
融合马尔科夫决策过程与信息熵的对话策略
2021-03-18 08:04:12朱映波赵阳洋王振宇
计算机工程 2021年3期
朱映波,赵阳洋,王 佩,尹 凯,王振宇
(1.天翼爱音乐文化科技有限公司,广州 510081;2.华南理工大学软件学院,广州 510006)
0 概述
随着人工智能相关技术的飞速发展,人与智能设备之间的交互方式趋于智能化,逐渐从传统的图形化交互向人机对话交互转变[1-3],即利用智能助理来帮助用户完成多项任务或多项服务。任务型人机对话作为人机对话系统的重要分支之一,是人工智能领域中的一个热门研究课题[4-5],同时被逐渐应用于工业界的各个方面,例如苹果手机助手Siri[6]、亚马逊Alex 和阿里智能客服小蜜等。
任务型对话系统又称为目标驱动型对话系统,例如客服机器人、机票预订系统等[1,7-9],它们为用户提供特定领域的服务,旨在帮助用户完成购物、订机票等任务。这类人机对话系统能够大幅降低人力成本,简化人机交互过程,提高应用的智能程度,具有较高的研究和应用价值[10]。
任务型对话系统由自动语音识别(Automatic Speech Recognition,ASR)、自然语言理解(Natural Language Understanding,NLU)、对话管理(Dialogue Management,DM)、自然语言生成(Natural Language Generation,NLG)和语音合成(Text-To-Speech,TTS)5个模块组成[4,11]。其中:ASR 模块将用户的语音输入转化为文本的形式;NLU 模块的作用是理解用户的对话文本,并提取出与任务相关的槽-值对信息;DM 模块是对话系统的核心控制模块,包括对话状态跟踪(Dialogue State Tracking,DST)和对话策略(Dialogue Policy,DP)两个部分[11]:DST 接收来自NLU 模块的语义信息,更新当前的对话状态,DP 确定下一步系统的响应策略;NLG 模块根据系统响应策略生成自然语言文本;TTS模块将语言文本转为语音反馈给用户。
对话策略任务根据对话状态跟踪输出的当前状态分布,选择系统响应的动作或策略[12-13],其性能的优劣决定了人机对话系统的成败。因此,设计一个鲁棒的对话策略模型是任务型系统成功应用的关键。然而,通过现有的深度学习的方法训练一个高质量的对话策略需要大量的会话数据,且只能应用于已经有大型数据集的场景[14-15]。由于对话系统的潜在应用领域非常广泛,因此在现实场景中存在较多的对话数据稀缺性问题[16]。
本文构建一个融合马尔科夫决策过程和属性信息熵的对话策略模型。将对话策略视为一个马尔科夫决策过程,通过建立
1 相关工作
目前主流的对话策略模型可分为基于有限状态自动机的对话策略、填槽或填表法和基于概率模型的对话策略。其中,基于概率的模型能通过回报函数的迭代计算、训练状态和动作之间的映射关系,得到可用的对话策略规则,这种方法由于避免了依赖人工制定规则带来的局限性,并且能够通过训练提升模型的泛化能力,因此具有更好的效果。
1)基于有限状态自动机的对话策略
任务型多轮对话系统通过与用户进行多轮的对答,明确用户的需求,得到完成任务需要的信息,这个与用户进行多轮交互的过程类似于“初始状态→动作→更新状态→动作→更新状态→…→终止状态”的状态与触发动作进行交替的过程,与图模型中的有限状态自动机(Finite-State Machine,FSM)的定义非常吻合。有限状态自动机用来描述对象在一个生命周期内的状态序列以及状态间进行转移的动作事件,可以通过状态转移图来进行描述,图1 描述了在订餐任务中有限状态自动机的状态转移图示例。
在图1 中,节点表示系统执行的对话动作,节点之间的边表示用户执行的实际动作。在对话过程中,系统通过将用户的输入进行解析,得到相应的转移方向,使得对话沿着状态转移图的设定进行,对话中用户与系统每交互一次,状态就发生一次转移,直到对话结束。基于FSM 的对话策略方法是典型的系统主导型方法,对话的节奏完全由系统决定,用户需要按照系统指定的流程补充信息。这种方法通过预先人为地定义好对话流程,具有建模简单且逻辑清晰的优势,对简单任务的信息获取很友好。对于稍复杂的任务,如果对话过程中出现了系统没有预先定义好的状态,那么对话将会卡在其中的一个状态中无法继续进行。基于有限状态自动机的对话策略需要对对话中的细节提前进行编写和维护,缺少灵活性,因此在开发的过程中也很难对其进行扩展。

图1 基于有限状态自动机的对话策略状态转移图Fig.1 State transition diagram of dialog policy based on finite state automata
2)基于填槽的对话策略
基于填槽的对话策略在一定程度上改进了基于FSM 的方法,它将对话建模成一个填槽的过程,其中,槽表示在对话过程中完成特定的任务所需要获取的信息属性。系统通过制定填槽的优先级,根据当前的槽位状态来决定下一个系统动作。与基于FSM 的方法相比,填槽法不对获取用户信息的顺序进行限制,用户可以在对话过程中一次性补全一个或多个槽信息。经过系统的引导,用户进行输入,系统将用户输入转化为一个或多个槽信息的填充,这种方法为用户提供了相对灵活的输入方式,支持用户和系统混合主导的系统,适用于相对复杂的信息获取场景。但这种填槽的对话策略方法由于槽位的限制,当槽的数量过多时,算法的复杂程度也会急剧增长,因此不适用于更复杂的场景。
3)基于强化学习的对话策略
基于有限状态自动机和基于填槽的对话策略算法都需要人工制定规则,这种预先定义好所有场景的方法,不具备领域迁移的能力,当任务发生变化时,就需要重新制定规则。马尔科夫决策过程(MDP)是一个解决序列决策的模型,文献[17]将对话决策建模成一个马尔科夫决策过程,通过模拟系统与用户之间的交互过程,经过训练优化模型参数,得到状态和动作之间的映射关系(即对话策略)。在任务型对话系统中,通过将槽的取值状态映射为对话的状态,同时定义系统的动作、执行动作的回报函数和状态与状态间的转移概率,这种方法相比于人工定义对话规则的方法拥有更高的覆盖率。与需要大量标注数据的监督学习不同,强化学习可以通过构建智能体感知环境,然后由系统与用户进行交互,根据回报函数奖励好的行为、惩罚坏的行为,从而训练出对话系统的最优策略。
对于槽数量较多的复杂场景,基于强化学习的模型也有较好的扩展方式。面对过多的状态或动作空间,在传统强化学习很难进行高效探索时,深度强化学习能够大幅提升模型的收敛速度。同时,也出现了很多传统强化学习模型的变种,如文献[18-19]将卷积神经网络(Convolutional Neural Networks,CNN)与传统强化学习中的Q 学习[11]算法相结合,提出了深度Q 网络(Deep Q-Network,DQN)模型。
目前关于策略学习的相关研究在任务型对话系统中的比重相对较小,远少于自然语言理解和对话状态跟踪任务,仍然存在许多需要深入研究和解决的问题,如系统冷启动、管道型对话系统模块间误差传递和复杂场景中状态空间指数增加等,许多学者在对话策略学习的问题上进行了新的探索。
2 基于马尔可夫决策过程与信息熵的对话策略
2.1 马尔科夫决策过程模型构建
对话管理中的对话策略选择问题可以抽象为一个马尔科夫决策过程(MDP)[20-21]。马尔科夫决策过程由五元组<S,A,P,R,γ>来定义,5 个元素分别表示状态集合、动作集合、状态间的转移概率、及时回报和衰减因子。
1)状态集合S
在音乐搜索任务中,对话状态体现为6 个槽的取值情况,每个槽的状态分为已填充和未填充两种,将状态跟踪模块输出的对话状态转换为编号表示,则总共有26=64 种状态,按照下标01 依次编码,六位01 编码依次表示“song,singer,album,lyricwriter,composer,label”槽的填充与否,状态数量和对应的状态编号如表1所示。例如,当前的对话状态为<singer=周杰伦,song=稻香>,则所对应的状态编码应为S110000。那么,状态集合S={S000000,S100000,…,S111111}。

表1 对话状态的编号表示Table 1 Numbered representation of dialog state
终止状态表示对话的结束,若达到了终止状态,则表示系统应给出歌曲列表offer()结束对话。从经验常识出发,本文制定如下规则来定义对话的终止状态:
(1)当用户给出歌曲的歌名song 信息和任一其他属性信息,则该状态为终止状态,共5 种。
(2)当用户给出歌曲的专辑名album 和作词者lyricwriter 或作曲者composer,则该状态为终止状态,共2 种。
(3)6 个属性中已知任意3 个或3 个以上,则该状态为终止状态,共20+15+6+1=42 种。
因此,定义42 种终止状态,如表2 所示。

表2 对话终止状态说明Table 2 Description of dialogue final states
2)动作集合A
系统动作分为询问动作request()和提供歌曲列表动作offer(),询问动作又可以根据询问不同的槽分为询问歌曲名request(song)、询问歌手request(singer)、询问专辑request(album)、询问作词者request(lyricwriter)、询问作曲者request(composer)和询问歌曲类型request(label)6 个动作。因此,动作集合A={offer(songs),request(attrs)},其中,attrs=[song,singer,album,lyricwriter,composer,label]。
3)状态间的转移概率P
定义状态(s,s')之间的转移概率为s'可能的取值个数,当前状态s为非终止状态。用户在单轮的对话中,可能会给出不止一个槽的信息,因此,按照表3 定义对话状态之间的转移概率。

表3 对话状态转移概率示例Table 3 Example of dialogue state transition probability
4)及时回报R
定义当对话状态达到设定的49 种终止状态时,意味着用户完成了当前的任务,转移后的奖励值设为100,其他每一轮对话状态发生转移的奖励值均为-1,如表4 所示。

表4 对话状态转移奖励矩阵示例Table 4 Example of dialogue state transition reward matrix
5)衰减因子γ
衰减因子代表了未来收益对当前状态的重要程度,γ∈[0,1],本文设定衰减因子γ=0.8。
马尔科夫奖励过程中状态值函数的贝尔曼方程表示为:

使用值迭代的方式对状态值函数进行求解,得到收敛之后的状态值函数矩阵v。
2.2 属性信息熵计算
熵在信息论中表示信息量的大小,用来描述信源的不确定程度,不确定性越大,信息量越大,熵越大;反之,不确定性越小,信息量越小,熵越小。在基于多轮对话的音乐搜索任务中,每一轮对话后系统依据用户提供的目标约束搜索曲库,得到歌曲列表。不同属性槽取值的不确定程度不同,因此带有的信息量也不同。本文设计一种计算曲库搜索结果歌曲列表中各个属性信息熵的算法,根据属性信息熵的大小来衡量哪一个属性槽值的信息量最大,进而指导系统下一轮对话应引导用户给出信息熵最大的属性取值,以能够用最少的对话轮次完成音乐搜索任务。属性信息熵的计算公式如下:
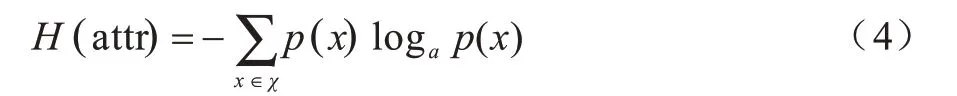
其中,χ表示属性attr 可能的取值集合。
首先依据每一轮次用户目标约束进行曲库搜索,得到音乐列表,判断搜索结果数量是否小于等于N,若小于等于N,则系统直接给出音乐结果offer(songs);若大于N,则系统计算结果列表中各个属性槽的信息熵,选择信息熵最大的属性进行询问。计算过程如式(5)所示:
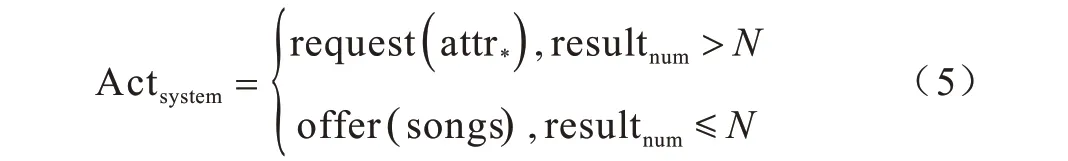
其中,attr*表示信息熵值最大的属性槽。
2.3 融合算法
强化学习的方法通过定义五元组将当前时刻之后的状态奖励考虑进来,使得对话中系统的决策具有前瞻性(考虑后序状态奖励),能够快速选择最快抵达终止状态的最优路径,不需花费太多时间,且不同状态的奖励值可通过自定义的方式进行设定,但该方法所得的状态之间的状态值函数可能相等,所选择的路径可能是次优解;而基于属性信息熵计算策略的计算方法考虑了音乐搜索结果列表,通过当前对话状态得到对应的目标约束,进行曲库搜索,然后计算音乐属性槽的信息熵,求得考虑了当前轮次音乐搜索结果的对话决策。由于基于属性的方法需要根据检索列表进行曲库搜索,数据集的属性种类越多,响应时间越久。两种方法都有自己的特点和优势,因此本文提出基于贝尔曼方程求解的强化学习和属性信息熵相结合的对话策略算法,融合两种算法的优点,利用基于贝尔曼方程求解的强化学习算法帮助基于属性信息熵的策略计算方法筛选检索列表以缩短响应时间,利用基于属性信息熵的策略方法帮助基于贝尔曼方程求解的强化学习算法排除次优解。本文根据基于贝尔曼方程求解的强化学习和属性信息熵相结合的对话策略算法对对话策略模块进行建模,算法的流程如图2 所示。
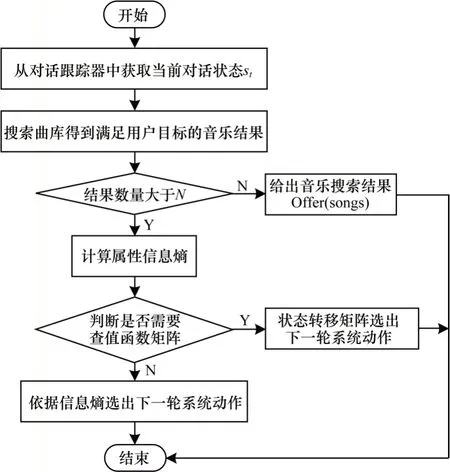
图2 融合强化学习与属性信息熵的对话策略流程Fig.2 Procedure of dialogue strategy combining reinforcement learning and attribute information entropy
融合算法步骤如下:
步骤1根据当前的对话状态得到用户的目标约束,通过目标约束搜索音乐曲库得出歌曲结果列表。
步骤2判断歌曲列表的数量resultnum,若resultnum>N,则计算属性信息熵,若resultnum≤N,则给出音乐搜索结果,即Actsystem=offer(songs)。
步骤3计算属性信息熵,判断是否需要查询状态值函数矩阵v,若是,则通过状态转移矩阵选出下一轮的系统动作,否则依据信息熵选出下一轮系统动作。
步骤3 判断是否需要查询状态值函数矩阵的具体逻辑如下:若信息熵大于0 的属性数量为1,说明只有一个属性attr△是有信息量的,因此系统直接依据信息熵给出下一轮的动作request(attr△);若信息熵大于0 的属性数量大于1,则查询计算出来的状态值函数矩阵v选出下一轮的系统动作。
通过状态值函数矩阵v计算下一轮系统动作的算法步骤如下:
步骤1查找状态转移矩阵P中对应当前状态为s的列向量Ps,将状态s的转移概率向量Ps转化为01 向量Ts(转移概率>0 节点的值取1),使用Ts对状态值函数矩阵v进行过滤,得到可能转移的下一个向量s'和对应的状态值。
步骤2下一个状态s'使得v*=v(s')最大,将s与s'进行对比,找出s为0、s'为1 的槽位。若有多个槽位上的值不相同,则一一组合得出新的s',并过滤掉信息熵为0 的槽位,然后进行状态值大小的比较,例如当前状态s=S000000,查找到状态值最大的下一状态s′=S110000,得到第0 位和第1 位上的值不同,且信息熵都大于0,于是组合出新的s′={S100000,S010000},对比v(S100000)和v(S010000)的大小,得知v(S100000)>v(S010000),因此s′=S100000,下一轮的系统动作应为询问第一个槽位song,即Actsystem=request(song);若v(S100000)=v(S010000),则以信息熵的大小来选取系统动作应询问的槽位。
3 实验
3.1 实验设置
本文实验的背景是基于多轮对话的音乐搜索任务,即用户通过与音乐搜索系统进行多轮次的对话从而完成音乐的查询。系统通过生成一个音乐查询问题相关的目标,然后希望能够经过尽量少的对话轮次搜索到目标歌曲。这个音乐搜索场景任务中共包含6 个槽,用于限定对话系统在数据库中的查询范围,分别为歌曲名song、歌手singer、专辑album、作词者lyricwriter、作曲者composer、歌曲标签label。曲库中包含618 319 首歌曲,而不同的槽有不同的取值空间,真实情况下的曲库槽位情况如表5 所示。
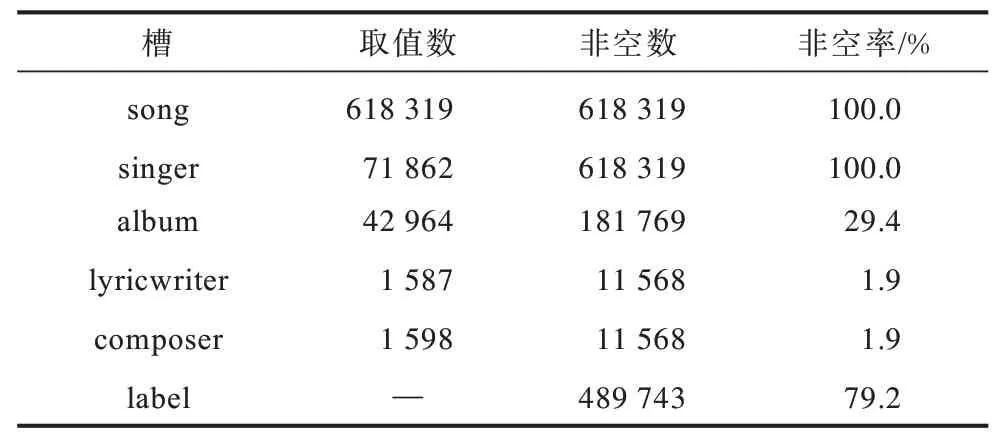
表5 曲库中各个属性的情况描述Table 5 Situation description of each attribute in the music database
系统随机生成1 000 首目标歌曲,并将它们对应的6 个槽取值作为对话中的用户目标。通过搭建系统-用户交互模拟器,构建对话策略的测试环境。首先由模拟器随机初始化用户对话状态,然后通过对话策略模块给出系统的应答策略,模拟器根据给定的用户目标和每一轮次填充指定的槽信息,从而模拟系统-用户对话。
由于展示界面的大小限制,在一个页面中只能为用户展示满足用户目标约束的一定数量的歌曲列表,通常为10 首~20 首歌曲,表示为N。因此,系统根据搜索结果的歌曲数量,来确定下一轮的动作为继续询问request()还是给出歌曲列表offer(),可以通过式(6)进行描述:

为证明本文提出的融合强化学习和属性信息熵的对话策略方法的有效性,实验给出了融合算法与3 种对话策略算法的结果比较,分别是随机选取系统询问目标、基于填槽法的对话策略和基于信息熵的对话策略,3 种对比算法的具体描述如下:
1)随机选取系统询问目标
系统在未知槽中随机选取下一轮询问的槽信息,向用户进行提问。
2)基于填槽法的对话策略
填槽法通过人工制定槽属性优先级规则制定对话策略。用户所知道的歌曲信息一般为大众化属性信息,例如歌曲名song、歌手singer 或专辑album,对于歌曲的作词者lyricwriter、作曲者composer 和歌曲类型label 等属性信息,用户通常不能准确说出。基于此,在系统动作为继续询问request()时,通过为不同的槽制定不同的优先级,来制定系统的应答策略规则。各个音乐属性的优先级顺序为:song >sin ger >album >lyricwriter >composer >label。
填槽法将对话过程看作是填槽的过程,系统按照属性优先级的顺序向用户进行发问,依次填充音乐的属性槽,直至属性信息能够被全部填充或者按照约束查询曲库得到的搜索结果数量小于设定的N,则代表实现对话目标。
3)基于信息熵的对话策略
通过将每一轮已知槽信息转化为知识库查询语句,得到歌曲的搜索结果,计算搜索结果中各个属性的信息熵,选取信息熵最大的槽作为系统下一轮询问的槽。
3.2 评价标准
在评价任务型对话系统中,对话策略模块的有效性方法通常是从任务完成率和任务完成的智能程度的角度出发,因此本文指定的评价标准主要从两个方面来衡量对话策略的有效性和智能性,一是查询目标歌曲的成功率,二是完成任务所需的对话轮次。查询目标歌曲的成功率通过对话结束时给出的歌曲搜索列表来计算,若目标歌曲在搜索列表的TopN中,则记为一次成功的查询,实验中设定N=10,任务完成的成功率计算公式如下:
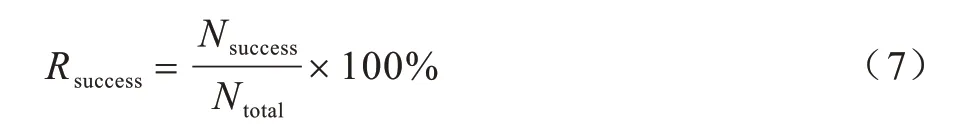
歌曲查询任务完成的成功率越高,说明策略模块的有效性也越高。
同时记录完成歌曲查询任务所需要的对话轮次Numturn,认为所需的对话轮次越少,对话策略的机制效率越高。
3.3 衰减因子γ 取值
本文设定衰减因子γ分别取值为0.0、0.2、0.5、0.8、1.0,并在音乐曲库数据集上进行实验,实验结果如表6 所示。
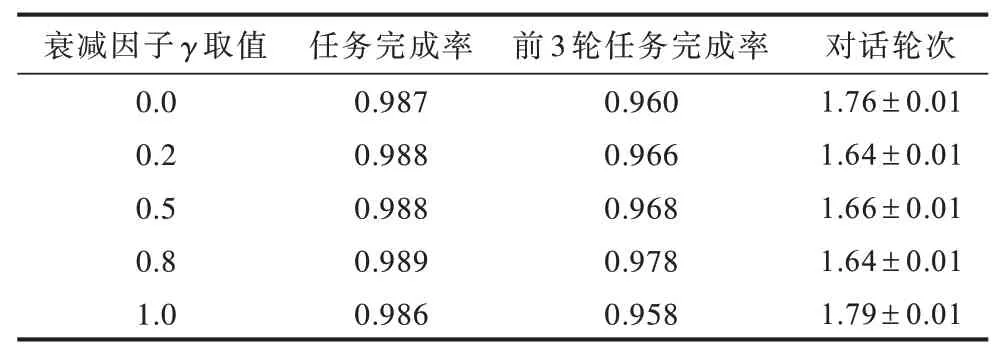
表6 实验评价结果Table 6 Results of experimental evaluation
从表1 的实验结果可以看出,虽然衰减因子γ对于融合强化学习算法的性能具有影响,但无论衰减因子γ取什么值,其结果都好于系统随机引导以及基于规则的对话策略,且与基于信息熵的对话策略的性能接近。当γ取值为0.8 时融合强化学习算法结果最好,为方便比较,本文设定衰减因子γ取值为0.8。
3.4 实验结果与分析
表7 所示为在音乐曲库数据集上使用系统随机引导、基于填槽法的对话策略、基于信息熵的对话策略和融合强化学习与信息熵的对话策略的实验结果。
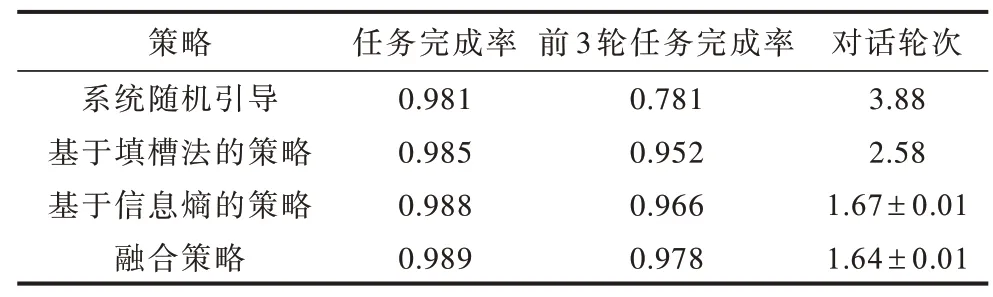
表7 4 种策略的实验评价结果Table 7 Experimental evaluation results of four strategies
从表7 可以看出:
1)系统随机引导与其他3 种改进算法相比,前3 轮任务完成率明显较低,相差20%左右,这是因为在任务中每个槽位的重要程度不同,并且针对不同的搜索目标和不同结果列表的信息量不同,系统直接采用随机的方式进行引导询问,会导致任务完成的效率偏低。
2)与系统随机引导的对话策略相比,基于人工制定属性槽优先级的对话策略能够显著减少完成音乐搜索任务所需的对话轮次(从3.88 次到2.58 次),这是因为人工定义属性槽的优先级,将领域知识通过制定规则的方式添加到算法中,从而提升了对话策略的智能程度。
3)考虑搜索结果属性信息熵的对话策略,在前3 轮任务完成率和对话轮次两个评价标准中均有显著的提升。与基于人工制定槽属性优先级的对话策略算法相比,基于属性信息熵的对话策略方法由于考虑了每次搜索结果的属性信息熵,从而动态地计算了属性槽位的信息含量,提升了对话策略的效率。
4)融合强化学习和属性信息熵的对话策略方法与基于信息熵的对话策略相比,在两项评价指标上有略微的提升,通过个案分析得知,在搜索热门歌手和歌曲时,由于曲库存在同一首歌的多个版本,各个槽位信息无法有效地将歌曲进行完全划分,因此结合基于表格的强化学习辅助进行判断,能够帮助系统做出更有效的决策。
4 结束语
在垂直领域的任务型对话系统中,通常没有针对特定领域的对话数据进行模型训练,从而导致对话策略在真实应用环境下的对话数据面临冷启动的问题。为此,本文提出了适用于知识库搜索型对话系统的融合强化学习和属性信息熵的对话策略,将对话决策过程抽象为一个马尔科夫决策过程,利用强化学习来选择下一步最优对话状态,并引入属性信息熵排除多个状态值函数相同的最优状态的情况。在音乐搜索领域数据集上的实验结果验证了本文方法的有效性。虽然本文方法可以解决对话策略在完全冷启动场景下的问题,但该方法属于离线学习,无法满足对话系统随着应用场景的变化不断调整的需要。因此,构建支持在线学习和优化的策略学习模型,实时获取用户与系统进行交互的对话数据从而对模型进行优化,将是下一步的研究工作。
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01 06:28:50
小学生作文(低年级适用)(2019年5期)2019-07-26 00:45:10
小学生作文(低年级适用)(2018年3期)2018-04-17 00:58:35
读友·少年文学(清雅版)(2018年12期)2018-04-04 05:16:40
电子测试(2017年12期)2017-12-18 06:35:48
少年博览·小学低年级(2017年4期)2017-06-09 16:22:28
雷达学报(2017年6期)2017-03-26 07:52:58
作文评点报·低幼版(2017年7期)2017-03-11 20:49:41
家庭百事通(2016年3期)2016-03-14 08:07:17
山东青年(2016年3期)2016-02-28 14:25:52
