
基于球面自编码器的文本分类
2021-03-11 03:09:38赵书安
电子器件 2021年6期
赵书安
(1.江苏开放大学信息工程学院,江苏 南京 210065;2.南京理工大学电子工程与光电技术学院,江苏 南京 210094)
文本分类是自然语言处理社区的经典问题,旨在为句子、搜索查询、文档等指派类别标签,在自动问答、垃圾信息识别、情感分析、新闻归档、用户意图分类等领域有着广泛的应用前景[1]。由于海量数据在互联网时代的易获取性,以及基于数据驱动的机器学习、深度学习理论算法的发展和应用,文本分类始终是当前的研究热点。比如在电信邮件诈骗领域,自动检测出具有诱导性的垃圾邮件,防止用户遭受欺骗,从而规避风险,减少不必要的损失[2];在媒体信息处理领域,针对新闻文本内容自动实现归档,然后向关注特定领域新闻事件的用户精准推送,有助于提高用户体验,增强用户粘性等等[3]。
在文本分类过程中,提取能够有效表征文本的特征表示以及选择合适的分类方法至关重要。针对文本的特征表示,传统合理有效的方法,包括构建特定领域关键词字典(Domain-specific key-phrases dictionary,DSKD)、N 元文法(N-gram)、词性标签(Partof-speech,POS)和考虑语言学结构的句法依存解析树(Dependency parsing tree,DPT);而对于分类方法,研究表明有效且应用最广泛的包括逻辑斯蒂回归(Logistic Regression,LR)、朴素贝叶斯(Naive Bayes,NB)、支撑向量机(Support vector machine,SVM)以及决策树(Decision tree,DT)等等[4]。随着文本数据规模的增加,传统的特征提取方法,尤其是构建关键词字典需要花费大量人工成本,因此可行性逐渐降低。而词向量[5]的提出,结合包括卷积神经网络(Convolutional neural network,CNN)[6]、递归神经网络(Recursive neural network,RecNN)[7]、循环神经网络(Recurrent neural network,RNN)[8]、注意力机制(Attention mechanism,AM)[9]、记忆网络(Memory network,MN)[10]等神经网络模型,能够学习深层语义信息,支持大规模预训练语言模型,在文本分类任务上取得了优异的表现[11]。
然而上述的文本分类方法大多是有标注信息、任务相关并且是基于特定领域的。在实际场景中的信息呈指数级增长,并不能够保证所获得的文本数据有足够准确的标注信息用于训练。因此许多研究工作聚焦于如何得到高质量的文本特征表示[12]。目前主流的文本特征表示研究主要分为两个方向,通过大规模预训练语言模型得到上下文相关的语言模型(Language model,LM),以及通过深度生成模型(Deep generative models,DGM)得到隐层表示。前者的典型工作有,Peters 等[13]提出了基于双层双向的RNN 语言模型ELMo,能够捕捉到动态语义信息;Radford 等[14]提出的GPT 模型在ELMo 基础上使用Transformer[15]代替RNN,结合下游任务得到任务相关的文本表示;Devlin 等[16]提出的BERT 使用Transformer 同时训练遮蔽的语言模型(Masked LM)和预测下一个句子任务,在各项自然语言任务上取得了当时最优的表现。后者基于深度神经网络结合概率生成模型,不受限于大规模语料数据集,不仅能够从数据中学习到较高质量的特征表示,而且在特定的计算机视觉、自然语言处理领域多种任务中还具有较好的可解释性。Kingma[17]提出了变分自编码器(Variational auto-encoder,VAE),在CIFAR10 数据集上的实验结果表明,VAE 学习到的特征表示与数字笔画、形状、倾角等相关,验证了VAE 能够学习到深层的图象特征表示。Miao[18]将VAE 应用于文本主题建模,在20NewsGroup 数据集上的实验结果表明,VAE 能够学习到文本内容相关的话题等深层语义信息。
基于上述讨论与分析,通过对VAE 在文本建模相关工作的研究,发现经常发生后验高斯概率分布的KL 散度塌陷现象[19],本文提出一种基于球面变分自编码器的文本分类方法,通过将VAE 隐变量的概率分布从高斯分布替换为概率空间分布在球面的冯米塞斯-费舍尔(von Mises-Fisher,vMF)分布[20],不仅使得隐变量能够表征更丰富的深层语义信息,而且在理论上保证不会出现后验分布塌陷现象,并应用于文本分类任务,得到了显著的效果。
1 变分自编码器
本文提出的基于球面VAE 的文本分类框架如图1 所示.其中N(μ,Σ)表示隐变量服从多元高斯分布,vMF(μ,κ)表示隐变量服从的球面分布。
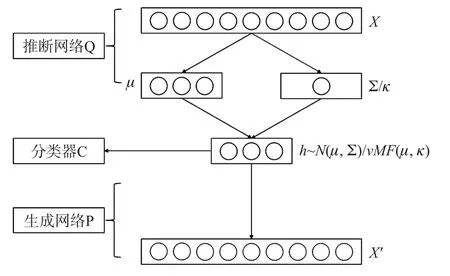
图1 基于球面VAE 的文本分类框架
VAE 最先被提出是用来学习数字图像的深层语义信息,将神经网络引入概率生成模型,包括推断网络和生成网络两部分。模型假设输入数据实际都对应各自的隐变量h服从特定的概率分布,推断网络的作用是对这个概率分布建模,得到均值和协方差。生成网络的作用是基于推断出的概率分布,再重构出输入数据。这个过程中可以得到输入数据对应的概率分布,而这个概率分布就具有表征输入数据的能力。
通常假设隐变量分布为高斯分布,对于推断网络qφ,其中φ表示推断网络的参数,可以得到隐变量的后验概率分布为qφ(h|x),先验概率分布p(h)为标准多元高斯分布。VAE 的优化目标是变分下界(Evidence lower bound,ELBO)

式中:pφ(x|h)为生成网络的重构输出;φ表示生成网络的参数;E表示分布求期望;D表示求分布的KL 散度。通俗来讲,VAE 的优化目标包括两项,分别是尽量使得重构输出的数据近似原始输入数据,以及推断网络得到的隐变量后验分布近似先验分布。选择高斯分布的原因之一,是两个高斯分布N1(μ1,Σ1)和N2(μ2,Σ2)之间的KL 散度存在解析解,计算公式如下
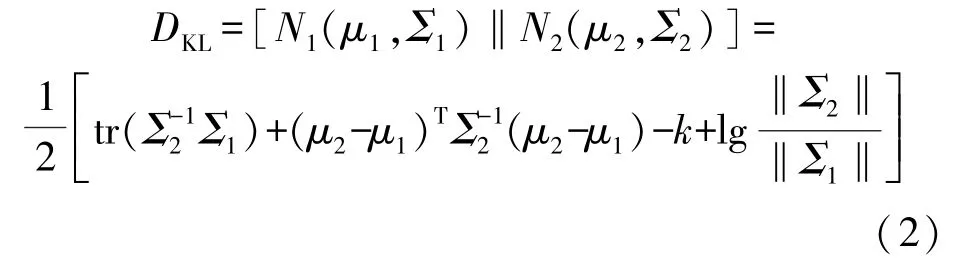
式中:tr(·)表示矩阵的迹运算;k表示多元隐变量维度;‖·‖表示方阵的行列式。代入先验概率分布和推断网络得到的后验分布表达式即可求得解析解。
在VAE 的推断—生成过程中,得到服从特定概率分布的隐变量即具有表征输入数据的能力,因为从隐变量概率分布可以重构出原始数据。重构误差越小,说明表征能力就越强。也因此,得到的隐变量可以看作是高质量的输入数据特征表示,可以用于文本分类任务,而且不受限于大规模语料。
2 vMF 分布
VAE 的优化目标涉及两项,其中一项是重构误差,优化这一项会使得隐变量能够更多地包含输入数据的信息;但另外一项KL 散度,优化这一项会使得隐变量服从的后验概率分布趋于先验,因此这一项也被视作约束项。虽然VAE 作为深度生成模型,在很多任务上都有很好的表现,但在自然语言处理任务中常常发生后验塌陷现象,即KL 散度被优化至趋于零,隐变量的后验概率分布趋于先验概率分布,这意味着实际上隐变量并没有学习到输入数据相关的信息;此时若重构误差仍然较小,只能说明VAE 的生成网络学习能力较强,在不需要隐变量的情况下依然可以重构出输入数据,而这也违背了VAE 模型想要从输入数据中学习隐变量概率分布的目的。
为了解决后验塌陷问题,Davidson 等[21]将vMF分布引入VAE。vMF 是ℝd空间上分布在(d-1)维球面的空间分布,其概率密度函数由它的方向向量μ(‖μ‖=1)和集中参数κ≥0 决定,公式如下

式中,Iν表示ν阶第一类修正贝塞尔方程。Xu[22]论证在VAE 文本建模中,只要简单地将集中参数设置为常数,便可从理论上解决后验概率塌陷的问题,并且同时可以得到较好的实验结果。此时的后验分布和先验分布之间的KL 散度仅依赖于κ,如式(5)所示。因此,若固定其参数值,KL 散度不会被优化至趋于零,这也保证了隐变量的后验分布不会完全塌陷至先验分布,从而使得隐变量具有能够表征输入数据的能力。
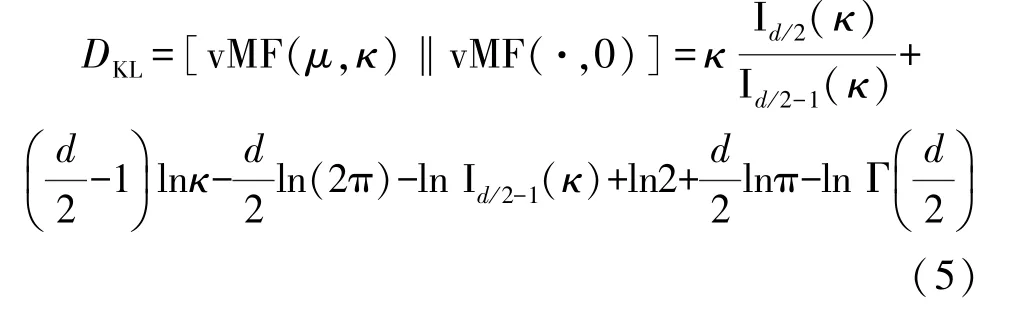
3 实验结果与分析
3.1 实验环境与设置
为说明将球面VAE 应用到文本分类的有效性,在被广泛使用的三个公开数据集上加以验证,分别是Yelp 数据集(https://www.yelp.com/dataset)、IMDB数据集(https://www.kaggle.com/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews)和AGNews 数据集(https://www.kaggle.com/amananandrai/ag-newsclassification-dataset)。其中,Yelp 数据集源自该点评网站上的用户对酒店餐厅的1-5 星评论,每个类别包括650 000 条训练样本和50 000 条测试样本;IMDB数据集是该网站用户对电影的观后评价,分为正面评价和负面评价两类,各个类别均包含25 000 条样本数据;AGNews 数据集是利用学术搜索引擎发布的从超过2 000 个新闻数据源网站上爬取的新闻报道,包括世界、科技、体育、商业4 个类别共120 000 条训练样本和7 600 条测试样本。
针对所使用的数据集,基于NLTK(https://www.nltk.org/)工具采用统一的数据预处理流程,包括词干抽取、停用词过滤、词表构建等,然后基于Tensorflow(https://www.tensorflow.org/)进行相关的实验。电脑操作系统是Windows10,显卡型号是GTX1060。
基线模型采用基本的VAE,记作Gauss-VAE;所提出的模型记作vMF-VAE。推断网络和生成网络均使用多层感知器(Multi-layer perceptron,MLP),输入数据为文本词袋表示的词频向量;分类器同样采用MLP。分类器使用MLP 的原因是想在不损失模型精确度的情况下,尽量减小模型复杂度。模型相关超参数情况为:数据批规模(batch size)设置为64,学习率(learning rate)设置为0.001,优化器(optimizer)设置为Adam[21],隐变量维度分别设置为25,50 和100.
3.2 结果与分析
表1 给出了基线模型和所提出模型在三种数据集上的准确识别率。

表1 分类结果 单位:%
不难发现,所提出的vMF-VAE 在Yelp 数据集上略有提升,在IMDB 和AGNews 数据集上的表现均明显好于Gauss-VAE,这说明本文提出的方法可以有效获得更有效的文本特征表示,从而可以更好地解决文本分类问题。
4 结论
本文提出了一种基于变分自编码器的文本分类方法。首先通过推断—生成框架得到文本特征表示,然后再基于此特征表示进行文本分类。受限于服从高斯分布的隐变量在优化过程中会发生后验塌陷的问题,本文引入了球面vMF 分布代替高斯分布,实验结果表明了本文所使用方法的有效性。近年来使用VAE 框架建模文本的研究取得了很大进步,越来越多的研究表明VAE 模型由于假设隐变量服从高斯分布而可能会存在问题,后续会继续跟进VAE 模型的相关工作并探索如何得到质量更好更稳定的文本特征表示问题。
猜你喜欢
数字通信世界(2021年3期)2021-04-09 02:05:00
装备制造技术(2020年3期)2020-12-25 05:22:02
湖北理工学院学报(2020年4期)2020-08-22 06:43:26
工程数学学报(2020年3期)2020-07-06 07:38:40
长治学院学报(2019年2期)2019-07-24 07:14:04
科技视界(2016年19期)2017-05-18 10:18:46
计算机应用与软件(2017年4期)2017-04-24 10:39:07
雷达学报(2017年6期)2017-03-26 07:53:04
中国工程咨询(2017年3期)2017-01-31 05:29:50
华东理工大学学报(自然科学版)(2014年5期)2014-02-27 13:49:31
