
融合语法规则的双通道中文情感模型分析
2021-03-07 05:15邱宁佳王晓霞王艳春
计算机应用 2021年2期
邱宁佳,王晓霞,王 鹏,王艳春
(长春理工大学计算机科学技术学院,长春 130022)
(*通信作者wpeng@cust.edu.cn)
0 引言
近年来对文本进行情感分析成为了自然语言处理领域的重要分支,进行有效的情感分析能够帮助用户及时掌握所在领域的情绪动态。传统的文本情感分类方法主要为基于情感词典与基于机器学习的方法。在基于情感词典的研究方法上,Araque 等[1]使用语义相似性度量与嵌入式表示结合使用,该模型表明了词汇的选择对跨数据集性能有影响;Zhang等[2]提出了一种基于情感词典的方法,解决了中文文本情感分析问题;Xu 等[3]提出的基于扩展情感词典的方法对评论文本的情感识别具有一定的可行性和准确性。此外,对于情感词典跨数据集的适用性问题,Hung[4]根据上下文信息构建适合领域的情感词典,并将其与偏好向量模型相结合,实现了IMDB和hotels.com 数据集口碑质量分类的显著改进;Khoo 等[5]也提出了新的通用情感词典WKWSCI(Wee Kim Wee School of Communication and Information),将其与常用的五种情感词典进行比较后也取得了不错的分类成绩。在基于机器学习的研究方法上,Singh 等[6]利用了朴素贝叶斯、J48、BFTree 和One Rule(OneR)四种机器学习分类器对IMDB 电影评论数据集进行了实验,对比分析了四种分类器各自的性能;Anggita等[7]使用粒子群优化(Particle Swarm Optimization,PSO)算法优化了朴素贝叶斯和支持向量机(Support Vector Machines,SVM),提高了原算法的分类精度;对产品评论进行情感分类时,Tama 等[8]采用了朴素贝叶斯算法得到了80.48%的分类准确性。基于情感词典的分类过分依赖于构建的情感词典,通用性不强;而基于机器学习的方法通常需依赖复杂的特征过程,且人工标注成本较高。
深度学习在不同情感分析领域取得了优异成绩,现已成为文本情感分析的主流技术。陈珂等[9]利用多通道卷积神经网络(Multi-Channels Convolutional Neural Network,MCCNN)模型使其从多方面的特征表示学习输入句子的情感信息;Long 等[10]将双向长短时记忆(Bidirectional Long Short-Term Memory,Bi-LSTM)网络与多头注意力机制相结合对社交媒体文本进行情感分析,克服了传统机器学习中的不足;孙凯[11]、李洋等[12]、赵宏等[13]将卷积神经网络(Convolutional Neural Network,CNN)与Bi-LSTM 融合起来,解决了现有情感分析方法特征提取不充分的问题,并分别通过实验表明了该融合模型在实际应用中具有较大的价值;同时,Wang 等[14]研究了树形结构的区域CNN-BiLSTM 模型,提供了更细粒度的情感分析,在不同语料库上都取得了不错的分类效果。同时,为了充分发挥语法规则在中文文本中的重要性,学者们还尝试将其融入神经网络中,如卢强等[15]将语法规则与Bi-LSTM相融合,何雪琴等[16]则将其与CNN 相融合,通过设置对比实验,各自都在不同数据集上取得了更好的分类效果。
针对上述研究现状,本文融合语法规则构建双通道中文情感模型,首先设计语法规则对文本进行预处理,以保留情感倾向更明显的文本;然后使用CNN 的强语义特征提取能力在不同窗口大小得到粒度不同的局部情感特征,同时为了弥补语法规则处理时可能忽视上下文信息问题的不足,利用Bi-LSTM挖掘到文本时间跨度更大时的语义依赖关系,获取到包含上下文信息的全局特征;最后将融合后的局部特征与全局特征使用分类器对文本进行情感分类。
1 中文语法规则的构建
为了解决因中文文本语义多样化而导致CNN 情感特征提取困难的问题,本文考虑首先设计语法规则对文本进行初步情感信息清洗,降低文本语义复杂性,从而获取到情感倾向更加明确的文本信息;再使用Word2Vec模型进行训练得到规则特征向量后作为CNN 的输入。通过中文文本语法规则研究发现:文本中的情感倾向词所在句直接表达了作者正面或负面情感;总结词则表明了文本的中心思想,直接影响了句子的情感倾向;而转折词则实现前后情感反转的作用。其中转折词分为两类:甲类转折词所在句带有明显的情感倾向;乙类转折词则起到过渡作用,所在句的内容不能够表达文本的情感倾向,其情感倾向常表现在余下语句中。为了充分发挥情感倾向词、总结词、转折词在文本情感倾向信息提取中的作用,本文将依据数据集进行这三类词的提炼汇总,设计出三类情感词典:EmoTendencyWords 情感倾向词词典、SumWords 总结词词典和TurnWords 转折词词典,然后根据这三类词典对中文文本进行语法规则设定,以获取情感倾向更加明确的信息,方便CNN 在训练时获取情感倾向特征。令W表示整个评论文本,Wi表示文本中的各个分句,定义该评论文本的分句集合为{W1,W2,…,Wn},W′则表示经语法规则处理后的文本。规则如下:
规则1 若评论文本W中通过匹配EmoTendencyWords情感倾向词词典,存在情感倾向词,则直接提取情感倾向词所在的分句Wi,然后根据情感倾向词词典直接判定评论文本W的正负面。
当文本中出现多个情感倾向词时,参照文献[16]提出的“主题词+直接分类法”进行该文本的情感倾向判定,通过主题词判定该情感倾向词是否有效,若无效则舍弃。具体方法为:首先根据数据集设定好种子主题词,利用Word2Vec 工具文本将文本转换为词向量表示wi={si1,si2,…,sik};然后计算词向量之间的欧氏距离来判断该分句与种子主题词之间相似度,阈值范围以内则为相关主题,表示该情感倾向词有效;最后统计有效正负面情感倾向词个数并比较,正面个数多则该文本W情感倾向为积极,反之则为消极。相似度计算公式如式(1)所示:
sim(w1,w2)=
∑
j=1,2,…,k(s1j-s2j)2(1)
规则2 若评论文本W中无情感倾向词,则与SumWords总结词词典进行匹配,若存在某总结词,则直接提取总结词后的分句Wi。若文本中出现多个总结词,为提高分类效率,默认只提取第一个总结词以后的分句Wi。
规则3 若评论文本W中无情感倾向词与直接分类词,则与TurnWords 转折词词典进行匹配,若存在甲类转折词,则直接提取该转折词之后的所有分句{Wi,Wi+1,…,Wn} ;若存在乙类转折词,则忽略该转折词所在分句Wi,提取评论其他内容{W1,W2,…,Wi-1,Wi+1,…,Wn} 。
规则4 若评论文本W均不属于上述三种情况,则直接保留原文本内容W。
利用语法规则提取情感倾向语句的流程如图1所示。

图1 利用语法规则提取情感倾向语句的流程Fig.1 Flowchart of extracting sentiment sentences using grammatical rules
文本W经语法规则处理后会先后出现四种情况:1)直接根据情感倾向词得到文本的情感分类结果;2)得到含有总结词的分句;3)得到判断甲乙类转折词的分句;4)得到原文本。如此处理后得到的文本W′,大部分相较原文本更加简短且具有明显的情感倾向,大大降低了中文文本的语义多样化,从而解决了输入到CNN 后训练时因文本语义复杂而导致的特征提取困难问题。
2 双通道神经网络
2.1 CNN通道
CNN 拥有局部感知与参数共享两大特点,每个神经元只需对局部进行感知,且在局部连接中,每个神经元的参数都是一样的,进行卷积操作时实际上是提取一个个的局部信息。因此对于规则处理后的文本W′,使用CNN 模型能够有效地提取出局部特征。CNN通道模型结构如图2所示。

图2 CNN通道模型结构Fig.2 Channel model structure of CNN
在CNN 模型训练中,经语法规则处理后得到评论文本W′,然后使用jieba 分词得到文本序列为x={x1,x2,…,xn},其中xn∈R(R表示文本数据集构成的词典),通过词嵌入技术Word2Vec 得到整个文本序列的词向量句子表示如式(2)所示,其中,xi表示wi对应的词向量,⊕为拼接操作。

将X作为卷积层的输入,通过大小为r*k的滤波器提取出不同位置的局部特征,计算公式如式(3):
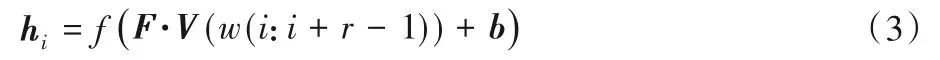
其中:F为滤波器大小,V(w(i:i+r-1))为X中从i到i+r-1 共r行词向量词组,b为偏置项。故通过卷积层后得到输出h=[h1,h2,…,hn-r+1]。由于卷积核共享存在着特征提取不充分的问题,需通过增加多个卷积核来弥补,通过固定参数的训练方法得到CNN 卷积窗口分别为3、4、5 时分类效果更好,故经过卷积操作后本文的卷积输出为h3、h4、h5。
然后对于卷积层的每一个输出向量h与Bi-LSTM 提取出的全局特征hblstm进行注意力池化操作以提取出更能够表达情感倾向的特征。其中,注意力池化是指通过式(4)、(5)计算出当前局部特征与全局特征之间的相似性,且相似性越高则为该局部特征分配更大的权重。
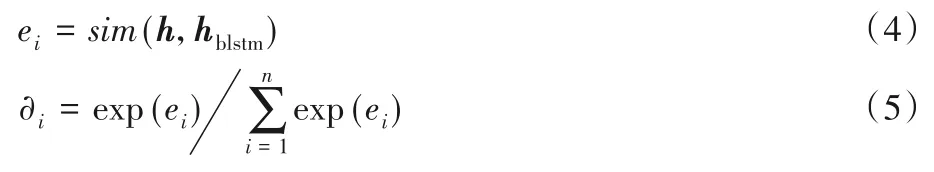
其中:函数sim()通过余弦函数计算局部特征与全局特征之间的相似度,∂i为权重。计算出权重后,最终的局部特征表示hcnn由式(6)得到。

2.2 Bi-LSTM通道
由于经语法规则处理后的评论文本W′可能会省略掉部分文本,从而导致了上下文信息缺失的问题,因此使用Bi-LSTM 模型来获取包含上下文信息的全局特征。模型结构如图3所示。

图3 Bi-LSTM通道模型结构Fig.3 Channel model structure of Bi-LSTM
将未经语法规则处理的文本经过jieba 分词以后利用Glove 工具训练得到词向量,再作为Bi-LSTM 模型的输入。其原理就是首先构建基于语料库的词共现矩阵,然后根据共现矩阵与Glove模型学习词向量。Glove模型综合了潜在语义分析(Latent Semantic Analysis,LSA)和Word2Vec 模型的优点,在高效清晰的地表达文本语义的同时考虑了全局的文本信息。设第i个单词的n维词向量表示为vi={w1,w2,…,wn},将每个单词向量V结合起来形成句子的矩阵表示形式Rs×n,其中,每一行是每个单词对应的词向量权重。设s代表单词总数,若确定了词向量权重的维度大小,则该矩阵的列也将确定,n代表词语维度。令vi∈Rn表示第i个词的n维词向量,则长度为s的文本表示为:

经过将单词转换为词向量,则句子中的每个词的词向量拼接最终组成了词向量矩阵,即V∈Rs×n。接着将词向量从前后两个方向输入模型,设定w、u、v、v′为Bi-LSTM 模型的权重,当前单元输入为xt,前一单元输入为ht-1,后一单元输入为ht+1。由式(8)得到上文的情感倾向特征,由式(9)得到下文的情感倾向特征,最终由式(10)得到了包含上下文信息的全局特征hblstm。

综上,由双通道神经网络得到了文本的局部hcnn与全局特征hblstm,并将两者作为本文提出的CB_Rule 模型特征融合的输入,以增强分类器中情感特征的全面性,从而提高情感分类精度。
3 融合语法规则的双通道中文情感分析模型
虽然经语法规则处理后的文本能够使CNN 获取到情感倾向更加明确的局部特征hcnn,但也存在因语法规则而存在的忽略上下文信息的问题,考虑使用Bi-LSTM 提取出的全局特征来作为局部特征被忽略问题的弥补,所以本文将其与Bi-LSTM 提取的全局特征hblstm融合起来。融合公式如式(11)所示:

融合即将hcnn与hblstm拼接在一起,一同作为全连接层的输入,并引入Dropout 机制,这样能有效避免模型对部分特征产生依赖,从而发生过拟合现象,最后将其输入到softmax 分类器中。融合流程如图4所示。
特征融合既充分利用了CNN 强大的文本特征提取能力,又发挥了Bi-LSTM 对时间序列信息强大的记忆力,最终能够让分类器得到的情感倾向特征h更加全面,最后通过分类器得到中文文本情感分类类别。分类公式如式(12)所示:

其中:Wh为权重矩阵,bh为偏置,y为情感类别。
同时本文将利用反向传播算法来训练模型,通过最小化交叉熵得到的损失函数来优化模型,如式(13)所示。

其中:c为情感类别数量,n为句子数量,pi为实际类别,yi为预测类别,λ为L2正则化权重,Θ包含了CNN 和Bi-LSTM 中的所有权重及偏置项。

图4 双通道特征融合流程Fig.4 Flowchart of double-channel feature fusion
综上,融合语法规则的双通道神经网络模型如图5所示。
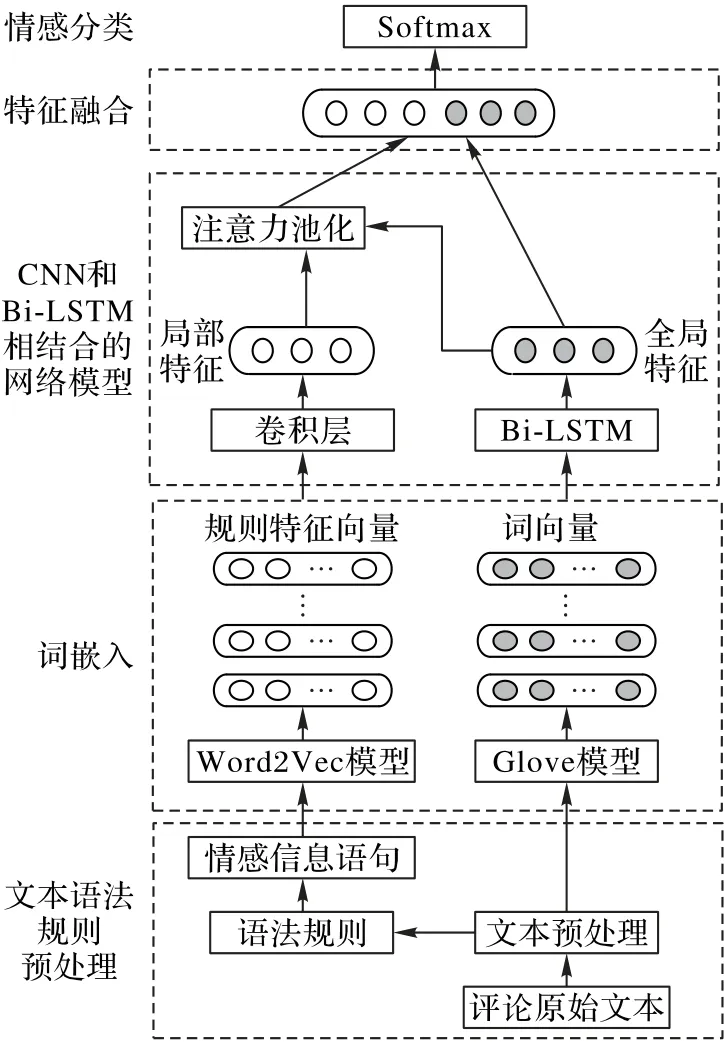
图5 融合语法规则的双通道神经网络模型Fig.5 Double-channel neural network model integrating grammar rules
由图5可知,模型的构建过程如下:
1)将文本预处理后的数据依据设定的语法规则获取到文本的情感信息语句,然后通过Word2Vec词嵌入工具转换成规则特征向量,再将规则特征向量输入到CNN 模型;同时将未经规则处理的文本经过Glove 工具转换成词向量,输入到Bi-LSTM模型。
2)在CNN 和Bi-LSTM 相结合的神经网络模型中,CNN 模型提取出文本的局部特征,其中将使用注意力池化的方法来提取出CNN 卷积层的局部特征,以此来判断哪些特征能够包含更多的情感信息;而Bi-LSTM 则用来提取出文本的全局特征。
3)将双通道神经网络模型输出的局部特征与全局特征进行融合后,输入到分类器中进行情感分类。
4 实验与结果分析
4.1 实验数据
本文所采用的实验数据为情感分析开源数据集online_shopping_10_cats 电商购物评论,数据对象有书籍、平板、手机、水果等十个类别,电商评论情感标签分为两类[0,1],积极评论情感标签为1,消极评论情感标签为0。共62 272条数据,其中正向评论31 351 条,负向评论31 421 条,数据集具体数据分布见表1。实验数据的训练集与测试集比例设置为8∶2。

表1 数据集的数据分布Tab.1 Data distribution of dataset
4.2 实验参数设置
本文融合神经网络模型中CNN 部分的参数及值如表2所示,Bi-LSTM部分的参数及值如表3所示。

表2 CNN部分的参数Tab.2 Parameters of CNN part

表3 Bi-LSTM部分的参数Tab.3 Parameters of Bi-LSTM part
针对不同数据集所需的情感词典不同,根据上文的规则设定,由本文实验所用的电商评论数据集得到的三类情感词典的部分关键词如下:
正面情感倾向词:推荐、值得、值、物超所值、强烈推荐、性价比高、质量不错、五星、好评、给力、满意等。
负面情感倾向词:不推荐、不值得、质量不行、性价比低、差评、不满意、失望、别买、一星、不值等。
总结词:总的来说、总之、总的感觉、总体、在我看来、综上所述、个人认为、反正、个人建议、整体等。
甲类转折词:但是、但、可是、却、不过、然而、所以、因此等。
乙类转折词:只是、只不过、但就是、而且、就是、虽然、如果等。
由电商评论数据集提取出的种子主题词有产品、快递、价格、质量、性能、包装、客服、外形等,种子主题词与待定主题之间相似度阈值范围设为0.8。
4.3 评价指标
本文将采用准确率Acc(Accuracy)、召回率Re(Recall)以及F1(F1值)作为实验评价指标,其他符号表示如表4所示。
准确率Acc表示测试集所有样本都正确分类的概率,计算公式如式(14):

召回率Re表示测试集分类结果中某情感标签中的真实类别占所有真实类别的比例,计算公式如式(15)所示。

F1 值是表示准确率Acc与召回率Re综合性能的指标,对两者加权调和计算得到最终分类效果,即
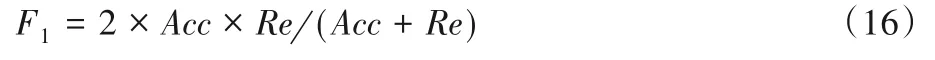
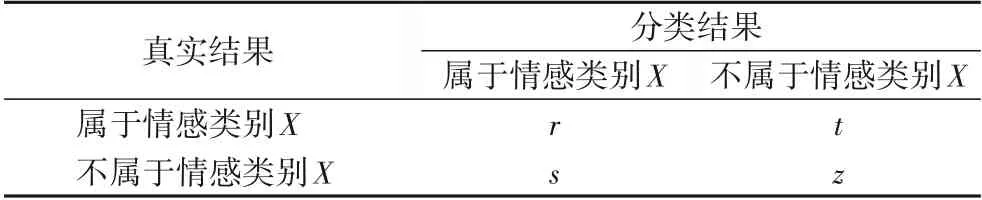
表4 分类类别混淆矩阵Tab.4 Confusion matrix of classification category
4.4 实验结果分析
4.4.1 语法规则可行性分析
随机选取电商评论中的10 000条数据来验证本文提出的语法规则对CNN 分类结果的影响,其中,r1、r2、r3为文中第一章提出的前三个规则,CNN 参数设置见表2,实验结果如表5所示。由表5 可以看出,本文根据情感倾向词、总结词、转折词设定的语法规则能够有效提升CNN 模型的分类精度,其中规则1 对模型的分类结果影响最大,F1值较CNN 模型提升了3.2 个百分点,表明情感倾向词对分类结果的影响比重高于总结词与转折词,通过提取有效情感倾向词更能够促进文本情感分类效果。虽然使用规则2 与规则3 的提升效果没有规则1 明显,但总体上都提升了CNN 模型的最终分类精度。这说明通过语法规则处理能够得到更加明确的情感倾向信息,进而帮助CNN提取到语义特征,提高分类精度。
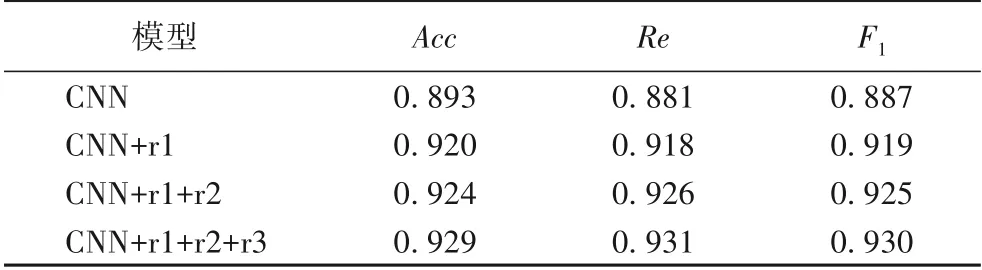
表5 语法规则对CNN分类结果的影响Tab.5 Influence of grammar rules on CNN classification results
同时,本文还将语法规则应用到了机器学习算法SVM上,并与CNN 模型进行对比实验,同样随机选取10 000 条数据,设定批大小batch 为64,迭代次数iteration 为157,数据集训练轮数epoch 为15,结果见图6。可以看出,语法规则应用到机器学习算法SVM 与传统CNN 模型上,分类准确率都得到了显著的提升,且准确率都随着epoch 的增加而增加,CNN、CNN_Rule、SVM、SVM_Rule 最终的准确率稳定在89%、93%、80%、86%左右,进一步有效验证了该语法规则的可行性。

图6 应用语法规则效果Fig.6 Effect of applying grammar rules
4.4.2 融合语法规则的双通道模型分类精度
为解决双通道模型特征融合时出现的过拟合现象,使用10 000 条电商评论文本作为实验数据,在模型全连接层加入Dropout,并通过实验对比了Dropout 值在0.1~1 的准确率变化,最终选择0.5 作为Dropout 的最适值,实验结果如图7所示。

图7 Dropout参数对模型性能的影响Fig.7 Influence of Dropout parameter on model performance
为验证本文CB_Rule 模型的性能,在相同实验环境下使用表1 数据进行实验,并根据图7 的实验结果选取Dropout 为0.5。首先分别利用Word2Vec 和Glove 向量化工具将评论文本转换成矩阵向量,再构造单一的CNN、Bi-LSTM 模型以及双通道模型CNN_BLstm 模型与CB_Rule 进行对比实验,使用接受者操作特征曲线(Rceiver Operating Characteristic curve,ROC 曲线)下面积(Area Under Curve,AUC)值作为情感分类效果的评价指标,ROC 曲线如图8 所示。由图8 可知,Bi_LSTM 的AUC 值比CNN 模型高出0.9%,说明在中文情感分类任务中,上下文信息影响着分类结果,所以仅使用融合规则的CNN 模型进行情感分类时,就容易忽略上下文信息,造成模型分类性能下降。双通道CNN_BLstm 模型的AUC 值较传统的单Bi-LSTM、单CNN 模型分别高出2.8%、3.7%,究其原因,CNN 模型具有的局部感知与参数共享使其关注的是局部语义特征的提取,而较少考虑到上下文信息;反之,Bi-LSTM 由于其对时间序列的超强记忆功能,通过正反向LSTM传播得到了上下文信息,但也忽略了局部语义特征在中文情感分析中的重要性。这再次说明了将CNN 提取出的局部特征与Bi-LSTM 提取的全局特征融合起来对情感分类效果有着显著的影响。同时,将语法规则融入双通道模型中时,CB_Rule 模型的AUC 值又比双通道CNN_BLstm 模型提高了1.2%,验证了将语法规则融入其中更有助于情感特征的获取,提升神经网络分类效果。
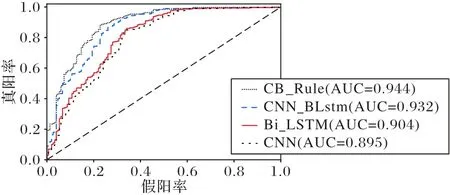
图8 CB_Rule模型与其他分类模型的ROC曲线Fig.8 ROC curves of CB_Rule model and other classification models
4.4.3 CB_Rule模型与其他模型的性能对比
为了验证本文提出的规则融合模型的情感分类性能,将本文提出的CB_Rule模型与文献[12-16]提出的模型在表1数据集上进行对比实验,其中各个模型的CNN 与Bi-LSTM 皆按照表2、3 进行参数设置,实验结果如表6 所示。其中:文献[12]提出的L-BiLSTM_CNN 模型将CNN 提取的局部特征与Bi-LSTM 提取的全局特征融合后使用分类器进行情感分类;Z-BiLSTM_CNN 为文献[13]构建的Bi-LSTM 和CNN 的串行混合模型,首先利用Bi-LSTM 提取上下文特征,再对上下文特征进行局部特征提取,最后使用分类器进行分类;R-Bi-LSTM 为文献[15]提出的融合语法规则的Bi-LSTM 模型,并采用Glove工具进行词向量训练;SCNN(Syntactic rules for Convolutional Neural Network)为文献[16]提出的融合句法规则和CNN 的旅游评论情感分析模型,但词向量训练采用Word2Vec模型。

表6 CB_Rule模型与其他模型的分类结果对比Tab.6 Comparison of classification results of CB_Rule model and other models
由表6 可知,本文所提出的CB_Rule 模型的准确率优于对比模型。将CNN提取出的局部特征和Bi-LSTM提取的全局特征进行融合时,L-BiLSTM_CNN 模型的准确率明显高于Z-BiLSTM_CNN 模型,说明直接并行提取出特征进行融合的效果优于串行提取出后再进行特征融合,故而本文采用了不同的词向量处理工具对文本数据并行处理。同时,本文提出的将语法规则融入双通道模型在准确率上较R-Bi-LSTM、SCNN 模型分别高出3.7 个百分点和0.6 个百分点,进一步验证了CB_Rule模型在情感分类上的有效性。
5 结语
进行情感研究对当今社会意义重大,本文针对传统的CNN 与Bi-LSTM 这类情感分类模型所存在的问题,提出了融合语法规则的双通道中文情感分析模型,将语法规则融入CNN中,训练得到更具有情感倾向的局部特征,同时为了解决语法规则处理后出现的忽略上下文信息问题,利用Bi-LSTM对之进行补充改进,最后将提取出的特征进行融合,将其输入到分类器中提高情感分类精度。在电商评论文本数据集上设计了语法规则的可行性分析、融合语法规则的双通道模型的分类精度以及CB_Rule 模型性能对比等实验,验证了本文提出的CB_Rule模型具有良好的情感分类效果。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
就业与保障(2021年23期)2021-04-06
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
时代英语·高一(2019年1期)2019-03-13
时代英语·高三(2017年1期)2017-03-01
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
电脑爱好者(2015年22期)2015-09-10
分析化学(2015年8期)2015-08-13
