
改进的PCA-LDA人脸识别算法的研究
2021-03-08 01:06:16房梦玉马明栋
计算机技术与发展 2021年2期
房梦玉,马明栋
(1.南京邮电大学 通信与信息工程学院,江苏 南京 210003;2.南京邮电大学 地理与生物信息学院,江苏 南京 210003)
0 引 言
自20世纪90年代以来,人脸识别逐渐成为模式识别和人工智能领域的研究热点[1],例如身份验证、门禁系统、刑侦破案以及医学图像等方面[2],对于社会经济具有广泛的应用价值。主成分分析和线性鉴别分析是人脸识别中常用的两种经典算法。
主成分分析(principal component analysis,PCA)[2-3]是线性变换,一般是先把样本矩阵变成一维向量,然后将多个样本的向量组成一个矩阵。向量通过线性变换是线性独立的,并且变换后的向量用于提取特征[4-5]。PCA算法存在处理后维数高的问题,使得特征提取困难,特征计算复杂。但是,二维主成分分析(two-dimensional principal component analysis,2DPCA)算法[6]不需要将矩阵转换为矢量,而是直接将图像矩阵构建为图像离散矩阵。由于2DPCA方法用于直接计算人脸图像,因此它保留了更多的结构信息,并且计算协方差的准确性更高。
线性鉴别分析(linear discriminant analysis,LDA)[7]是高维图像投影到最能识别向量空间的基本思想,即将高维空间投影中的数据点投影到一条直线上,将维数缩小为一维,确保在投影空间之后,每个样本还可以具有类间的最大散布距离和类内最小的散布距离。
然而,传统的LDA算法存在“小样本”和“边缘类”的问题[8],这是由于类间样本在投影时发生重叠所造成的。而存在这些问题的主要原因是因为该算法过分强调了类间距离的大小。并且传统的LDA算法下的Fisher准则会导致“小样本”问题的出现,因为很难找到充足的训练样本,以此来保证类内散布矩阵的可逆性,所以就会丢失很多有用的辨别信息。这些问题使识别率在一定的空间维数下达会到最大值,然后再当维数升高时,识别率会逐渐降低。基于以上出现的问题,“PCA+LDA”算法[3,9-10]解决了这个问题,它不仅会保持LDA算法的优势,也会通过PCA算法改善LDA的缺陷。首先利用PCA算法实现降维,然后通过LDA算法投影到最佳方向,使Fisher准则最大,根据邻近原则实现识别,也使得识别率随着维数升高逐渐增加。由于PCA算法实现的降维损失是由样本类间及样本类内的离散矩阵的零空间来交换的,但是有用的分类信息存在于类内离散矩阵零空间中,如果它丢失了,就会失去一些有效信息。
为了保存“最有辨识力”的信息,该文提出了2DPCA融合改进的LDA算法,该算法将一维主成分分析优化为二维主成分分析,对LDA算法中的类间离散度矩阵和Fisher准则进行修改,使得该算法在提取特征时更快更好,也保存了“最有辨识力”的信息。
1 相关工作
1.1 主成分分析
主成分分析方法是由M.Turk和A.Pentland提出来的[2],是一种可以对信息进行处理、压缩和抽取的有效方法,并且在降维和特征提取上效率较高。实质上PCA方法是基于K-L变换原理[11],对数据进行特征抽取,构成特征空间,然后将测试集投影到特征空间,得到投影系数,从而对人脸图像比对,进行识别。
如果人脸库有N个人脸图像,用M1,M2,…,MN表示人脸特征向量,由下式得到人脸库中人脸图像的平均脸:
(1)
人脸库中人脸图像与平均脸的均差为:
σi=Mi-Mave
(2)
PCA的构造协方差矩阵为:
(3)
求出矩阵的特征值λi和特征向量yi来构造特征脸空间,由于其维数较大,一般采用奇异值分解(singular value decomposition,SVD)[12]的方法求矩阵的特征值和特征向量。
特征值λi及其正交归一化特征向量xi,当e的值超过90%,即认为所选的t个特征值的贡献率已经包含了大部分信息。贡献率指选取的特征值的与总的特征值的和的比值,即:
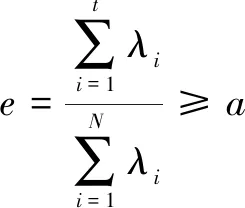
(4)
求出原协方差矩阵的特征向量:
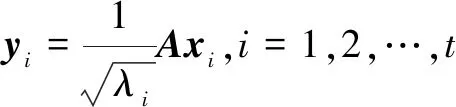
(5)
特征空间:
I=(x1,x2,…,xt)
(6)
将各样本与平均值做差投影到特征空间,即:
Ωi=ITσi,i=1,2,…,N
(7)
PCA算法训练以及识别流程如图1所示。
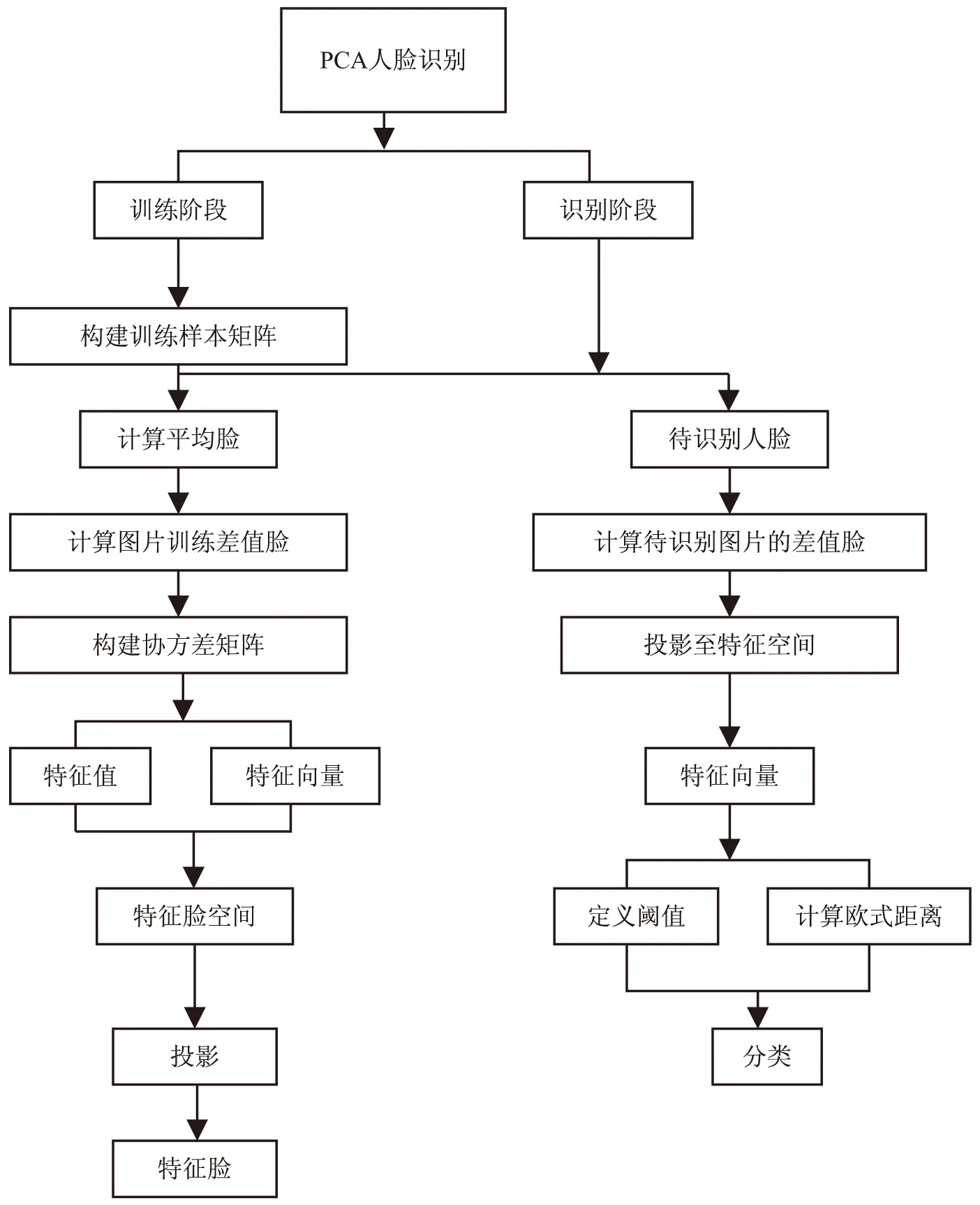
图1 PCA算法训练及识别流程
1.2 线性鉴别分析
LDA算法是首先对特征进行提取,利用提取的特征区分不同类别,聚集相同的类别。也就是求类间和类内离散度比值最大的特征,即Fisher准则函数[13]。类间离散度越大越好,类内离散度越小越好。这就要求提取的特征最具有判断力。
传统的LDA算法具体定义如下:
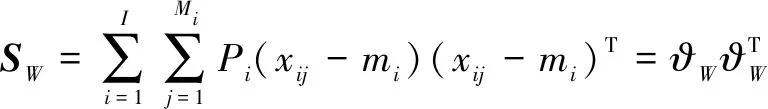
(8)
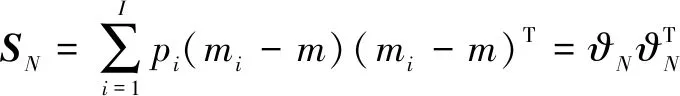
(9)
其中,SW为类内离散度矩阵,SN为类间离散度矩阵,I为包含的类数,M为样本总数,Mi(i=1,2,…,I)表示第i类的样本数量,mi为各个类模式的平均值。
I类的模式可以表示为:
xi={xi1,xi2,…,xiMi}
xij(i=1,2,…,I;j=1,2,…,Mi)
(10)
LDA的目标是要寻找变换V,当SW非奇异时,使得Fisher准则最大:
(11)
由下式得到Vi(i=1,2,…,m)的解:
SNVi=λSWVi
(12)
其中,Vi(i=1,2,…,m)就是前m个较大的特征值λ所对应的特征向量组成的矩阵。
1.3 主成分分析与线性鉴别分析融合
将PCA算法与LDA算法构造的特征子空间进行融合,然后将训练样本与测试样本分别朝该融合特征空间投影,获得识别特征。图2为PCA与LDA算法融合的原理过程。
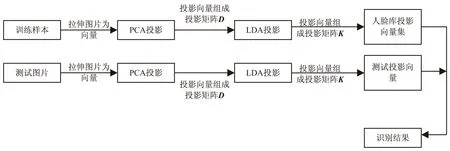
图2 PCA-LDA算法的原理过程
2 改进的PCA-LDA人脸识别算法的研究
2.1 二维主成分分析
二维主成分分析和PCA相似,都可以对特征进行有效的提取,但是不同于PCA方法的是2DPCA不需要将图像矩阵转换成向量[14],直接由原始样本的图像矩阵得到图像协方差矩阵,从而得到特征值和特征向量[15]。
训练样本的平均图像为:
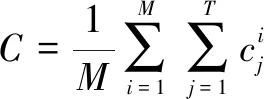
(13)
计算样本的协方差矩阵:
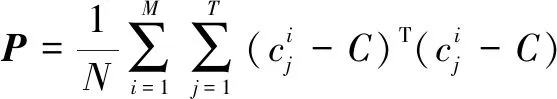
(14)
求P矩阵的特征值,对特征值排序,选取m个最大的特征值x1,x2,…,xm对应的特征向量X1,X2,…,Xm,对特征向量做正交化,求得的向量作为投影空间X。
在2DPCA中,求得的投影空间矩阵Y用来衡量准则函数F(W)中W的优劣:
F(W)=tr(CW)
(15)
其中,CW是投影矩阵Y的协方差矩阵,tr(CW)是CW的迹,且
CW=WTE{[x-E(x)]T[x-E(x)]}W
(16)
选取的特征向量为:
i≠j;i,j=1,2,…,m
(17)


(18)
2DPCA不像PCA需要将原始图像转成一维向量,直接利用原始图像矩阵得到协方差矩阵,避免了图像拉伸时,破坏图像的结构。所以2DPCA比PCA算法保留了更多的结构信息,计算协方差更为准确。
2.2 改进的线性鉴别分析
传统的LDA存在两个突出问题:(1)当样本维数大大超过训练样本的个数时,就会产生“小样本”问题;(2)由“小样本”问题导致的边缘类的特征空间解问题[16]。
针对传统LDA所固有的问题,该文提出了两种改进方法:
(1)对类间离散度矩阵和Fisher准则做出修改[17]。
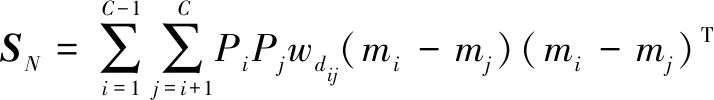
(19)
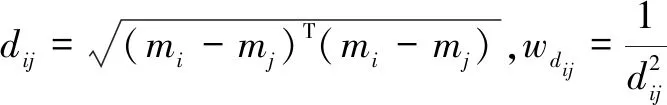
(20)
其中,dij是两个类别之间的欧氏距离,wdij是加权函数。
新的Fisher准则:
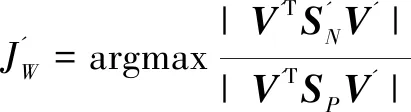
(21)

(22)
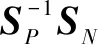
(2)采用Direct-LDA(D-LDA)算法去掉SN的零空间来降维[17-18]。
(23)
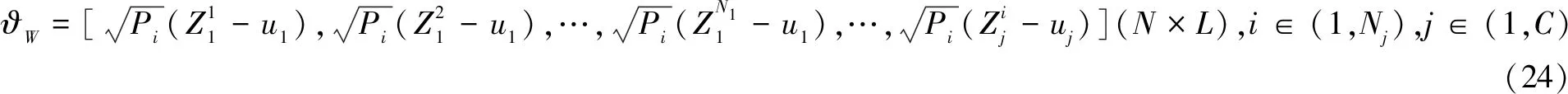
对于任意矩阵,LTL矩阵的特征向量为x,特征值为λ,那么可得LTLx=λx[16]。LTL特征向量到LLT特征向量为x→Lx。那么可以推导出,LLTLx=λLx。
2.3 二维主成分分析与改进的线性鉴别分析融合
2DPCA算法比PCA算法识别率高,特征抽取时间短;改进的LDA算法改善了传统的LDA算法的“小样本问题”和“边缘类问题”。因此,针对这两种方法的优点,将两种算法进行融合。文中算法第一步将训练样本进行2DPCA操作,产生新的特征空间矩阵,第二步使用改进的Fisher准则选择投影轴。图3为算法的整体流程。
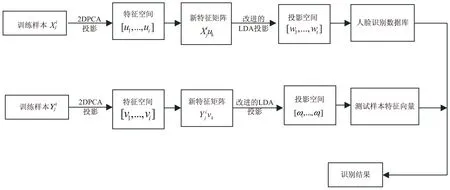
图3 算法的原理过程
3 实验结果与分析
实验直接采用ORL[19]人脸库中的图像。
图4是PCA-LDA算法、2DPCA算法、改进的LDA算法、2DPCA-改进的LDA算法的识别率对比结果。
传统的PCA算法识别率较低,而传统的LDA算法在一定的空间维度下,识别率较高,但是会出现最大值,只适用于特定维数空间。由图4可以清楚地看到,PCA-LDA算法在15~55维数间,保持上升趋势,显然克服了LDA存在的缺陷, 与2DPCA达到的识别率差不多。而改进的LDA算法的识别率比PCA-LDA算法的识别率要高,所以组合2DPCA与改进算法的LDA,融合改进后算法的优点,使得文中算法识别率在任何维数,比其中任何一种算法的识别率都要高。
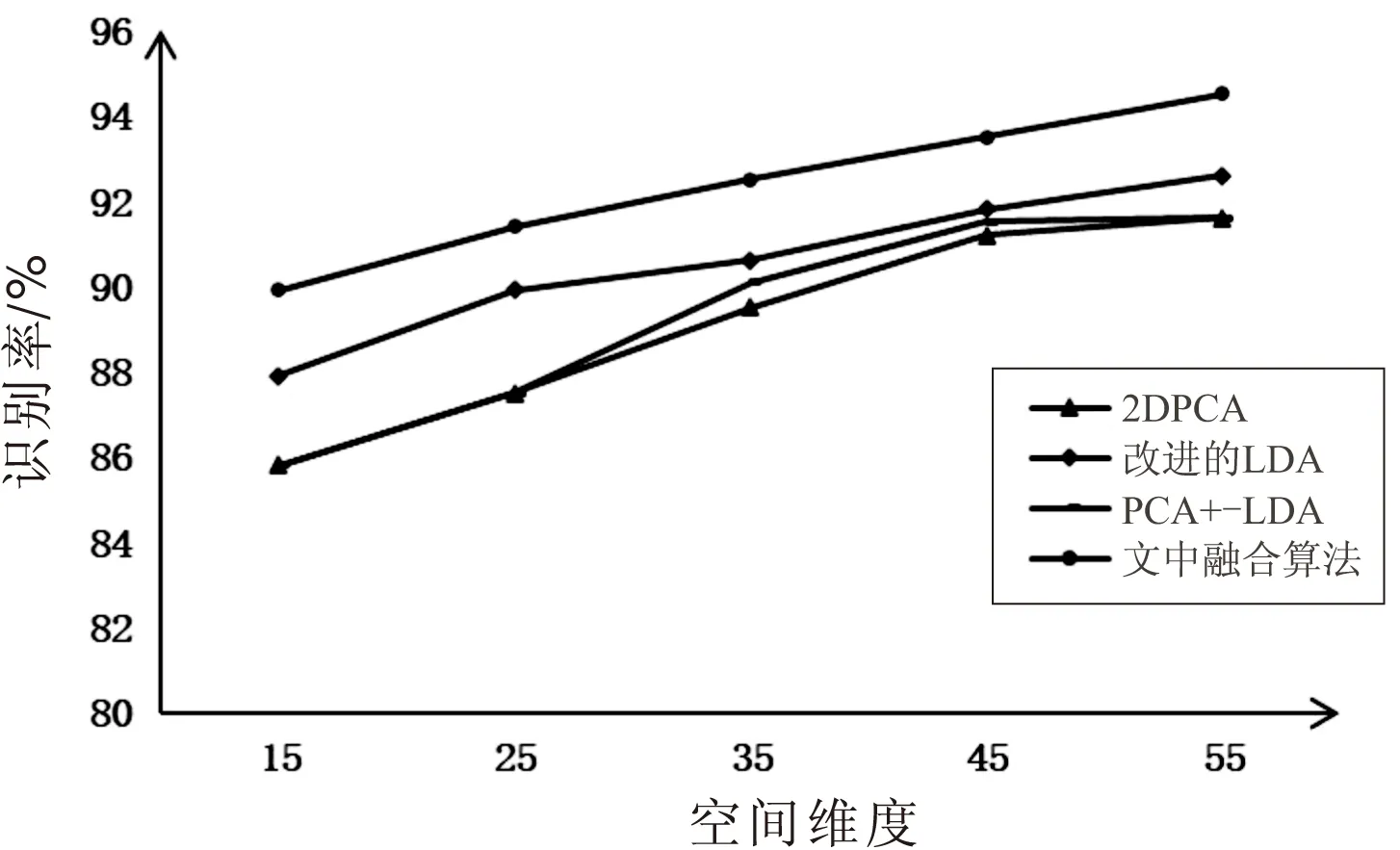
图4 各算法识别率对比
4 结束语
提出了2DPCA融合改进的LDA算法。该算法首先将一维主成分分析优化为二维主成分分析,对训练样本做二维主成分分析,然后对LDA算法中的类间离散度矩阵和Fisher准则做出修改,根据改进的线性鉴别分析,按照新的Fisher准则比的大小选择特征向量作为投影轴。该算法基于PCA-LDA算法加以改进,克服了PCA-LDA算法存在的缺陷,保存了“最有辨识力”的信息,同时还使得在特征提取时更快更好。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
保定学院学报(2022年2期)2022-04-07 02:26:50
无线互联科技(2020年22期)2021-01-11 13:52:34
弹箭与制导学报(2020年2期)2020-09-01 02:08:56
计算机工程(2020年3期)2020-03-19 12:24:50
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
传感器与微系统(2018年7期)2018-08-29 00:44:42
中国交通信息化(2018年3期)2018-06-13 03:27:58
许昌学院学报(2018年4期)2018-05-02 12:27:37
自动化学报(2017年4期)2017-06-15 20:28:55
