
用于苹果叶病分类的领域自适应方法研究*
2021-03-12 04:12:28吴蔚
智慧农业导刊 2021年12期
吴 蔚
(泰山学院 信息科学技术学院,山东 泰安 271000)
苹果是世界上重要的水果作物之一,具有重要的经济和营养价值。苹果叶部的外观和生长状态可以为苹果生长态势提供预判依据。然而苹果叶部时常遭受病虫害侵袭,及时识别叶病种类并采取针对性措施进行叶病防治,对于保证苹果增量增产具有十分重要的经济价值和现实意义。从20世纪80年代开始,计算机视觉技术在农作物病害识别领域得到了广泛的研究和发展。近十几年来,随着大数据技术和硬件设备的不断提升,深度学习技术在视觉识别领域取得了瞩目的成就,并被迅速应用到植物叶病识别领域。比如Liu等[1]使用基于GoogLeNet和AlexNet的深度网络模型进行苹果叶病诊断,达到了97.62%的识别准确率。宋晨勇[2]等以苹果作为研究对象,提出了一种基于深度学习的GoogLeNet改进模型,在提高苹果病害识别准确率的同时,也降低了模型训练收敛时间,实现了苹果病害的实时检测。
深度学习方法通过构建深度神经网络进行模型训练,伴随着大量的调参任务。为了提高神经网络模型的泛化能力,避免模型训练过程的过拟合,需要输入大量带标签的数据样本进行学习。然而在实际应用中,数据样本的获取可能存在环境的变化,比如苹果叶部图像可能在不同的光照、不同的拍摄设备以及不同的拍摄角度下获取。环境的变化往往导致获取的图像有着不同的数据分布。对某种数据分布的样本识别效果良好的网络模型,用于其他数据分布的数据识别时准确率可能会严重降低。为了解决该问题,领域自适应方法应运而生,该方法是一种迁移学习方法,目的是将在源域上学到的分类识别能力迁移到目标域上。领域自适应方法根据数据分布的不同将训练数据集分为带标签的源域和带少量或不带标签的目标域。领域自适应的思想就是将不同领域数据集映射到同一个特征空间,使其特征分布尽可能相近,从而可以将源域数据集的识别能力迁移到目标域数据集上。
基于领域对抗的神经网络DANN[3]被提出之后,基于对抗的思想成为实现领域对齐的主要方法之一。比如chen等[4]在图像级别和实例级别两个层面解决领域偏移问题,实现了跨域物体检测,其中所使用的域分类器便是采用对抗训练方式进行。Hsu[5]等通过构建过渡领域实现源域图片向目标域的转换,采用对抗训练思想在特征层面实现源域和目标域对齐。本研究针对样本获取时环境变化导致的数据分布差异问题,提出一种基于领域自适应的苹果叶病种类识别方法,采用对抗训练思想进行领域对齐,避免了网络模型的重新训练,实现了较好的苹果叶病种类跨域识别效果。
1 相关理论
1.1 卷积神经网络
卷积神经网络(Convolutional neural networks,CNN)的应用是深度学习在计算机视觉识别领域取得重要进展的关键因素之一。与传统机器学习方法不同,CNN不需要进行手工特征提取,而是能够对输入图像实现端到端的自动特征提取。典型的CNN结构主要由卷积层、池化层和全连接层构成。
卷积层是CNN的重要结构之一,它通过卷积核对输入特征进行卷积运算,从而实现特征的提取。卷积层的模型参数分成卷积核部分和偏差值部分。多个卷积层之间可以通过并行或串行连接设计出不同结构和复杂程度的卷积网络。第i层卷积网络的特征输出yi可用公式表示为:
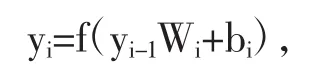
其中Wi表示第i层卷积核的权重参数;bi表示偏差值参数;yi-1表示卷积层的特征输入(其中y0表示网络输入端原始图像);f表示激活函数。
池化层的主要作用是强化卷积层提取特征的空间不变性,减轻对空间位置的过度依赖,从而使得同一物体即使存在位置变化也可以被网络模型很好地识别出来。常用的池化方法有最大池化法和平均池化法,分别计算池化窗口内的最大值和平均值,从而实现对特征的下采样过程。第s个池化层的第j块池化区域的特征输出可用公式表示为:
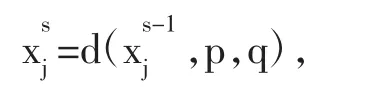
经过一系列的卷积和池化操作之后,通常连接一个或多个全连接层进行图像分类任务。最后的输出层通常再经过Softmax函数将输出结果变为值为正且和为1的概率分布。第j个输出结果Oj可表示为:
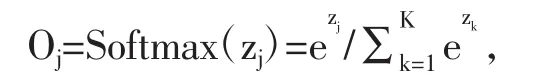
其中j∈{1,…,K},K为最后一个连接层的输出个数;z代表最后一个连接层的输出向量。
1.2 领域自适应
传统的深度学习模型主要针对相同数据分布的训练样本进行训练,并应用于相同分布的测试样本上。当训练样本和测试样本存在不同数据分布时,基于某一种数据分布学习到的模型通常无法很好适应这种数据分布差异,在具体的分类识别任务中表现出较差的泛化性。领域自适应就是用来解决这种数据分布差异问题的方法。它将分布不同的数据分为源域和目标域,通过不同的方式实现源域和目标域的数据对齐,从而将从源域数据学到的分类识别能力迁移到目标域上。所以,领域自适应方法本质是一种迁移学习方法。
2 研究方法
2.1 数据集
用于本研究的苹果叶病图片数据来源于AI-Challenger-Plant-Disease-Recognition(https://challenger.ai/),共包含健康型、一般黑星病型、严重黑星病型、灰斑病型、一般雪松锈病型、严重雪松锈病型6种类型。对每种叶病类型进行数据增广操作以扩充数据量,主要包括随机裁剪、随机缩放、随机旋转等操作。扩充后的数据集共8169张图片,针对每种类别随机选取70%数据作为训练集,30%数据作为测试集。训练集中每个类别按照4:1的比例划分源域数据和目标域数据。为了模拟源域和目标域不同的数据分布,针对训练集中的目标域数据和测试集数据原始图片进行增加亮度操作[6]。所有图片被处理为224×224的固定分辨率。
2.2 领域自适应方法
本研究中源域数据集包含大量有标签数据,目标域数据集包含大量无标签数据。假设苹果叶病训练集中源域图片XS的数据量为ns,所属类别数为K,则源域数据可表示为,其中 xs∈XS,ys∈YS={1,2,…,K}。目标域图片Xt的数据量为nt,则目标域数据可表示为,其中 xt∈Xt。Xs与 Xt中数据相似但分布不同,构成跨域数据集,且Xt中数据标签Yt与Ys相同。领域自适应的目的是通过降低源域和目标域中的数据分布差异,使得具备对源域数据分类识别能力的网络模型能够对目标域数据进行分类预测。
本研究中基于领域自适应的苹果叶病分类网络模型如图1所示,主要包含三个模块:特征提取模块G,叶病分类模块C和领域分类模块D。其中特征提取模块的功能是提取特征用于叶病分类识别,同时混淆源域和目标域的特征分布;叶病分类模块的功能是利用提取的特征对叶病种类进行识别;领域分类模块的功能是识别传入的特征来自源域还是目标域。可以看出,通过特征提取模块得到的特征同时作为其他两个模块的输入。
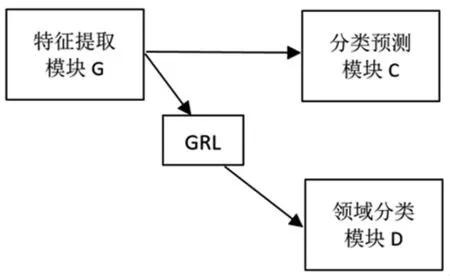
图1 基于领域自适应的神经网络模型
为了对模型进行训练,需要输入源域图片流经特征提取模块后进入叶病分类模块进行预测,得到的结果与真实标签通过交叉熵损失函数计算出分类损失Ly,并进行反向传播更新该网络分支的参数。另外,需要输入源域图片和目标域图片,流经特征提取模块后进入领域分类模块进行领域预测,该分支的领域预测损失Ld可表示为:
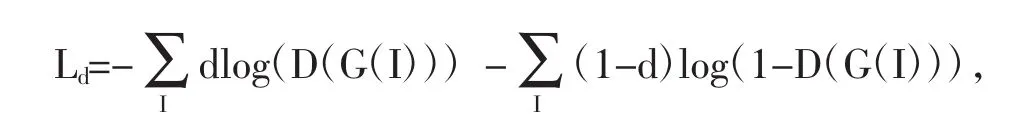
其中I表示输入的源域和目标域图片,d∈{0,1},且当输入图片来自源域时取值0,来自目标域时取值1。领域分类模块的训练目标是使领域分类器更加准确,而网络提取模块的训练目标是提取源域和目标域中共性的特征,使得领域分类器无法辨别。因此,该分支的网络训练是一种典型的对抗思想,其训练目标可表示为maxGminDLd。在具体实施时,特征提取模块和领域对抗模块之间通过添加梯度反转层(Gradient Reversal Layer,GRL)[7],实现对抗训练的效果。汇总以上两条分支的损失函数,便构成了网络模型的最终损失Ltotal,表示为:
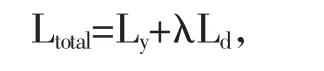
其中λ是用来平衡两条网络分支的超参数。训练阶段结束后,使用测试集数据进行苹果叶病分类预测。此时需要移除模型中的领域分类模块,只保留特征提取模块和叶病分类模块。
3 实验
为了验证本研究算法中领域自适应方法的有效性,与传统神经网络模型方法进行了实验对比,两者的特征提取模块和叶病分类模块均使用经过预训练的GoogLeNet神经网络架构。领域分类模块由3个全连接层构成,每一层的神经元个数分别为1024、512和1。实验对比结果如表1所示。可以看出,在只使用源域数据训练的传统神经网络模型进行跨域叶病种类识别的平均准确率只有37.6%,说明经过图片亮度处理后的目标域图片与源域图片存在较大数据分布差异,识别准确率较低。而经过领域自适应训练的神经网络,能够缩小这种数据分布差异,使得对测试集样本的识别准确率提高到82.3%。实验结果充分说明了在苹果叶病跨域数据集上使用领域自适应算法的必要性,可以带来较大的准确率提升。

表1 基于不同网络模型的苹果叶病分类准确率对比
4 结论
本文基于领域自适应方法进行苹果叶病跨域样本上的分类识别研究,首先使用源域数据训练苹果叶病分类器,然后通过网络对抗训练对齐不同领域之间的数据分布,实现了跨域样本上较好的叶病分类识别效果。实验结果验证了领域自适应方法在苹果叶病跨域识别上的有效性。未来的研究中将在农业领域跨域识别问题上进行更加有益的探索。
猜你喜欢
计算机技术与发展(2024年3期)2024-03-25 02:10:02
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
数码设计(2020年16期)2020-12-08 02:12:05
计算机技术与发展(2020年11期)2020-12-04 07:50:46
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电子技术与软件工程(2016年8期)2016-07-10 08:07:53
中兴通讯技术(2016年2期)2016-03-24 00:14:53
电子与信息学报(2015年12期)2015-08-17 11:14:42
北方经贸(2014年8期)2014-09-21 20:32:16
