
基于可微神经计算机和贝叶斯网络的知识推理方法
2021-03-07 05:16孙建强许少华
计算机应用 2021年2期
孙建强,许少华
(山东科技大学计算机科学与工程学院,山东青岛 266590)
(*通信作者电子邮箱sunjianqiangv@outlook.com)
0 引言
人工智能(Artificial Intelligence,AI)的发展大致可分为三个层次:计算智能、感知智能和认知智能。人工智能的终极目标是实现通用人工智能(Artificial General Intelligence,AGI)[1]。现阶段,机器对海量数据的处理得益于其高性能的运算能力,机器的计算智能已远超人类水平。感知智能是机器对语音、图像等进行感知的能力,例如在画面中可以识别出客体信号,已基本达到甚至超过了人类水平。认知智能对人工智能提出了更高要求,机器需要具有人类智能水平,具有解释数据、解释过程、解释现象的能力,从而对问题进行推理、规划、创作,得到正确的决策判断[2-3]。
知识图谱(Knowledge Graph,KG)被认为是人工智能由感知智能通向认知智能的基石,其中很大的原因在于KG 强大的语义理解能力和知识推理能力[4]。KG 可将知识以机器可读的方式进行结构化,基于语义表达解决实际问题,但它不能处理知识的不确定性。贝叶斯网络(Bayesian Network,BN)通过置信度,以概率表示知识的不确定性,并结合图论,展现了其在知识推理方面解决不确定性问题和处理非完整性信息的优势[5]。
人工神经网络(Artificial Neural Network,ANN)具有强大的学习能力和泛化能力,被广泛应用于知识推理领域[6]。针对KG 中许多隐藏事实未能挖掘的问题,文献[7]中提出了一种神经张量网络(Neural Tensor Network,NTN)模型,对发现实体间隐藏关系具有良好效果;但其计算复杂度非常高,且在稀疏KG 上的效果较差。文献[8]中提出了投影嵌入(Embedding Projection,ProjE)模型,对模型参数规模进行了优化,降低了计算复杂度;但它对实体和关系嵌入向量预处理的效果存在很大的依赖。针对神经网络有限的存储记忆能力,基于辅助存储的推理受到了研究者的重视。文献[9]中提出了隐性推理网(Implicit ReasoNets,IRN)模型,使用共享记忆部件存储记忆信息,通过对共享记忆组件的读取来隐式地进行推理;但IRN 模型无法对记忆信息进行即时写入或修改。文献[10]中提出了神经图灵机(Neural Turing Machine,NTM)模型,模拟冯诺依曼体系,将深度神经网络和辅助存储分别视为中央处理器和内存,为推理功能提供了记忆基础;但NTM无法避免多个存储单元互相干扰,而且无法释放存储单元。文献[11]中提出的可微神经计算机(Differentiable Neural Computer,DNC)在NTM 基础上对存储管理方式进行了改进,而且时序记忆链接的加入使得DNC 可以跳跃读取或更新记忆信息;但同其他神经网络模型一样,DNC无法对数据不确定性进行处理。针对现有方法有限的记忆能力无法很好对KG中隐含信息进行挖掘和KG 无法处理不确定知识的问题,提出一种可微神经计算机(DNC)和贝叶斯网络(BN)相结合的推理方法DNC-BN,并通过实验验证了DNC-BN的推理效果。
本文的主要工作是:
1)将具有长期记忆功能的可微神经计算机应用到KG 推理领域,以解决KG推理中隐含信息挖掘不充分的问题;
2)提出了DNC-BN 方法,模拟人脑推理过程,把人工神经网络、辅助存储和不确定性推理相结合,通过引入BN 处理数据不确定性,使用极大似然估计计算实体概率参数,量化了实体关系真实存在的可能性。
1 相关工作
1.1 知识图谱
KG 的概念[12]于2012 年由谷歌公司提出,其本质为具有图数据结构的知识库,可以认为KG 由语义网络(Semantic Network,SN)[4]发展而来。KG 最初用于增强搜索引擎的智能化,由于包含了丰富的语义关联和知识结构,可为学习和研究提供有价值的数据信息。如图1所示,可视化KG展示了2019新型冠状病毒与宿主、基因和蛋白等的关系。

图1 KG示意图Fig.1 Schematic diagram of KG
KG 可以使用事实三元组(头实体,关系,尾实体)来形式化表示事物及其之间关系,例如事实三元组(2019 新型冠状病毒,宿主实体,人类)中,头实体和尾实体分别为“2019 新型冠状病毒”和“人类”,两者之间的关系为“宿主实体”。
目前大部分的开放KG 并非很完善,大量的隐含信息亟待挖掘。KG 的不完整性对其可发挥的作用产生了一定的制约,因此,如何挖掘隐含信息,对KG 中的知识进行完善是一项重要的研究问题[13]。知识图谱补全(Knowledge Graph Completion,KGC)技术可以预测残缺信息,挖掘隐含数据,为解决KG 不完整性问题提供了重要支持。KGC 技术中,最重要的方法就是面向KG的知识推理[14]。
1.2 可微神经计算机
ANN 处理数据时,计算和存储并不是分开的,而是通过网络参数和网络结构混合在一起,它对存储需求的处理有限,并不能随着任务存储需求的增长对存储进行灵活的更迭。DNC则提供了解决问题的一种思路。
DNC 可以视为ANN 和外部存储矩阵的结合,即主要由控制器和记忆体组成[10,15]。和其他神经网络相比,DNC 可选择性地对存储进行读写,并迭代地修改存储数据。利用记忆体存储矩阵,DNC可以获取推理隐含信息,存储推理过程中的重要数据,通过模拟人脑的推理过程,提高了推理效率。DNC的核心是控制器,其本质是ANN,相当于计算机系统中的处理器。记忆体大大提高了DNC 的记忆能力,是DNC 的创新之处。DNC的模型结构见图2。
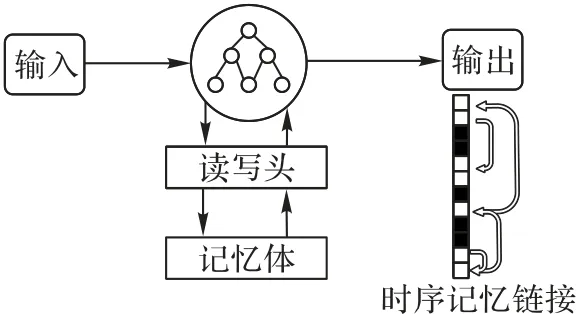
图2 DNC结构Fig.2 Structure of DNC
控制器和记忆体的交互对DNC 具有重要意义。控制器可选择性将记忆信息写入记忆体,并对写入的位置进行确定。控制器可以更新一个位置的记忆信息,并对信息是否释放作出决定。控制器还可以从记忆体的多个位置进行读取,关联时序链接记录了记忆信息被存储的顺序。
因此,DNC在具有长期记忆功能的同时,还可以灵活地对记忆信息进行更新,本文提出的方法将DNC 引入到KG 推理领域中,对推理和隐含信息的挖掘具有重要作用。
1.3 概率图模型
概率图模型(Probabilistic Graphical Model,PGM)由文献[16]提出,它结合了概率论和图论,通过构建图来表达问题中变量的联合概率分布,是不确定性推理问题的重要工具。
BN 是PGM 的一种,理论基础为贝叶斯法则[5]。BN 可形式化表示为BN(G,θ),其中网络拓扑结构G为有向无环图(Directed Acyclic Graph,DAG),图中节点为随机变量,包括已知变量、隐含变量以及未知参数等,节点之间的连线表示随机变量间的条件依赖,θ定量描述这种依赖,并通过条件概率表(Conditional Probability Table,CPT)表示。BN 运用不确定性推理原理,模拟人类推理过程中的因果关系,避免了数据的过拟合以及主观因素造成的偏差,可以出色地处理挖掘数据中潜在知识的问题[17]。
2 DNC-BN模型结构
本文提出的DNC-BN 模型主要由控制器、记忆体、BN 等组成,输入数据形式为已预处理为编码数据的事实三元组。输入数据在控制器中处理得到的记忆信息被写入到记忆体中,控制器和记忆体之间的交互通过读写头完成。控制器处理后的三元组数据再由BN计算实体节点之间的概率参数,推理实体之间存在关系的可能性,最终输出补全的三元组数据。DNC-BN模型整体架构和数据处理流程如图3所示。

图3 DNC-BN模型总体架构Fig.3 Overall structure of DNC-BN model
2.1 控制器
控制器是模型的核心。在t时刻,控制器从数据集中接收输入向量xt,在记忆体存储矩阵Mt-1中获取R个读向量,经过控制器网络处理,得到输出向量yt。令
控制器网络可以选择任何结构的神经网络,本文使用长短时记忆(Long Short-Term Memory,LSTM)网络作为控制器网络[18]。在t时刻,控制器网络l层输出值为:

在每一时刻,控制器网络都计算得到一个网络输出向量υt和一个交互向量ξt,其中交互向量用来参数化t时刻控制器和记忆体的交互:

控制器通过在计算图中创建循环将信息传递回来[19],进而得到υt等。计算图可如图4简要展示。

图4 控制器计算图Fig.4 Computation graph of controller
最后,控制器输出向量为:

这种设计使控制器通过加强对记忆体存储矩阵的依赖调节其输出决策。
2.2 读写头和记忆体
如图5 所示,控制器通过读写头对记忆体中的数据进行操作。
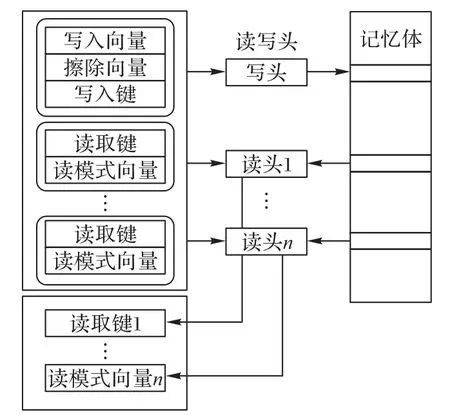
图5 控制器通过读写头与记忆体的交互Fig.5 Interaction between controller with memory through read and write heads
读取或写入的位置由相应的权重决定,N个位置上允许权重的集合是RN中标准单纯形的非负象限:
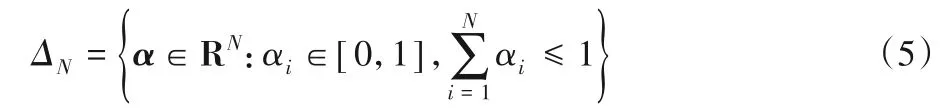

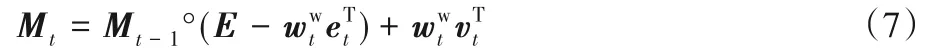
其中:°表示Hadamard乘积;E为N×M的全1矩阵。
DNC的寻址机制是多种结合的:在记忆体中写入数据时,使用了基于内容的寻址和动态寻址;在记忆体中读取数据时,使用了基于内容的寻址和时序记忆链接来获取位置。
2.2.1 基于内容的寻址
在存储矩阵M上进行内容查找操作定义为:

其中:向量k为查找键;β为键强度参数;D()为余弦相似度,用来作为内容相似性的评估函数。

C(M,k,β) ∈SN定义了存储位置上的归一化概率分布。SN是约束向量,被定义为标准(N-1)-单纯形:

2.2.2 动态寻址
动态寻址是通过释放列表φt实现的。释放列表记录了记忆体中空闲的存储位置,控制器对记忆体中数据进行改动后,释放列表也随之更新。
在写入数据之前,控制器为读取头i分配释放门参数用来判断最近读取的位置信息是否被释放。ψt为保留向量,表示位置信息不会被释放的程度:

ut表示t时刻的存储使用向量,u0=0,
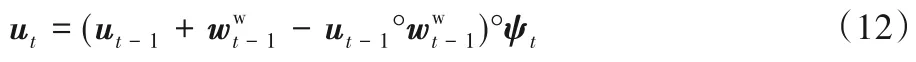
得到ut的值,对各个存储位置的使用情况进行升序排列,可以对释放列表进行更新。φt[1]记录了利用率最低的存储位置。排序操作使得顺序有变动的位置产生不连续性,在计算梯度时,由于产生的不连续性对学习无关,故将其忽略。
2.2.3 写入权重
定义分配权重at,用来产生新分配的写入位置:
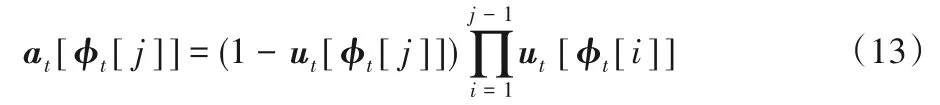
控制器对新分配的位置可选择写入或不写入。首先,定义写内容权重:


2.2.4 读取权重
对于读取头i,定义读内容权重


2.3 时序记忆链接
时序记忆链接保存了记忆体位置写入顺序的信息,被表示为Lt。Lt[i,j]表示位置i在写入位置j后被写入的程度,而且Lt的每行每列都可定义位置权重。

其中,pt为优先权重,pt[i]表示位置i被最后写入的程度:
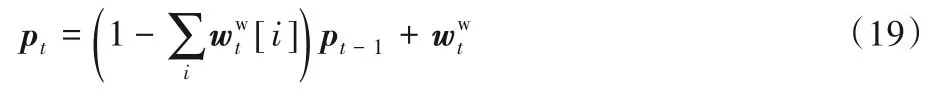
对于读取头i,定义反向权重和前向权重:

2.4 贝叶斯网络
BN 可有效表达节点间的条件独立性。节点n1,n2,…,nd的联合概率分布为:

其中pai为ni的父节点集。模型训练的过程为参数估计的过程,本文使用极大似然估计计算网络各个节点的概率参数。参数θt唯一确定PB(pai|ni),为方便表达,记PB(pai|ni)为PB(pai|θi)。参数θi对pai的似然是:

参数θi的极大似然估计为:

通过控制器网络对KG 三元组数据处理,记忆体对记忆信息的存储和更迭以及BN对不确定性信息的分析,本文模型对三元组数据进行推理,实现KG的补全。
3 实验与结果分析
3.1 实验数据
本文实验使用公开数据集WN18RR[20]和FB15k-237[21]来评估模型性能。WN18RR 和FB15k-237 分别为WordNet 子集WN18 和Freebase 子集FB15k 的修订数据集。WordNet 是一个基于认知语言学的大规模英语词汇语义知识图谱,WN18包含了其中的18 个关系和40 943 个实体;Freebase 是一个开放性的大规模链接数据库,FB15k 包含了其中的1 345 个关系和14 951个实体。WN18和FB15k存在测试集泄漏问题,即测试集中包含有可由训练集中三元组翻转得到的用例,这就使得实验模型极易取得较优结果。WN18RR 和FB15k-237 将训练集和测试集中的反向关系三元组数据进行了处理,解决了测试集泄漏的问题。WN18RR 和FB15k-237 基本情况统计如表1所示。

表1 数据集的基本情况统计Tab.1 Basic statistics of datasets
WN18RR 和FB15k-237 数据集都由多文件组成,其中train、valid、test 文件分别代表训练集文件、验证集文件、测试集文件,每个文件的第一行标注了样本的个数,其余每行的样本为三元组格式,以编码数据存储,且都保持(头实体,尾实体,关系)的顺序。entity2id 文件保存了所有实体及其对应的id编码,relation2id文件保存了所有关系及其对应的id编码。
3.2 实验参数设置
本文模型实验参数的设置参考了文献[11],并通过验证集对部分参数进行微调。其中控制器网络选择为LSTM,隐藏层设置为256 个神经元,使用均值为0、方差为0.1 的高斯分布初始化可更新参数。为提高收敛速度,优化算法选择为RMSProp,其中学习率设置为1× 10-4,模糊因子设置为1×10-10。记忆体中,设置64 个存储位置,每个位置的宽度设置为256,用于存储控制器处理生成的记忆信息。模型设置了2个读头和1 个写头用于控制器和记忆体之间记忆信息的交互。BN 使用极大似然估计计算网络各个实体节点的概率参数,并使用贝叶斯打分函数对实体之间的关系进行评估。
3.3 拷贝任务
拷贝任务可以作为一种健全性检查对动态存储分配进行测试,并通过可视化对实验过程进行分析。如图6(a)和(b)所示(图的横向表示时间步,纵向表示存储位置),在数据集中随机选择若干条序列作为输入,并在记忆体中按输入顺序进行召回创建为输出序列。在召回阶段,不再提供输入,从而确保网络将所有序列存储到了记忆体中。通过设置较少的存储位置,来测试动态存储分配和存储位置重用等。如图6(c)和(d)所示,相同的存储位置被重复使用。同时,结合图6(e)和(f),可以看出在读取阶段,释放门处于活跃状态,这意味着存储位置在被读取之后会被立即释放;在写入阶段,分配门处于活跃状态,这表明被释放的位置可以重新使用。
图6(g)给出了一个错误分配情况,第9 个位置未能正确地更新,导致其余的序列在后面的时间步中都不可以使用这些存储位置。

图6 拷贝任务可视化Fig.6 Visualization of copy task
3.4 结果分析
为了评估本文模型各组成部分对实验性能的影响,本文先进行消融实验;为了评估本文模型的综合推理性能,本文模型与TransE[22]模型、ConvE[20]模型及DistMult[23]模型进行了对比实验。
本文实验环境为JetBrains PyCharm 2018.3,64 位Windows 10 操作系统,使用了开源机器学习平台TensorFlow;硬件配置为Intel Core i5-4 210 CPU @2.4 GHz,8 GB物理内存。
对于每一个测试三元组,使用数据集中所有实体分别替换要推理的实体,如对于测试三元组(hei,tei,teli),若需要推理hei,则需要构造三元组(he1,tei,teli),(he2,tei,teli),…,(hen,tei,teli),其中he1,he2,…,hen∈E,n为实体总数,每一个构造出的三元组都有对应的得分。
实验评估指标使用Mean Rank 及Hits@10,其中Mean Rank 代表正确实体在得分排名中的平均位次,Hits@10 代表正确实体在前十排名中的比例。因此,Mean Rank 取得较低值、Hits@10取得较大值是理想的结果。
消融实验在WN18RR 数据集上进行,结果如表2 所示。从表2 中可以看出,当添加了BN 后,推理效果有较为明显的提升,这表明BN 对隐含信息的推理产生了效果;而在LSTM基础上使用记忆体,即DNC的提升效果明显更好;同时,DNCBN 较仅使用DNC 的提升效果不如在LSTM 上使用BN 的提升效果明显,也表明记忆体的引入对增强方法的推理能力起到了更大的作用。
本文DNC-BN模型同其他推理模型在WN18RR和FB15k-237 上的对比实验结果如表3 所示。同TransE、DistMult、ConvE 相比,本文模型在WN18RR 上Mean Rank 至少提前了769,Hits@10至少提高了0.8个百分点;在FB15k-237 上,Mean Rank 至少提前了42,Hits@10至少提高了1.8个百分点。
可以看出,本文模型在Mean Rank 上的性能较对比模型提升明显,这一结果表明,知识图谱推理过程中,考虑对记忆信息的存储和利用以及对不确定性的处理,可以更好地挖掘潜在信息,提升推理效果。

表2 在WN18RR上的消融实验结果Tab.2 Results of ablation experiment on WN18RR

表3 DNC-BN同其他模型在WN18RR和FB15k-237上的Mean Rank 和Hits@10对比实验结果Tab.3 Comparison of Mean Rank and Hits@10 between DNC-BN and other models on WN18RR and FB15K-237
4 结语
本文提出的DNC-BN 模型基于可微神经计算机(DNC)和贝叶斯网络(BN),遵循认知智能的思想,使用人工神经网络作为控制器对数据进行处理,将记忆信息存储在记忆体,通过读写头进行交互,并结合不确定性理论,对知识图谱进行推理。在数据集WN18RR 和FB15k-237 上的实验结果表明,本文模型所具有的辅助存储及不确定性推理等提升了推理结果排名,展现了良好的推理效果。同多层LSTM 类似,堆叠型DNC 在原理上可以增加模型的学习和推理能力,研究堆叠型DNC的知识推理效果,是下一步将要开展的工作。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
中国自行车(2022年3期)2022-06-30
计算机系统应用(2021年11期)2022-01-06
当代陕西(2019年5期)2019-03-21
网络空间安全(2019年8期)2019-03-18
21世纪商业评论(2018年3期)2018-03-02
现代出版(2014年6期)2014-03-20
科技传播(2012年10期)2012-06-06
