
基于语义解析的领域问答系统的设计与实现
2021-11-15 11:48刘园园李劲华赵俊莉
计算机应用与软件 2021年11期
刘园园 李劲华 赵俊莉
(青岛大学数据科学与软件工程学院 山东 青岛 266071)
0 引 言
问答系统由于具有简单、准确的回答而越来越成为自然语言处理、信息检索等领域研究的重点,与传统的搜索引擎相比,问答系统不仅能接受用户直接的自然语言方式提问,而且能够更深层次地理解用户的查询意图,返回精准的答案。
中国每年参加高考的学生越来越多,高考结束后所有考生都将面临艰难的志愿选择问题,学生需要在有限的时间内充分地了解学校信息、选择合适的学校,一旦报名时选择有误,就可能会与理想的学校失之交臂,因此,能够快速、准确地了解学校信息非常重要。目前对学校基本信息的查询主要是基于搜索引擎,但是这种方式返回的是成百上千的网页,学生从中定位到所需要的信息需要耗费大量精力,而且每查询一个学校的信息都需要进行一次网页检索,做出很多无用功,另外单个学校的搜索也无法实现对学校信息整合、比较。因此研究并开发一款面向考生的、综合各学校信息的高考咨询领域的智能问答系统,具有现实意义且十分必要。
问答系统按其问题答案的来源可以分为基于Web的问答系统[1]、基于社区的问答系统[2]、基于知识图谱的问答系统[3]等。知识图谱能够通过建立数据之间的关联链接,将碎片化的数据有机地组织起来,更易于信息的搜索、挖掘和分析[4],因此成为问答系统常用的数据存储形式。
基于知识图谱的问答方法(KBQA)主要分为基于语义解析[5]的方法和基于信息检索[6]的方法。基于语义解析的方法通过对自然语言进行语义解析,将其转换成逻辑形式,然后生成相应的结构化查询语句,在知识库中检索得出答案。基于信息检索的方法可以看作是答案的排序算法,从知识库中检索候选答案的集合,根据问题特征和候选答案特征对候选答案进行评分和排序,选择得分最高的作为最终答案。
现有的KBQA方法大多集中在简单的问题上,即仅涉及一个实体和一个关系,常见的解决方法是将问题映射到知识图谱中的三元组查询,即能得到答案;而涉及多个实体和关系的复杂问句,一般的KBQA方法则不能很好的工作[7]。高考咨询领域的问句大多是含有多实体或关系的复杂问句,如问句“山东省排名第一的大学是哪个?”中就包含多个约束:1) 问句意图是学校;2) 学校位于山东省;3) 学校排名第一。因此,为了能回答多约束问题, 本文设计一个基于语义解析的问答模型,首先通过主题实体和查询意图生成核心推理链,然后通过添加约束生成最终的查询图,从而将语义解析转化为查询图生成,最后将查询图转换为知识库查询语句。
1 构建高校信息知识图谱
1.1 知识图谱
知识图谱是一种新的知识表示方法,最先由谷歌提出以提供更加智能的搜索服务。知识图谱本质是具有一个有向图结构的知识库,以结构化的方式描述了现实世界中存在的实体、概念,以及它们之间的语义关系,以更好地组织、管理和理解互联网时代产生的海量信息[8]。目前知识图谱已经在医学[9]、电商[10]等多个领域得到广泛研究。
知识图谱的构建方式有两种,一种是自顶向下的构建方式,一种是自底向上的构建方式。前者指的是预先为知识库定义好本体或数据模式,然后再将实体加入到知识库中;后者指的是先利用相关技术把文本中的有用实体提取出来,从中选择置信度较高的添加到知识库中,从而构建出顶层本体模式[11]。本文高校信息知识图谱的构建大体分为三个步骤:1) 设计知识图谱本体;2) 采集数据;3) 数据导入与可视化。构建流程如图1所示。
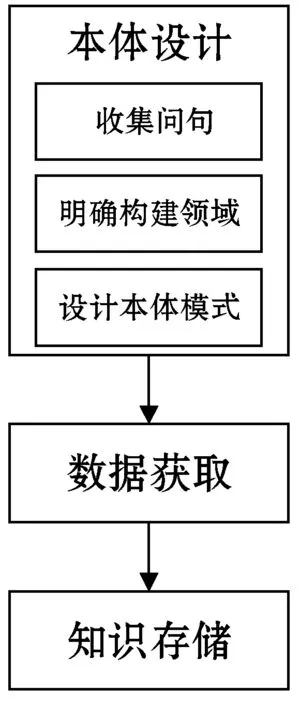
图1 知识图谱构建流程
1.2 本体设计
构建知识图谱之前要了解构建的领域,然后设计知识图谱的结构。为了能了解到学生在高考报名时最常咨询的信息,本文在一些大学的贴吧、高考咨询类网站等收集相关的问句,对其进行整理分类,可以了解到,学生想要知道的信息大体分为三种情况:1) 学校基本信息。如地址、排名、是否是985、奖学金政策、宿舍环境等。2) 学院信息。如招生计划、学院特色、招生专业等。3) 专业信息。包括未来就业方向、所学课程、录取分数等。
知识图谱包括实体、属性和关系,一些信息点既可以作为实体存储,也可以作为实体的属性存储,为了有效地划分实体和属性,本文首先列举出所有的信息点,然后把其中与其他实体有联系的、易成为比较点的、易反向询问的、带有属性的信息点归为实体类,其他的归为属性类。如“专业的录取分数”这个信息点由于具有录取时间、录取省份和录取类别等多个属性,因此不能作为“专业”这个信息点的属性,而是作为一个单独的节点,与“专业”节点建立联系;而如“学校地址”这个信息点由于是学校单独有的,而且各个学校的地址都不相同,不太可能与其他实体相连,因此,将其划分为属性。
为了能更清晰地了解各个实体之间的联系,本文选用protege构建高校知识图谱的本体模型。如图2所示,共构建了12个实体,14种关系,每个实体有不同的属性。
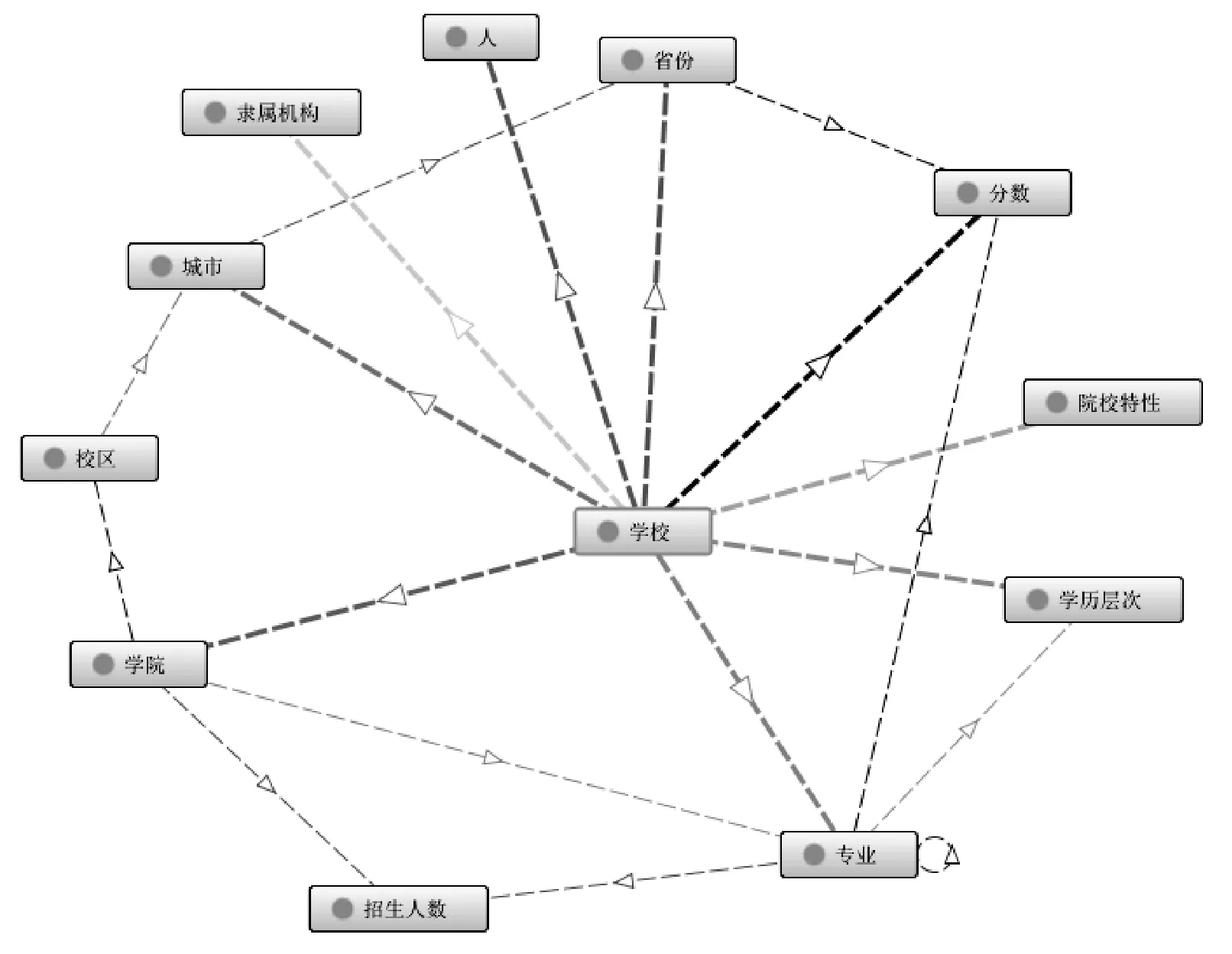
图2 高校信息知识图谱本体
1.3 数据获取
构建完本体之后,下一步就是数据的获取,本文主要通过Python爬虫的方式获取数据,主要数据来源如下: 学校的基本信息从百度百科等半结构化数据进行爬取;院系设置、专业录取分数线和招生计划等从各学校官网和中国教育在线-高考数据库网站获取;学校排名、院校特性和宿舍条件等从阳光高考网站进行获取。阳光高考网站是教育部高校招生阳光工程指定平台,集合了一些院校信息、就业率、录取分数线等信息,爬取的部分信息如图3所示。另外还有一部分数据来自于中文开放知识图谱CN-DBpedia。

图3 基于阳光高考网站爬取的数据示例
1.4 知识存储
知识图谱的存储可以分为基于表结构的存储和基于图结构的存储,基于图结构的存储用节点表示实体,用边表示实体之间的关系,能够直接准确反映知识图谱的内部结构,有利于对知识的查询。本文采用属性图数据库Neo4j进行知识存储,为实现高考咨询领域的问答系统提供底层的数据支持。
Neo4j是目前最广泛流行的属性图数据库,具有成熟数据库的所有特性,能够对数据进行高效的处理。另外,Neo4j还支持以图的方式对数据进行可视化展示。Neo4j自带一个大数据量的导入工具neo4j-import,支持并行、可扩展地大规模导入CSV数据,导入的CSV文件一般至少包含一个实体文件和一个关系文件。实体文件的格式一般包括“:ID”“name”“:LABEL”等栏,关系文件的格式包括“:START_ID”“:END_ID”“name”“:TYPE”等栏,其中“:LABEL”和“:TYPE”分别代表实体的类型和关系的类型,“:START_ID”和“:END_ID”分别是关系中开始节点和结束节点的ID,二者缺一不可,因为关系不能指向空也不能从空发起。本文将爬取的信息数据转换成以上的CSV文件,然后进行数据导入。导入后的可视化效果如图4所示,单击节点可以看到该节点的属性,有向边代表两个实体的关系,为了方便查询,本文将一些时间、省份等属性添加到关系中,如图5所示。

图4 知识图谱的可视化展示
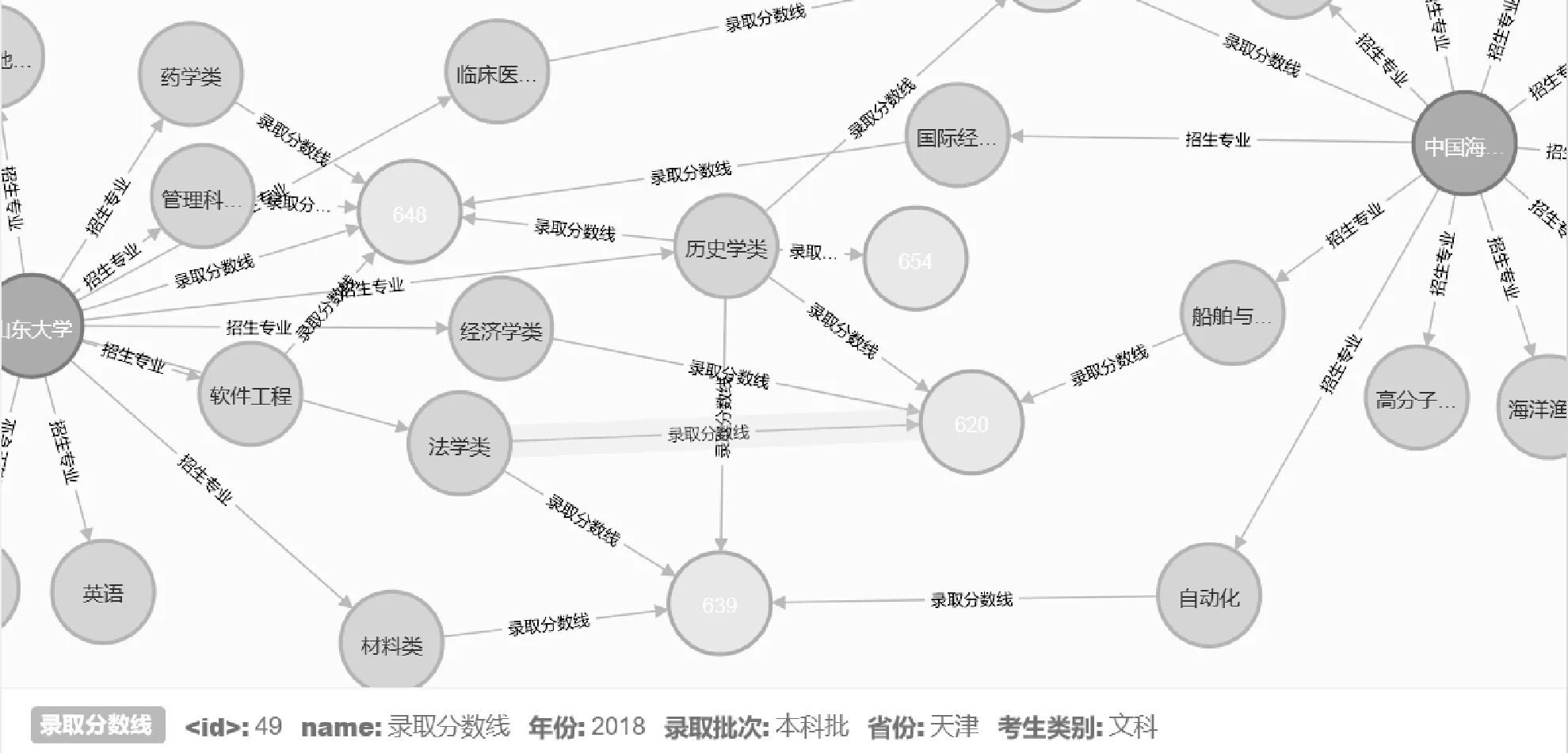
图5 知识图谱中关系的属性展示
2 基于语义解析的问答系统
本文主要采用基于语义解析的方法实现问答系统,通过添加约束到核心推理链[12]以生成查询图,然后将查询图映射成Cypher语句。采用的方法如下:1) 识别问句意图以生成答案节点。2) 将问句进行实体识别并提取出主题实体。3) 根据问句类别和主题实体生成核心推理链,并通过相似度计算模型对其进行质量评估。4) 对每条核心推理链添加约束,生成查询图,对生成的查询图再次进行相似度计算,并得到最终的得分。5) 将得分最高的查询图转换为Cypher查询语句,到知识库中检索答案返回给用户。其架构如图6所示。
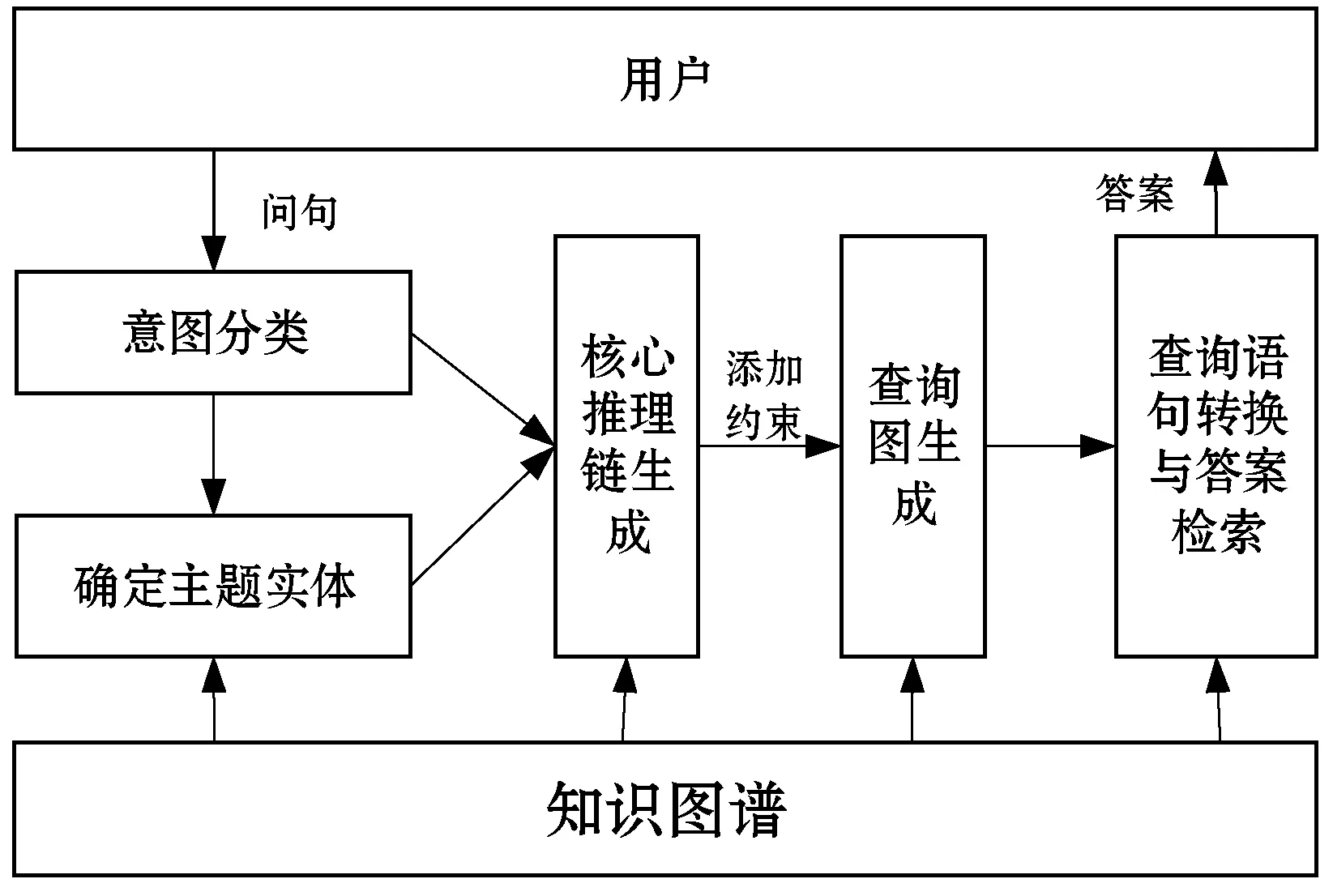
图6 问答系统流程
2.1 意图分类
意图分类的目的是知道用户的查询意图,即最终要返回给用户的节点类型。例如,当意图分类的结果是“专业”,那么也就知道最终返回给用户的实体必须属于“专业”类型;当意图分类的结果是“学校-属性”,那么就知道答案节点是“学校”类型,且询问的是其某个属性,因此,将答案节点限制为学校类型,并且通过“RETURN 学校.属性”的方式返回给用户所想要的答案。
本文定义分类的类别包括所构建的本体中的所有实体类型(12种)、实体-属性类型(5种)、关系类共18个类别。实体-属性类型是指询问的不是某个实体本身,而是实体的某个属性,如问句“青岛大学文学院在哪”的类别就属于“学院-属性”类,实体-属性类只有5种是因为一些实体类型如“省份”没有给其设置属性。关系类是指询问两个实体之间的关系,如“青岛大学是985高校吗”就属于关系类。
意图分类是本文问答系统的关键环节,其准确率较大地影响到问答系统的准确率,经过多种分类器的实验比较,本文选择BERT[13]微调模型用于本文的问句分类。微调模型如图7所示,将句子的每个字分割成一个token,即图7中的Toki,BERT的输入是Toki对应的表征Ei,然后通过堆叠的Transform编码器生成字向量Ti,由于句子头部的[CLS]对应的向量C包含了整个句子的语义信息,因此被送到输出层用于分类。
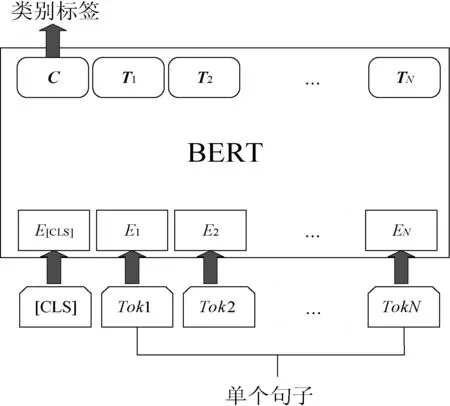
图7 BERT分类微调模型
2.2 主题实体识别
主题实体是问句查询的核心实体。大多数问题的答案都与核心实体有着直接或间接的联系,因此只需要找到一个核心实体,然后通过边的连接搜索其子图即可找到问题的答案[14]。
主题实体的识别分为两步。首先,通过命名实体模块识别所有实体;然后,根据设定的规则对其进行打分排序,设置排序第一的实体为主题实体。
2.2.1实体识别
实体识别的目的是识别句子中的实体信息,本文设计的问答系统面向的是高考咨询领域,因此涉及到的实体主要有省份、城市、学校、专业、学院、校区、年份、人名、录取分数、院校特性、排名等。对于类别有限、固定且易统计的实体,如省份、城市、年份、人名、学校名、录取批次等,本文通过调用HanLP的Python接口pyhanlp,利用其CRF实现并加上添加专业字典的方式来进行实体的识别,pyhanlp词性标注功能可以准确地实现大部分实体的识别。对于其他容易造成混淆的实体以及不能用词性标注解决的实体,如“青岛大学是211吗?”中“211”在词性标注里的结果是数词“m”,但在这里指的是学校特性。因此,对于这些实体,本文选择了BiLSTM-CRF的NER模型,这个模型在实体识别方面具有较好的效果,其数据集的标注格式如图8所示。

图8 实体识别数据集标注示例图
实体识别之后通过同义词典或正则对其进行改写,改写成在知识库中存储的标准形式,如“山东省”和“山东”都统一为“山东”。
2.2.2实体排序
在实体识别模块之后,获得了一系列实体,本文根据高考领域的本体模型以及常见问题,设置了如下的打分规则:
(1) 类型优先级。由于大部分问题是围绕学校的,因此学校类型的实体具有最高的优先级,分数为0;其余的实体类型按照到学校类型的最短距离来计算,距离越近优先级越高。
(2) 指向关系。指向关系是指优先选择指向其他实体的节点,而不是被指向的节点。对每个实体,计算指向此实体的边数,每条边计一分。
(3) 距离疑问词的距离。计算每个实体到问句疑问词的距离,将距离值作为分数添加给每个实体。
最后,将每个实体按其得分由低到高进行排序,分数最低的那个实体为主题实体。“排序”实体不算在主题实体中,如果问句中没有实体可以作为主题实体,用问句的答案节点作为主题实体。
2.3 核心推理链生成
核心推理链是指主题实体到答案节点的路径,比如问句“青岛大学有哪些专业在中心校区?”中主题实体节点“<青岛大学>”到答案节点“:专业”之间的路径就有四种情况,如图9所示,其中:“:”后的词表示实体的类型;“<>”中的词表示实体的值。本文将有实体值的节点称为实体节点,仅有实体类型而无具体值的节点称为变量节点,代表答案的节点称为答案节点,答案节点也属于变量节点。图9显示了四条路径:“青岛大学-属于-属于”“青岛大学-招生专业”“青岛大学-院系设置-招生专业”“青岛大学-包含校区-所属校区-招生专业”。
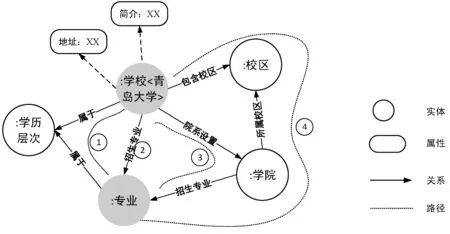
图9 核心推理链示例图
虽然这四条路径均能与答案节点相连,但是无疑第四条路径的质量最高,为了评估每条路径的质量,本文通过计算每条路径与问句的相似度,对每条路径进行评分排序。
通过观察本体图,我们发现任意两个实体的距离不超过3,而且问句中的答案大多数都在三跳以内,因此,我们只考虑三跳以内的核心推理链,具体步骤如下:
首先,通过查询知识库,计算主题实体节点与答案节点的最短距离,如果等于1,那么从知识库中查询主题实体节点到答案节点的所有一跳、两跳、三跳的路径;如果等于2,那么查询所有两跳、三跳的路径;如果等于3,那么仅查询一条路径即可。
在获得所有核心推理链之后,计算与问题之间的相似性。本文使用BERT初始化词向量,将两个句子分别输入到Siamese循环神经网络[15]来生成句子的语义表示,然后利用曼哈顿距离计算语义相似度,搭建的模型(BERT-Siamese模型)结构如图10所示,其中hleft和hright分别是两个BiLSTM的输出向量,将其进行曼哈顿距离计算后输出相似度结果y。

图10 本文相似度计算模型
2.4 添加约束
在得到核心推理链之后,还需要解析问句中的约束,问句中的约束是指对答案的限定,将答案聚焦在想要的范围。约束一般分为实体约束、非实体约束、排序约束,以及计数约束等[16]。
约束一般加在实体节点或者中间的变量节点处。核心推理链的实体节点就是主题实体,变量节点就是推理链中没有具体值的节点,如图11所示。对于问句“青岛大学哪些专业2019年的录取分数小于560?”,其核心推理链之一为“青岛大学-招生专业”,对于剩余实体“560”和“2019”即是对答案节点“:专业”约束,把剩余实体与答案节点建立连接,即生成最终的查询图。

图11 添加约束示例
添加约束的算法如算法1所示,由于已经将时间约束归为实体约束里,因此本文就依次考虑对实体约束、排序约束和计数约束的添加。
算法1添加约束算法
输入:核心推理链t,待添加的实体集合E。
输出:G。
1 G = ∅
2 insertttoT
3 foreache∈Edo
4Temp(t) = ∅
5 foreacht∈Tdo
6g=AddConstraint(t,e)
7 insertgtoTemp(t)
8 end
9T=Temp(t)
10 end
11 insertTtoG
12 ifpaixu==True:
13 foreachg∈Gdo
14 if “分数” or “排名”or “招生人数” ∈g:
15 insert paixuConstraint tog
16 else
17g1 =AddConstraint(g, “分数”)
18g2 =AddConstraint(g, “排名”)
19g3 =AddConstraint(g, “招生人数”)
20 insertg1,g2,g3 toG
21 end
22 ifisJishu==True:
23 foreachg∈Gdo
24 insertjishuConstrainttog
25 end
26 returnG
对于实体约束,首先判断此约束是实体类约束(如“中心校区”)还是属性类约束(如录取分数的属性“2019年”),如果是属性类约束,则先将其转换为具有此属性的实体类型。然后在推理链中查询是否有此实体类型的节点,如果有,则直接将约束添加给那个变量节点;如果没有,则与其中的变量节点建立关系,建立关系的原则是选择与距离最近的变量节点建立关系,如果与多个变量节点的最近距离相同,则分别与之建立关系,生成多个不同的查询图,如果与任一节点均无法建立关系,则舍弃掉此实体约束。另外对于类型为“分数”的实体进行额外检测,利用字符串匹配方法判断问句中是否在其前面出现“大于”或“小于”等词语,如果存在,则将约束中的“=”改为“>=”或“<=”。
对于排序约束,能进行排序的实体类型包括“排名”“分数”“招生人数”,因此如果有排序实体的存在,那么就查询此时的查询图中是否存在上述变量节点之一,如果有,则将此约束加到这个变量节点当中,如果查询图中没有上述变量节点,则分别添加上述节点和对应的排序约束,生成多个查询图。
对于计数约束,本文通过训练一个二分类的分类器,判断需要返回的是实体还是实体的数量。
最后采用2.3节的相似度计算模型对生成的每个查询图进行评分,此得分加上生成此查询图的推理链的分数为查询图最终的得分,选择最终得分排名第一的查询图作为最终的查询图。
2.5 查询语句生成
得到最终的查询图之后要将其转换为Neo4j数据库语句,Neo4j数据库使用的是Cypher查询语句,图12描述了程序运行中查询图的自动生成过程以及查询语句的转换。

图12 查询语句生成示例图
3 实 验
3.1 数据集
问句数据集:本文通过人工构建问句以及在一些大学的贴吧、百度知道等网站爬取高考咨询相关问句的方式,得到3 000条事实类问句作为数据集。本文的问句分类(意图分类和计数约束二分类)和命名实体识别均使用此数据集。
相似度计算数据集:相似度计算模型的输入为两个句子及其相似性标签,第一个句子来自于爬取的3 000条问句,第二个句子来自于知识库,从生成的核心推理链和查询图中人工选取其中最正确的数据,标签设置为1,其余的标签为0。为了让数据集的正负样本均衡,将正样本重复2次进行过采样。经过以上处理,得到一个含有29 000个句子对的数据集,将其按7∶3的比例分为训练集和测试集。
3.2 实验结果
本文采用微调BERT的方法进行问句分类,在测试集上的准确率分别为97%和100%,另外本文也探索了其他方法进行问句分类效果对比,实验结果如表1所示。
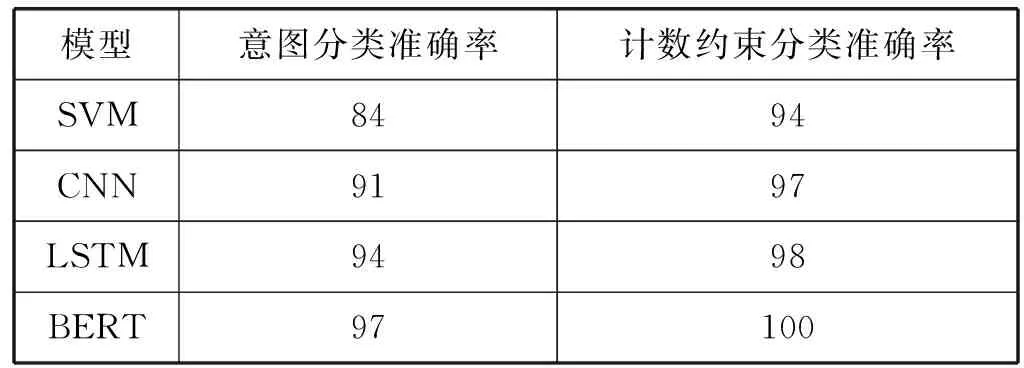
表1 问句分类实验结果(%)
BiLSTM-CRF模型的命名实体识别结果为:精确率为93%,召回率为92%,F1值为92%。BERT-Siamese模型的相似度计算结果为:精确率为79%,召回率为85%,F1值为81%。整个问答系统随机采取100道进行测试,其中84%的问题回答正确,从而验证了本文所提出的问答模型的合理性,也说明本文系统基本可以满足用户对高考咨询的一般问答需求。
3.3 问答系统实现
为了方便用户使用,利用Python的Flask框架搭建问答系统,运行界面如图13所示。考生可以查看各个省份的学校,或者根据分数选专业或者根据专业选大学,还可以查看学校之间的关系等。

图13 本文的问答系统界面
4 结 语
本文基于高考报名时考生经常咨询的问题,利用protégé设计高考领域的知识图谱本体,构建了高校信息知识图谱。在此基础上,对多限制问句的问答方法进行了研究,采用基于深度学习和语义解析相结合的方法,将用户的问句自动转换成知识库查询语句,实现了高考咨询问答系统。
本文的问答系统也有不足之处,本文系统只可以回答高考咨询领域的事实类问句,对于非事实类问句或者知识库中没有存入的知识无法回答;另外查询图的相似度计算的准确率也有待提高,因此今后的工作将在数据源、相似度计算算法等方面进行深入研究。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
军事文摘(2022年16期)2022-08-24
北京大学学报(自然科学版)(2022年1期)2022-02-21
校园英语·上旬(2020年5期)2020-08-02
校园英语·下旬(2019年2期)2019-04-08
校园英语·中旬(2019年1期)2019-02-26
新城乡(2018年6期)2018-07-09
校园英语·中旬(2018年3期)2018-05-29
——基于与QuestionPoint的对比
新世纪图书馆(2014年11期)2014-02-23
读写算·高年级(2009年3期)2009-11-16
