
中美理工科学者学术论文摘要言语特征量化比较
2021-03-11 08:42:22潘筱,樊渊
海南热带海洋学院学报 2021年1期
潘 筱,樊 渊
(安徽大学 a.外语学院;b.计算智能与信号处理教育部重点实验室,合肥 230601)
当前英文期刊已成为国际学者传播和了解科学知识的主要渠道,越来越多的非英语本族语者需要在国际期刊上发表英文学术论文,包括中国学者在内。因此,国内学者有必要了解英语母语使用者在发表学术论文时所遵守的语言习惯。Graesser[1]指出同一学科领域的专家学者通常会明示或暗示其专业领域内的学术文章写作需要遵循一定的言语或话语规则。因此,某一特定学科领域内的非英语本族语者如果在撰写英文学术论文时误用或误解了这些规则,显然不利于其文章被领域内学者认可和接收。
关于英语学术论文写作与发表方面的研究国内研究起步较晚,研究内容主要包括以下几个方面:一是介绍国外的相关学术英语研究成果,如齐曦[2]回顾过去30年以来国际学术英语写作评估研究,穆从军[3]从理论框架、研究方法和研究内容等方面整理归纳20世纪80年代以来的科研发表英语相关研究;二是关于学术英语的语篇体裁研究,其中鞠玉梅[4]用体裁分析理论比较英汉学术论文摘要的宏观语篇结构,韩萍、贺宏[5]运用批评性体裁分析方法研究了二语习得方面学术论文摘要和引言的体裁关系;三是心理认知角度的学术英语写作研究,如丁展平[6]指出遁言是用语言形式体现作者心理取向的产物且成功的学术英语写作需要借助遁言以达到交际目的,徐昉[7]分析学术写作身份语块的使用和变化特点;四是基于计算机和语料库的学术英语写作研究,如康勤、孙萍[8]比较不同学科论文摘要部分的宏观结构及其对情态动词和语态的影响,娄宝翠[9]基于研究生学术英语语料库考察研究生学术英语语篇中外壳名词的使用特点。由此可见,国内学者在考察学术文本特征时多侧重词汇和句子层面,如连接词、外壳名词、立场标记、学术词块等,比较少见的是对学术文本语篇连贯的分析,尤其是英汉学术文本的对比研究。考虑到摘要是学术论文的第一项重要组成部分,它传递出论文最浓缩和最有价值的信息,是读者了解一篇论文是否值得关注或研究的基础。因此,对中美学者所撰写的论文摘要部分言语特征进行量化比较研究,对理解英语母语作者的语篇连贯性具有代表性意义。本研究通过Coh-Metrix在线工具测量中外学术论文摘要部分的文本特征并运用计算机分析,从词汇难度、句法复杂度和语篇连贯性三个层面量化比较中国学者和美国母语使用者在话语特征上的差异性,以期利用得出的客观结果对中国学者的学术英语写作提供理论指导。
一、 Coh-Metrix工具
美国孟菲斯大学Graesser等[10]设计并开发的自然语言处理软件Coh-Metrix是一项可以测量文本衔接性和文章难度的自动分析工具,可以在线同时测量文本特征、衔接手段、词汇多样性、句法复杂度和文本可读性等106个文本特征。Coh-Metrix的运行主要基于句法分析器、潜伏语义分析和其他计算语言模块,其中潜伏语义分析技术挖掘深层次文本变量的方式是通过输入大量的文本,构建词项和文本之间庞大的term-by-article矩阵,再通过奇异值分解实现减维降噪,最后获得包含有词项向量和文本向量的向量空间,并根据向量间的广义距离如余弦值等求取向量之间的相关性。潜伏语义分析的结果不再是简单的词条出现频率和分布关系,而是文本中各部分之间的语义相关性,因而改善了以往传统技术仅限于对文章表层形式特征统计的局限性。
Coh-Metrix自从2002年问世以来被广泛应用,国外学者利用Coh-Metrix进行的研究主要包括两个方面:一是发现不同英语变体之间的具体差异,并通过对这些差异的量化统计分析较为准确地进行文本分类,如口语和笔语[11]、不同作者的作品[12]、原著和简写本[13]、美式和英式英语文本[14]等;另一类是考察连贯性和语篇质量之间的关系,如文本连贯性与英语母语写作者作文成绩的相关性[15]、连贯性与二语写作文本质量之间的相关性[16]。国内利用Coh-Metrix对英语写作文本的语言特征进行分析的研究相对较少,如梁茂成[17]分析了语篇连贯能力和作文成绩之间的关系,桂林[18]比较了L1和L2作文中蕴涵的语义关系等。本文试图利用Coh-Metrix提供的文本数据比较中国学者和母语使用者在话语特征上的差异性,试图让更多的中国学者了解如何调整自己的语言使用来与该行业领域内母语使用者的习惯保持一致。
二、 研究设计
(一)研究问题
本研究主要回答以下问题:
1.中国理工科类学者发表在中国学术期刊上论文的英文摘要部分与美国学者发表在国际知名期刊上的论文摘要部分从词汇、句法和语篇角度分析是否存在语言上的显著差异?
2.中国理工科类学者发表在国际学术期刊上论文的英文摘要部分与美国学者发表在国际知名期刊上的论文摘要部分从词汇、句法和语篇角度分析是否存在语言上的显著差异?
3.美国学者发表在国际知名期刊上的论文语言具有哪些特征可以供中国理工科类学者借鉴和模仿?
(二)语料来源
本研究采用对比分析的方法对自建的小型语料库进行分析。选取中美学者近五年来发表在地理信息科学领域学术论文摘要150篇,其中包括中国学者发表的中文核心期刊论文摘要50篇(以下简称CC),中国学者发表在该学科领域的顶级SCI期刊论文摘要50篇(以下简称CE),以及美国学者发表的顶级SCI期刊论文摘要50篇(以下简称AE)。选取的标准参考:
1.第一作者和导师来自同一所大学或研究机构;
2.第一作者和导师的姓名均为美国国家姓名典型格式。
本研究选取的论文主要来源期刊有《地理与地理信息科学》、《地球信息科学》、InternationalJournalofGeographicalInformationScience、AppliedGeography等。
(三)数据分析
对150篇中美学者的学术论文英文摘要部分从词汇难度、句法复杂度和语篇连贯性三个层面进行判别功能分析。具体操作方法是先将150篇论文摘要分为两个部分,即90篇训练集和60篇测试集。首先使用训练集中的数据找到在Coh-Metrix给出的多项指标中最能区分中美两国学者在学术英语中使用的语言差异所在,再利用这些差异度最大的变量创建模型,生成判别函数,最后再由测试集中的数据去检验模型的有效性。
根据选择的数据库样本大小,为了避免过度拟合,对训练集中三组数据的比较分析仅限于五个变量。由于从Coh-Metrix网站上获得的指标远超过本研究需要的五个变量,因此我们决定先从总计108项指标中挑选出理论上更相关以及更能引起学者关注的指标。Haberlandt & Graesser[19]指出绝大部分读者阅读文章时会从以下三个不同的层面分析文章:词汇、句子和语篇。其中词汇层面主要包括将单词的视觉特征编码成抽象的字素或音素单位以及从长期记忆中检索单词含义;句子层面包括从语义上翻译从句并将一句话中的所有信息整合为一体;而语篇层面会利用文本提示及读者对世界的认识将从不同语句中获得的信息相互关联起来。参照这个标准版本研究将Coh-Metrix在线网站上提供的指标分为三大类别:词汇指标、句法指标和语篇连贯指标。
为了从这三大类别中找出最具代表性的五个变量,我们首先从这三类指标中各选取一个区分度最大的变量。对三个类别的变量分别进行ANOVA分析,不同语言类型作为组间变量,Coh-Metrix指标作为因变量,所产生的F-值按照效应值大小排列。选择每一组中拥有最高F-值得变量代表其组别。为了得到剩下的两个变量,将所有剩余的变量按照F-值大小排列。为了避免共线性问题,不能简单的选取F-值最高的两个变量。参照Duran[20]的做法,首先确保所有变量之间相关性r<.70,若任意两个变量间的相关性r≥.70,则先删除那个单变量关系值较小的变量,按F-值从大到小的顺序依次取得剩余的两个变量,结果如表1所示。
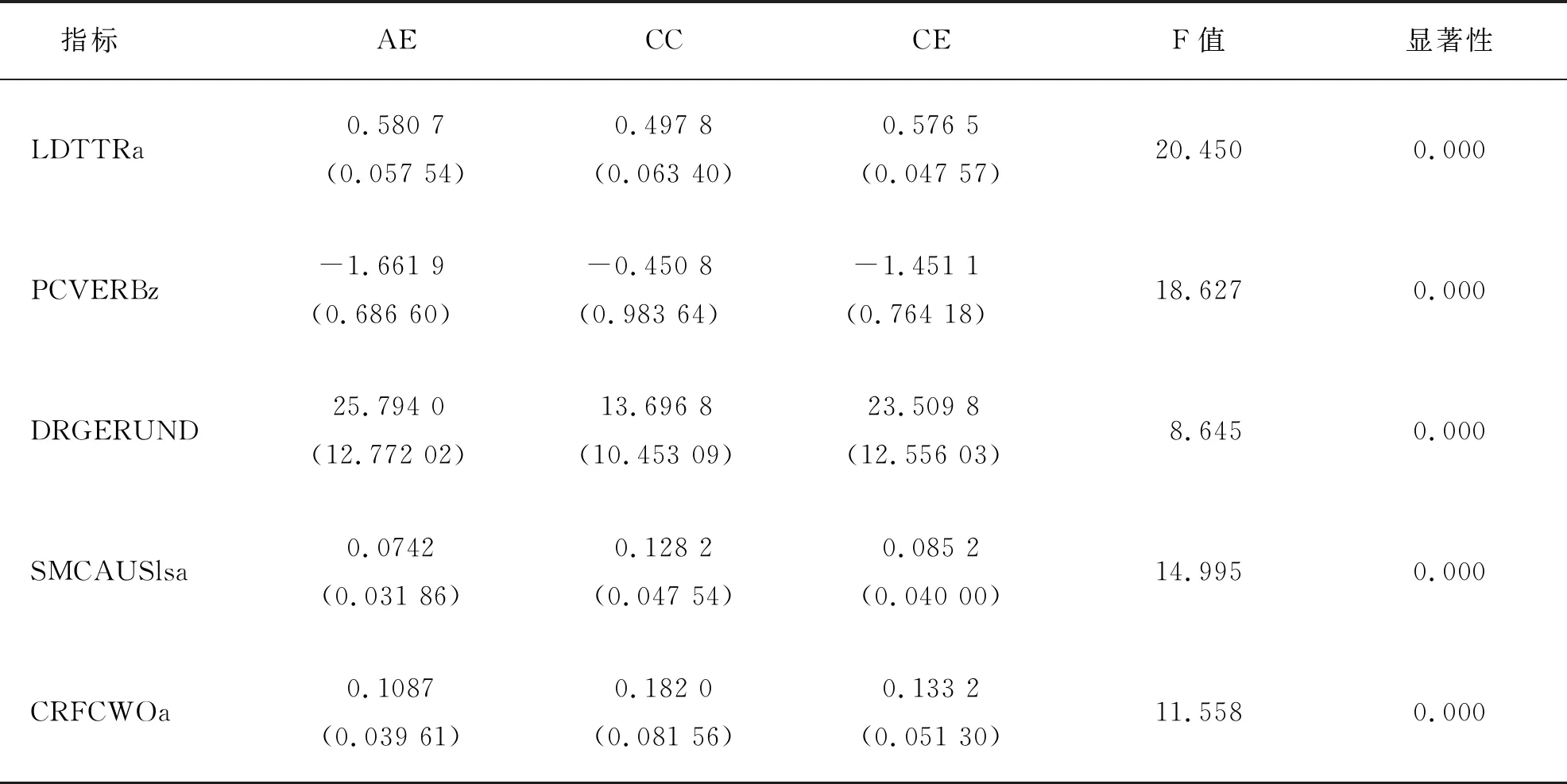
表1 按F值大小排列的五个区分度最大的变量
四、 结果与讨论
(一)中美学者言语特征对比
我们首先对三组数据的五个变量分别进行独立样本t检验,结果如表2所示。

表2 独立样本t检验结果
从表2可以看出,第一组AE和第二组CC五个变量的t检验结果显著性均为.000,因为.000的p值小于0.05,所以可判定中国理工科类学者发表在中国学术期刊上论文的英文摘要部分与母语使用者发表在国际知名期刊上的论文摘要部分在这五个指标上均存在语言上的显著差异。而第一组AE和第三组CE在五个变量的t检验结果显著性p值均大于0.05,所以可判定中国理工科类学者发表在国际学术期刊上论文的英文摘要部分与英语本族语使用者发表在国际知名期刊上的论文摘要部分在这五个指标上不存在语言上的显著差异。详细的比较结果如下。
1.所有单词类符/形符比(Type-token ratio for all words,LDTTRa)
类符/形符比(TTR)是衡量文本中词汇密度的常用方法,可以辅助说明文本的词汇难度。TTR比值越高,该文本用词越丰富,反之则越贫乏。实验结果显示,美国学者论文摘要部分TTR稍高于中国学者发表在国际期刊上的论文摘要部分TTR,且明显高于中国学者发表在中文核心期刊上的论文英文摘要部分TTR。TTR数据高可能有两个原因:其一,美国学者词汇使用较丰富,在国际顶级期刊上发表论文的中国学者英文词汇丰富性略低于母语使用者,而大部分在中文期刊上发表中文学术论文的中国学者的词汇使用多样性较低;其二,中国学者写作的英文摘要部分可能有大量功能词出现,文本每增加一个词,形符就会增加一个,但类符却未必随之增加。这样文本越长,功能词重复次数越多,TTR会越低。
2.动词衔接度(Text Easability PC Verb cohesion,z score,PCVERBz)
动词在构成英语的衔接机制中主要表现为“复现”和“同现”,且较多地体现在近义词的复现、同现。动词衔接度越高,说明文本中动词本身或其近义词的重复率越高,语篇连贯性也就越高,文本越容易被理解。实验结果显示,美国学者论文摘要部分动词衔接度稍低于中国学者发表在国际期刊上的论文摘要部分动词衔接度,但明显低于中国学者发表在中文核心期刊上的论文英文摘要部分动词衔接度。这一结果说明美国学者使用动词或其近义词的机率相对较低,文本难度较高,而在中文期刊上发表中文学术论文的中国学者使用动词或其近义词的几率最高,文本难度最低。
3.动名词发生率(Gerund density,DRGERUND)
Halliday[21]发现科学语篇最显著的特征之一是大量使用以名词化形式出现的语法隐喻,因为名词化结构能够代替小句使表达更加简洁、专业和客观。名词化是语篇正式程度的一个标志,语篇的程度越高,名词化越多,信息含量也越高。实验结果显示,美国学者论文摘要部分动名词发生率稍高于中国学者发表在国际期刊上的论文摘要部分动名词发生率,且明显高于中国学者发表在中文核心期刊上的论文英文摘要部分动名词发生率。这一结果说明美国学者论文中语篇名词化最多,正式程度最高,信息含量也越高,而中国学者发表在中文核心期刊上的论文英文摘要部分名词化结构最少,信息含量也最少。
4.因果类动词重叠率(LSA verb overlap,SMCAUSlsa)
因果类动词在科技英语中使用较为普遍,这类动词可以表示主语“会发生什么”或“期待可能发生什么”,他们的作用除了连接其他成分构成完整的句子以外,还可以表示句子间的因果关系,这种关系对于帮助我们阅读理解整句话甚至是整篇文章大有裨益。实验结果显示,美国学者论文摘要部分因果动词重叠率稍低于中国学者发表在国际期刊上的论文摘要部分动名词发生率,且明显低于中国学者发表在中文核心期刊上的论文英文摘要部分动名词发生率。这一结果说明中国学者在学术论文中倾向于使用更多的因果类动词,这些动词的使用可以帮助读者理解上下文间的逻辑关系,也从某种程度上降低了文本难度。
5.实义词重叠率(Content word overlap,all sentences,CRFCWOa)
实义词重叠是词汇共指关系中的一个主要衡量指标,这里我们参考的指标是文中所有句子间的实义词重叠。Kintsch&Van Dijk[22]指出词汇共指可以帮助读者理解文章并提高阅读速度。Crossley[23]研究发现越简单的文章使用的共指关系更多,因为词汇的重复可以帮助读者建立语篇不同部分之间的关系。实验结果显示,美国学者论文摘要部分实义词重叠率低于中国学者发表在国际期刊上的论文摘要部分实义词重叠率,且明显低于中国学者发表在中文核心期刊上的论文英文摘要部分实义词重叠率。这一结果表明中国学者的学术论文中实义词重叠出现的机会更大,也从某种程度上说明中国学者的学术论文难度更低。
(二)判别分析
首先,基于训练集中的数据,取按F值大小排列的五个指标作为自变量,不同语言水平(AE,CC和CE)作为因变量,得出的分类函数系数如表3所示。
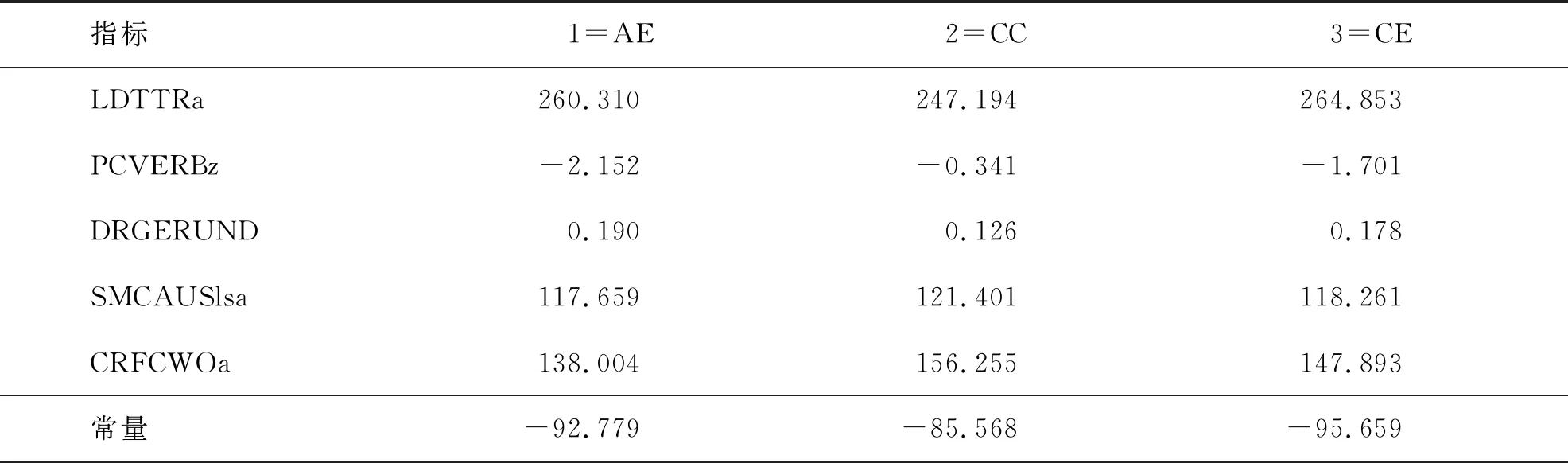
表3 Fisher线性判别式函数
为了检验模型的准确性,我们利用测试集中的数据进行判别功能分析。利用已知测试集中的60篇文章,可以依据判别分析的预测结果判断其准确性。参考的度量值有三项:召回率、准确率和F值。其中:
召回率=提取出的正确信息条数/样本中的信息条数,
正确率=提取出的正确信息条数/提取的信息条数,
F值=正确率*召回率*2/(正确率+召回率)。
正确率和召回率两者取值在0和1之间,数值越接近1,查准率或查全率就越高(见表4)。
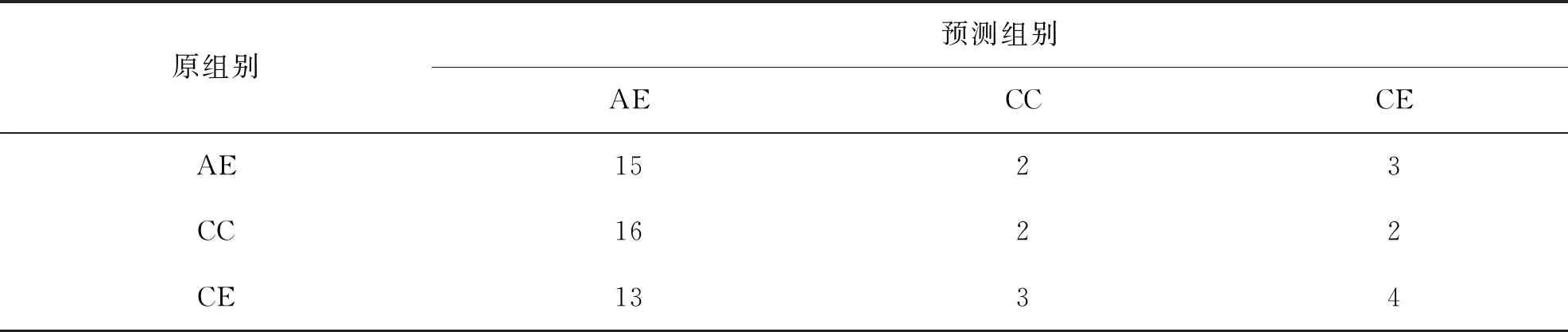
表4 原组别和预测组别
对于测试集中的60篇论文摘要,判别分析成功预测了其中46篇的组别,总体准确率达到76.667%。每一组别的准确性判断如表5所示。

表5 三个组别判别分析准确率、召回率和F值
结 语
本文研究结果表明,AE和CC差异显著,而AE与CE差异较小。这个结果说明在国际知名期刊上发表论文的中国理工科学者更好地学习和应用学术英语的使用规则,他们的语言更符合英语母语使用者在发表学术论文时所遵守的语言习惯。相较之下,在国内期刊上发表论文的中国理工科学者在撰写英文学术论文时需要更深层次地理解英语母语使用者的习惯和规则。具体来说,在国际知名期刊上发表的英文学术论文具有以下特点值得中国学者学习:(1)类符/形符比较高,(2)动词衔接度较低,(3)动名词发生率较高,(4)因果类动词重叠率较低,(5)实义词重叠率较低。
考虑到中国理工科类学者发表在国内学术期刊上论文的英文摘要部分与母语使用者发表在国际知名期刊上的论文摘要部分从词汇、句法和语篇连贯分析三个层面均存在语言上的显著差异,英语母语使用者在评审、编辑或阅读中国理工科类学者发表在中国学术期刊上论文的英文摘要部分时可能会认为这些学者并不了解其专业领域内的学术文章写作需要遵循的语言或话语规则,这显然不利于中国理工科类学者在国际知名期刊上发表英文论文。因而中国理工科类学者若希望在国际知名期刊上发表高水平英文论文,必须进一步学习和掌握英语母语使用者在发表学术论文时所遵守的语言习惯,进一步缩小本研究中反映出的中美学者在语篇连贯性上的差异。
猜你喜欢
系统医学(2023年18期)2024-01-10 01:57:20
系统医学(2023年13期)2023-10-26 04:04:08
系统医学(2022年17期)2022-11-07 09:23:50
管子学刊(2022年2期)2022-05-10 04:13:10
中北大学学报(自然科学版)(2022年2期)2022-05-05 09:04:08
系统医学(2022年2期)2022-05-05 07:10:46
管子学刊(2022年1期)2022-02-17 13:29:10
鄱阳湖学刊(2016年6期)2017-01-16 13:05:41
中国远程教育(2016年6期)2016-12-07 10:07:02
影视与戏剧评论(2016年0期)2016-11-23 05:26:00
