
面向开放集图像分类的模糊域自适应方法
2021-03-11 06:20:52刘晓龙王士同
计算机与生活 2021年3期
刘晓龙,王士同
1.江南大学 人工智能与计算机学院,江苏 无锡214122
2.江南大学 江苏省媒体设计与软件技术重点实验室,江苏 无锡214122
目前国内外大多数的域自适应的工作都假定目标域样本必然属于源域的已知类,两者有相同的类别空间,样本特征分布虽然不同但是相似。在实际的开放情况中,这种情况大多是不存在的,测试的目标域中大多还是有不同于源域的独立类别样本,把这些独立类别称为“未知类”,源域和目标域完全相同的类别,称为“共享类”。但是如果源域和目标域除了包含共享类别之外还都有完全独立的未知类别样本,那么称作这是一种开放集合领域场景。在此种开放的场景下,源域和目标域的共享已知类样本特征分布相似,差异较小;但是由于未知类的多样性,源域和目标域中未知类样本与共享类样本之间分布差异或大或小,简单的线性分类器不能应用到此种开放集的场景下。源域和目标域在开放集场景下不再像在封闭集下那样受限于共享相同的类别。图1 展示了开放集和封闭集领域场景:图(a)中源域和目标域只包含同一组共享类别的图像;图(b)中源域和目标域包含未知类别或存在其他领域的类别的样本,即有共同的已知类别样本之外,还有完全独立的未知类别样本。这种开放集合的领域是基于一种开放设置[1]的概念引申出来的。

Fig.1 Closed set domain and open set domain图1 封闭集合域与开放集合域
为了解决源域中带标签的数据集与目标域中的非标签数据之间的转移问题,从标签丰富的源域中训练分类器应用到另一个目标域样本,国内外学者也提出了许多域自适应方法[2-6]。文献[2]提出的对抗性区分域自适应方法学习一种对抗无监督适应方法的通用框架,使用倒置标签生成对抗网络(generative adversarial network,GAN)损失将优化分为两个独立的目标,一个用于生成器,一个用于判别器,考虑了独立的源映射和目标映射(两个流之间未共享的权重),从而可以学习领域特定的特征提取。文献[3]提出了一种深度域自适应方法,该方法利用域损失最小化,同时最大化不同域和类的标记样本之间的距离。文献[4]利用了将实例分配给部分潜在的领域并通过优化二进制来解决分类情况的思想,将实际的测试数据与已知领域内的带标记实例相关联,解决不平衡跨领域问题。文献[6]基于对抗网络方法提出了一种全新的度量源域和目标域数据分布差异的方法。通过梯度翻转层训练卷积网络并结合损失将损失最小化用于域自适应分类任务。由于不同领域的样本有不同的特征,会降低不同领域分类器的性能,因此尽可能地要使源域数据和目标数据之间有相似的分布且存在迁移的情况下训练判别分类器。这种特殊直推式迁移学习,由于不需要高成本的标签注释器就可以进行源域和目标域之间的知识传递,可以更好地解决现实问题,因此这种优势技术受到了更多的关注。文献[7]提出的迁移成分分析(transfer component analysis,TCA)和文献[8]提出的转移均衡的分布式适应(balanced distribution adaptation,BDA)都是基于边缘分布的自适应方法。文献[9-10]利用两个域之间存在某些共享子空间提出了测地线流式核方法(geodesic flow kernel,GFK)。最小化了源域和目标域的二阶统计特征的关联对齐法(correlation alignment,CORAL)[11-12]形式简单并且高效。这些域自适应算法的测试数据大多都来源于训练数据。
然而要进行图像分类和行为识别这种实际应用,现实由于目标域样本示例没有给定标签,因此不能确定所属类别一定是在源域已知类别范围之内,例如从共享网站收集的数据集与应用程序需要处理的数据有很大差别。目前大多域自适应算法不能解决源域和目标域样本类别不匹配的迁移问题。利用源域和目标域的共享子空间和“未知类”有效解决这个问题,并且进一步提出了一种基于开放集图像分类的模糊域自适应方法。鉴于复杂的目标域样本的复杂性和不同环境配置获取的图像样本的特征相似性,利用欧式距离很难直接精确地判断目标域样本标签问题,因此引进的是模糊系统中的不确定性模糊隶属度[13-14]。在分配伪标记过程中,通过模糊聚类算法的思想获得样本模糊隶属度,通过最小化分配的距离来学习从源域到目标域的模糊映射,使两个域相关联并且分布在同一个空间中。在下一个迭代中使用转换后的源域样本重新模糊分配并更新转换映射,直到在目标域样本上,学习的分类器达到最好的分类效果为止。通过是否预先给目标域样本固定部分标签,得到了无监督模糊域自适应和半监督模糊域自适应两种情形。
1 无监督模糊域自适应
对目标域样本实例进行模糊分配伪标签,利用源域的已知类别数据对每个目标样本分配伪标签。在开放数据集中,定义源域样本包涵C个类别,包涵C-1 个已知样本类别和一个额外的未知类别。利用模糊C 均值聚类算法(fuzzy C-means,FCM)的主要思想[13-14],计算目标域样本到源域类别中心的距离来得到一个模糊隶属矩阵来反映样本点属于某一类别的隶属程度,判断样本点上属于某一类。目标域n个样本,则可以表示为T={t1,t2,…,tn},定义第k次迭代的源域所有样本类别的均值为和V(k)由D维的样本特征表示。表示第k次迭代中样本tj属于第i类的隶属度,表示第k次迭代中样本tj属于奇异值的隶属度。定义第k次迭代中样本tj到第i个中心点的距离为:

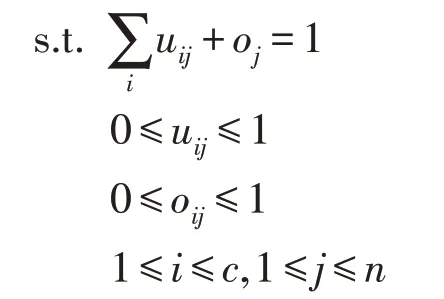
利用拉格朗日乘子法求解式,得到隶属度公式:

可以得到第k次迭代样本对源域类别隶属矩阵和样本为奇异值的隶属矩阵。相比直接二分类而言,模糊隶属度更能符合现实情况和增加容错率。通过隶属度目标样本得到一个带隶属度的伪标签。
2 半监督模糊域自适应
其他条件不变,当给目标样本注少量标签时,无监督分配问题变成半监督问题。在这种情况下,增加约束条件使带注释的目标样本不再改变类别标签。将τ表示样本的先验标签集合,yrj=1 表示样本tj带r类标签。并且是第k次迭代中样本tj被分配的伪标签,并且。
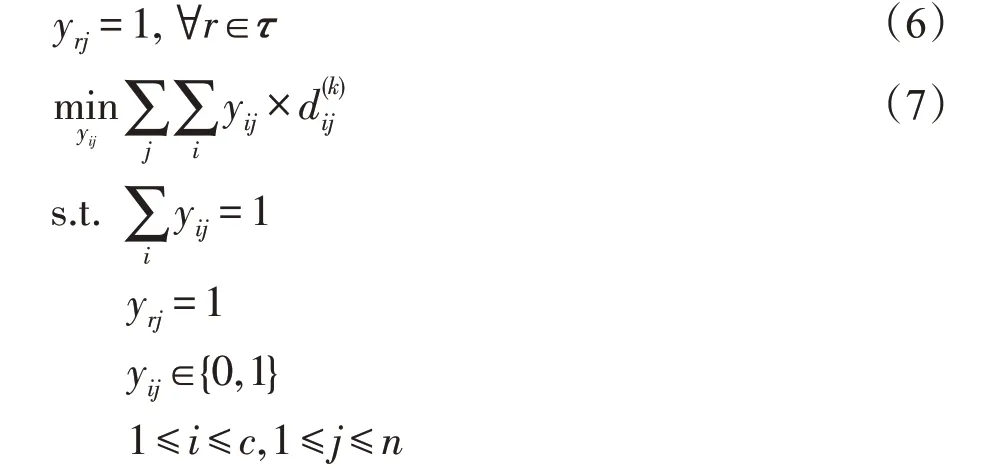
式(6)、式(7)利用最小化目标域样本到源域类别中心的距离,完成对所有目标域样本实例的标签的初步分配,每个样本得到一个伪标签。
通过计算样本类别均值,把定义各个类别均值之间的距离作为类别间的距离:第k次迭代源域中两两类别之间距离为:

目标域样本实例tj标签为i类的代价通过来表示,添加第二项在半监督目标方程中。另外通过K近邻算法得到tj的所有近邻Nj,如果目标域中一个样本实例tj的一个邻居样本被分配到tj所属类别之外的另一个类别,添加源域中类别之间的距离作为额外的代价。定义分配标签的距离代价目标函数为:

为了方便求解,把第k次迭代中样本到已知类的距离和额外近邻距离组合成新的距离损失:

利用拉格朗日乘子法求解式,得到隶属度公式:

3 学习源域到目标域映射
为将源域和目标域的样本特征变换到相同的空间,需要学习一个映射函数W(k)∈ℝD×D来完成这个转化。在学习这个映射过程中,选取每个样本在隶属矩阵U(k)和O(k)最大隶属度,其设置为0,如果样本的最大隶属度出现在O中,那么实验场景拒绝这个样本参与学习映射函数W(k)。表示的是第k次迭代中样本tj为第i类的最大模糊隶属度。那么表示样本tj没有分配第i类别。在无监督和半监督两种场景下,都是通过最小化损失函数来估计映射W(k):

表示第k次迭代中第i类样本均值的转置,用最小二乘法[15-16]求解这个凸目标函数的最优解W(k),学习源域到目标域的模糊映射矩阵W(k)之后,将源样本特征映射到与目标域相同的空间中。每一次迭代会得到新的映射。在转换后的源域数据上训练线性SVM分类器[17],更新分类器,获得目标域样本的分类结果。对于半监督设置的数据集合,实验还将带注释的目标样本添加到训练集中。
输出:隶属度矩阵U(k)、O(k),模糊映射函数W(k),分类精度。
步骤1初始化循环次数k=1。
步骤2分无监督、半监督两种场景:
(1)无监督场景下
根据式(2)得到φ(k);
根据式(4)、式(5)得到隶属矩阵U(k)、O(k)。
(2)半监督场景下
根据式(2)得到φ(k);
根据式(10)~(12)迭代更新得到隶属矩阵U(k)、O(k)。
步骤3根据式(15)得到映射W(k)。
步骤4W(k)×S(k):将源域和目标域的样本特征变换到相同的空间。
步骤5在转换后的源域上训练SVM 分类器,用于目标域分类,作为下次循环的源域。
步骤6判断当前迭代是否是最优精度,若是则返回步骤1,令k=k+1循环继续;若否,但超过最大迭代次数K,则循环停止,输出前K次迭代中的最优精度。
4 实验研究和分析
通过具体的实验数据集验证了提出的模糊域自适应方法的性能,在常用的Office数据集[18]上做了图像的分类实验。并且根据预先设定好的开放集协议[19]和是否为目标域样本加标记的设定,实验分为了无监督下的开放集模糊域自适应和半监督下的开放集模糊域自适应两大部分内容。相同的实验参数环境下,在Office 数据集[18]上进行了图像分类的实验,并且与经典的域自适应算法进行了对比。
4.1 数据集以及参数设置
在Office 数据集[18]上对本文方法进行了评估和比较。它提供了3 个不同的领域,即Amazon (A)、DSLR(D)和Webcam(W)。Amazon 数据集包含白色背景上的中心对象,其他两个包含在办公环境下拍摄的不同质量级别的照片。总共有6个源域-目标域的31个公共类的组合。有6个领域组合转换(A→D,A→W,D→A,D→W,W→A,W→D)可以进行实验的验证,从AlexNet模型的全连通层(fc7)中提取特征向量[20-21]。通过将Caltech 数据集[9]与Office 数据集[18]的10 个相同类别作为共享类,本文为该数据集引入了一个开放集协议[19]。按照字母顺序,在源域中使用第11~20个类作为未知样本类,类21~31作为目标域中的未知样本类,源和目标域中选择出来的10 个类作为共享类,其他分配的未知类不被共享。实验把独立的未知类作为源域中单独的一个类别,那么源域中就有共享的10个类别和另加一个未知类。同时设定了源域和目标域两者仅包含10个共享类的样本的封闭集合(Close)协议。本文在封闭和开放集合协议[19]上都做了大量实验工作。
为确保每个域转化实验过程中有同样参数配置环境,这样训练出来的分类器才能体现本文的模糊域自适应方法与无任何自适应结果的对比的公平性。选择最大迭代次数K=10,对于正则参数α的调整,在实验过程中,在[2-5,25]中以2 为步长寻找最优值,直到达到最优解。根据与文献[11,16]中相似的分类任务实验,使用线性核函数训练SVM分类器,得到了比较好的软间隔优化,因此基于先前的惩罚因子系数的选择,在实验中取[10-5,100]范围中以10为步长寻取本次实验最优的惩罚因子,选取多个域转换的效果最好的系数。为了体现实验的真实公平性,选取C=0.000 1 为本次所有基线算法和对比算法的惩罚因子系数。如果β设置为无穷大,那么这种情况就不考虑任何奇异值。若设置较低的参数值,那么几乎拒绝所有已知类的分配标签,即都分配为奇异值,显然这样无法实验,更不符合逻辑与现实情况。4.2节实验中分析了β取不同值带来的实验性能的影响,由实验表明β=0.5时多半实验会有最优效果,因此选取β=0.5作为实验的默认值。
4.2 无监督模糊域自适应实验
同时报告了将数据转换为普通低维子空间的方法结果,这些算法都是在域自适应问题上表现非常显著的。在Office 数据集[18]上对以下几个算法进行实验,包括迁移成分分析法(TCA)[7],实验中设定使用线性核函数进行映射,转化后的维为d=2/D,D为样本数据维度;构建了一条测地线来使源域靠近目标域的测地线流核(GFK),实验中利用子空间分歧度量(subspace disagreement measure,SDM)[9]和贪心算法求得这次实验中的最优子空间维度d*。此外,还有最小化源域和目标域的二阶统计特征的CORAL[11],实验用k近邻分类器,设置近邻k=1;在无监督情况下的实验,避免两个域之间适配条件分布和边缘分布被平衡对待而导致的实际问题中不平衡的问题,同样也对比了转移均衡的分布式适应算法(BDA),参考文献[8]中的设置,实验使用线性核,平衡因子μ=1,循环次数为10次。为了更好地分析本文方法FDA(fuzzy domain adaptation)算法不同形式的变换形式,FDA 是拒绝所有奇异值的表现,源域中的类别对目标域所有样本开放,即β=∞;FDAβ表示允许有奇异值的出现,并且在参数β设置方面在实验部分有精确说明。将单独用源域数据训练的SVM 分类器[17]作为比较对象,更好体现模糊域自适应的有效性。在使用开放集设置上[19],本文的实验报告如表1 所示,明显可以看到模糊映射自适应方法的优越性,本文方法FDA 在开放集和封闭集协议设定上都有显著的分类效果,比其他算法提升幅度更大。对于所有开放集合设定下的精度都小于封闭集合下的精度,但是本文方法在所有方法中仍然是表现最好的。
明显得到,关于Amazon这种大数据集领域组合的转换(A-D,A-W,D-A,W-A)改进的幅度更大。Amazon 到Dslr 的开放数据集上提升了8.74 个百分点,封闭数据集上提升了11.46个百分点。Amazon到Webcam数据开放集合和封闭集合上提升了16.31个百分点和11.55个百分点。从小样本域到大样本域的适应过程提升幅度也会有很明显的提升,并且提升幅度很大。Dslr到Amazon的开放集和封闭集上分别提升了6.15 个百分点和11.8 个百分点。而小样本域(D,W)之间的迁移时提升幅度不是特别显著,但是也有不错的效果。本文方法相比较没有自适应学习的环境,幅度有明显提升。在Office 数据集[18]上,开放集合协议和封闭集合协议整体平均提升了8.01个百分点和9.08个百分点。相对于实验的其他域自适应学习算法,提升幅度最显著。
参数β的影响:目标样本是否被视为异常值由φ取值确定,φ由样本到已知类之间的距离和参数β决定。为了分析参数β给实验带来的影响,取β=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]共9 个不同的值在转化域中都做实验。图2 显示了不同的β取值对实验精度的影响。在Office数据集[18]的6个转化域中多半在β=0.5 左右取得了最佳结果。当β接近0 时,由于丢弃了太多的样本,精度大幅下降。因此选取β=0.5 作为所有实验的默认值。
4.3 半监督模糊域自适应实验
本文方法也在Office 数据集[18]上的半监督设置中进行了评估。在目标域的已知类别样本中,对每个已知类随机抽取3 个样本固定标签。其余未标标记。把未进行域自适应时训练支持向量机(SVM)分类器的准确性作为基线,这些支持向量机仅在带注释的目标样本(a)和源域样本和带注释样本(a+s)上训练。半监督设定下的开放集和封闭集下6 个域转换的实验结果由表2所示,同时也对比了考虑奇异值和不考虑奇异值的情况,并且做了对比实验。本文也在有1 个近邻约束(FDA-N1)和有2 个近邻约束(FDA-N2)两个不同条件下进行了实验对比,并且分别考虑了有无奇异值约束的两种情况,实验结果表明,差距不是很大。但是与预期一样,在半监督场景下,模糊域自适应效果比其余的都要好。
在半监督场景下,每一个已知类随机选取了3个样本加固定标签作为带有先验信息的样本,这样的样本有普遍性,近邻距离影响可能较小或者没有,在目标函数中不具有能决定分配伪标签的效果。具有特殊先验信息的半监督设定下6 个域转化实验精度的均值和方差如表3 所示。导致运行本次半监督实验结果的鲁棒性很强。考虑现实情况,如果在特殊人为的先验条件下,凭经验能确定部分具有代表性的和容易判断错误的样本标签,那么这类样本对整个分类判别分析的影响会很大,并且在选取少量固定标签样本情况下变化幅度也会很大,通过实验来验证本文的猜想。在这样的假设条件下,优先选择具有代表性的或者容易分配为错误标签的样本,一个特殊的半监督场景:在第一次通过目标域样本到已知类中心的距离判断伪标签的时候,选择出那些判断错误的样本,作为半监督场景下加注释的部分。在优先选择这些强注释样本条件下,同样每个类别随机抽取3个样本加标签注释,形成特殊的半监督环境。实验验证了本文的猜想,并且与先前验证实验效果一致。

Table 1 Accuracy comparison of 6 domain transformation experiments under unsupervised settings表1 无监督设定下6个域转化实验的精度对比 %
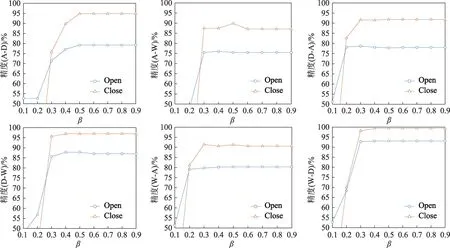
Fig.2 Influence of different parameter β on accuracy of 6 domain transformation experiments图2 不同的参数β 对6个域转化实验精度的影响
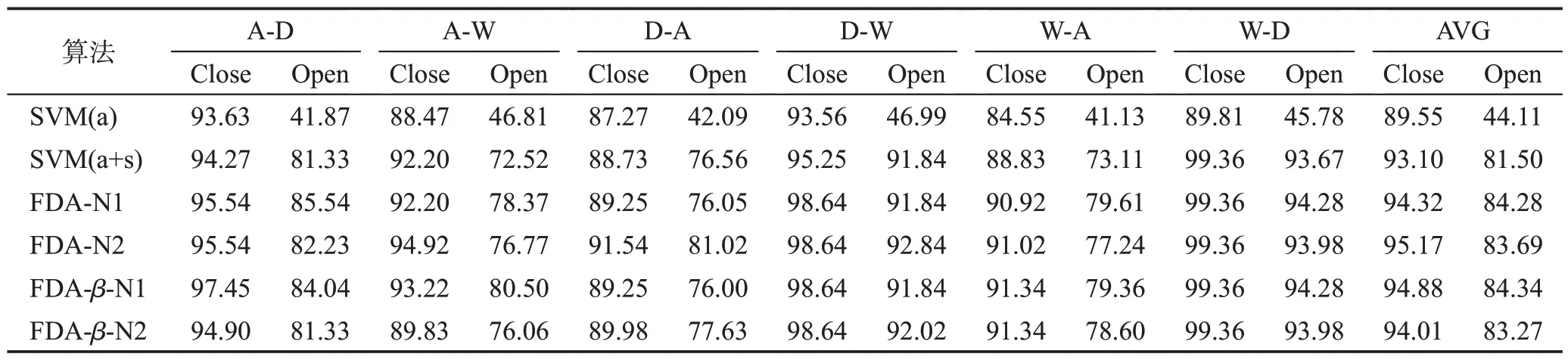
Table 2 Accuracy comparison of 6 domain transformation experiments under semi-supervised settings表2 半监督设定下6个域转化实验的精度对比 %
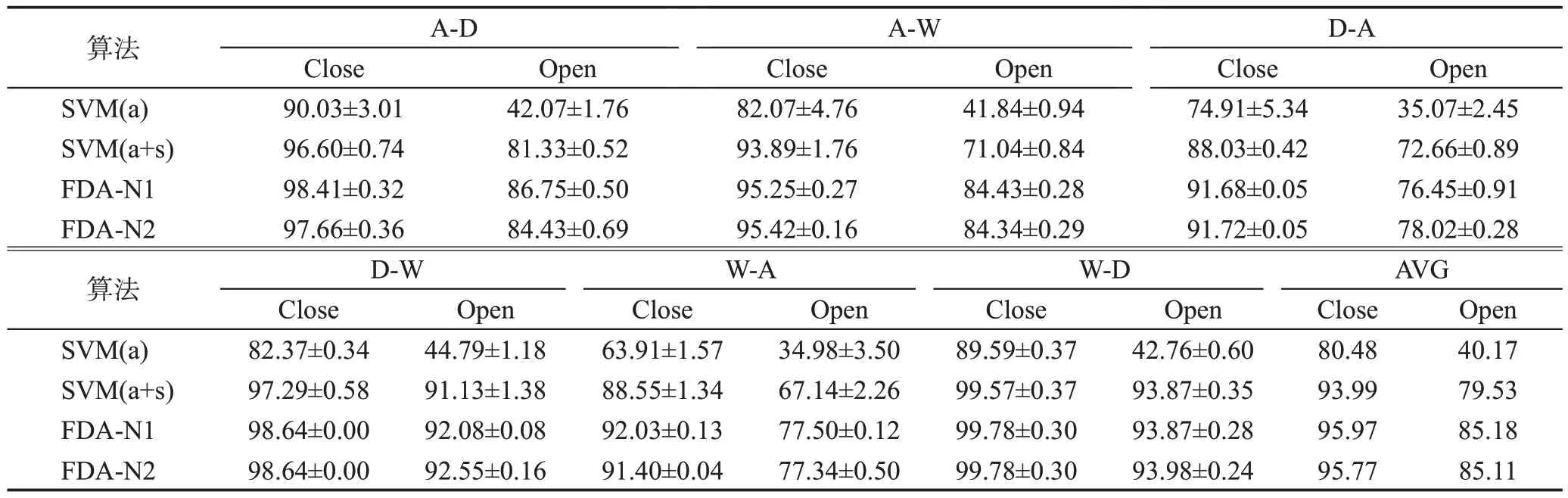
Table 3 Mean and variance of 6 domain transformation experiments accuracy under semi-supervised settings with special prior information表3 具有特殊先验信息的半监督设定下6个域转化实验精度的均值和方差 %
为了保证实验结果真实准确,对每个域转化下的数据集都进行了3次实验,然后取平均值作为最终结果并且用标准差来评估预测的离散程度。
5 结束语
现实场景更具有开放性,目标域与源域有完全独立的类别样本。鉴于独立类别样本的复杂性和重复性,本文提出的面向开放集合的模糊域自适应的方法基于源域和目标域的共享子空间对齐,通过计算目标样本模糊隶属度的方法得到带有模糊隶属度的伪标签,迭代更新源域到目标域的模糊映射函数,将源域和目标域的样本特征变换到相同的空间。实验结果证明,本文算法有效解决了传统域自适应算法解决不了的开放性问题,并且在无监督和半监督场景下都能获得比较显著的结果。模糊域自适应的方法也可以应用于图像分类的行为动作识别和视角检测上等更广泛的开放场景。
猜你喜欢
计算机技术与发展(2024年3期)2024-03-25 02:10:02
计算机技术与发展(2020年11期)2020-12-04 07:50:46
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
新校长(2016年8期)2016-01-10 06:43:59
电子与信息学报(2015年12期)2015-08-17 11:14:42
商事法论集(2014年1期)2014-06-27 01:20:42
电测与仪表(2014年15期)2014-04-04 12:05:20
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
