
基于CEEMDAN 排列熵与SVM 的螺旋锥齿轮故障识别∗
2021-03-03 09:20蒋玲莉谭鸿创李学军雷家乐
振动、测试与诊断 2021年1期
蒋玲莉, 谭鸿创, 李学军, 雷家乐
(1.湖南科技大学机械设备健康维护省重点实验室 湘潭,411201)(2.佛山科学技术学院机电工程与自动化学院 佛山,528225)
引 言
螺旋锥齿轮传动因其重叠系数大、承载能力强、传动比高、传动平稳和噪声小等优点,被广泛应用于航空、汽车和矿山等机械传动领域,是机械工程中重要的基础传动件。由于制造和装配误差,以及运行过程中的润滑不良和超速超载工作等因素,螺旋锥齿轮易发生损伤和故障,由此导致振动异常等,影响整个传动系统的正常运行。对螺旋锥齿轮的运行状态进行监测和诊断,确保整个传动系统安全、高效、稳定运行,具有重要的现实意义。
由于螺旋锥齿轮副啮合对数、啮合点位置及瞬时传动比不断变化,轮齿在啮合过程中不断撞击,因此振动信号异常复杂,故障出现时信号更是呈现强非线性非平稳特性,故障特征信息被淹没在强噪声中,非常微弱,难以识别,是其故障诊断的难点[1-2]。为了实现螺旋锥齿轮故障的有效诊断,近年来国内外学者开展了部分螺旋锥齿轮典型故障诊断研究[3-5],主要集中在基于小波分解的特征提取上,例如基于离散小波弧齿锥齿轮的故障诊断方法[4]以及自适应提升多小波的螺旋锥齿轮的故障诊断方法等[5]。总体来说,相对于平行轴齿轮系及行星轮系齿轮故障诊断研究,交叉轴螺旋锥齿轮故障诊断方法研究还不够深入[6-7]。
继小波分解后,经验模态分解(empirical mode decomposition,简称EMD)在工程实际中被证明是优于小波分解的信号处理方法[8],适用于螺旋锥齿轮故障特征提取,但存在模态混叠问题。Wu 等[9]对EMD 进行了改进,提出集总经验模态分解(ensemble empirical mode decomposition,简 称EEMD)。EEMD 在一定程度上有效缓解EMD 分解模态混叠现象,但由于EEMD 加入高斯白噪声,无法得到IMF 精确重建原始信号,使分解得到的IMF 数量不尽相同,且存在迭代运行高、计算效率低的问题。互补集总经验模态分解(complementary ensemble empirical mode decomposition,简称CEEMD)[10]解决了EEMD 无法精确重构的问题,可极大降低重构误差,提高计算效率,但存在产生不同数量IMF 的弊端。针对以上算法的缺陷,自适应噪声完备经验模态 分解[11]是对EMD,EEMD 和CEEMD 的发展和继承,其在执行分解的各阶段添加自适应的高斯白噪声,消除虚假的IMF,重构误差接近于0,分解效率高且极其完整[12-13]。
通过EMD,EEMD,CEEMD 和CEEMDAN 分解获得IMF 构造敏感特征量,是故障诊断领域行之有效的方法,例如以IMF 能量、熵和能量熵等为典型故障敏感特征量[14-15]。随着熵理论的发展,排列熵(permutation entropy,简称PE)[16]被提出,其具有计算量少、鲁棒性强等特点,可以用于检测时间序列随机性、复杂性以及振动信号突变[17-18],已在机械故障诊断领域初步应用。施莹等[19]为提高列车轮轴承故障诊断效率,提出排列熵与EEMD 相结合的方法。丁闯等[20]研究行星齿轮箱3 种状态的排列熵,提出局部均值分解和排列熵的行星齿轮箱故障诊断方法。螺旋锥齿轮在故障状态下运行时,其振动信号复杂多变,而排列熵可在复杂多变的运动中找到规律,CEEMDAN 排列熵可作为螺旋锥齿轮故障敏感特征量,用于其状态识别。
由于螺旋锥齿轮早期故障特征信息微弱,关键信息完全淹没在噪声中,在进行故障特征提取之前,仅检测待测信号的动力学突变难以准确实现故障辨识,笔者结合SVM 开展螺旋锥齿轮故障状态识别研究。在深入研究CEEMDAN 和排列熵的基础上,针对螺旋锥齿轮故障机理及其振动信号特征,将实测信号用CEEMDAN 得到若干IMF,利用相关系数计算各IMF 分量与原始信号的相关程度,结合信噪比的大小,提取包含主要故障信息的IMF 的排列熵,作为特征向量输入SVM,通过SVM 进行故障状态分类与识别,实现螺旋锥齿轮典型故障的诊断。
1 基本理论
1.1 CEEMDAN 基本原理
CEEMDAN 通过向原始信号进行EMD 的各阶段添加自适应的高斯白噪声,消除虚假的IMF。令Mk(•)为经过EMD 所产生的第k个内禀模态函数,CEEMDAN 产生的第k个内禀模态函数定义为则CEEMDAN 的分解流程如下。
1)令原始时间序列信号为y(n),加入高斯白噪声wi(n) 得 到 新 信 号yi(n) =y(n) +γ0wi(n),其中,γ0为噪声标准差。CEEMDAN 对信号yi(n)执行I次分解,得到第1 阶内禀模态函数为
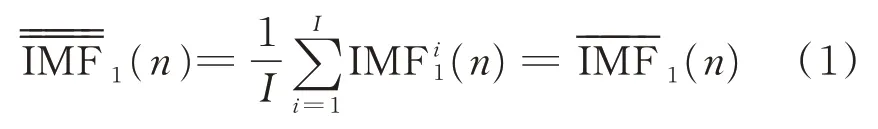
2)在分解的第1 阶段(k=1)得到第1 阶余量信号,即
3)对新的余量信号r1(n) +γ1M1(wi(n) )进行EMD,得到第1 个内禀模态函数时停止,获得CEEMDAN 的第2 个内禀模态函数为
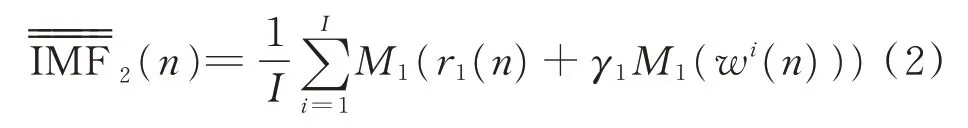
4)以此类推,当k=2,3,…,K时,第k个余量信号为
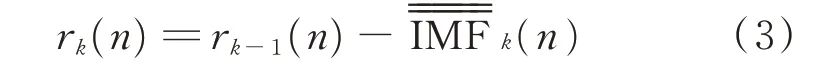
对rk(n)进行EMD,得到第1 阶内禀模态函数时停止,获得CEEMDAN 的第k+1 个内禀模态函数为

5)多次执行步骤4,直至余量不能继续分解,即余量信号的极值点个数最多为两个。最终的余量满足
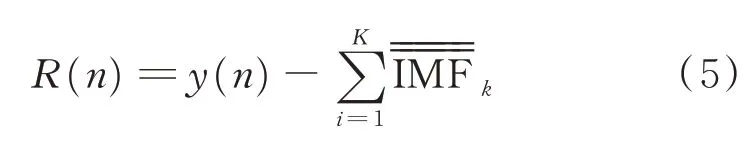
其中:K为CEEMDAN 算法分解所得到的内禀模态函数个数。
因此,原始时间序列信号y(n)可表示为
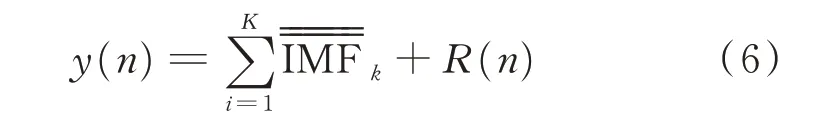
1.2 排列熵基本原理及参数选取
1.2.1 排列熵原理
熵可用于描述数据信息的不确定性,而排列熵具有可准确刻画复杂时间序列突变性的特点,对动态的数据变化有很强的敏感性,通过排列熵值的变化来反映设备的不同运行状态,从而达到异常检测的目的,其算法过程如下。
假设长度为N的时间序列 {a(i),i=1,2,…,N},对其进行相空间重构,得到新的重构矩阵H为
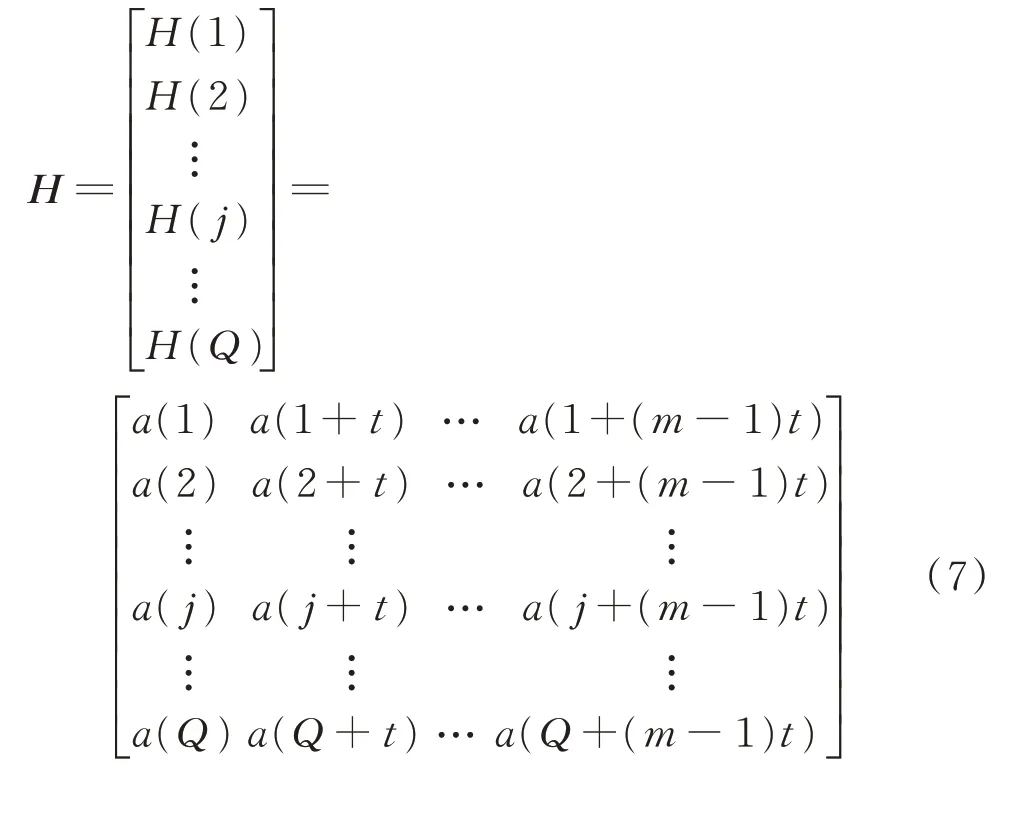
其中:j=1,2,…,Q;m为嵌入维数;t为时延;Q+(m−1)t=n。
将重构矩阵H中的第j个重构分量H(j)={a(j)a(j+t)a(j+(m−1)t)}按照升序重新排列,即
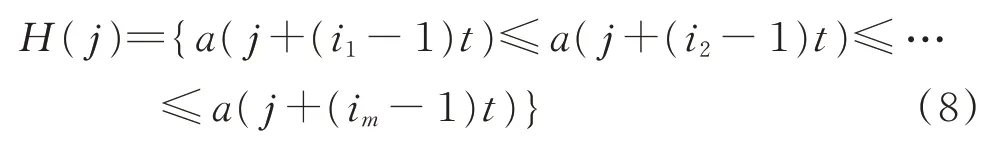
其中:i1,i2,…,im为H(j)分量中元素所在列的位置。
如 果 存 在a(j+(ie−1)t)=a(j+(ic−1)t),则按照e,c的大小来排序,即e>c时,有a(j+(ie−1)t)≥a(j+(ic−1)t);反之亦然。
因此,任意一个包含于重构矩阵H分量H(j)都可得到对应的位置序列

其中:q≤m!;S(j)为m!种代码序列中的一种。
m个不同的代号[i1,i2,…,im]有m!种不同的排列组合,即有m!种不同的符号序列。
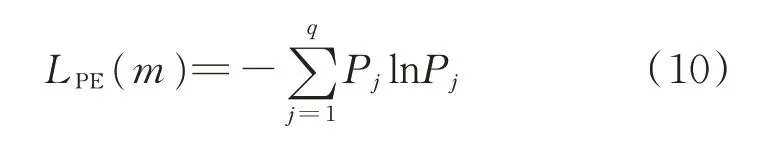
当Pj=1/m时,LPE(m)取得最大值ln(m!)。借助ln(m!)将排列熵LPE(m)进行标准化处理,即
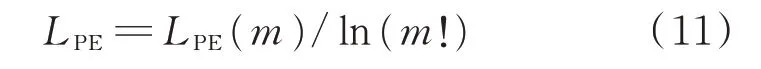
其中:0 ≤LPE≤1。
LPE值的大小表示一维时间序列的随机性程度。LPE越大,说明时间序列随机性越强;反之,则说明时间序列规律性越强。
1.2.2 重叠组合法优选排列熵参数
在排列熵运算中,不同参数的设置会对计算结果产生影响,选取最佳的嵌入维数m和时延t是螺旋锥齿轮排列熵特征提取的关键。
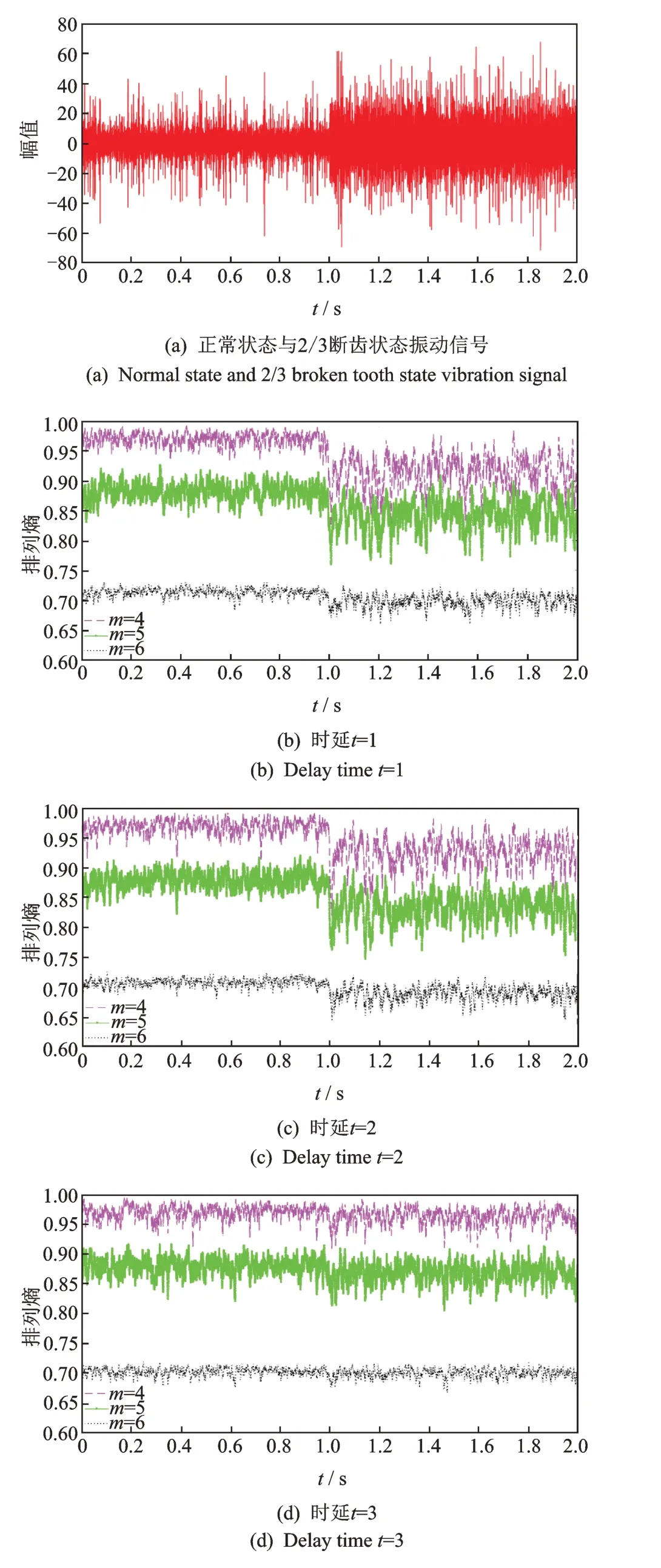
图1 不同m,t 的排列熵Fig.1 Permutation entropy of different m and t
通过对不同运行状态螺旋锥齿轮原始振动信号进行对比,发现当嵌入维数m=4,5,6,时延t=1,2,3 时,排列熵对振动信号的细微突变更敏感。图1 为不同m,t的排列熵。由于嵌入维数和时延的选择都会对排列熵计算结果产生影响,仅考虑单一参数的变化缺乏合理性,故笔者采用重叠组合法确定嵌入维数m和时延t,即将螺旋锥齿轮的一段原始振动信号按照时间序列分成一系列的子序列w1,w2,…,wn,w1向后移动一个数据点得到w2,以此类推,用一对嵌入维数m和时延t计算排列熵值。由于较大的w不能精确反映出信号的变化,而较小的w不仅效率低且无统计意义,故选择w=128。图1(a)为采样频率为16384 Hz 的螺旋锥齿轮正常状态与故障状态原始振动信号的组合,0~1 s 为正常齿轮状态,1~2 s 为2/3 断齿状态。由图1 可知:在正常状态下螺旋锥齿轮振动信号充满随机性,排列熵较大;在断齿故障时,振动冲击相对有规律,排列熵值较小;排列熵可以表述振动信号的突变。对比图1(b),(c),(d)可知:在时延t=1,2,嵌入维数m=4,5 时,排列熵均能有效放大微弱的信息突变,较好地区分出螺旋锥齿轮正常与2/3 断齿状态;当t=1,m=4 时最能体现螺旋锥齿轮正常状态到2/3 断齿状态的突变。故笔者选择排列熵时延t=1,嵌入维数m=4。
2 基于CEEMDAN 排列熵与SVM 的螺旋锥齿轮故障诊断
螺旋锥齿轮传动系统振动信号异常复杂,故障信号呈强非线性非平稳特性,通过以CEEMDAN 分解所得IMF 的排列熵为特征向量,以SVM 为分类器进行齿轮故障分类与识别。CEEMDAN 分解可得到一系列IMF,而故障信息主要集中在少数的IMF中,以各阶IMF 与CEEMDAN 分解前信号的相关系数为依据,结合信噪比进行IMF 优选,选取相关系数大且信噪比高的IMF 分量,并计算其排列熵,作为输入SVM 的特征向量,在确保诊断精度的同时,提高计算速度。基于CEEMDAN 排列熵与SVM 的螺旋锥齿轮故障诊断流程如图2 所示,具体步骤如下。
1)原始振动信号采集。采集螺旋锥齿轮典型故障状态下的振动信号,作为后续分析的原始时间序列信号。
2)CEEMDAN 分解。对不同故障状态下的原始振动信号进行CEEMDAN,得到一系列IMF。
3)有效IMF 优选。计算各阶IMF 与CEEMDAN 信号的相关系数,结合信噪比,选取相关系数大且信噪比高的IMF 分量。
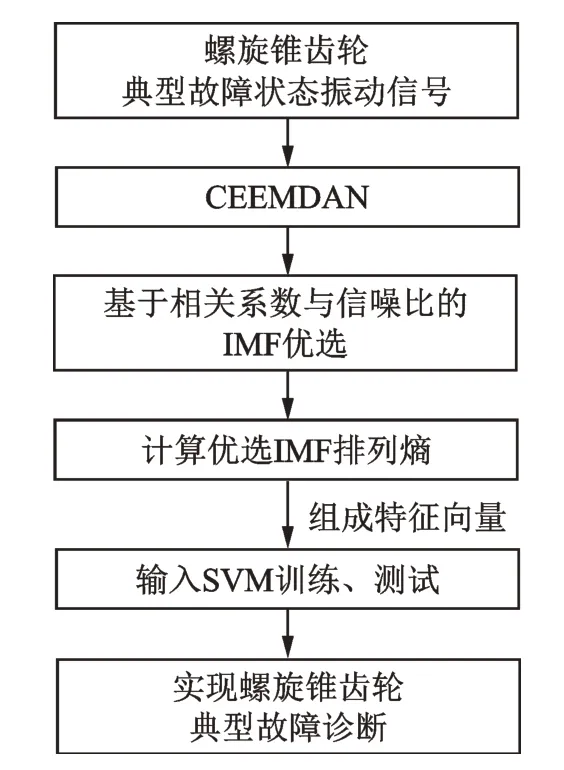
图2 诊断流程图Fig.2 Diagnosis flow chart
4)排列熵计算。计算优选IMF 的排列熵,组成多维特征向量[LPE1,LPE2,…,LPEh]。
5)SVM 分类器训练。以第4 步获得的特征向量对SVM 进行训练,获得典型故障状态分类器。
6)故障识别。重复步骤1~4,获得训练样本的多维特征向量,利用SVM 分类器进行故障状态识别,实现故障诊断。
3 试验验证
以螺旋锥齿轮典型故障诊断实例来验证本研究方法的有效性。用于典型故障状态振动信号采集的螺旋锥齿轮箱试验台如图3 所示。该试验台由调速器、电机、联轴器、一对螺旋锥齿轮和负载5 部分组成,主动齿轮齿数为10,从动齿轮齿数为30。以主动齿轮为试验齿轮,分别装置正常齿轮、1/3 断齿和2/3 断齿来模拟3 种断齿故障状态,如图4 所示。
使用B&K 公司的PULSE 数据采集系统进行振动信号采集。试验过程中,通过调节调速器使电机的转速恒定为1200 r/min,采集3 种不同程度断齿故障状态、相同负载下的振动信号,采样频率为16384 Hz,取输入轴支撑轴承处的轴向振动信号进行分析。

图3 螺旋锥齿轮箱试验台Fig.3 Spiral bevel gear box

图4 3 种断齿故障状态Fig.4 Three kinds of broken tooth fault states
3 种状态时域信号如图5 所示。可见,相比正常状态,幅值峰值明显增大,且随着断齿程度的加重,轮齿啮合时振动冲击最明显。
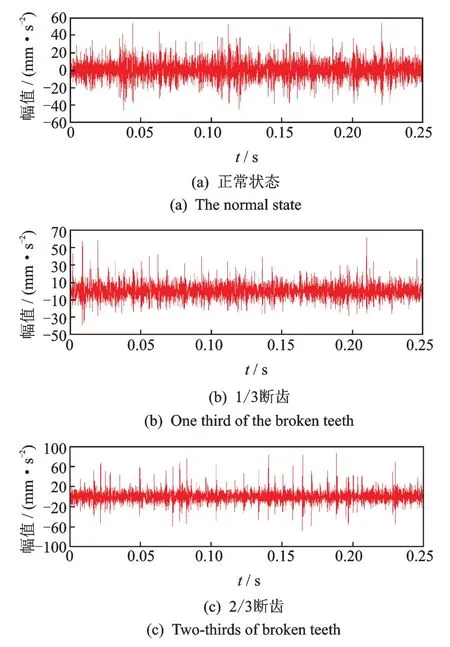
图5 3 种状态时域信号Fig.5 Three state time domain signals
对3 种断齿故障状态下的螺旋锥齿轮振动信号进行CEEMDAN,其噪声标准差为0.19,总体平均次数为100。限于篇幅,仅展示1/3 断齿故障的CEEMDAN 结果,如图6 所示。由图6 可知,原始振动信号被分解成13 个IMF,其中第13 个分量为余项,从IMF1到IMF12波形的混叠现象逐渐减弱,频率也是由高到低分布。
各IMF 序列的排列熵如图7 所示。由图7 可知,IMF1~IMF13的排列熵逐渐变小,排列熵越大,说明时间序列随机性越强;反之,则说明时间序列规律性越强。随着IMF 阶数增大,其频率成分越来越单一,表现出更强的规律性,与理论分析结果基本吻合。
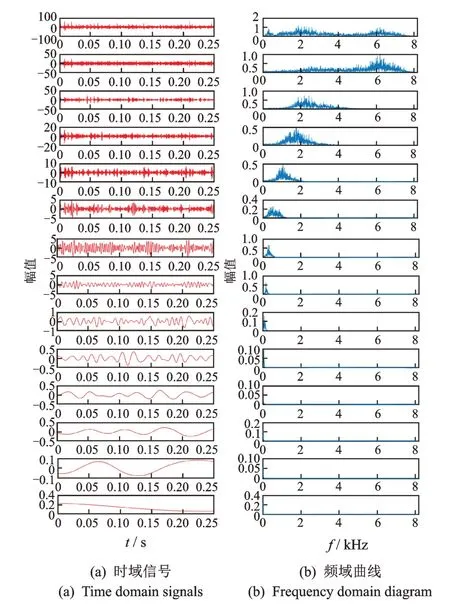
图6 1/3 断齿故障的CEEMDAN 结果Fig.61/3 broken tooth fault of CEEMDAN result
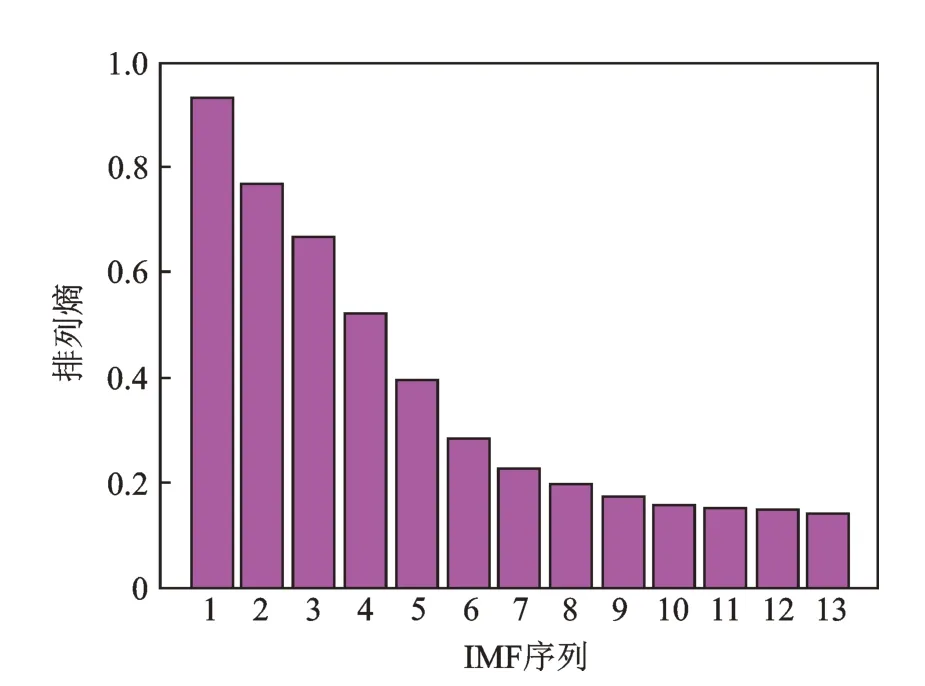
图7 各IMF 序列排列熵Fig.7 Permutation entropy of each IMF sequence
分别计算1/3 断齿原始振动信号与其CEEMDAN 所得各阶IMF 的相关系数与信噪比,如表1 所示。从表1 可知,前2 阶IMF 与原始振动信号的相关程度比较高,都在0.6 以上;信噪比在−8 dB 以上,故优选前两阶IMF。
计算3 种不同程度断齿故障状态CEEMDAN前两阶IMF 的排列熵,取时延t=1,嵌入维数m=4,信号长度N=4096。3 种状态部分样本的CEEMDAN 排列熵对比结果如图8 所示。由图8 可知,优选IMF 的排列熵对螺旋锥齿轮3 种典型断齿故障状态有较好的区分度。
将优选IMF 的排列熵值作为特征向量输入SVM 分类器进行训练,每种故障状态取40 个样本,共120 个样本作为训练样本。SVM 设置3 个两类向量机分类器,将3 类状态的排列熵特征向量输入向量机,把螺旋锥齿轮正常状态标签设为“1”,1/3 断齿状态设为“2”,2/3 断齿状态设为“3”。SVM 核函数采用径向基函数(radial basis function,简称RBF),使用交叉验证的网格搜索方法寻找最优的惩罚因子和核函数参数,避免了人为设置的经验性缺陷。
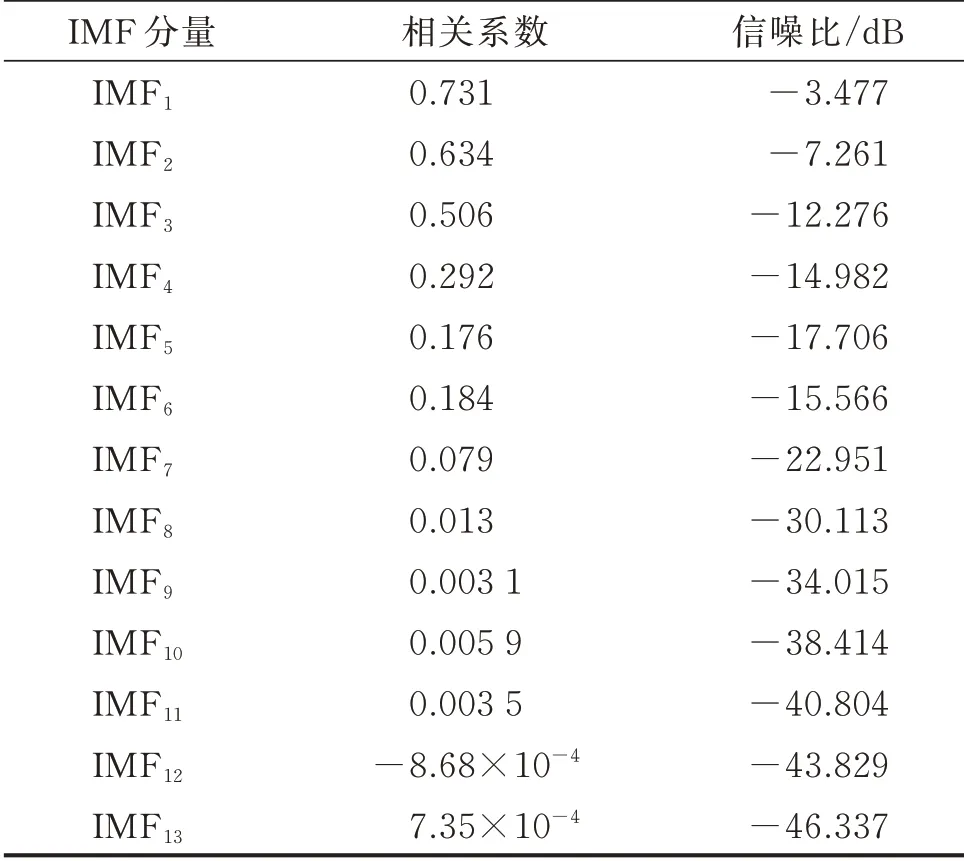
表1 各IMF 的相关系数和信噪比Tab.1 Correlation coefficient and signal to noise ratio of each IMF

图8 3 种状态CEEMDAN 排列熵对比Fig.8 Comparison of three states CEEMDAN permutation entropy
每种故障状态取40 个样本,共120 个样本作为测试样本,输入训练好的SVM 分类器进行分类识别,CEEMDAN 排列熵诊断结果如图9 所示,准确率高达100%。

图9 CEEMDAN 排列熵诊断结果Fig.9 CEEMDAN permutation entropy diagnosis result
为了验证基于CEEMDA 排列熵螺旋锥齿轮故障诊断方法的优越性,将上述3 种状态螺旋锥齿轮振动信号分别使用EEMD 和EMD,计算前两阶IMF 的排列熵。使用相同参数设置的EEMD 并计算前两阶IMF 的排列熵如图10 所示。由图10 可知,EEMD 排列熵对螺旋锥齿轮3 种不同程度断齿故障状态的区分度明显劣于图9 所示的CEEMDAN 排列熵。以EEMD 排列熵构造多维特征向量输入SVM 分类器进行训练与测试,诊断结果如图11 所示,总体分类结果仅为88.33%。其中:在标签1 中,即螺旋锥齿轮正常状态,40 个测试样本中有7 个样本识别出错;在标签2 中,即1/3 断齿状态,40个测试样本中有7 个样本识别出错;在标签3 中,即2/3 断齿状态,识别完全正确。
按照上述同样的方法,3 种状态螺旋锥齿轮振动信号分别经EMD,提取并计算IMF1与IMF2的排列熵构造特征向量,输入支持向量机进行训练与测试。EMD 排列熵诊断结果如图12 所示,总体分类结果仅为83.33%。其中:在标签1 的40 个测试样本中,有5 个样本识别出错;在标签2 的40 个测试样本中,也有5 个样本识别出错;在标签3 中有10 个样本识别出错。
分析可知,以CEEMDAN 的优选IMF 排列熵为特征向量,对螺旋锥齿轮3 种不同程度断齿故障的诊断准确率明显高于EEMD 和EMD 的分析结果,说明了CEEMDAN 在螺旋锥齿轮断齿故障诊断中的优越性。
为了进一步说明CEEMDAN 排列熵的优越性,用EEMD 和EMD 将上述3 种状态螺旋锥齿轮振动信号进行分解,计算IMF1~IMF3,…,IMF1~IMF8的排列熵,并组成高维特征向量输入SVM 进行识别,结果如表2 所示。由表2 可知,利用EEMD 需要提取前7 阶IMF 排列熵才能正确识别3 种状态螺旋锥齿轮,而在同样的特征提取方法下,CEEMDAN仅需提取前两阶IMF 的排列熵。特征向量维数越高,SVM 的训练与测试所需的时间越长,同样体现了CEEMDAN 的优越性。
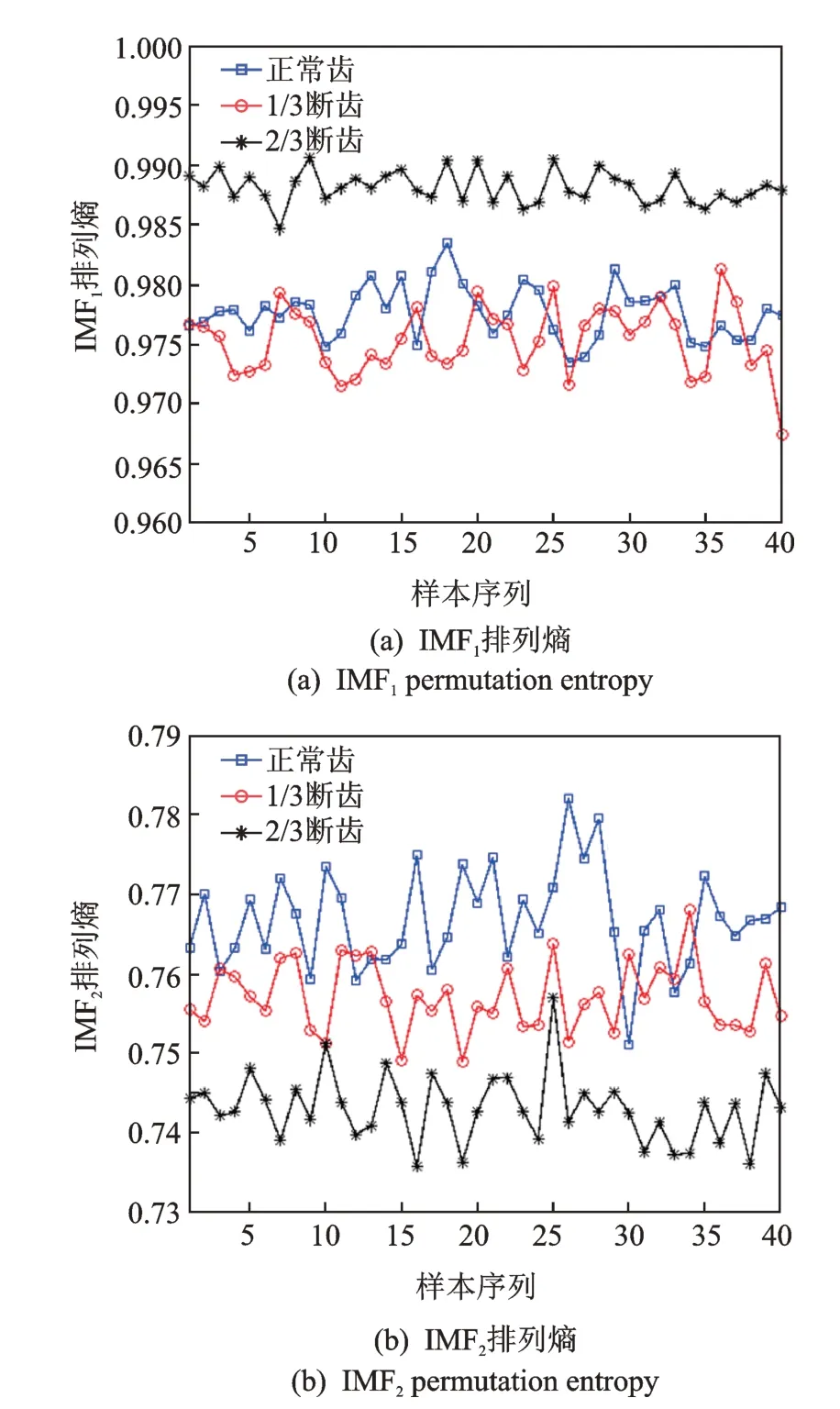
图10 3 种状态EEMD 排列熵对比Fig.10 Comparison of three states EEMD permutation entropy
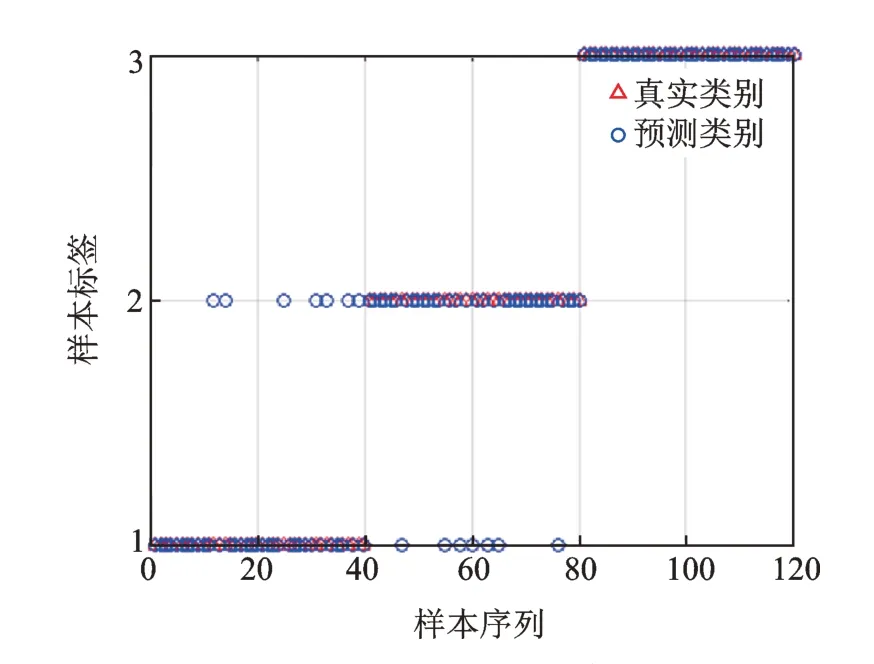
图11 EEMD 排列熵诊断结果Fig.11 EEMD permutation entropy diagnosis results
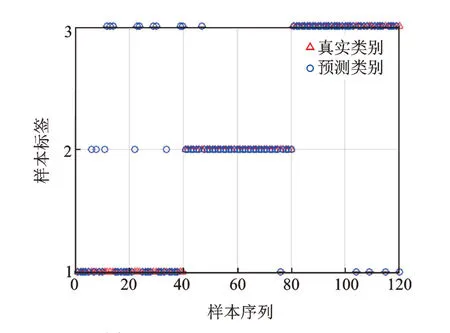
图12 EMD 排列熵诊断结果Fig.12 EMD permutation entropy diagnosis results
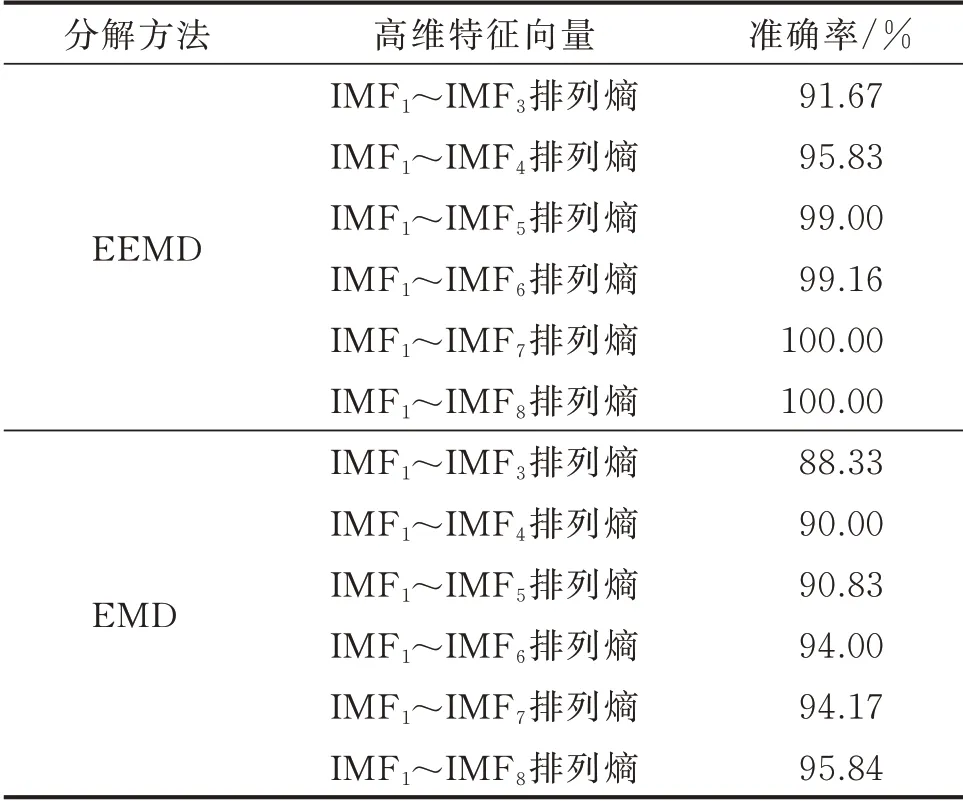
表2 EEMD 排列熵和EMD 排列熵的准确率Tab.2 Accuracy of EEMD permutation entropy and EMD permutation entropy
4 结束语
提出一种基于CEEMDAN 排列熵与SVM 的螺旋锥齿轮故障诊断方法,并以实例分析验证了该方法的有效性。分析结果表明:CEEMDAN 排列熵对螺旋锥齿轮的不同程度断齿故障状态具有很好的区分度,可作为敏感特征量用于螺旋锥齿轮故障诊断;以优选的CEEMDAN 排列熵为特征向量,结合SVM可获得满意的螺旋锥齿轮不同程度断齿故障分类诊断结果,且明显优于EEMD 和EMD 的分析结果。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
热处理技术与装备(2020年4期)2020-09-03
山东冶金(2018年5期)2018-11-22
许昌学院学报(2018年4期)2018-05-02
制造技术与机床(2017年3期)2017-06-23
中华建设(2017年1期)2017-06-07
北京汽车(2016年6期)2017-01-06
山东工业技术(2016年15期)2016-12-01
光学精密工程(2016年6期)2016-11-07
