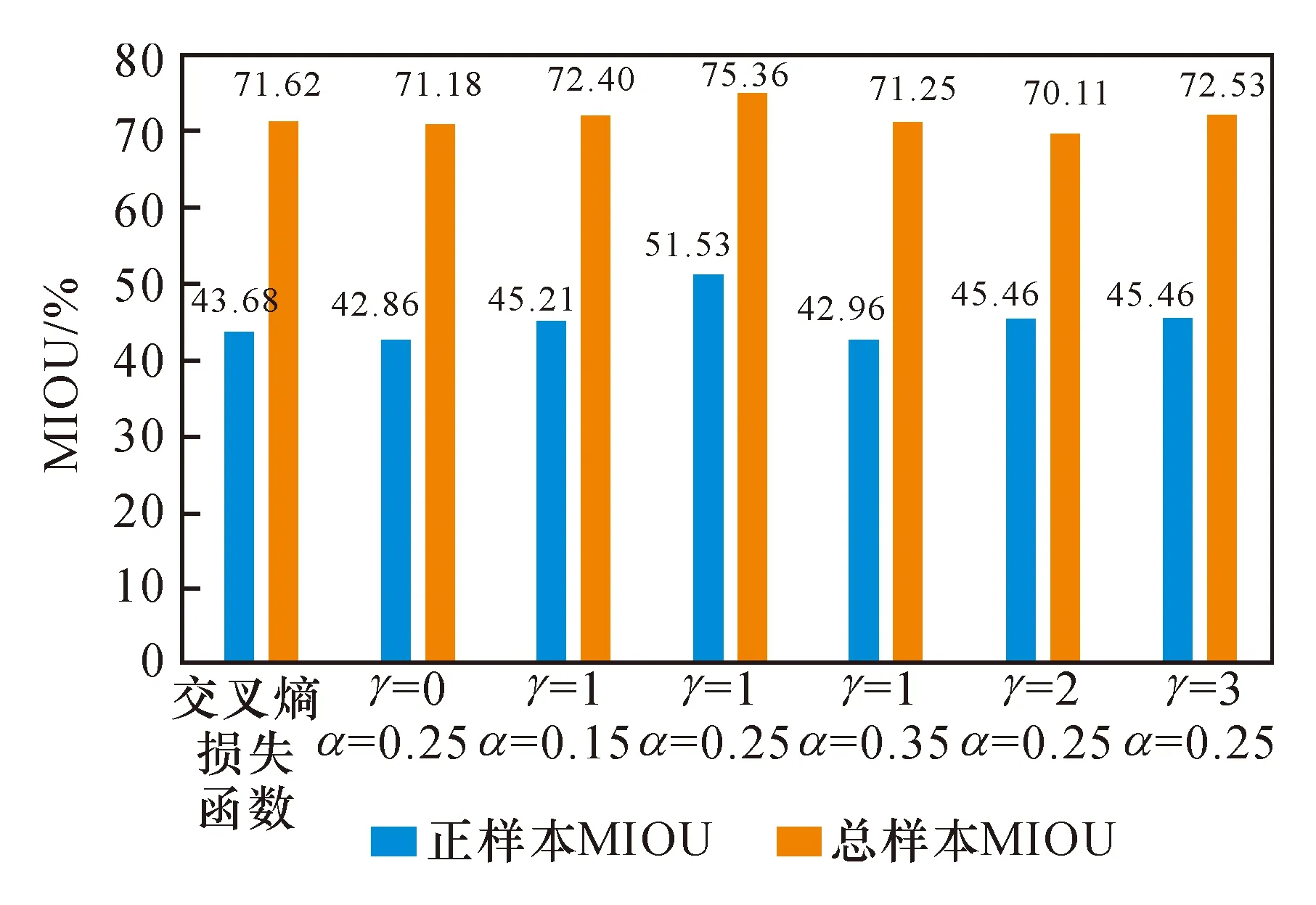
图6 不同参数组合对比结果Fig.6 Comparison of different parameter combinations

图7 损失函数对模型预测结果的影响Fig.7 Influence of loss function on model prediction results
3.2 迭代次数对模型效果的影响
为了分析迭代次数对模型的影响,采用Adam优化器,学习率为10-5,学习衰减率为5×10-4,迭代50次模型的相似度与损失值如图8所示。当迭代次数较少时,网络学习效果并不理想,随着迭代次数的增加、网络参数的不断优化,经过30次迭代之后模型的相似度系数的提升和损失函数的下降已趋于稳定,模型迭代20次已经基本收敛,损失值稳定在0.15左右,相似度基本稳定在98%左右。通过模型在测试集上的表现,不同训练轮次下模型效果如图9所示。模型训练迭代次数为25时,模型效果最优,正样本MIOU达到55.82%,总样本MIOU为77.83%,如果继续训练模型将会产生过拟合现象。
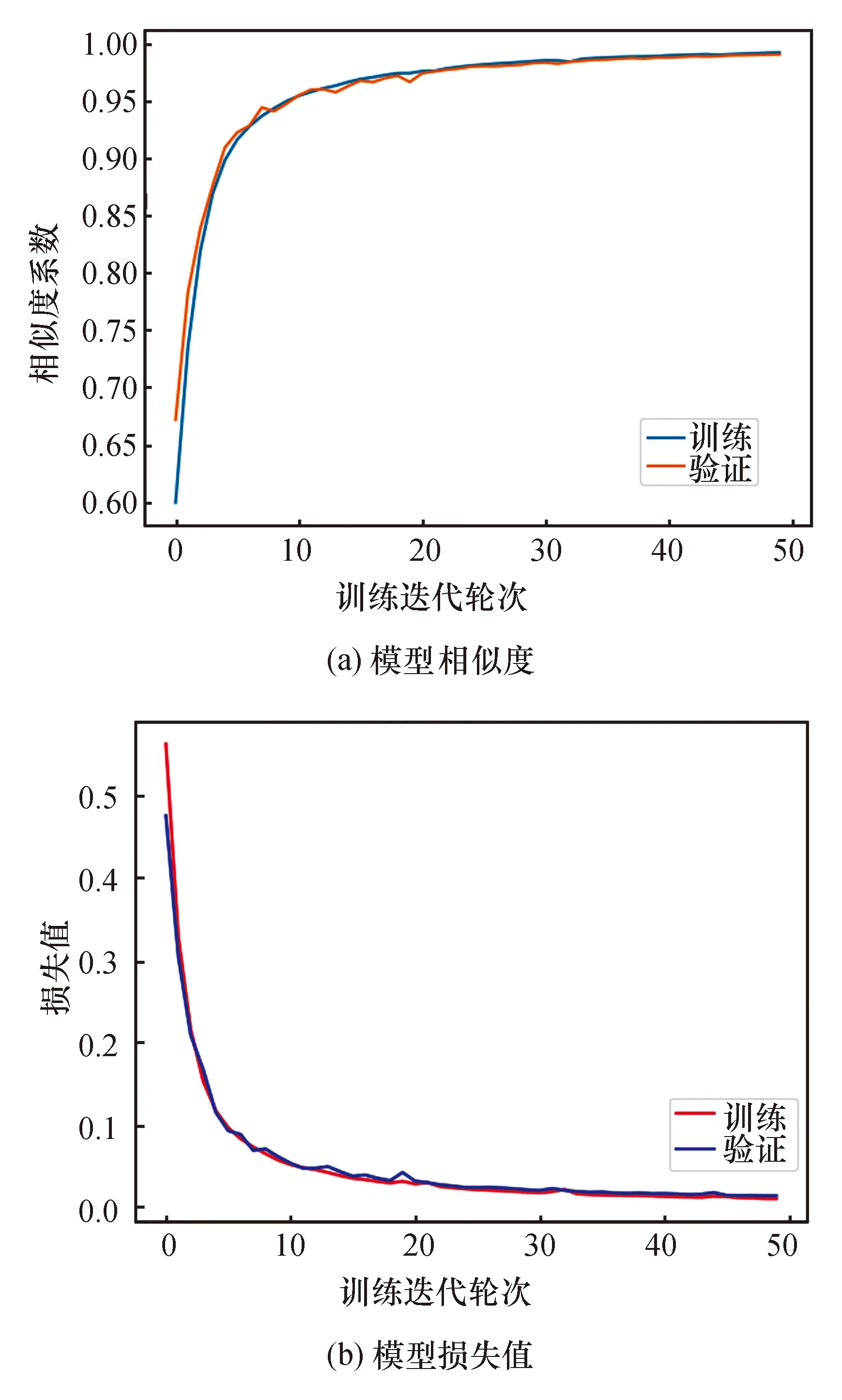
图8 模型训练过程Fig.8 The process of model training
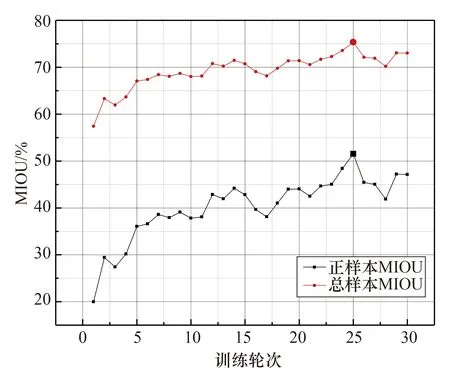
图9 不同训练轮次下模型预测结果Fig.9 Model predict results under different training rounds
3.3 后端优化对模型效果的提升
通过损失函数的约束,模型在一定程度上缓解了误检问题,但是由于前端网络不断的卷积和池化操作,使后续像素点的感受野不断增大,导致输出结果对边缘约束力不足,最后的分割结果较粗。因此,后端优化模块考虑全局信息(颜色和空间位置),对模型分割结果进行细化,通过能量函数优化求解,对预测结果和原始图像中明显不符合事实的进行识别、判断、剔除,替换成合理的解释,对图像语义预测结果进行优化,生成最终的语义分割结果。使用CRF前后模型MIOU指标对比见表3。
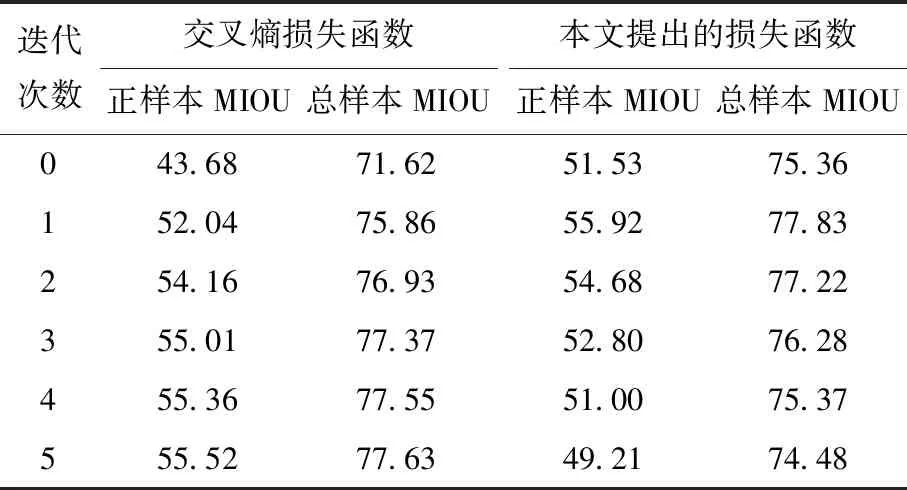
表3 使用CRF前后数据对比Tab.3 Data Comparison with CRF %
由表3可知,使用交叉熵损失函数通过CRF优化迭代5次时,正样本MIOU为55.52%,总样本MIOU为77.63%;使用改进的损失函数通过CRF优化迭代1次时,正样本MIOU为55.92%,总样本的MIOU为77.83%。改进损失函数后CRF迭代次数更少,速度更快,模型效果更优。使用后端优化模块前后模型预测结果对比如图10所示,可以看出由于图像采集过程中背景的干扰和噪声的存在导致模型存在误检情况。图10(c)是经过CRF对模型调优后的结果。在空间位置上,距离很近的像素应该分为同一类,在RGB颜色空间上会给予一定的惩罚值和一些能量项,使得对于模型预测的概率进行修正,减少对一些离散像素的误检测和对边缘进行细化,能够抑制一定的噪声,减少过分割和误检测。通过对比可以看出,使用后端优化模块调优网络结构的输出并强化其捕捉细粒度信息,促成了底层图像信息(如像素间的相互关系)与产生像素级别的类别标签推理输出的结合。这样可有效地细化分割结果,减少过分割和误检测,提升模型的鲁棒性和泛化能力,能够完成复杂环境下的煤中异物检测。

图10 后端优化前后预测结果对比Fig.10 Comparison of prediction results with CRF
3.4 模型误检原因分析
为了进一步了解神经网络的分类决策策略,方便对神经网络决策过程调试,使用类激活图进行可视化对模型误检原因进行分析。可视化结果如图11所示。可以看出,误检主要出现在煤矸表面有明显的棱角及其边缘、视觉容易混淆的区域,并且图像噪声会对煤中异物的识别带来一定的干扰。因此,对于背景和噪声干扰带来的误检问题提出一种损失函数用于网络训练,并使用条件随机场对模型预测结果进行细化,效果提升明显。从图11(b)中可以看出,针对易分类和难分类样本分布两种极端情况,通过损失函数对模型进行调整,降低易分类样本的权重,使模型更加关注于难分类的样本,从而在一定程度上缓解误检情况。针对可能误分类样本采用后端优化模块从颜色和空间位置上对网络输出结果进行调整,使得模型能有效地细化分割结果,减少误检情况,提升模型的鲁棒性和泛化能力,能够完成复杂环境下的煤中异物检测。

图11 类激活图Fig.11 Class activation map
4 结 论
(1) 针对煤矸分选系统中的异物图像进行数据增强,增加模型泛化能力和鲁棒性,简单有效;提出一种损失函数,在一定程度上解决了复杂易混淆背景和煤中异物所占图像像素比例小所带来的误检问题;模型使用多尺度信息融合,取长补短,提升结果测试能力。通过对3 743张测试数据集进行测试,检测准确率达到98.58%,正样本MIOU达到55.82%,总样本MIOU为77.83%。
(2) 提出使用条件随机场作为其后端优化模块,调优分割架构的输出并强化其捕捉细粒度信息,促成了底层图像信息(如像素间的相互关系)与产生像素级别的类别标签推理输出的结合。能有效地细化分割结果,减少过分割和误检测,提升模型准确率。针对本文提出的损失函数,使用CRF优化使得正样本MIOU提升了4.39%,总样本MIOU提高了2.17%。
(3) 基于类激活图的可视化方法分析了模型误检原因。对损失函数的改进和条件随机场的优化,可有效缓解模型对煤矸石表面和背景的误检情况。
猜你喜欢
今日农业(2022年15期)2022-09-20
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
小雪花·成长指南(2021年6期)2021-08-18
小天使·二年级语数英综合(2019年10期)2019-11-08
文萃报·周二版(2018年22期)2018-09-18
读者·校园版(2015年19期)2015-05-14
海外英语(2013年8期)2013-11-22
