
基于NCS2 神经计算棒的车辆检测方法
2021-03-18 08:04:14江枭宇李忠兵张军豪
计算机工程 2021年3期
江枭宇,李忠兵,张军豪,彭 娇,文 婷
(西南石油大学电气信息学院,成都 610500)
0 概述
环境感知是无人驾驶汽车路径规划的基础,无人驾驶系统主要通过摄像头采集、实时检测和获取周边车辆信息,对周边环境形成认知模型,从而实现对环境的感知。在车辆检测方面,传统车辆检测方法主要通过梯度直方图(Histogram of Oriented Gradient,HOG)[1]与尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)[2]提取特征信息,并使用支持向量机(Support Vector Machine,SVM)[3]、Adaboost[4]或Gradient Boosting[5]等自适应分类器进行识别,但该方法无法获取高层语义信息。近年来,深度学习技术在车辆检测领域得到广泛应用。与传统车辆检测方法不同,基于深度学习的车辆检测方法不是人为设置特征,而是通过反向传播[6]自适应获取特征,具有较好的高层语义信息描述能力,该方法主要包括One Stage 方法和Two Stage 方法。Two Stage 方法是通过预选框[7-8]确定位置,针对该位置进行识别,例如R-CNN[9]方法、Fast R-CNN[10]方法和Faster R-CNN[7]方法等。One Stage方法是端到端一次性识别出位置与类别,例如YOLO[11-12]方法、SSD[13]方法等。基于深度学习的车辆检测方法具有较好的检测精度,但是由于网络模型复杂、参数量大以及计算周期长导致检测实时性较差,因此其无法应用于实际车辆检测。
为解决上述问题,文献[14]对YOLO 网络进行精简后提出Tiny-Yolo 网络,但是该网络部署在嵌入式设备上参数多,且计算时间较长。对此,文献[15]采用神经计算棒进行加速计算。本文受上述文献的启发,使用深度可分离卷积(Depthwise Separable Convolution,DSC)[16]替换传统车辆检测算法中Tiny-YOLO 网络的标准卷积,将改进的Tiny-YOLO网络部署到配备NCS2 神经计算棒的嵌入式设备上,并对目标检测准确率与实时性进行对比与分析。
1 YOLOV3 原理
在YOLO 系列网络中,YOLOV2 是在YOLOV1的基础上加入1×1 卷积并采用正则化方法防止过拟合,YOLOV3 是对YOLOV2 的改进,主要包括基础网络Darknet53 和全卷积层[17],其中Darknet53 由包含53 个卷积层的残差结构[18]组成,可降低网络训练难度并提高计算效率。
将输入的416 像素×416 像素图像经过Darknet53和全卷积层,得到输出的13 像素×13 像素特征图、26 像素×26 像素特征图以及52 像素×52 像素特征图。每个特征图被分为多个网络域,每个网络域输出尺寸为1×1×(B×(5+C)),其中,1×1 为最后一层卷积的大小,B为每个网络域可预测的边界框(以下称为预测框)数量。预测框包括5+C个属性,分别为每个预测框中心点x轴坐标的偏移值tx、中心点y轴坐标的偏移值ty、中心点宽度的偏移值tw、中心点高度的偏移值th、Objectness 分数以及C类置信度。
由于YOLOV3 网络训练会造成其梯度不稳定,因此在MS COCO 数据集样本中使用K-means 聚类算法[19]生成9 个不同尺度的先验框,预测框基于这9 个先验框进行微调。设Px、Py为特征图中先验框中心点的预测坐标,Pw、Ph分别为特征图中先验框的预测宽度和高度,Gx、Gy为特征图中先验框中心点的真实坐标,Gw、Gh分别为特征图中先验框的真实宽度和高度,其对应偏移值的计算公式如下:


先验框高度与宽度的偏移值由真实值与预测值相除后缩放到对数空间得到。先验框预测值和真实值之间的偏移值可用于修正先验框和预测框的偏移关系,如图1 所示。
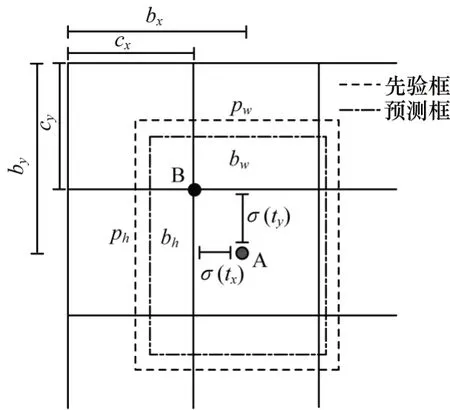
图1 先验框和预测框的偏移关系Fig.1 The offset relationship between prior box and prediction box
图1 中A 点为预测框中心点,B 点为预测中心点,其所在网络域的坐标为(Cx,Cy),该坐标由Px和Py确定。预测框中心点的坐标值bx、by,以及中心点宽度bw、中心点高度bh由tx、ty、tw和th计算得到,相关公式如下:

其中,σ为Sigmoid 函数。网络域尺寸为1×1,使用Sigmoid 函数将tx和ty缩放到0~1 范围内,可有效确保目标中心处于网络域中,防止其过度偏移。由于tw和th使用了对数空间,因此将其通过指数计算得到Gw/Pw或者Gh/Ph后再乘以真实的Pw或Ph可得到真实的宽度与高度。
Objectness 分数的计算公式如下:

其中:CObject为网络域中含有车辆的自信度;PObject为目标是否存在的标记值,当存在目标时,PObject=1,否则PObject=0;IOU 为预测框和原标记框的面积交并比。
在原始YOLOV3 网络中,当B=3 且C=80 时,表示一个网络域需要预测3 个边界框且有80 个类别,通过设计多个先验框可提高先验框预测尺寸匹配的概率。
2 改进的Tiny-YOLO
Tiny-YOLO 网络删除了原始YOLO 网络中加深网络的残差结构,在节省内存的同时加快了计算速度,且输出的特征图中网络域个数只有13×13 和26×26 两个尺寸,该网络中的标准卷积会增大计算量,而MobileNet[20]的深度可分离卷积可大幅减少计算量。
2.1 深度可分离卷积
深度可分离卷积将标准卷积分解为深度卷积和逐点卷积,可减少计算复杂度,适用于嵌入式设备,其分解过程如图2 所示。
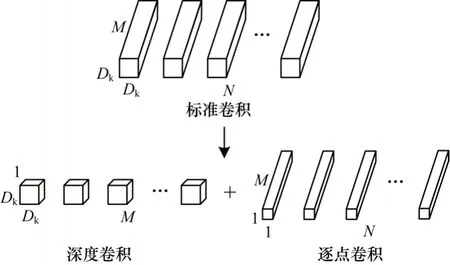
图2 深度可分离卷积分解过程Fig.2 Decomposition procedure of depthwise separable convolution
卷积计算时的输入F∈RDf×Df×M,Df×Df为输入特征图的大小,M为输入特征图的通道数;卷积K∈RDk×Dk×M×N,Dk×Dk为卷积尺寸,M和N分别为卷积的通道数和个数;输出G∈RDg×Dg×N,Dg×Dg为输出特征图的大小,N为输出特征图的通道数。标准卷积的计算公式如下:
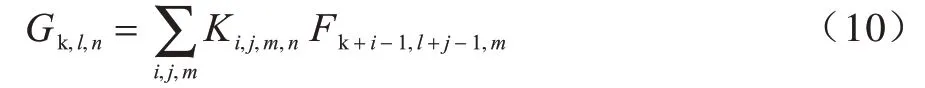
标准卷积的计算量为:

深度卷积是在输入特征图的每个通道上应用单个滤波器进行滤波,其输入F∈RDf×Df×M,卷积,计算公式如下:
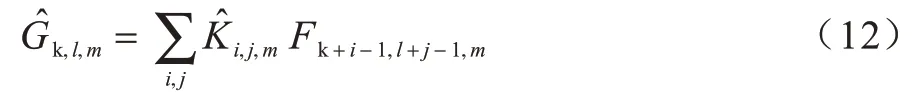
深度卷积的计算量为:

与标准卷积相比,深度卷积能有效进行维度变换,其除了过滤输入通道,还可组合创建新功能。因此,通过1×1 卷积创建线性组合生成新特征,深度可分离卷积计算量为:

深度可分离卷积计算量与标准卷积计算量比值为:
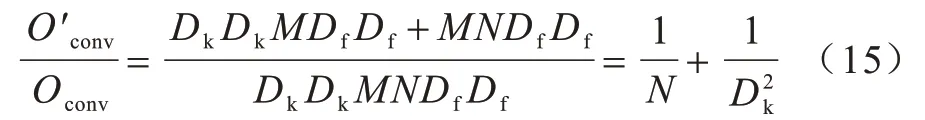
由式(15)可见,当N>1 且Dk不变时,深度可分离卷积计算量较标准卷积计算量明显降低。
2.2 改进的Tiny-YOLO 网络结构
为进一步降低Tiny-YOLO 网络的计算量,本文引入3×3 深度可分离卷积(S Conv)代替原始Tiny-YOLO网络中9个3×3标准卷积(Conv),改进前后的Tiny-YOLO网络结构及3×3 标准卷积的具体信息分别如图3 和表1所示。为防止池化操作导致低级特征信息丢失,本文删除原始Tiny-YOLO 网络中所有的池化层(Maxpool),并采用全卷积层进行连接。
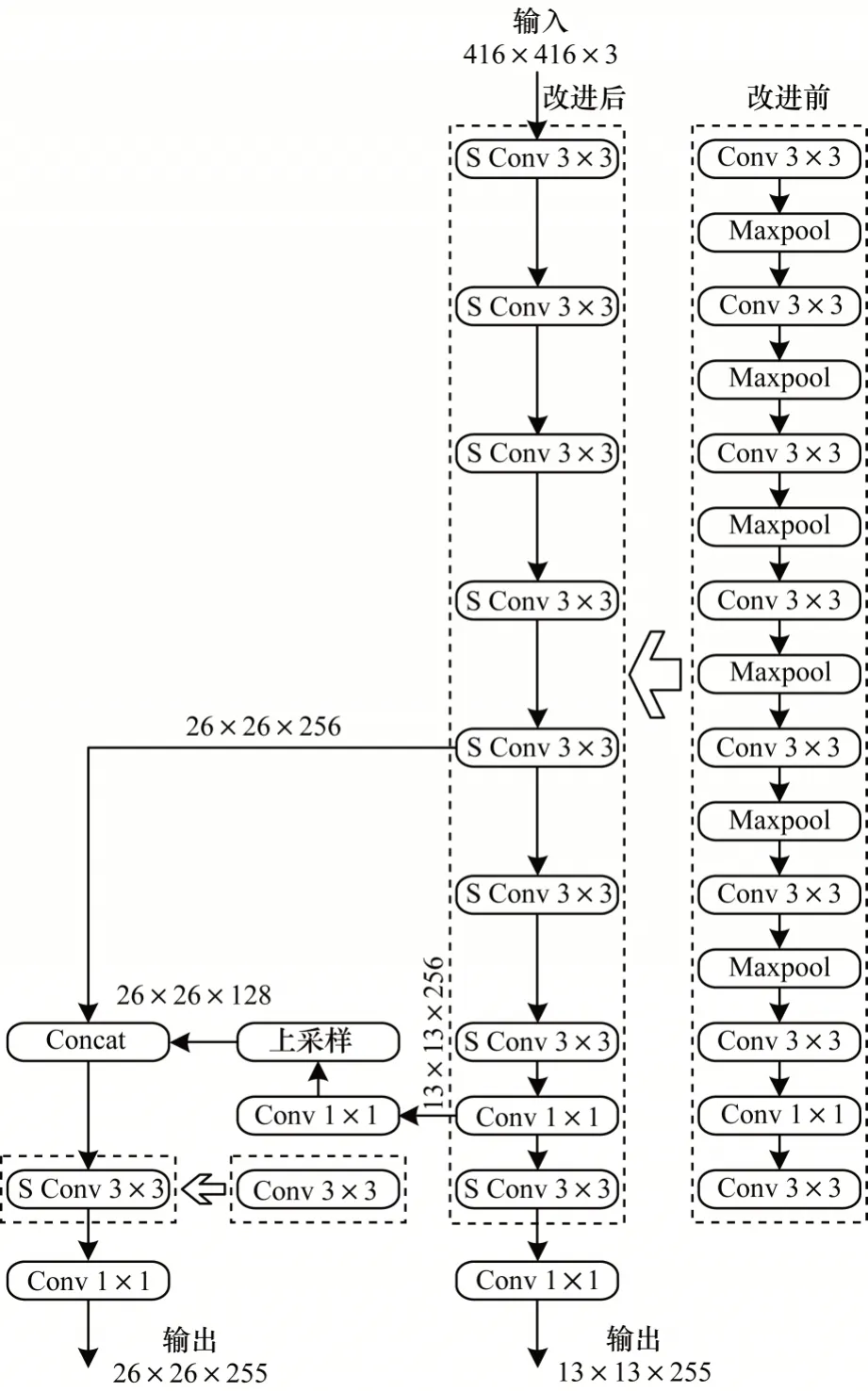
图3 改进前后的Tiny-YOLO 网络结构Fig.3 Structure of the Tiny-YOLO network before and after improvement
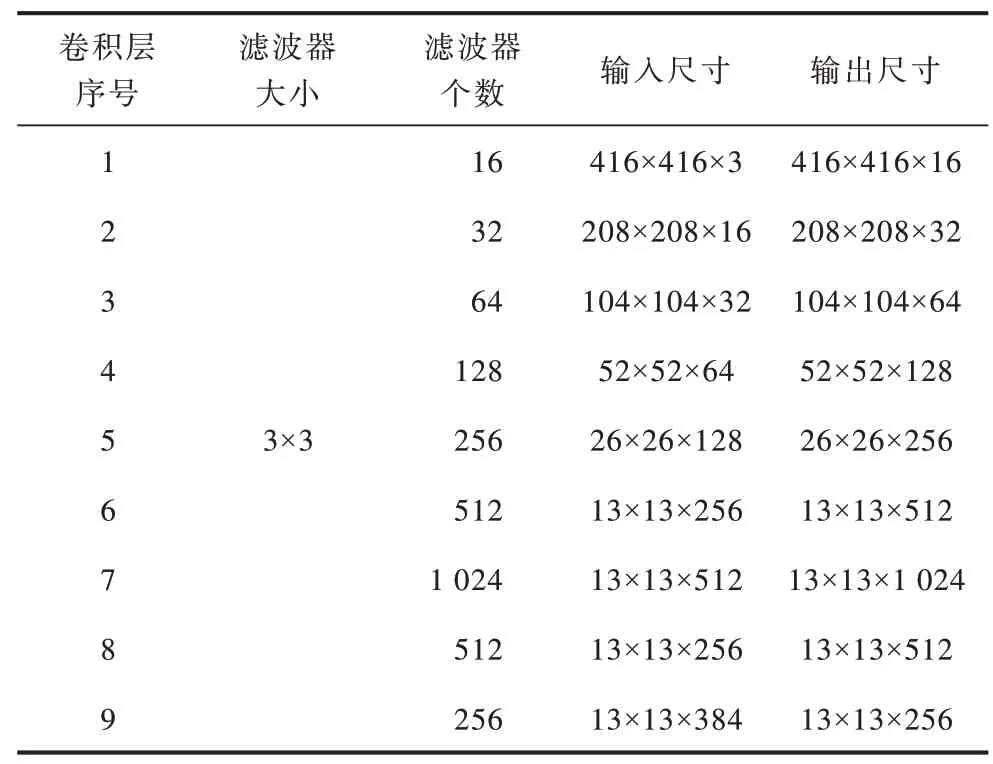
表1 原始Tiny-YOLO 网络中3×3 标准卷积信息Table 1 3 × 3 standard convolution information in original Tiny-YOLO network
3 实验与结果分析
本文采用MS COCO 数据集作为实验数据集,选取车辆尺度不同且角度随机的821 张图像,图像高度大于400 像素。将MS COCO 数据集中的700 张图像作为训练集,将MS COCO 数据集中121 张图像和VOC2007 数据集中895 张图像作为测试集。
本文实验采用Ubuntu 16.04 操作系统和Tensorflow 深度学习框架,下位机设备为树莓派Raspberry 3b+与NCS2 神经计算棒,上位机设备为E5 2680+GTX1066。
3.1 NCS2 神经计算棒的部署
本文在改进Tiny-YOLO 网络的基础上部署NCS2 神经计算棒对网络性能进一步优化,具体流程如图4 所示。改进的Tiny-YOLO 网络的训练和测试图像的输入尺寸与原始Tiny-YOLO 网络一致,通过深度可分离卷积网络提取车辆特征信息,再采用两个不同尺寸的特征图进行预测。在上位机设备上采用Tensorflow 深度学习框架对改进的Tiny-YOLO 网络进行训练,获得Tensorflow 模型后,用Open VINO模型优化器将其转换为NCS2 神经计算棒支持的IR文件,并部署到具有NCS2 神经计算棒的树莓派Raspberry 3b+上。

图4 NCS2 神经计算棒的部署流程Fig.4 Deployment procedure of NCS2 neural computing stick
3.2 网络改进前后的计算量对比
在神经网络的计算中,由于乘法计算次数远大于加法计算次数,而一次乘法的计算时间远大于一次加法的计算时间,因此加法的总计算时间可忽略。本文将一次乘法计算记为一次计算量,则原始Tiny-YOLO 网络中9 层3×3 标准卷积在替换为深度可分离卷积前后各卷积层计算量与总计算量的对比情况如图5 所示。可以看出,标准卷积被深度可分离卷积替换后,各卷积层计算量与总计算量均大幅降低,且总计算量从2.74×109减少到0.39×109,计算量降幅约为86%。
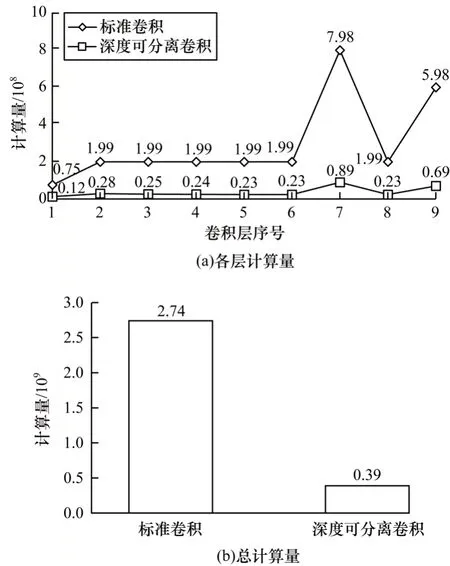
图5 卷积替换前后各卷积层计算量与总计算量的对比Fig.5 Comparison of the calculation amount of each convolution layer and the total calculation amount before and after convolution replacement
3.3 网络改进前后准确率及实时性对比
本文使用平均准确率(Mean Average Precision,MAP)对原始Tiny-YOLO 网络、改进Tiny-YOLO 网络以及NCS2 神经计算棒部署下改进Tiny-YOLO 网络的检测准确率进行评价,并以每秒传输帧数(Frames Per Second,FPS)作为检测实时性的评价指标。MAP 的计算公式为:

其中,P为准确率,R为召回率,P(R)为不同召回率上的平均准确率。
表2 为采用改进Tiny-YOLO 网络的方法(以下称为改进Tiny-YOLO)、原始Tiny-YOLO 网络的方法(以下称为原始Tiny-YOLO)以及NCS2 神经计算棒部署下改进Tiny-YOLO 网络的方法(以下称为改进Tiny-YOLO+NCS2)得到的实验结果。可以看出:改进Tiny-YOLO 在MS COCO 数据集和VOC2007 数据集上的MAP 值比原始Tiny-YOLO 分别提高0.011 2 和0.002 3,改进Tiny-YOLO 的FPS 值为原始Tiny-YOLO的2 倍;改进Tiny-YOLO+NCS2 的MAP 值略低于其他两种方法,但其FPS 值达到12,远高于其他两种方法。由上述结果可知,改进Tiny-YOLO+NCS2 在牺牲少许检测精度的情况下,其实时性较其他两种方法大幅提高,更适合部署在无人驾驶系统中。

表2 3 种算法的实验结果Table 2 Experimental results of three algorithms
3.4 不同场景的效果对比
将改进Tiny-YOLO与原始Tiny-YOLO在VOC2007数据集上的检测效果进行对比,结果如图6 所示,其中每组左、右两侧图像分别由原始Tiny-YOLO 和改进Tiny-YOLO 检测得到。可以看出:当车辆尺寸不同时,原始Tiny-YOLO 较改进Tiny-YOLO 更易丢失小目标信息;当车辆被遮挡时,原始Tiny-YOLO 无法获取被遮挡的车辆信息,改进Tiny-YOLO 可准确检测到被遮挡的车辆信息;在恶劣环境与夜间环境下,原始Tiny-YOLO较改进Tiny-YOLO 易受环境和光线干扰。上述结果表明,改进Tiny-YOLO 的车辆检测效果要优于原始Tiny-YOLO。

图6 2 种方法在不同场景下的检测效果对比Fig.6 Comparison of detection effect of two methods in different scenes
4 结束语
本文提出一种结合改进Tiny-YOLO 网络与NCS2 神经计算棒的车辆检测方法。采用深度可分离卷积代替原始Tiny-YOLO 网络标准卷积,使用NCS2 神经计算棒为低性能嵌入式设备提供深度学习加速功能。实验结果表明,采用该方法检测每秒传输帧数达到12,实时性较原始Tiny-YOLO 网络大幅提高。后续将对改进Tiny-YOLO 网络进行量化压缩提高计算速度,以应用于STM32 等常用嵌入式设备。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电脑报(2020年12期)2020-06-30 19:56:42
成都信息工程大学学报(2019年3期)2019-09-25 08:31:14
电脑报(2019年4期)2019-09-10 07:22:44
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
自动化学报(2017年5期)2017-05-14 06:20:44
少儿美术·书法版(2016年1期)2016-02-06 00:59:39
探测与控制学报(2015年4期)2015-12-15 15:00:56
大众摄影(2015年9期)2015-09-06 17:05:41
