
Gath-Geva联合模糊聚类的生菜近红外光谱聚类分析
2021-03-09 10:12周树斌武小红贾红雯
光谱学与光谱分析 2021年3期
武 斌,周树斌,武小红,贾红雯
1. 滁州职业技术学院信息工程学院,安徽 滁州 239000 2. 江苏大学科技信息研究所,江苏 镇江 212013 3. 江苏大学电气信息工程学院,江苏 镇江 212013
引 言
生菜是最为常见的绿色蔬菜之一,不仅为社会带来了极大的经济效益,同时具有食用、药用以及保健价值,富含抗氧化成分(如抗坏血酸、类胡萝卜素)、膳食纤维以及矿物质元素(如钙和铁)等有益物质。生菜有益健康且便于食用,被消费者喜爱,保障市场上生菜的新鲜品质就很有必要。对于生菜的新鲜程度,生菜的储存时间是重要的影响因素,生菜储藏时间过长易积聚大量的硝酸盐以及微生物,从而对人体健康构成潜在威胁。因此,对生菜的储藏时间实现高效精准的鉴别就十分必要。
近红外光谱技术是一种无损检测技术,具有设备简单、检测速度快且绿色环保的特点。近年来,近红外光谱技术以其优越的性能在食品、农业、石化等众多领域得到了广泛的应用[1-3]。例如: Subedi等利用近红外光谱技术对鳄梨果实干物质(dry matter content,DMC)含量进行评估,DMC的增长率可以预测作物何时达到目标规格从而对果实的成熟度进行检测,结果表明该技术可以用于确定果园区域的收获顺序[4]。Mo等利用可见近红外和近红外高光谱成像技术对鲜切生菜生物污染物进行鉴别,结果表明高光谱反射成像技术具有检测新鲜生菜蠕虫的潜力[5]。Sun等基于高光谱成像技术对番茄叶片镉残留量进行研究与分析,提出了一种涉及小波变换和最小二乘支持向量机回归的方法来选择最优波长并建立检测模型[6]。Bert等利用可见/近红外反射光谱对野苣的前期贮藏期进行估算,通过偏最小二乘回归将可见/近红外光谱与存储时间联系起来,最终表明可见/近红光谱技术可以作为一种有价值、快速和无损的方法来识别和量化野苣的前期贮藏期[7]。Shubhangi等利用近红外光谱技术和分级聚类分析方法对昆虫侵染的水稻品种进行鉴定分析[8]。近红外光谱技术结合主成分分析(PCA)与排序判别分析实现了对红富士、花牛苹果的精准鉴别,为苹果的鉴别分类提供了一种创新的方法思路[9]。武小红等采用近红外光谱技术,提出了一种模糊判别C均值聚类(fuzzy discriminant c-means,FDCM)算法完成了对苹果品种的鉴别分类,证明了将近红外光谱与PCA和FDCM相结合聚类可以成功区分苹果品种的可行性[10]。武小红等利用傅里叶变换近红外光谱和Adaboost-ULDA对猪肉贮藏时间进行了准确预测[11]。
模糊聚类是非监督学习的最重要方法之一,在常规聚类方面有明显优势。模糊C均值聚类(FCM)算法、可能性C均值聚类(possibilistic c-means,PCM)是经典的模糊聚类算法,但都具有一定的局限性[12],PCM相比于FCM处理噪声性能更好,但对初始值比较敏感,而联合模糊C均值聚类(AFCM)将FCM与PCM结合起来,能够同时产生隶属度和典型值,在更好地处理噪声的同时,避免了一致性聚类,提高了聚类准确性[13]。在基于欧式距离测度的AFCM基础上引入指数距离测度从而提出了一种GG联合模糊聚类(GGAFCM)分析算法,并应用该算法进行不同储藏时间生菜的模糊聚类分析。
首先使用傅里叶近红外光谱仪采集不同储藏时间生菜样本的原始光谱,然后经过主成分分析和模糊线性判别分析(FLDA)的数据降维处理和鉴别信息提取,最终通过GGAFCM聚类算法实现对不同储藏时间生菜近红外漫反射光谱数据的聚类分析。实验结果表明,本方法可完成对不同储藏时间生菜的快速准确鉴别。
1 实验部分
1.1 生菜近红外漫反射光谱采集
共采集了60个生菜样本,将其清洁处理后放入贴有标签的保鲜袋内,而后置于5 ℃的冰箱内存储,每隔一段时间将其取出进行近红外漫反射光谱检测,检测时间间隔设定为12 h,共计3次,总获取180个生菜的近红外漫反射光谱。采集光谱时,实验室温度和相对湿度保持相对恒定。AntarisⅡ傅里叶近红外光谱分析仪开机预热1 h,通过反射积分球模式采集生菜的近红外漫反射光谱,扫描各生菜样品32次以获取样品的漫反射光谱均值。光谱扫描波数范围介于10 000~4 000 cm-1之间,扫描间隔是3.857 cm-1,采集到的各个生菜样品的光谱为1 557维的数据。为尽可能的减少实验误差,对各样本采样3次,取平均值作为后续研究所使用的最终实验数据。采集到生菜样本的近红外漫反射光谱图如图1所示。
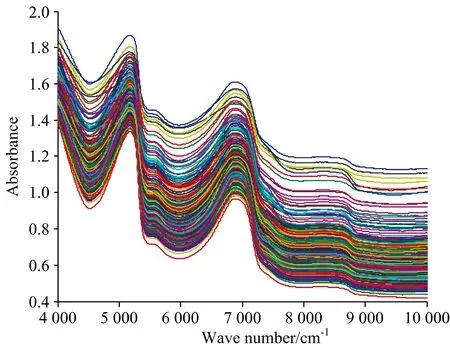
图1 生菜样本的近红外光谱图Fig.1 FT-NIR spectra of lettuce samples
1.2 指数距离测度模糊聚类算法描述
GG联合模糊聚类(GGAFCM)算法描述如下:

(2)计算参数γi
式中,n和c分别代表测试样本数据的数量和类别数。
(3)进行以下迭代计算直至收敛:
步骤1 计算距离测度
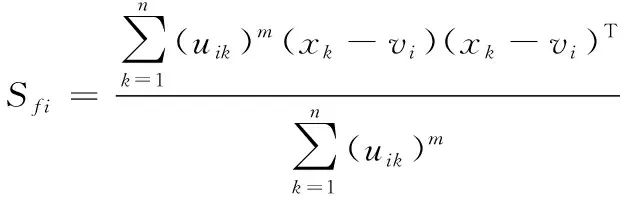
步骤2 计算模糊隶属度
步骤3 计算典型值
步骤4 计算聚类中心值
vi是第i类的聚类中心值; 模糊隶属度值uik表示第k个样本xk属于类别i的模糊隶属度值; 典型值tik表示第k个样本xk属于类别i的典型值。
2 结果与讨论
2.1 生菜近红外光谱的降维处理与鉴别信息提取
采集到的生菜近红外光谱数据中包含了大量的冗余信息,不利于后续的光谱分析,需要对其进行降维压缩处理。通过PCA将生菜光谱数据由1557维压缩至22维时的累积贡献率达到99.99%,剔除光谱数据中绝大部分无用的冗余信息。将生菜样本分为三种类型的储藏时间,即“储藏时间1”、“储藏时间2”、“储藏时间3”,其依次代表了第1次采集生菜近红外漫反射光谱,再每隔12 h各采集一次生菜近红外光谱。根据储藏时间的不同将生菜的光谱数据分为3类,每类光谱数据60个,共计180个生菜的近红外漫反射光谱数据。从每类生菜样本中选取30个样本作为训练样本,即训练集样本数为90个,同样选取30个样本作为测试样本,即测试集样本数为90个。所有程序的设计和运行采用Matlab7.0软件。
而后通过模糊线性判别分析(FLDA)方法对降维的光谱数据进行特征提取以便于提取出有用的鉴别信息。设置训练样本数为N1=90,测试样本数为n=90,权重指数m=2,类别数c=3,鉴别向量(由训练集样本计算得出)数为2,经FLDA将22维的测试集样本投影到其鉴别向量上得到了新的测试样本,其得分图如图2所示。其中“*,o,+”分别代表了“储藏时间1”、“储藏时间2”和“储藏时间3”等三种类型的生菜数据。观察得分图可知,三类生菜测试样本中,“储藏时间1”和“储藏时间2”的生菜光谱数据存在部分重叠的现象,而“储藏时间3”的数据则与另外两类数据基本不存在重叠。数据的部分重叠会使得生菜数据在分类时存在一定的误分类。

图2 FLDA得分图Fig.2 Scores plot of FLDA
2.2 模糊聚类分析
2.2.1 设置聚类分析初始参数
GGAFCM和AFCM的初始参数设置为: 测试集样本数为n=90,模糊加权参数m=2,系数a=1,b=1,类别数c=3;ε=0.000 01; 最大迭代次数rmax=100,初始迭代计数器r0=1; 对图2得到的二维光谱数据运行模糊C均值聚类(FCM),将FCM得到的模糊隶属度值和聚类中心值分别作为GGAFCM和AFCM的初始模糊隶属度值和初始聚类中心。
2.2.2 生菜储藏时间鉴别分类
把经过FLDA处理后的新的测试样本数据作为模糊聚类分析的数据样本。GGAFCM的模糊隶属度和典型值分别如图3和图4所示。在权重指数均为m=2的情况下,运行FCM后的模糊隶属度聚类准确率为91.11%,GGAFCM的模糊隶属度和典型值鉴别准确率均为95.56%,AFCM的模糊隶属度和典型值鉴别准确率均为91.11%。可知,GGAFCM具有更高的鉴别准确率,AFCM与FCM的鉴别准确率相同。GGAFCM迭代4次达到收敛,AFCM与FCM均为8次达到收敛。GGAFCM收敛速度比AFCM和FCM更快。

图3 GGAFCM模糊隶属度值Fig.3 Fuzzy membership values from GGAFCM

图4 GGAFCM典型值Fig.4 Typical values from GGAFCM
3 结 论
在联合模糊C均值聚类(AFCM)基础上引入指数距离测度从而提出GG联合模糊聚类(GGAFCM)分析算法。GGAFCM算法相比于FCM和AFCM算法鉴别准确率更高。实验结果表明: 使用近红外光谱技术对生菜进行检测,结合主成分分析和模糊线性判别分析后,GGAFCM方法可对生菜存储时间实现高效、精准的分类,相比于FCM和AFCM具有明显更高的聚类准确率。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中老年保健(2022年6期)2022-08-19
农家参谋(2020年5期)2020-06-15
经济技术协作信息(2018年22期)2019-01-19
食品与健康(2017年3期)2017-03-15
美食堂(2017年2期)2017-02-14
科学启蒙(2016年11期)2016-12-09
中国光学(2015年5期)2015-12-09
西藏科技(2015年4期)2015-09-26
食品工业科技(2014年23期)2014-03-11
