
基于智能算法的DGA变压器故障诊断研究及决策树验证
2021-03-02 10:05张英徐龙舞王明伟刘喆张倩潘云
电力大数据 2021年11期
张英,徐龙舞,,王明伟,刘喆,张倩,潘云
(1.贵州电网有限责任公司电力科学研究院,贵州 贵阳 550002;2.贵州大学,贵州 贵阳 550025;3.贵州电网有限责任公司凯里供电局,贵州 凯里 556000)
油浸式变压器在电力系统中担任着重要的输配电功能,其安全稳定运行关乎着电力系统的安全稳定。然而,系统中运行的变压器难免存在各种潜伏性故障,主要分为过热故障及放电故障[1-2]。油浸式变压器在过热及放电下,变压器油及变压器内部绝缘物质发生分解,释放出表征设备运行状况的特征气体。针对变压器故障状态不同,其特征气体的产气速率、组分以及含量信息也有区别,研究其气体信息可实现变压器的故障诊断。然而,从大量油中溶解气体组分(DGA)数据分析可知,特征气体信息与变压器故障类型,故障程度间为复杂的关联关系,从而给基于变压器油中溶解气体的变压器故障判断工作带来了困难,本文将对经典方法、智能算法等进行简要分析,从而为DGA数据分析方向提供一些建议。
1 经典分析法
利用变压器油中溶解气体分析变压器故障的工作起始于19世纪60年代,随着大量研究的开展,变压器油中溶解气体分析变压器故障的工作取得了一系列的成效。国际电工委员会在热力动力学基础及大量的实践基础上,相继推荐IEC三比值法和改良三比值法分析充油变压器内部故障;德国发展的四比值法较三比值法而言,加入了C2H6与CH4气体组分的比值,四比值法对过热类的铁芯接地故障判断最有效;我国推荐的三比值法是基于我国的研究经验以及IEC标准所制定。在实践中,这些方法的可行性都被有力地证实[3];然而在实践中,该方法存在一定缺陷,三比值法存在编码不足问题,使得超出编码边界的故障无法判断,从而影响其判断的准确性[4]。基于智能算法的变压器故障诊断研究应需而生。
2 基于智能算法的变压器故障诊断研究
19世纪90年代以来,为克服传统方法的缺陷,以新方法新思路解决问题。典型的方法有专家系统[5],模糊理论[6],机器学习[7]等。
2.1 专家系统
专家系统模拟了专家基于自身知识进行推理的过程,国外应用专家系统大多只针对色谱分析数据的单项诊断,而我国的专家系统充分整合了变压器的色谱分析数据以及预防性试验所得的历史性数据。知识库和推理机是专家系统的主要部分。知识库获取是专家系统中的重点难点问题,研究者在该方面做了大量研究,常规表示知识的方式有产生式规则、框架式表示方法、面向对象的表示方法等。此外,知识库的模块化形式设计有利于整合变压器内外部的特征,嵌入其他故障诊断方法,建立多指标判断方法[8]。而推理机则基于丰富的知识库信息进行正向或方向链推理。
2.2 模糊不确定性
由于变压器故障原因与故障现象之间的映射关系复杂,各故障原因之间又存在模糊不确定性,而传统的三比值法采用的比值区间过于绝对,导致使用三比值等传统方法诊断时,对处于区间边界的数据易发生误判。利用模糊理论对变压器油中溶解气体数据进行模糊化处理,将故障现象作为模糊输入,故障原因作为模糊输出,建立变压器故障诊断模糊系统,能够有效提高诊断效果。
正是由于故障现象与故障原因之间的不确定性,模糊理论作为解决不确定性问题的有力工具,可用于变压器的故障诊断。文献[9]利用模糊理论处理了DGA,电气试验及绝缘油特性试验组成的多源参数,但在隶属度的选择存在主观性,导致实现结果存在一定局限。在模糊理论中,隶属函数的选择直接影响着模糊模型的准确度,而隶属度的选择仍是困扰研究者的关键问题。近年来,研究者在这方面也做了大量工作,然而所选择的隶属函数都存在一定的局限。因此,隶属函数的选择将仍然是近几年的研究热点之一。
2.3 机器学习
随着人工智能的兴起,机器学习在故障诊断,行为预测,智能识别等领域发挥着巨大的作用。机器学习在变压器故障诊断中的应用较早,且占据了一定比重。机器学习按照监督方式可分为监督学习,无监督学习,半监督学习。传统采用监督学习机制诊断变压器故障的有神经网络,决策树,支持向量机等,无监督学习有聚类和主成分分析(PCA),以及半监督学习有协同学习(Co-Training),三训练算法(Tri-Training)。
早些年的机器学习模型诊断变压器故障研究虽然较多,但未取得突破性进展。关键原因在于机器学习模型对训练样本集的数据,网络结构以及训练方案有着严格要求[10-11]。而早些年研究者又未对数据,网络结构以及训练方法进行充分地探讨。近年来,数据处理,智能优化计算,以及机器学习等技术的迅猛发展,使得研究者开始在数据、结构、训练方法上做大量的研究。
2.3.1 集成学习与深度学习
近年来,机器学习迅猛发展,更多的机器学习模型:极限学习机[12]、双向长短时记忆(Bi-LSTM)网络[13]、集成学习、深度学习等应用于变压器故障诊断中。其中,集成学习和深度学习由于独到的优势成为近几年来广受研究的热点模型。集成学习[14-15]由于组合了多种学习器的结果而获得比个体学习器更优的性能;深度学习模型在传统的浅层网络上改进,它模拟人脑的深层结构,对故障信息逐层抽象,逐次迭代,深度挖掘故障的潜在规则。文献以分类回归树CART为基分类器的XGBoost模型在损失函数中增加正则化项,提高了模型的泛化能力。此外,为克服交叉验证以及网格搜索参数寻优等传统优化方法的缺点,使用GA遗传算法训练模型参数。深度学习最具代表的模型有卷积神经网络(CNN)[16],深度信念网络(DBN)[17],堆叠自编码器(SAE)[18-19]等。卷积神经网络由于加入了卷积层而实现了高层次特征提取。卷积操作实质是对原始特征的转换,从低层次的特征经卷积操作后不断获得高层次的特征,通过训练得到的卷积神经网络内部蕴含了反应故障的高层次特征。
2.3.2 样本集数据的处理
作为诊断模型的输入量,特征量的性质决定性地影响着诊断模型的精度。早些年的研究未取得突破性的进展,关键原因之一在于未考虑模型输入数据中存在的冗余信息,输入信息与模型的匹配度,以及DGA数据作为单一指标数据的局限性等。近年来,研究者在样本数据问题的研究上取得了一系列进展。文献[20]利用数据处理工具,挑选出与故障类型最相关的输入变量。文献[21]对特征气体进行关联分析,在原始的DGA数据中得到一组新的特征量,基于此特征量能有效提高变压器的故障诊断率。文献[22]针对变压器不同故障类别发生概率不平衡及不同故障识别效果迥然不同等问题,利用层次分类和集成学习建立了一种多级层次变压器故障诊断模型。文献[23]以及文献[24]将DGA与电气试验数据等多信息融合作为诊断模型的样本数据,解决了DGA单指标难以完整表达故障信息的问题。
2.3.3 智能优化算法与诊断算法融合
诊断模型的训练问题是非线性函数求最优解解问题,训练方法的好坏直接影响着网络模型的诊断速度和精度。由于传统训练方法存在的固有缺陷,近年来,研究者们开始将智能计算方法引入到模型的训练中,力求获得用时少,占用内存少,精度高的智能诊断模型。GA、ACS—SA、帝国殖民竞争算法等进化计算和粒子群算法(PSO)、蝙蝠算法、天牛须算法等[25-29]群智能算法被广泛用于训练模型中,表1给出了智能优化算法与诊断算法融合建立的模型案例。

表1 智能优化算法与诊断算法融合案例Tab.1 Fusion case of intelligent optimization algorithm and diagnosis algorithm
这些智能优化算法虽能在一定程度上改进模型,然而,其模型在诊断速度以及准确率上仍未取得重大突破,需要进一步研究。
本文在综述了相关智能算法在变压器故障诊断的基础上,应用决策树算法对变压器的故障进行了预测工作。
3 基于决策树算法的变压器故障诊断
3.1 原理
决策树是一种典型的监督学习方式,结构呈树状。决策时,从根结点出发依次递归到中间结点,叶子节点。根结点和中间结点为每个属性的测试,决策树分支表示测试的输出,叶子结点表示最终的测试类别。
3.2 决策树的建立及决策树剪枝
对于给定的属性集合,可以训练出的决策树模型数量可以达到指数级别,其中的模型准确率不尽相同,如何建立出分类性能优越的决策树模型是关键问题,解决此问题的关键在于如何分裂训练数据以及如何结束树的分裂行为。
3.2.1 选择属性测试条件
决策树的好坏以划分前后的类分布定义,划分后的结点不纯度的高低反映了类分布的倾斜程度。Gini指标是衡量划分后的子女结点不纯度的度量方式之一。
(1)
其中,c为记录的类别,p表示某一类别占据总记录的比重。
Gini值越低反应划分后的子女结点纯度越高。Gini的取值范围在0到1之间。
进一步,增益G反映了划分前后的决策树效果。增益Z的定义为:
(2)
其中,Gini(parent)是给定父节点下的Gini不纯度度量,N为父节点上的记录总数,N(vj)为与子女结点vj相关联的记录数。Gini(parent)为定值,因此获得最佳决策树的划分方法等价于最小化子女结点的Gini加权平均值。
3.2.2 决策树剪枝
选取何种策略结束决策树的划分是关键问题之一。欠生长的决策树难以形成较为完备的分类规则,分类准确率欠佳;过分生长的决策树虽在训练样本上具有较低的分类误差,但同时会面临着过拟合的风险。先剪枝和后剪枝是终止决策树增长的主要策略。先剪枝是在完全拟合全部训练数据的决策树之前停止决策树的进一步增长。而后剪枝是预先让树充分增长,直到完全拟合训练数据,再通过自下而上地剔除子树。后剪枝是在完全生长的决策树上进行的剪枝操作,因此可避免先剪枝过早地停止树的增长的缺陷。
3.3 实验设计及结果分析
3.3.1 实验设计
本实验选取IEC TC10故障数据,共118条数据,包含低能放电,高能放电、中低温过热、高温过热以及正常数据。选取其中93条数据作为训练数据,25条数据用于测试,训练数据和测试数据的具体分布如表2。

表2 训练数据、测试数据分布Tab.2 Distribution of training data and test data
1)特征量选择
本文使用三比值法提供的三对比值乙炔含量与乙烯含量之比(C2H2/C2H4)、甲烷含量与氢气含量比(CH4/H2)以及乙烯含量与乙烯含量比(C2H4/C2H6)作为特征量。
2)建立基于决策树的变压器故障诊断模型
将93条训练数据训练生成完全生长的决策树,再利用后剪枝对决策树进行修剪。
3.3.2 结果分析
利用93条训练数据训练出来的完全生长的决策树以及修剪后的决策树分别如图1、2所示。
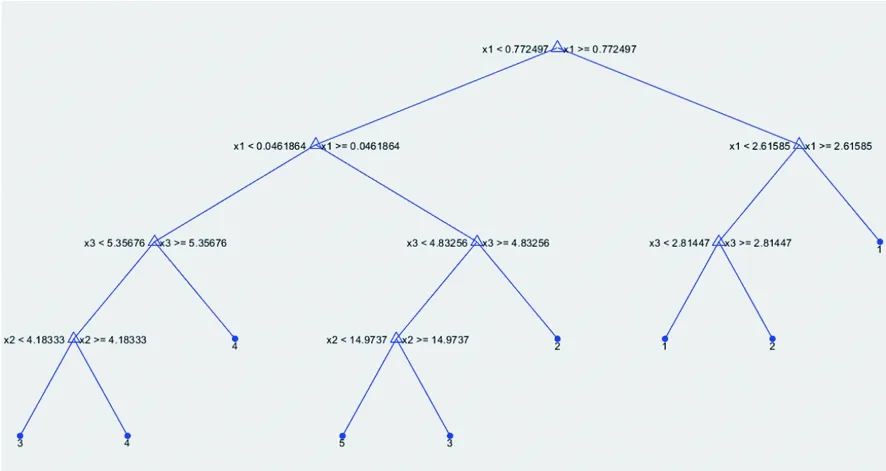
图1 完全生长的决策树Fig.1 Fully grown decision tree
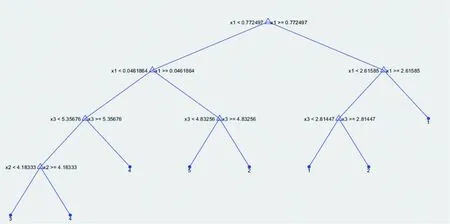
图2 剪枝后的决策树Fig.2 Decision tree after pruning
训练及经过后剪枝处理的决策树模型预测结果如图3所示。

图3 基于DGA数据的变压器故障诊断决策树Fig.3 Transformer fault diagnosis decision tree based on DGA data
在25条测试数据中,8条数据预测错误,其中低能放电共5条数据,预测成功3条;高能放电数据10条预测成功8条;中低温过热数据3条成功预测1条;高温过热3条数据成功预测2条;正常数据共4条成功预测3条,该模型的准确率在68%。提供的三比值法预测结果(准确率60%)相比提高了8%。
从数据的分析可知,本文提出的基于决策树的变压器故障诊断相比三比值法而言,预测故障准确率有一定程度的提高,是一种积极有效的诊断方法,但准确率仍有较大的提升空间。本文在通过综述智能算法在变压器故障诊断上的应用研究以及该决策树算法预测验证的基础上,对进一步提高各种基于DGA数据的变压器故障诊断提出相关建议。
4 基于智能算法的变压器故障诊断展望与建议
4.1 数据优化与整合
未来应充分借助数据挖掘技术等数据处理技术处理数据缺失,数据不平衡,数据冗余,数据含噪等问题,并深入挖掘数据的潜在价值。卷积神经网络应考虑如何最大效率地发挥卷积操作的价值,提取有用的特征。此外,未来还应将DGA数据,电气试验数据等多指标信息整合,实现数据深度融合应用于变压器故障诊断。在应用多指标信息诊断时,结合变压器故障案例,充分考虑不同指标对故障诊断的权重问题。
4.2 诊断模型的问题
模型的结构对诊断的效果有着直接影响:(1)深度学习应充分考虑模型深度,模型参数等信息。(2)集成学习除选择同类基分类器外,还应组合不同基分类器,充分综合各模型的优点。(3)结合各智能算法的优势。专家系统,模糊理论,神经网络,智能优化计算等多种智能方法应相辅相成,扬长避短,从而发展出性能优越的模型。(4)模型的选择和训练方法应当考虑数据的特点。将数据的不平衡,数据冗余等问题采用合适的模型及训练方法来解决,将更有利于提高DGA诊断变压器故障的准确率,指导生产运行。
猜你喜欢
保健医苑(2022年5期)2022-06-10
计算机应用与软件(2021年11期)2021-11-15
成都信息工程大学学报(2021年6期)2021-02-12
科学与信息化(2019年28期)2019-10-21
广东教育·高中(2018年1期)2018-01-31
中学生数理化·教与学(2017年4期)2017-04-22
天津诗人(2017年2期)2017-03-16
科学与财富(2016年32期)2017-03-04
新高考·高一物理(2015年4期)2015-08-20
决策与信息·下旬刊(2013年1期)2013-03-11
