
基于多目标效用优化的分布式数据交易算法
2021-03-09 08:55黄小红张勇闪德胜钱叶魁韩璐李丹丹丛群
通信学报 2021年2期
黄小红,张勇,闪德胜,钱叶魁,韩璐,李丹丹,丛群
(1.北京邮电大学计算机学院(国家示范性软件学院),北京 100876;2.中国人民解放军32147 部队,陕西 宝鸡 721000;3.陆军炮兵防空兵学院郑州校区,河南 郑州 450052;4.北京网瑞达科技有限公司技术研发部,北京 100876)
1 引言
随着物联网、车联网、微电网以及移动应用的发展,大数据呈现爆炸式的增长趋势[1-2]。预计到2026 年,数据价值将达到922 亿美元[3]。目前,大部分数据都存储在公司或组织的数据库中,形成一个个数据孤岛,只有少部分数据真正得到充分利用,而且在使用上也有各种限制[4]。许多App 开发者和研究人员迫切需要数据来提高产品和研究的质量,并且愿意为此支付一定的经济成本[5-6]。因此,一些数据交易市场应运而生,如 Infochimps、Datacoup、Microsoft Azure Marketplace 等[7],但这些市场仍处于起步阶段,缺乏适用的交易规则。而且,从经济学的角度来看,市场组织者都是自私的,他们追求的是自身利益的最大化,而不是系统的整体效用。
因此,设计一种有效的数据交易机制成为学者的研究重点[8-9]。Niyato 等[10]描述了一种典型的数据交易市场模型,该模型由3 种实体组成:数据提供者(DP,data provider)、数据消费者(DC,data consumer)和数据代理(DA,data agent)。Cao 等[11]考虑了数据市场中存在多个DP、DA 和DC 的情况,提出了一种迭代拍卖机制来协调交易。Jiao 等[12]考虑了大数据的“无限供给”性,提出了一种基于拍卖的大数据市场模型,通过拍卖机制得到最优的数据交易价格和交易量。Yu 等[13]通过考虑数据质量和数据多版本发布的策略,提出了一个双层数学规划模型来优化数据交易。
当前针对数据交易的研究主要考虑了数据量、数据质量等数据本身的因素,忽视了数据属性、属性的相关性等与用户任务相关的因素。而且,在存在多个DC 的场景下,这些因素之间是存在竞争关系的,在研究数据交易时也应将这些竞争考虑在内。此外,现有框架一般以DA 作为中介来实施数据交易,即DA 从DP 处购买数据,然后将其出售给DC。由于DA 的信任危机和数据产品的低复制成本,这些集中式的解决方案带来了数据泄露方面的问题。
因此,一些学者针对如何提高数据交易的安全性和隐私性进行了研究[14]。Niu 等[15]提出了基于同态加密和身份签名的数据交易市场架构来保护DP的隐私。Jung 等[16]研究了数据交易中DC 的行为,并设计了AccountTrade 来保证DC 为其不诚实的行为承担责任。但是,这些基于密码学的解决方案复杂性较高,在时间和空间方面代价昂贵。基于分布式对等网络的区块链技术具有去中心化、不可篡改、可追溯、匿名性和透明性五大特征,这些特征为数据交易的安全问题提供了很好的解决方案[17-18]。Delgado-segura 等[19]提出了一种基于比特币的公平的分布式数据交易协议。Missier 等[20]使用区块链构建了一个分布式的、可信的、开放的物联网数据交易架构,并基于以太坊进行了实现。Sabounchi 等[21]利用区块链技术和契约理论设计了一种基于以太坊的P2P 数据交易机制。Gao 等[22]提出了一种安全、公平的数据交易方案,并设计了一种新型的比特币脚本来减少交易时延。这些方案采用分布式的架构解决了数据交易中的安全与信任问题,但是在效率方面仍存在不足,比如,比特币的吞吐量为7 TPS(transaction per second),以太坊的吞吐量为15 TPS,与实际需求相去甚远。
基于以上研究,本文提出了基于联盟区块链的分布式数据交易框架。在此框架下,通过考虑多维因素,建立了DP 和DC 的效用函数,并构建了双层多目标优化模型对他们进行优化。为求解优化模型,提出了协作式NSGAII,并通过实验对算法的性能进行了评估。本文的主要贡献如下。
1)针对中心化交易方案容易出现数据泄露的问题,提出基于联盟区块链的分布式数据交易框架,实现了DP 与DC 的P2P 的数据交易。
2)为了提高数据交易的有效性,通过综合考虑数据本身和用户任务相关的因素,基于数据质量、数据属性、属性的相关性、消费者竞争等多维因素构建双层多目标优化模型,以优化DP 和DC 的效用函数。
3)针对NSGAII 会泄露用户隐私的问题,提出一种改进算法——协作式NSGAII,通过DP、DC以及数据聚合器(AG,data aggregator)的协作来进行计算。DP 和DC 的效用函数由用户在本地进行计算,以免泄露隐私。
4)使用北京的空气质量数据进行了实验,以评估所提算法的性能。结果表明,所提算法在DP 和DC 的效用方面可以实现很好的性能。
2 系统模型
本节描述了分布式数据交易的场景,并构建了基于联盟区块链的分布式数据交易框架。
2.1 分布式数据交易框架
图1 展示了基于联盟区块链的数据交易框架,为确保数据交易的安全性和效率,本节设计了基于联盟区块链的数据交易框架。联盟区块链是一种特殊的区块链,它建立在许多预选的共识节点上,并由这些节点执行共识算法[23]。相比于公链,由于参与共识的节点较少,联盟链多采用实用拜占庭容错机制(PBFT,practical Byzantine fault tolerance)、委托拜占庭容错机制(DBFT,delegated Byzantine fault tolerance)、Raft 等共识机制。这些机制相较于公链所采用的工作量证明(PoW,proof of work)、权益证明(PoS,proof of state)等机制,数据处理速度有很大提升,因此极大地提升了联盟链的效率和吞吐量,对比比特币的7 TPS 和以太坊的15 TPS,采用联盟链的Fabric 可以达到500 TPS、Quorum 可以达到800 TPS[24]。
数据交易框架包含3 种实体,分别是AG、DP和DC。
1)AG 在系统中是数据交易组织者,负责数据交易过程中一些信息的传递以及对DP 数据的质量评估。每个AG 负责某种类型数据的交易。例如,在图1 中,AG4负责物联网数据的交易,AG6负责互联网数据的交易。在联盟区块链中,AG 充当选定节点来验证交易。
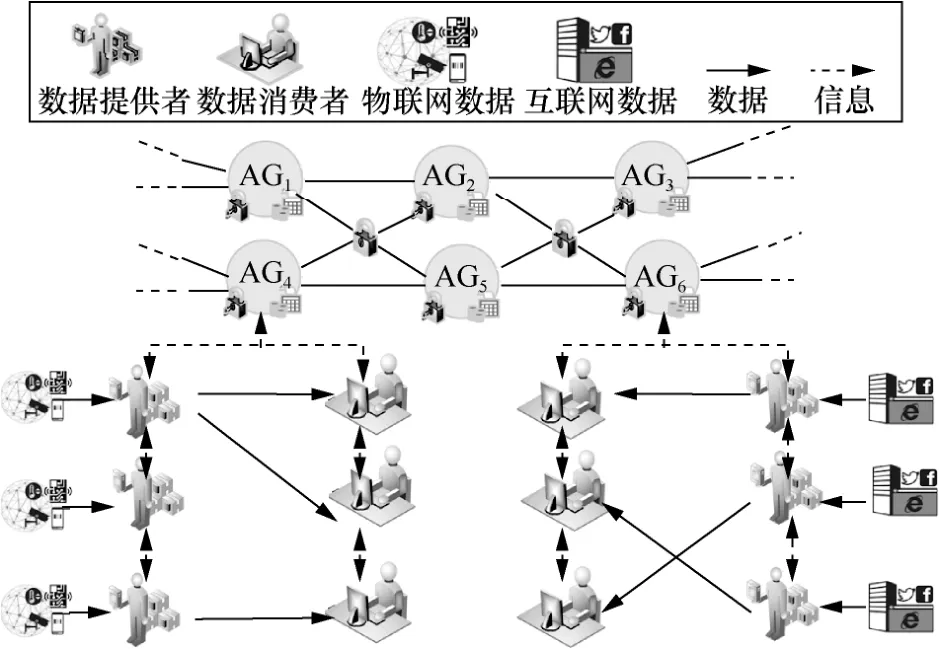
图1 基于联盟区块链的数据交易框架
2)DP 收集从各种来源(如传感器、移动设备、互联网等)生成的数据,这些数据包含某些属性。
3)DC 是购买数据并对数据具有某些属性需求的最终用户。
每个实体都有自己的账户和钱包。账户用于存储交易记录;钱包用于管理账户中的数字货币。交易完成后,DP 和DC 使用钱包来进行数字货币的收/付款。AG 使用钱包收取数据质量评估的费用。借助PBFT,至少1/3 的AG 确认交易,才能达成共识。
2.2 数据交易流程
数据交易流程如图2 所示,其具体步骤如下。
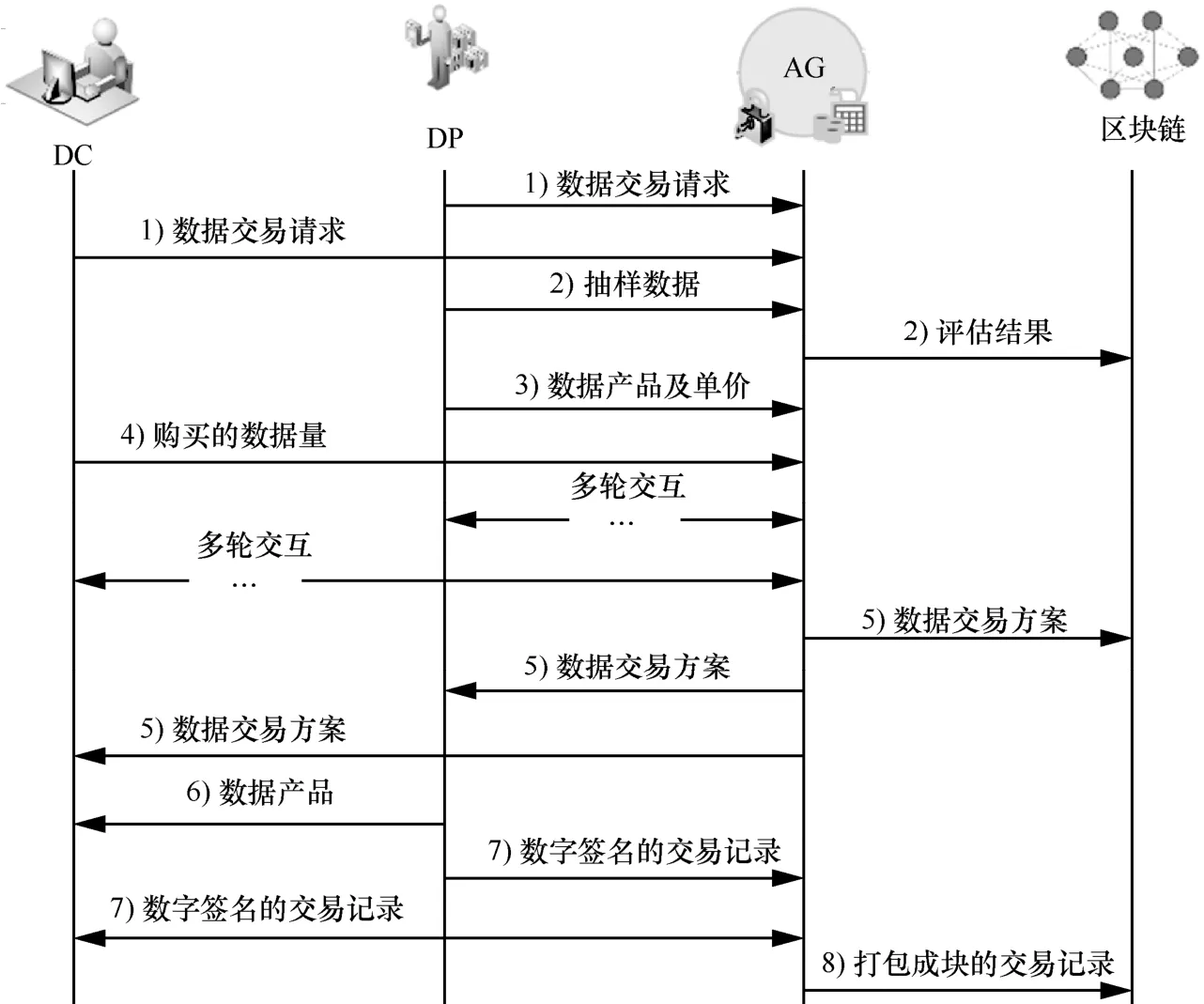
图2 数据交易流程
1)初始化。DP 和DC 使用有效的身份证明(例如居民身份证、企业营业执照等)向AG 注册成为合法实体,包括公钥、私钥的一对密钥将被分配给他们。DP 和DC 使用私钥生成钱包地址来参与数据交易。随后,DP 和DC 根据数据的类型将交易请求发送到相应的AG,DP 的请求包括其数据的数量和属性信息,DC 的请求包括其属性需求。
2)AG 广播这些数据交易请求并进行数据质量评估。AG 从DP 处获取一定比例的数据样本,执行质量评估,并将评估结果记录到区块链上。
3)DP 根据DC 的属性需求为每个DC 提供相应的数据产品和单价。数据产品的属性是DP 所能提供的属性与DC 所需的属性的交集。
4)根据DP 所提供的数据产品,DC 以最大化自身的效用为目标,选择最合适的数据产品,并计算购买量。DP 根据DC 的反馈,进一步调整数据产品的单价。
5)经过多轮交互,确定最终的交易方案,并由AG 将其存储在区块链上。根据数据交易方案,AG为每一笔交易创建相应的智能合约,DC 将数字货币存储在相应的合约地址中。
6)DP 将相应的数据产品发送给DC。
7)数据传输完成后,DP 对交易记录进行数字签名,然后发送给AG。AG 将交易记录发送给相应的DC。DC 验证交易记录并进行数字签名后回传给AG。此时,DC 保留在智能合约中的数字货币也将被发送到DP 的钱包地址。
8)经过一段时间的收集后,具有排序功能的AG 将交易记录打包成块,然后通过PBFT 将它们存储在区块链上。
在交易过程中,AG 负责数据质量评估、信息传输和共识算法执行。交易的数据由DP 直接传输给DC,因此是分布式的P2P 数据交易。这种交易方法可以避免单点故障、信息泄露和其他集中式交易的安全问题。
3 双层多目标数据交易匹配优化模型
本节将描述如何构建数据交易匹配模型,以优化DP 和DC 的效用,并给出模型的求解算法。
3.1 问题描述
在描述问题之前,给出所需参数及其含义,如表1 所示。
如图1 所示,存在一组AG,记作A,ai∈A,1≤i≤I。一段时间内,ai收集DP 和DC 的数据交易请求。设P和C分别表示DP 和DC 的集合,P中包含J位DP,pj∈P,1≤j≤J,pj向ai提交其数据属性集合和数据量Nj;C中包含K位DC,ck∈C,1≤k≤K,ck向ai提交其属性需求集合。

表1 参数及其含义
接收到AG 广播的DC 的属性需求后,DP 将为每个DC 提供相应的数据产品,数据产品的属性将是DP 可以提供的属性与DC 的属性需求的交集。例如,pj将为ck提供数据产品PCj,k,它的属性集合为然后根据成本和效用,给出PCj,k的单价wj,k。收到数据产品的信息后,DC将根据其效用函数确定最合适的数据产品以及购买的数据量。DP 收到DC 的决定后将进一步调整单价。通过多轮交互,确定最终的交易方案。AG 会将交易方案记录在区块链上,以解决可能发生的争议。
在匹配过程中,需考虑2 个方面:DP 的效用函数和DC 的效用函数。
3.2 DP 的效用函数
DP 的效用函数主要考虑数据交易的收入、数据收集的成本以及数据质量评估的成本,计算式为

其中,R(pj)表示pj的收入,L(pj)表示pj收集数据的成本,S(pj)表示ai为质量评估收取的费用。R(pj)的计算式为
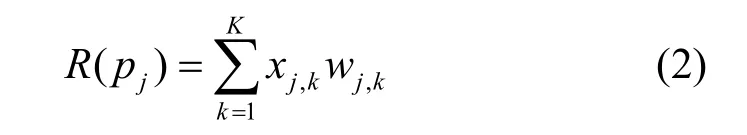
其中,xj,k和wj,k分别表示ck从pj处购买数据的数量和单价。
对于数据收集成本,不同的属性通常需要不同的收集设备,因此成本也有所不同。将收集第e个属性的单位成本表示为be,,则pj的数据收集成本为
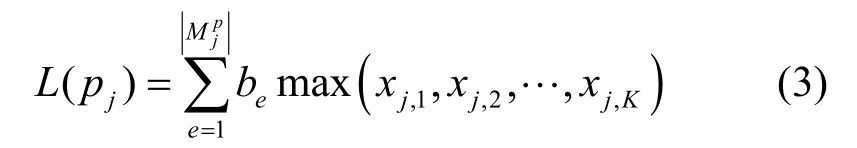
ai将对pj的数据采样并进行质量评估,评估费用与采样数据的数量成正比。因此,质量评估的成本为
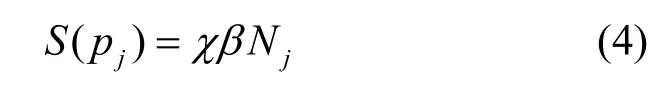
其中,χ是单位数据评估的价格,β是采样比例。
DC 购买数据主要是为了建立数据挖掘模型,其中分类和回归是数据挖掘的2 个主要类别。ai考虑与客户体验相关的绩效指标,使用所有采样数据和历史数据建立模型,以评估DP 数据的质量。对于分类问题,将分类准确性(即正确预测结果的比例)作为性能指标。对于回归问题,使用基于绝对误差的满意率作为性能指标。以pj为例,ai将使用(p1,…,pj−1,pj+1,…,pJ)的采样数据及其自身的历史数据训练模型,并将pj的属性作为标签依次进行测试。
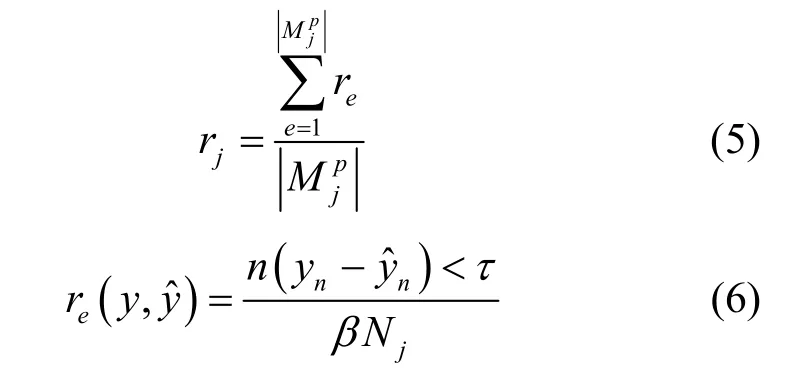
其中,yn、和分别表示数据样本的真实值、预测值和绝对预测误差;τ是预设阈值,表示预测的最大容限;函数n(⋅)用来计算满足条件的数据样本数。
为了确保采样的数据可以代表完整的数据,β的取值至关重要。为确定β的取值,首先定义欺骗。如果DP 在L条数据中包含了l条伪造数据,并且AG 从DP 处抽取了d条数据,但是这些采样数据中不包含伪造数据,那么DP 成功欺骗了AG。DP 成功欺骗AG 的概率为

AG 的公平性对数据质量评估有很大影响,为保证AG 能够公平地进行质量评估,本文采用如下的评价方式。ck购买了pj提供的产品PCj,k,如果ck使用PCj,k进行训练得到的模型准确率rj,k与ai给出的数据质量评估rj之间的差距超过约定的阈值σ,即rj−rj,k≥σ,则ck可以对ai进行投诉。在一段时间内,如果ai受到的投诉累积量大于阈值ϑ,则ai会被认为是不公平的,它将会被裁撤。
3.3 DC 的效用函数
DC 从DP 处购买数据,以满足自己的需求,并为此付费。因此,DC 的效用函数由2 个部分组成:满意度函数和成本函数,计算式为

其中,ST(ck)表示ck的满意度函数,参考文献[17]中的构造方式,其计算式为

ST(ck)的构造考虑了数据购买量、数据的属性及质量、ck的个人偏好、DC 之间的竞争性等方面的因素。首先,ST 是数据购买量的单调递增函数,并且随着购买数量的增长,ST 的增长速度越来越慢,这是因为数据中所包含的信息熵增长越来越慢[25]。DP 所提供的数据具有不同的属性和质量,属性越丰富,数据质量越高,越能够带来有效的数据量。数据属性的丰富程度用属性相关性qj,k来度量,属性越丰富,qj,k越高。数据质量用rj来表示。此外,ck的个人偏好也会对ST(ck)产生影响,用λk来表示ck的个人偏好程度,λk可以根据ck的需求、习惯等来定义。例如,经常出差的人更喜欢天气预报服务。DC 之间的竞争性采用属性需求的相似度来度量,2 个DC 的数据属性需求越相似,他们之间具有竞争业务的可能性就越大,从而对DC 满意度的负面影响也越大。利用Jaccard 相似系数,定义其他DC 对ck的影响参数ak为
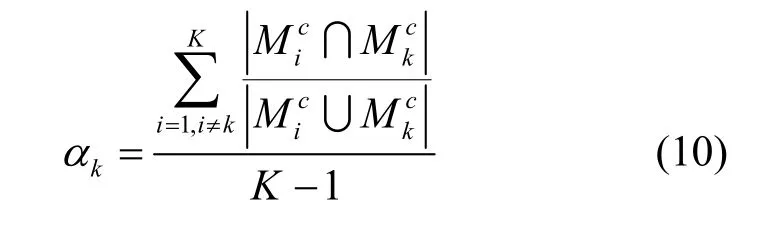
计算属性相似度实际上是计算2 个集合之间的相似度,因此采用了Jaccard 相似系数进行计算。
消费者ck具有属性要求,但是在某些情况下,DP 可能无法完全满足DC 的需求。当属性需求未完全满足时,数据仍然可用,但需要更多数据才能达到相同的效果,qj,k表示pj提供的数据对ck的可用性。当ck对数据属性与其任务的相关性没有一定的了解,或者认为数据的每个属性的相关性一致时,qj,k可以表示为
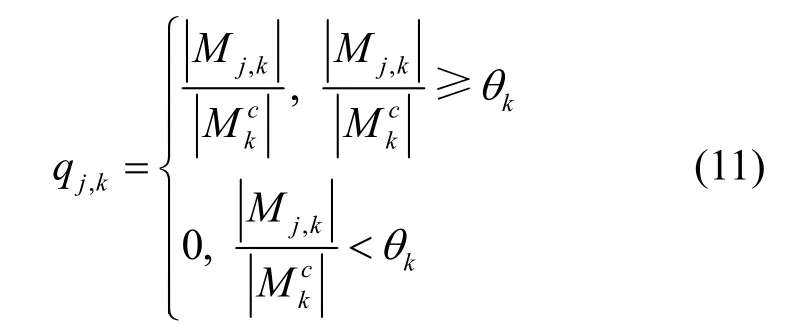
其中,θk是ck根据相关知识或经验设置的阈值。
在实际的数据挖掘过程中,数据属性的相关性是不一致的。如果ck曾经执行过相关的数据挖掘任务,他将对数据属性的相关性有一定的了解。设第f个属性的相关性为δf,qj,k可更新为

上述描述定义了DP 和DC 的效用函数,在数据交易过程中他们都以最大化自身的效用为目标。
3.4 数据交易匹配模型
在交易过程中,DP 首先提供产品和价格,可以看作交易的领导者,随后,DC 根据DP 所提供的信息做出自己的购买决策,可以看作交易的跟随者。因此,为了优化DP 和DC 的效用函数,建立了一个涉及多个领导者(所有DP)和多个跟随者(所有DC)的双层优化问题(BLPP,bi-level programming problem)。在上层,DP 根据DC 的属性需求提供相应的数据产品,并给出单价,以最大化其效用。在下层,DC 以最大化自身的效用为目标,通过自我选择过程做出购买决定。上述问题的模型可以表示如下。
1)上层:DP 的决策
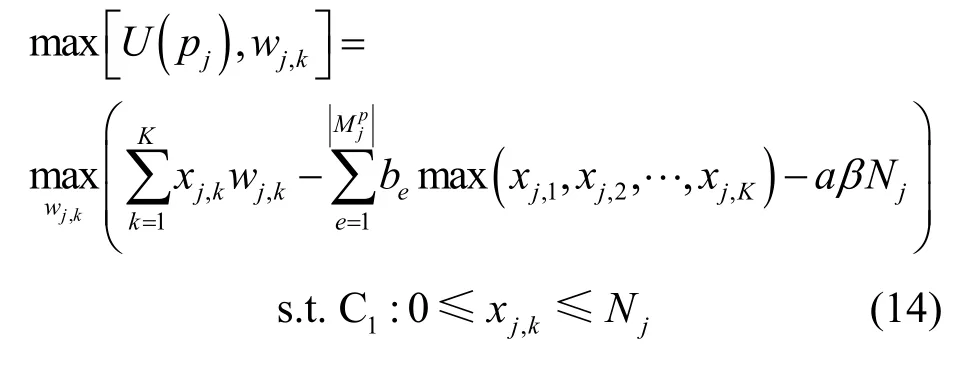
DP 的决策变量是为每个DC 提供的数据产品的单价。
2)下层:DC 的决策

DC 的决策变量是从某个DP 处购买的数据量。
3.5 求解算法
BLPP 描述了现实世界中自然发生的层次结构,但是很难求解,甚至最简单的线性双层规划问题也被证明是NP 难的[26]。由于所提模型涉及许多变量和非线性的效用函数,且下层目标函数是非凸的,因此很难使用经典算法求解[27]。在下层,DC遍历DP 的产品,可以得出最优的决策。在得到DC 的决策后,BLPP 问题就退化为单个多目标优化问题。因此,本文提出了基于NSGAII 的BLPP求解方案。
NSGAII 算法是一种中心化的优化算法,由一个节点来计算所有的目标函数,需要知晓DP 和DC的完整参数(如be、、λk、qj,k等)来计算U(pj)和U(ck)。这些信息中包含了DP 和DC的隐私。因此,本文对NSGAII 进行了改进,提出了协作式NSGAII 算法,U(pj)和U(ck)分别由DP和DC 在本地进行计算,以免泄露隐私。DP 负责种群的产生,即提供给DC 的产品的价格,以及种群的遗传和变异。DC 从DP 提供的产品中进行选择,以决策从哪个DP 购买产品和所购买的数据量。AG负责非支配的排序,它可以避免DP 的一些自私行为产生的影响,例如欺诈性排序等,还可以加快算法的收敛速度。T和Genmax是需要设置的参数,T是种群中的个体数;Genmax是最大迭代次数,用来限制算法的迭代次数,当迭代次数达到Genmax时,算法会终止运行,并输出结果。协作式NSGAII 如算法1 所示。


本文所提交易匹配算法中,每次迭代内的计算复杂度是O(JT2),迭代进行的最大次数是Genmax,因此匹配算法的计算复杂度是O(GenmaxJT2)。
4 安全性分析和实验结果
4.1 安全性分析
本文所提基于联盟区块链的数据交易框架通过加密算法、数字签名等技术,可以满足以下与区块链相关的安全要求。
1)避免不可信第三方造成的数据泄露。在基于区块链的交易框架中,DP 会将数据产品直接传输给DC,避免了不可信第三方可能造成的数据泄露。
2)用户身份隐私保护。链上的交易记录中记录的都是DP 和DC 的钱包地址,而通过钱包地址很难挖掘出用户的真实身份。
3)数据不可篡改。联盟区块链的分散性质与数字签名相结合,确保了区块链上的数据不会被篡改。
4)没有双花。数字货币依靠数字签名来证明所有权以及公开的交易历史,可以防止双花。
同时,交易框架中一些机制的设定,也可以进一步保证交易的安全性与公平性。
1)交易过程中,DP 仅需提供数据的属性和数据量信息,DC 仅需提供属性需求信息,这些信息中并不包含可能泄露用户身份的隐私数据,这一设定有助于保护用户的身份隐私。
2)AG 对DP 数据的质量评估需要采样DP 的数据,这部分数据可能被泄露。为保证采样数据能够代表完整的数据,并且尽量少地泄露DP 的数据,需要设定合适的采样比例。为此,本文计算了不同采样比例下成功欺骗的概率。图3 展示了不同伪造数据占比的情况下,成功欺骗的概率随采样比例的变化。在伪造数据占比为0.2%、1%和2%的情况下,很难通过低的采样率来得到较低的欺骗成功率,但此时伪造数据对数据集的影响也很小。当伪造数据的占比达到5%、采样比例为5%时,成功欺骗的概率只有0.72%,这能够满足AG 的需求,而且5%的数据泄露对DP 来说也是可接受的[19]。

图3 不同伪造数据占比的情况下,成功欺骗的概率随采样比例的变化
3)在执行交易匹配算法时,由AG 进行非支配排序,相比于选定某一个DP 或DC 进行排序,可以保证排序的公平性,从而维护所有DP 与DC 的效用。为此设计了以下实验,分别由AG 和随机选取的某个DP(实验中选取了DP1)进行非支配排序,DP 在排序时会进行欺诈排序,即将自己的出价排在上层,实验结果如图4 所示。

图4 AG 和DP1分别进行排序时效用函数的对比
从图4 中可以看出,当DP1进行排序时,可以提高自己的效用,但会使DP 和DC 的平均效用下降,即损失了其他DP 和DC 的效用。因此,采用AG 进行排序有助于维护所有DP 与DC 的效用。
4.2 实验结果
实验使用北京的空气质量数据来提供空气质量预测服务[28]。该数据集包括12 个空气质量监测站点的空气污染物数据,每个监测站点被视为一个DP。空气质量数据来自北京市环境监测中心。每个空气质量监测站点的气象数据均与最近的气象站相匹配。时间段是从2013 年3 月1 日到2017 年2 月28 日。每个数据集都包含35 064 条数据样本。每条样本包含时间、PM2.5、PM10、SO2含量等17 种属性。为了使这12 个DP 的数据产生显著差异,实验中删除了某些DP 数据的一些属性,并给数据集加入了不用程度的噪声。在实验过程中,设AG 的采样比例为5%,即β=5%。AG 使用经典的机器学习算法(随机森林回归算法)进行数据质量评估。实验虚拟了100 个DC,即K=100。在DC 中,一半DC 是经验丰富的,具有属性相关性的知识,利用式(12)进行计算;另一半DC 没有经验,利用式(11)进行计算。设定1 000 条数据样本为单位数据。
为了展示协作式NSGAII 的收敛性,图5 和图6分别给出了DP 和DC 的效用随迭代次数的变化。

图5 DP 的效用随迭代次数的变化

图6 DC 的效用随迭代次数的变化
从图5 和图6 可以看出,随着迭代次数的增多,DP 和DC 的效用都逐渐增长。当达到一定的迭代次数后,DP 和DC 的效用逐渐趋于稳定。从所有DP和DC 的平均效用来看,算法在30 次之内可以达到收敛。就迭代次数而言,30 次是满足用户需求可接受的数量。
为了体现效用函数的灵敏性,实验中对DP 和DC 进行了差异化处理。针对DP,对数据的属性和数量进行了调整,有些DP 只能提供一部分属性,并且在数据集中增加了不同程度的噪声。为模拟不同DC 的需求,实验中设定了多样化的属性需求、数据量需求、偏好以及对属性相关性是否熟悉等参数。DP 和DC 的效用函数分别如图7 和图8 所示。
从图7 和图8 可以看出,实验中对DP 和DC的差异化处理在他们的效用上得到了体现,这说明效用函数对DP 和DC 的参数具有灵敏性。
为了验证协作式NSGAII 的可扩展性,图9 和图10分别给出了迭代次数随DP 和DC 数量增长的变化。
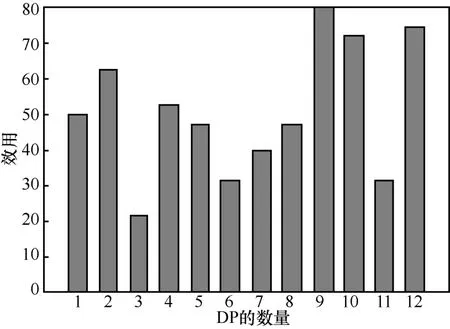
图7 DP 的效用函数

图8 DC 的效用函数
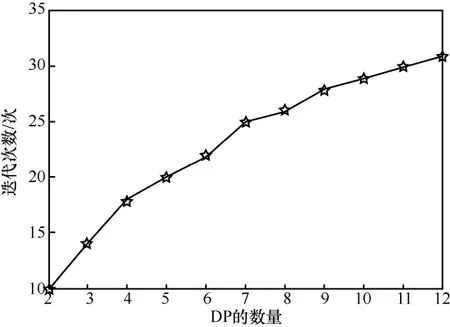
图9 迭代次数随DP 数量增长的变化

图10 迭代次数随DC 数量增长的变化
从图9 可以看出,随着DP 数量的增加,迭代次数也随之增加,并且两者近似成正比。从图10可以看出,随着DC 数量的增加,迭代次数的增长速度逐渐减慢并最终趋于稳定。根据对数据交易市场的调研发现,对于特定类型的数据,数据市场基本是寡头市场的形式,DP 的数量不会太多,因此不会导致迭代次数的大幅增加。而对于DC 的增加,该算法具有很好的收敛性。这表明协作式NSGAII是可扩展的,可以应用于大规模的用户。
在模型的构建中,考虑了数据属性的影响。当不能完全满足DC 属性需求或完全满足属性需求的数据价格过高时,DC 可以通过使用较低的价格来购买较少属性的数据以提升自身的效用。具有较少属性的DP 可以通过使用较低的价格将数据卖给更多的DC,从而提升效用。为了验证这种考虑是否有助于提高DP 和DC 的效用,图11 和图12 分别给出了DP 和DC 的效用对比。
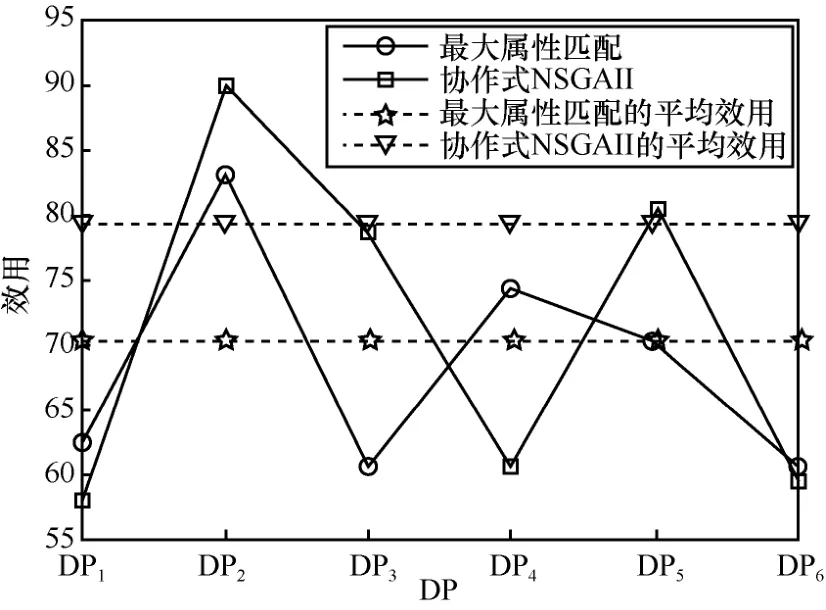
图11 DP 的效用对比
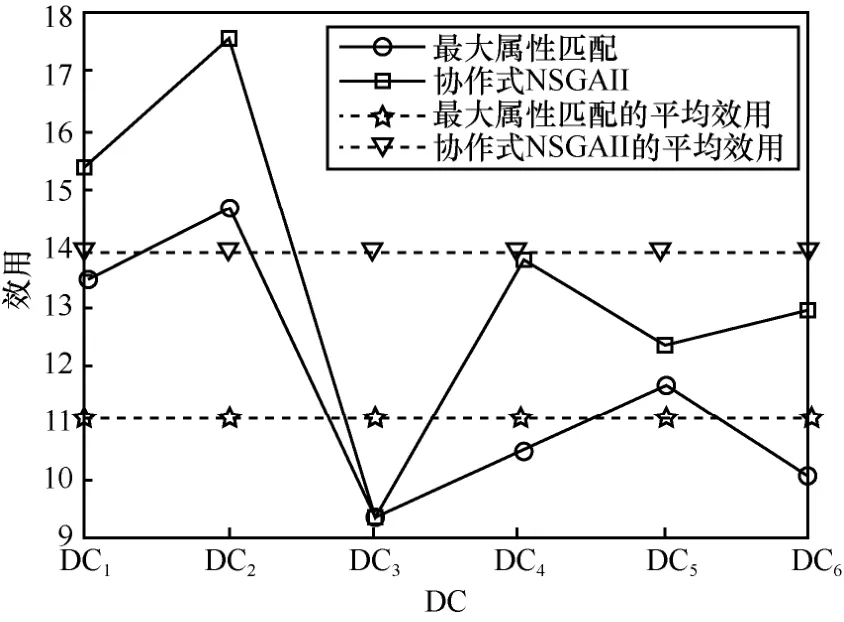
图12 DC 的效用对比
图11 中,DP1~DP6是从12 个DP 中选取的6 个,他们在数据属性、数据数量及添加的噪声方面存在区别,具体参数如表2 所示。

表2 DP 的具体参数
表2 中,每单元包含1 000 条数据,增加的高斯白噪声分别为Ⅰ、Ⅱ、Ⅲ和Ⅳ这4 个等级,对应的噪声量分别为0~2%、4%~6%、8%~10%和12%~14%。
图12 中,DC1~DC6是从100 个DC 中选取的6 个,他们在属性需求、数据量需求、个人偏好等方面存在区别,具体参数如表3 所示。
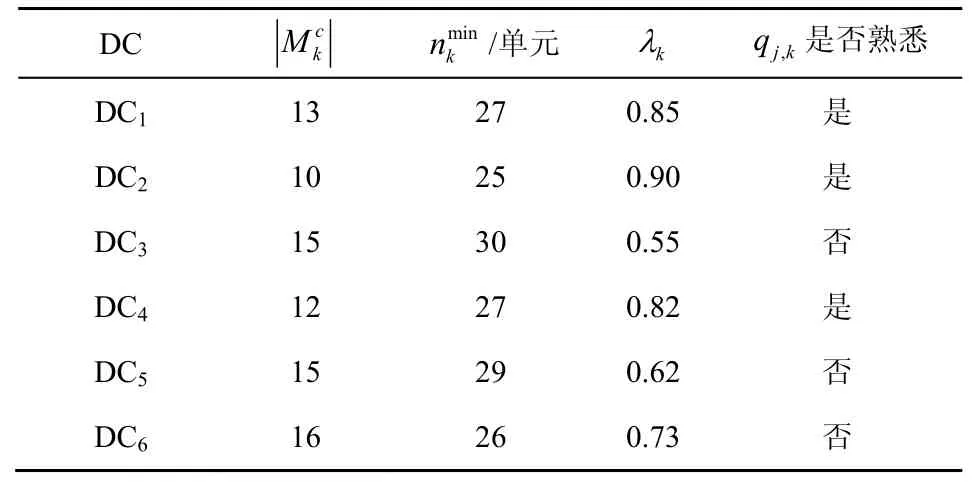
表3 DC 的具体参数
从实验结果可以看出,协作式NSGAII 取得了很好的效果。最大属性匹配算法是DC 将购买最能满足其属性需求的数据产品。在应用最大属性匹配算法的情况下,从DC 的角度来看,他们的产品选择要小得多,因此他们可能无法实现最高的效用。从DP 的角度来看,具有丰富属性的DP 将出售更多的数据,而具有较少属性的DP 则难以出售数据,最终降低了总体效用。因此,考虑数据属性在数据匹配过程中的影响,对DP 和DC 的效用函数具有一定的改善作用。
在实际的数据挖掘中,数据属性与任务的相关性对最终的模型具有很大的影响。在某些实验中,甚至使用PCA 等算法过滤掉一些属性。相关性的考虑可以促使DC 选择具有更大相关性的属性,使用较少的属性来获得更好的数据挖掘结果,从而降低成本并提高效用。为了显示这种效果,图13 给出了是否考虑相关性的情况下DC 效用的对比。

图13 是否考虑相关性的情况下DC 效用的对比
从图13 可以看出,通过考虑属性的相关性,DC 的效用得到了改善。
为了进一步展示协作式NSGAII 的有效性,将它与其他几种算法进行了比较。时间匹配算法是区块链系统中常见的基于时间戳的匹配方案。数据质量匹配算法是Yu 等[13]提出的基于数据质量的匹配算法。社会福利最大化是Cao 等[11]提出的一种社会福利最大化的数据交易算法。利润最大化是Jiao 等[12]提出的一种以最大化代理利润为目标的匹配算法。DP 和DC 的平均效用在不同算法上的对比分别如图14 和图15 所示。

图15 DC 的平均效用在不同算法上的对比
从图14 和图15 中可以看出,协作式NSGAII取得了最佳效果,它综合考虑了数据质量、数据属性、属性相关性以及消费者竞争的影响,使DC 和DP能够根据自身的情况更细粒度地执行数据交易,从而提升了他们的效用。
为进一步展示协作式NSGAII 的效果,将它的实验结果与Gurobi 优化工具箱的结果进行了对比,结果如图16 所示。

图16 协作式NSGAII 与Gurobi 的对比
Gurobi 优化工具箱是一种应用广泛的优化问题求解工具箱,它的计算结果可以认为已经接近全局最优解。从实验结果可以看出,协作式NSGAII 的实验结果与Gurobi 的结果极其相近,这在某种程度上说明了协作式NSGAII 的实验结果很接近全局最优解。
5 结束语
为了提高数据交易的有效性,本文提出了一种基于联盟区块链的分布式交易框架。该框架可在不依赖第三方的情况下实现DP和DC之间P2P的数据交易。在此框架下,本文还提出了双层多目标优化模型,以优化DP 和DC 的效用函数,模型构建过程中考虑了数据属性、数据质量、属性相关性以及消费者竞争的影响。为求解此模型,提出了一种协作式NSGAII,通过DC、DP 和AG 的合作来得到该模型的解。最后,基于北京空气质量数据的实验表明,所提算法在DP和DC 的效用函数方面可以实现更好的性能。
猜你喜欢
建材发展导向(2021年7期)2021-07-16
中国药学药品知识仓库(2021年18期)2021-02-28
科学(2020年5期)2020-11-26
科学(2020年6期)2020-02-06
红楼梦学刊(2020年3期)2020-02-06
冰雪运动(2018年3期)2018-12-29
金桥(2018年7期)2018-09-25
经济研究导刊(2016年30期)2016-12-24
读书(1996年3期)1996-07-15
