
基于深度学习的3D时空特征融合步态识别*
2021-03-05 07:15:26赵黎明张超越
传感器与微系统 2021年2期
赵黎明,张 荣,张超越
(宁波大学 信息科学与工程学院,浙江 宁波 315211)
0 引 言
步态识别是利用步态信息对人的身份进行识别[1]。与指纹识别、虹膜识别、人脸识别等技术相比,步态识别具有获取容易、距离远、非接触、不易伪装、无创等优点。它是生物特征识别、计算机视觉和信息安全等领域的研究热点。
步态识别的研究方法主要分为两类,一类是基于非模型的方法,另一类是基于模型的方法。基于非模型的方法主要有两种,第一种是将步态轮廓序列合成或压缩成图像[2,3]。如步态能量图像(GEI)[2]是基于步态周期中步态轮廓的平均图像信息建立的步态特征,这种方法相对来说简单,但很容易丢失时间和细粒度的空间信息。第二种直接从原始步态轮廓序列中提取特征[4],但容易受到视角、行人服装变化等外部因素的影响。基于模型的方法通常将人体模型与输入图像相匹配,然后提取运动信息作为特征。目前大部分的基于模型的方法利用三维模型来模拟行人的运动[5,6]。基于三维模型的方法能在一定程度上抵抗视角、携带、服装变化等外部因素的影响。但由于三维建模计算复杂,一般只适用于完全可控的多摄像机协作环境,而在现实环境当中大多只有普通RGB摄像机的场景,限制了这些方法在实际中的应用。
为了解决上述问题,本文利用三维姿态估计技术,建立了行人3D姿态“轻”模型。即不需要额外的深度相机设备配合,通过普通RGB摄像机就能获取所需的三维模型,且三维模型相对简单,计算复杂度降低,这增加了实际应用的可能性。本文将基于3D模型与非模型的方法融合,在CASIA-B数据集上的结果表明,融合了3D空间的行人运动特征提高了步态特征的鲁棒性,进一步提高了步态识别率。
1 3D时空特征的步态识别网络结构
1.1 网络整体架构
提取行人3D运动信息的网络主要由卷积神经网络(convolutional neural network,CNN)和长短期记忆网络(long short-term memory,LSTM)网络组成,用三元组损失Triplet loss训练网络。提取3D运动信息网络结构如图1所示。

图1 提取3D时空运动信息网络结构
1.2 三维姿态预处理
本文采用了文献[7]提出的3D姿态估计网络,该网络使用卷积姿态机(convolutional pose machines,CPM)[8]获得二维热图,并基于此估计人的三维姿态。它以368×368图像为输入,输出尺寸为n×3×17的三维人体姿态估计,其中n为图像中的人数,3为每个关节点的三维坐标x,y,z,17为关节点的个数。
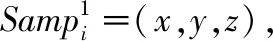
然后基于树结构的遍历方法[9]对每个时间帧的三维姿态进行建模,以保持关节的空间相邻关系。需要注意的是,3D姿态估计生成17个关节点。根据树的遍历规则,本文删除了下颌点并将头部连接到颈部,遍历规则如如图2所示,其中8是脊椎,是遍历的起点。对关节点的遍历规则,依次为8—9—10—9—11—12—13—12—11—9—14—15—16—15—14—9—8—1—2—3—4—3—2—1—5—6—7—6—5—1—8。
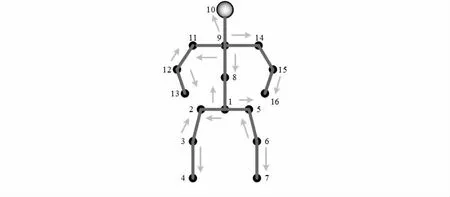
图2 生成的关节点
因为人体的运动往往需要相邻关节点的协同运动,因此相邻关节点之间有着密切的运动联系,根据这个遍历规则,关节点的坐标依次形成一个循环,相邻关节点在序列中处于相近的位置,可以方便提取相邻关节点的空间运动信息。
1.3 CNN-LSTM 网络结构
这里使用CNN和LSTM来提取行人运动的时空特征。为了提取这些相邻关节点之间的关系,利用神经网络对处理后的3D骨架序列进行一维卷积。其中卷积核的大小可以灵活设置。本文借鉴了文献[10]的网络结构,只使用文献[11]中的编码部分。同时,对网络做了一些改变。网络结构如图3所示。在经过遍历规则后,3D骨架序列的输入大小为T×31×3,其中T为序列的帧数,31为遍历依次经过的关节点个数,3代表关节点的三维坐标x,y,z。

图3 CNN-LSTM 网络结构
首先通过两层一维卷积模块提取运动序列的空间结构特征,然后使用LSTM提取特征的时间关系,通过卷积网络和LSTM来共同提取更深层次的时空序列特征。
具体来说,空间特征提取包括两个卷积模块,每个卷积模块包括卷积、池化和通道正则化操作。此外,受文献[12]的启发,考虑了注意力机制对网络性能的改善,从而在卷积层后添加压缩激励(squeeze-and-excitation networks,SE)模块[12]有选择地增强卷积特征。在图3中,给出了模块的详细结构。
为了得到步态的时间特征,使用LSTM网络对步态的空间特征进行进一步的处理。最后一帧LSTM网络输出作为最终的时空序列特征。
1.4 融合训练与测试
考虑到大多数步态识别数据集缺乏真实的三维标签,如果将3D时空特征直接用于步态识别并给出识别结果,结果缺乏可信度。因此,本文没有直接使用3D时空特征进行识别,而是利用神经网络融合训练3D时空特征网络(CNN-LSTM)结构与基于轮廓图的网络结构,最终只使用2D轮廓图进行识别。这里需要注意的是,此时的2D轮廓特征是通过两个特征互补训练获得的新的2D轮廓特征。如果使用这种融合了新的2D轮廓特征的最终识别率有所提高,则证明了所提出的3D时空特征的有效性。
因此,本文没有对现有提取的二维轮廓网络结构进行更改,而是比较融合3D时空特征训练的网络提取得到的新2D轮廓特征识别率有所提高,从而证明3D时空特征确实起到了积极的作用,能够进一步增强步态特征的鲁棒性。
训练时采用CNN-LSTM网络结构和现有的网络结构提取步态轮廓进行联合训练,融合2D轮廓特征f2D和3D时空序列特征f3D得到融合特征f。公式为
f=concat(f3D,f2D)
其中,concat是在高度维度上拼接两个特征。最后采用三元组损失Triplet loss训练网络。如图4所示。
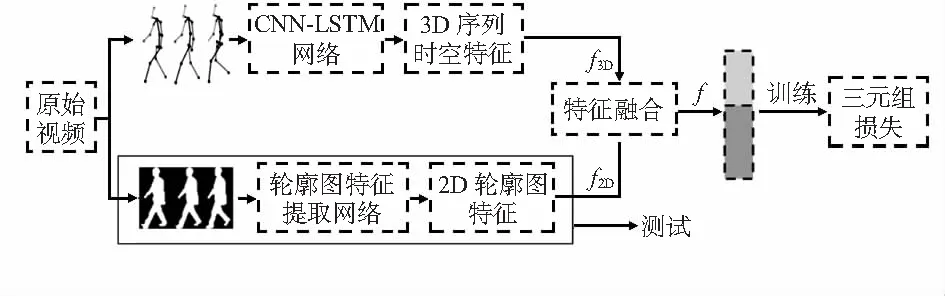
图4 整体网络结构
在测试时,如图4中黑色实线框所示,不需要额外的3D骨架信息,只使用从网络中提取的2D轮廓特征,这也大大减少了实际应用时的复杂性和计算量。
2 实 验
2.1 数据集
CASIA-B数据集[13]是目前常用的步态数据集。它包含124名受试者(编号001-124),3种步行条件和11个视角(0°,18°,…,180°)。行走条件包括正常(NM)(每个受试者6个序列)、背包行走(BG)(每个受试者2个序列)和穿着外套或夹克(CL)(每个受试者2个序列)。本文使用目前文献中常用的3种实验设置,即小样本训练(ST)、中等样本训练(MT)、大样本训练(LT)。在ST中,前24个行人被用于训练,其余用于测试。在MT中,前62个行人用于训练。在LT中,前74个行人用于训练。在所有三个设置的测试集中,前4个NM条件序列(NM#1~4)被放置在图库(gallery)中,最后两个NM条件序列(NM#5~6)以及BG#1~2条件和CL#1~2条件序列被用作查询(probe)。
2.2 训练细节
神经网络在训练过程中有两个输入,即2D轮廓序列和3D骨架序列。对于2D轮廓序列特征的提取,本文选择了文献[6]中的网络结构。对于3D时空特征的提取,输入是从原始视频图像中提取的与2D轮廓相对应的骨架顺序序列。本文所有的实验基于Pytorch框架。实验环境是Ubuntu18.04,NVIDIA GeForce 2080Ti。采用随机优化方法Adam对网络进行训练。训练的初始学习率设定为0.0001。3D骨架序列的T为30。对于ST,MT和LT,分别训练了50 k次迭代、100 k次迭代和110 k次迭代。
2.3 主要结果
表1给出了不同训练设置下的Rank—1识别率。对于不同条件的probe,给定probe的角度,表中给出了所有允许的gallery视角(不包括相同视角)的Rank—1平均识别率,最后一列给出了probe所有角度的平均识别率。可以看到,融合3D骨架序列训练网络得到的2D轮廓特征进一步提高了步态识别率。特别地,在MT的训练设置下,在probe为BG#1~2和CL#1~2条件,融合了3D时空特征下平均识别率较之前分别提高了2.7 %和3.7 %,在其他训练设置下的识别率也均有提高,这也证明了3D时空特征的有效性。
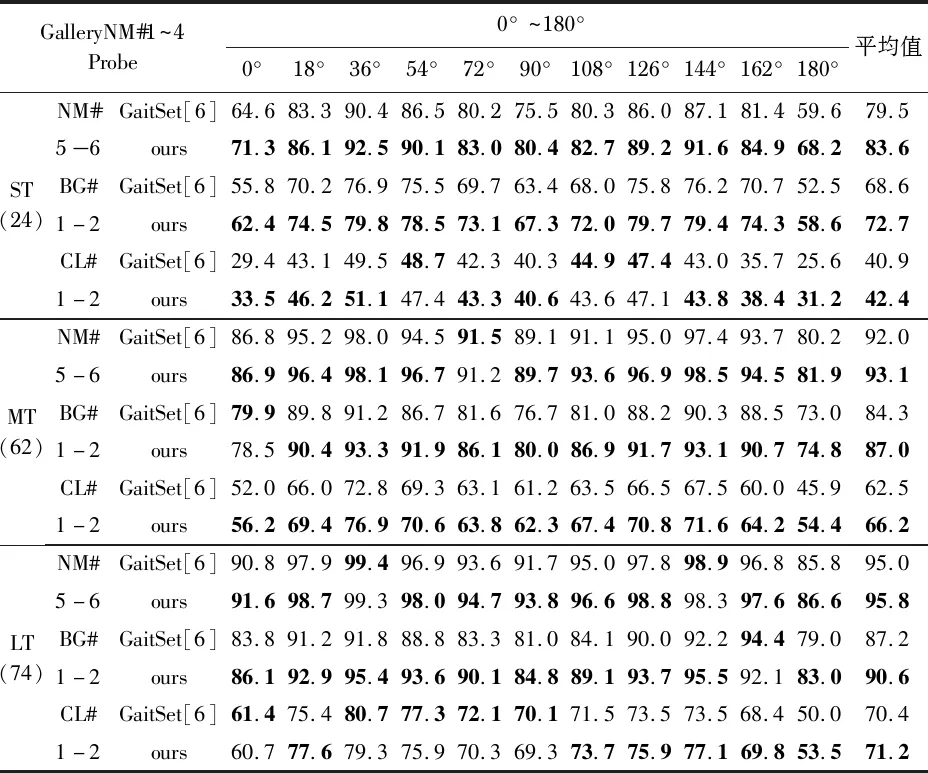
表1 CASIA-B在三种不同实验设置下的Rank—1识别率(不包括相同视角)
本文认为原因如下,3D骨架序列中包含了三维空间上的运动信息,这与2D轮廓图的特征不同,是从三维空间上描述的步态运动,其次,空间上的步态变化与轮廓图体现的步态变化本质上都是在描述行人的运动规律,因此3D时空运动信息与二维轮廓信息融合进一步丰富了步态特征,在一定程度上增加了原有步态特征的鲁棒性,从而提高了步态识别率。此外在融合训练时,融入3D时空特征提高了网络的学习能力,在测试时不需要去获取行人的3D模型,这也大大减低了实际应用的复杂度和计算量。
3 结束语
为了挖掘步态的空间运动信息,本文引入了3D姿态模型提取时空信息,降低了3D模型获取的复杂度,提高了3D模型在实际环境中应用的可能性。本文利用卷积神经网络融合行人3D时空特征与轮廓图特征一起训练,进一步增强了步态特征的鉴别力。在CASIA-B的数据集上的结果表明,融合了3D时空运动信息增强了步态特征的鲁棒性,进一步提升了步态识别的识别率。
猜你喜欢
科学大众(2024年5期)2024-03-06 09:40:34
科学技术创新(2021年19期)2021-07-16 10:07:04
沈阳航空航天大学学报(2020年6期)2021-01-27 02:11:30
电子制作(2018年18期)2018-11-14 01:48:04
自动化学报(2018年6期)2018-07-23 02:55:42
军营文化天地(2017年6期)2017-06-28 11:30:19
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
管理现代化(2016年3期)2016-02-06 02:04:13
智能系统学报(2015年4期)2015-12-27 09:37:52
