
基于高斯滤波器组混合特征的录音回放攻击检测研究
2021-03-18 08:04陈旭,蒋晔
计算机工程 2021年3期
陈 旭,蒋 晔
(南京财经大学信息工程学院,南京 210023)
0 概述
声纹识别即说话人识别,是根据人说话的声音判定人身份的技术,因其获取成本低、安全系数高及使用便捷而应用于安全、司法、通信等多个领域[1]。但在实际应用中,声纹识别系统容易受到声音模拟[2]、语音合成[3]、声音转换[4]、录音回放(含录音拼接回放)等仿冒语音的攻击,此类攻击极大地影响了声纹识别系统本身的安全性,进而也给采用声纹识别技术进行访问控制的系统带来了安全隐患。录音回放攻击是指攻击者使用高保真录音设备录制合法用户进入认证系统时的语音,或通过其他手段获得用户的语音样本,然后在声纹身份认证系统的拾音器端通过高保真功放回放,从而达到对声纹身份认证系统实施攻击的目的。由于高保真录音设备的普及,合法用户语音极易被偷录,录音回放攻击已成为声纹识别技术中抗仿冒攻击的首要解决问题。
由英国爱丁堡大学、法国国家信息与自动化研究所等组织发起的ASVspoof 是迄今为止对仿冒语音鉴别规模最大、最全面的挑战赛[5]。ASVspoof 2015 是用语音合成、声音转换技术产生数字语音,直接输入系统(不用麦克风)进行逻辑层面的攻击(Logical Access),ASVspoof2017 是使用录音回放的方法,经过麦克风进入系统进行物理层面的攻击(Physical Access)。在实际应用中,语音合成及声音转换技术生成的语音也需要经过重放环节转化为Physical Access。国内外研究学者如NAGAR SHETH 等人[6]用高通滤波器对高频信息进行提取,提取出来的HFCC 参数尽管能提高识别率,但是该参数特征会丢失语音部分特征信息。文献[7-8]提出的常量Q 倒谱特征(Constant Q Cepstral Coefficients,CQCC)替代傅里叶变换增加了低频域的分辨率,而实际上录音回放攻击语音与原始语音相比,由于存在录音和回放这两个额外过程,录音设备和回放设备的频响特性是非均匀的,使得其频谱在低频段和高频段都会不同程度地出现衰减或畸变现象,因此仅仅强调低频段频谱信息是不充分的。文献[9]重点研究了瞬时频率余弦系数特征,以及倒谱特征常数Q 倒谱系数和MEL 频率倒谱系数,执行所有这些功能的组合以获得高精度的欺骗检测。该方法单纯地组合了各个特征系数,特征过于冗余。文献[10]使用Gammatone 滤波器仿真了人耳基底膜的特性,GFCC[11]模拟了人耳的听觉响应,具有较强的噪声鲁棒性。但是该特征在低频段的分辨率要高于高频段,模糊了高频的特征,因而该方法在录音回放攻击中的效果达不到预期结果。
本文在真实语音和录音回放语音差异化研究的基础上,针对如何提高语音频谱高频信息,减少频谱在低频段和高频段不同程度的衰减或畸变现象,提出两种有效的特征参数G-IEFCC 和G-IFCC。为达到更好的检测效果,本文研究基于Fisher 比的特征融合方法。
1 Fisher比混合倒谱特征
1.1 真实语音与录音回放语音的差异化分析
原始语音和录音回放语音在时域波形图中的差异并不明显,本文采用语谱图探究两者在频域中的差别。选取ASVspoof2017 中的一段语音:“Birthday parties have cupcakes and ice cream”。真实语音和录音回放语音语谱图分析如图1 所示,其中,录音设备为Rode smartlav,回放设备为VIFA M10MD-39-08 Speaker。
由图1 对比分析可知,两者的差异主要集中在高频段上(4 000 Hz~8 000 Hz),中低频略有差异且包含一些对于攻击和真实语音之间的干扰信息,且在回放过程中会夹杂着噪声。目前无论LPCC、MFCC,还是CQCC 都采用了强化低频段频谱信息的方法。而高频段集中了真实语音和录音回放语音的主要差异信息,这些特征无法有力刻画两者的个性信息。因此,传统特征参数在录音回放攻击检测实验中表现一般[12]。针对传统方法的不足,本文在特征提取阶段对频率尺度和滤波器组进行改进,使得设计的特征更能有效地区分真实语音和录音回放语音。

图1 真实语音和录音回放语音语谱图分析Fig.1 Analysis of real speech and recording playback speech spectrum
1.2 频率尺度及高斯滤波器分析
传统声纹识别领域中使用MEL 频率尺度提取语音特征。该特征参数较好地表达了语音的频谱包络结构,也一定程度上反映了人类听觉系统的特点。但由于真实语音与录音回放语音在频谱包络结构上的高度相似性,以及录音回放攻击检测需要具有超越人类鉴别能力的水平,因此基于MEL 频率尺度的参数在实验中所表现出的性能一般。而等效矩形带宽(Equivalent Rectangular Bandwidth,ERB)频率尺度对公共场合异常声音鉴别有较强鲁棒性[13]。鉴于以上分析,本文尝试用高斯滤波器组代替传统三角滤波器组,为强化高频段频谱信息,采用ERB 频率尺度代替传统MEL 频率尺度,同时将ERB 尺度转换成逆ERB 尺度,通过该过程提取的特征称之为高斯逆ERB 频率倒谱系数(Gaussian-Inverse ERB Frequency Cepstral Coefficients,G-IEFCC)。为均衡细化高频与低频频谱信息,用线性频率代替传统MEL 频率,通过该过程提取的特征称为高斯线性频率倒谱系数(Gaussian-Linear Frequency Cepstral Coefficients,G-LFCC)。本文采用的3 种频率转换关系如下:
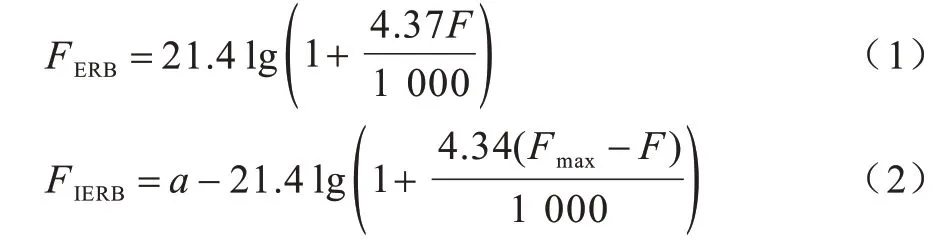
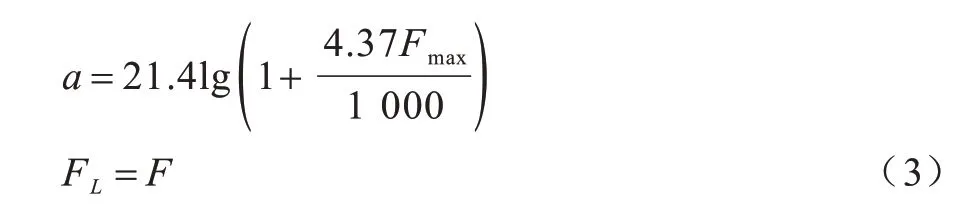
其中,F是实际频率,FERB是ERB 频率,FIERB是逆ERB 频率,FL是线性频率,Fmax是语音信号的最大频率。
传统的特征参数提取主要是基于三角滤波器组,以MFCC 为例,如图2 所示,其中,图2(a)代表传统MFCC 提取采用的滤波器,该滤波器低频段分布密切,强调低频部分,而高频段分布稀疏,提升了低频的差异却忽略了差异明显的高频段。图2(b)代表IMFCC 提取采用的滤波器,相对于图2(a)的逆操作,在弱化低频部分的同时强化了高频部分。图2(c)代表线性倒谱系统采用的滤波器,该率波器呈等带宽分布和高低频段信息平均分布。
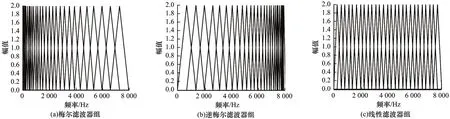
图2 三角滤波器组分析Fig.2 Triangle filter bank analysis
研究发现,三角形状的滤波器下降趋势过于陡快,不够平滑,因此传统的三角滤波器会使相邻子带丢失部分联系,高斯滤波器[14-15]的时频宽积最小,既能减小信号的失真,又可以有效地选频衰减。本文采用高斯滤波器组加强子带联系,以弥补三角滤波器的不足。高斯滤波器组频率响应如下:

其中,at为标准偏差,mt为第t个滤波器的边界点,其标准偏差at公式如下:

其中,n为方差,可由具体实验选取最优值。如图3所示,图3(a)为G-IEFCC 选用的逆高斯滤波器组,图3(b)为G-IFCC 选用的等宽高斯滤波器组。

图3 高斯滤波器组分析Fig.3 Gaussian filter bank analysis
1.3 G-LFCC 和G-IEFCC 的提取
本文参数提取过程如图4 所示。
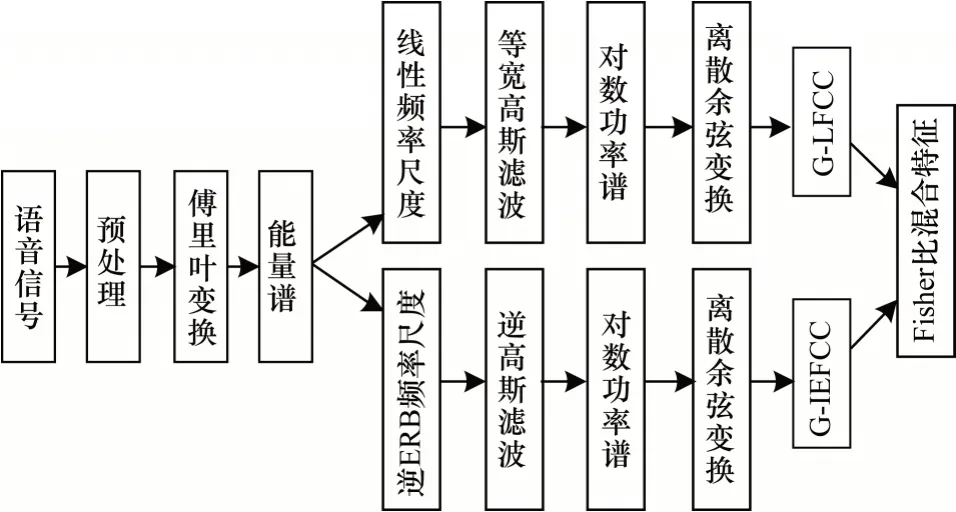
图4 混合参数提取过程示意图Fig.4 Schematic diagram of extraction process of mixed parameters
本文参数提取具体过程如下:
1)预处理
在预处理阶段采用预加重、分帧和加窗3 个步骤。在预处理阶段,将数字语音信号x(n)通过一个高通滤波器,减少尖锐噪声影响。

取帧长n为256 个采样点,帧移为128 个采样点。并加汉明窗减少Jibbs 效应。
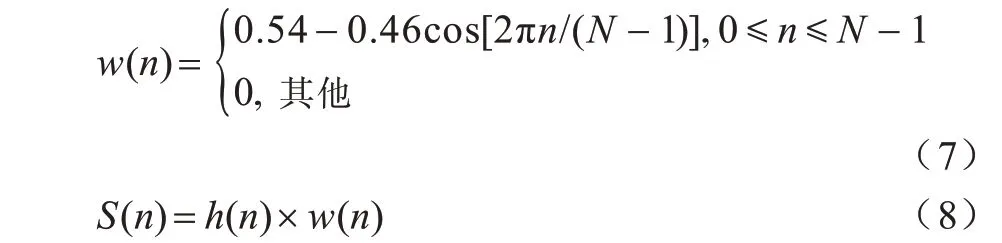
其中,w(n)是窗信号,S(n)是加窗后的信号。
2)傅里叶变换
对经过预处理后的信号S(n)进行快速傅里叶变换得到频谱:

其中,N是傅里叶变换点数,k是频率序号
傅里叶变换后将时域信号转化为频域分量得到频谱,求频谱的平方(|X(k)|2),即为能量谱。
4)频率尺度变换及滤波器设计
G-LFCC 和G-IEFCC 的区别主要体现在频率尺度的变换上,频率尺度的变换使得后续进行高斯滤波时呈现等宽高斯和逆高斯两种形态,其具体算法如下:
(1)设置相关参数,采样频率Fs=16 000,频域范围Fl~Fh(Fl=0,Fh=Fs/2),傅里叶点数N=256,滤波器个数M=27。
(2)由式(3)得出G-LFCC 的线性频域Fl'~Fh',由式(2)得出G-IEFCC 的逆ERB 频域
(3)将以上两个频域分别等分成M+2 个频率值,由式(2)和式(3)的逆变换得出G-LFCC 对应实际频率Fa(i) 和G-IEFCC 对应实际频率Fb(i)(i=1,2,…,M+2)。
(4)计算频率分辨率:
本文的研究对象确定为TF boys这一偶像团体的粉丝群体。TF boys是目前首屈一指国内偶像团体,他们在团体的高热度和广泛的关注度以及粉丝的强大力量方面有着其他组合不可比拟的优势,且其粉丝群体内部的属性构成完善,因此,TF boys的粉丝社群无疑本研究最合适的研究对象。

(5)根据高斯滤波器式(4)、式(5)循环计算每个滤波器数组并组合成最终G-LFCC 的等宽高斯滤波器组Ha(t):

同理,得到G-IEFCC 的逆高斯滤波器组Hb(t):

其中,m=1,2,…,129,t=1,2,…,M。
5)对数功率谱
分别用以上两种滤波器组进行滤波,并对滤波后的能量取对数得到对数功率谱Pa(t)、Pb(t):
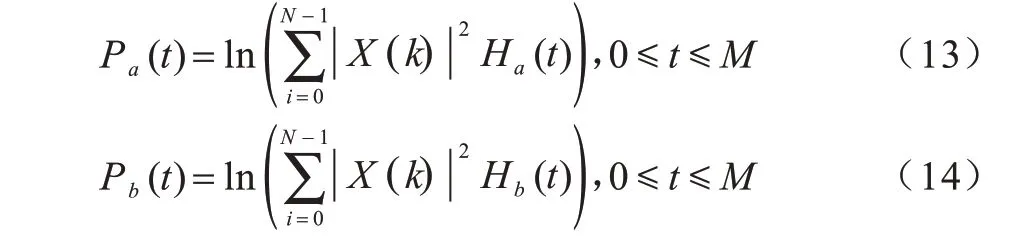
6)离散余弦变换
将所得的对数功率谱进行离散余弦变换得到L阶倒谱系数,分别求出G-LFCC 和G-IEFCC 倒谱系数:
其中,n=1,2,…,L,本文L取13。
1.4 Fisher 比混合特征
在声纹识别中常会提取多维特征,可是在增加特征维数的过程中,各维特征的贡献率不同,所以一般会对特征参数进行特征选择。其中,Fisher 准则就是常用的方法。Puzansky 利用方差分析进行声纹识别研究,提出了有效的Fisher 比[16],而在重放语音攻击检测中尚未发现有人研究,本文探究该方法是否可行。Fisher 比的计算公式如下:

其中,σbetween是类间离散度,在声纹识别中表示说话人第k维参数类间方差之和,σwithin是类内离散度,表示某个说话人第k维参数类内方差和,在重放语音攻击检测中存在真实语音和重放语音两类。说话人样本总数为M,说话人i拥有的语音段数量为ni,说话人i的第k维特征参数均值为所有说话人第k维特征参数均值为μk,说话人i的第j段语音的第k维特征参数为。σbetween和σwithin计算公式如下:
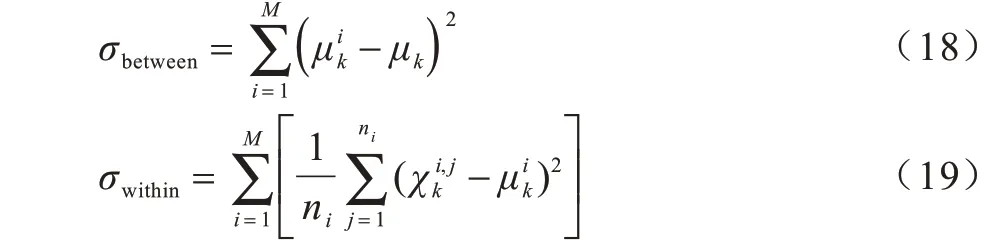
Fisher 比越大,表明该维特征更能表征个性信息。而在重放语音攻击检测中,通过Fisher 比准则,对比值进行降序排列,用贡献率来确定特征维数,基于Fisher 比的特征可去除冗余信息,突出真实语音和回放语音的个性信息。本文计算G-LFCC 和GIEFCC 各维的Fisher 比,然后分别选择Fisher 比较高的6 维特征,组合成最终12 维的融合特征。该融合特征通过G-IEFCC 的提取强化高频段频谱信息,通过G-LFCC 的提取均匀细化低频段和高频段信息,两者结合更大限度地突出了真实语音和回放语音的差别,同时减少回放语音中因不同录音设备、回放设备所产生的差异。
1.5 重放语音检测算法
在训练阶段运用本文方法提取训练集语音的特征参数,分别训练出两个GMM 模型、一个是录音回放语音的GMM 模型A;另一个是真实语音GMM 模型B。在测试过程中将测试语音的特征参数集φ与A和B计算似然比,计算公式如下:

用所得的似然比作为得分判决待测语音跟哪个模型更为接近。而后设定阈值作为最后的分类判断,判决成果采用等错误概率(Equal Error Rate,EER)给出,定义如下:

其中,Pfa(θ)表示在阈值θ处的虚警率,反映被判定为真实语音的样本中,有多少个是回放语音,Pmiss(θ)表示在阈值θ处的漏警率,反映有多少个真实语音被判定为回放语音,当两者相等时错误率为等错误率,Pfa(θ)表示单调递减函数,而Pmiss(θ)则表示单调递增函数,通过调节阈值使得虚警率和漏警率得以调节。根据具体情况选择合适的阈值达到理想状况,比如对于机密安全领域,通过调节阈值使得漏警率较低;而对于日常应用,则可以适当调节阈值在漏警率和虚警率两者间取得一个平衡。
2 实验结果与分析
2.1 数据集
实验语音数据采用ASVspoof2017 数据集[17]。在2017 年,国际语音通信协会(ISCA)组织了ASVspoof 国际挑战赛,主要针对声纹识别中录音回放攻击检测技术进行研究和交流,该数据库包含了训练集和开发集。语料使用RedDots 库[18]里最常用的10 个短语,运用不同录音设备在多种环境下录制,样本采样频率为16 kHz。具体数据集参数如表1所示。

表1 ASVspoof2017 数据集Table 1 ASVspoof2017 dataset
录音回放环境主要涉及到录音设备、回放设备、偷录环境等。在每种回放环境下,同一个说话人录制同一短语多次。本文实验训练集所用大赛数据集中的Train 集,而测试集选择Dev 集。
2.2 高斯滤波器参数分析
高斯滤波器的方差是调节滤波器性能的参数,它关系着高斯滤波器的形成,方差越大滤波器越陡,反之亦然,在说话人识别中方差[19]通常取1.1、1.5、2.0。而在录音回放语音检测领域,尚未有方差取值的分析,因此本文针对G-IFCC 采用的等宽高斯滤波器组和G-IEFCC 采用的逆高斯滤波器组中方差取值进行研究。
实验条件:特征参数维数为13 维,GMM 混合度为512。拓展方差参数选取从1.0 到4.0,以0.5 为间隔的7 个方差,评测标准采用EER,所得结果如表2 所示。
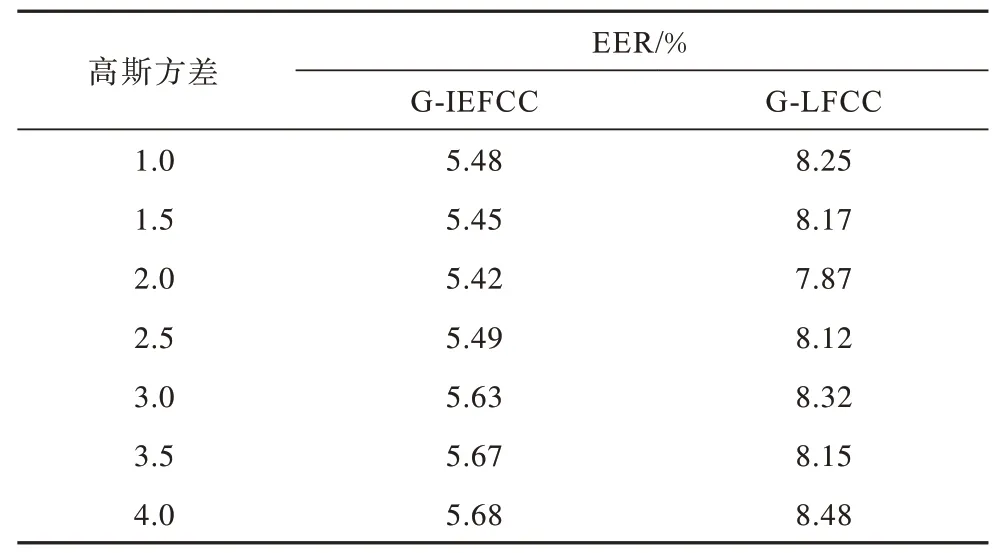
表2 方差取值对检测结果的影响分析Table 2 Analysis of the effect of variance on the test results
从表2 可以看出,当方差选取2.0 时,G-IEFCC和G-LFCC 检测结果EER 较小,当方差大于2.0 时,滤波器越陡则过度加强了子带的联系,致使特征参数里混杂了噪声,而小于2.0 时滤波器较为平坦,子带联系不明显,致使个性信息不突出。因而当方差选取2.0 时,可以得到较好的结果。
2.3 特征参数Fisher 比分析
为选择G-LFCC 和G-IEFCC 中各维Fisher 比贡献度较大所对应的维度,分别计算每一维所对应的Fisher 比,为特征融合奠定基础,图5 为13 维特征每一维所对应的Fisher 比结果。
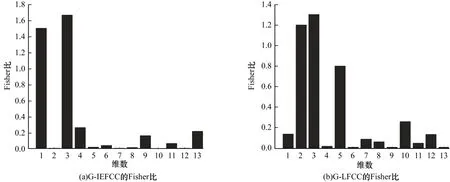
图5 特征参数各维数Fisher 比Fig.5 Fisher ratio of each dimension of characteristic parameters
Fisher 比越大表明蕴含的个性信息越丰富,因此,将G-LFCC 和G-IEFCC 的Fisher 比较高的6 维特征进行融合得到最终Fisher 比混合特征。
2.4 GMM 混合度分析
在检测重放语音过程中训练两个GMM 模型,模型的参数对结果有一定的影响,因此在实验中将GMM 混合度作为变量分别对G-IEFCC 和G-LFCC以及混合特征进行检测,探究GMM 混合度对实验结果的影响。具体实验结果如表3 所示。
从表3 可以看出,基于Fisher 比的混合特征普遍比单一特征G-LFCC 和G-IEFCC 实验效果要好。而在128 混合度下GMM 模型糅合了高频与低频信息的混合特征的EER 最低。实验结果表明,本文提出的混合特征相比单一特征能更有效地检测真实语音和录音回放语音。
2.5 不同特征参数实验效果分析
针对不同特征参数进行录音回放检测实验比较。CQCC 是ASVspoof2017 官方给出的基线特征,该特征由信号经过常量Q 变换(CQT),对其频谱求对数功率谱,再对经过离散变换的倒谱进行归一化处理。该变换的频域采样点随频率呈现指数分布,低频段频率分辨率远远高于高频段频率分辨率,所以CQCC 特征主要包含语音频谱低频段信息,弱化了语音频谱高频段的信息。对于基于高斯均值超矢量(Gaussian Super Vector,GSV)的特征提取则是将含有语音信息的GMM 均值排列成超矢量作为分类器的输入,分类器采用的是最常见的SVM,而GSVSVM[20-21]通常使用在说话人确认领域,把GSV-SVM应用在回放语音攻击检测中也是可行的。此外,本文将未采用高斯滤波器组(采用三角滤波器组)的LFCC 和IMFCC[22]特征和采用Gammatone 滤波器的GFCC 也纳入实验分析,将实验系统耗时作为花费时间代价作为参考。
实验条件为CQCC(90 维)、GFCC(31 维)、GSV(23 040 维)、LFCC 和IMFCC(13 维)和混合特征(12 维),为得到每一种参数的较好结果,前3 项特征采用512GMM 混合度,后3 项采用128GMM 混合度。测试平台配置:CPU(Intel i5-8400@2.80 GHz,双核四线程),16 GB 内存;64 位Win10 教育版系统;matlaR2016b 实验平台,结果如表4 所示。
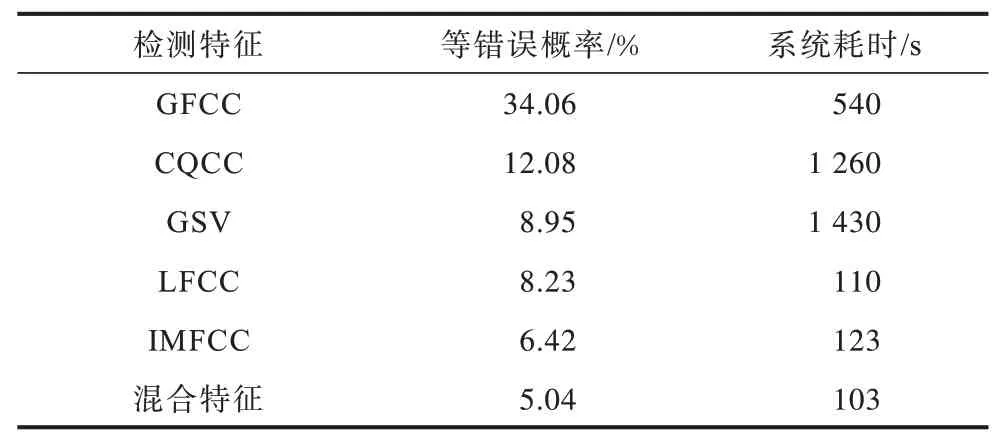
表4 不同特征参数实验对比分析Table 4 Comparative analysis of experiments with different characteristic parameters
从表4 可以看出,GFCC 虽然适合于声纹识别但是在重放语音攻击中效果最差,而GSV 效果比基线特征CQCC 等错误概率低,但因其特征维数较高导致实验中所花费的时间代价要高。采用三角滤波器组的LFCC 和IMFCC 因弱化了语音频谱高频段的信息,也未能达到最好效果。本文所提出的高斯滤波器组下基于Fisher 比的混合特征因强化了语音频谱高频段的信息,同时均匀细化了低频部分,比其他特征效果都好。与基线特征CQCC 相比,EER 降低了58.3%。通过图6 的EER 曲线能够更直观地展现该方法的良好性能。
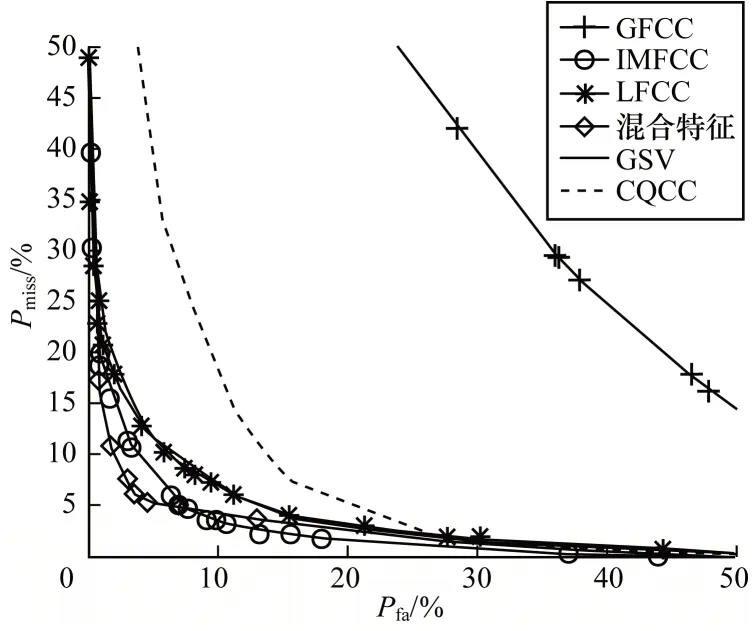
图6 不同特征等错误概率曲线Fig.6 Equal error rate curves of different features
3 结束语
本文在频率尺度和滤波器组上对传统特征参数进行改进。采用逆ERB 频率尺度代替传统MEL 尺度,利用高斯滤波代替传统三角滤波,形成逆高斯滤波器组,即高斯逆ERB 频率倒谱特征(G-IEFCC)。为均匀细化低频和高频信息,降低因录音设备和回放设备不同而造成的频谱信息衰减或畸变现象,运用线性频率尺度和等宽高斯滤波器形成高斯线性频率倒谱系数(G-LFCC)。同时通过Fisher 比准则将改进的两个特征参数融合,最终形成基于Fisher 比的混合特征。实验结果表明,本文提出的混合特征相比其他常用特征参数,在录音回放攻击检测中的检测效果显著。在实际应用中声纹识别系统的攻与防不只是针对虚假语音,其在攻与防中防处于不利地位。为此,提高仿冒语音攻击检测的泛化能力将是下一步的研究方向。
猜你喜欢
中国特种设备安全(2021年5期)2021-11-06
装备制造技术(2021年4期)2021-08-05
阅读(快乐英语中年级)(2021年10期)2021-03-08
阅读(快乐英语中年级)(2020年10期)2020-12-09
阅读(快乐英语中年级)(2020年5期)2020-07-27
小天使·二年级语数英综合(2019年4期)2019-10-06
阅读(快乐英语中年级)(2019年9期)2019-09-10
小学生学习指导(低年级)(2019年6期)2019-07-22
制造技术与机床(2017年11期)2017-12-18
电影故事(2015年16期)2015-07-14
