
结合自注意力的BiLSTM-CRF的电子病历命名实体识别
2021-03-16 13:55曾青霞熊旺平杜建强郭荣传
计算机应用与软件 2021年3期
曾青霞 熊旺平 杜建强 聂 斌 郭荣传
1(江西中医药大学岐黄国医书院 江西 南昌 330004)
2(江西中医药大学计算机学院 江西 南昌 330004)
0 引 言
命名实体识别(Named Entity Recongition,NER)是自然语言处理(Natural Language Processing,NLP)任务中的重要步骤之一,其主要目的是识别给定文本中的命名实体。NER还可用于处理很多下游NLP任务,例如关系提取、事件提取和问题问答。电子病历是医生对病人的个人信息、病因、病机等就诊过程中产生的信息的记录,包含大量的医疗就诊信息以及患者的个人信息[1]。有关电子病历中的命名实体主要有检查、体征、治疗和疾病等医学专有名词及相关的修饰词。例如某份病历中的“主因咳嗽、少痰1个月、抽搐1次,肺炎”,其中:“咳嗽”“少痰”“抽搐”为体征,“肺炎”为疾病[2]。电子病历命名实体识别就是对这类词语进行识别。
电子病历文本的命名实体识别研究不同于通用领域的命名实体识别研究,两者文本存在着较大的差异。通用领域的文本语料有着严格的书写规范和严谨的命名方式,而电子病历实体种类繁多,长短不一,书写不规范,且不断有新词出现[3]。具体表现如下:1) 部分句子语法成分不完整(如“多于活动中起病”“双侧瞳孔等大同圆”),这种情况需要结合整句文本来推测出当前的缺失部分。2) 包含大量的专业性术语和习惯用语(如“脑栓塞”“病理反射”“伴”“尚可”)。3) 包含嵌套实体,即多个实体嵌套在一起,一个实体实例化另外一个实体(如“脑萎缩”“右侧共济运动查体差”)。4) 较长句子中的相隔较远位置的实体存在依赖关系(如“无恶心、呕吐、伴腰痛、伴双下肢乏力”,其中:“恶心”属于症状,和症状“呕吐”位置距离较近,可以影响“呕吐”的标记判断,但是和“呕吐”相隔距离较远的症状“乏力”则没有受影响,而只能受到身体部位“双下肢”的影响,同时“双下肢”只能影响到“乏力”的标记判断,而不能影响到其他症状的标记判断)。
近年来,通用领域的命名实体识别研究方法被陆续提出,主要包括浅层机器学习和深层神经网络方法。浅层机器学习主要包括隐马尔可夫模型[4]、支持向量机和条件随机场(Conditional Random Field,CRF)[5]等。以上方法需要通过人工的方式提取有效的语法特征,然后设定特征模板进行实体识别,因此特征模板的选择直接影响实体识别的结果。许源等[6]将CRF与RUTA规则结合,通过调整规则来提高CRF在命名实体识别中的性能;邱泉清等[7]在建立知识库、选取合适的特征模板的基础上,采用CRF进行命名实体识别并取得了良好的效果。有关使用深度神经网络进行NER的研究中,张海楠等[8]采用深度学习框架,通过在字向量中加入词特征,在一定程度上缓解了分词错误和出现未登录词所带来的影响,通过引入词性信息来提高实体识别的准确率;为了获取更多的上下文语义信息,Li等[9]使用双向长短期记忆网络(Bi-directional LSTM,BiLSTM),分别将文本编码并从正向和反向的两个方向作为输入,进行连接操作后送入中间层,该方法在通用领域数据集上取得了良好的效果;李丽双等[10]利用卷积神经网络得到字向量和词向量,将两者结合作为BiLSTM模型的输入,并在生物语料上达到了目前最好的效果。尽管这些方法在NER任务上取得了较大的进步,但还是无法适应电子病历的命名实体识别。在预测实体类型时,以上大多数模型难以处理长距离依赖关系,尤其对于长文本,其丢失的关键信息就越多。虽然BiLSTM在一定程度上可以缓解长距离依赖的问题,但是不能将任意两个字符进行连接,从而获取全局信息。因此,如何更好地捕获整个句子的全局依赖性是提高命名实体识别准确率的关键所在。
为了更好地获取实体之间的长距离依赖关系,本文提出了一种结合自注意力的BiLSTM+CRF的方法(SelfAtt-BiLSTM-CRF),通过在原有的模型基础上引入自注意力机制,捕捉整个句子的全局依赖性并学习句子的内部结构特征。在CCKS2018的电子病历数据集和CoNLL2003数据集上评估模型。实验结果表明,在不考虑使用特征模板的条件下,本文模型优于现有的深度神经网络模型,准确率分别为91.01%和89.2%。
1 模型设计
1.1 整体框架
图1为本文的SelfAtt-BiLSTM-CRF模型框架。本文模型总共由四部分组成,分别为Embedding模块、BiLSTM模块、SelfAttention模块和CRF模块。首先采用预训练好的字向量作为Embedding输入;然后经过BiLSTM进行编码,将编码完的结果拼接送入到Self-Attention层获取任意词的长程依赖关系;最后使用CRF模块进行解码,将隐含层的输出解码成出现概率最大的标记序列。
1.2 Embedding模块
Embedding模块主要是负责将输入窗口的字进行字向量映射,也就是将离散字符映射到分布式表示中。首先将已标注好的语料进行简单的预处理(去除多余的字符),然后采用Word2vec模型预训练好词向量,即嵌入矩阵。建立字典,即语料的词汇表,且字典中的每个字都能通过嵌入矩阵表示成一个固定长度为d的一维向量。对于电子病历数据集给定的句子x={c1,c2,…,cn},通过在预训练好的嵌入矩阵中查找每个字ci对应的字向量,将给定的句子逐字映射并进行纵向拼接,形成一个n×d的向量矩阵,作为模型的输入。
1.3 BiLSTM模块
长短期记忆网络(Long Short-Term Memory,LSTM)[11]是一种时间循环神经网络(Recurrent Neural Network,RNN),是为了解决一般的RNN存在的长期依赖问题而专门设计出来的,其通过引入门结构和存储单元来解决RNN中的梯度消失和梯度爆炸问题。LSTM网络的主要结构可以表示为:
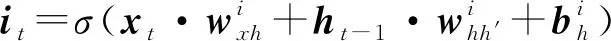
(1)
式中:σ是激活函数sigmoid;⊗是点乘运算;tanh是正切激活函数;it、ft、ot分别表示在t时刻的输入门、遗忘门、输出门;ct表示t时刻的细胞状态;ht表示t时刻的隐藏状态。
为了能够有效利用上下文信息,采用双向LSTM结构,对每条文本分别采用正向和反向输入,通过计算得到两个不同的中间层表示,然后将两个向量进行拼接并作为隐含层的输出:
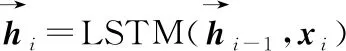
(2)
1.4 Self-attention模块
Attention机制就是把注意力放在所关注的点上,忽略其他不那么相关的因素,最初起源于图像领域。2014年,Mnih等[12]将Attention机制用于循环神经网络模型进行图像分类任务。随后,Bahdanau等[13]将其用于机器翻译任务上并取得了较为显著的效果,这也是第一个将注意力机制应用到自然语言处理领域中的例子。2017年,Vaswani等[14]使用了Self-attention机制来学习文本表示,Self-attention机制可以用来学习句子中任意两个字符之间的依赖关系并捕捉内部结构信息,其计算过程如下:
假设BiLSTM的输出为H={h1,h2,…,hn}。对应的scaled dot attention可以描述为:
(3)
式中:Q、K和V分别是查询矩阵、键矩阵和值矩阵;d为H的维度;Q=K=V=H。
Multi-head attention是在Self-attention的基础上加以完善的。它扩展了模型专注于不同位置的能力,给出了自注意力层的多个“表示子空间”。在“多头”注意力机制下,为每个头保持独立的查询、键、值权重矩阵,从而产生不同的查询、键、值矩阵。然后将多个头并行执行scaled dot attention,最后将这些attention的结果拼接起来,得到一个融合所有注意力头信息的矩阵。Multi-head attention描述如下:
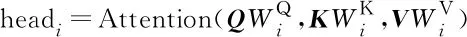
(4)

1.5 CRF模块
CRF能够通过考虑标签之间的依赖关系获得全局最优的标记序列。给定一个预测序列y={y1,y2,…,yn},CRF标记过程可形式化如下:
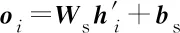
(5)
式中:Ws和bs是可训练的参数;Oi,yi表示第i个单词标记为yi个标签的概率,矩阵T是转移矩阵,例如Tij表示由标签i转移到标签j的概率。在原语句S的条件下产生标记序列y的概率为:
(6)
在训练过程中标记序列的似然函数为:
(7)
式中:Yx表示所有可能的标记集合,包括不符合BIOES规则的标记序列。预测时,由式(8)输出整体概率最大的一组序列。
(8)
2 实 验
为了验证本文模型的有效性和泛化性,分别选用了CCKS2018的电子病历纯文本文档和CoNLL2003语料进行实验。所有实验都在采用相同的预训练词向量和参数水平的基础上进行。
2.1 实验数据
CCKS2018的电子病历和CoNLL2003语料详细信息如表1所示。

表1 语料信息
CCKS2018电子病历语料中的目标序列集合包括:非实体部分、治疗方式、身体部位、疾病症状、医学检查、疾病实体。CoNLL2003语料中的目标序列集合包括LOC(地名)、ORG(组织)、PER(人民)、MISC(其他)。为了更清楚地标注出待识别的命名实体,上述两个数据集都是采用了BIO三元标记实体,其中:B代表实体的开头;I代表实体除中间部分;O代表其他,即非实体部分。
2.2 实验结果分析
本文模型在CCK2018电子病历语料上的命名实体识别的结果如表2所示,下面通过对比实验结果来分析各个模块在模型中起到的作用。
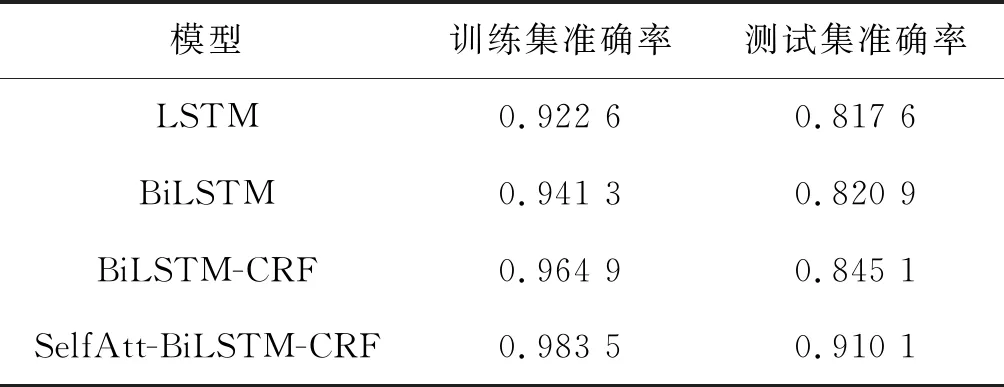
表2 CCKS2018语料模型结果
1) BiLSTM模块。为说明该模块的有效性,实验对比了LSTM和BiLSTM两个模块的实验结果。实验结果显示,BiLSTM模型在电子病历语料上训练集和测试集的准确率分别为0.941 3和0.820 9,比LSTM模型在训练集和测试集上的准确率分别高出了1.87和0.33个百分点。无论是在训练集还是在测试集上的准确率BiLSTM模型都要优于LSTM,主要因为BiLSTM相对于LSTM更加充分地运用了上下文信息。
2) CRF模块。为证明该模块的有效性,实验对比了双向长短记忆网络模块以及在该模块的基础上添加CRF模块的两组实验结果。结果显示,BiLSTM-CRF模型在电子病历语料上的训练集和测试集的准确率分别为0.964 9和0.845 1,比BiLSTM模型在训练集和测试集上的准确率分别高出了2.36和2.42个百分点。BiLSTM-CRF无论是在训练集还是在测试集上的准确率都要优于BiLSTM,主要是因为CRF充分考虑到各个标签属性之间的关系,对隐含层的输出进行解码后,通过动态规划的思想获得全局最优输出序列标签,提高了实体识别的性能。
3) Self-attention模块。为了验证Self-attention模块的有效性,进行了SelfAtt-BiLSTM-CRF和BiLSTM-CRF的对比实验。结果显示,SelfAtt-BiLSTM-CRF模型在电子病历语料上的训练集和测试集的准确率分别为0.983 5和0.910 1,比BiLSTM-CRF模型在训练集和测试集上的准确率分别高出了1.86和6.50个百分点。主要是因为Self-attention能够捉整个句子的全局依赖性并学习句子的内部结构特征,而测试集准确率提高的幅度大于训练集是因为训练集准确率的基数已经很高了。
为验证本文模型的泛化能力,表3给出了在CoNLL2003语料上的对比实验结果。
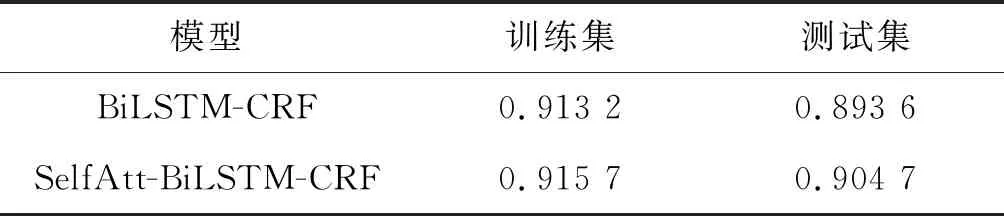
表3 CoNLL2003语料模型结果
可以看出,本文模型在CoNLL2003语料上的训练集和测试集的准确率分别为0.915 7和0.904 7,比BiLSTM-CRF模型在训练集和测试集上的准确率分别高出了0.25和1.11个百分点。由表3可得:(1) 本文模型确实具有泛化能力,在其他数据集上也具有良好的表现。(2) 模型在CoNLL2003语料上训练集和测试集的准确率均得到提高,证明在公共数据集上,引入自注意力机制的模型确实优于基线模型BiLSTM-CRF,且在准确率较低的情况下,准确率提高的幅度会更大。
3 结 语
本文针对电子病历命名实体识别任务,提出了结合自注意力机制的BiLSTM-CRF的网络模型,通过引入自注意力机制弥补BiLSTM-CRF模型不能获取两个实体之间的长距离依赖关系的缺陷;采用获取上下文信息的双向LSTM作为神经网络隐含层,在一定程度上缓解了长文本输入的依赖问题以及梯度爆炸问题;为了获取更加准确的识别结果,通过CRF对SelfAtt-BiLSTM网络的输出进行解码,获得最优标记序列。通过在CCKS2018的电子病历纯文本文档和CoNLL2003语料上进行实验比较,证明了本文提出的引入自注意力机制的模型性能优于现有的模型。
猜你喜欢
西北大学学报(自然科学版)(2022年5期)2022-11-13
科学家(2022年3期)2022-04-11
现代计算机(2021年33期)2022-01-21
计算机研究与发展(2022年1期)2022-01-19
作文评点报·低幼版(2020年25期)2020-07-23
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
中国社区医师(2016年8期)2016-12-20
文苑(2015年9期)2015-09-10
新课程学习·中(2013年3期)2013-06-14
