
基于LightGBM的风电机组齿轮箱油温故障预警研究
2021-03-02 10:01赵娟娟刘广臣王瑞桃徐晓宇张玫洁黄文广
电力大数据 2021年11期
赵娟娟,刘广臣*,王瑞桃,徐晓宇,张玫洁,黄文广
(1.鲁东大学 数学与统计科学学院,山东 烟台 264000;2.华风数据(深圳)有限公司,广东 深圳 518110)
风电机组设备庞大,地处偏远、维修成本高,对风机过去和现在状态进行分析,实现对未来运行状态的估计和预判,进而可以在风机故障发生前对故障进行有效地识别并预警,大大降低经济损失,提高工作效率,延长机组寿命。
温度作为发生故障的重要标志,温度过高或过低会影响机组的正常运行。文献[1-2]依据发电机在故障中的运行特征,改进极端梯度提升(XGBoost)算法进行改进,建立故障监测模型。文献[3]提出了一种随机森林(BF)算法与LightGBM算法结合的模型来对风机叶片状态进行分类预测。文献[4-5]改进支持向量机(SVM)建立风电机组故障预测模型。文献[6]提出一种将多元状态估计技术(MSET)和集成学习结合的齿轮箱故障预警方法。文献[7-13]建立不同神经网络模型来对齿轮箱的运行状态进行监测。文献[14-17]应用深层网络融合SCADA数据进行故障预警。文献[18]提出基于多点最优调整的最小熵解卷积(MOMEDA)与1.5维能量谱相结合的故障诊断方法降低漏判误判。文献[19]提出了一种利用DFIG定子电流信号进行非平稳状态下风电传动齿轮箱故障诊断的新方法。文献[20-22]基于PCA对最优变量选择进行风电机组故障检测与识别。
本文对齿轮箱油温(gearbox_oil_temperature _gearbox)建模分析,研究内容包括:(1)在正常状态的风电机历史数据上进行方差排序、Pearson相关系数和递归特征消除(Recursive Feature Elimination,REF)方法筛选特征变量,生成不同特征组合的三个数据集;(2)在不同数据集上建立齿轮箱油温的轻量级梯度提升机LightGBM模型,综合模型拟合效果和训练耗时选择性能最优的数据集,并且选取时下流行的极限提升树XGBoost和CatBoost算法模型作为对照算法;(3)根据LightGBM模型预测的齿轮箱油温值与真实值的偏离程度[23-24],在偏差较大时启动预警,工作人员检修时可根据模型输出特征重要性排序结合专业经验对部件进行检修。
1 风机齿轮箱油温分析
风电机组[25]组成包括叶片、轮毂、齿轮箱、发电机、制动器、偏航系统、塔身等,该系统结构复杂,运行时各个部件紧密联系,互相影响。风电机组的工作原理,简单来说:在风力作用下,风电机组的叶片推动叶轮转动,进而促使传动系统驱动发电机工作,进而实现风力机械能向电能转换。齿轮箱是传动系统的关键部件,也是整个机组发生故障比例最高的部件,一旦齿轮箱发生故障,就必须更换整个传动系统。因此,齿轮箱故障是造成机组停机时间较长的因素之一。
齿轮箱油冷系统既减少了机械器件之间的摩擦又起到散热效果,保证了齿轮箱正常工作。油冷系统的散热原理是通过控制温控阀从而控制润滑油通路及散热片的冷却作用来实现齿轮箱温度调节的。润滑油性质易受环境温度影响,当润滑油温度较低时,其流动性差;当润滑油温度较高时,润滑油品的黏度较低,内部机械部件表面的油膜很薄,可能导致边界润滑程度不足,摩擦力增大,磨损严重。另外,高温容易造成齿轮油的氧化,油品品质难以保证。综上,低温或高温齿轮箱润滑油都难以为齿轮提供充分的润滑。在通常情况下,当齿轮箱温度超过极限值时,整个机组无法正常运作,风机将会自动停机。毋庸置疑,停机造成的供电量不足以及相关检测维修,都会导致一笔巨大的经济损失。
因而,齿轮箱油温是否保持在一个合适的范围内,直接影响到风机组的正常运行。研究发现,齿轮箱油温过高时,风机组的自我保护机制使得它低功率运行,甚至可能停机,影响供电量;同时,齿轮油的润滑冷却能力被影响,使得油液老化变快,齿轮箱故障甚至报废。齿轮箱油温过低时,风力机组也会有相应的保护机制使得机组不能正常运行。影响油温高的因素有很多[26],包括翅片结构选型不适、机舱密封不严、润滑油问题,以及温控阀失效、油温传感器失灵等。
利用传统人工排查耗时费力,大数据背景下,采用大数据技术作为故障预警、设备诊断、运行优化、标准化提升的有效途径,可以为风电场设计建设各个环节提供精准的数据支持,因此,本文利用建模分析油温波动,进而进行故障预警势在必行。
2 模型方法体系
2.1 LightGBM模型
轻量级梯度提升机LightGBM[27]是由微软推出的基于决策树模型的分布式Boosting集成算法,是对GBDT算法的改进,还可以称之为带有基于梯度的单边采样(GOSS)和互斥特征捆绑(EFB)新GBDT算法。随着大数据的出现(无论是在特征数量上还是数据数量上),传统的Boosting算法,如XGBoost、CatBoost、GBDT等集成学习算法面临巨大挑战。决策树构造过程中,需要计算分裂点的信息增益,传统算法需要根据所有数据样本计算每个特征的信息增益,计算过程烦琐,且样本越大特征越多,面临的计算负担也越重。这使得这些算法在处理大数据时非常耗时并且在准确性和效率之间难以权衡,与之相比,LightGBM利用GOSS及EFB,不需要扫描所有的样本点寻找最佳切分点,效率更高,减少内存使用,对硬件要求也有所降低,不损失精度同时缩短耗时。
2.1.1 LightGBM 算法原理

图1 LightGBM算法原理图Fig.1 Schematic diagram of LightgBM algorithm
2.1.2 LightGBM算法核心
1)基于Histogram的决策树算法
轻量级梯度提升机LightGBM是基于Histogram的决策树算法,它不是在排序后的特征值上寻找分割点,而是将连续的特征值放入离散的K个箱(bin)中,即将连续特征离散化成K个数, 训练时只需要遍历K个离散值而不用遍历所有样本数据。若需要进行特征选择,构造K值特征直方图,根据离散值遍历寻找增益最高的分割点。Histogram方法由传统的遍历所有数据变为遍历K个离散化数据,降低数据分隔复杂度,大大缩短时间,同时存储时用8位整型,可以减少内存占用。
2)单边梯度采样GOSS
数据样本梯度的不同直接影响信息增益的大小。根据信息增益的定义,梯度较大的实例(即训练不足的实例)对信息增益的贡献更大。因此,梯度较小的样本对信息增益影响较小,在保证一定准确性的情况下,可以随机去除低梯度样本,保留高梯度样本。基于以上分析,为了减少样本量,GOSS算法保留大梯度样本,对剩余小梯度样本进行随机采样,并且,为了补偿原始数据分布,小梯度样本数据引入常数乘子。计算信息增益时使用方差增益进行计算。大大减少了样本的数据量,提高了训练速度并减少了内存消耗。

图2 GOSS算法原理图Fig.2 Schematic diagram of Goss algorithm
3)互斥特征绑定EFB
在实际应用中,虽然有大量的特征,但特征空间是稀疏的,也就是说,许多特征(几乎)是互斥的,即它们很少同时取非零值,这就为减少特征维度提供了思路,在精度损失较小条件下,可以将多个互斥特征捆绑在一起,从而将特征维度变低,减少计算复杂度。以上就是互斥特征绑定EFB算法的思想,大大减少了特征数量。EFB算法将最优捆绑问题简化为图着色问题(特征作为顶点,如果它们不互斥,则两个特征有公共边),并采用常数近似比的贪心算法求解。

图3 EFB算法原理图Fig.3 Schematic diagram of EFB algorithm
2.1.3 LightGBM算法优点
(1)LightGBM是在Histogram算法的基础之上,从遍历样本变为遍历直方图,缩短了时间消耗,所占内存空间减少。
(2)EFB算法捆绑互斥特征,将时间复杂度从所有特征降为捆绑后的少量特征,有效避免不必要值特征的计算。
(3)LightGBM在取样时,GOSS算法选择梯度大的样本点,对于其他样本点依据一定比例抽取,保证模型精度,减少计算量。
(4)LightGBM支持特征变量的并行和样本数据并行计算。
(5)LightGBM选用带有深度限制的Life-wise算法机制,在同等分裂次数时,可以降低误差,提升精确度。
2.2 模型评价指标
本文通过对齿轮箱油温预测温度与实测温度之间的均方误差(Mean Squared Error,MSE)、均方根误差(root mean square error, RMSE)、平均绝对误差(mean absolute error,MAE)、平均相对误差绝对值(mean absolute percent error,MAPE)、拟合优度(R squared)和建模耗费时长这五项指标的计算,进而判断模型的可靠性。
(1)
(2)
(3)
(4)

3 齿轮箱油温预警实现
3.1 数据来源及数据预处理
用于分析的数据来自深圳××数据公司某风场C33号风机的SCADA[28-29]数据库2018年1月至2020年12月分钟级历史运行数据,共1519203行73列,占据存储空间461200KB。
共提供71个特征用于研究。在整个数据集中ControllerState列表示风机运行状态,包括待机状态、故障状态、维修状态、检查状态等,可以以此对风机历史数据进行清洗。研究目标齿轮箱油温值波动,对数据进行如下处理:(1)根据控制状态ControllerState列筛选风机正常运行数据行,删除风机待机、维修及故障状态数据行,为了减少波动的影响,根据风机故障记录删除故障发生前后一天内的数据。(2)对于缺失数据,考虑到数据量比较大,删除个别样本并不会影响模型的最终效果,对于缺失数据行,本文进行删除处理。(3)不同特征由于其量方式以及量纲不同导致数值差别较大,比如发电机速度1058.9,发电机温度9.7,直接用原始数据容易减弱数值小的变量的影响,用Z-score方法对数据进行标准化处理,通过处理,去除量纲影响,可使建模更可信。
3.2 特征工程
数据量过大,特征过多,往往会给机器学习的算法带来维度灾难,并且在现实应用中,时间消耗也是需要考虑的重要因素。选择部分重要特征,在确保一定精度条件下降低学习任务的难度,提升模型的效率,减少算法学习时间,增加模型的可解释性,使模型泛化能力更强。本文的特征工程主要聚焦特征变量贡献大小及其与目标的相关性两个方面。
(1)特征是否发散:如果一个特征是不发散的,那么对于辨别样本而言,该特征并没有起到影响。用低方差过滤进行特征选择,筛选方差较高特征变量。
(2) 特征与目标的相关性:计算Pearson相关系数,Pearson相关系数可以直接明了地刻画特征和响应变量之间关系,这一方法关注的重点是变量之间的线性相关关系,取值范围是[-1,1],越靠近1或-1说明变量之间相关性越高,越靠近0表示变量之间相关性越低。
(3)考虑到Pearson相关系数反映的是与目标变量的线性相关关系,不能反映非线性的相关关系,进而采用递归特征消除(REF)进行特征排序,递归消除特征法去掉一些权值系数较低的特征,组成新的特征集合。
用以上方式进行特征变量筛选,产生三个数据集:①使用全部特征变量(70个特征变量),构成数据集1;②基于方差排序筛选排名前30的变量,构成数据集2;③在②的基础上,使用Pearson相关系数和递归特征消除两种方式筛选综合排名前14的变量,构成数据集3。

表1 特征变量综合排序(前14)Tab.1 Comprehensive ranking of characteristic variables (top 14)
3.3 模型训练
3.3.1 划分训练集、测试集

表2 数据集划分Tab.2 Data set partition
3.3.2 LightGBM参数调优及模型预测效果
(1)参数调优
1)随机搜索(RandomizedSearchCV):
随机搜索顾名思义就是随机搜索进行超参数组合进行尝试,同样寻找在验证集上精度最高的超参数组合,但搜索机理不通。若搜索范围是连续的,则根据分布进行随机采样,若搜索范围是离散数值,则等概率采样,组合超参数。随机参数搜索也会输出超参数组合中最优的组合。由于是随机采样的,容易错过一些重要的信息,也正因如此,搜索速度更快,适合大规模数据。
2)网格搜索(GridSearchCV):
网格搜索法,在指定范围内寻找在验证集上精度最高的超参数组合,网格搜索会遍历给定范围内所有超参数组合,由于没有错过任何超参数,搜索效果很好,但面临大规模数据,时间代价较高,面临着维度灾难,数据较大时,通常不予选择。
寻找最优超参数组合时先使用Randomized SearchCV大致确定超参数范围,再经过GridSearchCV确定最优组合,不同规模数据超参数调优结果如表3所示。

表3 不同数据集的LightGBM的参数调优结果Tab.3 Parameter tuning results of LightGBM for different data sets
(2) 模型拟合效果
基于上述超参数训练模型,并用测试集数据进行拟合,对比轻量级梯度提升机LightGBM模型在三个数据集参数调优后的评价指标(见表4),综合误差和模型训练时长,LightGBM在数据集2的表现更好。
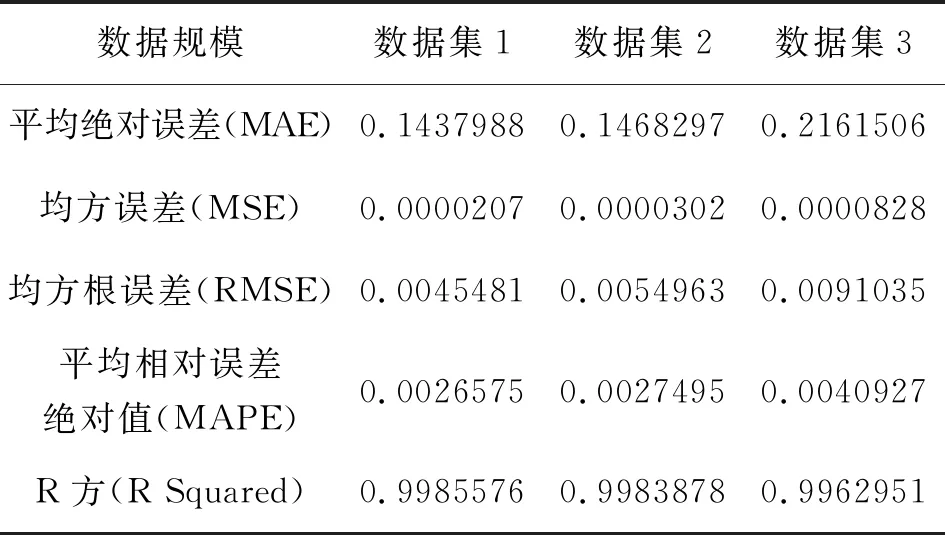
表4 LightGBM在不同数据集的表现Tab.4 Performance of LightGBM in different data set

图4 数据集2—LightGBM齿轮箱油温拟合曲线Fig.4 Dataset 2—Fitting curve of oil temperature based on Lightg BM gear box
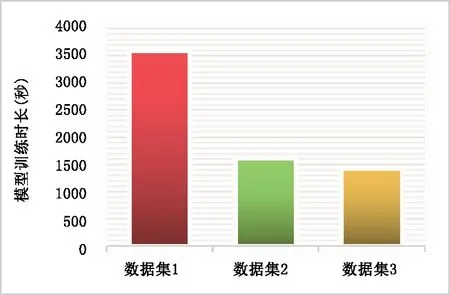
图5 不同数据集模型训练时长Fig.5 Training duration of different dataset models
3.3.3 其他模型效果
选择boosting另外两个流行算法XGBoost和CatBoost作为对照,模型训练时,选用轻量级梯度提升机LightGBM性能最佳的数据集2,同样按8∶2划分数据集,并使用同样的调参方式(Randomized SearchCV和Grid SearchCV),表5是XGBoost和CatBoost模型参数调优结果。综合比较LightGBM、XGBoost及CatBoost模型的评价指标测度值和模型训练耗时,LightGBM算法在时效性较优的同时,准确率最高,具有更好的鲁棒性。

表5 XGBoost、CatBoost的参数调优结果Tab.5 Parameter tuning results of XGBoost and CatBoost

图6 不同模型评价指标Fig.6 Evaluation indexes of different models
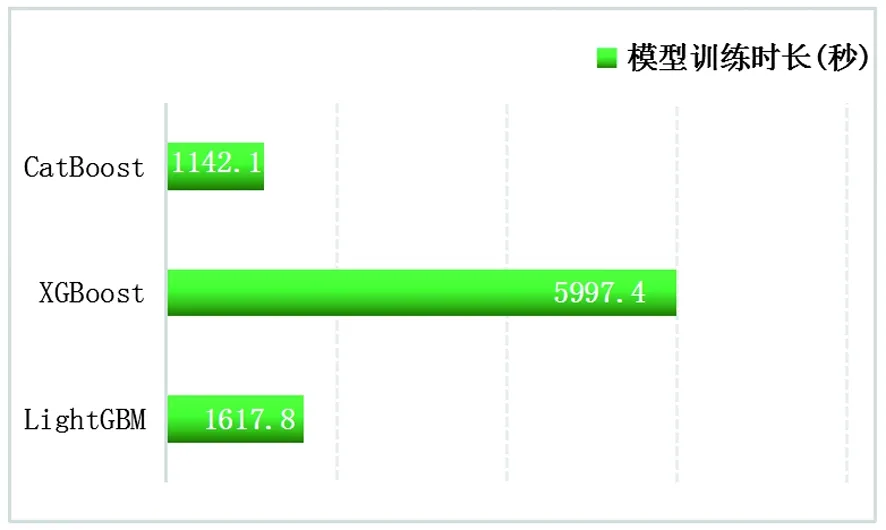
图7 不同模型训练时长Fig.7 Training duration of different models
3.3.4 模型故障诊断
对于实时运行数据,调用训练完成的LightGBM模型对齿轮箱油温进行预测,若预测值偏离真实值较大,表示风机齿轮箱可能会发生故障,可以此作为提前预警的标志。预警信号发出,需要对风电机组检修,检查整个风电机组部件工程庞大,此时可以参照LightGBM模型训练输出的重要性排序结果优先检查故障发生可能性较高的部件,尽量降低风机停机损耗。

表6 特征重要性排序(前10)Tab.6 Rank of feature importance(top 10)
3.4 实例分析
本文为了验证模型LightGBM模型的实用性及可靠性,基于风场某台风机为期三年的历史数据,筛选此风机故障原因为齿轮箱油温的故障记录,共查到2个历史故障,故障时段分别为2018年6月8日16时57分—23时00分;2019年6月9日9时38分—11时05分。对于齿轮箱油温的两个历史故障调用训练完成的LightGBM模型,输入故障发生前的数据进行预测。观察故障即将发生时齿轮箱油温的变化趋势,若基于模型的预测值与真实值偏离较大,方可启动预警提醒。
纵观图8和图9的2个故障的模型效果图,2018年6月8日的故障事前拟合效果更好,2019年6月9日故障事前拟合稍微欠缺。分析齿轮箱油温真实值与模型预测值波动趋势,明显两个故障在发生前,预测温度都有大幅度下降趋势,齿轮箱油温预测值与其真实值趋势偏离较大,认为其即将发生故障。故以上2个故障基于LightGBM模型都可以识别出来,此模型效果较优,可以用此模型进行齿轮箱油温的故障预警。

图8 齿轮箱油温6月8日故障预警图Fig.8 Failure warning chartof gearbox oil temperature on June 8
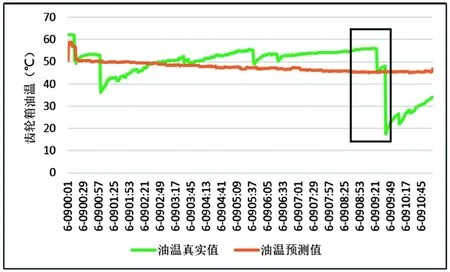
图9 齿轮箱油温6月9日故障预警图Fig.9 Failure warning chartof gearbox oil temperature on June 9
4 结论
本文在特征变量筛选时,使用方差排序、Pearson相关系数和递归特征消除淘汰低贡献变量;选择boosting当前三大流行算法(LightGBM、XGBoost、CatBoost)建立齿轮箱油温模型。综合比较不同模型的评价指标及训练时长,LightGBM算法的监测模型性能最佳;在齿轮箱油温预测值与真实值偏离较大时发出预警提示,维修人员在对大部件检修时,结合LightGBM模型的特征重要性排序及专业经验逐个预检。
实现风机故障预警可在故障发生前提醒工作人员检修关键部件,减少停机频率。目前风电机组的运行和维护还处于发展阶段。本文对于齿轮箱故障预警的研究极具实际意义。
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
交通科技与管理(2022年8期)2022-05-07
今日自动化(2022年1期)2022-03-07
科学与生活(2021年6期)2021-09-10
科学家(2021年24期)2021-04-25
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
福建基础教育研究(2019年3期)2019-05-28
西部资源(2018年1期)2018-11-01
女士(2017年2期)2017-03-25
恋爱婚姻家庭·养生版(2016年10期)2016-10-10
