
基于LLVM的编译锁机制技术研究与实现
2021-11-15 11:48巩令钦周清雷
计算机应用与软件 2021年11期
巩令钦 沈 莉 周清雷 胡 浩
1(郑州大学信息工程学院 河南 郑州 450000) 2(中国科学技术大学计算机科学与技术学院 安徽 合肥 230000) 3(无锡江南计算技术研究所 江苏 无锡 214083)
0 引 言
底层虚拟机(LLVM)是一款开源的编译器架构,目前已被苹果、Google、Facebook等各大公司采用[1]。LLVM在重用GCC前端高级语言处理的同时,提供了独特的编译器后端移植架构[2]。为了充分挖掘处理器的计算潜力,并行处理技术的实现显得尤为重要。软件层面中,并行处理技术通过多线程技术和向量化进行实现,其中基于多线程的并行处理技术对处理器的操作系统环境改动最小[3]。
在多线程环境下,程序的执行由传统的线性执行变为非线性执行。两个或多个线程访问相同的内存单元时,会造成系统内存的不一致性。由于多个线程共享同一块内存,当内存访问冲突时,将产生错误的执行结果,同一个进程内的其他线程也将受到影响[4]。严重的情况下将导致程序出现死锁,造成系统资源浪费。并行计算的同步原语和多线程的调度的正确性都是基于原子指令实现的,原子指令的实现方式决定程序的正确性以及运行性能的好坏[5]。所以,如何保证多线程环境下对内存操作的原子性,保证访问内存的正确性,是LLVM多线程编译支持中的重要课题。
原子指令实现的关键是保证对内存操作的原子性。原子性规定了指令对内存单元修改的顺序性。在对内存操作进行处理时,原子指令的读操作和写操作之间不能有其他指令对该内存单元进行修改[6]。除此之外,需要确保LLVM编译器的指令调度不会破坏原子指令的顺序性和完整性。
根据申威处理器的硬件特性,选择使用锁机制实现LLVM编译器原子指令的编译支持,对需要原子性访问的地址空间加锁。当编译器进行原子指令的翻译时,使用锁指令实现原子指令的原子性。本文在申威处理器下基于LLVM编译器对锁机制进行研究与实现。在多线程环境下使用并行计算机基准测试集NPB进行测试,所有程序均通过自校验。在16个线程下,Fortran语言程序平均加速比为11.91,最大加速比为15.73,C语言程序平均加速比为8.08,最大加速比为13.32。
1 相关工作
锁机制是一种可以使所有共享访问互斥进行的同步控制机制[7]。 锁机制在X86和MIPS等架构中均有不同的实现方式。LLVM编译器后端中,尚未有针对申威处理器架构的锁机制的编译支持。
在X86架构的Linux内核中,提供了3种机制保证原子性,包括基本操作的原子性、总线锁机制(Bus Locking)和Cache内部锁机制。在基本操作的原子性中,X86处理器保证了对8位、16位、32位、64位共享内存读写的原子性。在总线锁机制中使用LOCK#信号阻塞其他处理器的总线访问请求。在Cache内部锁机制中通过CPU直接使用Cache内部的锁进行实现,Cache内部锁可以保证整条cache line不会同时被多个原子指令修改[8]。X86架构提供原子操作的指令包括inc、xchg、xand等,通过对原子指令加入LOCK宏可以实现指令执行的原子性。
MIPS架构使用精简指令集计算机(Reduced Instruction Set Computer,RISC)架构的指令集,未提供诸如X86架构支持的inc、xchg、xand等复杂原子指令。在MIPS架构中提供支持实现锁机制的汇编指令链接加载(Load Linked,ll)以及条件存储(Store Conditional,sc)[9]。ll指令的功能是原子性地读取指定内存单元中的值,sc指令的功能是原子性地对内存单元进行修改。在ll指令和sc指令之间的汇编指令会被原子性执行[10]。MIPS架构通过ll指令和sc指令进行锁机制的实现。 同时,Alpha、PowerPC和ARM等RSIC指令集架构均支持链接加载和条件存储指令[11]。
LLVM编译器中对X86和MIPS指令集均有相应的X86后端和MIPS后端进行编译支持。申威处理器采用自主指令集,LLVM编译器需要增加后端对申威架构的支持。相比于X86架构,申威处理器不提供LOCK宏及inc、xchg、xadd等复杂原子指令。相比于MIPS等RSIC指令集架构,申威处理器不提供链接加载和条件存储作为基本的原子指令。由于申威处理器的硬件特性和指令集与MIPS架构和X86架构均有较大区别,所以无法使用X86架构或MIPS架构下锁机制的实现方式作为LLVM编译器申威架构后端锁机制的实现方式。本文基于LLVM编译器并结合申威处理器指令集特性提出了一种锁机制的实现方式,保证了多线程环境下原子操作的原子性。
2 锁机制的编译支持策略
2.1 原子指令语义映射
LLVM编译器架构分为高级语言前端、中间代码优化器和后端代码生成器三个部分。高级语言前端主要负责将高级语言转化为LLVM IR,中间代码优化器对LLVM IR进行优化,后端代码生成器对IR进行降级和代码生成操作。在锁机制的实现过程中,前端对高级语言解析后将原子操作转化为IR中的atomic关键字并传递给后端。IR降级的过程中,后端根据指令模板对伪指令的定义、原子操作类型和数据类型的区别,将atomic关键字降级为对应的伪指令并继续进行后续编译流程。在伪指令扩展Pass中对伪指令进行语义映射,最终生成汇编代码。其过程如图1所示。

图1 原子操作指令生成过程
编译器对伪指令进行语义映射处理时,对每条伪指令映射的汇编代码通过锁指令进行加锁。多线程环境下,并行的指令流水在遇到加锁的汇编代码时转为串行执行。根据申威处理器的硬件特性,为8位、16位、32位和64位数据类型的数据设计不同的伪指令。每种数据类型的伪指令根据功能的不同可划分为2种,分别为原子二元运算操作和原子比较并交换操作。原子二元操作包括原子加、原子减、原子与、原子交换、原子或、原子异或。对每条伪指令,在后端实现伪指令语义映射及锁机制降级处理流程。其中,伪指令含义参考Linux内核中内建函数接口设计,不同数据类型的内建函数对应不同的伪指令。面向申威处理器的LLVM的伪指令的含义如表1所示。其中,n=8,16,32,64,分别表示8位、16位、32位、64位数据类型。

表1 伪指令设计及含义
在实现对每条伪指令的语义映射过程中,将加锁的汇编代码作为一个独立的基本块。该基本块内的指令不参与指令调度。在设计锁机制汇编基本块时,需要考虑指令排布和寄存器的使用,以尽可能少地汇编指令实现锁机制。基本块的实现过程如图2所示。

图2 锁机制基本块的实现

图3 基本块的插入
LLVM编译器前端对高级语言解析后将原子操作转化为IR中的atomic关键字并传递给后端。后端将atomic关键字转换为伪指令后,对伪指令进行降级处理,实现原子指令的语义映射。
2.2 锁机制数据处理
申威处理器中锁机制需要支持8位、16位、32位和64位数据读写的原子操作。申威处理器对齐访存最小粒度为4字节,32位数据和64位数据类型的地址不需要进行对齐处理。8位和16位的数据需要锁机制对内存地址进行对齐处理后执行存取操作。锁机制中对8位和16位数据类型处理包括对非对齐内存地址的对齐处理和保证非对齐地址中有效数据提取和写回的正确性。
在锁机制中,传入的非对齐内存地址的对齐处理可以通过与立即数的与非操作实现。如需确保地址N字节对齐,则传入的地址与立即数N-1进行与非操作。
非对齐地址中的有效数据的正确提取和写回需要使用有效数据位拼接的方式实现。锁机制中使用数据抽取操作,数据插入操作,数据屏蔽操作和数据按位或操作对数据进行处理。数据插入处理指将有效数据插入全零内存区域,确保存储有效数据的内存单元中没有脏数据位。数据插入处理如图4所示。
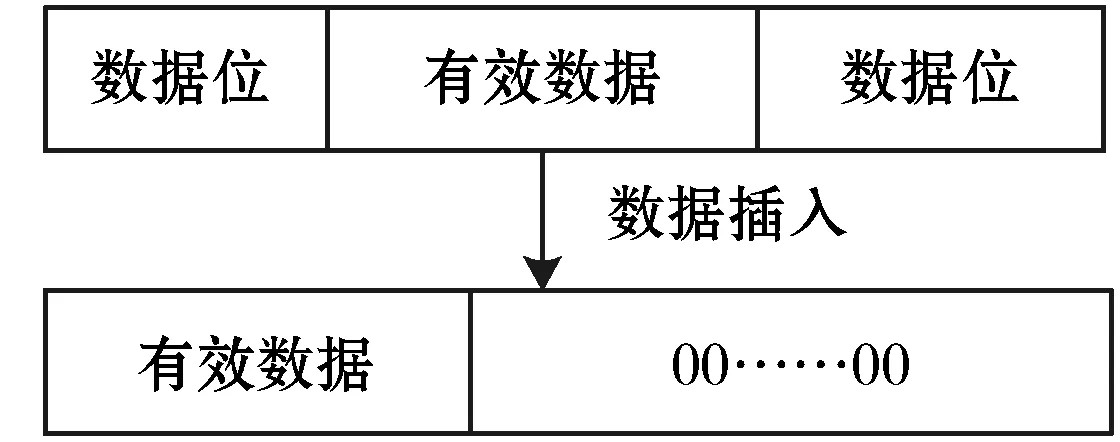
图4 数据插入处理
数据插入操作处理在内存单元中,有效数据前后均有数据位的情况。数据插入处理在锁机制算法中使用insert函数表示。
数据抽取处理指将有效数据抽取至全零内存区域,确保存储有效数据的内存单元中没有脏数据位。数据抽取处理在锁机制算法中使用extract函数表示。数据抽取处理如图5所示。

图5 数据抽取处理
数据屏蔽处理指屏蔽内存单元中的有效数据,将内存单元中除有效数据外的数据位抽取至全零内存区域。确保有效数据写回时内存单元的无关数据位的一致性。数据屏蔽处理在锁机制算法中使用mask函数表示。数据屏蔽处理如图6所示。
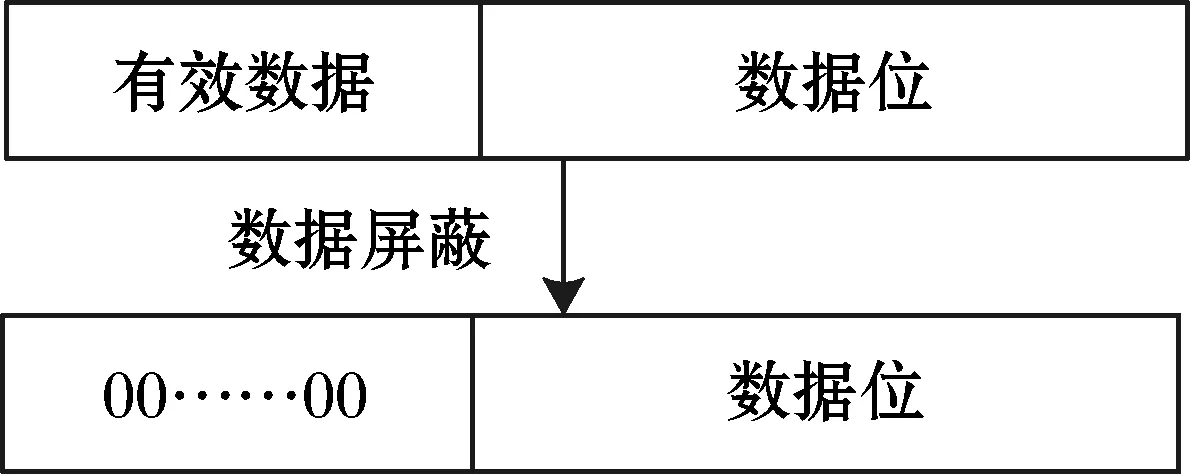
图6 数据屏蔽处理
通过数据插入操作,数据抽取操作,数据屏蔽操作和数据按位或操作进行数据拼接操作,可保证非对齐内存地址中有效数据提取和写入的正确性。数据拼接操作过程如图7所示。

图7 数据拼接操作
从对齐内存地址中取出数据后,使用数据抽取操作和数据屏蔽操作将有效数据和其余数据位抽取到全零区域中。然后使用抽取后的有效数据进行运算,将运算后的有效数据与抽取后的其余数据位进行按位或操作,得到完整的有效数据并写回内存。
3 锁机制编译支持技术实现
3.1 32位和64位数据的锁机制实现
在实现锁机制的过程中,关键操作包括lock_load32、lock_load64、lock_store32、lock_store64、lock_read、lock_write和barrier。lock_load32操作表示在对齐锁地址指向的内存单元中读取4字节数据,lock_load64操作表示在对齐锁地址指向的内存单元中读取8字节数据。lock_store32操作对内存单元进行修改,执行4字节数据的原子写操作,lock_store64操作执行8字节数据的原子写操作。lock_write操作判断是否获取锁。lock_read操作判断锁机制是否成功执行。barrier表示存储器栏栅,编译器在存储器栏栅指令之前所有读写操作都执行后才可以执行存储器栏栅指令之后的操作。
val_cmp_32表示32位数类型的原子比较并交换操作。以val_cmp_32伪指令为例,不需要锁机制进行数据处理的32位数据类型的原子性比较并交换操作在锁机制中的伪指令语义映射算法如算法1所示。
算法1val_cmp_32语义映射
输入: new_val, old_val, lock_ptr。
输出: res_val。
do{
insert(barrier)
lock_val ← lock_load32(lock_ptr)
res_val ← lock_val
cmp ← old_val == lock_val
flag ← lock_write(cmp)
if cmp is 0 then
break
else if flag is 1 then
lock_store32(new_val, lock_ptr)
end if
flag ← lock_read()
}while flag is 0
算法1是val_cmp_32伪指令语义映射后的逻辑的伪代码。该算法将参数中指针指向的值与老值比较,若相等,则将新值写入内存,并返回老值。若比较失败,则不更改原内存地址中的值并返回参数指针指向的值。当lock_write(cmp)为1时,表示获取写锁成功,否则跳出锁机制处理。当lock_read()为1时表示锁机制成功执行,否则重新执行该原子操作直至锁机制成功执行。64位数据类型的比较并交换与此类似。
原子加、原子减、原子与、原子交换、原子或、原子异或操作均为二元操作,可以使用相同的处理流程。以原子加的add_fetch_32伪指令为例,锁机制的实现如算法2所示。
算法2add_fetch_32语义映射
输入: val, lock_ptr。
输出: res_val。
do{
教育是未来的事业,儿童是民族的未来。教师要把一个不懂事的孩子培养成国家的栋梁,民族的脊梁,要付出毕生的精力。教师工作是平凡的,每天上课下课、备课、批改作业,为学生解惑排难;但教师的职业又是伟大的,教师要把儿童这个幼苗培育成参天大树。古人说:“十年树木,百年树人。”说明创造物质是比较容易的,塑造人、铸造人的精神是要经过几代人的努力。因此,教师要满怀对学生的真心关爱,以学生的发展为本,甘为人梯,乐于奉献,用心灵和汗水一点一滴地滋润学生的心田,把全部精力和满腔热情献给教育事业。
insert(barrier)
lock_val ← lock_load32(lock_ptr)
lock_write(1)
res_val ← val + lock_val
lock_store32(res_val, lock_ptr)
}while lock_read() is 0
算法2是add_fetch_32伪指令语义映射后的逻辑的伪代码。该算法将参数值与内存中的老值相加,返回相加后的新值,并存入内存。res_val是执行二元运算操作后的结果值。即将指针指向内存地址中的值与参数值执行二元运算操作,如原子加、原子减等6种二元运算操作。64位数据类型的二元运算操作与此类似。
3.2 8位和16位数据的锁机制实现
val_cmp_8表示8位数据类型的原子比较并交换操作。以伪指令val_cmp_8为例,锁机制中需要对数据进行处理的8位数据原子比较并交换操作的伪指令语义映射算法如算法3所示。
算法3val_cmp_8语义映射
输入: new_val, old_val, lock_ptr。
输出: res_val。
do{
insert(barrier)
lock_align_ptr ← nand(lock_ptr,7)
eff_new_val ← insert(new_val, lock_ptr)
ori_lock_val ← lock_load64(lock_align_ptr)
eff_lock_val ← extract(ori_lock_val, lock_ptr)
res_val ← eff_lock_val
cmp ← old_val == eff_lock_val
flag ← lock_write(cmp)
if cmp is 0 then
break
if flag is 1 then
other_lock_val ← mask(ori_lock_val,lock_ptr)
ret_val ← or(other_lock_val, new_val)
lock_store64(ret_val, lock_align_ptr)
end if
}while lock_read() is 0
算法3中,主体算法框架与4.1节类似,算法中主要新增对8位数据类型的有效数据和非对齐内存地址的处理。nand(lock_ptr,7)表示通过与立即数7进行与非操作,实现对地址进行8字节对齐处理。or表示数据按位逻辑或。该算法将参数中指针指向的值与老值比较,若相等,则将新值写入内存,并返回老值,若不相等,则返回指针指向的值。16位数据类型的比较并交换与此类似。
原子加、原子减、原子与、原子交换、原子或、原子异或均为二元操作,可以使用相同的锁机制处理流程。以伪指令add_fetch_8为例,锁机制中需要对数据进行处理的8位数据原子加操作的伪指令语义映射算法如算法4所示。
算法4add_fetch_8语义映射
输入: val, lock_ptr。
输出: res_val。
do{
insert(barrier)
lock_align_ptr ← nand(lock_ptr, 7)
ori_lock_val ← lock_load64(lock_align_ptr)
lock_write(1)
eff_lock_val ←extract(ori_lock_val, lock_ptr)
ori_res_val ← val + eff_lock_val
eff_res_val ←insert(ori_res_val, lock_ptr)
other_lock_val ← mask(ori_lock_val,lock_ptr)
res_val ← or(other_lock_val, eff_res_val)
lock_store64(res_val, lock_align_ptr);
}while lock_read() is 0
算法4是add_fetch_8伪指令语义映射后的逻辑伪代码。该算法将参数值与内存中的老值执行二元运算操作,如原子加,返回二元运算操作后的新值,并存入内存。使用nand(lock_ptr,7)处理非对齐内存地址,使用insert操作、extract操作和mask操作实现有效数据位的提取和写回。16位数据类型的二元运算操作与此类似。
4 实 验
在申威1621处理器的LLVM编译器上对锁机制分别进行正确性测试和性能测试。LLVM编译器版本为7.0,并行测试环境为16个CPU的并行环境。正确性测试使用Linux内核源码中的内建函数进行测试。性能测试采用NPB(NAS Parallel Benchmark)测试集[12]。 NPB测试集为3.0版本的C语言NPB测试集和3.0版本的Fortran语言NPB测试集。
4.1 正确性测试
Liunx内核源码中,通过一系列内建函数实现原子操作[13]。内建函数以及其完成的功能如表2所示。

表2 Liunx内建函数功能
通过调用Linux内核中的13个内建函数并分别传入8位、16位、32位、64位数据对LLVM中的锁机制进行验证。实验结果如表3所示。

表3 功能测试结果
实验结果表明LLVM编译器锁机制中新增52条伪指令均正确运行,执行结果与标准结果一致。在申威1621处理器的多线程环境下,LLVM编译器可以正确通过锁机制实现原子操作。
4.2 性能测试
NPB是NASA提供的,用于评估并行超级计算机性能的测试程序集,是并行计算机基准测试程序。其中共包含8道测试题目,分别为EP(Embarrassingly parallel)、MG(3D MultiGrid)、FT(Fast Fourier transform)、IS(Integer sort)、CG(Conjugate Gradient)、LU(Lower upper triangular)、SP(Scalar penta-diagonal)、BT(Block Tri-Diagonal)[14]。每题包含5种测试规模,分别为S、W、A、B、C。其中S类为样例程序,W类通常用于工作站,A类通常是运行中等性能的工作站系统,B类运行于高端的工作站系统或者小型的并行系统,C类则用于超级计算系统[15]。选用B类规模进行测试,B类规模大小如表4所示。

表4 B类规模大小
在LLVM编译器中,C/C++语言采用clang作为前端对进行编译处理,Fortran语言采用flang作为前端进行编译处理。本文测试了C语言的NPB测试集和Fortran语言的NPB测试集,对16个线程下OpenMP库的加速情况进行了对比。
面向申威1621处理器的LLVM编译器对于C语言程序的并行加速比如表5所示,平均加速比为8.08,最大加速比为13.32。

表5 C语言程序NPB加速比

续表5
面向申威1621处理器的LLVM编译器对于Fortran语言程序的并行加速比如表6所示,平均加速比为11.91,最大加速比为15.73。

表6 Fortran语言程序NPB加速比
4.3 实验结果分析
由功能性测试可知,锁机制中52条伪指令均可完成对应的原子性操作。在基于申威1621处理器的LLVM编译器上加入锁机制后,可正确对内存进行原子性的读写操作,实现了8位、16位、32位、64位数据类型的原子加、原子减、原子与、原子交换、原子或、原子异或、原子比较并交换操作,保证了多线程环境下对内存访问的一致性。
由性能测试可知,在加入锁机制后,LLVM编译器通过使用OpenMP库,C语言版NPB测试集所有程序和Fortran语言版NPB测试集所有程序在16个线程的环境下均正确执行并自校验通过。C语言版NPB测试集程序平均加速比为8.08,最大加速比为13.32。Fortran语言版NPB测试集程序平均加速比为11.91,最大加速比为15.73。
5 结 语
本文对锁机制和原子指令进行了介绍,结合申威处理器的特性与LLVM编译器的特点,针对锁机制的具体实现进行了讨论并介绍了52条伪指令及其算法实现。
通过本文对锁机制的实现,LLVM编译器可以正确稳定地在申威处理器下的多线程环境中运行,使得申威处理器的多核化优势得到了利用和体现。下一步的工作将对锁机制开销进行进一步的分析并充分挖掘申威处理器并行计算的潜力。
猜你喜欢
北京航空航天大学学报(2022年2期)2022-03-08
少儿科学周刊·儿童版(2021年22期)2021-12-11
少儿科学周刊·儿童版(2021年22期)2021-12-11
少儿科学周刊·儿童版(2021年22期)2021-12-11
学校教育研究(2020年11期)2020-06-08
电脑报(2019年31期)2019-09-10
航空科学技术(2019年2期)2019-09-10
当代陕西(2019年13期)2019-08-20
电脑爱好者(2015年21期)2015-09-10
中华少年(2009年9期)2009-09-14
