
融合用户历史行为与社交关系的个性化社交事件推荐方法
2021-03-07 05:16孙鹤立贾晓琳
计算机应用 2021年2期
孙鹤立,徐 统,何 亮,贾晓琳
(西安交通大学电子与信息学部,西安 710049)
(*通信作者电子邮箱xlinjia@xjtu.edu.cn)
0 引言
随着移动互联网的发展,各种社交服务平台大量涌现,其中基于事件的社交网络(Event-Based Social Network,EBSN)受到越来越多的关注,如Meetup、Eventbrite、豆瓣同城等。EBSN 的快速发展,吸引了众多科研工作者对其进行研究。Liu等[1]在2012年首次给出了基于事件社交网络的定义,此后研究者们对EBSN 进行了广泛研究,提出了许多新的研究方向,如事件的流行因素发现[2]、事件的联合搭档推荐[3]、事件的参与人数预测[4]、群组的流行度预测[5]、线上线下的社交影响[6]等问题。基于事件社交网络中的用户之间不仅可以进行在线社交互动,也可以参加线下事件进行离线社交互动。随着基于事件社交网络中事件数量的增多,导致了平台中用户事件信息过载的问题。为了减轻信息过载带来的消极影响,各个EBSN 服务平台都推出了自己的解决方法,目前比较普遍的解决办法是为每个用户推荐其所在城市的事件,同时允许用户搜索事件。由于用户在参加线下事件时不仅要考虑对该事件的兴趣,同时也要考虑该事件举办的时间和地点等其他影响因素,所以仅根据用户所在城市推荐事件的方法不能够为用户提供满意的推荐结果,而用户根据平台预先设定条件搜索事件的方法则灵活性不足,因此基于事件社交网络中的个性化社交事件推荐问题引起了研究者的广泛关注。
在基于图模型的推荐方法中,研究者们通常将社交网络构建为一个图模型,将推荐问题转换为节点之间的接近度问题,图模型选择与查询节点之间转移概率较大的节点构成查询节点的推荐结果列表。Pham 等[7]提出了基于异构图的推荐算法(HeteRS),该算法将社交网络建模为异构网络来获取社交网络中的语义信息进行推荐;Liu等[8]将社交网络构建为图模型,然后执行随机游走算法并从用户参加过的活动中提取用户偏好,得到最终的推荐事件列表;Mo 等[9]将社交网络构建为异构网络,并使用逆向随机游走算法进行推荐;Liu等[10]在研究连续事件推荐时分别将社交网络构建为主图和反馈图,然后在图上执行随机游走算法进行社交事件推荐。
在基于影响因素的推荐方法中,研究者们在推荐过程中综合考虑多种因素来提升推荐效果。任星怡等[11]在研究社交网络中的兴趣点推荐时,综合考虑了地理位置、社交等因素;Macedo 等[12]在事件的推荐过程中考虑了待推荐事件的上下文信息、事件的地理位置信息以及用户的地理位置信息来提升推荐效果;Qiao 等[13]综合考虑了用户的线上和线下社交关系、事件的地理位置和用户的隐性评分等因素来进行事件推荐;Liao 等[14]首先构建事件参与网络和物理邻近网络两个异构网络,然后使用它们来提取用户的潜在偏好和潜在社交关系等重要因素。
近年来,深度学习技术的发展为解决基于事件社交网络中的推荐问题提供了新的解决思路。Shan 等[15]于2016 年提出的Deep Crossing 模型是使用深度学习技术解决推荐问题的经典方法。该模型通过加入嵌入层将稀疏特征转化为低维稠密特征,然后将分段的特征向量连接起来,再通过多层残差网络完成特征的组合、转换,然后进行推荐。Cheng 等[16]提出了Wide&Deep 模型,该模型Wide 部分和Deep 部分分别具有记忆能力和泛化能力;Song 等[17]则使用Transformer 网络中的多头自注意力机制[18]来学习不同特征的权重提出了自动特征交互模型(AutoInt);Zhou 等[19]提出了融合注意力机制的深度兴趣网络(Deep Interest Network,DIN)模型,该模型从用户的历史行为中提取用户特征,然后使用激活单元使模型能够根据不同候选物品调整用户历史行为中不同物品的权重;Wang等[20]使用TextCNN 方法从用户历史参与的事件中提取用户偏好提出了深度用户社交事件推荐(Deep User Modeling framework for Event Recommendation,DUMER)模型。
本文使用深度学习方法,同时结合基于事件社交网络的特点,从用户历史行为中提取用户偏好,使用注意力机制根据候选推荐事件自动学习与用户关联的历史社交事件的权重。本文在建立用户模型时,引入表示用户偏好的负向量,并从用户的社交网络中提取用户的社交关系向量。此外,在推荐过程中考虑了事件的时间地点信息以及用户兴趣爱好随时间变化等影响因素。在真实数据集上的实验结果表明,本文提出的深度用户偏好和社交关系模型(Deep User Preference and Social Relationship Model,DUPSRM)在多个评价指标上优于对比模型。
1 基于事件的社交网络
EBSN 模型如图1 所示,主要包含用户、群组和事件三种实体,用户之间存在线上社交互动和线下社交互动。
给定基于事件的社交网络SN={V,R},V表示其中的实体集合,R表示关系集合。V={U,G,E},其中U为用户集合,G表示群组集合,E表示离线事件集合;R={Ron,Roff}表示用户之间的关系集合,Ron表示用户之间的在线社交关系,Roff表示用户之间的离线社交关系。
本文将EBSN 中的社交事件推荐问题转化为目标用户是否会参加候选推荐事件的二分类问题。对于目标用户表示用户u参与的事件序列,表示用户u拒绝参与的事件序列,Nu=表示以用户u为中心的在线社交网络和离线社交网络中的社交邻居集合,e表示候选推荐事件。社交事件推荐问题可以描述如下:对于目标用户u,候选推荐事件e,目标用户u的参与事件序列和拒绝参与事件序列,以及用户的社交邻居集合Nu,判断目标用户u是否会参与候选推荐事件e。

图1 基于事件的社交网络Fig.1 Event-based social network
2 深度用户偏好和社交关系模型
本文在对用户建模时,考虑了用户的历史行为特征以及用户的潜在社交关系;在对社交事件建模时,考虑了事件所在群组的类别特征、事件的地理位置特征和事件的时间段特征。图2 展示了DUPSRM 的结构,主要由输入层、嵌入层、双向门循环单元层(Bidirectional Gated Recurrent Unit Layer,Bi-GRU Layer)、权重层以及输出层组成。
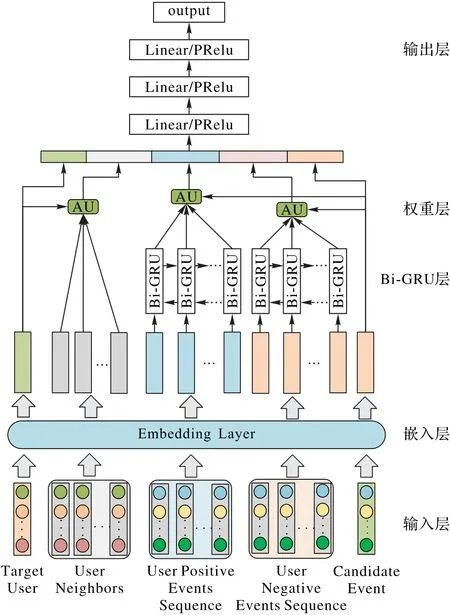
图2 DUPSRM结构Fig.2 Structure of DUPSRM
2.1 输入层
输入层接收输入数据,输入数据主要包含用户数据和候选推荐事件数据两个部分,其中用户数据部分主要包含了目标用户、目标用户社交邻居集合,以及目标用户历史行为相关的数据。因此,输入数据中主要包含了用户和社交事件这两种实体,这两种实体由多个特征域组成,下面分别描述这两种实体的数据输入形式。
用户实体的数据包含了用户id、地理位置区块、兴趣类别这3个特征域;社交事件实体的数据来自事件id、事件群组id、事件地理位置、事件类别、时间段这5 个特征域。这些特征域中的特征为离散特征,因此需要对离散特征进行独热编码后从输入层输入模型,图3 表示了用户实体和社交事件实体的独热编码向量。

图3 实体的独热编码向量Fig.3 One-hot encoding vector of entity
在划分地理位置区块时,统计用户与其所参与的事件经纬度之间的距离,来确定大部分用户经常参与社交事件的地理范围,图4 为用户与参加事件之间距离的累积分布函数图(Cumulative Distribution Function Diagram,CDFD)。以使用MeetUP API 爬取的纽约市数据为例,从用户事件距离累积分布函数图中可以发现,有83%的用户活动在4 km 的范围内,因此将纽约市划分为80 个4 km×4 km 的地理区块,使用用户所处的区块来代替用户的地理位置信息。

图4 用户参与事件之间距离的CDFDFig.4 CDFD of user event distance
2.2 嵌入层
输入层的离散特征经过独热编码后特征维度升高,同时变得十分稀疏,在模型的训练过程中,特征过于稀疏则会导致整个网络收敛速度过慢,因此需要将输入层的数据输入嵌入层,将特征域的独热编码向量转化为低维稠密向量。
Embedding 起源于词向量Word2Vec 模型,在多个深度学习领域中,如以推荐、广告、搜索为核心的互联网领域,Embedding 技术被广泛地应用,因此Embedding 技术是深度学习中的基础操作。Embedding通常由浅层神经网络实现。
输入层中的用户实体和社交事件实体包含了多个特征域,经过嵌入层后每个特征域映射为低维稠密特征向量,然后将不同特征域的嵌入向量进行拼接,就得到了实体的低维嵌入特征向量表示,用户实体的嵌入向量为:

社交事件实体的嵌入向量为:

其中,concat(·)表示拼接函数。
2.3 双向GRU层
循环神经网络是一类用于处理序列数据的神经网络。在DUPSRM 中将用户历史参与事件和拒绝参与事件按照时间顺序排列,生成用户的历史事件序列,然后使用双向GRU 层来从用户的历史事件序列中提取社交事件之间的关联。双向GRU 层中包含了两层传递方向相反的GRU 层,每层中包含多个GRU 单元,用来获取从前向后和从后向前的序列信息。设每层GRU 层中包含了k个GRU 单元,在从前向后的GRU 层中,hi表示该层中第i个GRU 单元的隐状态,hi既包含了前面(i-1)个隐状态中的特征,也包含了第i个事件的特征;在从后向前的GRU 层中,hk-i+1表示该层中第(k-i+1)个GRU单元的隐状态,hk-i+1既包含了后面(k-i)个隐状态中的特征,也包含了第(k-i+1)个事件的特征。然后将hi和hk-i+1对应元素求和,便得到表示第i个事件的向量hi=hi⊕hk-i+1,该向量中既包含了事件i的特征,也包含了事件序列中与事件i相邻的事件的特征。
2.4 权重层
在DUPSRM中权重层的权重激活单元使用了DIN模型[19]中的结构,用来计算用户历史参与事件序列中的事件和拒绝参与事件序列中的事件对用户参与候选推荐事件e的影响权重,权重激活单元的结构如图5所示。

图5 权重激活单元Fig.5 Weight activation unit
下面以双向GRU 层的隐向量hi为例介绍权重激活单元的作用。
权重激活层中的激活单元(Activation Unit,AU)计算过程如下:
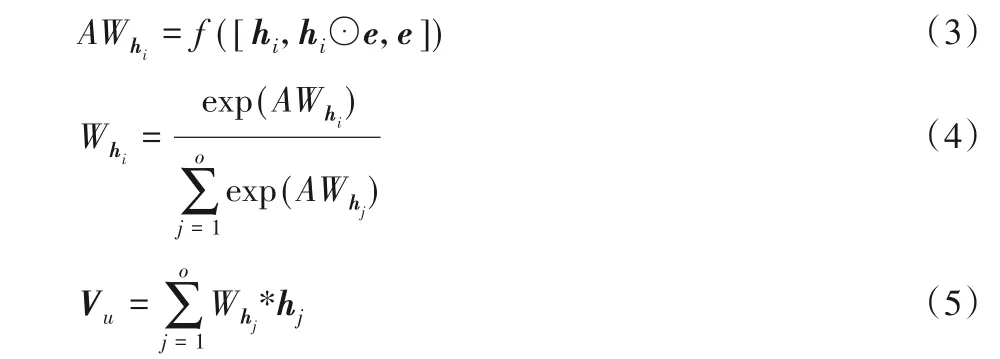
其中:f(·)表示激活单元中的线性层和激活层,[·,·]表示向量拼接,⊙表示向量点积表示隐向量hi的权重,表示隐向量hi的归一化权重。当表示目标用户u历史事件的正向量;当时,表示目标用户历史事件的负向量。
计算用户的社交邻居向量的方法如下:

经过权重层后,就获得了目标用户u完整的向量表示:

2.5 输出层
经过双向GRU 层和权重层后得到了用户的完整向量表示Vu和候选推荐事件的向量表示e,由于矩阵分解算法的前提假设是用户隐向量Vu和候选推荐事件隐向量e来自共同的k维隐向量空间,在DUPSRM 中由于用户向量Vu和候选事件向量e的特征维度不同,因此将用户向量Vu和候选事件e拼接起来,输入到多层感知机中预测目标用户u参与候选事件e的概率,输出层的计算过程如下:

其中:f(·)表示输出层的多层感知机,[·,·]表示向量拼接,σ(·)表示sigmoid激活函数。
在第1 章中,将个性化社交事件推荐问题转化为目标用户是否参与候选推荐事件的二分类问题,因此DUPSRM 的损失函数采用对数损失函数:

其中:S表示训练集,N为训练集样本数量,y表示样本标签,表示模型的预测输出,λ表示L2 正则化系数,w表示网络参数。
3 实验结果与分析
3.1 数据集
在实验过程中使用Meetup网站提供的API对纽约市的数据进行爬取,在对数据进行清洗和一系列预处理操作后得到实验数据集,该数据集包含了纽约市的社交群组、用户以及线下社交事件,数据集的具体信息如表1 所示。为了保证同一个用户出现在训练集和测试集中,数据集划分采用Top-K推荐中常用的留一法。测试集中的负样本采用随机抽样生成。

表1 Meetup数据集信息Tab.1 Meetup dataset information
3.2 对比模型
1)DUMER 模型:该模型使用TextCNN 方法从用户参与的历史事件内容中提取用户偏好的向量表示,然后将用户的向量表示与候选推荐事件的向量表示使用概率矩阵分解方法进行事件推荐。
2)DIN模型:使用用户的历史行为信息对其建模,通过激活单元对于不同的候选事件自动学习用户历史参与事件的权重以获得用户的向量表示,然后将用户向量和候选事件向量输入多层神经网络,由神经网络输出最终的推荐概率。
3)DUPM:为了验证本文DUPSRM 中引入用户偏好负向量表示带来的效果,该模型在推荐时只考虑用户的偏好。
4)DUSRM:为了验证本文DUPSRM 中引入用户社交关系带来的效果,在推荐时只考虑用户的偏好正向量表示和用户的社交关系。
3.3 评价指标
在推荐系统中,命中率(Hits Ratio,HR)、归一化折损累计增益(Normalized Discounted Cumulative Gain,NDCG)、平均倒数排名(Mean Reciprocal Rank,MRR)等指标经常被用来评价模型或算法的效果,本文也使用以上三个指标对模型进行评估:
1)HR@K用来衡量模型的召回率,在K确定的情况下,HR取值越大,表明模型的召回率越高。HR@K的计算方式如下:

其中:|GT| 表示测试集合中样本总数,NumberofHits@K表示每个用户推荐列表的前K个项目中属于测试集中个数的总和。
2)NDCG@K用来对推荐列表中每个项目的预测概率值排序,如果推荐列表中靠前项目的预测概率值越大,则NDCG 的值越大,模型的推荐效果越好。

其中:|U| 表示测试集合中用户的数量,为每个用户的NDCG值之和。
3)MRR 用来表示正确检索结果值在检索结果中的排名,计算方法如下:

其中:|U| 是用户的个数;ranki表示对于第i个用户,推荐列表中第一个相关物品所在的排列位置。
3.4 对比与分析
3.4.1HR@K结果对比
图6 为五种模型在Meetup 数据集上的HR@K运行结果。可以看出,五种模型在HR@10 评价指标下的HR 值均优于HR@5 评价指标下的HR 值,说明随着推荐事件数量的增加,五种模型的推荐效果都会有提升。而DUPM、DUSRM 以及DUPSRM 在数据集上的表现优于DUMER模型和DIN模型,说明这三个模型能够推荐较多与用户相关联的社交事件。DUPSRM 相对于DUMER 模型在HR@5 指标下提升了9.4%,在HR@10 指标下提升了7.6%。五种模型中,DUMER 模型的HR值最低,说明在推荐过程中仅使用社交事件的描述信息不能为用户推荐合适的社交事件;DUPM 和DUSRM 的HR 值较为接近,说明用户的社交关系和用户偏好负向量在社交事件推荐过程中都能带来推荐效果的提升。
3.4.2NDCG@K结果对比
如图7 所示,在NDCG@5 和NDCG@10 评价指标下,DUPM、DUSRM 以及DUPSRM 在Meetup 数据集上的表现均优于DUMER模型和DIN模型,说明这三个模型能够将与目标用户相关联的事件排序在推荐列表中靠前的位置,推荐的效果更好。DUPSRM 相对于DUMER 模型在NDCG@5 指标下提升了8.07%,在NDCG@10 指标下提升了8.1%;而DUMER 模型在五个模型中表现最差,DIN 模型表现相对较好;DUPM 和DUSRM 的NDCG 值相对于DUMER 模型和DIN 模型都有提升,五种模型中DUPSRM 的NDCG 值最高,说明该模型的推荐效果最好。

图6 五种模型在Meetup数据集上的HR@K结果Fig.6 Results of HR@K by five models on Meetup dataset

图7 五种模型在Meetup数据集上的NDCG@K结果Fig.7 Results of NDCG@K by five models on Meetup dataset
3.4.3 MRR结果对比
图8 为五种模型在Meetup 数据集上MRR 的运行结果。在MRR评价指标下,DUMER模型的MRR值最低,DIN模型的MRR 值次之,DIN 模型的推荐效果优于DUMER 模型;DUPSRM 的推荐效果相对于DUMER 模型在MRR 指标下提升了8.2%,DUPM的推荐效果略优于DUSRM。
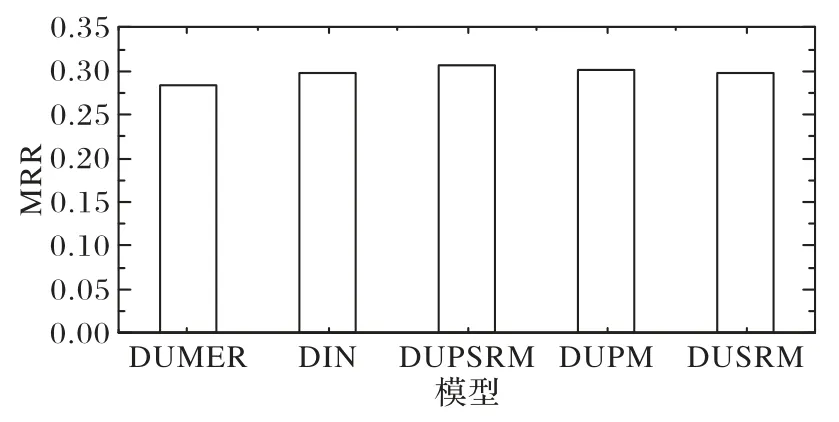
图8 五种模型在Meetup数据集上的MRR结果Fig.8 Results of MRR by five models on Meetup dataset
4 结语
本文使用深度学习方法来解决基于事件社交网络中个性化社交事件推荐问题,在推荐过程中使用社交邻居信息以及历史行为信息对用户建模。在使用用户历史行为信息建模时,构建了用户偏好的正向量及负向量,使用双向GRU 层和权重层建立用户的向量表示,提高了模型的准确性。通过在真实数据集上的实验结果表明,本文提出的DUPSRM 的效果相比当前基于事件社交网络中的个性化社交事件推荐方法有一定的提升。同时,基于事件社交网络中离线事件也包含了许多上下文特征,如事件的规模、事件的组织者信息等,这些特征可能对于用户参与事件有一定的影响,这也为我们改进DUPSRM或者提出新模型指明了方向。
猜你喜欢
心理学报(2022年5期)2022-05-16
意林彩版(2022年2期)2022-05-03
新高考·高一数学(2022年3期)2022-04-28
好日子(2021年8期)2021-11-04
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
当代陕西(2020年17期)2020-10-28
第一财经(2020年4期)2020-04-14
文苑(2018年17期)2018-11-09
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
