
利用KL散度度量通道冗余度的深度神经网络剪枝方法
2021-11-15 11:49袁晓彤
计算机应用与软件 2021年11期
杨 鑫 袁晓彤
1(南京信息工程大学自动化学院 江苏 南京 210044) 2(江苏省大数据分析技术重点实验室大气环境与装备技术协同创新中心 江苏 南京 210044)
0 引 言
卷积神经网络(Convolutional Neural Network, CNN)的成功通常伴随着一些问题,如占用内存过大、计算成本过高等,而往往参数数目超过1亿的深度神经网络所需要的计算成本更高,这个问题阻碍了很多实际应用的实施,特别是基于便携式设备和手机端的应用。以经典的VGG16[1]为例,它拥有高达1.3亿的参数数量,且占用了超过500 MB的存储空间,仅运行VGG16网络进行图像识别这一功能就需要完成309亿个浮点运算(FLOPs),这些都在严重制约着深度神经网络在实际生活中的应用。
近年来,越来越多的研究人员加入到深度神经网络的加速与压缩的行列中,他们提出了各种新颖的算法,在追求模型性能优越的同时,尽可能地降低模型复杂度,追求性能与资源损耗的平衡。很多网络压缩方法的总结[2-3]将压缩方法进行了分类,大体上可以分为以下几种方法:低秩近似[4]、权重剪枝[5-7]、参数量化[6]、二值化网络[8]、知识蒸馏[9-11]、紧凑卷积滤波器设计[12]和通道剪枝[13-21]等。剪枝是实现网络压缩一种较为直接而且有效的方法,目前大多数剪枝算法都是先训练一个大型的复杂预训练模型,然后对这个模型进行剪枝,从而得到一个性能不错且较为紧凑的小模型。
本文采用结构化剪枝方法,利用KL散度定义通道的重要因子,根据重要因子对CNN的每层卷积层逐层进行通道剪枝,从而达到减少网络参数数量和FLOPs的目的。Li等[13]和Liu等[18]采用硬剪枝方法,验证了基于范数剪枝标准的通道剪枝方法有效性,而He等[17]从迭代软剪枝的角度证明了范数标准的通用性。本文对比了基于范数标准的方法,发现通道之间存在着差异性,保留不同的通道是至关重要的,且实验表明在CIFAR-10上剪枝ResNet,基于KL散度的剪枝标准优于其他方法,不仅如此,在CIFAR-100这样稍复杂的数据集上,表现也不错。本文还发现越深的网络存在着越多的通道冗余,往往更加需要网络压缩来减少计算开销。同时在增加剪枝率的情况下,网络性能并未下降太多,而在剪枝率过大的时候,精度下降则会变得严重。平衡好剪枝率与性能的关系才能在减少占用内存和浮点运算的同时,还可以提高网络的鲁棒性。本文的实验代码与模型都可以在Github上下载。
1 相关工作
随着CNN深度的加深,大量的研究人员研究了很多不同的算法来加速和压缩CNN模型,这些算法会以很多指标作为压缩的标准,比如降低的内存、减少的浮点运算、加速推理的速度等。根据对网络结构的破坏程度,本文将目前压缩算法分为非结构化压缩方法和结构化压缩方法。
首先,非结构化压缩方法分为以下几种方法:低秩近似[4]、权重剪枝[5-7]、参数量化[6]和二值化网络[8]等。Denton等[4]利用了几种基于奇异值分解的张量分解方法,并通过低秩近似权重矩阵来压缩卷积层,可以很大程度上减少所需的计算资源。Han等[5]提出了一种分为三个步骤的权重剪枝方法。首先,通过正常的网络训练找出“重要的”权重连接,然后删除“不重要的”权重连接,最后对剪枝后的稀疏网络进行微调,直到更好地达到性能和计算开销的平衡。为了进一步地压缩网络,Han等[6]继续采用霍夫曼编码来量化剪枝后的权重,这使得剪枝后的网络得到了最大程度上的压缩和加速。文献[5-6]的方法是在训练过程结束后进行剪枝操作的,而Jin等[7]则提出了迭代硬阈值的方法来提升深度神经网络的性能,主要分为两个步骤来执行,先使用硬阈值方法将一些权重小于阈值的连接置为0,对保留的有效连接进行微调,然后再重新激活置0的连接,可以大大减少网络参数量的大小。Rastegari等[8]提出了两种二值化网络:Binary weight network和XNOR-Nets,主要是通过对权重进行二值化操作,达到减少模型存储的目的,同时可以加速模型。参数量化和二值化网络大多旨在最大限度地减小网络规模,会很大程度上改变网络原本的结构,且需要特殊的硬件来实现加速功能。
结构化压缩的方法不会破坏原来的网络结构,主要包括:知识蒸馏[9-11]、紧凑卷积滤波器设计[12]和通道剪枝[13-21]等。CNN主要是从数据集中提取特征来完成分类、识别、预测和分割等任务,在这个环节中提取特征是非常重要的,特征能直接影响到网络最终的性能,而越深的神经网络往往能提取出更鲁棒的特征,知识蒸馏也就应运而生了。Hinton等[9]提出了将一个大模型作为教师网络,将一个小模型作为学生网络,让学生网络从教师网络中蒸馏知识,即用学生网络的分类概率去逼近教师网络的分类概率,Yang等[11]也使用了知识蒸馏来提升小网络的性能。通道剪枝则是另一种较为常见的结构化压缩方法,这些方法大体上分为两种:(1) 采用三步骤剪枝方法,先训练好网络,然后对网络剪枝,最后通过微调来提升准确率。如:Li等[13]利用L1范数作为剪枝标准,认为通道权重的L1范数较小的为不重要通道,那么去除后对于网络最终的结果不会有很大影响。He等[15]则是用LASSO回归来选择通道,并用剩下的通道与原始网络进行误差重构,使得剪枝后的网络与剪枝前的网络输出特征映射尽量相似,这样经过微调后剪枝网络的性能也不会下降太多。(2) 采用软剪枝的方法,在训练的过程中通过剪枝标准将不重要通道的权重置0,训练结束后再进行网络重构得到剪枝后的网络。如:He等[16]用L2范数作为剪枝的标准,在训练的每次迭代中将权重范数较小的通道置0,在迭代更新参数的时候还允许置0通道进行更新,让网络在训练过程中选择剪枝通道。接下来的工作中,He等[17]还提出了通道之间存在冗余,用欧氏距离来判断通道能否被其他通道所代替,从很大程度上减少了通道的冗余且极大地减少了浮点运算。靳丽蕾等[21]则将卷积核剪枝和权重剪枝结合起来,混合剪枝CNN,还利用最小化重构误差来提升网络的性能。随着网络剪枝的发展,网络结构搜索与自动机器学习逐渐流行起来,Liu等[18]总结了几种最先进的剪枝算法,提出了为了获得一个有效的小网络去训练一个参数过多的大网络是不必要的,剪枝算法可以被认为是在搜索有效的网络结构。由于手工剪枝算法耗费很多的人力与时间,He等[19]提出用强化学习来学习如何剪枝,当准确率上升或下降时用奖励惩罚机制去训练自动机器学习工具。目前网络结构搜索和自动机器学习已经成为热门研究课题,网络结构搜索旨在搜索鲁棒的迁移性能优越的网络结构块,而剪枝标准则可以成为搜索通道的标准。
基于以上结构化剪枝的启发,不同于使用L1范数衡量通道的重要性,本文提出利用KL散度去衡量通道之间的差异性,如果一个通道与另一个通道的分布比较接近,那就可以说明这两个通道可以彼此替换,删去其中一个对最终性能可能影响并不大。而KL散度正好可以表示两个分布之间的相似度,即KL散度越大说明这两个通道差异性越大,所以本文利用KL散度去除差异性较小的通道,实现对CNN模型的压缩与加速。
2 基于KL散度的通道剪枝方法
如今CNN的应用主要受到以下两个方面的制约:(1) 时间复杂度,即模型的运算次数(FLOPs),主要包括单个卷积层和CNN整体的时间复杂度,时间复杂度决定了模型的训练以及预测时间,如果复杂度过高,则会导致模型训练和预测耗费大量时间,既无法快速地验证想法和改善模型,也无法做到快速的预测。(2) 空间复杂度,主要包括参数数量以及模型在实际运行时每层计算的输出特征图大小,空间复杂度决定了模型的参数数量,由于维度的限制,模型的参数越多,训练模型所需的数据量就越大,这些参数以及网络结构信息都需要存储在磁盘上面,占用过大的磁盘存储空间对于嵌入式设备来说是一个巨大的资源负担。
通道剪枝的原理是通过某一衡量标准来裁剪不符合要求的通道,减少了卷积通道数目在不改变网络原始结构的基础上,还可以减少模型占用内存和FLOPs,进一步提升网络的推理速度。但是对预训练的网络直接进行通道剪枝会带来一定准确率的下降,这是不可避免的。本文采用硬剪枝方法,对一个预训练模型直接进行剪枝重构网络,这种方式较为暴力,往往会造成精度的急剧下降,所以对硬剪枝过后的网络进行微调,即在较低学习率的情况下,利用数据集再次训练重构之后的网络,允许保留的网络参数进行更新,经过适当的迭代后,剪枝网络的性能会与原始网络的性能相差无几。利用KL散度选择出重要因子较小的通道并剪枝,然后微调剪枝网络,直到达到性能和计算开销上较好的平衡。
2.1 CNN剪枝框架
首先训练一个性能优越的大网络,对预训练网络的每一层卷积层的通道分别计算KL散度;然后通过每个通道的KL散度来判断在当前卷积层中与其他通道的差异性,即KL散度大的通道则是不可替代的,而KL散度小的通道与其他通道差异性较小则可以裁剪掉,根据这一方法,CNN的每一层卷积层按照一定的剪枝率剪枝完成后,便可得到剪枝后的模型;最后将剪枝后的网络进行微调,最终能得到性能优越的小模型,小模型不仅推理速度更快,而且拥有较少的参数量和FLOPs。根据KL散度进行通道剪枝的整体框架如图1所示。
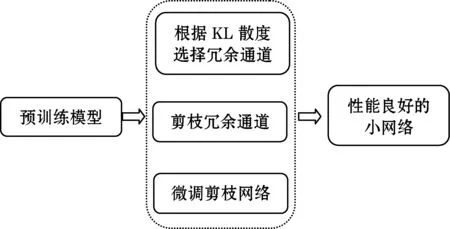
图1 基于KL散度的通道剪枝框架
2.2 KL散度
KL散度又叫作相对熵,是描述两个概率分布P与Q之间差异的一种方法,可以用来衡量一个分布偏离另一个分布的程度,若两个分布完全一样,则它们之间的散度为0,当KL散度越小的时候,两个分布越接近。
首先假设两个离散概率分布分别为P与Q,那么两者的KL散度为:
(1)
卷积层的每个通道权重并不是一个离散概率分布,所以本文将每个通道权重进行规范化,即将通道权重进行归一化,从而获得通道权重的离散概率分布。具体实施是先对单个通道权重取绝对值,继而累加起来,然后除以总和,最后可以得到每个通道权重的离散概率分布。
2.3 利用KL散度进行通道选择
现阶段很多研究人员提出了很多不同的剪枝标准来衡量通道的重要性,比较热门的是用基于范数的通道选择,基于范数的剪枝标准[13,16,18]认为通道权重范数较大可以认定为是重要通道,即这些通道对于最终结果具有很大影响,相反权重范数较小的通道则没有太大影响,实验也表明剪枝权重范数较小的通道对于最终结果影响会小一些。当然还有Liu等[14]提出的以网络BN层的比例因子作为重要因子,来决定哪些通道将会被剪,具体是利用L1正则化重要因子,将重要因子较小的通道剪枝。基于范数的剪枝标准通常无法考虑到通道之间的相似性,本文则提出利用KL散度来度量通道之间的分布信息,通道之间的差异性相同的通道对于最终的结果影响是大致一样的,所以剪枝相似的通道可能是更加合理的。
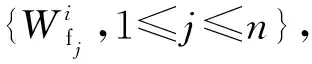
(2)
在第i层卷积层中,这些通道之间的差异性越高,其KL散度就越小,由于差异性只能判断两个通道之间的关系,本文便提出重要因子的概念,将通道之间的差异性累加便得到了重要因子,KL散度越小的通道,相似度越高,说明通道之间差异性也就越小,重要因子越小,则需要被剪枝。定义第j个通道的重要因子为:
(3)
如式(3)所示,第i层的每个通道都会计算出相应的重要因子,并根据重要因子排序选择出重要因子较小的通道,保留重要的通道。
本文实现的通道剪枝方法如图2所示,首先对第i层卷积层的通道进行KL散度衡量重要性,接下来去除掉差异性较小的通道,最后将剩余通道权重赋值给新网络,便可得到剪枝后的网络。图中用白色虚线代表被剪枝的部分,当然并不存在于剪枝网络中。
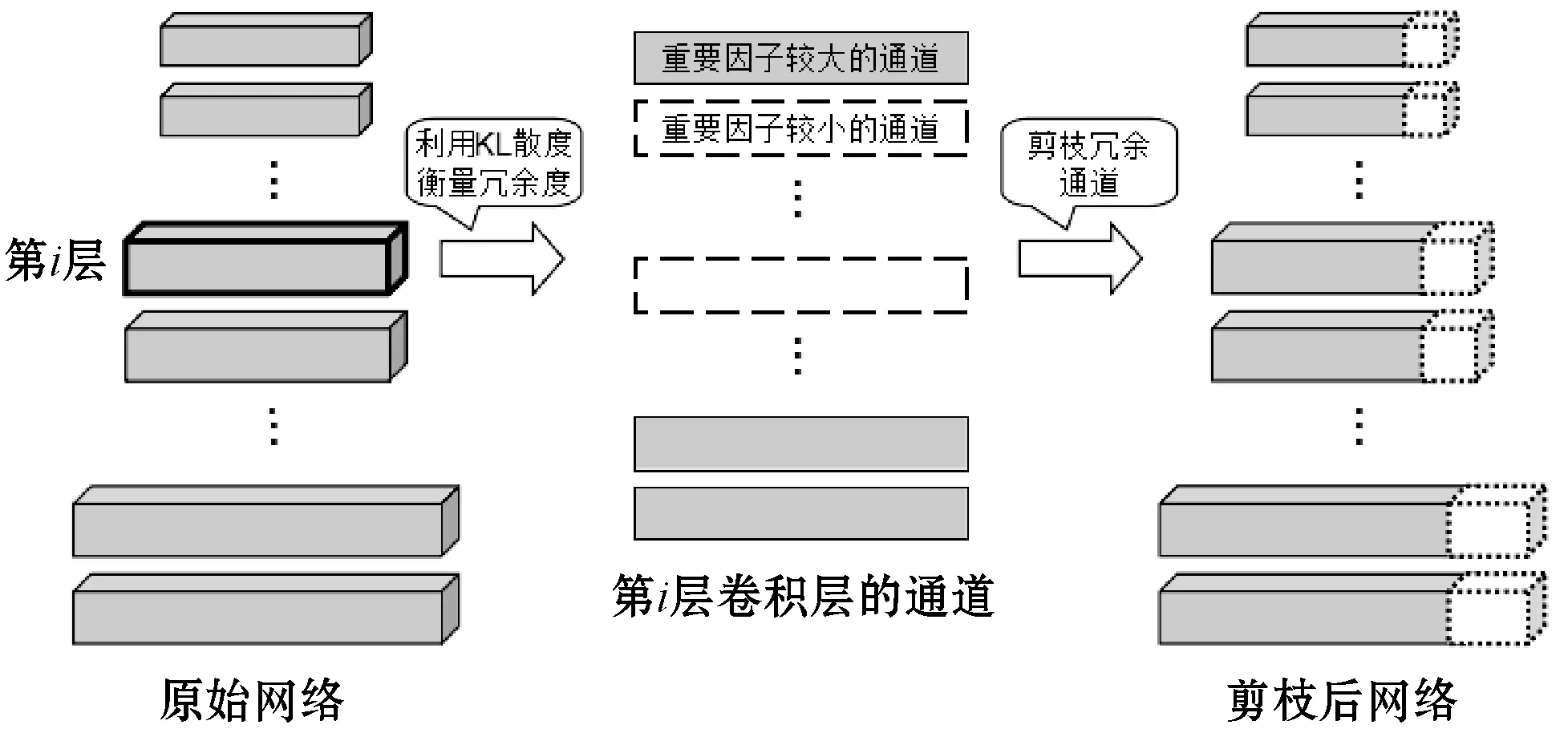
图2 通道剪枝示意图
2.4 通道剪枝及网络重构
算法1给出了本文整体训练过程。首先对于给定的预训练好的大型原始网络,根据每层卷积层的剪枝率,经过通道选择后,确定每次需要剪枝的通道数量,随后进行硬剪枝,且根据剪枝率重构出一个新的紧凑网络。随后归一化通道权重并计算通道的重要因子,并将保留重要因子较大的通道权重赋值给紧凑网络,这样得到的紧凑网络便是剪枝后的网络,参数数量和FLOPs根据不同的剪枝率相应的降低,然后通过一定的迭代来微调剪枝网络,使得剪枝网络最终的性能达到与原始网络相近,甚至更加优越。
算法1基于KL散度的通道剪枝算法
输入:网络权重W={Wi,1≤i≤L},剪枝率ri。
输出:剪枝网络Ws={Wsi,1≤i≤L}。
Step1遍历网络中的L层卷积层。
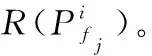
Step3根据重要因子排序,保留n×(1-ri)个重要因子较大的通道,并删除剩余n×ri个通道。
Step4将保留通道的权重W赋值给剪枝网络。
Step5在数据集上微调剪枝网络,输出表现良好的网络权重Ws。
经过通道剪枝与网络重构之后,微调过后的网络性能通常会下降一些,甚至低于原始网络准确率,根据不同的剪枝率,网络的占用内存和FLOPs都会不同,且越高的剪枝率会使得越多的计算开销下降,当然也可能导致性能的急剧下降,所以找到性能与计算开销的平衡点是很重要的。
3 实验与结果分析
本文在两种数据集(CIFAR-10[22]和CIFAR-100[22])上实现了利用KL散度来对ResNet[23]进行通道剪枝的实验,在Pytorch[24]上实现了对ResNet的加速与压缩。ResNet是经典的CNN框架,其主要的计算量集中在卷积层当中,全连接层参数数量很小,卷积操作的计算开销占FLOPs的绝大部分,所以压缩与加速ResNet可以用来证明剪枝标准的有效性。CIFAR-10数据集是深度学习图像分类的一种较为常用的数据集,它包含60 000幅像素为32×32的彩色图片,分为10类,每类含有6 000幅图片,训练集为50 000幅图片,测试集为10 000幅图片。CIFAR-100图片数目不变只是类别变成了100类,训练集和测试集图片数目不变。
3.1 CIFAR-10上不同方法实验结果对比
在CIFAR-10数据集上,本文对 ResNet56和ResNet110进行了通道剪枝,用KL散度来计算出每个通道的重要因子,将重要因子较小的通道直接剪枝,并将保留的通道权重复制到重构后的紧凑模型中,然后将紧凑模型微调60个迭代,在每个迭代中遍历数据集,用随机梯度下降算法进行后向传播更新紧凑模型的网络权重,直到达到令人满意的性能,并且在迭代过程中采用学习率递减的调参方式,使得性能提升。
本文主要与四种方法进行了比较:L1-pruning[13]、 LCCL[25]、SFP[16]和Rethinking[18]。本文的实验设置与文献[18]的Rethinking算法一致,在ResNet56上跳跃第20、38和54层,在ResNet110上跳跃第36、38和74层,即上述层不进行剪枝,因为上述层较为敏感,在这些层上应用过高的剪枝率会导致性能的急剧下降。由于剪枝设置一样,所以本文的FLOPs下降率与Rethinking算法也相同。
如表1所示,本文是基于Rethinking基础上实现的算法,所以它们的基本精度相同,而与SFP不同,根据下降精度来看本文的剪枝标准性能更加客观一点,本文还将每次剪枝后性能最优的方法加粗了,这样可以直观地看出在CIFAR-10数据集上,本文在ResNet56和ResNet110上剪枝10%和30%都超过了上述方法,与原始网络性能相比也不逊色,且参数量与FLOPs都减少很多。卷积神经网络的本质是通过卷积层提取特征,然后通过分类器进行分类任务,而通道之间提取到的特征存在着冗余,可以由其他通道提取的特征替换,所以适当剪枝后有些网络的预测性能提升,而当剪枝率过高时,裁剪掉不可替换的通道时便会导致网络性能的下降。本文通过通道之间的差异性来判别冗余通道,能在最大限度上降低精度损失。

表1 不同剪枝方法在CIFAR-10数据集上对ResNet剪枝的实验结果对比
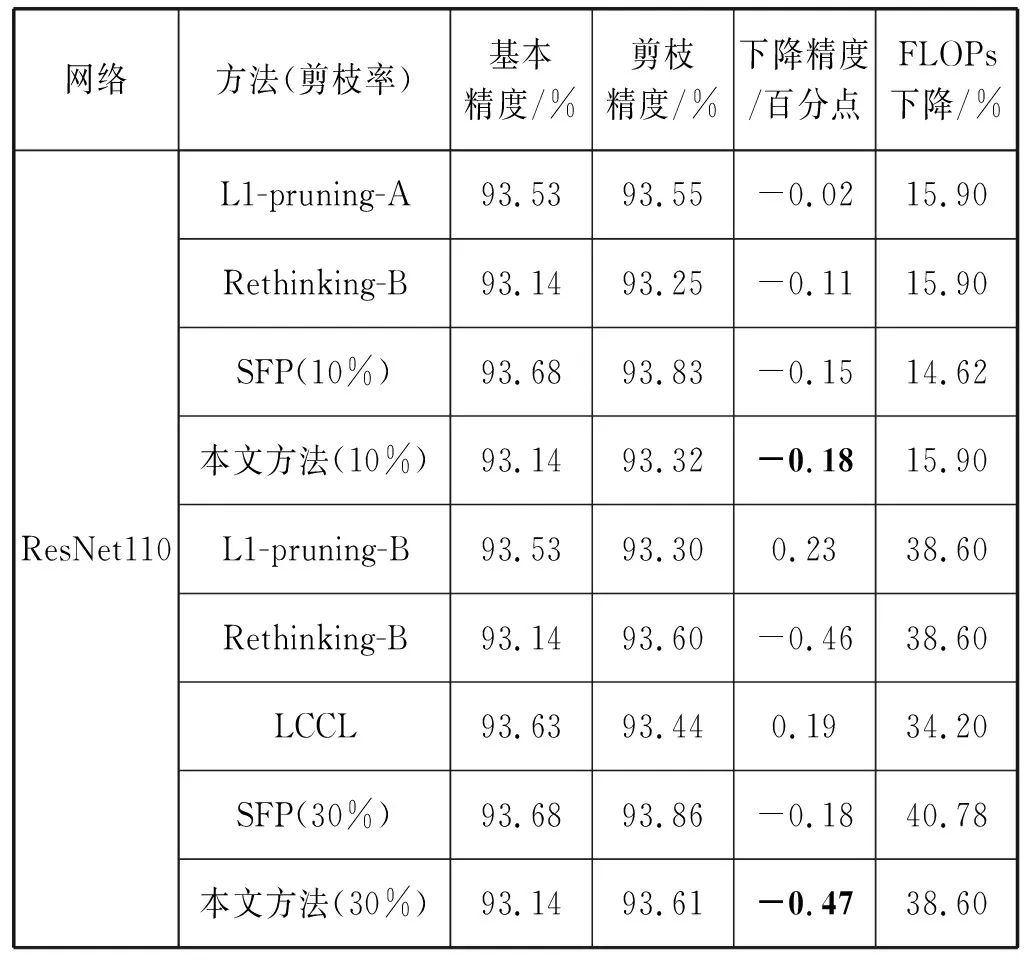
续表1
3.2 基于CIFAR-10不同剪枝标准实验结果对比
本节比较了两种不同剪枝标准对于剪枝网络最终的影响,如表2所示,其中剪枝标准为KL散度是基于KL散度保留差异性较大的通道,而L1范数则是将通道权重的L1范数较大的通道保留。在进行对比实验时,除了剪枝标准不同外,其余设置都是相同的,都是采用三步剪枝方法,预训练网络相同,且剪枝后微调次数也一致,超参数的设置也都相同。

表2 不同剪枝标准在CIFAR-10数据集上对ResNet剪枝实验(%)
表2实验结果是基于CIFAR-10的,通过剪枝后精度对比原始网络精度,用基于KL散度的剪枝标准最高可以提升0.9百分点的精度。此外,剪枝精度大多略高于原始精度,可以看出剪枝从一定程度上提升了网络的性能。同样对比剪枝后的精度发现基于KL散度的剪枝标准是优于L1范数的剪枝标准的,也可以从另一方面解释通道之间存在可替代性,所以,利用剪枝标准选择差异性较大的通道并保留是至关重要的。
表3是在CIFAR-100数据集上剪枝ResNet56和ResNet110的,可以看出精度下降有点严重,可能是网络并不存在很大的冗余,每次提取的特征都是很重要的。KL散度方法较之L1范数的方法也较为有优势,在下降精度方面KL散度大多高于L1范数。当剪枝率从10%增加到30%可以对比看出有时候剪去20%效果与10%效果相差不大,但是较之原始网络下降较多,说明CNN卷积层中剪枝一部分重要通道后,还会存在一些重要通道之间的冗余。ResNet56与ResNet110的下降精度可以看出在大网络中冗余度是随着深度增加而增加的,而且去除更多的通道精度下降并不是很多,所以大网络上运用剪枝效果会更加明显。

表3 不同剪枝标准在CIFAR-100数据集上对ResNet剪枝实验(%)
3.3 基于CIFAR-10不同剪枝率实验结果对比
由3.2节得出的结论,CNN的卷积层都存在一定的冗余通道,在不同的剪枝率下,卷积层的冗余通道不断减少,最终达到性能与计算开销的平衡,所以剪枝率的选择对于网络压缩是很关键的。
如图3所示,本文通过在CIFAR-10数据集上对ResNet56应用不同剪枝率,来找到剪枝率对于性能的影响。可以看出,剪枝率在50%的时候精度下降了很多,一些重要通道被剪枝时导致性能的急剧下降。而在10%~40%剪枝率下,性能略微有所提升,且基本保持不变,可以看出网络删减了冗余的通道,还从一定程度上提高了网络的性能。通常网络剪枝是需要一个严格的剪枝标准来衡量滤波器重要性,即使达到了这个标准,过高的剪枝率还是会对网络性能产生影响,使用一些特殊的方法来提升准确率便必不可少,可以利用特征映射重构来最小化重构误差,还可以通过知识蒸馏来提升网络性能,即在尽可能减少网络尺寸的同时维持网络性能才是关键。
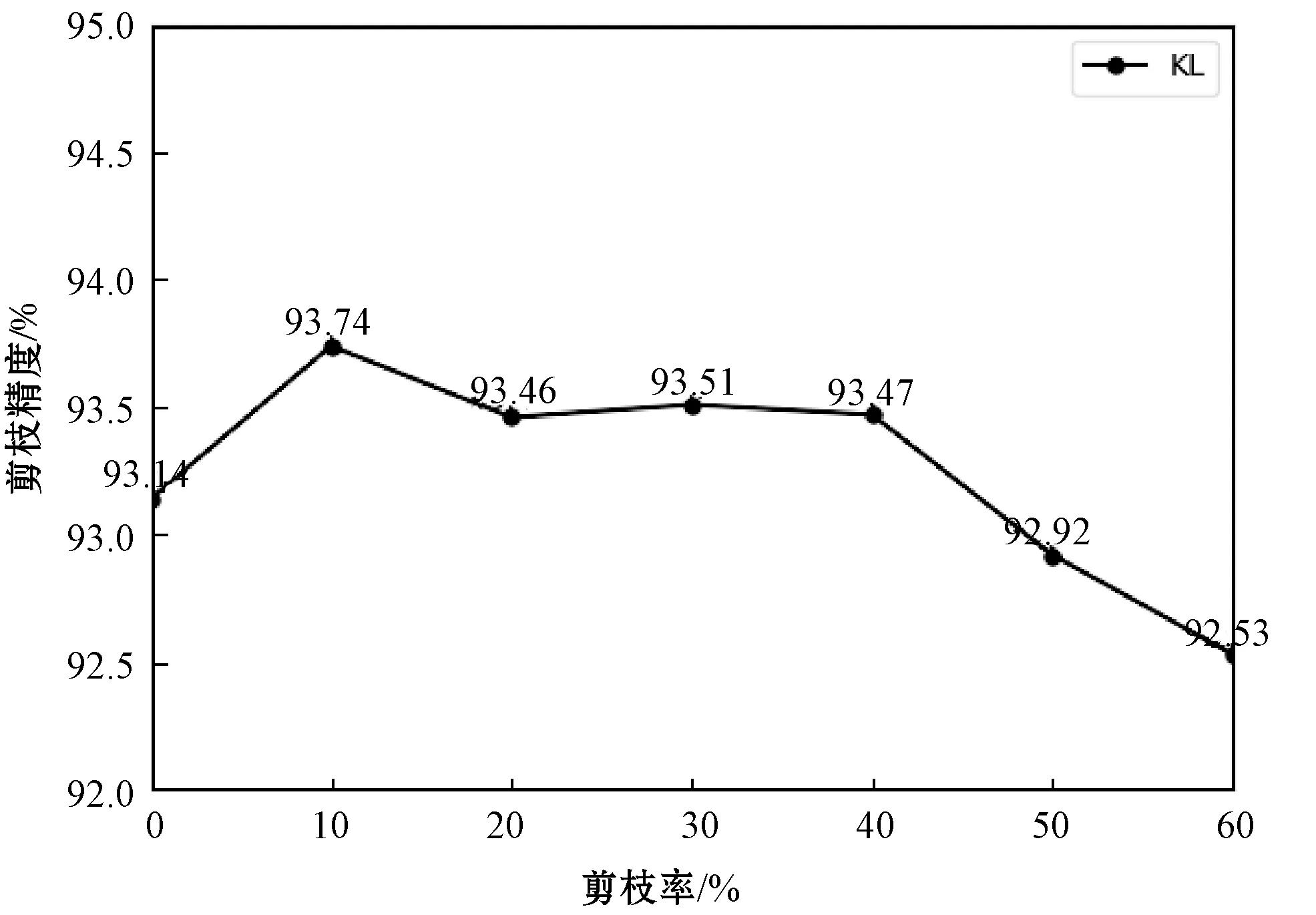
图3 ResNet56在CIFAR-10上不同剪枝率的性能比较
3.4 剪枝后ResNet性能指标
剪枝后网络的参数数量、浮点运算率(FLOPs)和网络测算时间都是在卷积神经网络应用时需要重点考虑的事情。表4为剪枝后的ResNet在10 000幅图片的CIFAR-10数据集上推理的时间、网络参数数量和浮点运算数量的对比。
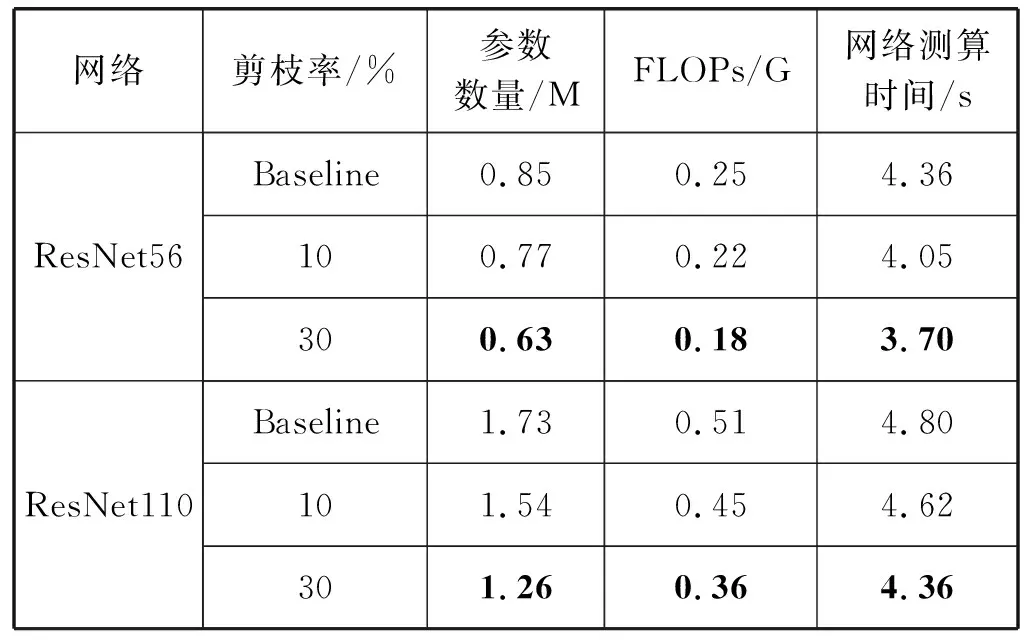
表4 ResNet在CIFAR-10数据集上的性能指标
表4中,Baseline表示未剪枝的原网络模型,网络测算时间的计算方法是推理5次,去除最高值和最低值,剩余3次网络测算时间取平均网络测算时间。随着剪枝率的提高,参数数量和浮点运算数量都大幅地下降了,并与剪枝率基本呈线性关系,网络测算时间也下降了0.5 s左右。
4 结 语
本文将KL散度用作通道之间差异性的衡量标准,并定义通道的重要因子,在精度下降不大的情况下,剪枝不重要的冗余通道,从而达到减少网络参数以及FLOPs的目的。对于一个预训练好的网络模型,本文直接对其进行剪枝,然后再通过微调的方法恢复与原始网络相近的性能。一个严格的剪枝标准在结构化剪枝中是必不可少的,而本文通过实验证明了KL散度能够选择出冗余的通道,是一个较为有效的标准。实验还表明越深的网络往往存在更多的冗余,设置合适的剪枝率可以提升网络性能,降低网络测算时间。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
农业工程学报(2022年12期)2022-09-09
农业工程学报(2022年6期)2022-06-27
计算机应用(2022年5期)2022-06-21
心理学报(2022年5期)2022-05-16
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
当代陕西(2020年17期)2020-10-28
人大建设(2018年5期)2018-08-16
